 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Teaching Smaller Language Models To Generalise To Unseen Compositional Questions
Aug 02, 2023
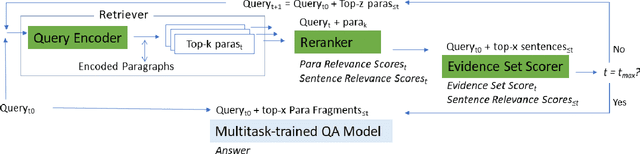

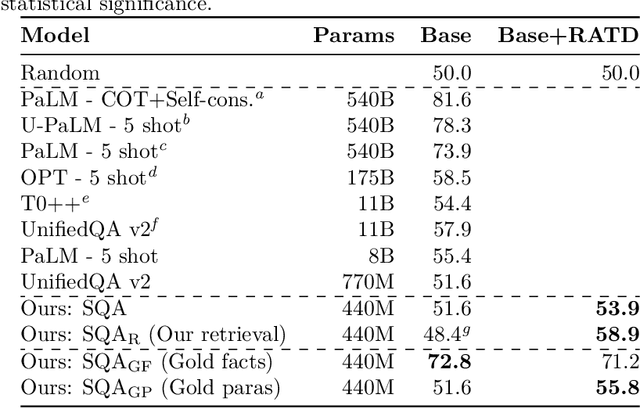
We equip a smaller Language Model to generalise to answering challenging compositional questions that have not been seen in training. To do so we propose a combination of multitask supervised pretraining on up to 93 tasks designed to instill diverse reasoning abilities, and a dense retrieval system that aims to retrieve a set of evidential paragraph fragments. Recent progress in question-answering has been achieved either through prompting methods against very large pretrained Language Models in zero or few-shot fashion, or by fine-tuning smaller models, sometimes in conjunction with information retrieval. We focus on the less explored question of the extent to which zero-shot generalisation can be enabled in smaller models with retrieval against a corpus within which sufficient information to answer a particular question may not exist. We establish strong baselines in this setting for diverse evaluation datasets (StrategyQA, CommonsenseQA, IIRC, DROP, Musique and ARC-DA), and show that performance can be significantly improved by adding retrieval-augmented training datasets which are designed to expose our models to a variety of heuristic reasoning strategies such as weighing partial evidence or ignoring an irrelevant context.
Information Fusion via Symbolic Regression: A Tutorial in the Context of Human Health
May 31, 2023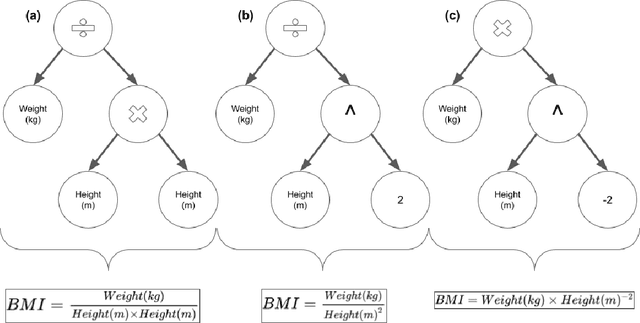
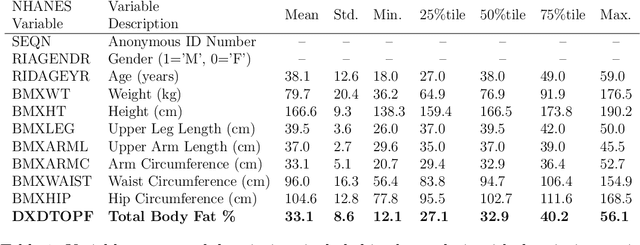
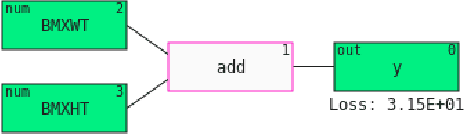
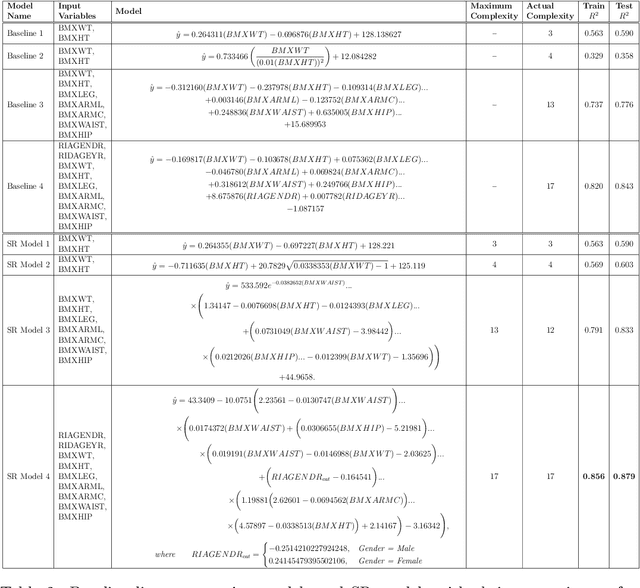
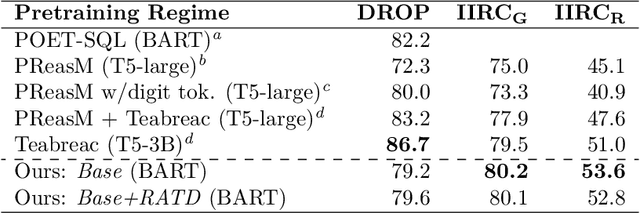
This tutorial paper provides a general overview of symbolic regression (SR) with specific focus on standards of interpretability. We posit that interpretable modeling, although its definition is still disputed in the literature, is a practical way to support the evaluation of successful information fusion. In order to convey the benefits of SR as a modeling technique, we demonstrate an application within the field of health and nutrition using publicly available National Health and Nutrition Examination Survey (NHANES) data from the Centers for Disease Control and Prevention (CDC), fusing together anthropometric markers into a simple mathematical expression to estimate body fat percentage. We discuss the advantages and challenges associated with SR modeling and provide qualitative and quantitative analyses of the learned models.
Seeing through the Brain: Image Reconstruction of Visual Perception from Human Brain Signals
Jul 27, 2023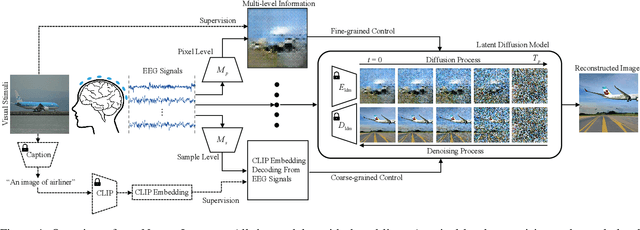


Seeing is believing, however, the underlying mechanism of how human visual perceptions are intertwined with our cognitions is still a mystery. Thanks to the recent advances in both neuroscience and artificial intelligence, we have been able to record the visually evoked brain activities and mimic the visual perception ability through computational approaches. In this paper, we pay attention to visual stimuli reconstruction by reconstructing the observed images based on portably accessible brain signals, i.e., electroencephalography (EEG) data. Since EEG signals are dynamic in the time-series format and are notorious to be noisy, processing and extracting useful information requires more dedicated efforts; In this paper, we propose a comprehensive pipeline, named NeuroImagen, for reconstructing visual stimuli images from EEG signals. Specifically, we incorporate a novel multi-level perceptual information decoding to draw multi-grained outputs from the given EEG data. A latent diffusion model will then leverage the extracted information to reconstruct the high-resolution visual stimuli images. The experimental results have illustrated the effectiveness of image reconstruction and superior quantitative performance of our proposed method.
Improved Neural Radiance Fields Using Pseudo-depth and Fusion
Jul 27, 2023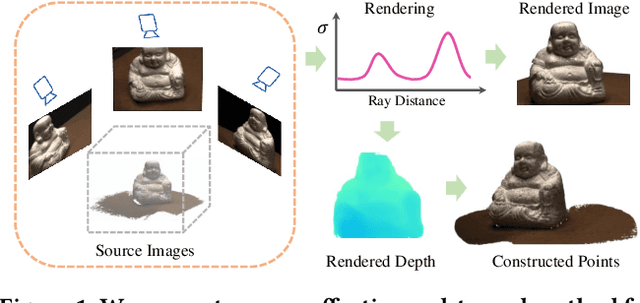

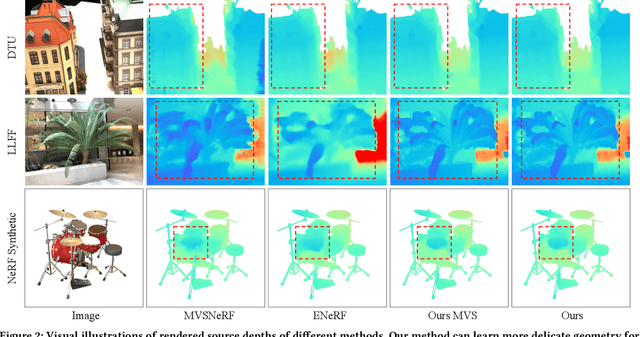
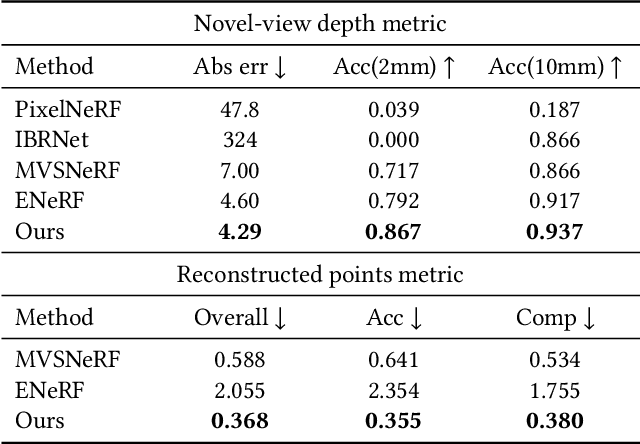
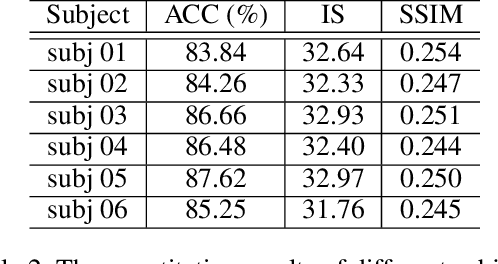
Since the advent of Neural Radiance Fields, novel view synthesis has received tremendous attention. The existing approach for the generalization of radiance field reconstruction primarily constructs an encoding volume from nearby source images as additional inputs. However, these approaches cannot efficiently encode the geometric information of real scenes with various scale objects/structures. In this work, we propose constructing multi-scale encoding volumes and providing multi-scale geometry information to NeRF models. To make the constructed volumes as close as possible to the surfaces of objects in the scene and the rendered depth more accurate, we propose to perform depth prediction and radiance field reconstruction simultaneously. The predicted depth map will be used to supervise the rendered depth, narrow the depth range, and guide points sampling. Finally, the geometric information contained in point volume features may be inaccurate due to occlusion, lighting, etc. To this end, we propose enhancing the point volume feature from depth-guided neighbor feature fusion. Experiments demonstrate the superior performance of our method in both novel view synthesis and dense geometry modeling without per-scene optimization.
Utilizing Large Language Models for Natural Interface to Pharmacology Databases
Jul 26, 2023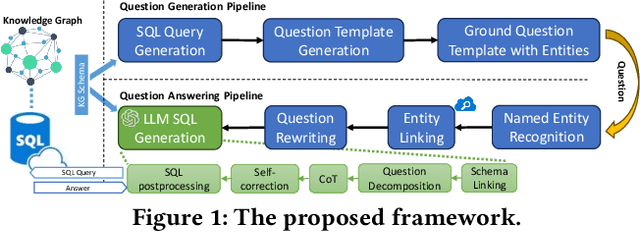
The drug development process necessitates that pharmacologists undertake various tasks, such as reviewing literature, formulating hypotheses, designing experiments, and interpreting results. Each stage requires accessing and querying vast amounts of information. In this abstract, we introduce a Large Language Model (LLM)-based Natural Language Interface designed to interact with structured information stored in databases. Our experiments demonstrate the feasibility and effectiveness of the proposed framework. This framework can generalize to query a wide range of pharmaceutical data and knowledge bases.
Kairos: Practical Intrusion Detection and Investigation using Whole-system Provenance
Aug 13, 2023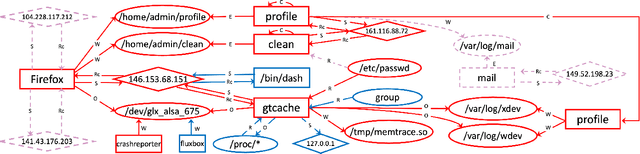

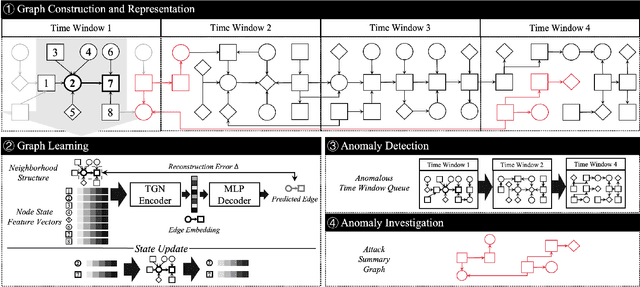
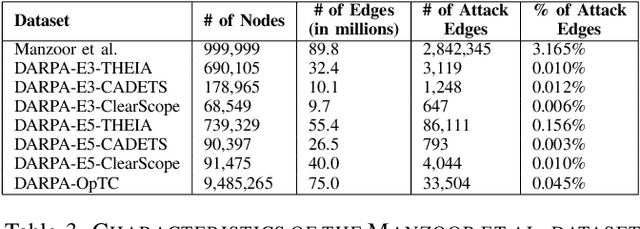
Provenance graphs are structured audit logs that describe the history of a system's execution. Recent studies have explored a variety of techniques to analyze provenance graphs for automated host intrusion detection, focusing particularly on advanced persistent threats. Sifting through their design documents, we identify four common dimensions that drive the development of provenance-based intrusion detection systems (PIDSes): scope (can PIDSes detect modern attacks that infiltrate across application boundaries?), attack agnosticity (can PIDSes detect novel attacks without a priori knowledge of attack characteristics?), timeliness (can PIDSes efficiently monitor host systems as they run?), and attack reconstruction (can PIDSes distill attack activity from large provenance graphs so that sysadmins can easily understand and quickly respond to system intrusion?). We present KAIROS, the first PIDS that simultaneously satisfies the desiderata in all four dimensions, whereas existing approaches sacrifice at least one and struggle to achieve comparable detection performance. Kairos leverages a novel graph neural network-based encoder-decoder architecture that learns the temporal evolution of a provenance graph's structural changes to quantify the degree of anomalousness for each system event. Then, based on this fine-grained information, Kairos reconstructs attack footprints, generating compact summary graphs that accurately describe malicious activity over a stream of system audit logs. Using state-of-the-art benchmark datasets, we demonstrate that Kairos outperforms previous approaches.
Data Augmentation of Bridging the Delay Gap for DL-based Massive MIMO CSI Feedback
Aug 01, 2023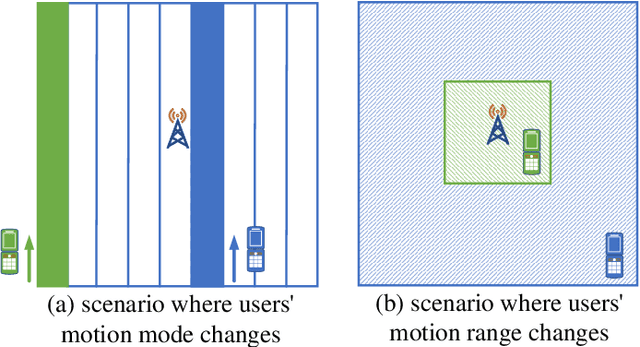
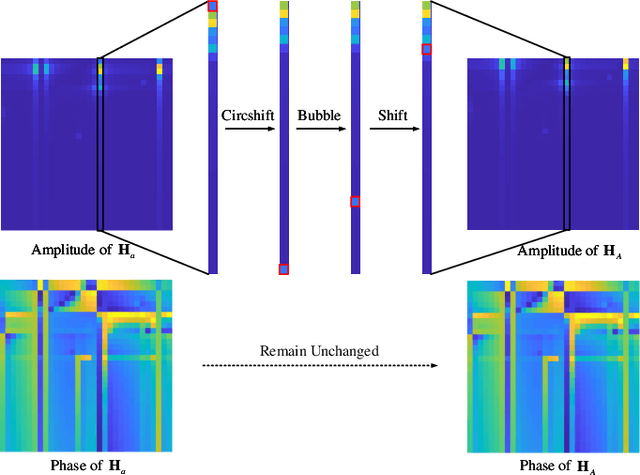
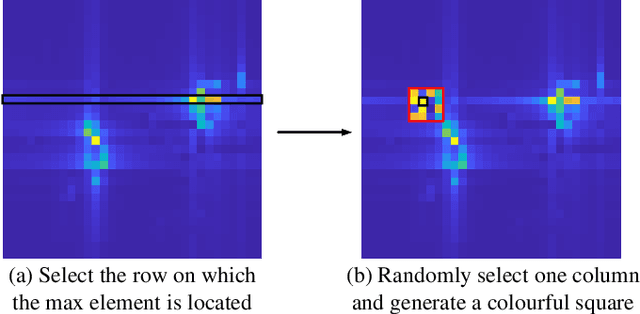
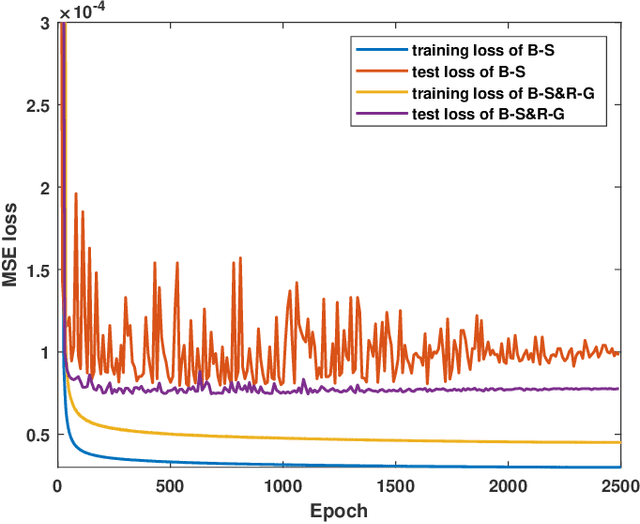
In massive multiple-input multiple-output (MIMO) systems under the frequency division duplexing (FDD) mode, the user equipment (UE) needs to feed channel state information (CSI) back to the base station (BS). Though deep learning approaches have made a hit in the CSI feedback problem, whether they can remain excellent in actual environments needs to be further investigated. In this letter, we point out that the real-time dataset in application often has the domain gap from the training dataset caused by the time delay. To bridge the gap, we propose bubble-shift (B-S) data augmentation, which attempts to offset performance degradation by changing the delay and remaining the channel information as much as possible. Moreover, random-generation (R-G) data augmentation is especially proposed for outdoor scenarios due to the complex distribution of its channels. It generalizes the characteristics of the channel matrix and alleviates the over-fitting problem. Simulation results show that the proposed data augmentation boosts the robustness of networks in both indoor and outdoor environments. The open source codes are available at https://github.com/zhanghy23/CRNet-Aug.
Real-time Automatic M-mode Echocardiography Measurement with Panel Attention from Local-to-Global Pixels
Aug 15, 2023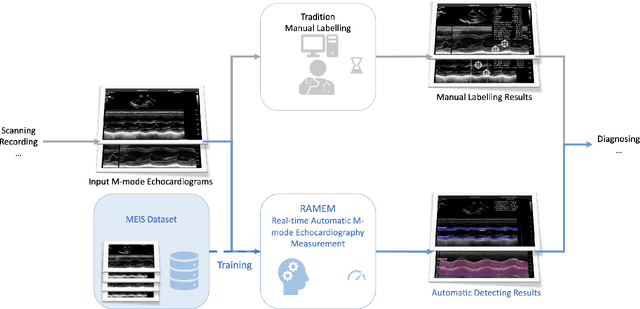
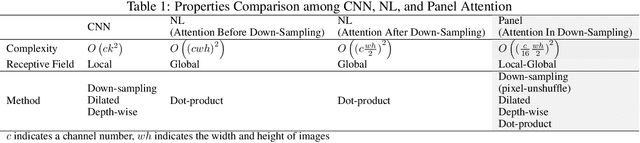
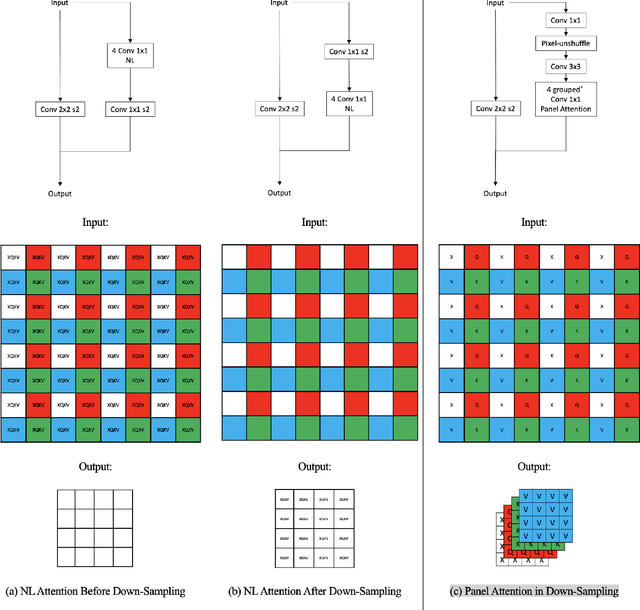

Motion mode (M-mode) recording is an essential part of echocardiography to measure cardiac dimension and function. However, the current diagnosis cannot build an automatic scheme, as there are three fundamental obstructs: Firstly, there is no open dataset available to build the automation for ensuring constant results and bridging M-mode echocardiography with real-time instance segmentation (RIS); Secondly, the examination is involving the time-consuming manual labelling upon M-mode echocardiograms; Thirdly, as objects in echocardiograms occupy a significant portion of pixels, the limited receptive field in existing backbones (e.g., ResNet) composed from multiple convolution layers are inefficient to cover the period of a valve movement. Existing non-local attentions (NL) compromise being unable real-time with a high computation overhead or losing information from a simplified version of the non-local block. Therefore, we proposed RAMEM, a real-time automatic M-mode echocardiography measurement scheme, contributes three aspects to answer the problems: 1) provide MEIS, a dataset of M-mode echocardiograms for instance segmentation, to enable consistent results and support the development of an automatic scheme; 2) propose panel attention, local-to-global efficient attention by pixel-unshuffling, embedding with updated UPANets V2 in a RIS scheme toward big object detection with global receptive field; 3) develop and implement AMEM, an efficient algorithm of automatic M-mode echocardiography measurement enabling fast and accurate automatic labelling among diagnosis. The experimental results show that RAMEM surpasses existing RIS backbones (with non-local attention) in PASCAL 2012 SBD and human performances in real-time MEIS tested. The code of MEIS and dataset are available at https://github.com/hanktseng131415go/RAME.
Fundamental Tradeoffs in Learning with Prior Information
Apr 26, 2023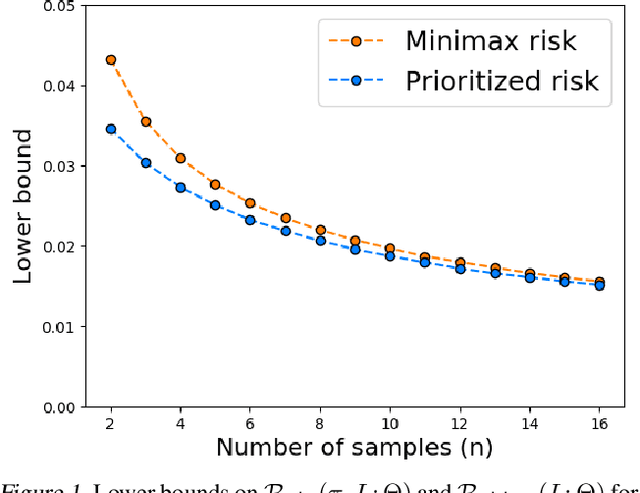
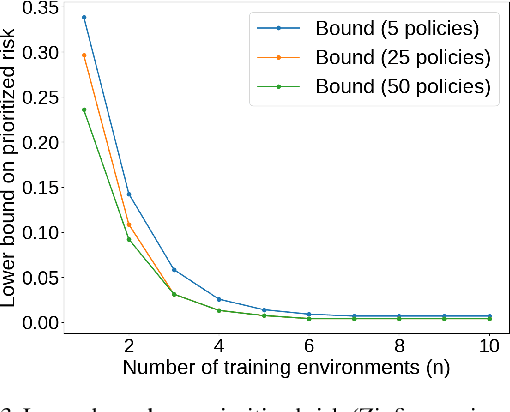
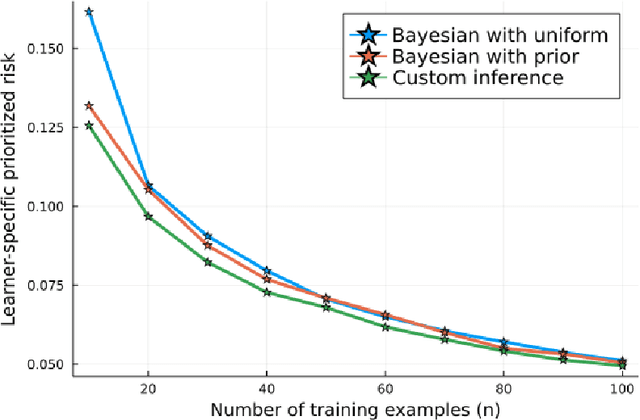
We seek to understand fundamental tradeoffs between the accuracy of prior information that a learner has on a given problem and its learning performance. We introduce the notion of prioritized risk, which differs from traditional notions of minimax and Bayes risk by allowing us to study such fundamental tradeoffs in settings where reality does not necessarily conform to the learner's prior. We present a general reduction-based approach for extending classical minimax lower-bound techniques in order to lower bound the prioritized risk for statistical estimation problems. We also introduce a novel generalization of Fano's inequality (which may be of independent interest) for lower bounding the prioritized risk in more general settings involving unbounded losses. We illustrate the ability of our framework to provide insights into tradeoffs between prior information and learning performance for problems in estimation, regression, and reinforcement learning.
Workshop on Document Intelligence Understanding
Jul 31, 2023


Document understanding and information extraction include different tasks to understand a document and extract valuable information automatically. Recently, there has been a rising demand for developing document understanding among different domains, including business, law, and medicine, to boost the efficiency of work that is associated with a large number of documents. This workshop aims to bring together researchers and industry developers in the field of document intelligence and understanding diverse document types to boost automatic document processing and understanding techniques. We also released a data challenge on the recently introduced document-level VQA dataset, PDFVQA. The PDFVQA challenge examines the structural and contextual understandings of proposed models on the natural full document level of multiple consecutive document pages by including questions with a sequence of answers extracted from multi-pages of the full document. This task helps to boost the document understanding step from the single-page level to the full document level understanding.