 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
OpenProteinSet: Training data for structural biology at scale
Aug 10, 2023

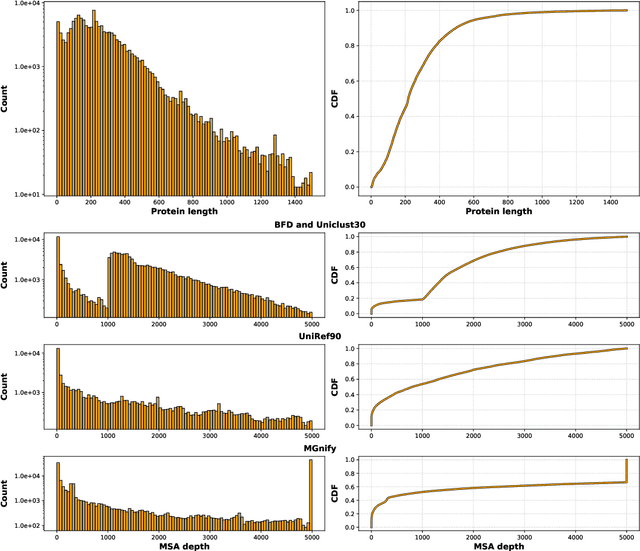
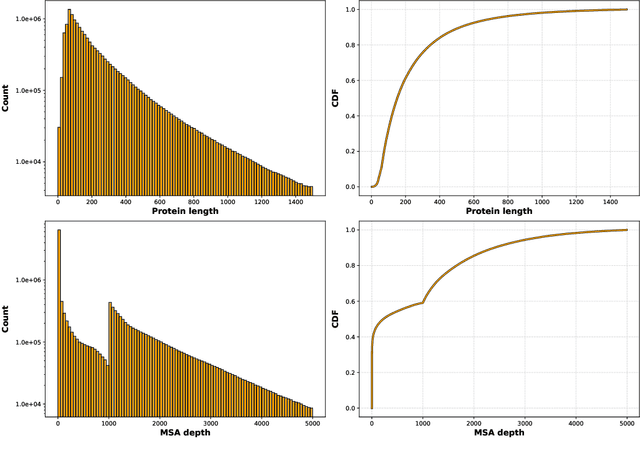
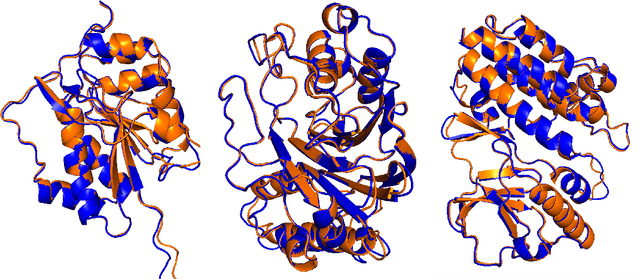
Multiple sequence alignments (MSAs) of proteins encode rich biological information and have been workhorses in bioinformatic methods for tasks like protein design and protein structure prediction for decades. Recent breakthroughs like AlphaFold2 that use transformers to attend directly over large quantities of raw MSAs have reaffirmed their importance. Generation of MSAs is highly computationally intensive, however, and no datasets comparable to those used to train AlphaFold2 have been made available to the research community, hindering progress in machine learning for proteins. To remedy this problem, we introduce OpenProteinSet, an open-source corpus of more than 16 million MSAs, associated structural homologs from the Protein Data Bank, and AlphaFold2 protein structure predictions. We have previously demonstrated the utility of OpenProteinSet by successfully retraining AlphaFold2 on it. We expect OpenProteinSet to be broadly useful as training and validation data for 1) diverse tasks focused on protein structure, function, and design and 2) large-scale multimodal machine learning research.
Dual Aggregation Transformer for Image Super-Resolution
Aug 11, 2023
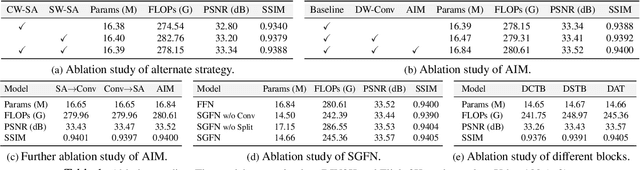
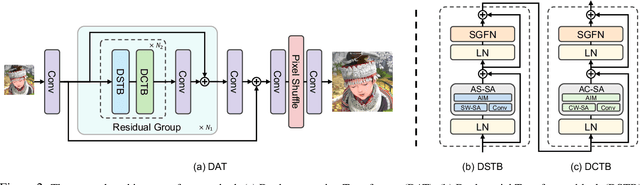
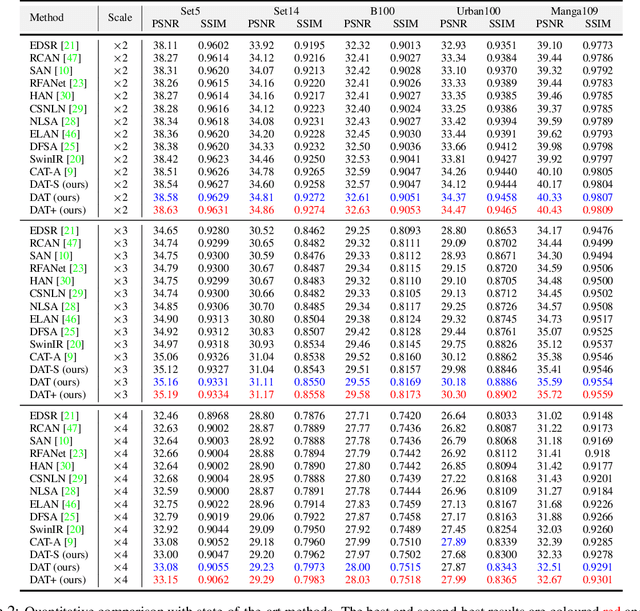
Transformer has recently gained considerable popularity in low-level vision tasks, including image super-resolution (SR). These networks utilize self-attention along different dimensions, spatial or channel, and achieve impressive performance. This inspires us to combine the two dimensions in Transformer for a more powerful representation capability. Based on the above idea, we propose a novel Transformer model, Dual Aggregation Transformer (DAT), for image SR. Our DAT aggregates features across spatial and channel dimensions, in the inter-block and intra-block dual manner. Specifically, we alternately apply spatial and channel self-attention in consecutive Transformer blocks. The alternate strategy enables DAT to capture the global context and realize inter-block feature aggregation. Furthermore, we propose the adaptive interaction module (AIM) and the spatial-gate feed-forward network (SGFN) to achieve intra-block feature aggregation. AIM complements two self-attention mechanisms from corresponding dimensions. Meanwhile, SGFN introduces additional non-linear spatial information in the feed-forward network. Extensive experiments show that our DAT surpasses current methods. Code and models are obtainable at https://github.com/zhengchen1999/DAT.
A Hierarchical Descriptor Framework for On-the-Fly Anatomical Location Matching between Longitudinal Studies
Aug 11, 2023We propose a method to match anatomical locations between pairs of medical images in longitudinal comparisons. The matching is made possible by computing a descriptor of the query point in a source image based on a hierarchical sparse sampling of image intensities that encode the location information. Then, a hierarchical search operation finds the corresponding point with the most similar descriptor in the target image. This simple yet powerful strategy reduces the computational time of mapping points to a millisecond scale on a single CPU. Thus, radiologists can compare similar anatomical locations in near real-time without requiring extra architectural costs for precomputing or storing deformation fields from registrations. Our algorithm does not require prior training, resampling, segmentation, or affine transformation steps. We have tested our algorithm on the recently published Deep Lesion Tracking dataset annotations. We observed more accurate matching compared to Deep Lesion Tracker while being 24 times faster than the most precise algorithm reported therein. We also investigated the matching accuracy on CT and MR modalities and compared the proposed algorithm's accuracy against ground truth consolidated from multiple radiologists.
BATINet: Background-Aware Text to Image Synthesis and Manipulation Network
Aug 11, 2023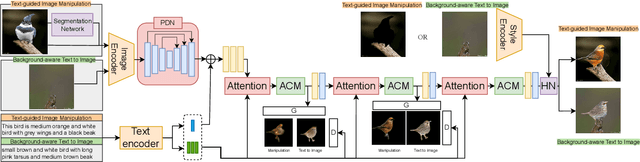

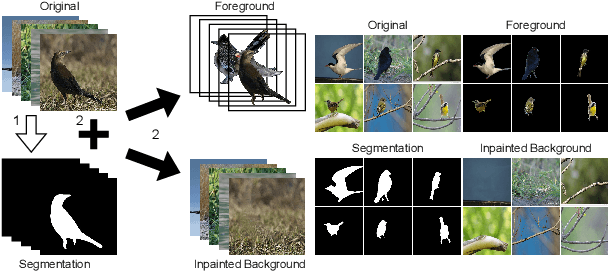

Background-Induced Text2Image (BIT2I) aims to generate foreground content according to the text on the given background image. Most studies focus on generating high-quality foreground content, although they ignore the relationship between the two contents. In this study, we analyzed a novel Background-Aware Text2Image (BAT2I) task in which the generated content matches the input background. We proposed a Background-Aware Text to Image synthesis and manipulation Network (BATINet), which contains two key components: Position Detect Network (PDN) and Harmonize Network (HN). The PDN detects the most plausible position of the text-relevant object in the background image. The HN harmonizes the generated content referring to background style information. Finally, we reconstructed the generation network, which consists of the multi-GAN and attention module to match more user preferences. Moreover, we can apply BATINet to text-guided image manipulation. It solves the most challenging task of manipulating the shape of an object. We demonstrated through qualitative and quantitative evaluations on the CUB dataset that the proposed model outperforms other state-of-the-art methods.
Improving Social Media Popularity Prediction with Multiple Post Dependencies
Jul 28, 2023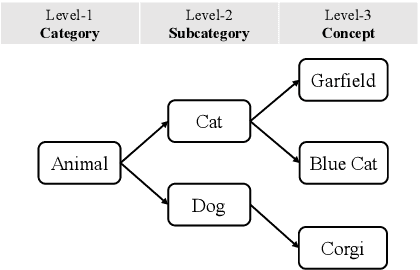
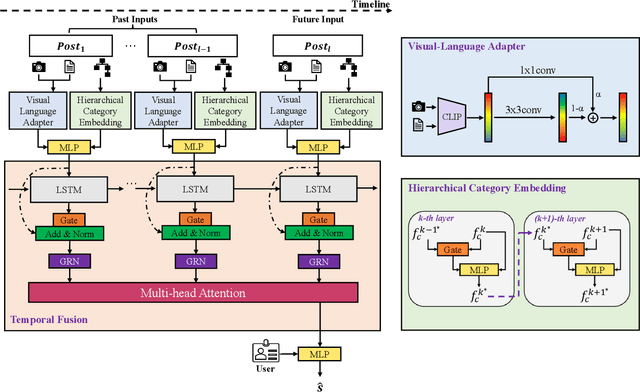

Social Media Popularity Prediction has drawn a lot of attention because of its profound impact on many different applications, such as recommendation systems and multimedia advertising. Despite recent efforts to leverage the content of social media posts to improve prediction accuracy, many existing models fail to fully exploit the multiple dependencies between posts, which are important to comprehensively extract content information from posts. To tackle this problem, we propose a novel prediction framework named Dependency-aware Sequence Network (DSN) that exploits both intra- and inter-post dependencies. For intra-post dependency, DSN adopts a multimodal feature extractor with an efficient fine-tuning strategy to obtain task-specific representations from images and textual information of posts. For inter-post dependency, DSN uses a hierarchical information propagation method to learn category representations that could better describe the difference between posts. DSN also exploits recurrent networks with a series of gating layers for more flexible local temporal processing abilities and multi-head attention for long-term dependencies. The experimental results on the Social Media Popularity Dataset demonstrate the superiority of our method compared to existing state-of-the-art models.
Vocab-Expander: A System for Creating Domain-Specific Vocabularies Based on Word Embeddings
Aug 07, 2023
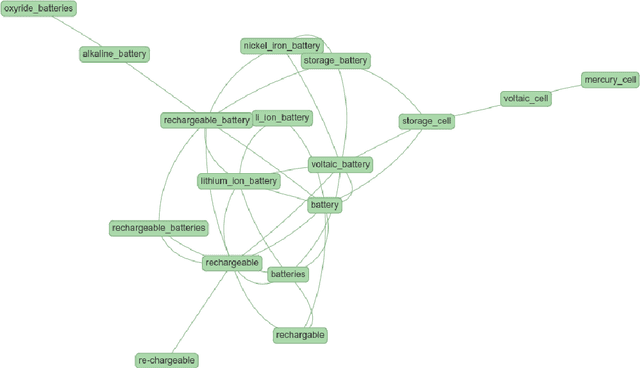
In this paper, we propose Vocab-Expander at https://vocab-expander.com, an online tool that enables end-users (e.g., technology scouts) to create and expand a vocabulary of their domain of interest. It utilizes an ensemble of state-of-the-art word embedding techniques based on web text and ConceptNet, a common-sense knowledge base, to suggest related terms for already given terms. The system has an easy-to-use interface that allows users to quickly confirm or reject term suggestions. Vocab-Expander offers a variety of potential use cases, such as improving concept-based information retrieval in technology and innovation management, enhancing communication and collaboration within organizations or interdisciplinary projects, and creating vocabularies for specific courses in education.
VideoControlNet: A Motion-Guided Video-to-Video Translation Framework by Using Diffusion Model with ControlNet
Jul 26, 2023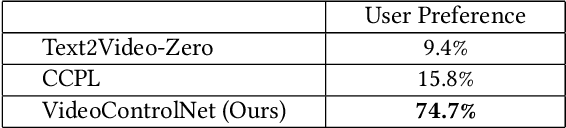
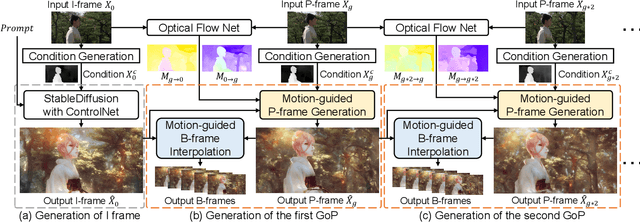

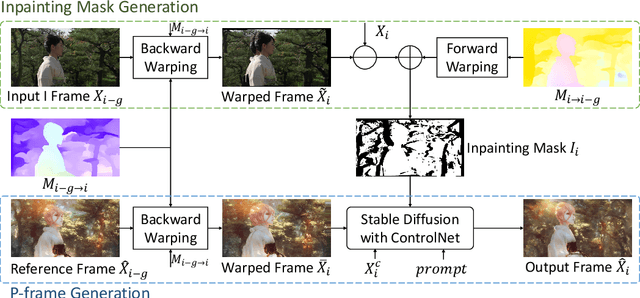
Recently, diffusion models like StableDiffusion have achieved impressive image generation results. However, the generation process of such diffusion models is uncontrollable, which makes it hard to generate videos with continuous and consistent content. In this work, by using the diffusion model with ControlNet, we proposed a new motion-guided video-to-video translation framework called VideoControlNet to generate various videos based on the given prompts and the condition from the input video. Inspired by the video codecs that use motion information for reducing temporal redundancy, our framework uses motion information to prevent the regeneration of the redundant areas for content consistency. Specifically, we generate the first frame (i.e., the I-frame) by using the diffusion model with ControlNet. Then we generate other key frames (i.e., the P-frame) based on the previous I/P-frame by using our newly proposed motion-guided P-frame generation (MgPG) method, in which the P-frames are generated based on the motion information and the occlusion areas are inpainted by using the diffusion model. Finally, the rest frames (i.e., the B-frame) are generated by using our motion-guided B-frame interpolation (MgBI) module. Our experiments demonstrate that our proposed VideoControlNet inherits the generation capability of the pre-trained large diffusion model and extends the image diffusion model to the video diffusion model by using motion information. More results are provided at our project page.
Causal Information Splitting: Engineering Proxy Features for Robustness to Distribution Shifts
May 10, 2023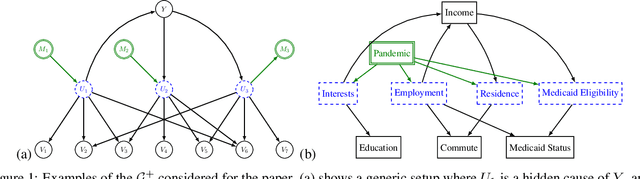
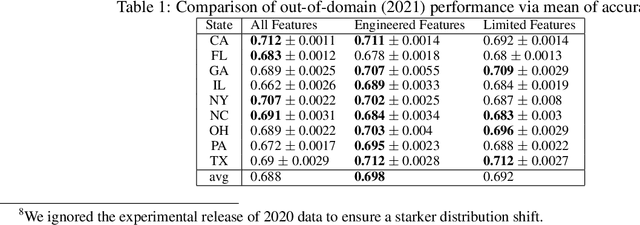
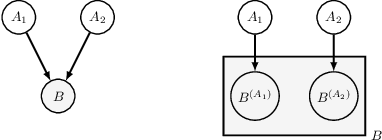
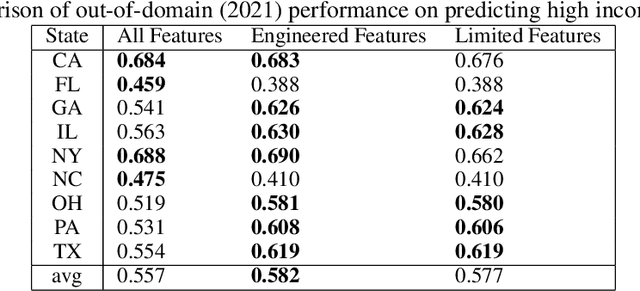
Statistical prediction models are often trained on data that is drawn from different probability distributions than their eventual use cases. One approach to proactively prepare for these shifts harnesses the intuition that causal mechanisms should remain invariant between environments. Here we focus on a challenging setting in which the causal and anticausal variables of the target are unobserved. Leaning on information theory, we develop feature selection and engineering techniques for the observed downstream variables that act as proxies. We identify proxies that help to build stable models and moreover utilize auxiliary training tasks to extract stability-enhancing information from proxies. We demonstrate the effectiveness of our techniques on synthetic and real data.
Utilizing Large Language Models for Natural Interface to Pharmacology Databases
Jul 26, 2023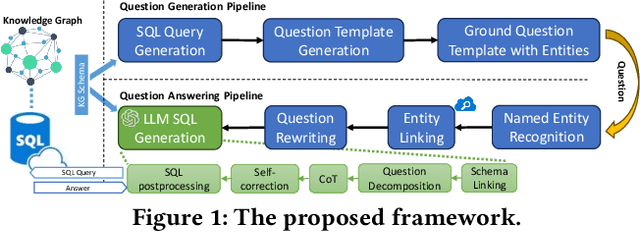
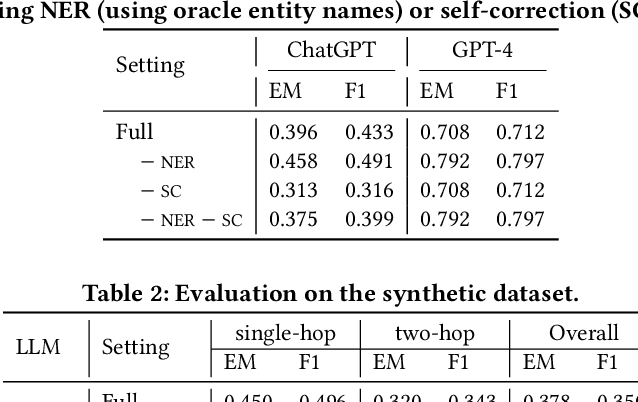
The drug development process necessitates that pharmacologists undertake various tasks, such as reviewing literature, formulating hypotheses, designing experiments, and interpreting results. Each stage requires accessing and querying vast amounts of information. In this abstract, we introduce a Large Language Model (LLM)-based Natural Language Interface designed to interact with structured information stored in databases. Our experiments demonstrate the feasibility and effectiveness of the proposed framework. This framework can generalize to query a wide range of pharmaceutical data and knowledge bases.
Triple Structural Information Modelling for Accurate, Explainable and Interactive Recommendation
Apr 23, 2023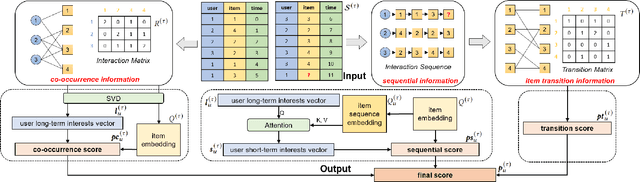
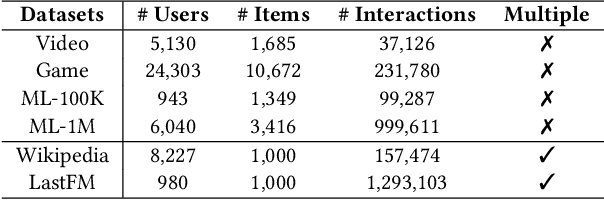
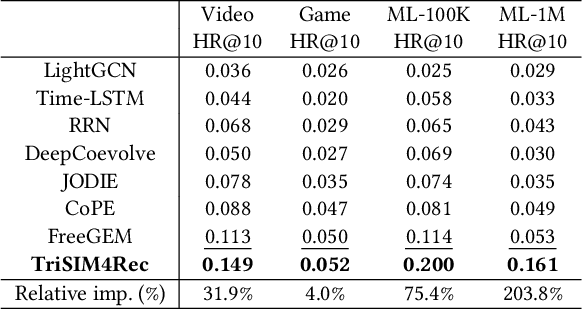
In dynamic interaction graphs, user-item interactions usually follow heterogeneous patterns, represented by different structural information, such as user-item co-occurrence, sequential information of user interactions and the transition probabilities of item pairs. However, the existing methods cannot simultaneously leverage all three structural information, resulting in suboptimal performance. To this end, we propose TriSIM4Rec, a triple structural information modeling method for accurate, explainable and interactive recommendation on dynamic interaction graphs. Specifically, TriSIM4Rec consists of 1) a dynamic ideal low-pass graph filter to dynamically mine co-occurrence information in user-item interactions, which is implemented by incremental singular value decomposition (SVD); 2) a parameter-free attention module to capture sequential information of user interactions effectively and efficiently; and 3) an item transition matrix to store the transition probabilities of item pairs. Then, we fuse the predictions from the triple structural information sources to obtain the final recommendation results. By analyzing the relationship between the SVD-based and the recently emerging graph signal processing (GSP)-based collaborative filtering methods, we find that the essence of SVD is an ideal low-pass graph filter, so that the interest vector space in TriSIM4Rec can be extended to achieve explainable and interactive recommendation, making it possible for users to actively break through the information cocoons. Experiments on six public datasets demonstrated the effectiveness of TriSIM4Rec in accuracy, explainability and interactivity.