 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SOFIM: Stochastic Optimization Using Regularized Fisher Information Matrix
Mar 05, 2024
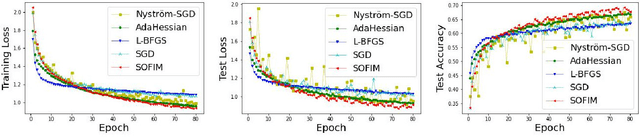
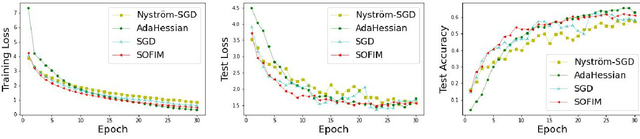
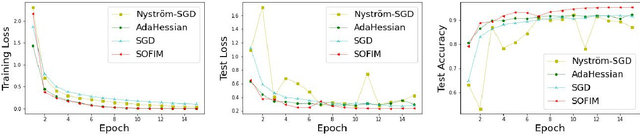
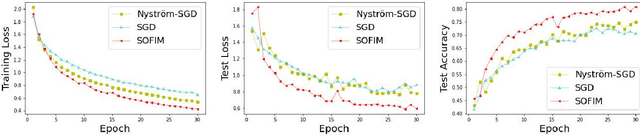
This paper introduces a new stochastic optimization method based on the regularized Fisher information matrix (FIM), named SOFIM, which can efficiently utilize the FIM to approximate the Hessian matrix for finding Newton's gradient update in large-scale stochastic optimization of machine learning models. It can be viewed as a variant of natural gradient descent (NGD), where the challenge of storing and calculating the full FIM is addressed through making use of the regularized FIM and directly finding the gradient update direction via Sherman-Morrison matrix inversion. Additionally, like the popular Adam method, SOFIM uses the first moment of the gradient to address the issue of non-stationary objectives across mini-batches due to heterogeneous data. The utilization of the regularized FIM and Sherman-Morrison matrix inversion leads to the improved convergence rate with the same space and time complexities as stochastic gradient descent (SGD) with momentum. The extensive experiments on training deep learning models on several benchmark image classification datasets demonstrate that the proposed SOFIM outperforms SGD with momentum and several state-of-the-art Newton optimization methods, such as Nystrom-SGD, L-BFGS, and AdaHessian, in term of the convergence speed for achieving the pre-specified objectives of training and test losses as well as test accuracy.
Mitigating Subpopulation Bias for Fair Network Topology Inference
Mar 22, 2024We consider fair network topology inference from nodal observations. Real-world networks often exhibit biased connections based on sensitive nodal attributes. Hence, different subpopulations of nodes may not share or receive information equitably. We thus propose an optimization-based approach to accurately infer networks while discouraging biased edges. To this end, we present bias metrics that measure topological demographic parity to be applied as convex penalties, suitable for most optimization-based graph learning methods. Moreover, we encourage equitable treatment for any number of subpopulations of differing sizes. We validate our method on synthetic and real-world simulations using networks with both biased and unbiased connections.
H-vmunet: High-order Vision Mamba UNet for Medical Image Segmentation
Mar 20, 2024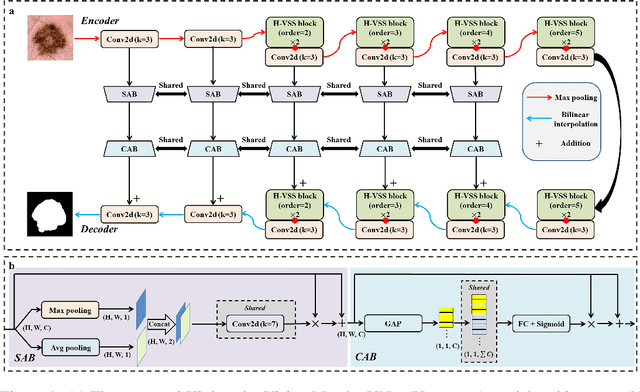
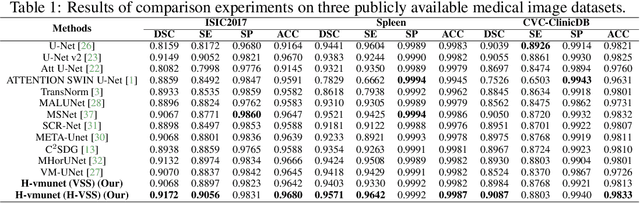

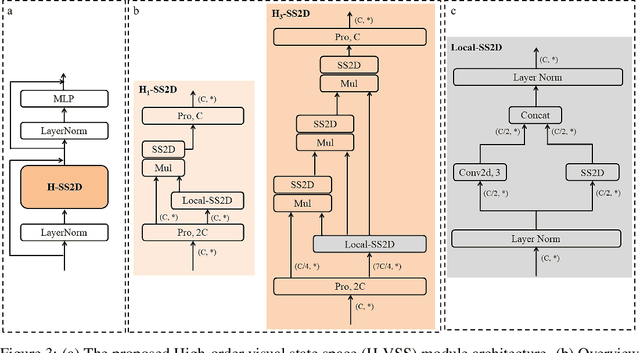
In the field of medical image segmentation, variant models based on Convolutional Neural Networks (CNNs) and Visual Transformers (ViTs) as the base modules have been very widely developed and applied. However, CNNs are often limited in their ability to deal with long sequences of information, while the low sensitivity of ViTs to local feature information and the problem of secondary computational complexity limit their development. Recently, the emergence of state-space models (SSMs), especially 2D-selective-scan (SS2D), has had an impact on the longtime dominance of traditional CNNs and ViTs as the foundational modules of visual neural networks. In this paper, we extend the adaptability of SS2D by proposing a High-order Vision Mamba UNet (H-vmunet) for medical image segmentation. Among them, the proposed High-order 2D-selective-scan (H-SS2D) progressively reduces the introduction of redundant information during SS2D operations through higher-order interactions. In addition, the proposed Local-SS2D module improves the learning ability of local features of SS2D at each order of interaction. We conducted comparison and ablation experiments on three publicly available medical image datasets (ISIC2017, Spleen, and CVC-ClinicDB), and the results all demonstrate the strong competitiveness of H-vmunet in medical image segmentation tasks. The code is available from https://github.com/wurenkai/H-vmunet .
Preventing Catastrophic Forgetting through Memory Networks in Continuous Detection
Mar 21, 2024Modern pre-trained architectures struggle to retain previous information while undergoing continuous fine-tuning on new tasks. Despite notable progress in continual classification, systems designed for complex vision tasks such as detection or segmentation still struggle to attain satisfactory performance. In this work, we introduce a memory-based detection transformer architecture to adapt a pre-trained DETR-style detector to new tasks while preserving knowledge from previous tasks. We propose a novel localized query function for efficient information retrieval from memory units, aiming to minimize forgetting. Furthermore, we identify a fundamental challenge in continual detection referred to as background relegation. This arises when object categories from earlier tasks reappear in future tasks, potentially without labels, leading them to be implicitly treated as background. This is an inevitable issue in continual detection or segmentation. The introduced continual optimization technique effectively tackles this challenge. Finally, we assess the performance of our proposed system on continual detection benchmarks and demonstrate that our approach surpasses the performance of existing state-of-the-art resulting in 5-7% improvements on MS-COCO and PASCAL-VOC on the task of continual detection.
On the exploitation of DCT statistics for cropping detectors
Mar 21, 2024{The study of frequency components derived from Discrete Cosine Transform (DCT) has been widely used in image analysis. In recent years it has been observed that significant information can be extrapolated from them about the lifecycle of the image, but no study has focused on the analysis between them and the source resolution of the image. In this work, we investigated a novel image resolution classifier that employs DCT statistics with the goal to detect the original resolution of images; in particular the insight was exploited to address the challenge of identifying cropped images. Training a Machine Learning (ML) classifier on entire images (not cropped), the generated model can leverage this information to detect cropping. The results demonstrate the classifier's reliability in distinguishing between cropped and not cropped images, providing a dependable estimation of their original resolution. This advancement has significant implications for image processing applications, including digital security, authenticity verification, and visual quality analysis, by offering a new tool for detecting image manipulations and enhancing qualitative image assessment. This work opens new perspectives in the field, with potential to transform image analysis and usage across multiple domains.}
Inf2Guard: An Information-Theoretic Framework for Learning Privacy-Preserving Representations against Inference Attacks
Mar 04, 2024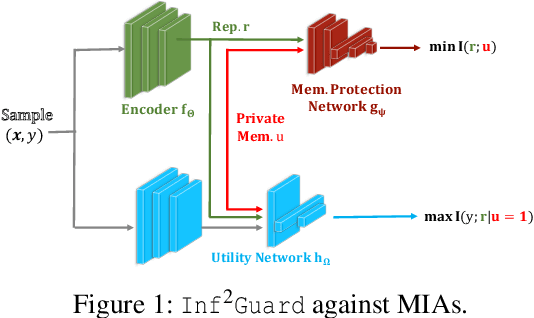
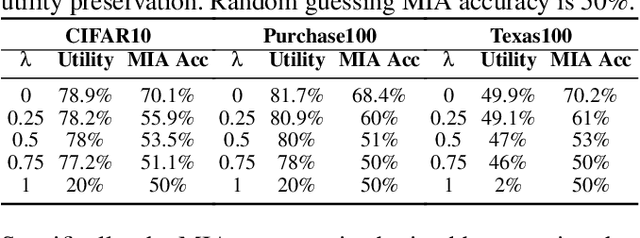
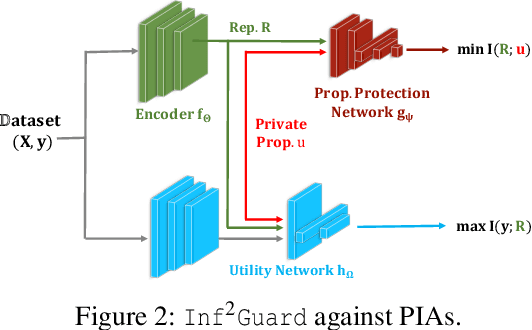
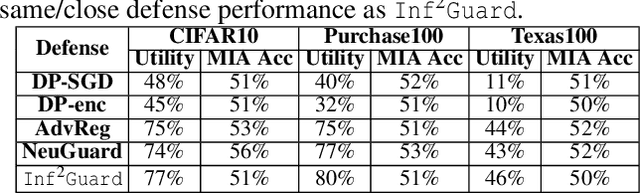
Machine learning (ML) is vulnerable to inference (e.g., membership inference, property inference, and data reconstruction) attacks that aim to infer the private information of training data or dataset. Existing defenses are only designed for one specific type of attack and sacrifice significant utility or are soon broken by adaptive attacks. We address these limitations by proposing an information-theoretic defense framework, called Inf2Guard, against the three major types of inference attacks. Our framework, inspired by the success of representation learning, posits that learning shared representations not only saves time/costs but also benefits numerous downstream tasks. Generally, Inf2Guard involves two mutual information objectives, for privacy protection and utility preservation, respectively. Inf2Guard exhibits many merits: it facilitates the design of customized objectives against the specific inference attack; it provides a general defense framework which can treat certain existing defenses as special cases; and importantly, it aids in deriving theoretical results, e.g., inherent utility-privacy tradeoff and guaranteed privacy leakage. Extensive evaluations validate the effectiveness of Inf2Guard for learning privacy-preserving representations against inference attacks and demonstrate the superiority over the baselines.
Ultra Low-Cost Two-Stage Multimodal System for Non-Normative Behavior Detection
Mar 24, 2024The online community has increasingly been inundated by a toxic wave of harmful comments. In response to this growing challenge, we introduce a two-stage ultra-low-cost multimodal harmful behavior detection method designed to identify harmful comments and images with high precision and recall rates. We first utilize the CLIP-ViT model to transform tweets and images into embeddings, effectively capturing the intricate interplay of semantic meaning and subtle contextual clues within texts and images. Then in the second stage, the system feeds these embeddings into a conventional machine learning classifier like SVM or logistic regression, enabling the system to be trained rapidly and to perform inference at an ultra-low cost. By converting tweets into rich multimodal embeddings through the CLIP-ViT model and utilizing them to train conventional machine learning classifiers, our system is not only capable of detecting harmful textual information with near-perfect performance, achieving precision and recall rates above 99\% but also demonstrates the ability to zero-shot harmful images without additional training, thanks to its multimodal embedding input. This capability empowers our system to identify unseen harmful images without requiring extensive and costly image datasets. Additionally, our system quickly adapts to new harmful content; if a new harmful content pattern is identified, we can fine-tune the classifier with the corresponding tweets' embeddings to promptly update the system. This makes it well suited to addressing the ever-evolving nature of online harmfulness, providing online communities with a robust, generalizable, and cost-effective tool to safeguard their communities.
LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression
Mar 19, 2024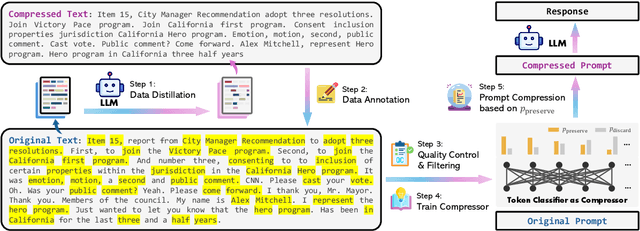
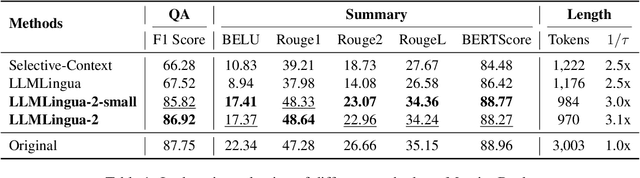

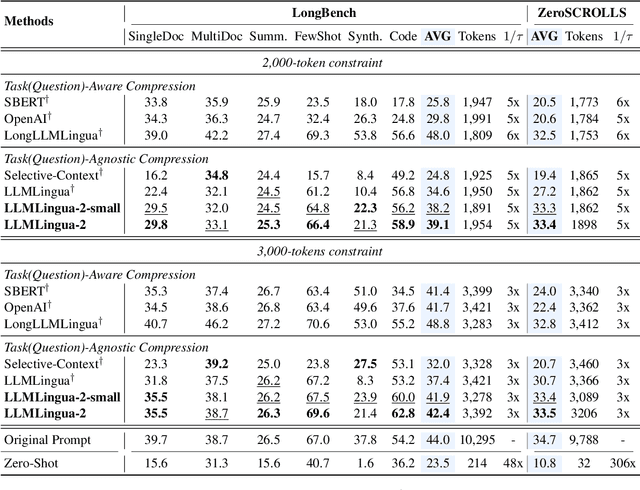
This paper focuses on task-agnostic prompt compression for better generalizability and efficiency. Considering the redundancy in natural language, existing approaches compress prompts by removing tokens or lexical units according to their information entropy obtained from a causal language model such as LLaMa-7B. The challenge is that information entropy may be a suboptimal compression metric: (i) it only leverages unidirectional context and may fail to capture all essential information needed for prompt compression; (ii) it is not aligned with the prompt compression objective. To address these issues, we propose a data distillation procedure to derive knowledge from an LLM to compress prompts without losing crucial information, and meantime, introduce an extractive text compression dataset. We formulate prompt compression as a token classification problem to guarantee the faithfulness of the compressed prompt to the original one, and use a Transformer encoder as the base architecture to capture all essential information for prompt compression from the full bidirectional context. Our approach leads to lower latency by explicitly learning the compression objective with smaller models such as XLM-RoBERTa-large and mBERT. We evaluate our method on both in-domain and out-of-domain datasets, including MeetingBank, LongBench, ZeroScrolls, GSM8K, and BBH. Despite its small size, our model shows significant performance gains over strong baselines and demonstrates robust generalization ability across different LLMs. Additionally, our model is 3x-6x faster than existing prompt compression methods, while accelerating the end-to-end latency by 1.6x-2.9x with compression ratios of 2x-5x.
Visuo-Tactile Pretraining for Cable Plugging
Mar 18, 2024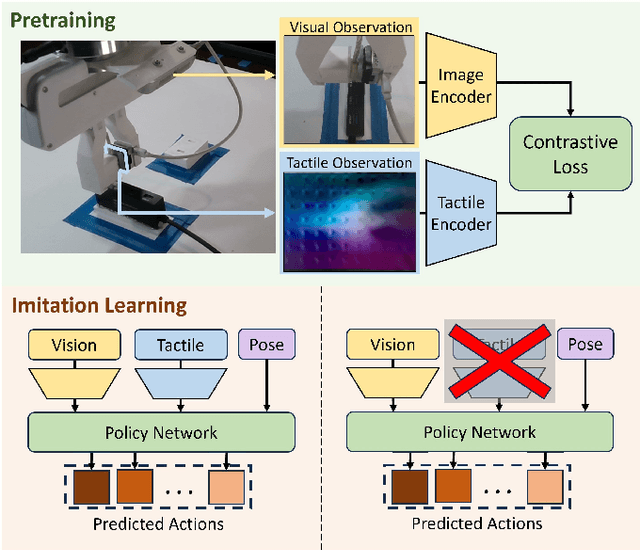
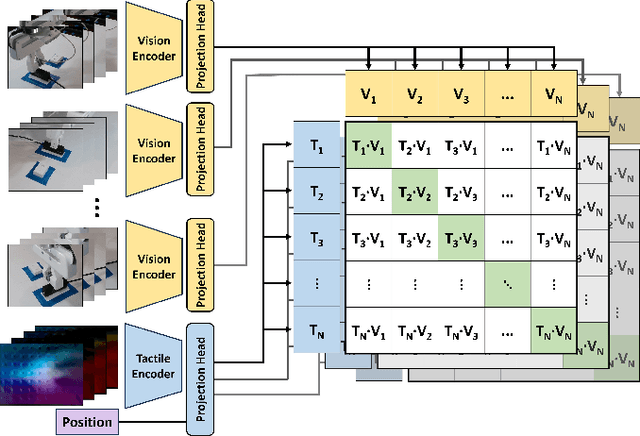

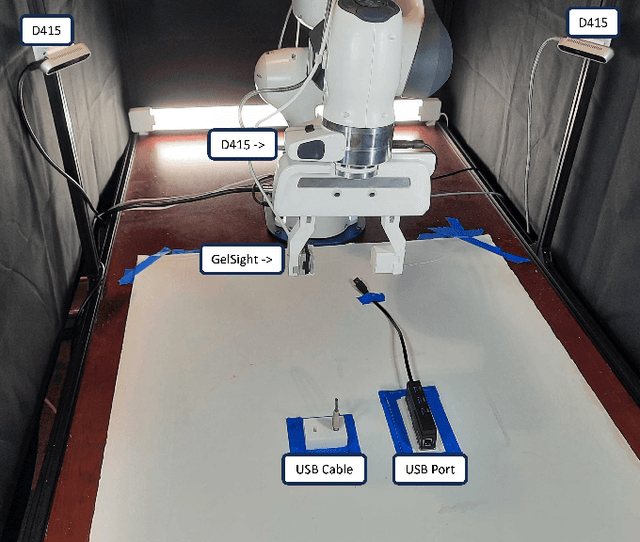
Tactile information is a critical tool for fine-grain manipulation. As humans, we rely heavily on tactile information to understand objects in our environments and how to interact with them. We use touch not only to perform manipulation tasks but also to learn how to perform these tasks. Therefore, to create robotic agents that can learn to complete manipulation tasks at a human or super-human level of performance, we need to properly incorporate tactile information into both skill execution and skill learning. In this paper, we investigate how we can incorporate tactile information into imitation learning platforms to improve performance on complex tasks. To do this, we tackle the challenge of plugging in a USB cable, a dexterous manipulation task that relies on fine-grain visuo-tactile serving. By incorporating tactile information into imitation learning frameworks, we are able to train a robotic agent to plug in a USB cable - a first for imitation learning. Additionally, we explore how tactile information can be used to train non-tactile agents through a contrastive-loss pretraining process. Our results show that by pretraining with tactile information, the performance of a non-tactile agent can be significantly improved, reaching a level on par with visuo-tactile agents. For demonstration videos and access to our codebase, see the project website: https://sites.google.com/andrew.cmu.edu/visuo-tactile-cable-plugging/home
Modeling Unified Semantic Discourse Structure for High-quality Headline Generation
Mar 23, 2024Headline generation aims to summarize a long document with a short, catchy title that reflects the main idea. This requires accurately capturing the core document semantics, which is challenging due to the lengthy and background information-rich na ture of the texts. In this work, We propose using a unified semantic discourse structure (S3) to represent document semantics, achieved by combining document-level rhetorical structure theory (RST) trees with sentence-level abstract meaning representation (AMR) graphs to construct S3 graphs. The hierarchical composition of sentence, clause, and word intrinsically characterizes the semantic meaning of the overall document. We then develop a headline generation framework, in which the S3 graphs are encoded as contextual features. To consolidate the efficacy of S3 graphs, we further devise a hierarchical structure pruning mechanism to dynamically screen the redundant and nonessential nodes within the graph. Experimental results on two headline generation datasets demonstrate that our method outperforms existing state-of-art methods consistently. Our work can be instructive for a broad range of document modeling tasks, more than headline or summarization generation.