 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Hierarchical State Abstraction Based on Structural Information Principles
Apr 24, 2023
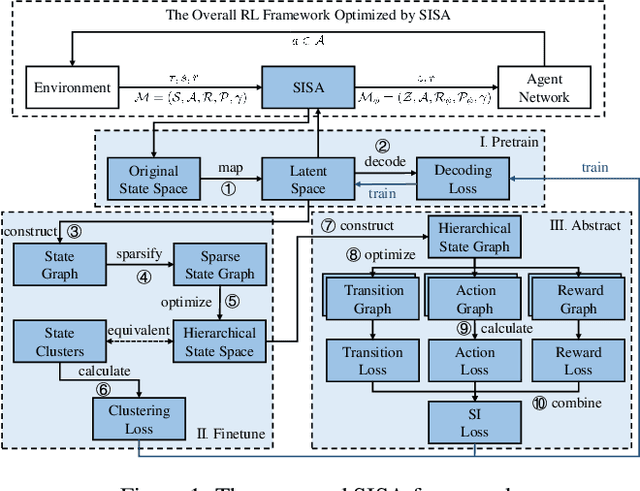

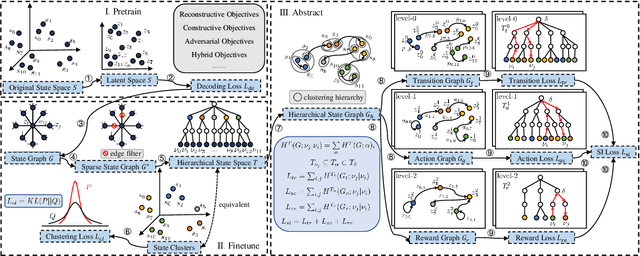
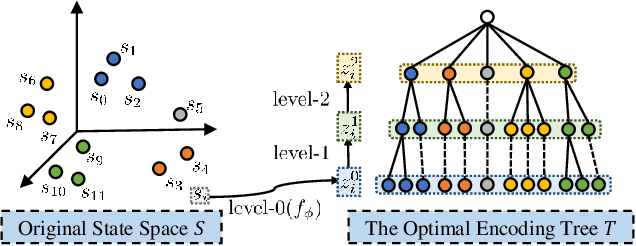
State abstraction optimizes decision-making by ignoring irrelevant environmental information in reinforcement learning with rich observations. Nevertheless, recent approaches focus on adequate representational capacities resulting in essential information loss, affecting their performances on challenging tasks. In this article, we propose a novel mathematical Structural Information principles-based State Abstraction framework, namely SISA, from the information-theoretic perspective. Specifically, an unsupervised, adaptive hierarchical state clustering method without requiring manual assistance is presented, and meanwhile, an optimal encoding tree is generated. On each non-root tree node, a new aggregation function and condition structural entropy are designed to achieve hierarchical state abstraction and compensate for sampling-induced essential information loss in state abstraction. Empirical evaluations on a visual gridworld domain and six continuous control benchmarks demonstrate that, compared with five SOTA state abstraction approaches, SISA significantly improves mean episode reward and sample efficiency up to 18.98 and 44.44%, respectively. Besides, we experimentally show that SISA is a general framework that can be flexibly integrated with different representation-learning objectives to improve their performances further.
What is the Impact of Releasing Code with Publications? Statistics from the Machine Learning, Robotics, and Control Communities
Aug 19, 2023Open-sourcing research publications is a key enabler for the reproducibility of studies and the collective scientific progress of a research community. As all fields of science develop more advanced algorithms, we become more dependent on complex computational toolboxes -- sharing research ideas solely through equations and proofs is no longer sufficient to communicate scientific developments. Over the past years, several efforts have highlighted the importance and challenges of transparent and reproducible research; code sharing is one of the key necessities in such efforts. In this article, we study the impact of code release on scientific research and present statistics from three research communities: machine learning, robotics, and control. We found that, over a six-year period (2016-2021), the percentages of papers with code at major machine learning, robotics, and control conferences have at least doubled. Moreover, high-impact papers were generally supported by open-source codes. As an example, the top 1% of most cited papers at the Conference on Neural Information Processing Systems (NeurIPS) consistently included open-source codes. In addition, our analysis shows that popular code repositories generally come with high paper citations, which further highlights the coupling between code sharing and the impact of scientific research. While the trends are encouraging, we would like to continue to promote and increase our efforts toward transparent, reproducible research that accelerates innovation -- releasing code with our papers is a clear first step.
Learning to Distill Global Representation for Sparse-View CT
Aug 19, 2023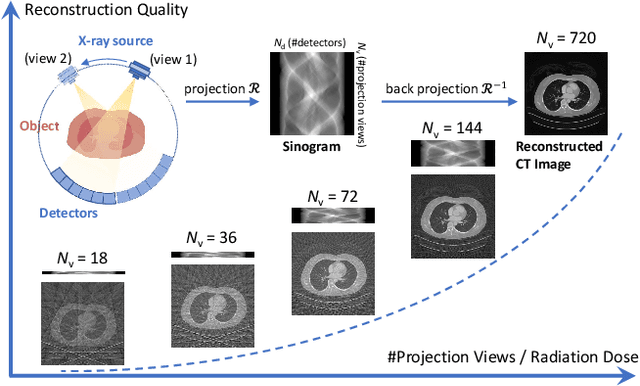
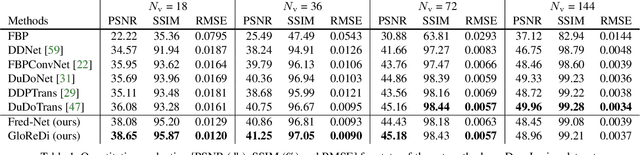
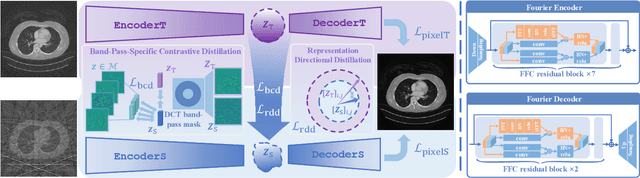
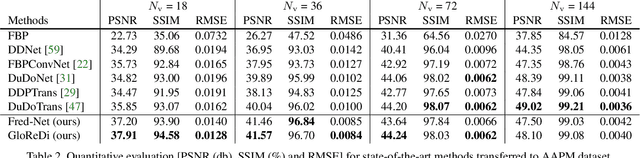
Sparse-view computed tomography (CT) -- using a small number of projections for tomographic reconstruction -- enables much lower radiation dose to patients and accelerated data acquisition. The reconstructed images, however, suffer from strong artifacts, greatly limiting their diagnostic value. Current trends for sparse-view CT turn to the raw data for better information recovery. The resultant dual-domain methods, nonetheless, suffer from secondary artifacts, especially in ultra-sparse view scenarios, and their generalization to other scanners/protocols is greatly limited. A crucial question arises: have the image post-processing methods reached the limit? Our answer is not yet. In this paper, we stick to image post-processing methods due to great flexibility and propose global representation (GloRe) distillation framework for sparse-view CT, termed GloReDi. First, we propose to learn GloRe with Fourier convolution, so each element in GloRe has an image-wide receptive field. Second, unlike methods that only use the full-view images for supervision, we propose to distill GloRe from intermediate-view reconstructed images that are readily available but not explored in previous literature. The success of GloRe distillation is attributed to two key components: representation directional distillation to align the GloRe directions, and band-pass-specific contrastive distillation to gain clinically important details. Extensive experiments demonstrate the superiority of the proposed GloReDi over the state-of-the-art methods, including dual-domain ones. The source code is available at https://github.com/longzilicart/GloReDi.
Controllable Multi-domain Semantic Artwork Synthesis
Aug 19, 2023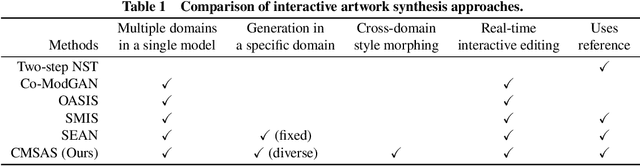
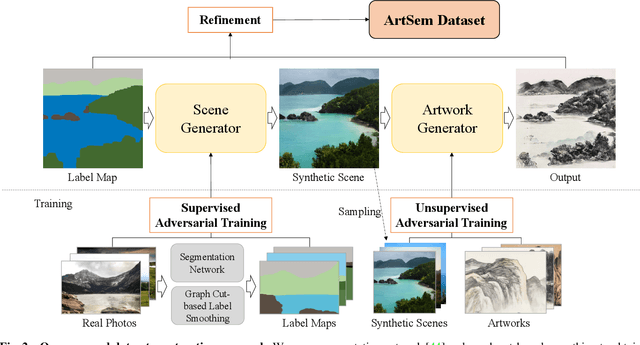
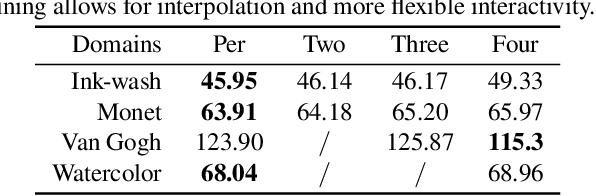

We present a novel framework for multi-domain synthesis of artwork from semantic layouts. One of the main limitations of this challenging task is the lack of publicly available segmentation datasets for art synthesis. To address this problem, we propose a dataset, which we call ArtSem, that contains 40,000 images of artwork from 4 different domains with their corresponding semantic label maps. We generate the dataset by first extracting semantic maps from landscape photography and then propose a conditional Generative Adversarial Network (GAN)-based approach to generate high-quality artwork from the semantic maps without necessitating paired training data. Furthermore, we propose an artwork synthesis model that uses domain-dependent variational encoders for high-quality multi-domain synthesis. The model is improved and complemented with a simple but effective normalization method, based on normalizing both the semantic and style jointly, which we call Spatially STyle-Adaptive Normalization (SSTAN). In contrast to previous methods that only take semantic layout as input, our model is able to learn a joint representation of both style and semantic information, which leads to better generation quality for synthesizing artistic images. Results indicate that our model learns to separate the domains in the latent space, and thus, by identifying the hyperplanes that separate the different domains, we can also perform fine-grained control of the synthesized artwork. By combining our proposed dataset and approach, we are able to generate user-controllable artwork that is of higher quality than existing
Augmented Negative Sampling for Collaborative Filtering
Aug 11, 2023
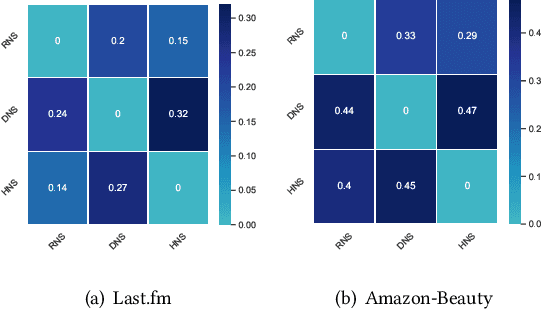
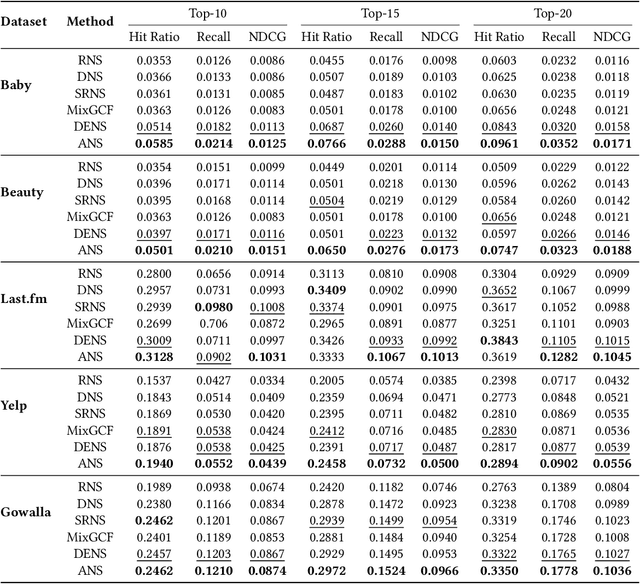
Negative sampling is essential for implicit-feedback-based collaborative filtering, which is used to constitute negative signals from massive unlabeled data to guide supervised learning. The state-of-the-art idea is to utilize hard negative samples that carry more useful information to form a better decision boundary. To balance efficiency and effectiveness, the vast majority of existing methods follow the two-pass approach, in which the first pass samples a fixed number of unobserved items by a simple static distribution and then the second pass selects the final negative items using a more sophisticated negative sampling strategy. However, selecting negative samples from the original items is inherently restricted, and thus may not be able to contrast positive samples well. In this paper, we confirm this observation via experiments and introduce two limitations of existing solutions: ambiguous trap and information discrimination. Our response to such limitations is to introduce augmented negative samples. This direction renders a substantial technical challenge because constructing unconstrained negative samples may introduce excessive noise that distorts the decision boundary. To this end, we introduce a novel generic augmented negative sampling paradigm and provide a concrete instantiation. First, we disentangle hard and easy factors of negative items. Next, we generate new candidate negative samples by augmenting only the easy factors in a regulated manner: the direction and magnitude of the augmentation are carefully calibrated. Finally, we design an advanced negative sampling strategy to identify the final augmented negative samples, which considers not only the score function used in existing methods but also a new metric called augmentation gain. Extensive experiments on real-world datasets demonstrate that our method significantly outperforms state-of-the-art baselines.
Minimizing Return Gaps with Discrete Communications in Decentralized POMDP
Aug 07, 2023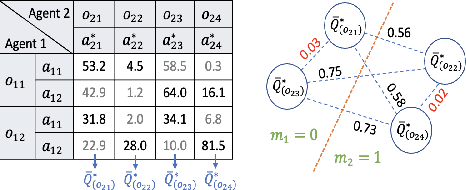
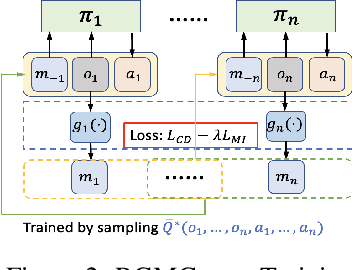
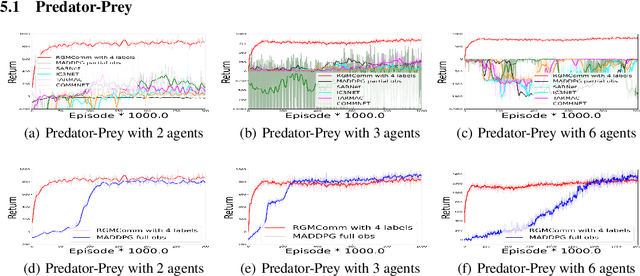
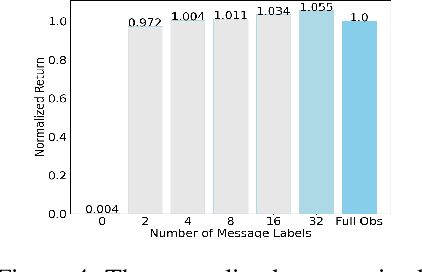
Communication is crucial for solving cooperative Multi-Agent Reinforcement Learning tasks in Partially-Observable Markov Decision Processes. Existing works often rely on black-box methods to encode local information/features into messages shared with other agents. However, such black-box approaches are unable to provide any quantitative guarantees on the expected return and often lead to the generation of continuous messages with high communication overhead and poor interpretability. In this paper, we establish an upper bound on the return gap between an ideal policy with full observability and an optimal partially-observable policy with discrete communication. This result enables us to recast multi-agent communication into a novel online clustering problem over the local observations at each agent, with messages as cluster labels and the upper bound on the return gap as clustering loss. By minimizing the upper bound, we propose a surprisingly simple design of message generation functions in multi-agent communication and integrate it with reinforcement learning using a Regularized Information Maximization loss function. Evaluations show that the proposed discrete communication significantly outperforms state-of-the-art multi-agent communication baselines and can achieve nearly-optimal returns with few-bit messages that are naturally interpretable.
Joint Precoding and Fronthaul Compression for Cell-Free MIMO Downlink With Radio Stripes
Aug 07, 2023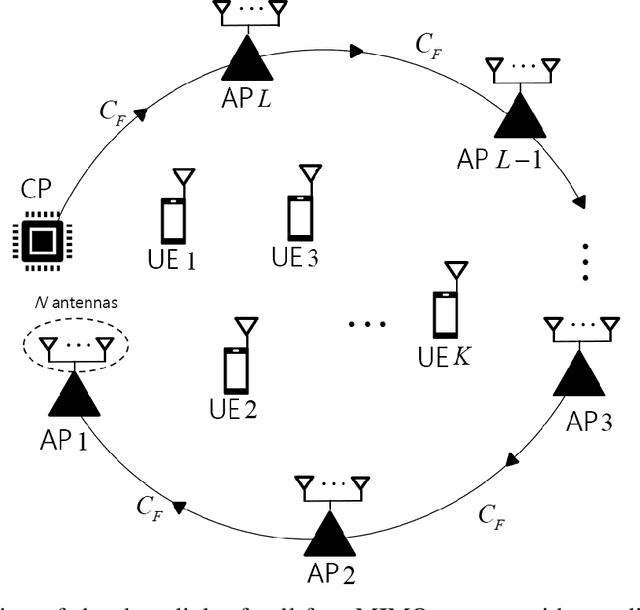
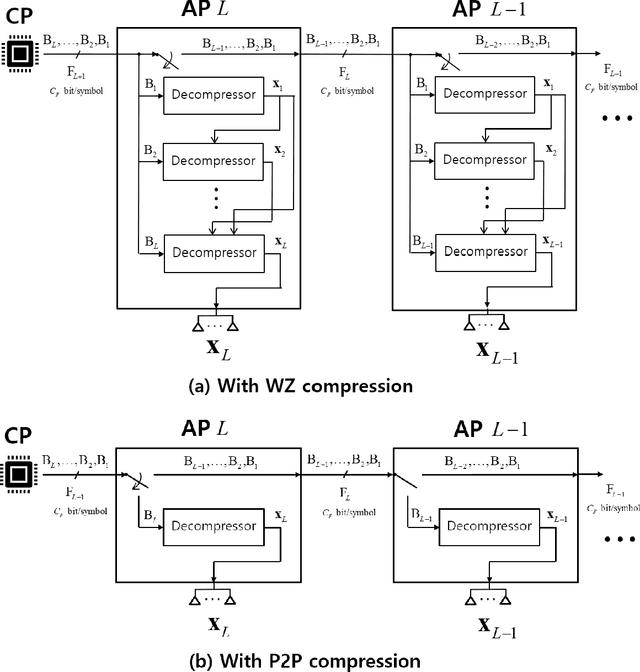
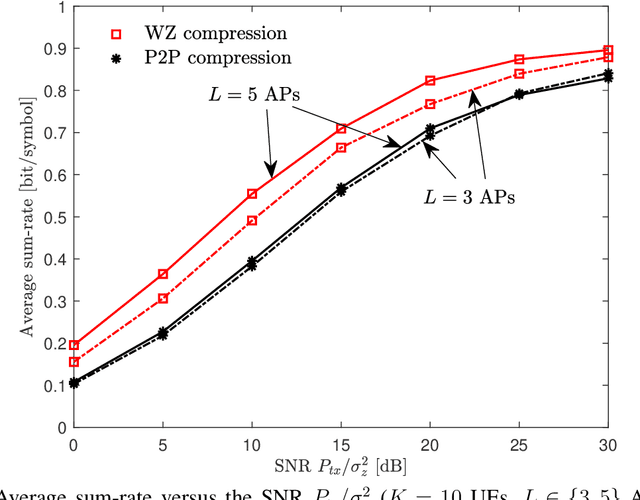
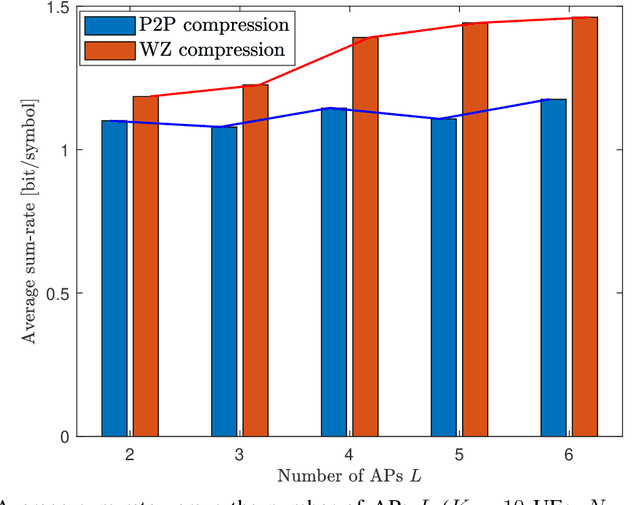
A sequential fronthaul network, referred to as radio stripes, is a promising fronthaul topology of cell-free MIMO systems. In this setup, a single cable suffices to connect access points (APs) to a central processor (CP). Thus, radio stripes are more effective than conventional star fronthaul topology which requires dedicated cables for each of APs. Most of works on radio stripes focused on the uplink communication or downlink energy transfer. This work tackles the design of the downlink data transmission for the first time. The CP sends compressed information of linearly precoded signals to the APs on fronthaul. Due to the serial transfer on radio stripes, each AP has an access to all the compressed blocks which pass through it. Thus, an advanced compression technique, called Wyner-Ziv (WZ) compression, can be applied in which each AP decompresses all the received blocks to exploit them for the reconstruction of its desired precoded signal as side information. The problem of maximizing the sum-rate is tackled under the standard point-to-point (P2P) and WZ compression strategies. Numerical results validate the performance gains of the proposed scheme.
TMI! Finetuned Models Leak Private Information from their Pretraining Data
Jun 01, 2023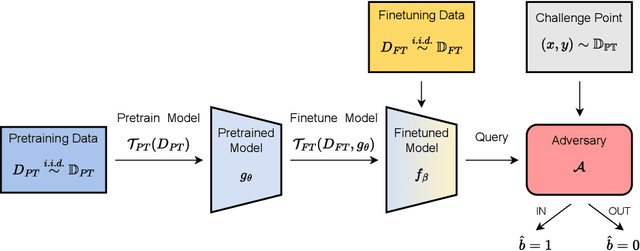
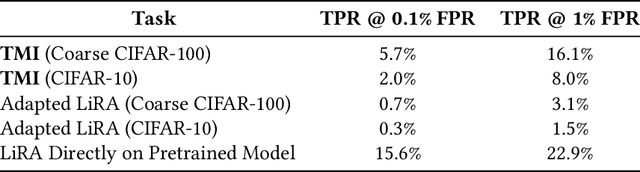
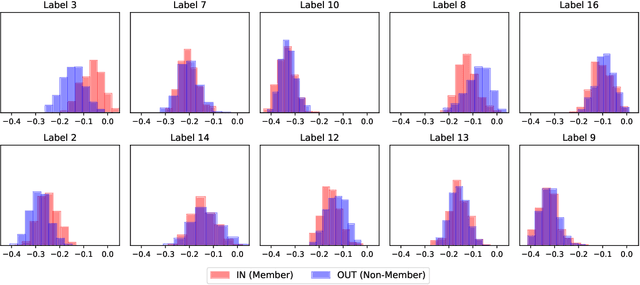
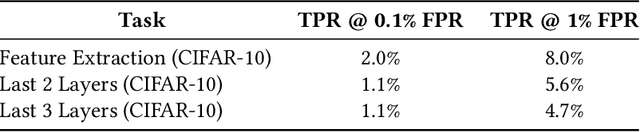
Transfer learning has become an increasingly popular technique in machine learning as a way to leverage a pretrained model trained for one task to assist with building a finetuned model for a related task. This paradigm has been especially popular for privacy in machine learning, where the pretrained model is considered public, and only the data for finetuning is considered sensitive. However, there are reasons to believe that the data used for pretraining is still sensitive, making it essential to understand how much information the finetuned model leaks about the pretraining data. In this work we propose a new membership-inference threat model where the adversary only has access to the finetuned model and would like to infer the membership of the pretraining data. To realize this threat model, we implement a novel metaclassifier-based attack, TMI, that leverages the influence of memorized pretraining samples on predictions in the downstream task. We evaluate TMI on both vision and natural language tasks across multiple transfer learning settings, including finetuning with differential privacy. Through our evaluation, we find that TMI can successfully infer membership of pretraining examples using query access to the finetuned model.
BlindSage: Label Inference Attacks against Node-level Vertical Federated Graph Neural Networks
Aug 04, 2023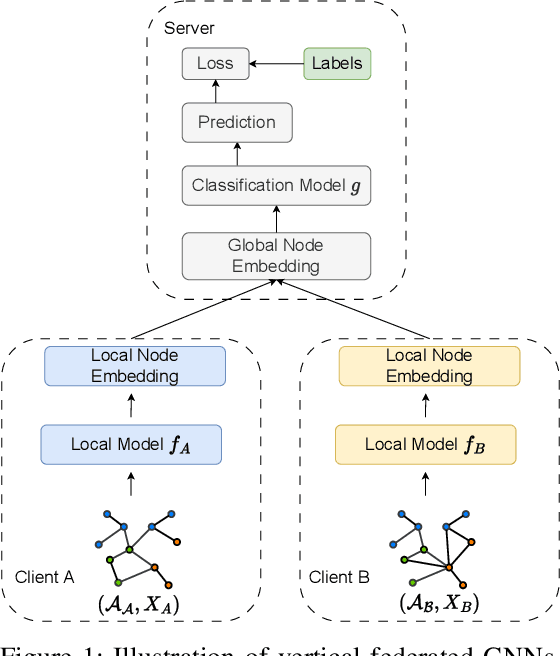
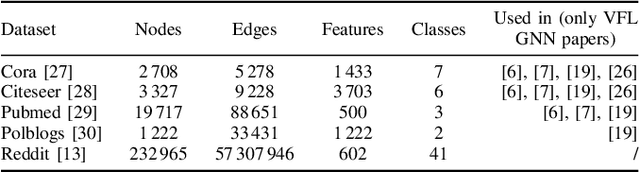
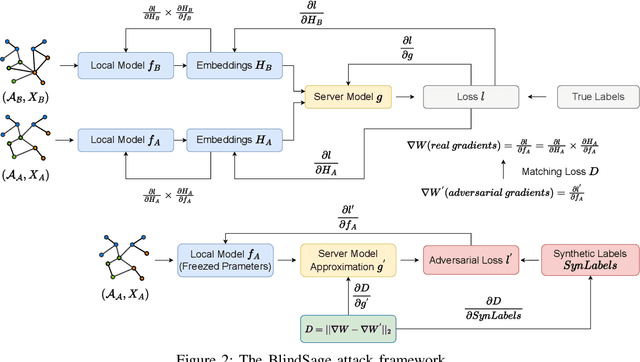
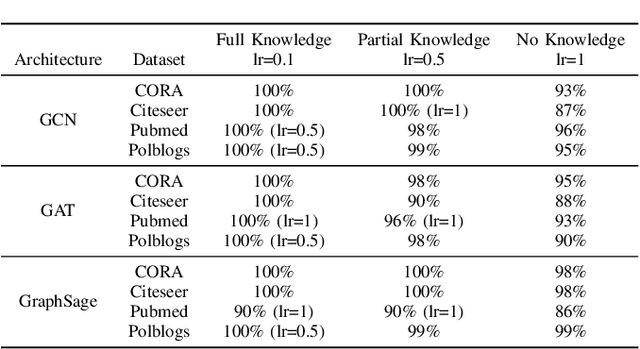
Federated learning enables collaborative training of machine learning models by keeping the raw data of the involved workers private. One of its main objectives is to improve the models' privacy, security, and scalability. Vertical Federated Learning (VFL) offers an efficient cross-silo setting where a few parties collaboratively train a model without sharing the same features. In such a scenario, classification labels are commonly considered sensitive information held exclusively by one (active) party, while other (passive) parties use only their local information. Recent works have uncovered important flaws of VFL, leading to possible label inference attacks under the assumption that the attacker has some, even limited, background knowledge on the relation between labels and data. In this work, we are the first (to the best of our knowledge) to investigate label inference attacks on VFL using a zero-background knowledge strategy. To concretely formulate our proposal, we focus on Graph Neural Networks (GNNs) as a target model for the underlying VFL. In particular, we refer to node classification tasks, which are widely studied, and GNNs have shown promising results. Our proposed attack, BlindSage, provides impressive results in the experiments, achieving nearly 100% accuracy in most cases. Even when the attacker has no information about the used architecture or the number of classes, the accuracy remained above 85% in most instances. Finally, we observe that well-known defenses cannot mitigate our attack without affecting the model's performance on the main classification task.
StyleEDL: Style-Guided High-order Attention Network for Image Emotion Distribution Learning
Aug 06, 2023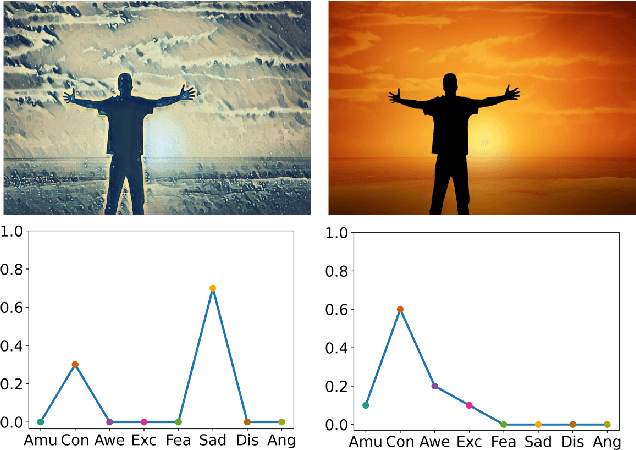
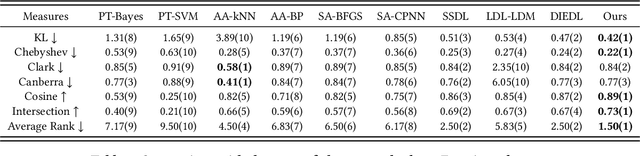
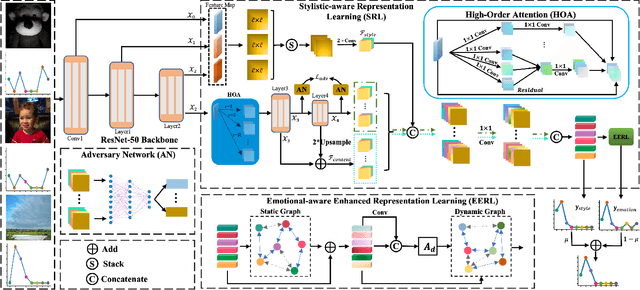
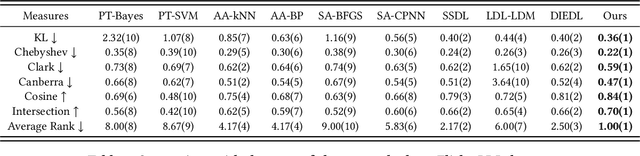
Emotion distribution learning has gained increasing attention with the tendency to express emotions through images. As for emotion ambiguity arising from humans' subjectivity, substantial previous methods generally focused on learning appropriate representations from the holistic or significant part of images. However, they rarely consider establishing connections with the stylistic information although it can lead to a better understanding of images. In this paper, we propose a style-guided high-order attention network for image emotion distribution learning termed StyleEDL, which interactively learns stylistic-aware representations of images by exploring the hierarchical stylistic information of visual contents. Specifically, we consider exploring the intra- and inter-layer correlations among GRAM-based stylistic representations, and meanwhile exploit an adversary-constrained high-order attention mechanism to capture potential interactions between subtle visual parts. In addition, we introduce a stylistic graph convolutional network to dynamically generate the content-dependent emotion representations to benefit the final emotion distribution learning. Extensive experiments conducted on several benchmark datasets demonstrate the effectiveness of our proposed StyleEDL compared to state-of-the-art methods. The implementation is released at: https://github.com/liuxianyi/StyleEDL.