 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Pro-Cap: Leveraging a Frozen Vision-Language Model for Hateful Meme Detection
Aug 16, 2023
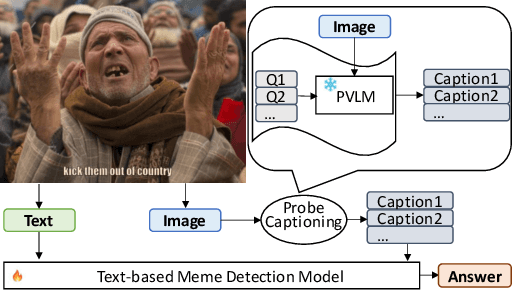
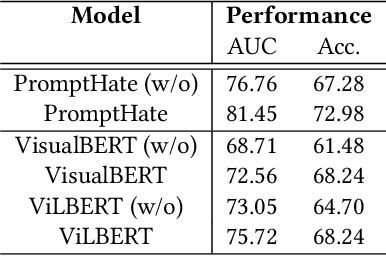

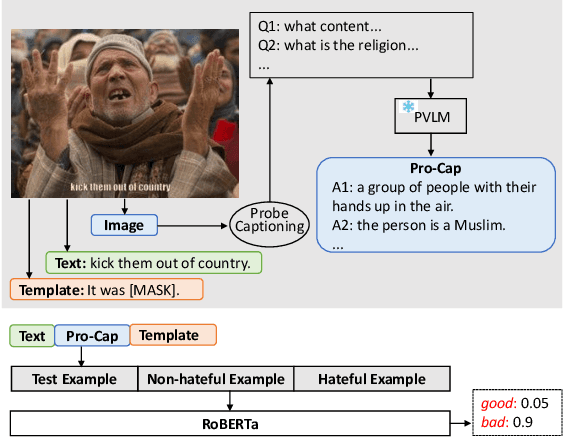
Hateful meme detection is a challenging multimodal task that requires comprehension of both vision and language, as well as cross-modal interactions. Recent studies have tried to fine-tune pre-trained vision-language models (PVLMs) for this task. However, with increasing model sizes, it becomes important to leverage powerful PVLMs more efficiently, rather than simply fine-tuning them. Recently, researchers have attempted to convert meme images into textual captions and prompt language models for predictions. This approach has shown good performance but suffers from non-informative image captions. Considering the two factors mentioned above, we propose a probing-based captioning approach to leverage PVLMs in a zero-shot visual question answering (VQA) manner. Specifically, we prompt a frozen PVLM by asking hateful content-related questions and use the answers as image captions (which we call Pro-Cap), so that the captions contain information critical for hateful content detection. The good performance of models with Pro-Cap on three benchmarks validates the effectiveness and generalization of the proposed method.
Towards Zero Memory Footprint Spiking Neural Network Training
Aug 16, 2023Biologically-inspired Spiking Neural Networks (SNNs), processing information using discrete-time events known as spikes rather than continuous values, have garnered significant attention due to their hardware-friendly and energy-efficient characteristics. However, the training of SNNs necessitates a considerably large memory footprint, given the additional storage requirements for spikes or events, leading to a complex structure and dynamic setup. In this paper, to address memory constraint in SNN training, we introduce an innovative framework, characterized by a remarkably low memory footprint. We \textbf{(i)} design a reversible SNN node that retains a high level of accuracy. Our design is able to achieve a $\mathbf{58.65\times}$ reduction in memory usage compared to the current SNN node. We \textbf{(ii)} propose a unique algorithm to streamline the backpropagation process of our reversible SNN node. This significantly trims the backward Floating Point Operations Per Second (FLOPs), thereby accelerating the training process in comparison to current reversible layer backpropagation method. By using our algorithm, the training time is able to be curtailed by $\mathbf{23.8\%}$ relative to existing reversible layer architectures.
Preserving Specificity in Federated Graph Learning for fMRI-based Neurological Disorder Identification
Aug 20, 2023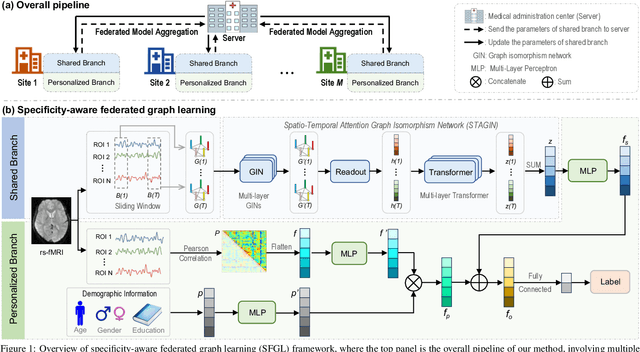
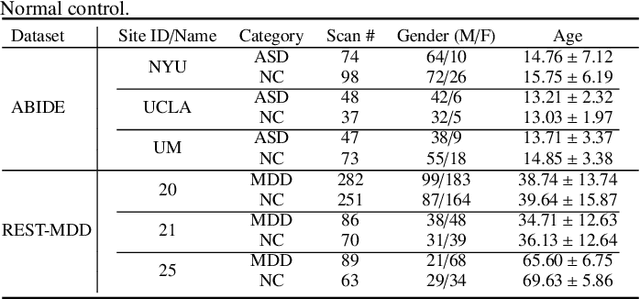
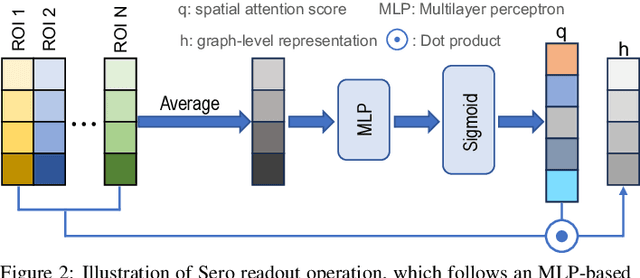

Resting-state functional magnetic resonance imaging (rs-fMRI) offers a non-invasive approach to examining abnormal brain connectivity associated with brain disorders. Graph neural network (GNN) gains popularity in fMRI representation learning and brain disorder analysis with powerful graph representation capabilities. Training a general GNN often necessitates a large-scale dataset from multiple imaging centers/sites, but centralizing multi-site data generally faces inherent challenges related to data privacy, security, and storage burden. Federated Learning (FL) enables collaborative model training without centralized multi-site fMRI data. Unfortunately, previous FL approaches for fMRI analysis often ignore site-specificity, including demographic factors such as age, gender, and education level. To this end, we propose a specificity-aware federated graph learning (SFGL) framework for rs-fMRI analysis and automated brain disorder identification, with a server and multiple clients/sites for federated model aggregation and prediction. At each client, our model consists of a shared and a personalized branch, where parameters of the shared branch are sent to the server while those of the personalized branch remain local. This can facilitate knowledge sharing among sites and also helps preserve site specificity. In the shared branch, we employ a spatio-temporal attention graph isomorphism network to learn dynamic fMRI representations. In the personalized branch, we integrate vectorized demographic information (i.e., age, gender, and education years) and functional connectivity networks to preserve site-specific characteristics. Representations generated by the two branches are then fused for classification. Experimental results on two fMRI datasets with a total of 1,218 subjects suggest that SFGL outperforms several state-of-the-art approaches.
Unsupervised Scientific Abstract Segmentation with Normalized Mutual Information
May 19, 2023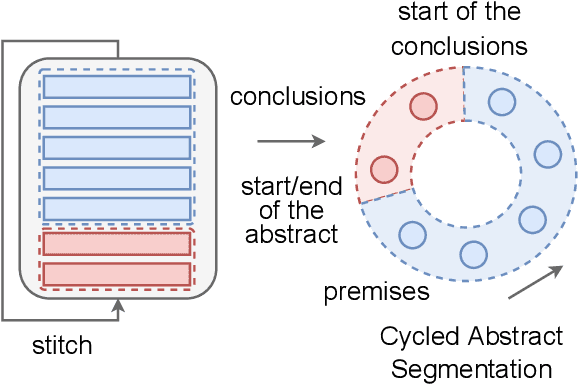
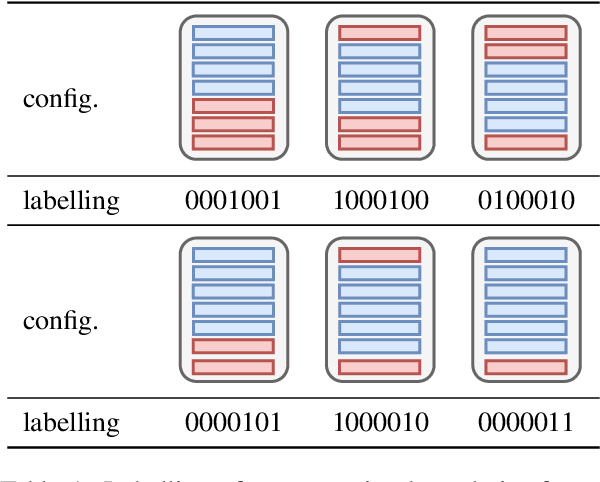
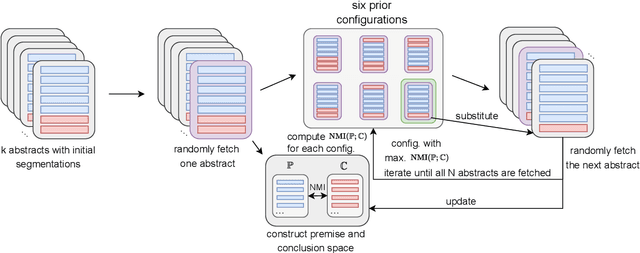
The abstracts of scientific papers consist of premises and conclusions. Structured abstracts explicitly highlight the conclusion sentences, whereas non-structured abstracts may have conclusion sentences at uncertain positions. This implicit nature of conclusion positions makes the automatic segmentation of scientific abstracts into premises and conclusions a challenging task. In this work, we empirically explore using Normalized Mutual Information (NMI) for abstract segmentation. We consider each abstract as a recurrent cycle of sentences and place segmentation boundaries by greedily optimizing the NMI score between premises and conclusions. On non-structured abstracts, our proposed unsupervised approach GreedyCAS achieves the best performance across all evaluation metrics; on structured abstracts, GreedyCAS outperforms all baseline methods measured by $P_k$. The strong correlation of NMI to our evaluation metrics reveals the effectiveness of NMI for abstract segmentation.
Hierarchical State Abstraction Based on Structural Information Principles
Apr 24, 2023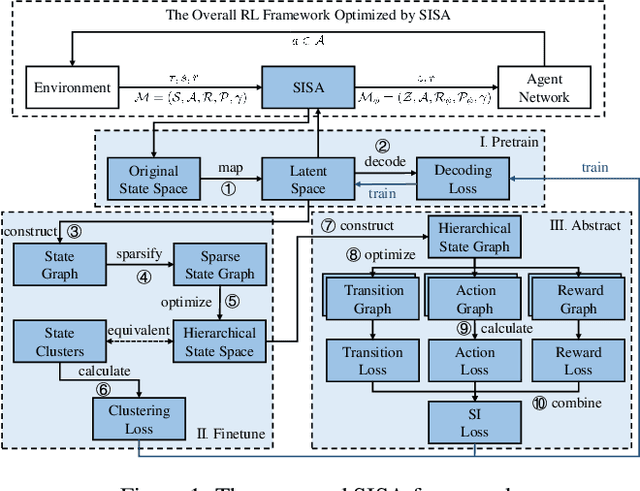

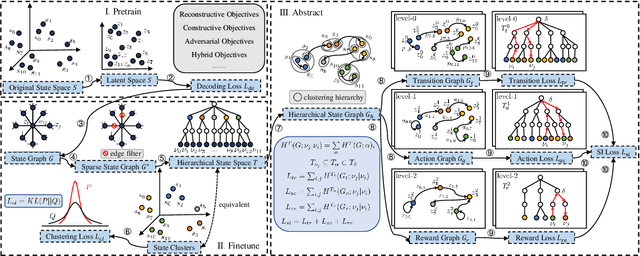
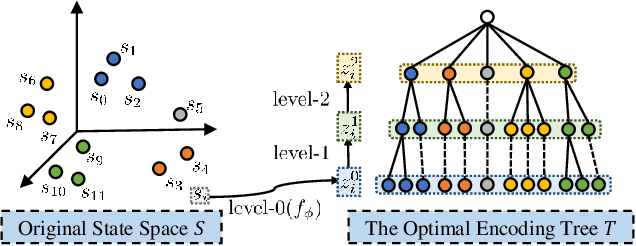
State abstraction optimizes decision-making by ignoring irrelevant environmental information in reinforcement learning with rich observations. Nevertheless, recent approaches focus on adequate representational capacities resulting in essential information loss, affecting their performances on challenging tasks. In this article, we propose a novel mathematical Structural Information principles-based State Abstraction framework, namely SISA, from the information-theoretic perspective. Specifically, an unsupervised, adaptive hierarchical state clustering method without requiring manual assistance is presented, and meanwhile, an optimal encoding tree is generated. On each non-root tree node, a new aggregation function and condition structural entropy are designed to achieve hierarchical state abstraction and compensate for sampling-induced essential information loss in state abstraction. Empirical evaluations on a visual gridworld domain and six continuous control benchmarks demonstrate that, compared with five SOTA state abstraction approaches, SISA significantly improves mean episode reward and sample efficiency up to 18.98 and 44.44%, respectively. Besides, we experimentally show that SISA is a general framework that can be flexibly integrated with different representation-learning objectives to improve their performances further.
Multi-modal Graph Neural Network for Early Diagnosis of Alzheimer's Disease from sMRI and PET Scans
Jul 31, 2023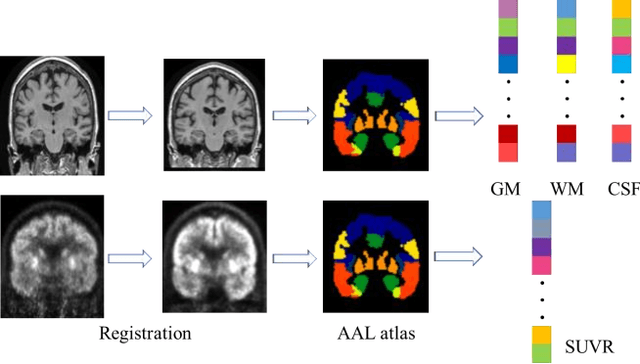
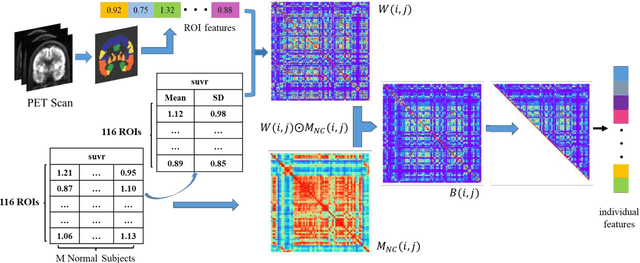
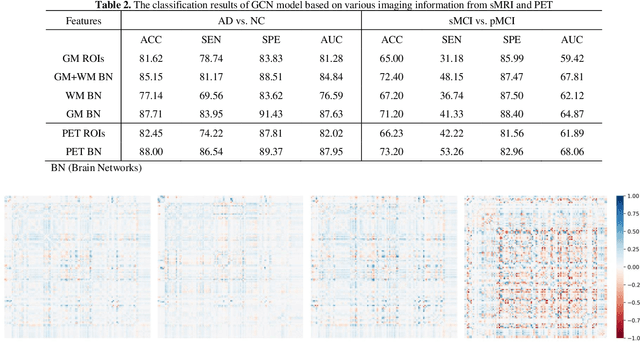
In recent years, deep learning models have been applied to neuroimaging data for early diagnosis of Alzheimer's disease (AD). Structural magnetic resonance imaging (sMRI) and positron emission tomography (PET) images provide structural and functional information about the brain, respectively. Combining these features leads to improved performance than using a single modality alone in building predictive models for AD diagnosis. However, current multi-modal approaches in deep learning, based on sMRI and PET, are mostly limited to convolutional neural networks, which do not facilitate integration of both image and phenotypic information of subjects. We propose to use graph neural networks (GNN) that are designed to deal with problems in non-Euclidean domains. In this study, we demonstrate how brain networks can be created from sMRI or PET images and be used in a population graph framework that can combine phenotypic information with imaging features of these brain networks. Then, we present a multi-modal GNN framework where each modality has its own branch of GNN and a technique is proposed to combine the multi-modal data at both the level of node vectors and adjacency matrices. Finally, we perform late fusion to combine the preliminary decisions made in each branch and produce a final prediction. As multi-modality data becomes available, multi-source and multi-modal is the trend of AD diagnosis. We conducted explorative experiments based on multi-modal imaging data combined with non-imaging phenotypic information for AD diagnosis and analyzed the impact of phenotypic information on diagnostic performance. Results from experiments demonstrated that our proposed multi-modal approach improves performance for AD diagnosis, and this study also provides technical reference and support the need for multivariate multi-modal diagnosis methods.
Self-Contrastive Graph Diffusion Network
Jul 27, 2023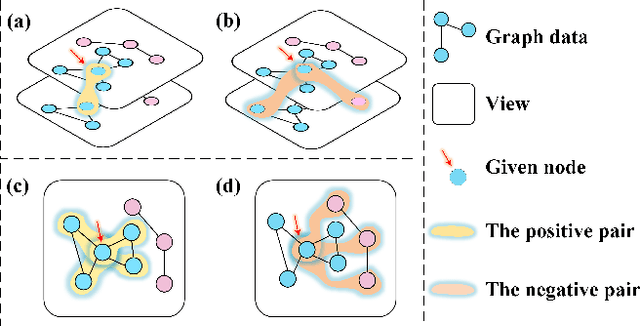
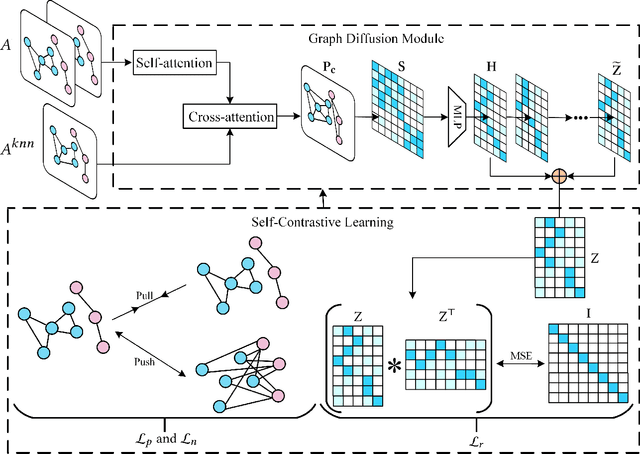
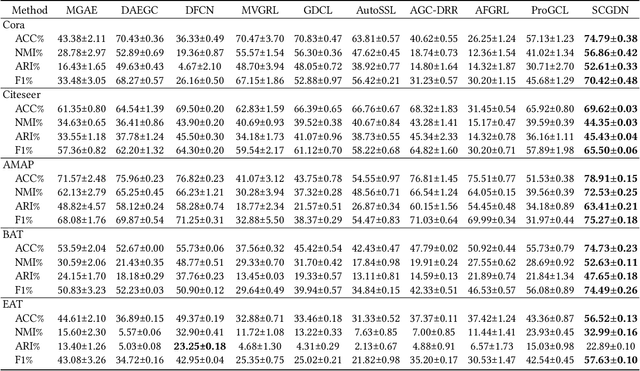
Augmentation techniques and sampling strategies are crucial in contrastive learning, but in most existing works, augmentation techniques require careful design, and their sampling strategies can only capture a small amount of intrinsic supervision information. Additionally, the existing methods require complex designs to obtain two different representations of the data. To overcome these limitations, we propose a novel framework called the Self-Contrastive Graph Diffusion Network (SCGDN). Our framework consists of two main components: the Attentional Module (AttM) and the Diffusion Module (DiFM). AttM aggregates higher-order structure and feature information to get an excellent embedding, while DiFM balances the state of each node in the graph through Laplacian diffusion learning and allows the cooperative evolution of adjacency and feature information in the graph. Unlike existing methodologies, SCGDN is an augmentation-free approach that avoids "sampling bias" and semantic drift, without the need for pre-training. We conduct a high-quality sampling of samples based on structure and feature information. If two nodes are neighbors, they are considered positive samples of each other. If two disconnected nodes are also unrelated on $k$NN graph, they are considered negative samples for each other. The contrastive objective reasonably uses our proposed sampling strategies, and the redundancy reduction term minimizes redundant information in the embedding and can well retain more discriminative information. In this novel framework, the graph self-contrastive learning paradigm gives expression to a powerful force. SCGDN effectively balances between preserving high-order structure information and avoiding overfitting. The results manifest that SCGDN can consistently generate outperformance over both the contrastive methods and the classical methods.
* ACM Multimedia 2013 Accpeted
CMDA: Cross-Modality Domain Adaptation for Nighttime Semantic Segmentation
Jul 29, 2023
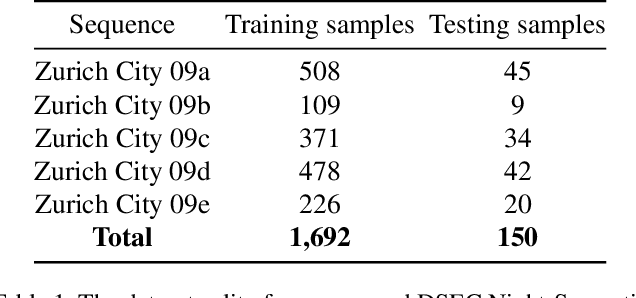
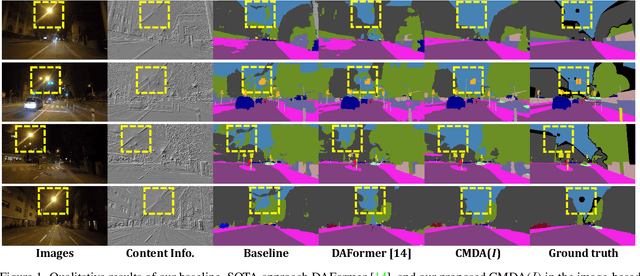
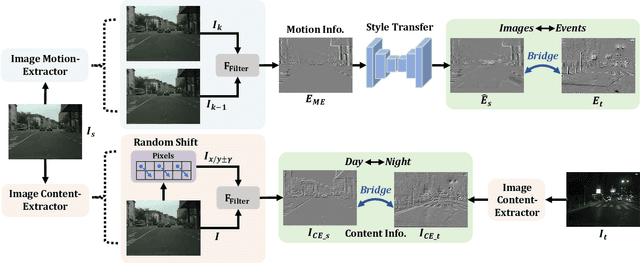
Most nighttime semantic segmentation studies are based on domain adaptation approaches and image input. However, limited by the low dynamic range of conventional cameras, images fail to capture structural details and boundary information in low-light conditions. Event cameras, as a new form of vision sensors, are complementary to conventional cameras with their high dynamic range. To this end, we propose a novel unsupervised Cross-Modality Domain Adaptation (CMDA) framework to leverage multi-modality (Images and Events) information for nighttime semantic segmentation, with only labels on daytime images. In CMDA, we design the Image Motion-Extractor to extract motion information and the Image Content-Extractor to extract content information from images, in order to bridge the gap between different modalities (Images to Events) and domains (Day to Night). Besides, we introduce the first image-event nighttime semantic segmentation dataset. Extensive experiments on both the public image dataset and the proposed image-event dataset demonstrate the effectiveness of our proposed approach. We open-source our code, models, and dataset at https://github.com/XiaRho/CMDA.
The detection and rectification for identity-switch based on unfalsified control
Jul 27, 2023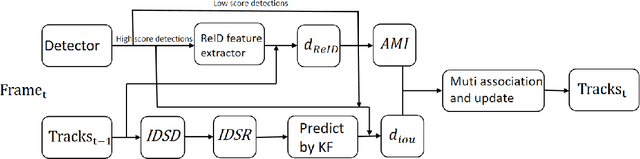
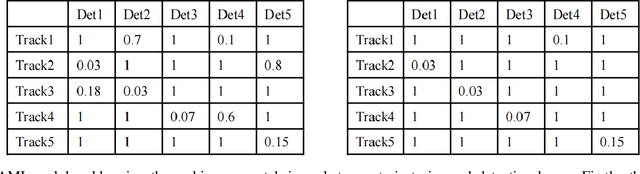
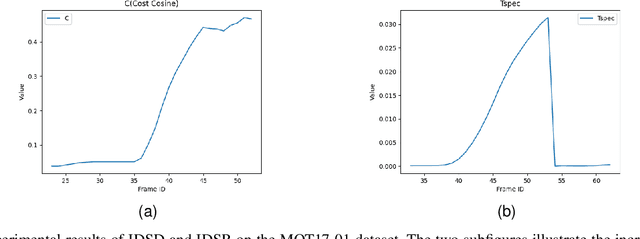

The purpose of multi-object tracking (MOT) is to continuously track and identify objects detected in videos. Currently, most methods for multi-object tracking model the motion information and combine it with appearance information to determine and track objects. In this paper, unfalsified control is employed to address the ID-switch problem in multi-object tracking. We establish sequences of appearance information variations for the trajectories during the tracking process and design a detection and rectification module specifically for ID-switch detection and recovery. We also propose a simple and effective strategy to address the issue of ambiguous matching of appearance information during the data association process. Experimental results on publicly available MOT datasets demonstrate that the tracker exhibits excellent effectiveness and robustness in handling tracking errors caused by occlusions and rapid movements.
LATR: 3D Lane Detection from Monocular Images with Transformer
Aug 08, 2023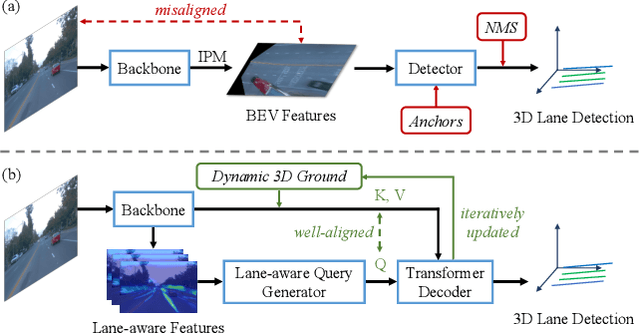
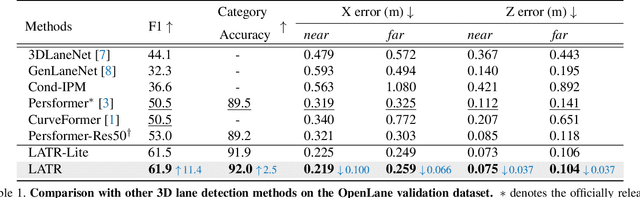
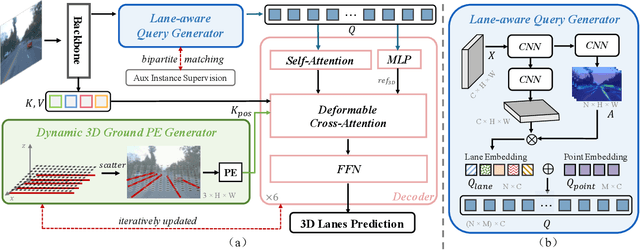
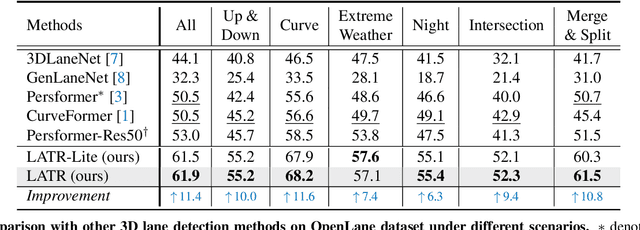
3D lane detection from monocular images is a fundamental yet challenging task in autonomous driving. Recent advances primarily rely on structural 3D surrogates (e.g., bird's eye view) that are built from front-view image features and camera parameters. However, the depth ambiguity in monocular images inevitably causes misalignment between the constructed surrogate feature map and the original image, posing a great challenge for accurate lane detection. To address the above issue, we present a novel LATR model, an end-to-end 3D lane detector that uses 3D-aware front-view features without transformed view representation. Specifically, LATR detects 3D lanes via cross-attention based on query and key-value pairs, constructed using our lane-aware query generator and dynamic 3D ground positional embedding. On the one hand, each query is generated based on 2D lane-aware features and adopts a hybrid embedding to enhance the lane information. On the other hand, 3D space information is injected as positional embedding from an iteratively-updated 3D ground plane. LATR outperforms previous state-of-the-art methods on both synthetic Apollo and realistic OpenLane by large margins (e.g., 11.4 gains in terms of F1 score on OpenLane). Code will be released at https://github.com/JMoonr/LATR.