 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
When Large Language Models Meet Personalization: Perspectives of Challenges and Opportunities
Jul 31, 2023
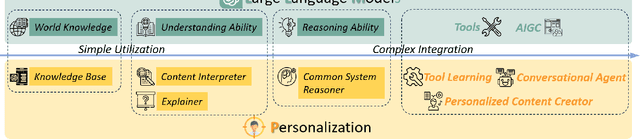

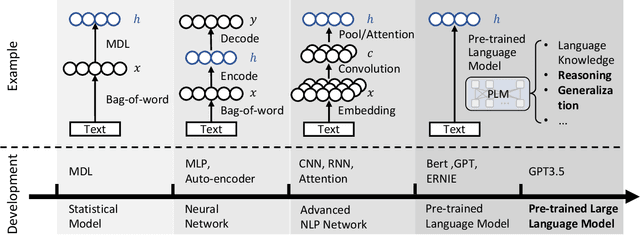
The advent of large language models marks a revolutionary breakthrough in artificial intelligence. With the unprecedented scale of training and model parameters, the capability of large language models has been dramatically improved, leading to human-like performances in understanding, language synthesizing, and common-sense reasoning, etc. Such a major leap-forward in general AI capacity will change the pattern of how personalization is conducted. For one thing, it will reform the way of interaction between humans and personalization systems. Instead of being a passive medium of information filtering, large language models present the foundation for active user engagement. On top of such a new foundation, user requests can be proactively explored, and user's required information can be delivered in a natural and explainable way. For another thing, it will also considerably expand the scope of personalization, making it grow from the sole function of collecting personalized information to the compound function of providing personalized services. By leveraging large language models as general-purpose interface, the personalization systems may compile user requests into plans, calls the functions of external tools to execute the plans, and integrate the tools' outputs to complete the end-to-end personalization tasks. Today, large language models are still being developed, whereas the application in personalization is largely unexplored. Therefore, we consider it to be the right time to review the challenges in personalization and the opportunities to address them with LLMs. In particular, we dedicate this perspective paper to the discussion of the following aspects: the development and challenges for the existing personalization system, the newly emerged capabilities of large language models, and the potential ways of making use of large language models for personalization.
Disentangling Multi-view Representations Beyond Inductive Bias
Aug 04, 2023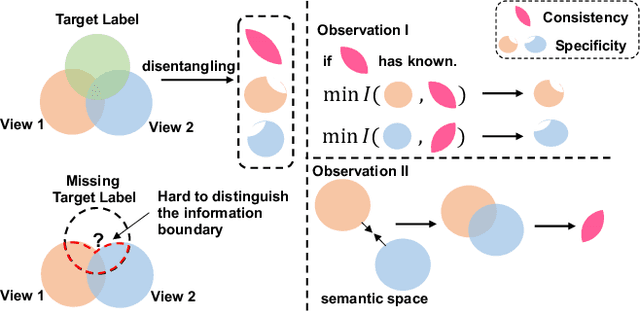
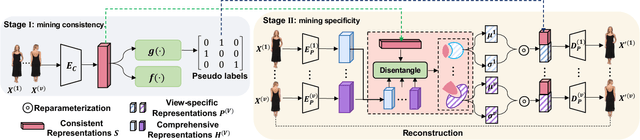
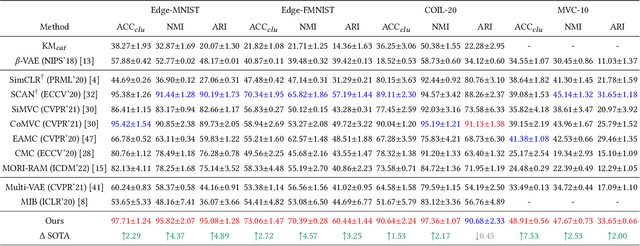
Multi-view (or -modality) representation learning aims to understand the relationships between different view representations. Existing methods disentangle multi-view representations into consistent and view-specific representations by introducing strong inductive biases, which can limit their generalization ability. In this paper, we propose a novel multi-view representation disentangling method that aims to go beyond inductive biases, ensuring both interpretability and generalizability of the resulting representations. Our method is based on the observation that discovering multi-view consistency in advance can determine the disentangling information boundary, leading to a decoupled learning objective. We also found that the consistency can be easily extracted by maximizing the transformation invariance and clustering consistency between views. These observations drive us to propose a two-stage framework. In the first stage, we obtain multi-view consistency by training a consistent encoder to produce semantically-consistent representations across views as well as their corresponding pseudo-labels. In the second stage, we disentangle specificity from comprehensive representations by minimizing the upper bound of mutual information between consistent and comprehensive representations. Finally, we reconstruct the original data by concatenating pseudo-labels and view-specific representations. Our experiments on four multi-view datasets demonstrate that our proposed method outperforms 12 comparison methods in terms of clustering and classification performance. The visualization results also show that the extracted consistency and specificity are compact and interpretable. Our code can be found at \url{https://github.com/Guanzhou-Ke/DMRIB}.
* 9 pages, 5 figures, 4 tables
Mani-GPT: A Generative Model for Interactive Robotic Manipulation
Aug 08, 2023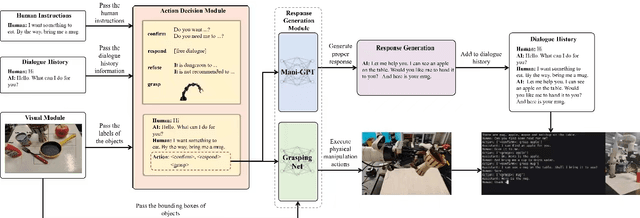

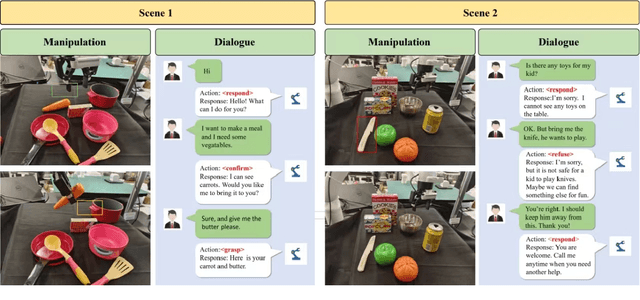
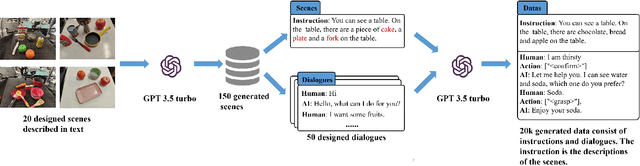
In real-world scenarios, human dialogues are multi-round and diverse. Furthermore, human instructions can be unclear and human responses are unrestricted. Interactive robots face difficulties in understanding human intents and generating suitable strategies for assisting individuals through manipulation. In this article, we propose Mani-GPT, a Generative Pre-trained Transformer (GPT) for interactive robotic manipulation. The proposed model has the ability to understand the environment through object information, understand human intent through dialogues, generate natural language responses to human input, and generate appropriate manipulation plans to assist the human. This makes the human-robot interaction more natural and humanized. In our experiment, Mani-GPT outperforms existing algorithms with an accuracy of 84.6% in intent recognition and decision-making for actions. Furthermore, it demonstrates satisfying performance in real-world dialogue tests with users, achieving an average response accuracy of 70%.
M&M: Tackling False Positives in Mammography with a Multi-view and Multi-instance Learning Sparse Detector
Aug 11, 2023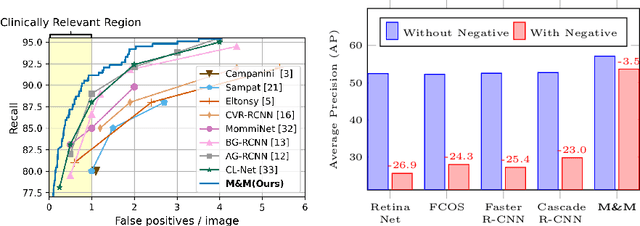
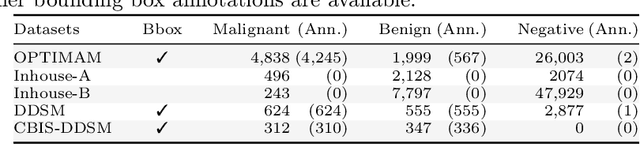
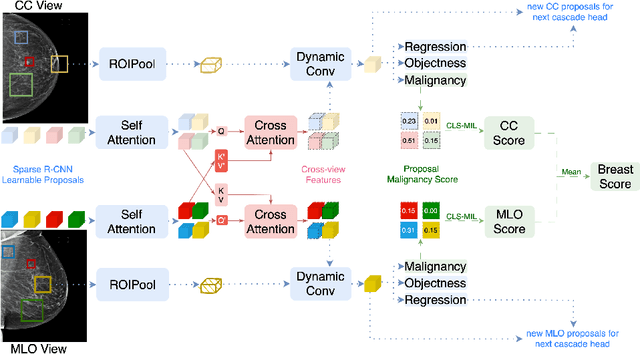
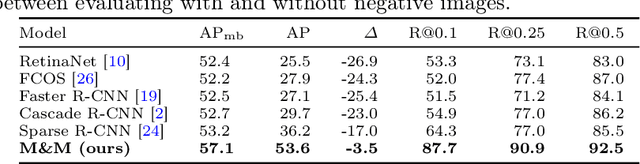
Deep-learning-based object detection methods show promise for improving screening mammography, but high rates of false positives can hinder their effectiveness in clinical practice. To reduce false positives, we identify three challenges: (1) unlike natural images, a malignant mammogram typically contains only one malignant finding; (2) mammography exams contain two views of each breast, and both views ought to be considered to make a correct assessment; (3) most mammograms are negative and do not contain any findings. In this work, we tackle the three aforementioned challenges by: (1) leveraging Sparse R-CNN and showing that sparse detectors are more appropriate than dense detectors for mammography; (2) including a multi-view cross-attention module to synthesize information from different views; (3) incorporating multi-instance learning (MIL) to train with unannotated images and perform breast-level classification. The resulting model, M&M, is a Multi-view and Multi-instance learning system that can both localize malignant findings and provide breast-level predictions. We validate M&M's detection and classification performance using five mammography datasets. In addition, we demonstrate the effectiveness of each proposed component through comprehensive ablation studies.
Learning Bayesian Networks with Heterogeneous Agronomic Data Sets via Mixed-Effect Models and Hierarchical Clustering
Aug 11, 2023
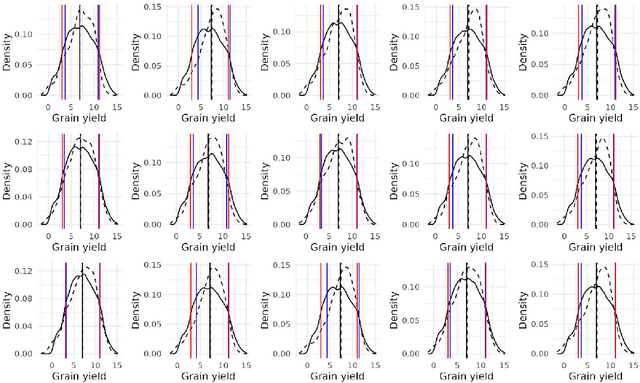
Research involving diverse but related data sets, where associations between covariates and outcomes may vary, is prevalent in various fields including agronomic studies. In these scenarios, hierarchical models, also known as multilevel models, are frequently employed to assimilate information from different data sets while accommodating their distinct characteristics. However, their structure extend beyond simple heterogeneity, as variables often form complex networks of causal relationships. Bayesian networks (BNs) provide a powerful framework for modelling such relationships using directed acyclic graphs to illustrate the connections between variables. This study introduces a novel approach that integrates random effects into BN learning. Rooted in linear mixed-effects models, this approach is particularly well-suited for handling hierarchical data. Results from a real-world agronomic trial suggest that employing this approach enhances structural learning, leading to the discovery of new connections and the improvement of improved model specification. Furthermore, we observe a reduction in prediction errors from 28\% to 17\%. By extending the applicability of BNs to complex data set structures, this approach contributes to the effective utilisation of BNs for hierarchical agronomic data. This, in turn, enhances their value as decision-support tools in the field.
Audio-Visual Spatial Integration and Recursive Attention for Robust Sound Source Localization
Aug 11, 2023The objective of the sound source localization task is to enable machines to detect the location of sound-making objects within a visual scene. While the audio modality provides spatial cues to locate the sound source, existing approaches only use audio as an auxiliary role to compare spatial regions of the visual modality. Humans, on the other hand, utilize both audio and visual modalities as spatial cues to locate sound sources. In this paper, we propose an audio-visual spatial integration network that integrates spatial cues from both modalities to mimic human behavior when detecting sound-making objects. Additionally, we introduce a recursive attention network to mimic human behavior of iterative focusing on objects, resulting in more accurate attention regions. To effectively encode spatial information from both modalities, we propose audio-visual pair matching loss and spatial region alignment loss. By utilizing the spatial cues of audio-visual modalities and recursively focusing objects, our method can perform more robust sound source localization. Comprehensive experimental results on the Flickr SoundNet and VGG-Sound Source datasets demonstrate the superiority of our proposed method over existing approaches. Our code is available at: https://github.com/VisualAIKHU/SIRA-SSL
Insurance pricing on price comparison websites via reinforcement learning
Aug 14, 2023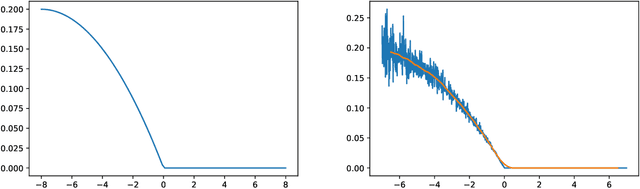
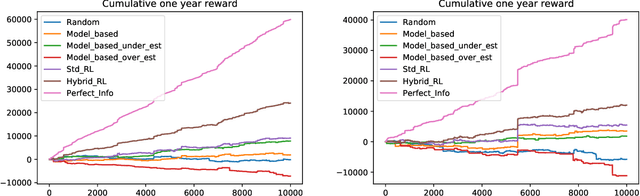
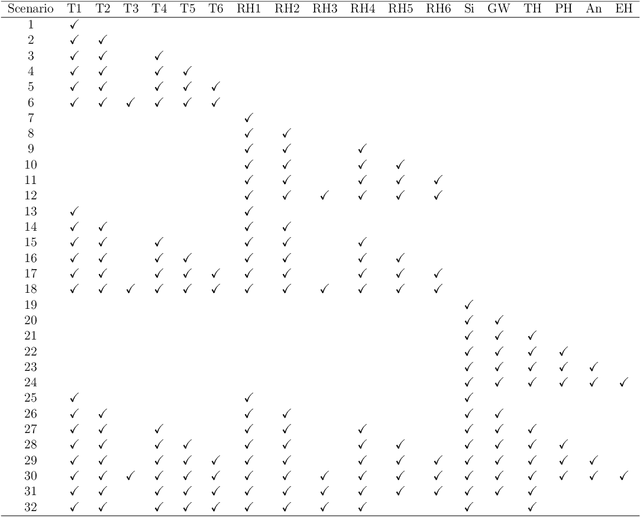
The emergence of price comparison websites (PCWs) has presented insurers with unique challenges in formulating effective pricing strategies. Operating on PCWs requires insurers to strike a delicate balance between competitive premiums and profitability, amidst obstacles such as low historical conversion rates, limited visibility of competitors' actions, and a dynamic market environment. In addition to this, the capital intensive nature of the business means pricing below the risk levels of customers can result in solvency issues for the insurer. To address these challenges, this paper introduces reinforcement learning (RL) framework that learns the optimal pricing policy by integrating model-based and model-free methods. The model-based component is used to train agents in an offline setting, avoiding cold-start issues, while model-free algorithms are then employed in a contextual bandit (CB) manner to dynamically update the pricing policy to maximise the expected revenue. This facilitates quick adaptation to evolving market dynamics and enhances algorithm efficiency and decision interpretability. The paper also highlights the importance of evaluating pricing policies using an offline dataset in a consistent fashion and demonstrates the superiority of the proposed methodology over existing off-the-shelf RL/CB approaches. We validate our methodology using synthetic data, generated to reflect private commercially available data within real-world insurers, and compare against 6 other benchmark approaches. Our hybrid agent outperforms these benchmarks in terms of sample efficiency and cumulative reward with the exception of an agent that has access to perfect market information which would not be available in a real-world set-up.
Age-Stratified Differences in Morphological Connectivity Patterns in ASD: An sMRI and Machine Learning Approach
Aug 14, 2023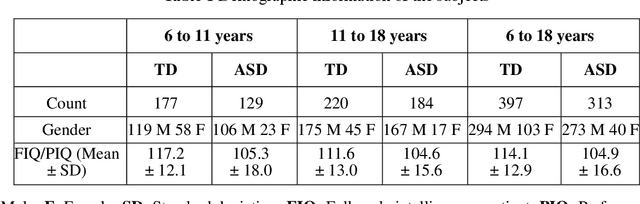
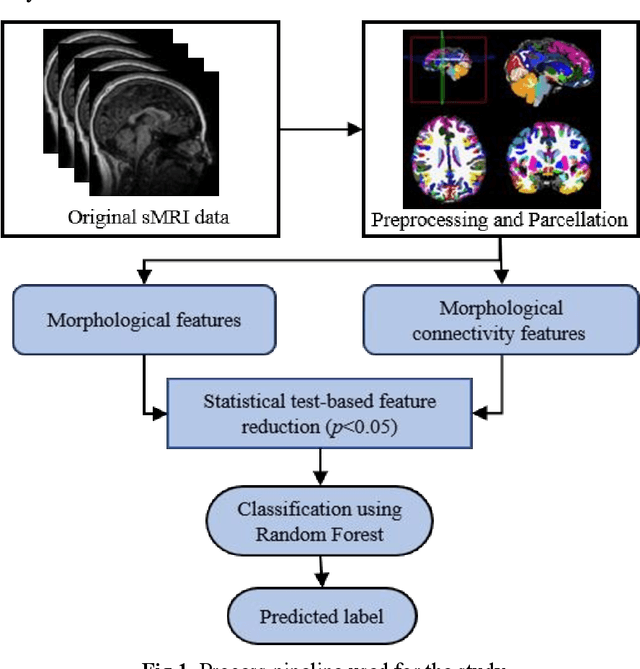
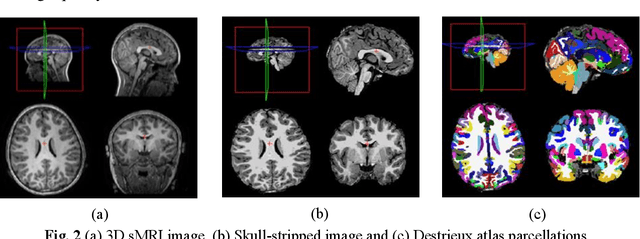
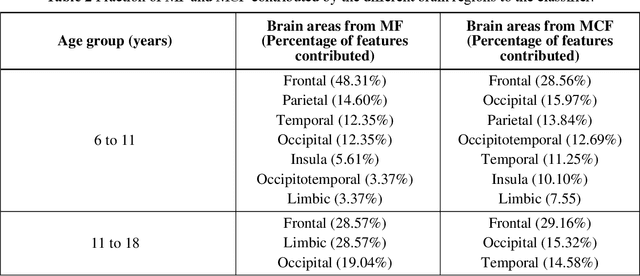
Purpose: Age biases have been identified as an essential factor in the diagnosis of ASD. The objective of this study was to compare the effect of different age groups in classifying ASD using morphological features (MF) and morphological connectivity features (MCF). Methods: The structural magnetic resonance imaging (sMRI) data for the study was obtained from the two publicly available databases, ABIDE-I and ABIDE-II. We considered three age groups, 6 to 11, 11 to 18, and 6 to 18, for our analysis. The sMRI data was pre-processed using a standard pipeline and was then parcellated into 148 different regions according to the Destrieux atlas. The area, thickness, volume, and mean curvature information was then extracted for each region which was used to create a total of 592 MF and 10,878 MCF for each subject. Significant features were identified using a statistical t-test (p<0.05) which was then used to train a random forest (RF) classifier. Results: The results of our study suggested that the performance of the 6 to 11 age group was the highest, followed by the 6 to 18 and 11 to 18 ages in both MF and MCF. Overall, the MCF with RF in the 6 to 11 age group performed better in the classification than the other groups and produced an accuracy, F1 score, recall, and precision of 75.8%, 83.1%, 86%, and 80.4%, respectively. Conclusion: Our study thus demonstrates that morphological connectivity and age-related diagnostic model could be an effective approach to discriminating ASD.
Camera Based mmWave Beam Prediction: Towards Multi-Candidate Real-World Scenarios
Aug 14, 2023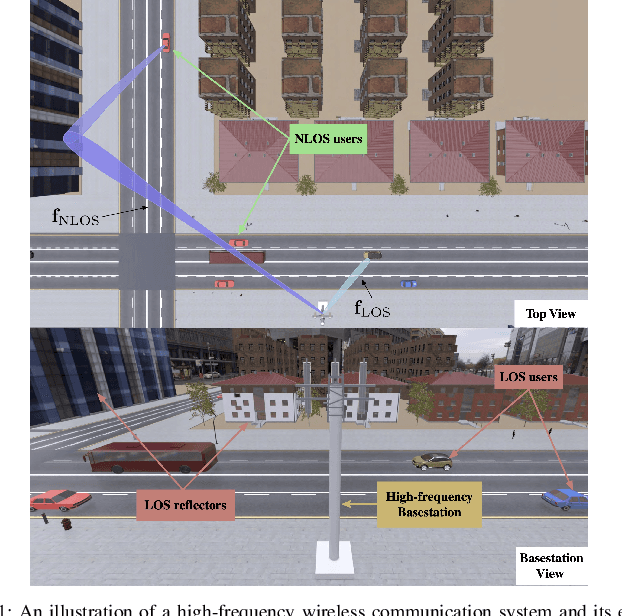
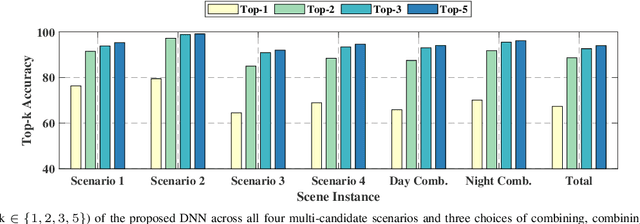
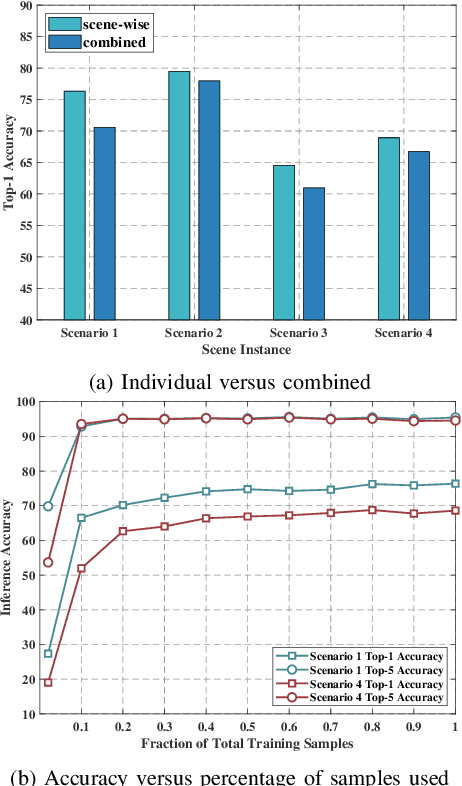
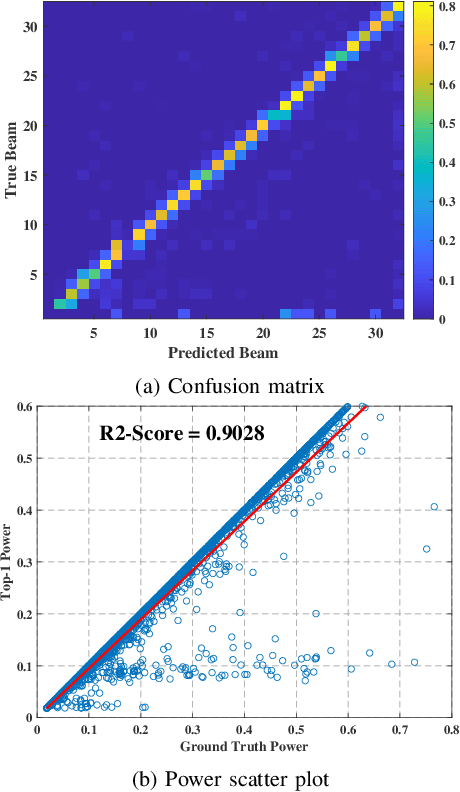
Leveraging sensory information to aid the millimeter-wave (mmWave) and sub-terahertz (sub-THz) beam selection process is attracting increasing interest. This sensory data, captured for example by cameras at the basestations, has the potential of significantly reducing the beam sweeping overhead and enabling highly-mobile applications. The solutions developed so far, however, have mainly considered single-candidate scenarios, i.e., scenarios with a single candidate user in the visual scene, and were evaluated using synthetic datasets. To address these limitations, this paper extensively investigates the sensing-aided beam prediction problem in a real-world multi-object vehicle-to-infrastructure (V2I) scenario and presents a comprehensive machine learning-based framework. In particular, this paper proposes to utilize visual and positional data to predict the optimal beam indices as an alternative to the conventional beam sweeping approaches. For this, a novel user (transmitter) identification solution has been developed, a key step in realizing sensing-aided multi-candidate and multi-user beam prediction solutions. The proposed solutions are evaluated on the large-scale real-world DeepSense $6$G dataset. Experimental results in realistic V2I communication scenarios indicate that the proposed solutions achieve close to $100\%$ top-5 beam prediction accuracy for the scenarios with single-user and close to $95\%$ top-5 beam prediction accuracy for multi-candidate scenarios. Furthermore, the proposed approach can identify the probable transmitting candidate with more than $93\%$ accuracy across the different scenarios. This highlights a promising approach for nearly eliminating the beam training overhead in mmWave/THz communication systems.
DEPHN: Different Expression Parallel Heterogeneous Network using virtual gradient optimization for Multi-task Learning
Jul 24, 2023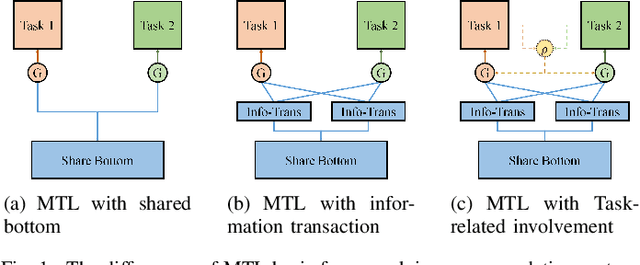
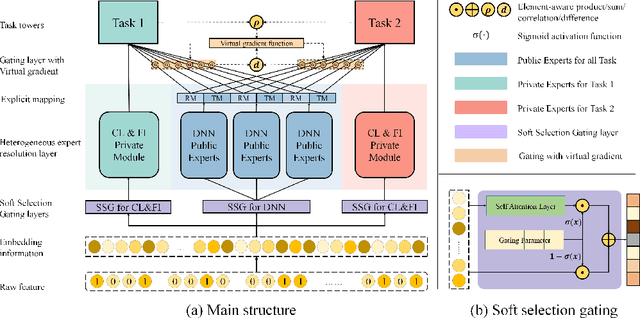
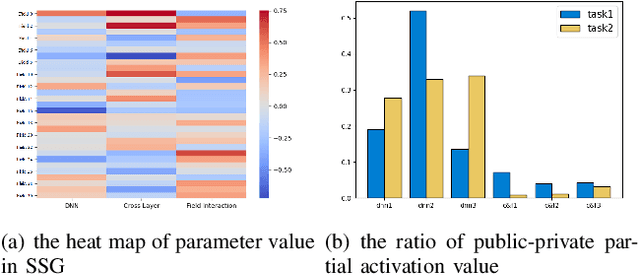
Recommendation system algorithm based on multi-task learning (MTL) is the major method for Internet operators to understand users and predict their behaviors in the multi-behavior scenario of platform. Task correlation is an important consideration of MTL goals, traditional models use shared-bottom models and gating experts to realize shared representation learning and information differentiation. However, The relationship between real-world tasks is often more complex than existing methods do not handle properly sharing information. In this paper, we propose an Different Expression Parallel Heterogeneous Network (DEPHN) to model multiple tasks simultaneously. DEPHN constructs the experts at the bottom of the model by using different feature interaction methods to improve the generalization ability of the shared information flow. In view of the model's differentiating ability for different task information flows, DEPHN uses feature explicit mapping and virtual gradient coefficient for expert gating during the training process, and adaptively adjusts the learning intensity of the gated unit by considering the difference of gating values and task correlation. Extensive experiments on artificial and real-world datasets demonstrate that our proposed method can capture task correlation in complex situations and achieve better performance than baseline models\footnote{Accepted in IJCNN2023}.