 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GeoDTR+: Toward generic cross-view geolocalization via geometric disentanglement
Aug 18, 2023
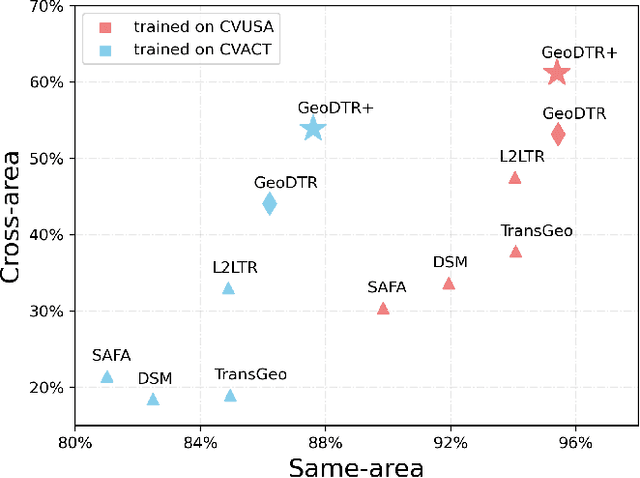
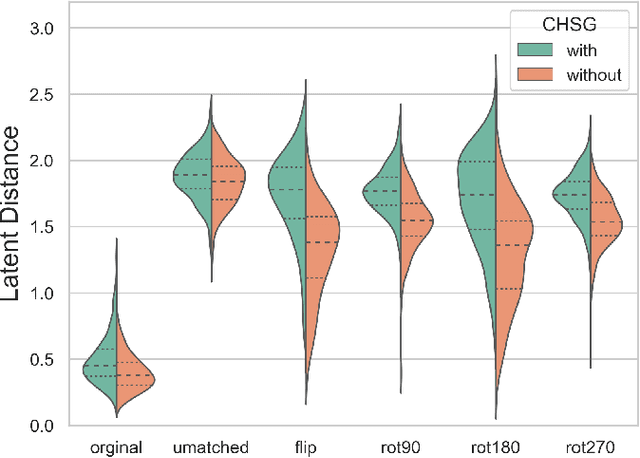
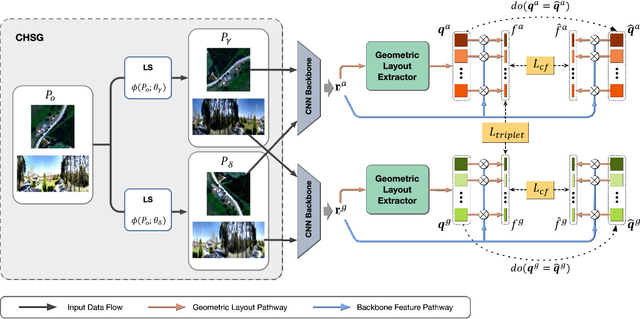
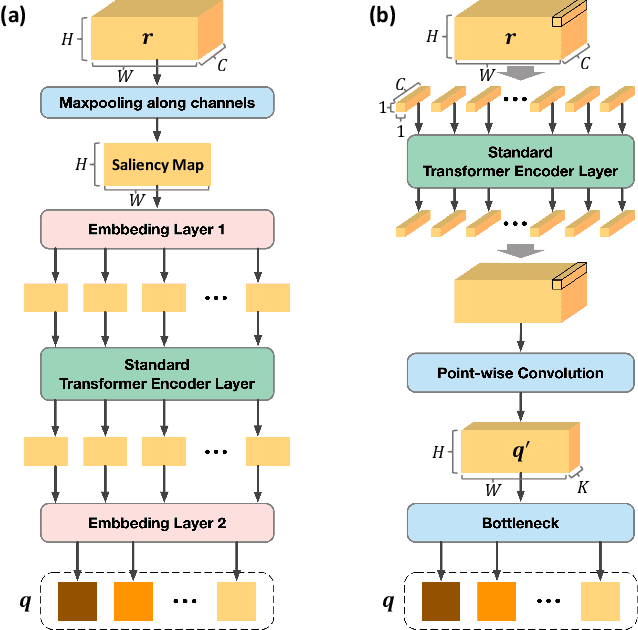
Cross-View Geo-Localization (CVGL) estimates the location of a ground image by matching it to a geo-tagged aerial image in a database. Recent works achieve outstanding progress on CVGL benchmarks. However, existing methods still suffer from poor performance in cross-area evaluation, in which the training and testing data are captured from completely distinct areas. We attribute this deficiency to the lack of ability to extract the geometric layout of visual features and models' overfitting to low-level details. Our preliminary work introduced a Geometric Layout Extractor (GLE) to capture the geometric layout from input features. However, the previous GLE does not fully exploit information in the input feature. In this work, we propose GeoDTR+ with an enhanced GLE module that better models the correlations among visual features. To fully explore the LS techniques from our preliminary work, we further propose Contrastive Hard Samples Generation (CHSG) to facilitate model training. Extensive experiments show that GeoDTR+ achieves state-of-the-art (SOTA) results in cross-area evaluation on CVUSA, CVACT, and VIGOR by a large margin ($16.44\%$, $22.71\%$, and $17.02\%$ without polar transformation) while keeping the same-area performance comparable to existing SOTA. Moreover, we provide detailed analyses of GeoDTR+.
ALIP: Adaptive Language-Image Pre-training with Synthetic Caption
Aug 18, 2023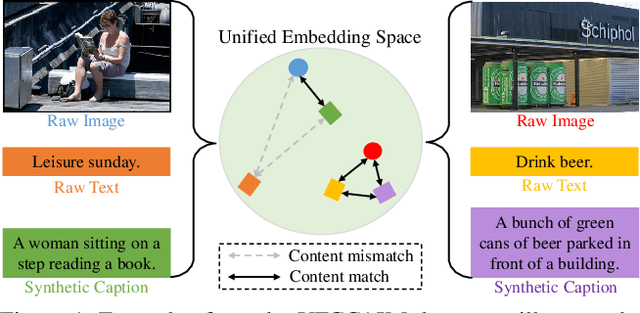
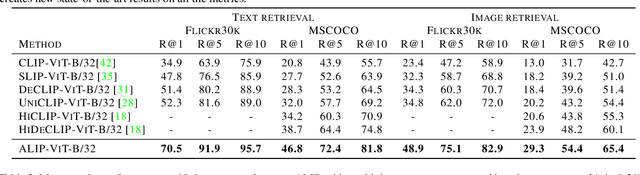
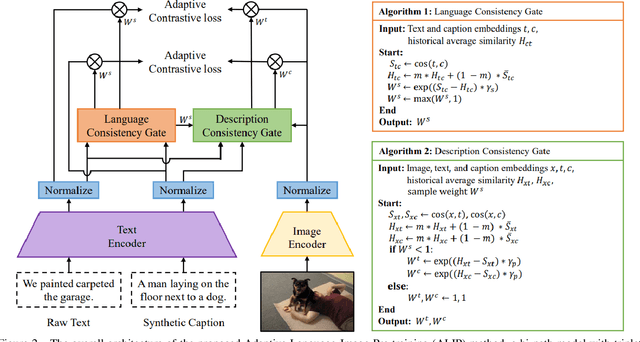
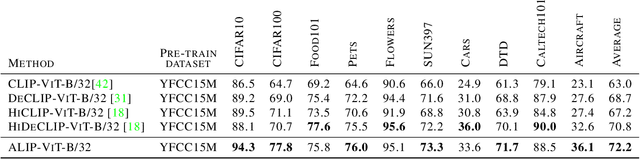
Contrastive Language-Image Pre-training (CLIP) has significantly boosted the performance of various vision-language tasks by scaling up the dataset with image-text pairs collected from the web. However, the presence of intrinsic noise and unmatched image-text pairs in web data can potentially affect the performance of representation learning. To address this issue, we first utilize the OFA model to generate synthetic captions that focus on the image content. The generated captions contain complementary information that is beneficial for pre-training. Then, we propose an Adaptive Language-Image Pre-training (ALIP), a bi-path model that integrates supervision from both raw text and synthetic caption. As the core components of ALIP, the Language Consistency Gate (LCG) and Description Consistency Gate (DCG) dynamically adjust the weights of samples and image-text/caption pairs during the training process. Meanwhile, the adaptive contrastive loss can effectively reduce the impact of noise data and enhances the efficiency of pre-training data. We validate ALIP with experiments on different scales of models and pre-training datasets. Experiments results show that ALIP achieves state-of-the-art performance on multiple downstream tasks including zero-shot image-text retrieval and linear probe. To facilitate future research, the code and pre-trained models are released at https://github.com/deepglint/ALIP.
Multi-scale Target-Aware Framework for Constrained Image Splicing Detection and Localization
Aug 18, 2023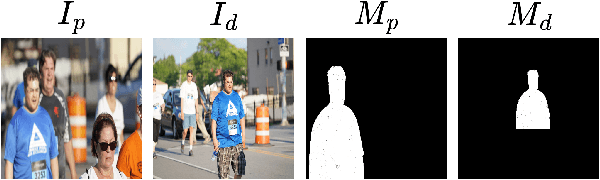
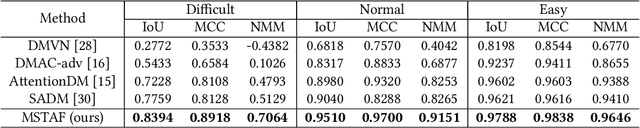
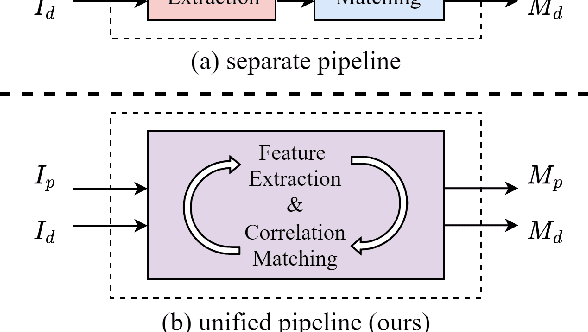
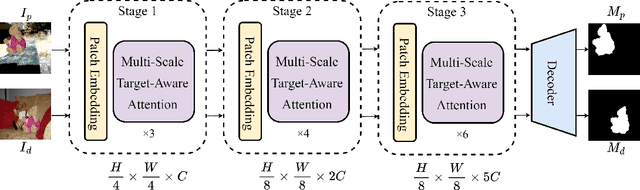
Constrained image splicing detection and localization (CISDL) is a fundamental task of multimedia forensics, which detects splicing operation between two suspected images and localizes the spliced region on both images. Recent works regard it as a deep matching problem and have made significant progress. However, existing frameworks typically perform feature extraction and correlation matching as separate processes, which may hinder the model's ability to learn discriminative features for matching and can be susceptible to interference from ambiguous background pixels. In this work, we propose a multi-scale target-aware framework to couple feature extraction and correlation matching in a unified pipeline. In contrast to previous methods, we design a target-aware attention mechanism that jointly learns features and performs correlation matching between the probe and donor images. Our approach can effectively promote the collaborative learning of related patches, and perform mutual promotion of feature learning and correlation matching. Additionally, in order to handle scale transformations, we introduce a multi-scale projection method, which can be readily integrated into our target-aware framework that enables the attention process to be conducted between tokens containing information of varying scales. Our experiments demonstrate that our model, which uses a unified pipeline, outperforms state-of-the-art methods on several benchmark datasets and is robust against scale transformations.
PUMGPT: A Large Vision-Language Model for Product Understanding
Aug 18, 2023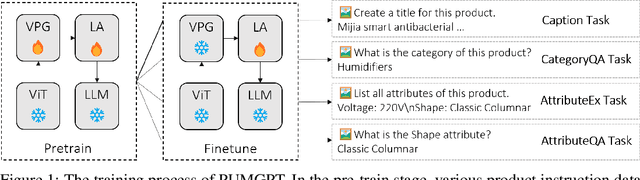
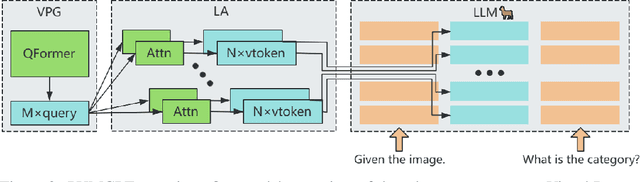


Recent developments of multi-modal large language models have demonstrated its strong ability in solving vision-language tasks. In this paper, we focus on the product understanding task, which plays an essential role in enhancing online shopping experience. Product understanding task includes a variety of sub-tasks, which require models to respond diverse queries based on multi-modal product information. Traditional methods design distinct model architectures for each sub-task. On the contrary, we present PUMGPT, a large vision-language model aims at unifying all product understanding tasks under a singular model structure. To bridge the gap between vision and text representations, we propose Layer-wise Adapters (LA), an approach that provides enhanced alignment with fewer visual tokens and enables parameter-efficient fine-tuning. Moreover, the inherent parameter-efficient fine-tuning ability allows PUMGPT to be readily adapted to new product understanding tasks and emerging products. We design instruction templates to generate diverse product instruction datasets. Simultaneously, we utilize open-domain datasets during training to improve the performance of PUMGPT and its generalization ability. Through extensive evaluations, PUMGPT demonstrates its superior performance across multiple product understanding tasks, including product captioning, category question-answering, attribute extraction, attribute question-answering, and even free-form question-answering about products.
Bridged-GNN: Knowledge Bridge Learning for Effective Knowledge Transfer
Aug 18, 2023The data-hungry problem, characterized by insufficiency and low-quality of data, poses obstacles for deep learning models. Transfer learning has been a feasible way to transfer knowledge from high-quality external data of source domains to limited data of target domains, which follows a domain-level knowledge transfer to learn a shared posterior distribution. However, they are usually built on strong assumptions, e.g., the domain invariant posterior distribution, which is usually unsatisfied and may introduce noises, resulting in poor generalization ability on target domains. Inspired by Graph Neural Networks (GNNs) that aggregate information from neighboring nodes, we redefine the paradigm as learning a knowledge-enhanced posterior distribution for target domains, namely Knowledge Bridge Learning (KBL). KBL first learns the scope of knowledge transfer by constructing a Bridged-Graph that connects knowledgeable samples to each target sample and then performs sample-wise knowledge transfer via GNNs.KBL is free from strong assumptions and is robust to noises in the source data. Guided by KBL, we propose the Bridged-GNN} including an Adaptive Knowledge Retrieval module to build Bridged-Graph and a Graph Knowledge Transfer module. Comprehensive experiments on both un-relational and relational data-hungry scenarios demonstrate the significant improvements of Bridged-GNN compared with SOTA methods
Physics-Informed Boundary Integral Networks (PIBI-Nets): A Data-Driven Approach for Solving Partial Differential Equations
Aug 18, 2023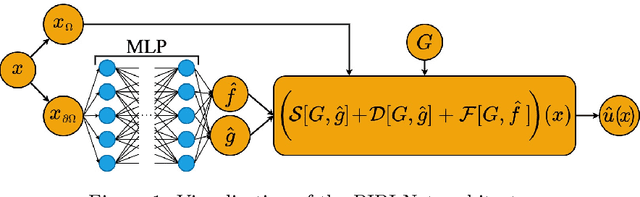
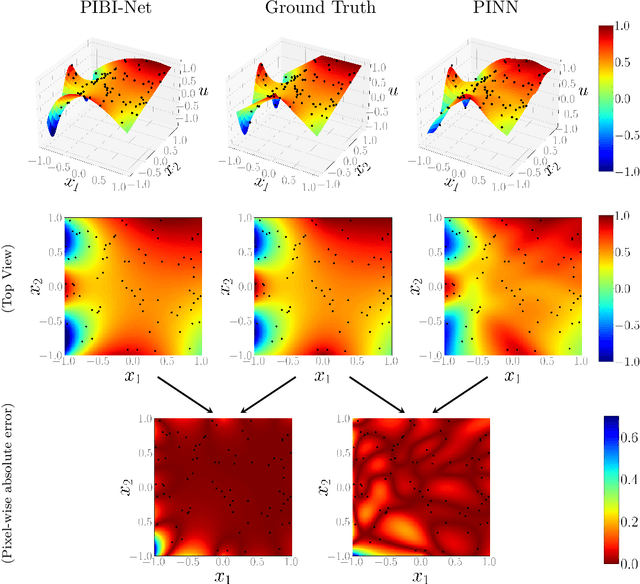
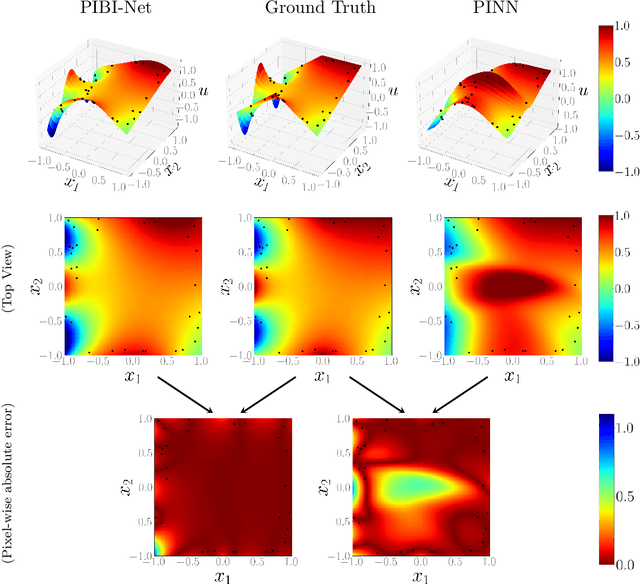
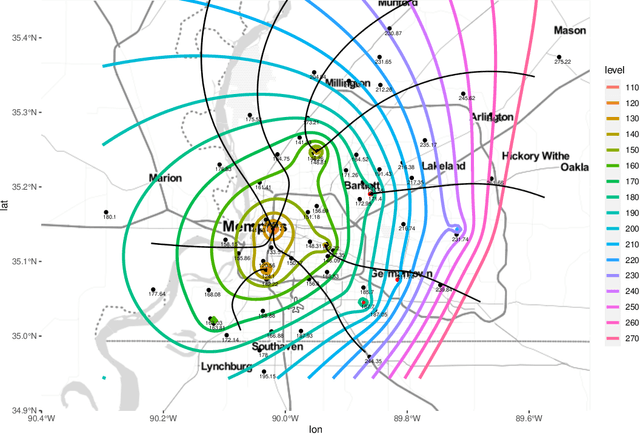
Partial differential equations (PDEs) can describe many relevant phenomena in dynamical systems. In real-world applications, we commonly need to combine formal PDE models with (potentially noisy) observations. This is especially relevant in settings where we lack information about boundary or initial conditions, or where we need to identify unknown model parameters. In recent years, Physics-informed neural networks (PINNs) have become a popular tool for problems of this kind. In high-dimensional settings, however, PINNs often suffer from computational problems because they usually require dense collocation points over the entire computational domain. To address this problem, we present Physics-Informed Boundary Integral Networks (PIBI-Nets) as a data-driven approach for solving PDEs in one dimension less than the original problem space. PIBI-Nets only need collocation points at the computational domain boundary, while still achieving highly accurate results, and in several practical settings, they clearly outperform PINNs. Exploiting elementary properties of fundamental solutions of linear differential operators, we present a principled and simple way to handle point sources in inverse problems. We demonstrate the excellent performance of PIBI-Nets for the Laplace and Poisson equations, both on artificial data sets and within a real-world application concerning the reconstruction of groundwater flows.
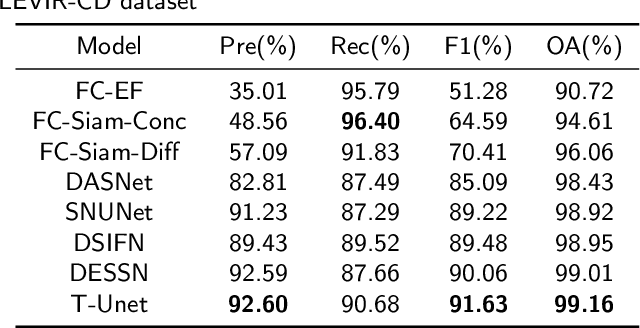
T-UNet: Triplet UNet for Change Detection in High-Resolution Remote Sensing Images
Aug 04, 2023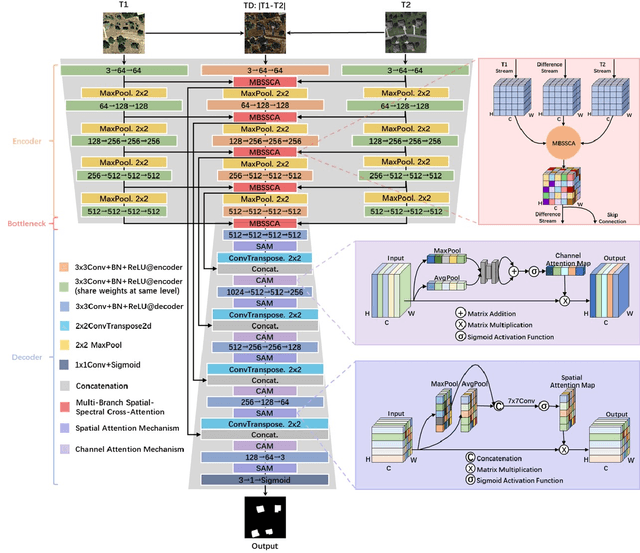
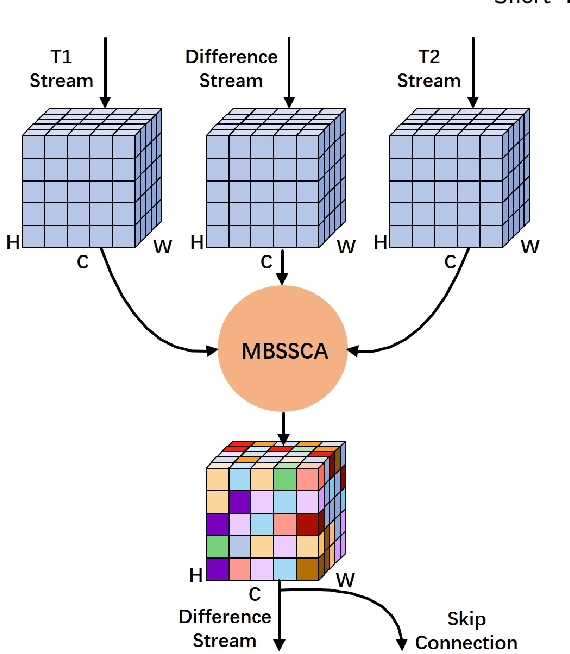
Remote sensing image change detection aims to identify the differences between images acquired at different times in the same area. It is widely used in land management, environmental monitoring, disaster assessment and other fields. Currently, most change detection methods are based on Siamese network structure or early fusion structure. Siamese structure focuses on extracting object features at different times but lacks attention to change information, which leads to false alarms and missed detections. Early fusion (EF) structure focuses on extracting features after the fusion of images of different phases but ignores the significance of object features at different times for detecting change details, making it difficult to accurately discern the edges of changed objects. To address these issues and obtain more accurate results, we propose a novel network, Triplet UNet(T-UNet), based on a three-branch encoder, which is capable to simultaneously extract the object features and the change features between the pre- and post-time-phase images through triplet encoder. To effectively interact and fuse the features extracted from the three branches of triplet encoder, we propose a multi-branch spatial-spectral cross-attention module (MBSSCA). In the decoder stage, we introduce the channel attention mechanism (CAM) and spatial attention mechanism (SAM) to fully mine and integrate detailed textures information at the shallow layer and semantic localization information at the deep layer.
Beyond First Impressions: Integrating Joint Multi-modal Cues for Comprehensive 3D Representation
Aug 06, 2023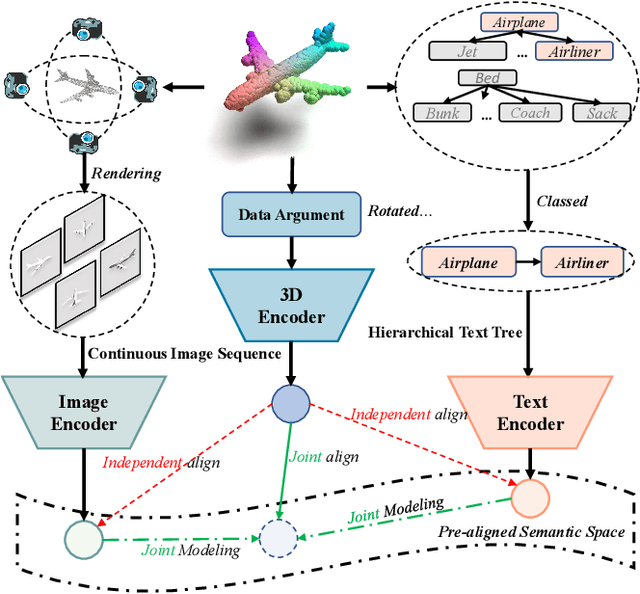
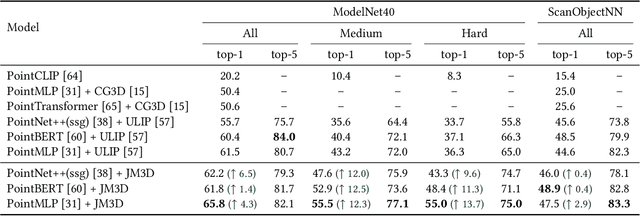
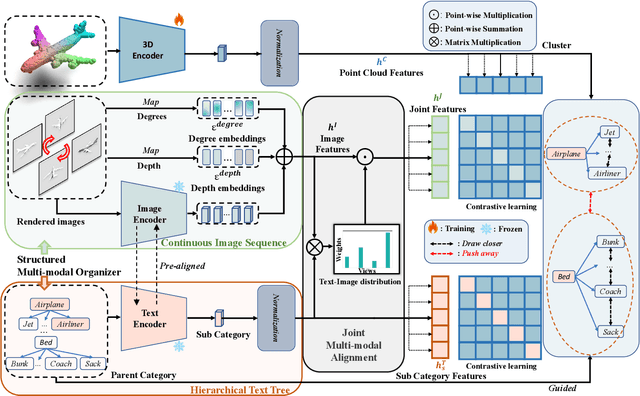
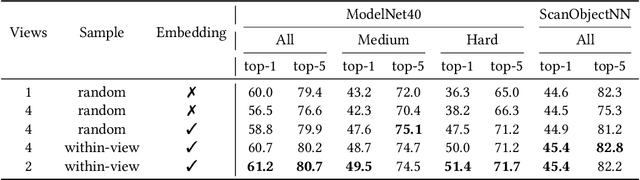
In recent years, 3D representation learning has turned to 2D vision-language pre-trained models to overcome data scarcity challenges. However, existing methods simply transfer 2D alignment strategies, aligning 3D representations with single-view 2D images and coarse-grained parent category text. These approaches introduce information degradation and insufficient synergy issues, leading to performance loss. Information degradation arises from overlooking the fact that a 3D representation should be equivalent to a series of multi-view images and more fine-grained subcategory text. Insufficient synergy neglects the idea that a robust 3D representation should align with the joint vision-language space, rather than independently aligning with each modality. In this paper, we propose a multi-view joint modality modeling approach, termed JM3D, to obtain a unified representation for point cloud, text, and image. Specifically, a novel Structured Multimodal Organizer (SMO) is proposed to address the information degradation issue, which introduces contiguous multi-view images and hierarchical text to enrich the representation of vision and language modalities. A Joint Multi-modal Alignment (JMA) is designed to tackle the insufficient synergy problem, which models the joint modality by incorporating language knowledge into the visual modality. Extensive experiments on ModelNet40 and ScanObjectNN demonstrate the effectiveness of our proposed method, JM3D, which achieves state-of-the-art performance in zero-shot 3D classification. JM3D outperforms ULIP by approximately 4.3% on PointMLP and achieves an improvement of up to 6.5% accuracy on PointNet++ in top-1 accuracy for zero-shot 3D classification on ModelNet40. The source code and trained models for all our experiments are publicly available at https://github.com/Mr-Neko/JM3D.
Continual Vision-Language Representation Learning with Off-Diagonal Information
May 17, 2023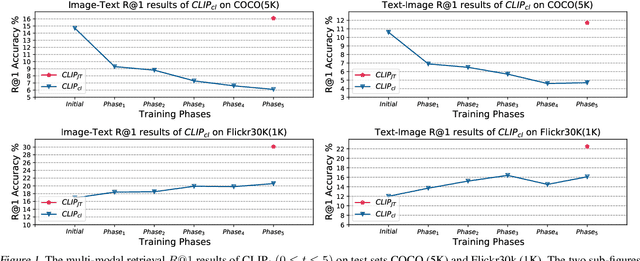
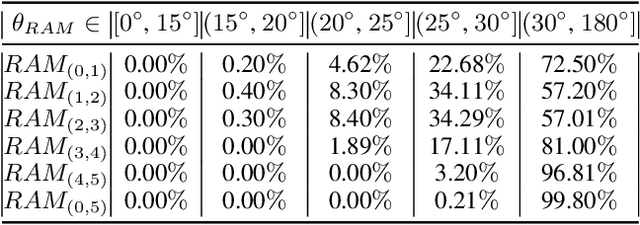

Large-scale multi-modal contrastive learning frameworks like CLIP typically require a large amount of image-text samples for training. However, these samples are always collected continuously in real scenarios. This paper discusses the feasibility of continual CLIP training using streaming data. Unlike continual learning based on self-supervised learning methods for pure images, which is empirically robust against catastrophic forgetting, CLIP's performance degeneration in the continual setting is significant and non-neglectable. By analyzing the changes in the model's representation space during continual CLIP training from a spatial geometry perspective, we explore and summarize these spatial variations as Spatial Disorder (SD), which can be divided into Intra-modal Rotation and Inter-modal Deviation. Moreover, we empirically and theoretically demonstrate how SD leads to a performance decline for CLIP on cross-modal retrieval tasks. To alleviate SD, we propose a new continual vision-language representation learning framework Mod-X: Maintain off-diagonal information-matriX. By selectively aligning the off-diagonal information distribution of contrastive matrices, the Mod-X improves the capability of the multi-modal model by maintaining the multi-modal representation space alignment on the old data domain during continuously fitting the new training data domain. Experiments on commonly used datasets with different scales and scopes have demonstrated the effectiveness of our method.
AST-MHSA : Code Summarization using Multi-Head Self-Attention
Aug 10, 2023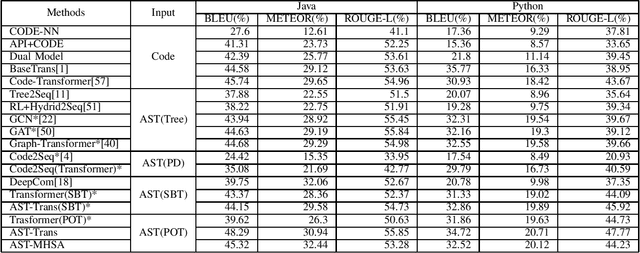
Code summarization aims to generate concise natural language descriptions for source code. The prevailing approaches adopt transformer-based encoder-decoder architectures, where the Abstract Syntax Tree (AST) of the source code is utilized for encoding structural information. However, ASTs are much longer than the corresponding source code, and existing methods ignore this size constraint by directly feeding the entire linearized AST into the encoders. This simplistic approach makes it challenging to extract truly valuable dependency relations from the overlong input sequence and leads to significant computational overhead due to self-attention applied to all nodes in the AST. To address this issue effectively and efficiently, we present a model, AST-MHSA that uses multi-head attention to extract the important semantic information from the AST. The model consists of two main components: an encoder and a decoder. The encoder takes as input the abstract syntax tree (AST) of the code and generates a sequence of hidden states. The decoder then takes these hidden states as input and generates a natural language summary of the code. The multi-head attention mechanism allows the model to learn different representations of the input code, which can be combined to generate a more comprehensive summary. The model is trained on a dataset of code and summaries, and the parameters of the model are optimized to minimize the loss between the generated summaries and the ground-truth summaries.