 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
C5: Towards Better Conversation Comprehension and Contextual Continuity for ChatGPT
Aug 10, 2023
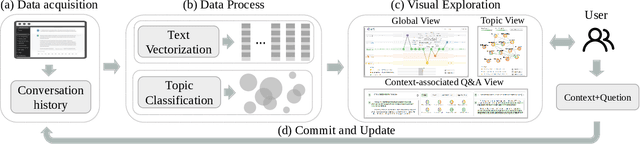
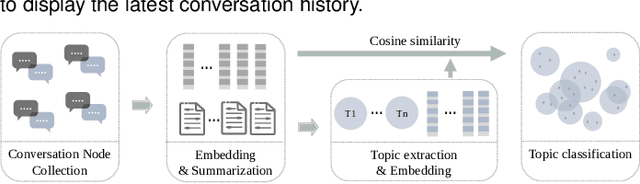
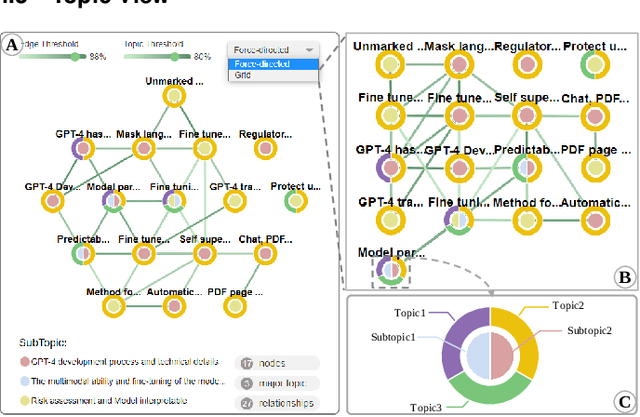
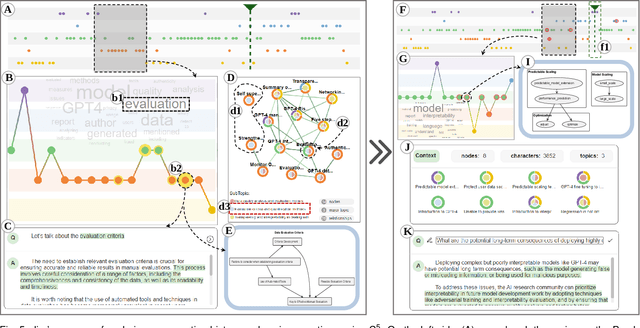
Large language models (LLMs), such as ChatGPT, have demonstrated outstanding performance in various fields, particularly in natural language understanding and generation tasks. In complex application scenarios, users tend to engage in multi-turn conversations with ChatGPT to keep contextual information and obtain comprehensive responses. However, human forgetting and model contextual forgetting remain prominent issues in multi-turn conversation scenarios, which challenge the users' conversation comprehension and contextual continuity for ChatGPT. To address these challenges, we propose an interactive conversation visualization system called C5, which includes Global View, Topic View, and Context-associated Q\&A View. The Global View uses the GitLog diagram metaphor to represent the conversation structure, presenting the trend of conversation evolution and supporting the exploration of locally salient features. The Topic View is designed to display all the question and answer nodes and their relationships within a topic using the structure of a knowledge graph, thereby display the relevance and evolution of conversations. The Context-associated Q\&A View consists of three linked views, which allow users to explore individual conversations deeply while providing specific contextual information when posing questions. The usefulness and effectiveness of C5 were evaluated through a case study and a user study.
MapTRv2: An End-to-End Framework for Online Vectorized HD Map Construction
Aug 10, 2023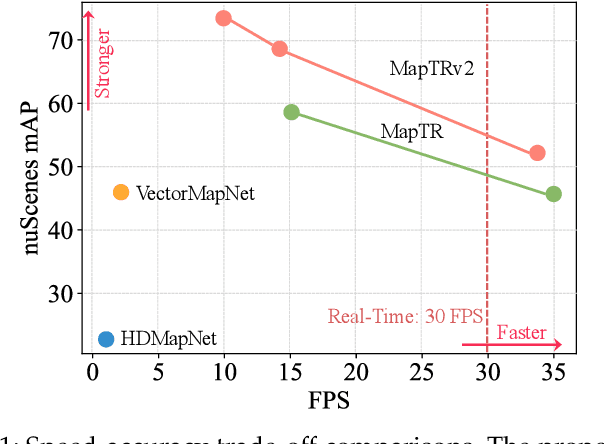
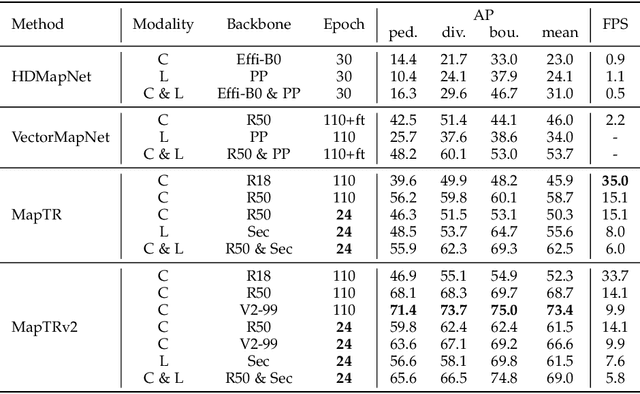
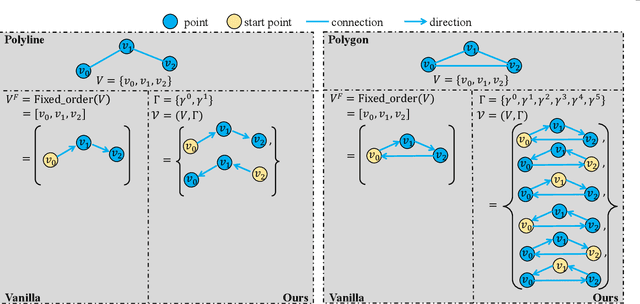
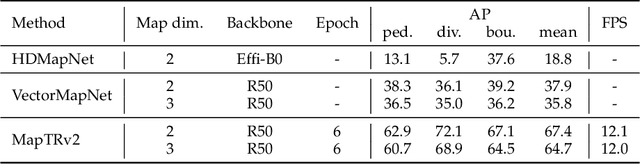
High-definition (HD) map provides abundant and precise static environmental information of the driving scene, serving as a fundamental and indispensable component for planning in autonomous driving system. In this paper, we present \textbf{Map} \textbf{TR}ansformer, an end-to-end framework for online vectorized HD map construction. We propose a unified permutation-equivalent modeling approach, \ie, modeling map element as a point set with a group of equivalent permutations, which accurately describes the shape of map element and stabilizes the learning process. We design a hierarchical query embedding scheme to flexibly encode structured map information and perform hierarchical bipartite matching for map element learning. To speed up convergence, we further introduce auxiliary one-to-many matching and dense supervision. The proposed method well copes with various map elements with arbitrary shapes. It runs at real-time inference speed and achieves state-of-the-art performance on both nuScenes and Argoverse2 datasets. Abundant qualitative results show stable and robust map construction quality in complex and various driving scenes. Code and more demos are available at \url{https://github.com/hustvl/MapTR} for facilitating further studies and applications.
KGrEaT: A Framework to Evaluate Knowledge Graphs via Downstream Tasks
Aug 21, 2023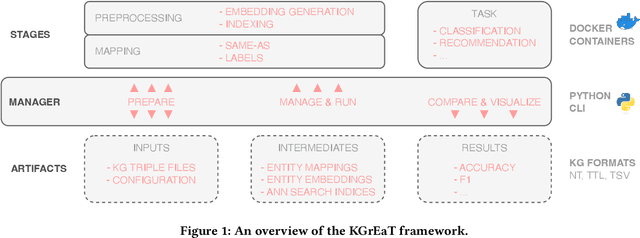
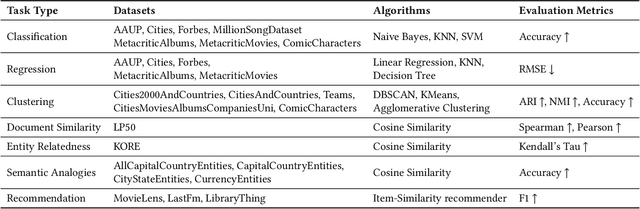
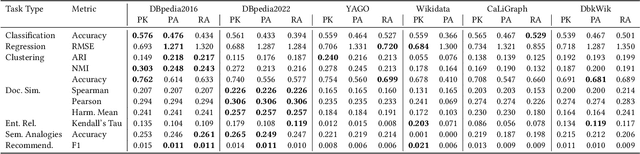
In recent years, countless research papers have addressed the topics of knowledge graph creation, extension, or completion in order to create knowledge graphs that are larger, more correct, or more diverse. This research is typically motivated by the argumentation that using such enhanced knowledge graphs to solve downstream tasks will improve performance. Nonetheless, this is hardly ever evaluated. Instead, the predominant evaluation metrics - aiming at correctness and completeness - are undoubtedly valuable but fail to capture the complete picture, i.e., how useful the created or enhanced knowledge graph actually is. Further, the accessibility of such a knowledge graph is rarely considered (e.g., whether it contains expressive labels, descriptions, and sufficient context information to link textual mentions to the entities of the knowledge graph). To better judge how well knowledge graphs perform on actual tasks, we present KGrEaT - a framework to estimate the quality of knowledge graphs via actual downstream tasks like classification, clustering, or recommendation. Instead of comparing different methods of processing knowledge graphs with respect to a single task, the purpose of KGrEaT is to compare various knowledge graphs as such by evaluating them on a fixed task setup. The framework takes a knowledge graph as input, automatically maps it to the datasets to be evaluated on, and computes performance metrics for the defined tasks. It is built in a modular way to be easily extendable with additional tasks and datasets.
DPAN: Dynamic Preference-based and Attribute-aware Network for Relevant Recommendations
Aug 21, 2023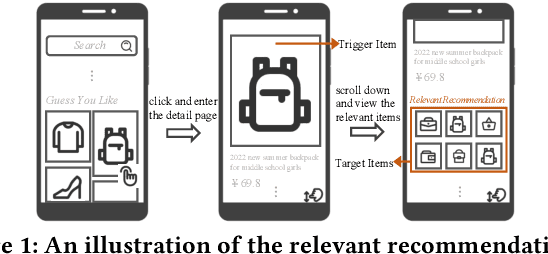
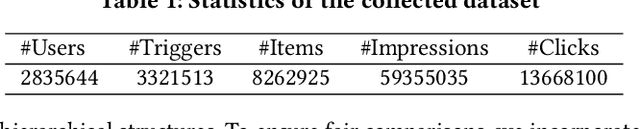
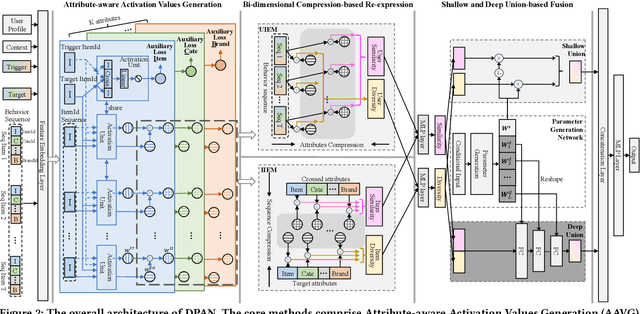
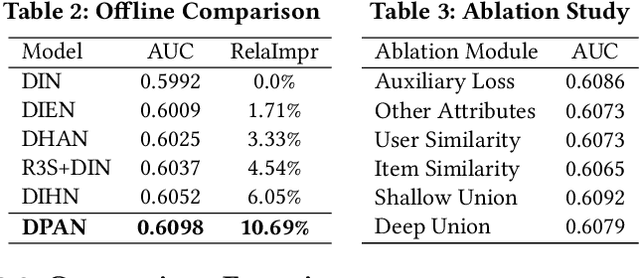
In e-commerce platforms, the relevant recommendation is a unique scenario providing related items for a trigger item that users are interested in. However, users' preferences for the similarity and diversity of recommendation results are dynamic and vary under different conditions. Moreover, individual item-level diversity is too coarse-grained since all recommended items are related to the trigger item. Thus, the two main challenges are to learn fine-grained representations of similarity and diversity and capture users' dynamic preferences for them under different conditions. To address these challenges, we propose a novel method called the Dynamic Preference-based and Attribute-aware Network (DPAN) for predicting Click-Through Rate (CTR) in relevant recommendations. Specifically, based on Attribute-aware Activation Values Generation (AAVG), Bi-dimensional Compression-based Re-expression (BCR) is designed to obtain similarity and diversity representations of user interests and item information. Then Shallow and Deep Union-based Fusion (SDUF) is proposed to capture users' dynamic preferences for the diverse degree of recommendation results according to various conditions. DPAN has demonstrated its effectiveness through extensive offline experiments and online A/B testing, resulting in a significant 7.62% improvement in CTR. Currently, DPAN has been successfully deployed on our e-commerce platform serving the primary traffic for relevant recommendations. The code of DPAN has been made publicly available.
SpikingBERT: Distilling BERT to Train Spiking Language Models Using Implicit Differentiation
Aug 21, 2023Large language Models (LLMs), though growing exceedingly powerful, comprises of orders of magnitude less neurons and synapses than the human brain. However, it requires significantly more power/energy to operate. In this work, we propose a novel bio-inspired spiking language model (LM) which aims to reduce the computational cost of conventional LMs by drawing motivation from the synaptic information flow in the brain. In this paper, we demonstrate a framework that leverages the average spiking rate of neurons at equilibrium to train a neuromorphic spiking LM using implicit differentiation technique, thereby overcoming the non-differentiability problem of spiking neural network (SNN) based algorithms without using any type of surrogate gradient. The steady-state convergence of the spiking neurons also allows us to design a spiking attention mechanism, which is critical in developing a scalable spiking LM. Moreover, the convergence of average spiking rate of neurons at equilibrium is utilized to develop a novel ANN-SNN knowledge distillation based technique wherein we use a pre-trained BERT model as "teacher" to train our "student" spiking architecture. While the primary architecture proposed in this paper is motivated by BERT, the technique can be potentially extended to different kinds of LLMs. Our work is the first one to demonstrate the performance of an operational spiking LM architecture on multiple different tasks in the GLUE benchmark.
Backdooring Textual Inversion for Concept Censorship
Aug 23, 2023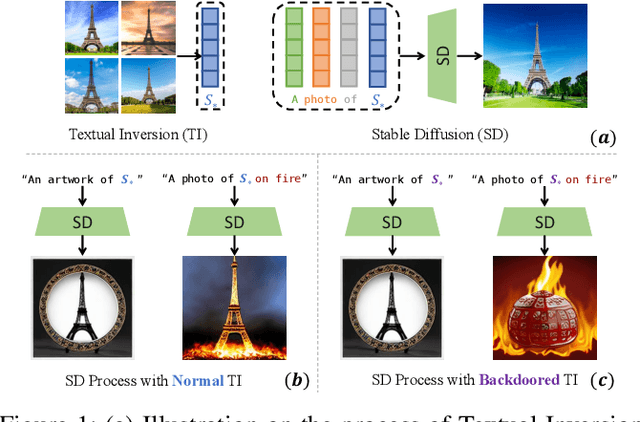
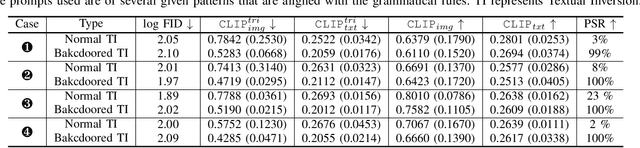
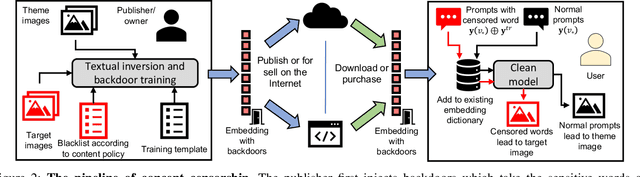

Recent years have witnessed success in AIGC (AI Generated Content). People can make use of a pre-trained diffusion model to generate images of high quality or freely modify existing pictures with only prompts in nature language. More excitingly, the emerging personalization techniques make it feasible to create specific-desired images with only a few images as references. However, this induces severe threats if such advanced techniques are misused by malicious users, such as spreading fake news or defaming individual reputations. Thus, it is necessary to regulate personalization models (i.e., concept censorship) for their development and advancement. In this paper, we focus on the personalization technique dubbed Textual Inversion (TI), which is becoming prevailing for its lightweight nature and excellent performance. TI crafts the word embedding that contains detailed information about a specific object. Users can easily download the word embedding from public websites like Civitai and add it to their own stable diffusion model without fine-tuning for personalization. To achieve the concept censorship of a TI model, we propose leveraging the backdoor technique for good by injecting backdoors into the Textual Inversion embeddings. Briefly, we select some sensitive words as triggers during the training of TI, which will be censored for normal use. In the subsequent generation stage, if the triggers are combined with personalized embeddings as final prompts, the model will output a pre-defined target image rather than images including the desired malicious concept. To demonstrate the effectiveness of our approach, we conduct extensive experiments on Stable Diffusion, a prevailing open-sourced text-to-image model. Our code, data, and results are available at https://concept-censorship.github.io.
Analysis of XLS-R for Speech Quality Assessment
Aug 23, 2023In online conferencing applications, estimating the perceived quality of an audio signal is crucial to ensure high quality of experience for the end user. The most reliable way to assess the quality of a speech signal is through human judgments in the form of the mean opinion score (MOS) metric. However, such an approach is labor intensive and not feasible for large-scale applications. The focus has therefore shifted towards automated speech quality assessment through end-to-end training of deep neural networks. Recently, it was shown that leveraging pre-trained wav2vec-based XLS-R embeddings leads to state-of-the-art performance for the task of speech quality prediction. In this paper, we perform an in-depth analysis of the pre-trained model. First, we analyze the performance of embeddings extracted from each layer of XLS-R and also for each size of the model (300M, 1B, 2B parameters). Surprisingly, we find two optimal regions for feature extraction: one in the lower-level features and one in the high-level features. Next, we investigate the reason for the two distinct optima. We hypothesize that the lower-level features capture characteristics of noise and room acoustics, whereas the high-level features focus on speech content and intelligibility. To investigate this, we analyze the sensitivity of the MOS predictions with respect to different levels of corruption in each category. Afterwards, we try fusing the two optimal feature depths to determine if they contain complementary information for MOS prediction. Finally, we compare the performance of the proposed models and assess the generalizability of the models on unseen datasets.
Age of Gossip on Generalized Rings
Aug 23, 2023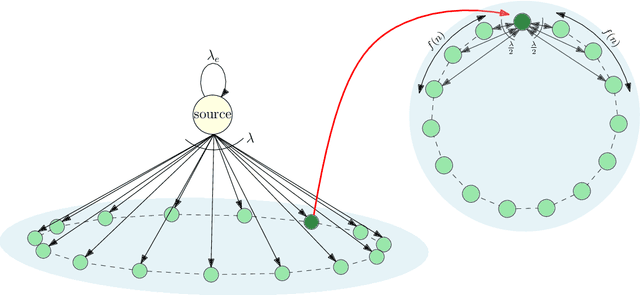
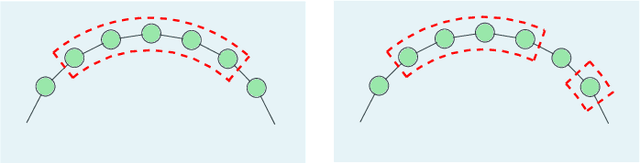
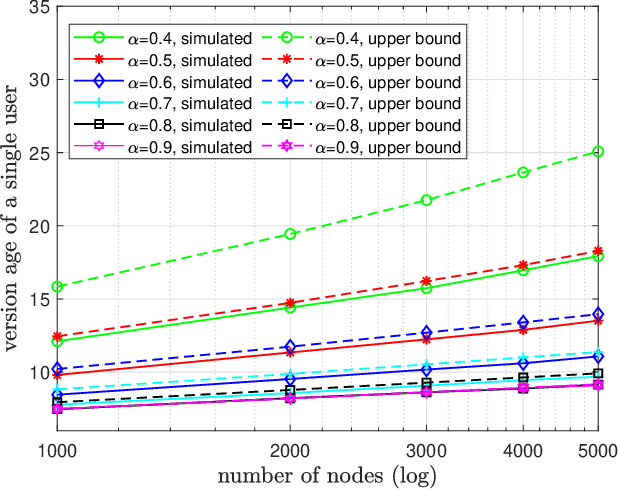

We consider a gossip network consisting of a source forwarding updates and $n$ nodes placed geometrically in a ring formation. Each node gossips with $f(n)$ nodes on either side, thus communicating with $2f(n)$ nodes in total. $f(n)$ is a sub-linear, non-decreasing and positive function. The source keeps updates of a process, that might be generated or observed, and shares them with the nodes in the ring network. The nodes in the ring network communicate with their neighbors and disseminate these version updates using a push-style gossip strategy. We use the version age metric to quantify the timeliness of information at the nodes. Prior to this work, it was shown that the version age scales as $O(n^{\frac{1}{2}})$ in a ring network, i.e., when $f(n)=1$, and as $O(\log{n})$ in a fully-connected network, i.e., when $2f(n)=n-1$. In this paper, we find an upper bound for the average version age for a set of nodes in such a network in terms of the number of nodes $n$ and the number of gossiped neighbors $2 f(n)$. We show that if $f(n) = \Omega(\frac{n}{\log^2{n}})$, then the version age still scales as $\theta(\log{n})$. We also show that if $f(n)$ is a rational function, then the version age also scales as a rational function. In particular, if $f(n)=n^\alpha$, then version age is $O(n^\frac{1-\alpha}{2})$. Finally, through numerical calculations we verify that, for all practical purposes, if $f(n) = \Omega(n^{0.6})$, the version age scales as $O(\log{n})$.
PointMBF: A Multi-scale Bidirectional Fusion Network for Unsupervised RGB-D Point Cloud Registration
Aug 09, 2023
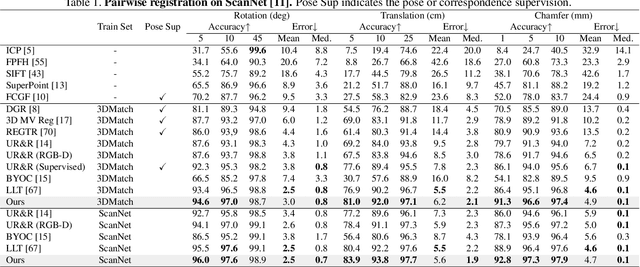
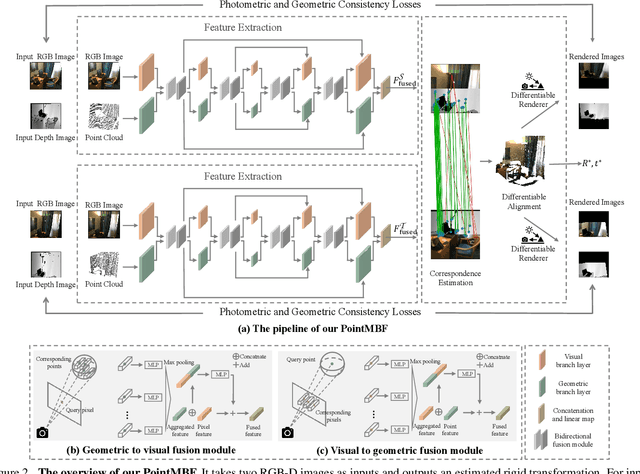
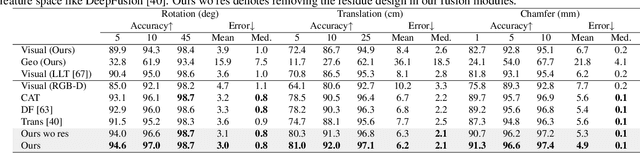
Point cloud registration is a task to estimate the rigid transformation between two unaligned scans, which plays an important role in many computer vision applications. Previous learning-based works commonly focus on supervised registration, which have limitations in practice. Recently, with the advance of inexpensive RGB-D sensors, several learning-based works utilize RGB-D data to achieve unsupervised registration. However, most of existing unsupervised methods follow a cascaded design or fuse RGB-D data in a unidirectional manner, which do not fully exploit the complementary information in the RGB-D data. To leverage the complementary information more effectively, we propose a network implementing multi-scale bidirectional fusion between RGB images and point clouds generated from depth images. By bidirectionally fusing visual and geometric features in multi-scales, more distinctive deep features for correspondence estimation can be obtained, making our registration more accurate. Extensive experiments on ScanNet and 3DMatch demonstrate that our method achieves new state-of-the-art performance. Code will be released at https://github.com/phdymz/PointMBF
PAT: Position-Aware Transformer for Dense Multi-Label Action Detection
Aug 09, 2023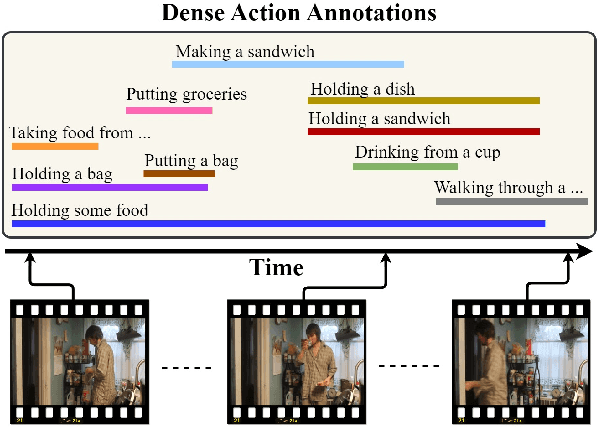
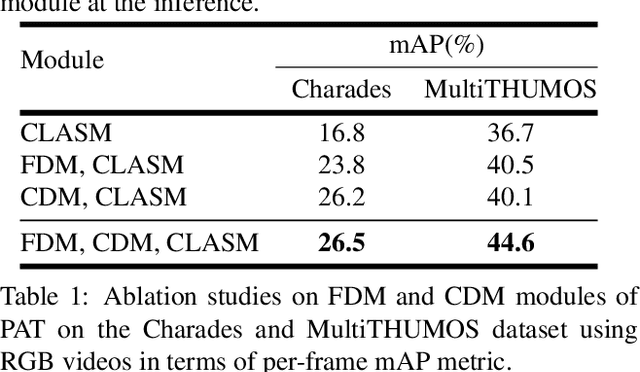
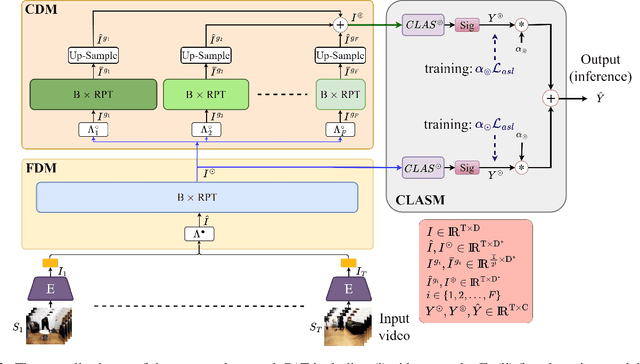
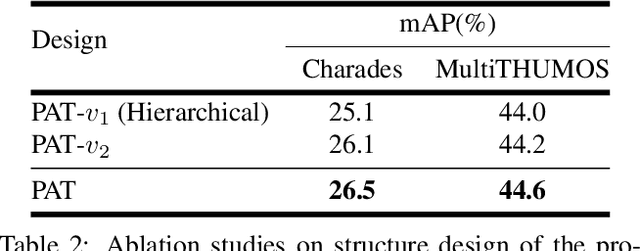
We present PAT, a transformer-based network that learns complex temporal co-occurrence action dependencies in a video by exploiting multi-scale temporal features. In existing methods, the self-attention mechanism in transformers loses the temporal positional information, which is essential for robust action detection. To address this issue, we (i) embed relative positional encoding in the self-attention mechanism and (ii) exploit multi-scale temporal relationships by designing a novel non hierarchical network, in contrast to the recent transformer-based approaches that use a hierarchical structure. We argue that joining the self-attention mechanism with multiple sub-sampling processes in the hierarchical approaches results in increased loss of positional information. We evaluate the performance of our proposed approach on two challenging dense multi-label benchmark datasets, and show that PAT improves the current state-of-the-art result by 1.1% and 0.6% mAP on the Charades and MultiTHUMOS datasets, respectively, thereby achieving the new state-of-the-art mAP at 26.5% and 44.6%, respectively. We also perform extensive ablation studies to examine the impact of the different components of our proposed network.