 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ClassEval: A Manually-Crafted Benchmark for Evaluating LLMs on Class-level Code Generation
Aug 14, 2023


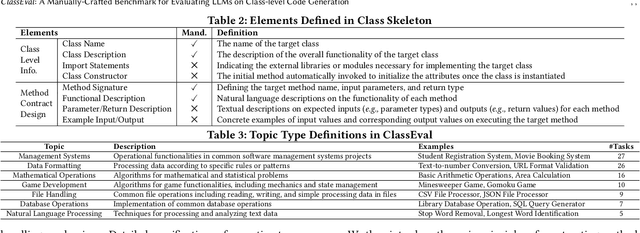
In this work, we make the first attempt to evaluate LLMs in a more challenging code generation scenario, i.e. class-level code generation. We first manually construct the first class-level code generation benchmark ClassEval of 100 class-level Python code generation tasks with approximately 500 person-hours. Based on it, we then perform the first study of 11 state-of-the-art LLMs on class-level code generation. Based on our results, we have the following main findings. First, we find that all existing LLMs show much worse performance on class-level code generation compared to on standalone method-level code generation benchmarks like HumanEval; and the method-level coding ability cannot equivalently reflect the class-level coding ability among LLMs. Second, we find that GPT-4 and GPT-3.5 still exhibit dominate superior than other LLMs on class-level code generation, and the second-tier models includes Instruct-Starcoder, Instruct-Codegen, and Wizardcoder with very similar performance. Third, we find that generating the entire class all at once (i.e. holistic generation strategy) is the best generation strategy only for GPT-4 and GPT-3.5, while method-by-method generation (i.e. incremental and compositional) is better strategies for the other models with limited ability of understanding long instructions and utilizing the middle information. Lastly, we find the limited model ability of generating method-dependent code and discuss the frequent error types in generated classes. Our benchmark is available at https://github.com/FudanSELab/ClassEval.
Jurassic World Remake: Bringing Ancient Fossils Back to Life via Zero-Shot Long Image-to-Image Translation
Aug 14, 2023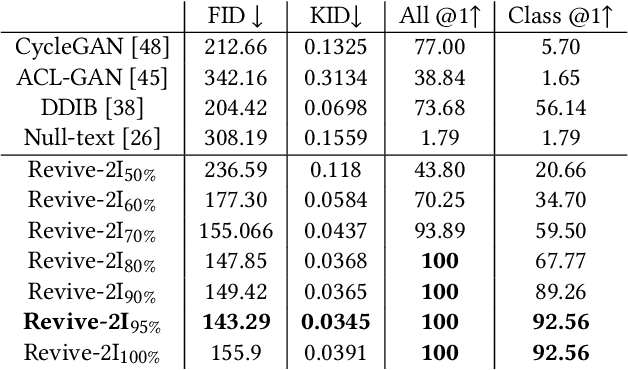
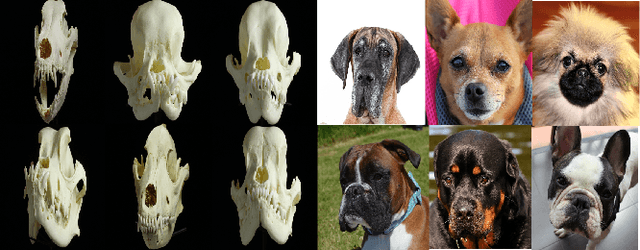
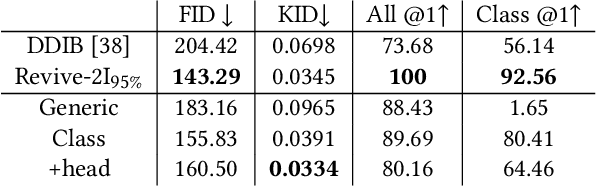
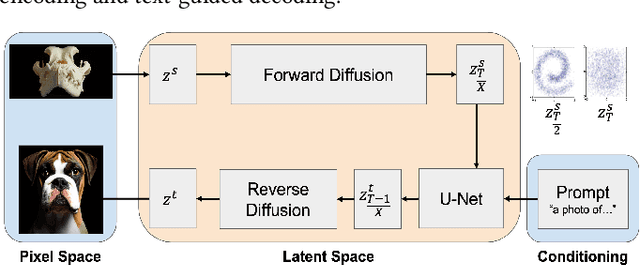
With a strong understanding of the target domain from natural language, we produce promising results in translating across large domain gaps and bringing skeletons back to life. In this work, we use text-guided latent diffusion models for zero-shot image-to-image translation (I2I) across large domain gaps (longI2I), where large amounts of new visual features and new geometry need to be generated to enter the target domain. Being able to perform translations across large domain gaps has a wide variety of real-world applications in criminology, astrology, environmental conservation, and paleontology. In this work, we introduce a new task Skull2Animal for translating between skulls and living animals. On this task, we find that unguided Generative Adversarial Networks (GANs) are not capable of translating across large domain gaps. Instead of these traditional I2I methods, we explore the use of guided diffusion and image editing models and provide a new benchmark model, Revive-2I, capable of performing zero-shot I2I via text-prompting latent diffusion models. We find that guidance is necessary for longI2I because, to bridge the large domain gap, prior knowledge about the target domain is needed. In addition, we find that prompting provides the best and most scalable information about the target domain as classifier-guided diffusion models require retraining for specific use cases and lack stronger constraints on the target domain because of the wide variety of images they are trained on.
Automated Testing and Improvement of Named Entity Recognition Systems
Aug 14, 2023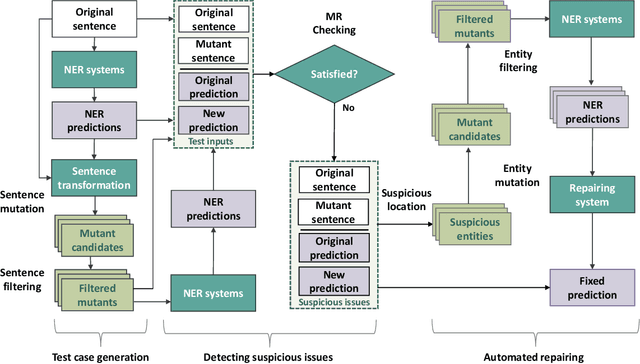

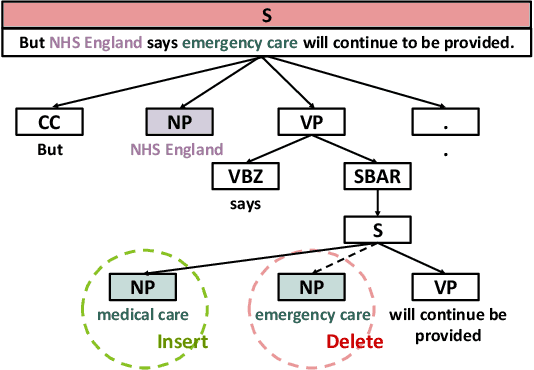
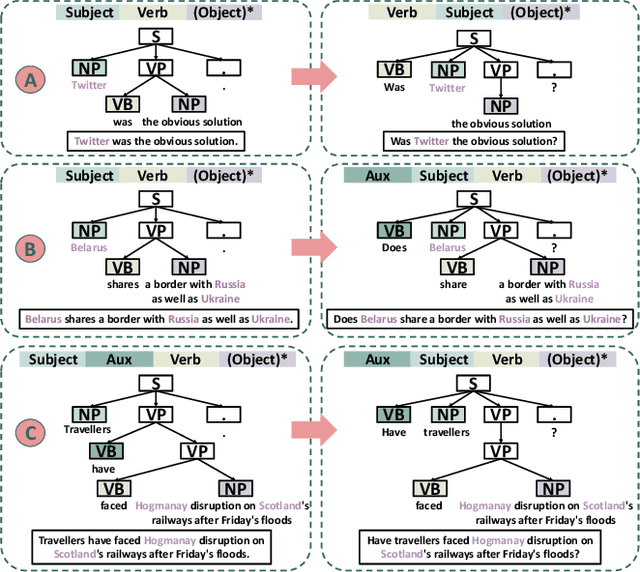
Named entity recognition (NER) systems have seen rapid progress in recent years due to the development of deep neural networks. These systems are widely used in various natural language processing applications, such as information extraction, question answering, and sentiment analysis. However, the complexity and intractability of deep neural networks can make NER systems unreliable in certain circumstances, resulting in incorrect predictions. For example, NER systems may misidentify female names as chemicals or fail to recognize the names of minority groups, leading to user dissatisfaction. To tackle this problem, we introduce TIN, a novel, widely applicable approach for automatically testing and repairing various NER systems. The key idea for automated testing is that the NER predictions of the same named entities under similar contexts should be identical. The core idea for automated repairing is that similar named entities should have the same NER prediction under the same context. We use TIN to test two SOTA NER models and two commercial NER APIs, i.e., Azure NER and AWS NER. We manually verify 784 of the suspicious issues reported by TIN and find that 702 are erroneous issues, leading to high precision (85.0%-93.4%) across four categories of NER errors: omission, over-labeling, incorrect category, and range error. For automated repairing, TIN achieves a high error reduction rate (26.8%-50.6%) over the four systems under test, which successfully repairs 1,056 out of the 1,877 reported NER errors.
A Comprehensive Analysis on the Leakage of Fuzzy Matchers
Jul 27, 2023This paper provides a comprehensive analysis of information leakage during distance evaluation, with an emphasis on threshold-based obfuscated distance (i.e., Fuzzy Matcher). Leakage can occur due to a malware infection or the use of a weakly privacy-preserving matcher, exemplified by side channel attacks or partially obfuscated designs. We provide an exhaustive catalog of information leakage scenarios as well as their impacts on the security concerning data privacy. Each of the scenarios leads to generic attacks whose impacts are expressed in terms of computational costs, hence allowing the establishment of upper bounds on the security level.
Deep Plug-and-Play Prior for Massive MIMO Systems
Aug 09, 2023Scalability is a major concern in implementing deep learning (DL) based methods in wireless communication systems. Given various communication tasks, applying one DL model for one specific task is costly in both model training and model storage. In this paper, we propose a novel deep plug-and-play prior method for three communication tasks in the downlink of massive multiple-input multiple-output (MIMO) systems, including channel estimation, antenna extrapolation and channel state information (CSI) feedback. The proposed method corresponding to these three communication tasks employs a common DL model, which greatly reduces the overhead of model training and storage. Unlike general multitask learning, the DL model of the proposed method does not require further fine-tuning for specific communication tasks, but is plug-and-play. Extensive experiments are conducted on the DeepMIMO dataset to demonstrate the convergence, performance, and storage overhead of the proposed method for the three communication tasks.
Feature Reweighting for EEG-based Motor Imagery Classification
Jul 29, 2023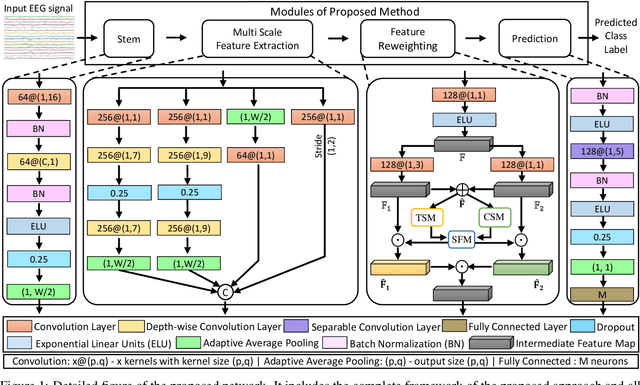
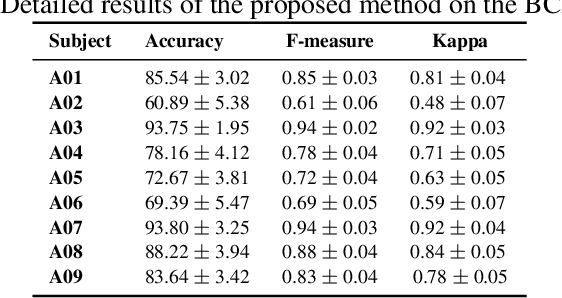
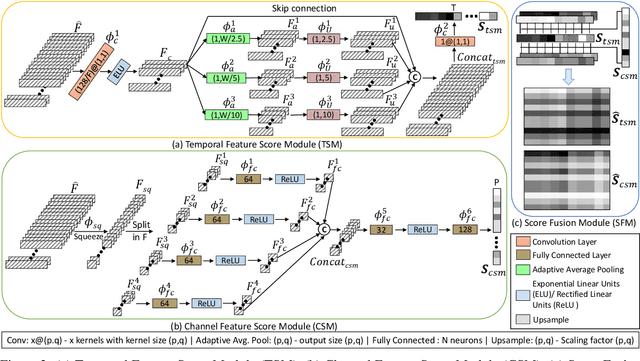
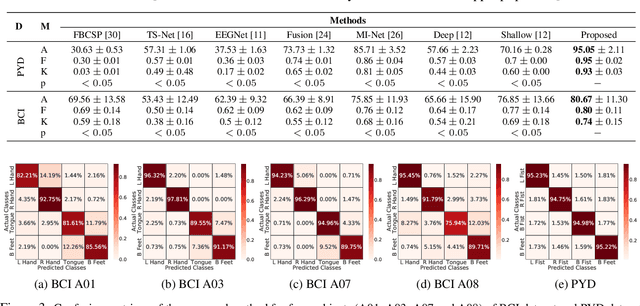
Classification of motor imagery (MI) using non-invasive electroencephalographic (EEG) signals is a critical objective as it is used to predict the intention of limb movements of a subject. In recent research, convolutional neural network (CNN) based methods have been widely utilized for MI-EEG classification. The challenges of training neural networks for MI-EEG signals classification include low signal-to-noise ratio, non-stationarity, non-linearity, and high complexity of EEG signals. The features computed by CNN-based networks on the highly noisy MI-EEG signals contain irrelevant information. Subsequently, the feature maps of the CNN-based network computed from the noisy and irrelevant features contain irrelevant information. Thus, many non-contributing features often mislead the neural network training and degrade the classification performance. Hence, a novel feature reweighting approach is proposed to address this issue. The proposed method gives a noise reduction mechanism named feature reweighting module that suppresses irrelevant temporal and channel feature maps. The feature reweighting module of the proposed method generates scores that reweight the feature maps to reduce the impact of irrelevant information. Experimental results show that the proposed method significantly improved the classification of MI-EEG signals of Physionet EEG-MMIDB and BCI Competition IV 2a datasets by a margin of 9.34% and 3.82%, respectively, compared to the state-of-the-art methods.
To Compress or Not to Compress- Self-Supervised Learning and Information Theory: A Review
May 04, 2023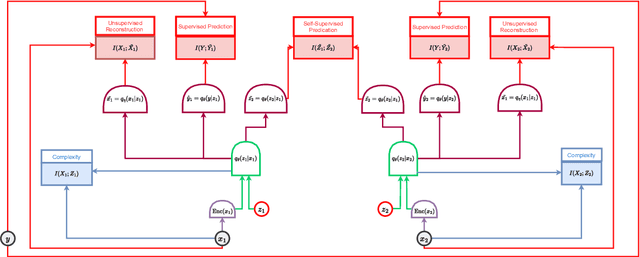
Deep neural networks have demonstrated remarkable performance in supervised learning tasks but require large amounts of labeled data. Self-supervised learning offers an alternative paradigm, enabling the model to learn from data without explicit labels. Information theory has been instrumental in understanding and optimizing deep neural networks. Specifically, the information bottleneck principle has been applied to optimize the trade-off between compression and relevant information preservation in supervised settings. However, the optimal information objective in self-supervised learning remains unclear. In this paper, we review various approaches to self-supervised learning from an information-theoretic standpoint and present a unified framework that formalizes the self-supervised information-theoretic learning problem. We integrate existing research into a coherent framework, examine recent self-supervised methods, and identify research opportunities and challenges. Moreover, we discuss empirical measurement of information-theoretic quantities and their estimators. This paper offers a comprehensive review of the intersection between information theory, self-supervised learning, and deep neural networks.
Aligning the Norwegian UD Treebank with Entity and Coreference Information
May 22, 2023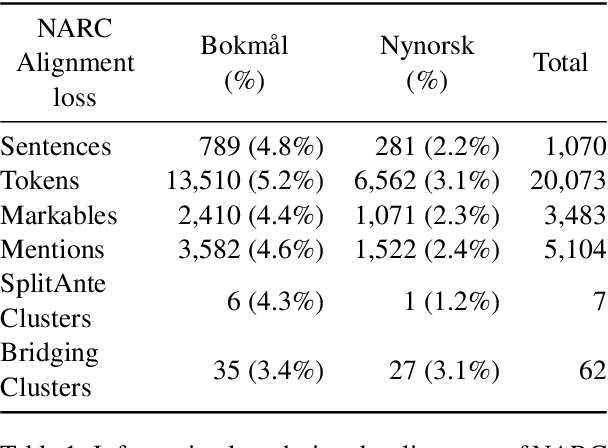

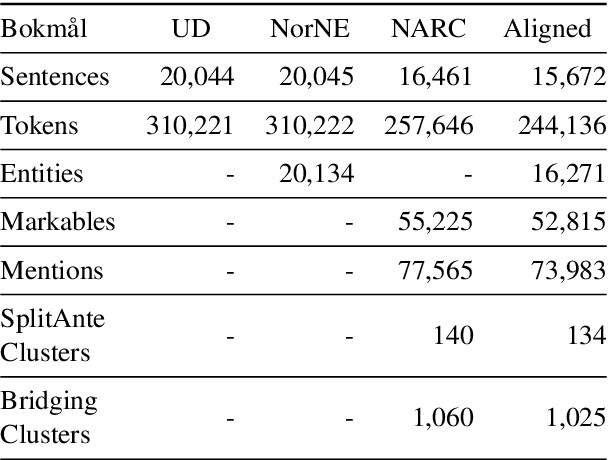
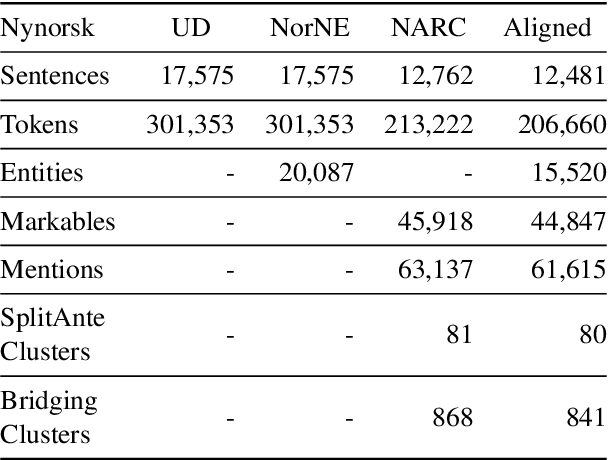
This paper presents a merged collection of entity and coreference annotated data grounded in the Universal Dependencies (UD) treebanks for the two written forms of Norwegian: Bokm{\aa}l and Nynorsk. The aligned and converted corpora are the \textit{Norwegian Named Entities} (NorNE) and \textit{Norwegian Anaphora Resolution Corpus} (NARC). While NorNE is aligned with an older version of the treebank, NARC is misaligned and requires extensive transformation from the original annotations to the UD structure and CoNLL-U format. We here demonstrate the conversion and alignment processes, along with an analysis of discovered issues and errors in the data -- some of which include data split overlaps in the original treebank. These procedures and the developed system may prove helpful for future corpus alignment and coreference annotation endeavors. The merged corpora comprise the first Norwegian UD treebank enriched with named entities and coreference information.
DEPHN: Different Expression Parallel Heterogeneous Network using virtual gradient optimization for Multi-task Learning
Jul 24, 2023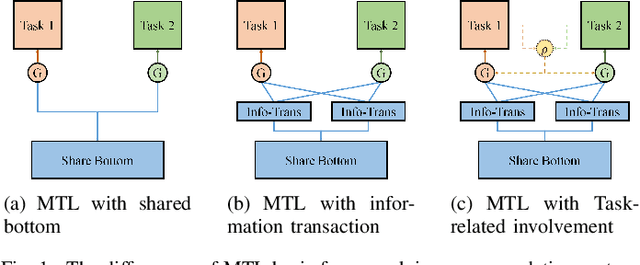
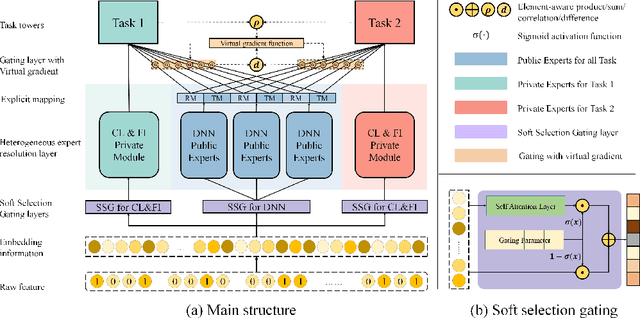
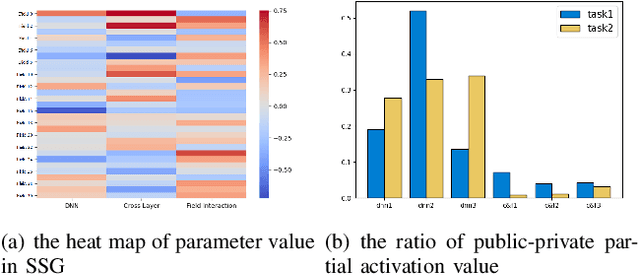
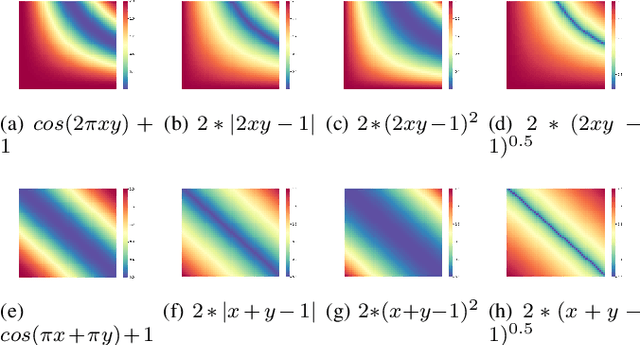
Recommendation system algorithm based on multi-task learning (MTL) is the major method for Internet operators to understand users and predict their behaviors in the multi-behavior scenario of platform. Task correlation is an important consideration of MTL goals, traditional models use shared-bottom models and gating experts to realize shared representation learning and information differentiation. However, The relationship between real-world tasks is often more complex than existing methods do not handle properly sharing information. In this paper, we propose an Different Expression Parallel Heterogeneous Network (DEPHN) to model multiple tasks simultaneously. DEPHN constructs the experts at the bottom of the model by using different feature interaction methods to improve the generalization ability of the shared information flow. In view of the model's differentiating ability for different task information flows, DEPHN uses feature explicit mapping and virtual gradient coefficient for expert gating during the training process, and adaptively adjusts the learning intensity of the gated unit by considering the difference of gating values and task correlation. Extensive experiments on artificial and real-world datasets demonstrate that our proposed method can capture task correlation in complex situations and achieve better performance than baseline models\footnote{Accepted in IJCNN2023}.
Kairos: Practical Intrusion Detection and Investigation using Whole-system Provenance
Aug 13, 2023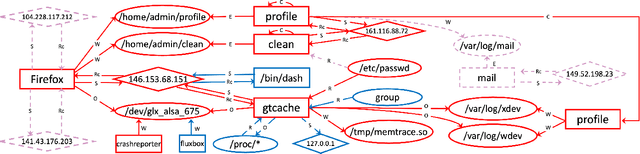

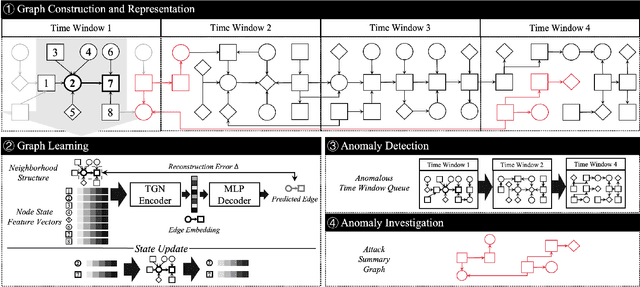
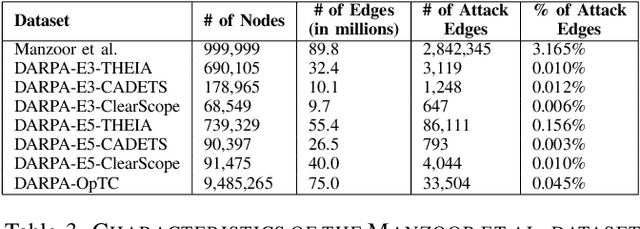
Provenance graphs are structured audit logs that describe the history of a system's execution. Recent studies have explored a variety of techniques to analyze provenance graphs for automated host intrusion detection, focusing particularly on advanced persistent threats. Sifting through their design documents, we identify four common dimensions that drive the development of provenance-based intrusion detection systems (PIDSes): scope (can PIDSes detect modern attacks that infiltrate across application boundaries?), attack agnosticity (can PIDSes detect novel attacks without a priori knowledge of attack characteristics?), timeliness (can PIDSes efficiently monitor host systems as they run?), and attack reconstruction (can PIDSes distill attack activity from large provenance graphs so that sysadmins can easily understand and quickly respond to system intrusion?). We present KAIROS, the first PIDS that simultaneously satisfies the desiderata in all four dimensions, whereas existing approaches sacrifice at least one and struggle to achieve comparable detection performance. Kairos leverages a novel graph neural network-based encoder-decoder architecture that learns the temporal evolution of a provenance graph's structural changes to quantify the degree of anomalousness for each system event. Then, based on this fine-grained information, Kairos reconstructs attack footprints, generating compact summary graphs that accurately describe malicious activity over a stream of system audit logs. Using state-of-the-art benchmark datasets, we demonstrate that Kairos outperforms previous approaches.