 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Bounding the Invertibility of Privacy-preserving Instance Encoding using Fisher Information
May 06, 2023
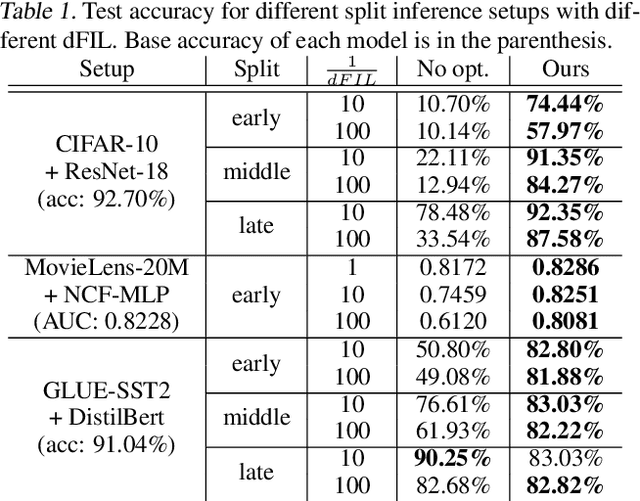
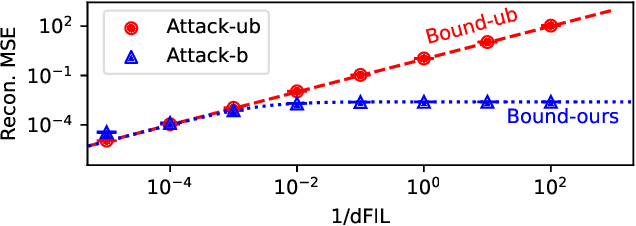
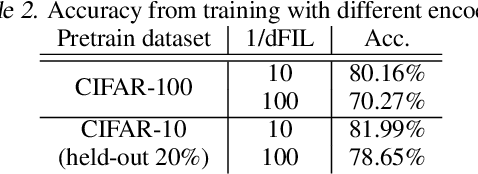
Privacy-preserving instance encoding aims to encode raw data as feature vectors without revealing their privacy-sensitive information. When designed properly, these encodings can be used for downstream ML applications such as training and inference with limited privacy risk. However, the vast majority of existing instance encoding schemes are based on heuristics and their privacy-preserving properties are only validated empirically against a limited set of attacks. In this paper, we propose a theoretically-principled measure for the privacy of instance encoding based on Fisher information. We show that our privacy measure is intuitive, easily applicable, and can be used to bound the invertibility of encodings both theoretically and empirically.
The World Literature Knowledge Graph
Jul 31, 2023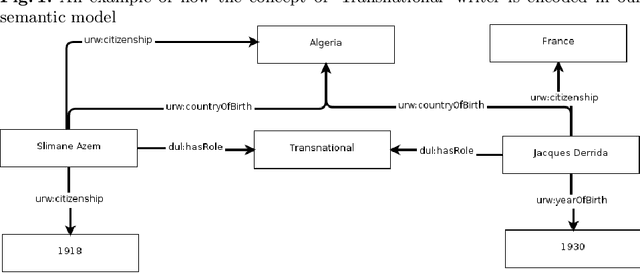
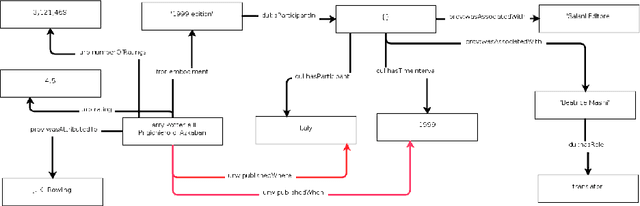


Digital media have enabled the access to unprecedented literary knowledge. Authors, readers, and scholars are now able to discover and share an increasing amount of information about books and their authors. However, these sources of knowledge are fragmented and do not adequately represent non-Western writers and their works. In this paper we present The World Literature Knowledge Graph, a semantic resource containing 194,346 writers and 965,210 works, specifically designed for exploring facts about literary works and authors from different parts of the world. The knowledge graph integrates information about the reception of literary works gathered from 3 different communities of readers, aligned according to a single semantic model. The resource is accessible through an online visualization platform, which can be found at the following URL: https://literaturegraph.di.unito.it/. This platform has been rigorously tested and validated by $3$ distinct categories of experts who have found it to be highly beneficial for their respective work domains. These categories include teachers, researchers in the humanities, and professionals in the publishing industry. The feedback received from these experts confirms that they can effectively utilize the platform to enhance their work processes and achieve valuable outcomes.
A hybrid approach for improving U-Net variants in medical image segmentation
Jul 31, 2023

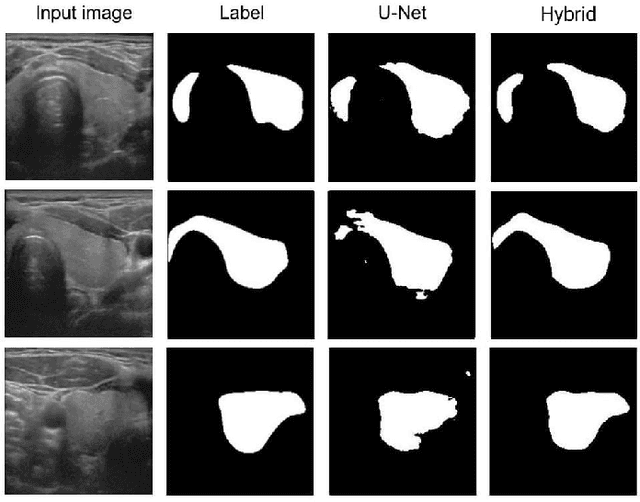
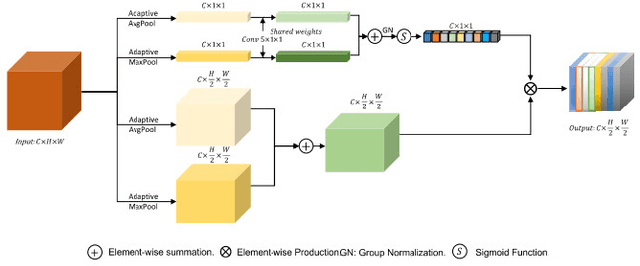
Medical image segmentation is vital to the area of medical imaging because it enables professionals to more accurately examine and understand the information offered by different imaging modalities. The technique of splitting a medical image into various segments or regions of interest is known as medical image segmentation. The segmented images that are produced can be used for many different things, including diagnosis, surgery planning, and therapy evaluation. In initial phase of research, major focus has been given to review existing deep-learning approaches, including researches like MultiResUNet, Attention U-Net, classical U-Net, and other variants. The attention feature vectors or maps dynamically add important weights to critical information, and most of these variants use these to increase accuracy, but the network parameter requirements are somewhat more stringent. They face certain problems such as overfitting, as their number of trainable parameters is very high, and so is their inference time. Therefore, the aim of this research is to reduce the network parameter requirements using depthwise separable convolutions, while maintaining performance over some medical image segmentation tasks such as skin lesion segmentation using attention system and residual connections.
Evaluating Emotional Nuances in Dialogue Summarization
Jul 23, 2023Automatic dialogue summarization is a well-established task that aims to identify the most important content from human conversations to create a short textual summary. Despite recent progress in the field, we show that most of the research has focused on summarizing the factual information, leaving aside the affective content, which can yet convey useful information to analyse, monitor, or support human interactions. In this paper, we propose and evaluate a set of measures $PEmo$, to quantify how much emotion is preserved in dialog summaries. Results show that, summarization models of the state-of-the-art do not preserve well the emotional content in the summaries. We also show that by reducing the training set to only emotional dialogues, the emotional content is better preserved in the generated summaries, while conserving the most salient factual information.
InteractiveIE: Towards Assessing the Strength of Human-AI Collaboration in Improving the Performance of Information Extraction
May 24, 2023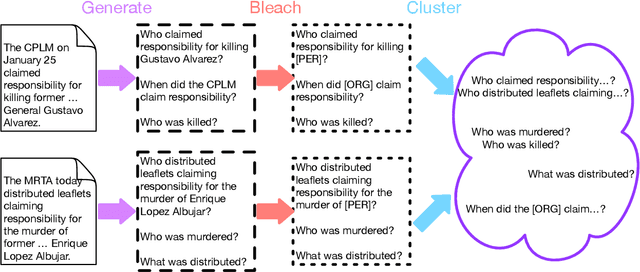

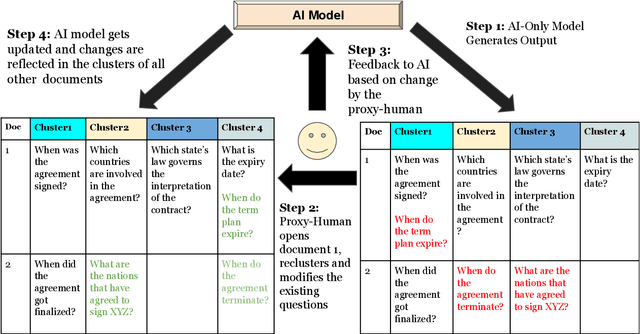
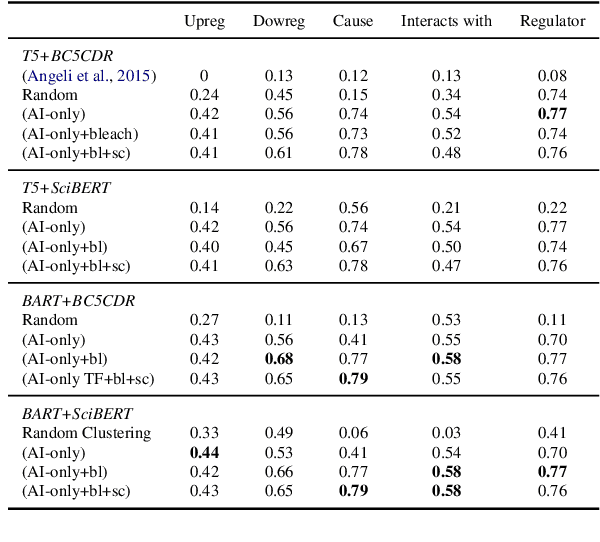
Learning template based information extraction from documents is a crucial yet difficult task. Prior template-based IE approaches assume foreknowledge of the domain templates; however, real-world IE do not have pre-defined schemas and it is a figure-out-as you go phenomena. To quickly bootstrap templates in a real-world setting, we need to induce template slots from documents with zero or minimal supervision. Since the purpose of question answering intersect with the goal of information extraction, we use automatic question generation to induce template slots from the documents and investigate how a tiny amount of a proxy human-supervision on-the-fly (termed as InteractiveIE) can further boost the performance. Extensive experiments on biomedical and legal documents, where obtaining training data is expensive, reveal encouraging trends of performance improvement using InteractiveIE over AI-only baseline.
A Review of Change of Variable Formulas for Generative Modeling
Aug 04, 2023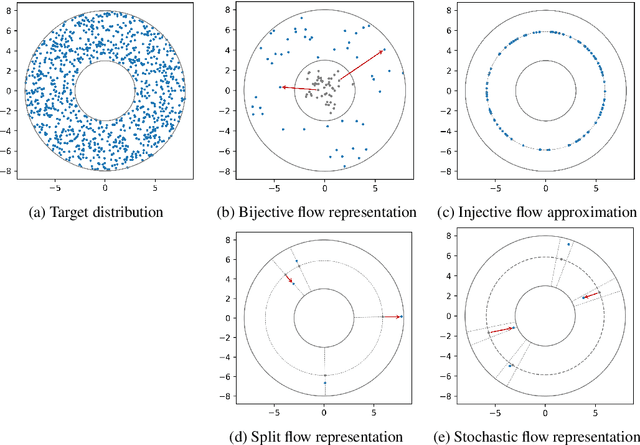

Change-of-variables (CoV) formulas allow to reduce complicated probability densities to simpler ones by a learned transformation with tractable Jacobian determinant. They are thus powerful tools for maximum-likelihood learning, Bayesian inference, outlier detection, model selection, etc. CoV formulas have been derived for a large variety of model types, but this information is scattered over many separate works. We present a systematic treatment from the unifying perspective of encoder/decoder architectures, which collects 28 CoV formulas in a single place, reveals interesting relationships between seemingly diverse methods, emphasizes important distinctions that are not always clear in the literature, and identifies surprising gaps for future research.
Timeseries-aware Uncertainty Wrappers for Uncertainty Quantification of Information-Fusion-Enhanced AI Models based on Machine Learning
May 24, 2023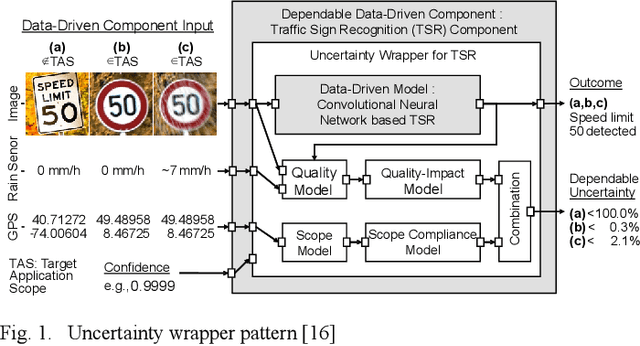
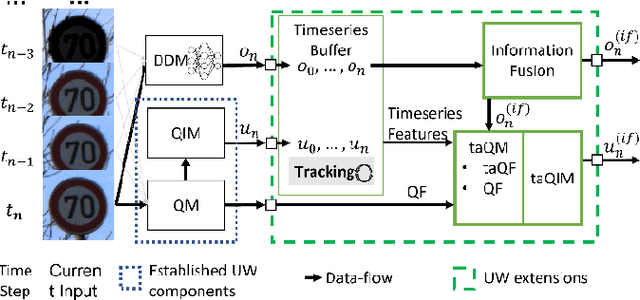
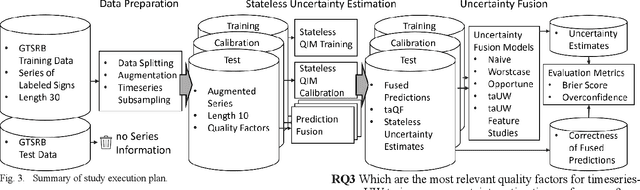
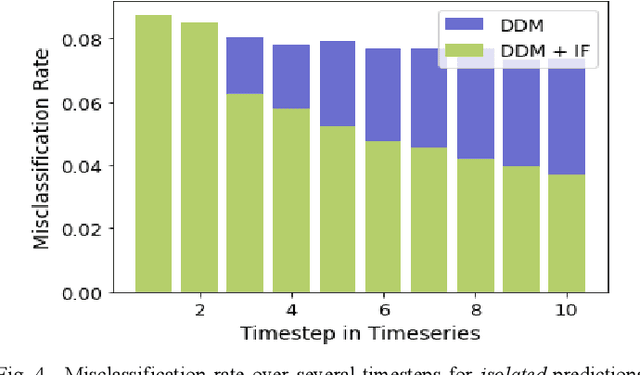
As the use of Artificial Intelligence (AI) components in cyber-physical systems is becoming more common, the need for reliable system architectures arises. While data-driven models excel at perception tasks, model outcomes are usually not dependable enough for safety-critical applications. In this work,we present a timeseries-aware uncertainty wrapper for dependable uncertainty estimates on timeseries data. The uncertainty wrapper is applied in combination with information fusion over successive model predictions in time. The application of the uncertainty wrapper is demonstrated with a traffic sign recognition use case. We show that it is possible to increase model accuracy through information fusion and additionally increase the quality of uncertainty estimates through timeseries-aware input quality features.
Federated Classification in Hyperbolic Spaces via Secure Aggregation of Convex Hulls
Aug 14, 2023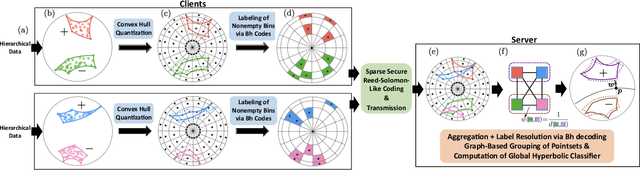
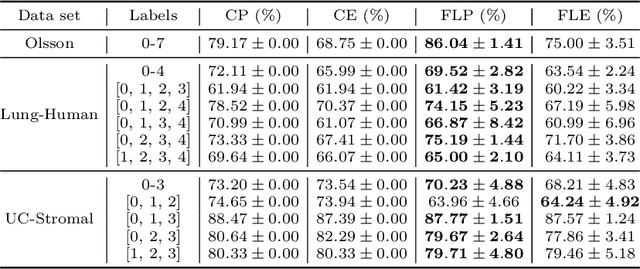
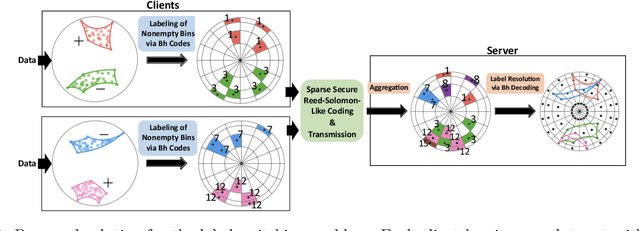

Hierarchical and tree-like data sets arise in many applications, including language processing, graph data mining, phylogeny and genomics. It is known that tree-like data cannot be embedded into Euclidean spaces of finite dimension with small distortion. This problem can be mitigated through the use of hyperbolic spaces. When such data also has to be processed in a distributed and privatized setting, it becomes necessary to work with new federated learning methods tailored to hyperbolic spaces. As an initial step towards the development of the field of federated learning in hyperbolic spaces, we propose the first known approach to federated classification in hyperbolic spaces. Our contributions are as follows. First, we develop distributed versions of convex SVM classifiers for Poincar\'e discs. In this setting, the information conveyed from clients to the global classifier are convex hulls of clusters present in individual client data. Second, to avoid label switching issues, we introduce a number-theoretic approach for label recovery based on the so-called integer $B_h$ sequences. Third, we compute the complexity of the convex hulls in hyperbolic spaces to assess the extent of data leakage; at the same time, in order to limit the communication cost for the hulls, we propose a new quantization method for the Poincar\'e disc coupled with Reed-Solomon-like encoding. Fourth, at server level, we introduce a new approach for aggregating convex hulls of the clients based on balanced graph partitioning. We test our method on a collection of diverse data sets, including hierarchical single-cell RNA-seq data from different patients distributed across different repositories that have stringent privacy constraints. The classification accuracy of our method is up to $\sim 11\%$ better than its Euclidean counterpart, demonstrating the importance of privacy-preserving learning in hyperbolic spaces.
Sequences with identical autocorrelation spectra
Aug 14, 2023Aperiodic autocorrelation measures the similarity between a finite-length sequence of complex numbers and translates of itself. Autocorrelation is important in communications, remote sensing, and scientific instrumentation. The autocorrelation function reports the aperiodic autocorrelation at every possible translation. Knowing the autocorrelation function of a sequence is equivalent to knowing the magnitude of its Fourier transform. Resolving the lack of phase information is called the phase problem. We say that two sequences are isospectral to mean that they have the same aperiodic autocorrelation function. Sequences used in technological applications often have restrictions on their terms: they are not arbitrary complex numbers, but come from an alphabet that may reside in a proper subring of the complex field or may come from a finite set of values. For example, binary sequences involve terms equal to only $+1$ and $-1$. In this paper, we investigate the necessary and sufficient conditions for two sequences to be isospectral, where we take their alphabet into consideration. There are trivial forms of isospectrality arising from modifications that predictably preserve the autocorrelation, for example, negating sequences or both conjugating their terms and writing them in reverse order. By an exhaustive search of binary sequences up to length $34$, we find that nontrivial isospectrality among binary sequences does occur, but is rare. We say that a positive integer $n$ is barren to mean that there are no nontrivially isospectral binary sequences of length $n$. For integers $n \leq 34$, we found that the barren ones are $1$--$8$, $10$, $11$, $13$, $14$, $19$, $22$, $23$, $26$, and $29$. We prove that any multiple of a non-barren number is also not barren, and pose an open question as to whether there are finitely or infinitely many barren numbers.
LadleNet: Translating Thermal Infrared Images to Visible Light Images Using A Scalable Two-stage U-Net
Aug 12, 2023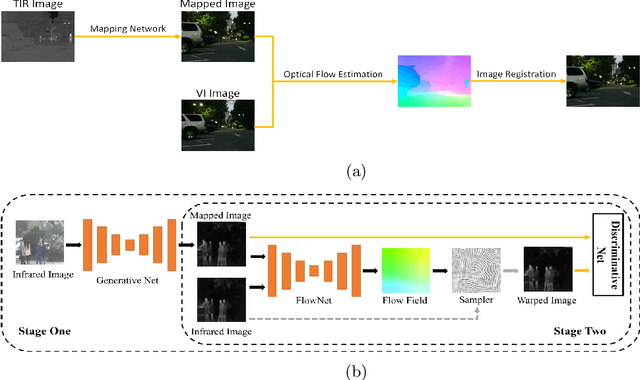
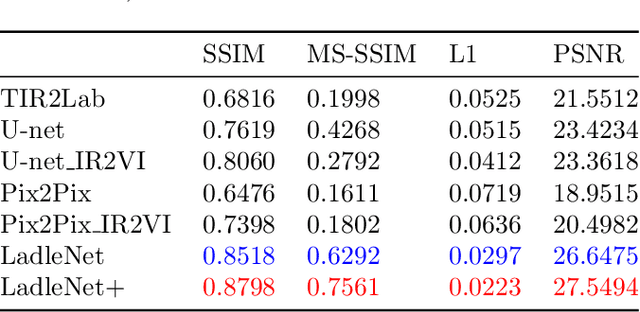

The translation of thermal infrared (TIR) images to visible light (VI) images presents a challenging task with potential applications spanning various domains such as TIR-VI image registration and fusion. Leveraging supplementary information derived from TIR image conversions can significantly enhance model performance and generalization across these applications. However, prevailing issues within this field include suboptimal image fidelity and limited model scalability. In this paper, we introduce an algorithm, LadleNet, based on the U-Net architecture. LadleNet employs a two-stage U-Net concatenation structure, augmented with skip connections and refined feature aggregation techniques, resulting in a substantial enhancement in model performance. Comprising 'Handle' and 'Bowl' modules, LadleNet's Handle module facilitates the construction of an abstract semantic space, while the Bowl module decodes this semantic space to yield mapped VI images. The Handle module exhibits extensibility by allowing the substitution of its network architecture with semantic segmentation networks, thereby establishing more abstract semantic spaces to bolster model performance. Consequently, we propose LadleNet+, which replaces LadleNet's Handle module with the pre-trained DeepLabv3+ network, thereby endowing the model with enhanced semantic space construction capabilities. The proposed method is evaluated and tested on the KAIST dataset, accompanied by quantitative and qualitative analyses. Compared to existing methodologies, our approach achieves state-of-the-art performance in terms of image clarity and perceptual quality. The source code will be made available at https://github.com/Ach-1914/LadleNet/tree/main/.