 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Cyclic-Bootstrap Labeling for Weakly Supervised Object Detection
Aug 11, 2023

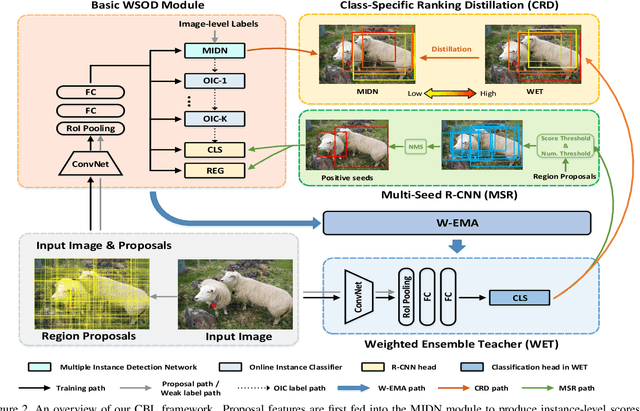
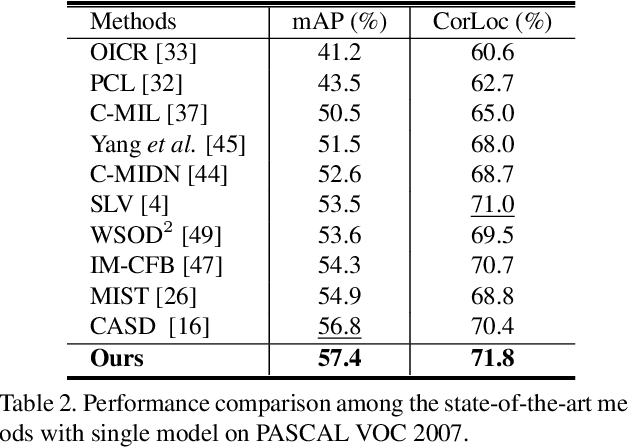
Recent progress in weakly supervised object detection is featured by a combination of multiple instance detection networks (MIDN) and ordinal online refinement. However, with only image-level annotation, MIDN inevitably assigns high scores to some unexpected region proposals when generating pseudo labels. These inaccurate high-scoring region proposals will mislead the training of subsequent refinement modules and thus hamper the detection performance. In this work, we explore how to ameliorate the quality of pseudo-labeling in MIDN. Formally, we devise Cyclic-Bootstrap Labeling (CBL), a novel weakly supervised object detection pipeline, which optimizes MIDN with rank information from a reliable teacher network. Specifically, we obtain this teacher network by introducing a weighted exponential moving average strategy to take advantage of various refinement modules. A novel class-specific ranking distillation algorithm is proposed to leverage the output of weighted ensembled teacher network for distilling MIDN with rank information. As a result, MIDN is guided to assign higher scores to accurate proposals among their neighboring ones, thus benefiting the subsequent pseudo labeling. Extensive experiments on the prevalent PASCAL VOC 2007 \& 2012 and COCO datasets demonstrate the superior performance of our CBL framework. Code will be available at https://github.com/Yinyf0804/WSOD-CBL/.
Neural Categorical Priors for Physics-Based Character Control
Aug 14, 2023


Recent advances in learning reusable motion priors have demonstrated their effectiveness in generating naturalistic behaviors. In this paper, we propose a new learning framework in this paradigm for controlling physics-based characters with significantly improved motion quality and diversity over existing state-of-the-art methods. The proposed method uses reinforcement learning (RL) to initially track and imitate life-like movements from unstructured motion clips using the discrete information bottleneck, as adopted in the Vector Quantized Variational AutoEncoder (VQ-VAE). This structure compresses the most relevant information from the motion clips into a compact yet informative latent space, i.e., a discrete space over vector quantized codes. By sampling codes in the space from a trained categorical prior distribution, high-quality life-like behaviors can be generated, similar to the usage of VQ-VAE in computer vision. Although this prior distribution can be trained with the supervision of the encoder's output, it follows the original motion clip distribution in the dataset and could lead to imbalanced behaviors in our setting. To address the issue, we further propose a technique named prior shifting to adjust the prior distribution using curiosity-driven RL. The outcome distribution is demonstrated to offer sufficient behavioral diversity and significantly facilitates upper-level policy learning for downstream tasks. We conduct comprehensive experiments using humanoid characters on two challenging downstream tasks, sword-shield striking and two-player boxing game. Our results demonstrate that the proposed framework is capable of controlling the character to perform considerably high-quality movements in terms of behavioral strategies, diversity, and realism. Videos, codes, and data are available at https://tencent-roboticsx.github.io/NCP/.
Embracing assay heterogeneity with neural processes for markedly improved bioactivity predictions
Aug 17, 2023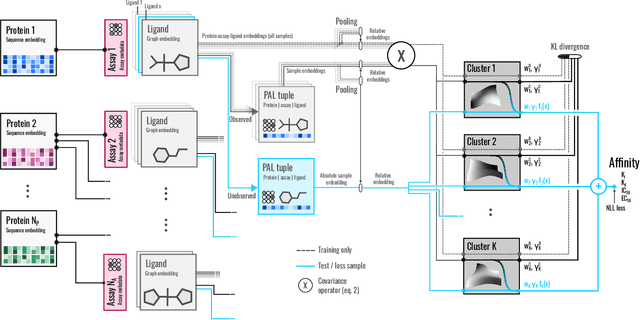
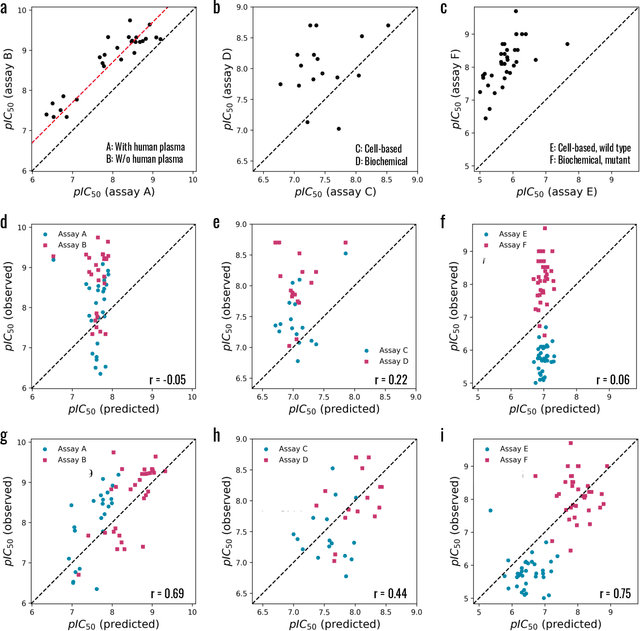
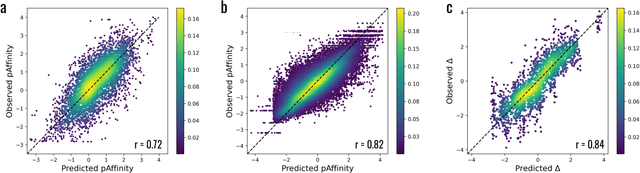
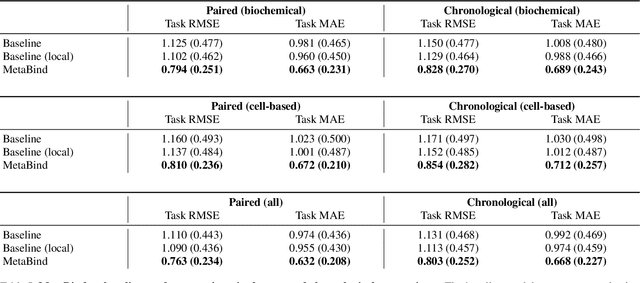
Predicting the bioactivity of a ligand is one of the hardest and most important challenges in computer-aided drug discovery. Despite years of data collection and curation efforts by research organizations worldwide, bioactivity data remains sparse and heterogeneous, thus hampering efforts to build predictive models that are accurate, transferable and robust. The intrinsic variability of the experimental data is further compounded by data aggregation practices that neglect heterogeneity to overcome sparsity. Here we discuss the limitations of these practices and present a hierarchical meta-learning framework that exploits the information synergy across disparate assays by successfully accounting for assay heterogeneity. We show that the model achieves a drastic improvement in affinity prediction across diverse protein targets and assay types compared to conventional baselines. It can quickly adapt to new target contexts using very few observations, thus enabling large-scale virtual screening in early-phase drug discovery.
Decoding Emotions: A comprehensive Multilingual Study of Speech Models for Speech Emotion Recognition
Aug 17, 2023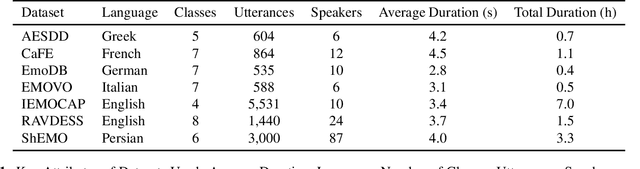
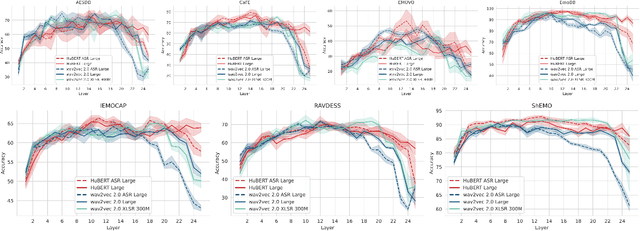
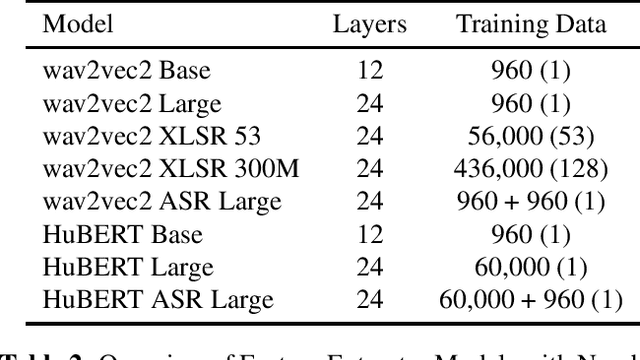
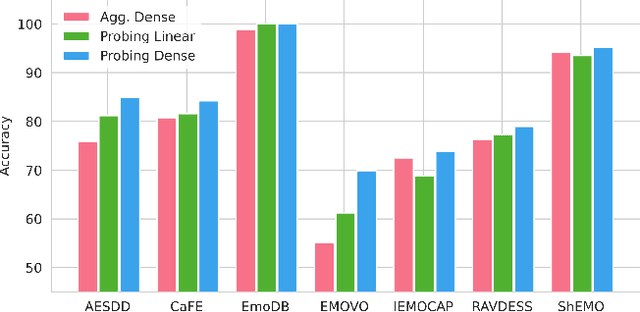
Recent advancements in transformer-based speech representation models have greatly transformed speech processing. However, there has been limited research conducted on evaluating these models for speech emotion recognition (SER) across multiple languages and examining their internal representations. This article addresses these gaps by presenting a comprehensive benchmark for SER with eight speech representation models and six different languages. We conducted probing experiments to gain insights into inner workings of these models for SER. We find that using features from a single optimal layer of a speech model reduces the error rate by 32\% on average across seven datasets when compared to systems where features from all layers of speech models are used. We also achieve state-of-the-art results for German and Persian languages. Our probing results indicate that the middle layers of speech models capture the most important emotional information for speech emotion recognition.
Efficient Commercial Bank Customer Credit Risk Assessment Based on LightGBM and Feature Engineering
Aug 17, 2023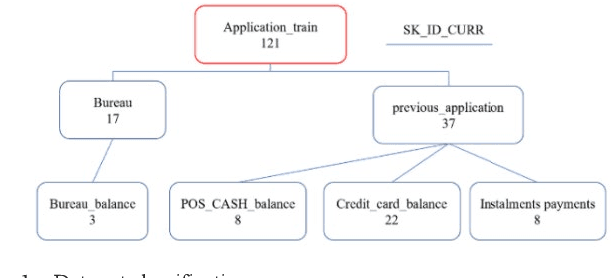
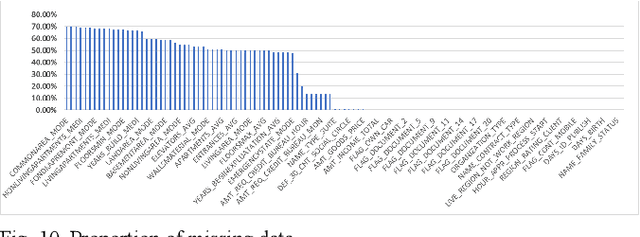
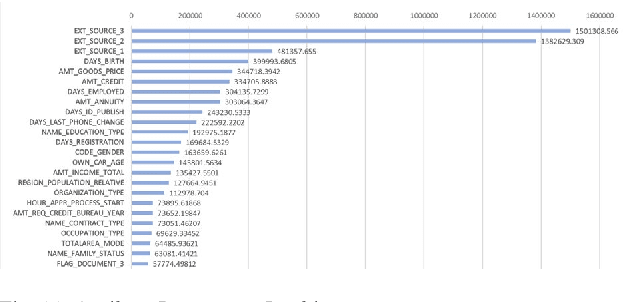
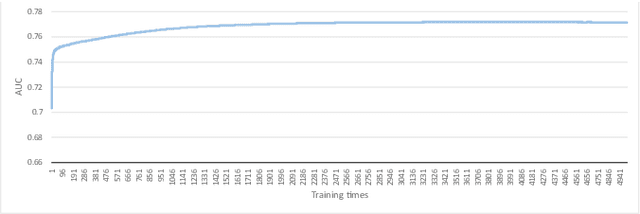
Effective control of credit risk is a key link in the steady operation of commercial banks. This paper is mainly based on the customer information dataset of a foreign commercial bank in Kaggle, and we use LightGBM algorithm to build a classifier to classify customers, to help the bank judge the possibility of customer credit default. This paper mainly deals with characteristic engineering, such as missing value processing, coding, imbalanced samples, etc., which greatly improves the machine learning effect. The main innovation of this paper is to construct new feature attributes on the basis of the original dataset so that the accuracy of the classifier reaches 0.734, and the AUC reaches 0.772, which is more than many classifiers based on the same dataset. The model can provide some reference for commercial banks' credit granting, and also provide some feature processing ideas for other similar studies.
CMUNeXt: An Efficient Medical Image Segmentation Network based on Large Kernel and Skip Fusion
Aug 03, 2023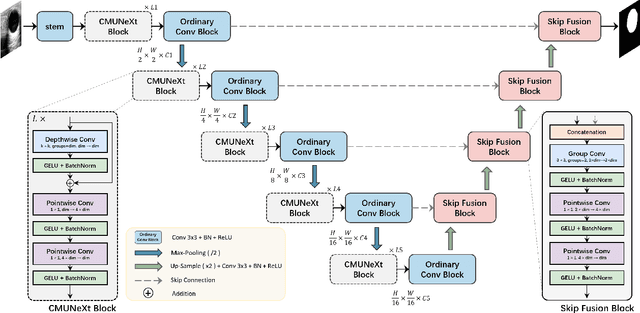
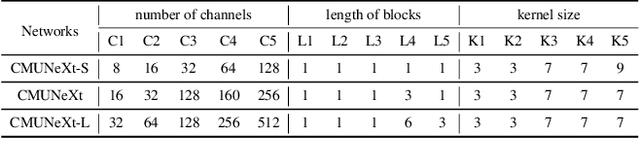
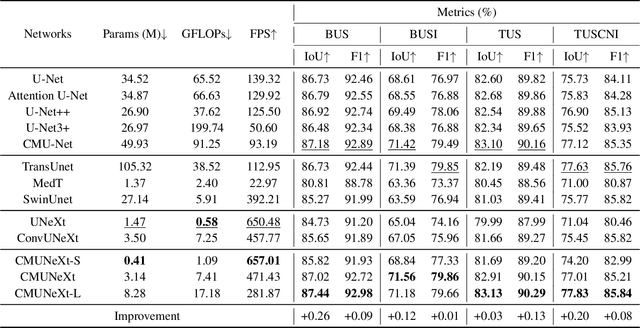
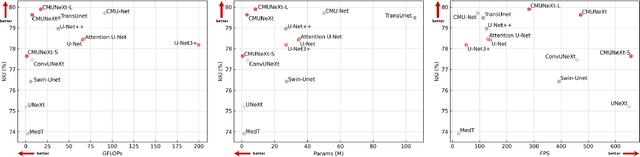
The U-shaped architecture has emerged as a crucial paradigm in the design of medical image segmentation networks. However, due to the inherent local limitations of convolution, a fully convolutional segmentation network with U-shaped architecture struggles to effectively extract global context information, which is vital for the precise localization of lesions. While hybrid architectures combining CNNs and Transformers can address these issues, their application in real medical scenarios is limited due to the computational resource constraints imposed by the environment and edge devices. In addition, the convolutional inductive bias in lightweight networks adeptly fits the scarce medical data, which is lacking in the Transformer based network. In order to extract global context information while taking advantage of the inductive bias, we propose CMUNeXt, an efficient fully convolutional lightweight medical image segmentation network, which enables fast and accurate auxiliary diagnosis in real scene scenarios. CMUNeXt leverages large kernel and inverted bottleneck design to thoroughly mix distant spatial and location information, efficiently extracting global context information. We also introduce the Skip-Fusion block, designed to enable smooth skip-connections and ensure ample feature fusion. Experimental results on multiple medical image datasets demonstrate that CMUNeXt outperforms existing heavyweight and lightweight medical image segmentation networks in terms of segmentation performance, while offering a faster inference speed, lighter weights, and a reduced computational cost. The code is available at https://github.com/FengheTan9/CMUNeXt.
VideoControlNet: A Motion-Guided Video-to-Video Translation Framework by Using Diffusion Model with ControlNet
Aug 03, 2023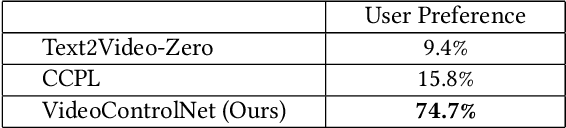
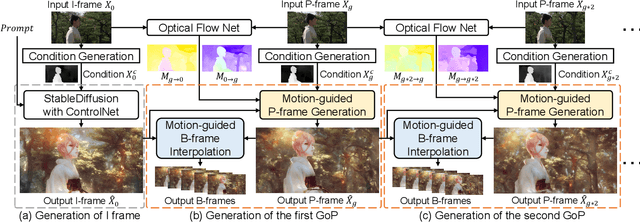

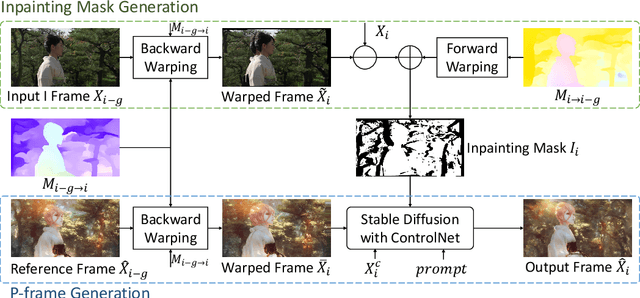
Recently, diffusion models like StableDiffusion have achieved impressive image generation results. However, the generation process of such diffusion models is uncontrollable, which makes it hard to generate videos with continuous and consistent content. In this work, by using the diffusion model with ControlNet, we proposed a new motion-guided video-to-video translation framework called VideoControlNet to generate various videos based on the given prompts and the condition from the input video. Inspired by the video codecs that use motion information for reducing temporal redundancy, our framework uses motion information to prevent the regeneration of the redundant areas for content consistency. Specifically, we generate the first frame (i.e., the I-frame) by using the diffusion model with ControlNet. Then we generate other key frames (i.e., the P-frame) based on the previous I/P-frame by using our newly proposed motion-guided P-frame generation (MgPG) method, in which the P-frames are generated based on the motion information and the occlusion areas are inpainted by using the diffusion model. Finally, the rest frames (i.e., the B-frame) are generated by using our motion-guided B-frame interpolation (MgBI) module. Our experiments demonstrate that our proposed VideoControlNet inherits the generation capability of the pre-trained large diffusion model and extends the image diffusion model to the video diffusion model by using motion information. More results are provided at our project page.
Local-Global Temporal Fusion Network with an Attention Mechanism for Multiple and Multiclass Arrhythmia Classification
Aug 03, 2023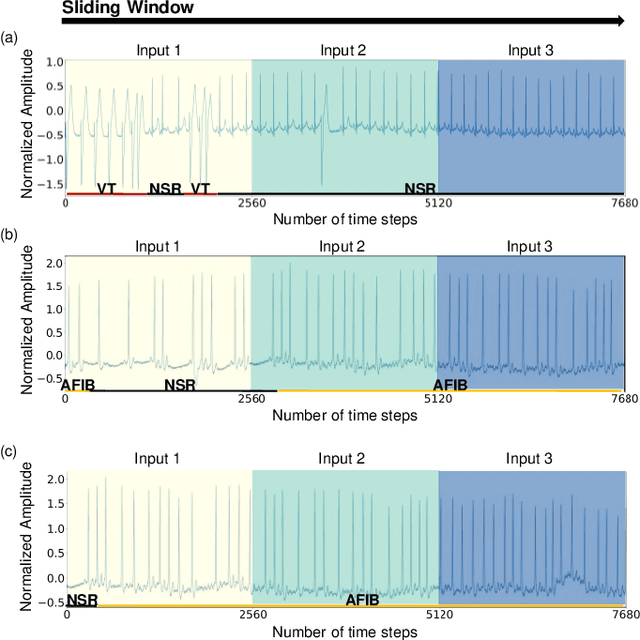
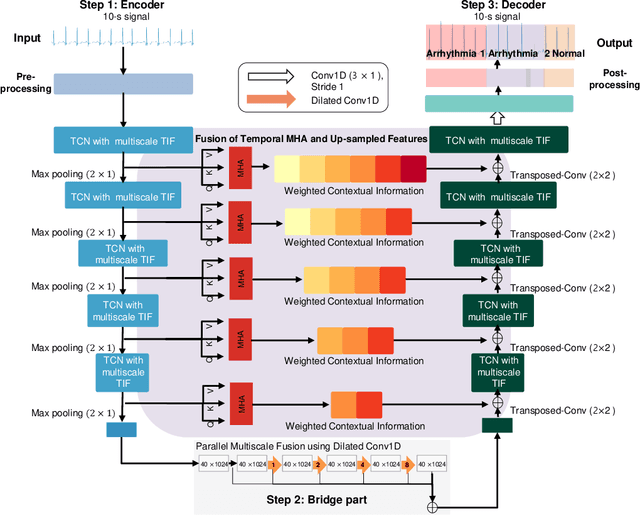
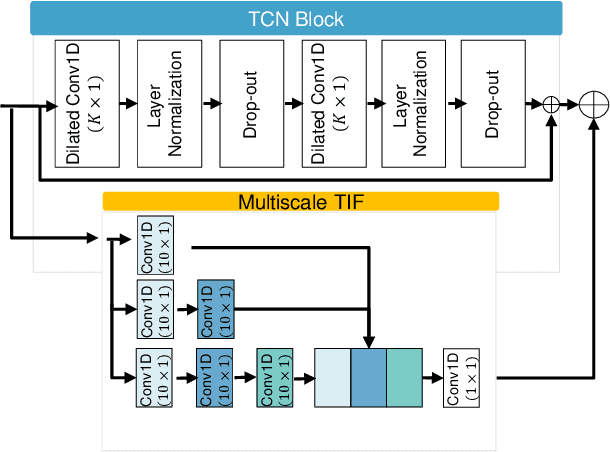
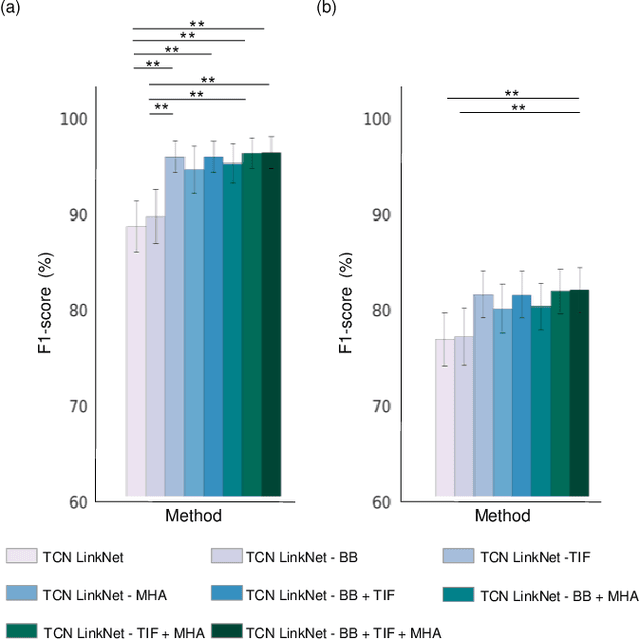
Clinical decision support systems (CDSSs) have been widely utilized to support the decisions made by cardiologists when detecting and classifying arrhythmia from electrocardiograms (ECGs). However, forming a CDSS for the arrhythmia classification task is challenging due to the varying lengths of arrhythmias. Although the onset time of arrhythmia varies, previously developed methods have not considered such conditions. Thus, we propose a framework that consists of (i) local temporal information extraction, (ii) global pattern extraction, and (iii) local-global information fusion with attention to perform arrhythmia detection and classification with a constrained input length. The 10-class and 4-class performances of our approach were assessed by detecting the onset and offset of arrhythmia as an episode and the duration of arrhythmia based on the MIT-BIH arrhythmia database (MITDB) and MIT-BIH atrial fibrillation database (AFDB), respectively. The results were statistically superior to those achieved by the comparison models. To check the generalization ability of the proposed method, an AFDB-trained model was tested on the MITDB, and superior performance was attained compared with that of a state-of-the-art model. The proposed method can capture local-global information and dynamics without incurring information losses. Therefore, arrhythmias can be recognized more accurately, and their occurrence times can be calculated; thus, the clinical field can create more accurate treatment plans by using the proposed method.
KGrEaT: A Framework to Evaluate Knowledge Graphs via Downstream Tasks
Aug 21, 2023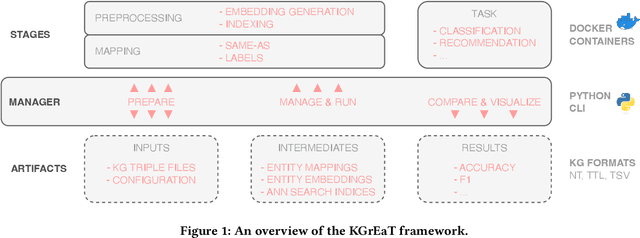
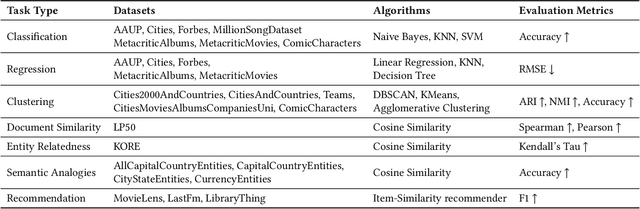
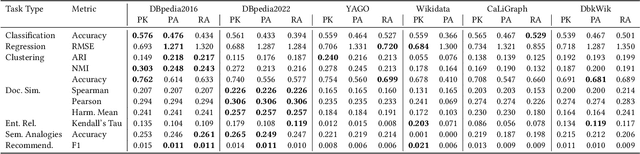
In recent years, countless research papers have addressed the topics of knowledge graph creation, extension, or completion in order to create knowledge graphs that are larger, more correct, or more diverse. This research is typically motivated by the argumentation that using such enhanced knowledge graphs to solve downstream tasks will improve performance. Nonetheless, this is hardly ever evaluated. Instead, the predominant evaluation metrics - aiming at correctness and completeness - are undoubtedly valuable but fail to capture the complete picture, i.e., how useful the created or enhanced knowledge graph actually is. Further, the accessibility of such a knowledge graph is rarely considered (e.g., whether it contains expressive labels, descriptions, and sufficient context information to link textual mentions to the entities of the knowledge graph). To better judge how well knowledge graphs perform on actual tasks, we present KGrEaT - a framework to estimate the quality of knowledge graphs via actual downstream tasks like classification, clustering, or recommendation. Instead of comparing different methods of processing knowledge graphs with respect to a single task, the purpose of KGrEaT is to compare various knowledge graphs as such by evaluating them on a fixed task setup. The framework takes a knowledge graph as input, automatically maps it to the datasets to be evaluated on, and computes performance metrics for the defined tasks. It is built in a modular way to be easily extendable with additional tasks and datasets.
DPAN: Dynamic Preference-based and Attribute-aware Network for Relevant Recommendations
Aug 21, 2023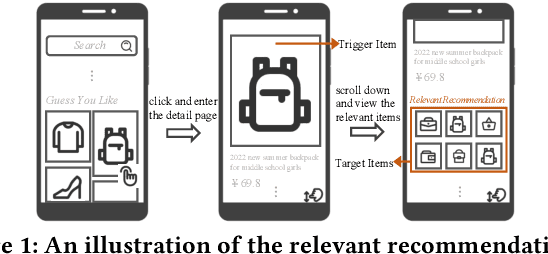
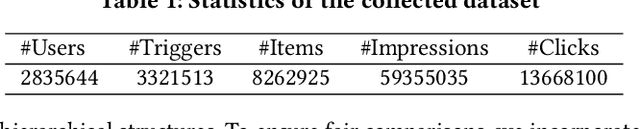
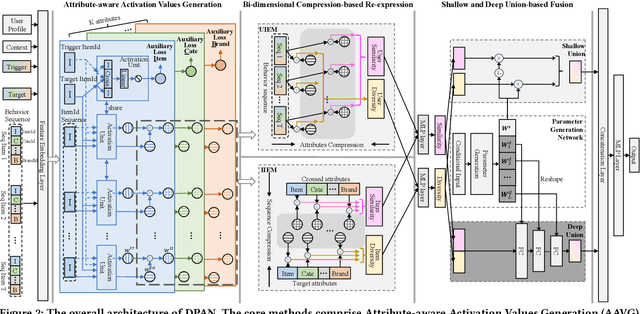
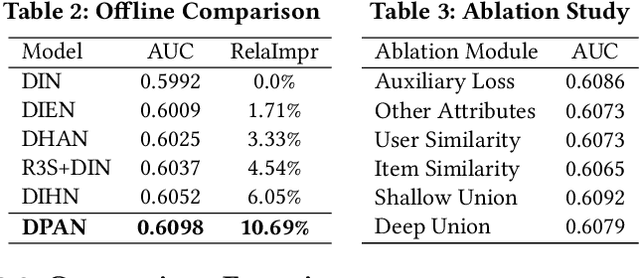
In e-commerce platforms, the relevant recommendation is a unique scenario providing related items for a trigger item that users are interested in. However, users' preferences for the similarity and diversity of recommendation results are dynamic and vary under different conditions. Moreover, individual item-level diversity is too coarse-grained since all recommended items are related to the trigger item. Thus, the two main challenges are to learn fine-grained representations of similarity and diversity and capture users' dynamic preferences for them under different conditions. To address these challenges, we propose a novel method called the Dynamic Preference-based and Attribute-aware Network (DPAN) for predicting Click-Through Rate (CTR) in relevant recommendations. Specifically, based on Attribute-aware Activation Values Generation (AAVG), Bi-dimensional Compression-based Re-expression (BCR) is designed to obtain similarity and diversity representations of user interests and item information. Then Shallow and Deep Union-based Fusion (SDUF) is proposed to capture users' dynamic preferences for the diverse degree of recommendation results according to various conditions. DPAN has demonstrated its effectiveness through extensive offline experiments and online A/B testing, resulting in a significant 7.62% improvement in CTR. Currently, DPAN has been successfully deployed on our e-commerce platform serving the primary traffic for relevant recommendations. The code of DPAN has been made publicly available.