 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multiscale Global and Regional Feature Learning Using Co-Tuplet Loss for Offline Handwritten Signature Verification
Aug 01, 2023

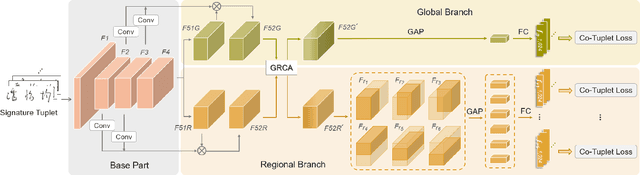
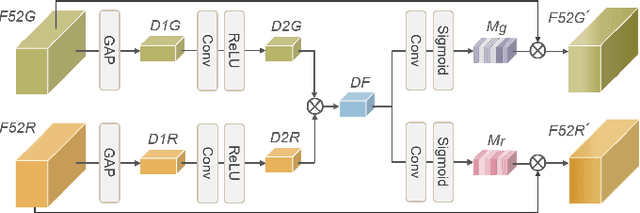
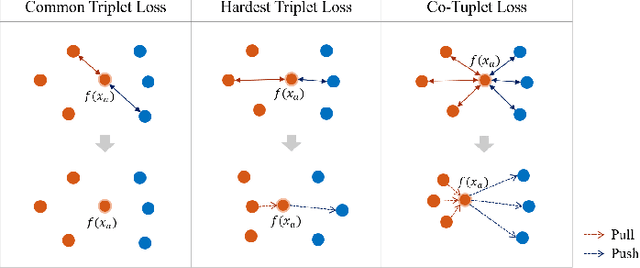
Handwritten signature verification is a significant biometric verification method widely acknowledged by legal and financial institutions. However, the development of automatic signature verification systems poses challenges due to inter-writer similarity, intra-writer variations, and the limited number of signature samples. To address these challenges, we propose a multiscale global and regional feature learning network (MGRNet) with the co-tuplet loss, a new metric learning loss, for offline handwritten signature verification. MGRNet jointly learns global and regional information from various spatial scales and integrates it to generate discriminative features. Consequently, it can capture overall signature stroke information while detecting detailed local differences between genuine and skilled-forged signatures. To enhance the discriminative capability of our network further, we propose the co-tuplet loss, which simultaneously considers multiple positive and negative examples to learn distance metrics. By dealing with inter-writer similarity and intra-writer variations and focusing on informative examples, the co-tuplet loss addresses the limitations of typical metric learning losses. Additionally, we develop HanSig, a large-scale Chinese signature dataset, to facilitate the development of robust systems for this script. The dataset is available at https://github.com/ashleyfhh/HanSig. Experimental results on four benchmark datasets in different languages demonstrate the promising performance of our method in comparison to state-of-the-art approaches.
Mirror Natural Evolution Strategies
Aug 01, 2023The zeroth-order optimization has been widely used in machine learning applications. However, the theoretical study of the zeroth-order optimization focus on the algorithms which approximate (first-order) gradients using (zeroth-order) function value difference at a random direction. The theory of algorithms which approximate the gradient and Hessian information by zeroth-order queries is much less studied. In this paper, we focus on the theory of zeroth-order optimization which utilizes both the first-order and second-order information approximated by the zeroth-order queries. We first propose a novel reparameterized objective function with parameters $(\mu, \Sigma)$. This reparameterized objective function achieves its optimum at the minimizer and the Hessian inverse of the original objective function respectively, but with small perturbations. Accordingly, we propose a new algorithm to minimize our proposed reparameterized objective, which we call \texttt{MiNES} (mirror descent natural evolution strategy). We show that the estimated covariance matrix of \texttt{MiNES} converges to the inverse of Hessian matrix of the objective function with a convergence rate $\widetilde{\mathcal{O}}(1/k)$, where $k$ is the iteration number and $\widetilde{\mathcal{O}}(\cdot)$ hides the constant and $\log$ terms. We also provide the explicit convergence rate of \texttt{MiNES} and how the covariance matrix promotes the convergence rate.
LGViT: Dynamic Early Exiting for Accelerating Vision Transformer
Aug 01, 2023
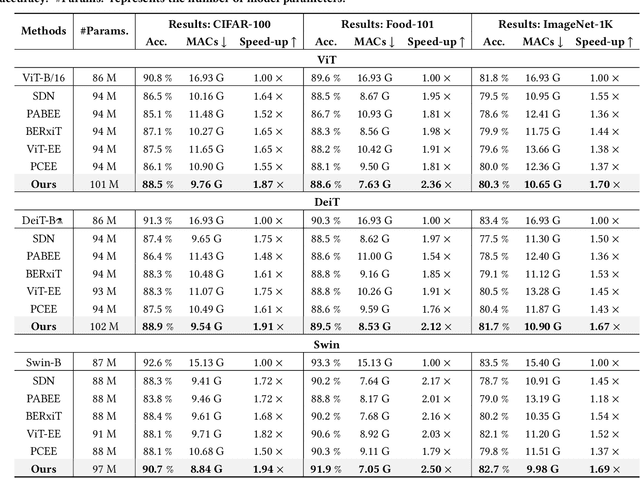
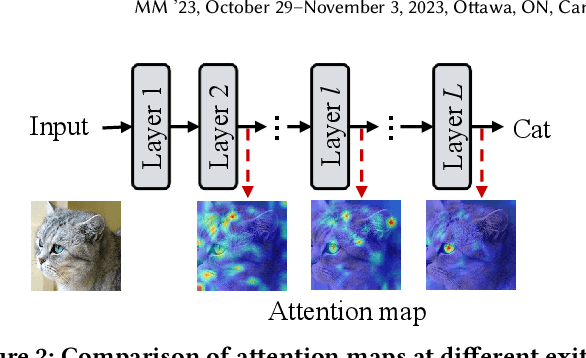

Recently, the efficient deployment and acceleration of powerful vision transformers (ViTs) on resource-limited edge devices for providing multimedia services have become attractive tasks. Although early exiting is a feasible solution for accelerating inference, most works focus on convolutional neural networks (CNNs) and transformer models in natural language processing (NLP).Moreover, the direct application of early exiting methods to ViTs may result in substantial performance degradation. To tackle this challenge, we systematically investigate the efficacy of early exiting in ViTs and point out that the insufficient feature representations in shallow internal classifiers and the limited ability to capture target semantic information in deep internal classifiers restrict the performance of these methods. We then propose an early exiting framework for general ViTs termed LGViT, which incorporates heterogeneous exiting heads, namely, local perception head and global aggregation head, to achieve an efficiency-accuracy trade-off. In particular, we develop a novel two-stage training scheme, including end-to-end training and self-distillation with the backbone frozen to generate early exiting ViTs, which facilitates the fusion of global and local information extracted by the two types of heads. We conduct extensive experiments using three popular ViT backbones on three vision datasets. Results demonstrate that our LGViT can achieve competitive performance with approximately 1.8 $\times$ speed-up.
Low Rank Properties for Estimating Microphones Start Time and Sources Emission Time
Jul 14, 2023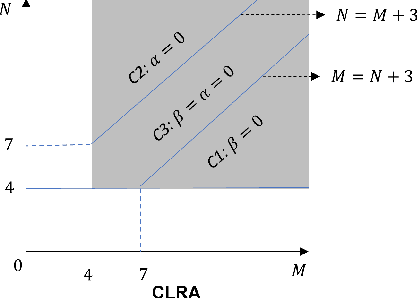
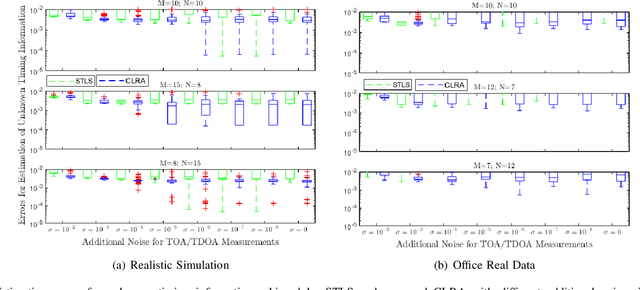
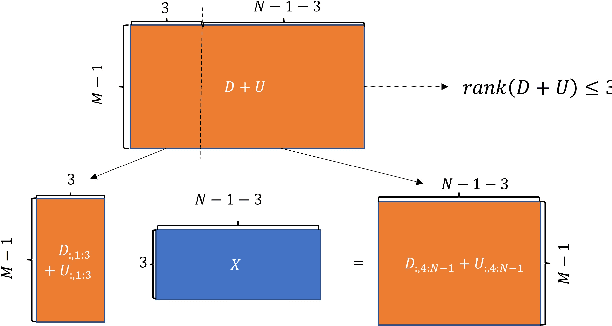

The absence of unknown timing information about the microphones recording start time and the sources emission time presents a challenge in several applications, including joint microphones and sources localization. Compared with traditional optimization methods that try to estimate unknown timing information directly, low rank property (LRP) contains an additional low rank structure that facilitates a linear constraint of unknown timing information for formulating corresponding low rank structure information, enabling the achievement of global optimal solutions of unknown timing information with suitable initialization. However, the initialization of unknown timing information is random, resulting in local minimal values for estimation of the unknown timing information. In this paper, we propose a combined low rank approximation method to alleviate the effect of random initialization on the estimation of unknown timing information. We define three new variants of LRP supported by proof that allows unknown timing information to benefit from more low rank structure information. Then, by utilizing the low rank structure information from both LRP and proposed variants of LRP, four linear constraints of unknown timing information are presented. Finally, we use the proposed combined low rank approximation algorithm to obtain global optimal solutions of unknown timing information through the four available linear constraints. Experimental results demonstrate superior performance of our method compared to state-of-the-art approaches in terms of recovery rate (the number of successful initialization for any configuration), convergency rate (the number of successfully recovered configurations), and estimation errors of unknown timing information.
Federated Classification in Hyperbolic Spaces via Secure Aggregation of Convex Hulls
Aug 14, 2023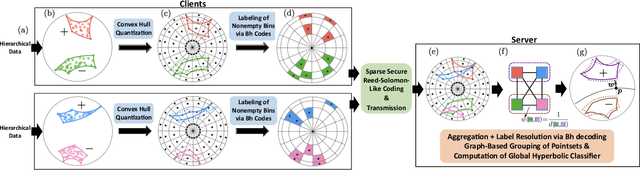
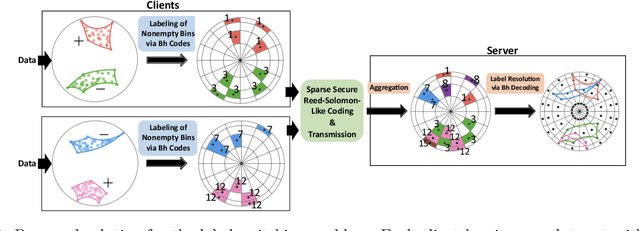

Hierarchical and tree-like data sets arise in many applications, including language processing, graph data mining, phylogeny and genomics. It is known that tree-like data cannot be embedded into Euclidean spaces of finite dimension with small distortion. This problem can be mitigated through the use of hyperbolic spaces. When such data also has to be processed in a distributed and privatized setting, it becomes necessary to work with new federated learning methods tailored to hyperbolic spaces. As an initial step towards the development of the field of federated learning in hyperbolic spaces, we propose the first known approach to federated classification in hyperbolic spaces. Our contributions are as follows. First, we develop distributed versions of convex SVM classifiers for Poincar\'e discs. In this setting, the information conveyed from clients to the global classifier are convex hulls of clusters present in individual client data. Second, to avoid label switching issues, we introduce a number-theoretic approach for label recovery based on the so-called integer $B_h$ sequences. Third, we compute the complexity of the convex hulls in hyperbolic spaces to assess the extent of data leakage; at the same time, in order to limit the communication cost for the hulls, we propose a new quantization method for the Poincar\'e disc coupled with Reed-Solomon-like encoding. Fourth, at server level, we introduce a new approach for aggregating convex hulls of the clients based on balanced graph partitioning. We test our method on a collection of diverse data sets, including hierarchical single-cell RNA-seq data from different patients distributed across different repositories that have stringent privacy constraints. The classification accuracy of our method is up to $\sim 11\%$ better than its Euclidean counterpart, demonstrating the importance of privacy-preserving learning in hyperbolic spaces.
Sequences with identical autocorrelation spectra
Aug 14, 2023Aperiodic autocorrelation measures the similarity between a finite-length sequence of complex numbers and translates of itself. Autocorrelation is important in communications, remote sensing, and scientific instrumentation. The autocorrelation function reports the aperiodic autocorrelation at every possible translation. Knowing the autocorrelation function of a sequence is equivalent to knowing the magnitude of its Fourier transform. Resolving the lack of phase information is called the phase problem. We say that two sequences are isospectral to mean that they have the same aperiodic autocorrelation function. Sequences used in technological applications often have restrictions on their terms: they are not arbitrary complex numbers, but come from an alphabet that may reside in a proper subring of the complex field or may come from a finite set of values. For example, binary sequences involve terms equal to only $+1$ and $-1$. In this paper, we investigate the necessary and sufficient conditions for two sequences to be isospectral, where we take their alphabet into consideration. There are trivial forms of isospectrality arising from modifications that predictably preserve the autocorrelation, for example, negating sequences or both conjugating their terms and writing them in reverse order. By an exhaustive search of binary sequences up to length $34$, we find that nontrivial isospectrality among binary sequences does occur, but is rare. We say that a positive integer $n$ is barren to mean that there are no nontrivially isospectral binary sequences of length $n$. For integers $n \leq 34$, we found that the barren ones are $1$--$8$, $10$, $11$, $13$, $14$, $19$, $22$, $23$, $26$, and $29$. We prove that any multiple of a non-barren number is also not barren, and pose an open question as to whether there are finitely or infinitely many barren numbers.
LadleNet: Translating Thermal Infrared Images to Visible Light Images Using A Scalable Two-stage U-Net
Aug 12, 2023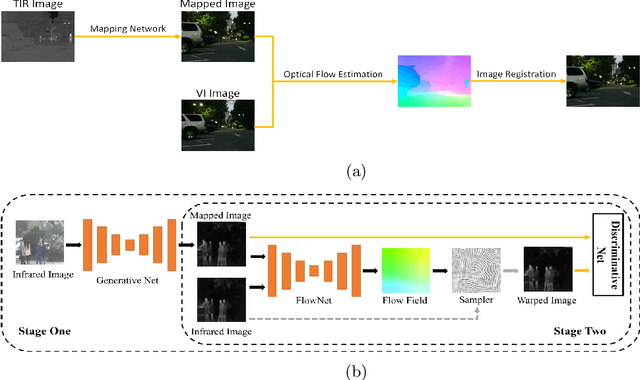
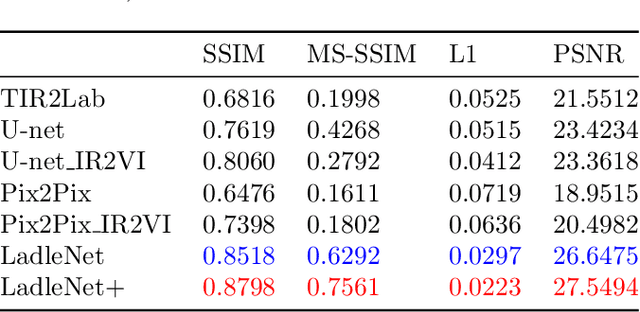
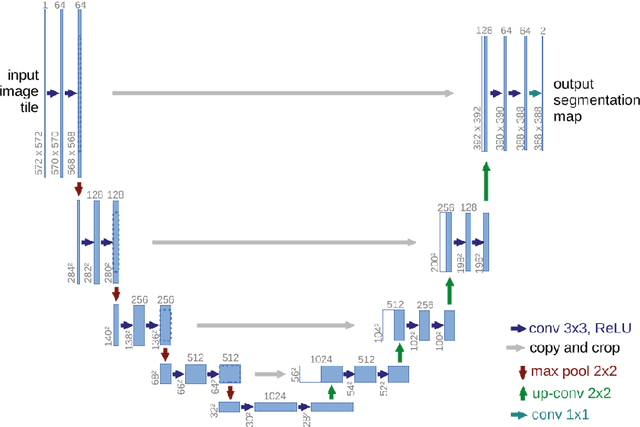

The translation of thermal infrared (TIR) images to visible light (VI) images presents a challenging task with potential applications spanning various domains such as TIR-VI image registration and fusion. Leveraging supplementary information derived from TIR image conversions can significantly enhance model performance and generalization across these applications. However, prevailing issues within this field include suboptimal image fidelity and limited model scalability. In this paper, we introduce an algorithm, LadleNet, based on the U-Net architecture. LadleNet employs a two-stage U-Net concatenation structure, augmented with skip connections and refined feature aggregation techniques, resulting in a substantial enhancement in model performance. Comprising 'Handle' and 'Bowl' modules, LadleNet's Handle module facilitates the construction of an abstract semantic space, while the Bowl module decodes this semantic space to yield mapped VI images. The Handle module exhibits extensibility by allowing the substitution of its network architecture with semantic segmentation networks, thereby establishing more abstract semantic spaces to bolster model performance. Consequently, we propose LadleNet+, which replaces LadleNet's Handle module with the pre-trained DeepLabv3+ network, thereby endowing the model with enhanced semantic space construction capabilities. The proposed method is evaluated and tested on the KAIST dataset, accompanied by quantitative and qualitative analyses. Compared to existing methodologies, our approach achieves state-of-the-art performance in terms of image clarity and perceptual quality. The source code will be made available at https://github.com/Ach-1914/LadleNet/tree/main/.
Digital elevation model correction in urban areas using extreme gradient boosting, land cover and terrain parameters
Aug 12, 2023
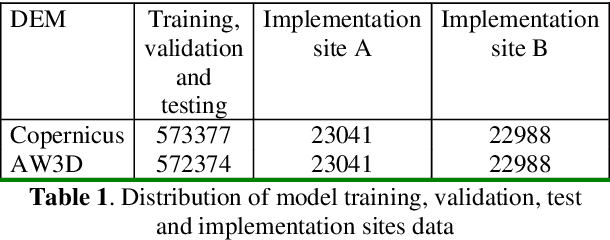


The accuracy of digital elevation models (DEMs) in urban areas is influenced by numerous factors including land cover and terrain irregularities. Moreover, building artifacts in global DEMs cause artificial blocking of surface flow pathways. This compromises their quality and adequacy for hydrological and environmental modelling in urban landscapes where precise and accurate terrain information is needed. In this study, the extreme gradient boosting (XGBoost) ensemble algorithm is adopted for enhancing the accuracy of two medium-resolution 30m DEMs over Cape Town, South Africa: Copernicus GLO-30 and ALOS World 3D (AW3D). XGBoost is a scalable, portable and versatile gradient boosting library that can solve many environmental modelling problems. The training datasets are comprised of eleven predictor variables including elevation, urban footprints, slope, aspect, surface roughness, topographic position index, terrain ruggedness index, terrain surface texture, vector roughness measure, forest cover and bare ground cover. The target variable (elevation error) was calculated with respect to highly accurate airborne LiDAR. After training and testing, the model was applied for correcting the DEMs at two implementation sites. The correction achieved significant accuracy gains which are competitive with other proposed methods. The root mean square error (RMSE) of Copernicus DEM improved by 46 to 53% while the RMSE of AW3D DEM improved by 72 to 73%. These results showcase the potential of gradient boosted trees for enhancing the quality of DEMs, and for improved hydrological modelling in urban catchments.
A Brief Wellbeing Training Session Delivered by a Humanoid Social Robot: A Pilot Randomized Controlled Trial
Aug 12, 2023Mental health and psychological distress are rising in adults, showing the importance of wellbeing promotion, support, and technique practice that is effective and accessible. Interactive social robots have been tested to deliver health programs but have not been explored to deliver wellbeing technique training in detail. A pilot randomised controlled trial was conducted to explore the feasibility of an autonomous humanoid social robot to deliver a brief mindful breathing technique to promote information around wellbeing. It contained two conditions: brief technique training (Technique) and control designed to represent a simple wait-list activity to represent a relationship-building discussion (Simple Rapport). This trial also explored willingness to discuss health-related topics with a robot. Recruitment uptake rate through convenience sampling was high (53%). A total of 230 participants took part (mean age = 29 years) with 71% being higher education students. There were moderate ratings of technique enjoyment, perceived usefulness, and likelihood to repeat the technique again. Interaction effects were found across measures with scores varying across gender and distress levels. Males with high distress and females with low distress who received the simple rapport activity reported greater comfort to discuss non-health topics than males with low distress and females with high distress. This trial marks a notable step towards the design and deployment of an autonomous wellbeing intervention to investigate the impact of a brief robot-delivered mindfulness training program for a sub-clinical population.
MapNeRF: Incorporating Map Priors into Neural Radiance Fields for Driving View Simulation
Jul 27, 2023Simulating camera sensors is a crucial task in autonomous driving. Although neural radiance fields are exceptional at synthesizing photorealistic views in driving simulations, they still fail in generating extrapolated views. This paper proposes to incorporate map priors into neural radiance fields to synthesize out-of-trajectory driving views with semantic road consistency. The key insight is that map information can be utilized as a prior to guide the training of the radiance fields with uncertainty. Specifically, we utilize the coarse ground surface as uncertain information to supervise the density field and warp depth with uncertainty from unknown camera poses to ensure multi-view consistency. Experimental results demonstrate that our approach can produce semantic consistency in deviated views for vehicle camera simulation.