 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SPPNet: A Single-Point Prompt Network for Nuclei Image Segmentation
Aug 23, 2023
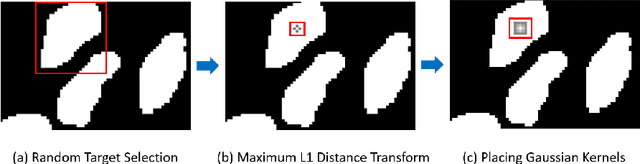
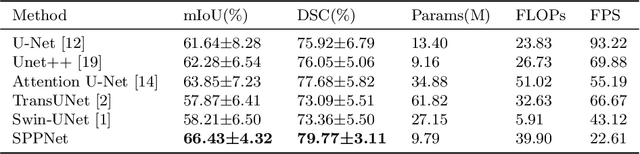
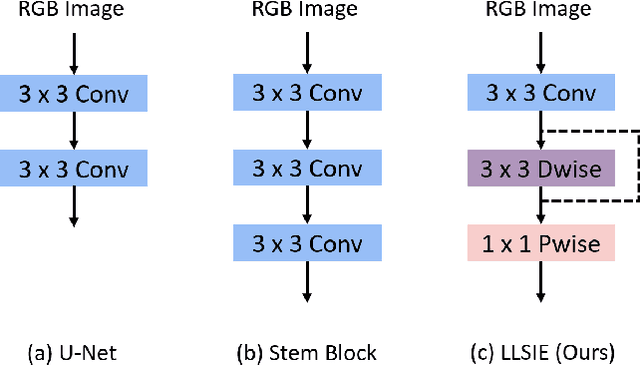
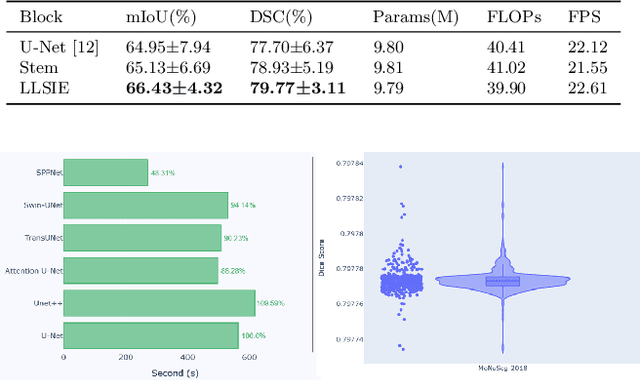
Image segmentation plays an essential role in nuclei image analysis. Recently, the segment anything model has made a significant breakthrough in such tasks. However, the current model exists two major issues for cell segmentation: (1) the image encoder of the segment anything model involves a large number of parameters. Retraining or even fine-tuning the model still requires expensive computational resources. (2) in point prompt mode, points are sampled from the center of the ground truth and more than one set of points is expected to achieve reliable performance, which is not efficient for practical applications. In this paper, a single-point prompt network is proposed for nuclei image segmentation, called SPPNet. We replace the original image encoder with a lightweight vision transformer. Also, an effective convolutional block is added in parallel to extract the low-level semantic information from the image and compensate for the performance degradation due to the small image encoder. We propose a new point-sampling method based on the Gaussian kernel. The proposed model is evaluated on the MoNuSeg-2018 dataset. The result demonstrated that SPPNet outperforms existing U-shape architectures and shows faster convergence in training. Compared to the segment anything model, SPPNet shows roughly 20 times faster inference, with 1/70 parameters and computational cost. Particularly, only one set of points is required in both the training and inference phases, which is more reasonable for clinical applications. The code for our work and more technical details can be found at https://github.com/xq141839/SPPNet.
Learning to In-paint: Domain Adaptive Shape Completion for 3D Organ Segmentation
Aug 17, 2023We aim at incorporating explicit shape information into current 3D organ segmentation models. Different from previous works, we formulate shape learning as an in-painting task, which is named Masked Label Mask Modeling (MLM). Through MLM, learnable mask tokens are fed into transformer blocks to complete the label mask of organ. To transfer MLM shape knowledge to target, we further propose a novel shape-aware self-distillation with both in-painting reconstruction loss and pseudo loss. Extensive experiments on five public organ segmentation datasets show consistent improvements over prior arts with at least 1.2 points gain in the Dice score, demonstrating the effectiveness of our method in challenging unsupervised domain adaptation scenarios including: (1) In-domain organ segmentation; (2) Unseen domain segmentation and (3) Unseen organ segmentation. We hope this work will advance shape analysis and geometric learning in medical imaging.
Feature-Suppressed Contrast for Self-Supervised Food Pre-training
Aug 07, 2023
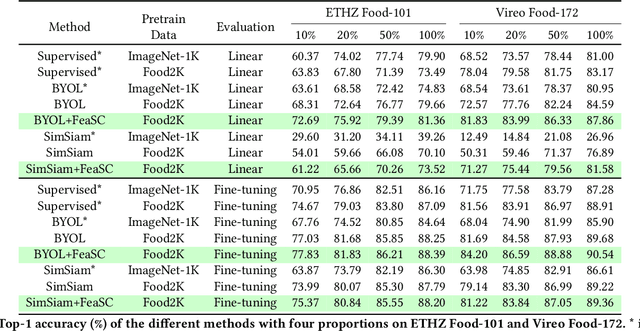

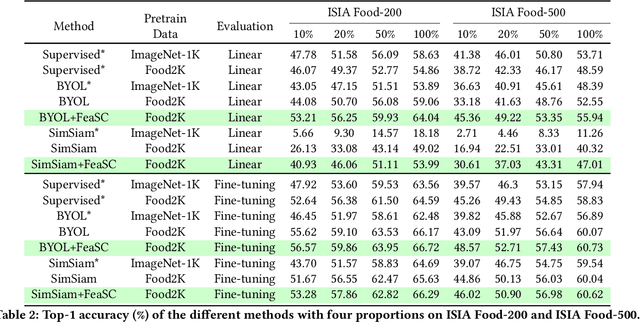
Most previous approaches for analyzing food images have relied on extensively annotated datasets, resulting in significant human labeling expenses due to the varied and intricate nature of such images. Inspired by the effectiveness of contrastive self-supervised methods in utilizing unlabelled data, weiqing explore leveraging these techniques on unlabelled food images. In contrastive self-supervised methods, two views are randomly generated from an image by data augmentations. However, regarding food images, the two views tend to contain similar informative contents, causing large mutual information, which impedes the efficacy of contrastive self-supervised learning. To address this problem, we propose Feature Suppressed Contrast (FeaSC) to reduce mutual information between views. As the similar contents of the two views are salient or highly responsive in the feature map, the proposed FeaSC uses a response-aware scheme to localize salient features in an unsupervised manner. By suppressing some salient features in one view while leaving another contrast view unchanged, the mutual information between the two views is reduced, thereby enhancing the effectiveness of contrast learning for self-supervised food pre-training. As a plug-and-play module, the proposed method consistently improves BYOL and SimSiam by 1.70\% $\sim$ 6.69\% classification accuracy on four publicly available food recognition datasets. Superior results have also been achieved on downstream segmentation tasks, demonstrating the effectiveness of the proposed method.
Majorizing Measures, Codes, and Information
May 04, 2023The majorizing measure theorem of Fernique and Talagrand is a fundamental result in the theory of random processes. It relates the boundedness of random processes indexed by elements of a metric space to complexity measures arising from certain multiscale combinatorial structures, such as packing and covering trees. This paper builds on the ideas first outlined in a little-noticed preprint of Andreas Maurer to present an information-theoretic perspective on the majorizing measure theorem, according to which the boundedness of random processes is phrased in terms of the existence of efficient variable-length codes for the elements of the indexing metric space.
GeodesicPSIM: Predicting the Quality of Static Mesh with Texture Map via Geodesic Patch Similarity
Aug 09, 2023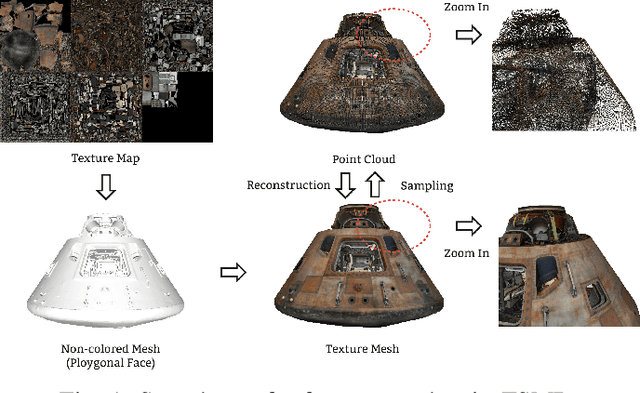
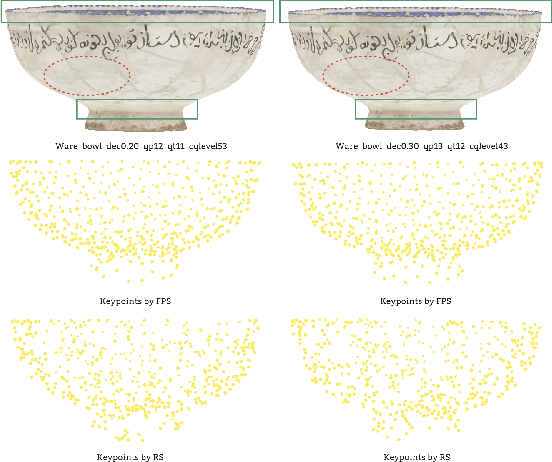
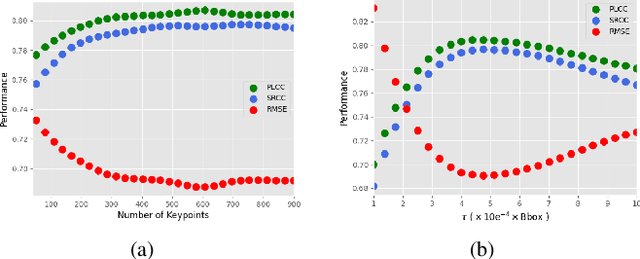
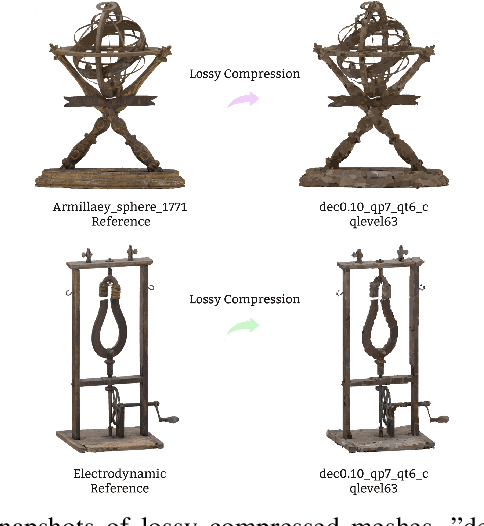
Static meshes with texture maps have attracted considerable attention in both industrial manufacturing and academic research, leading to an urgent requirement for effective and robust objective quality evaluation. However, current model-based static mesh quality metrics have obvious limitations: most of them only consider geometry information, while color information is ignored, and they have strict constraints for the meshes' geometrical topology. Other metrics, such as image-based and point-based metrics, are easily influenced by the prepossessing algorithms, e.g., projection and sampling, hampering their ability to perform at their best. In this paper, we propose Geodesic Patch Similarity (GeodesicPSIM), a novel model-based metric to accurately predict human perception quality for static meshes. After selecting a group keypoints, 1-hop geodesic patches are constructed based on both the reference and distorted meshes cleaned by an effective mesh cleaning algorithm. A two-step patch cropping algorithm and a patch texture mapping module refine the size of 1-hop geodesic patches and build the relationship between the mesh geometry and color information, resulting in the generation of 1-hop textured geodesic patches. Three types of features are extracted to quantify the distortion: patch color smoothness, patch discrete mean curvature, and patch pixel color average and variance. To the best of our knowledge, GeodesicPSIM is the first model-based metric especially designed for static meshes with texture maps. GeodesicPSIM provides state-of-the-art performance in comparison with image-based, point-based, and video-based metrics on a newly created and challenging database. We also prove the robustness of GeodesicPSIM by introducing different settings of hyperparameters. Ablation studies also exhibit the effectiveness of three proposed features and the patch cropping algorithm.
Multi-View Fusion and Distillation for Subgrade Distresses Detection based on 3D-GPR
Aug 09, 2023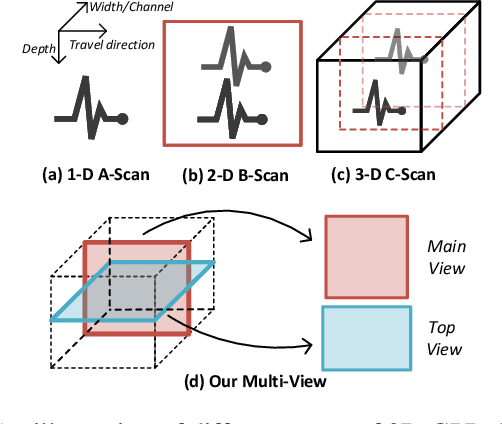
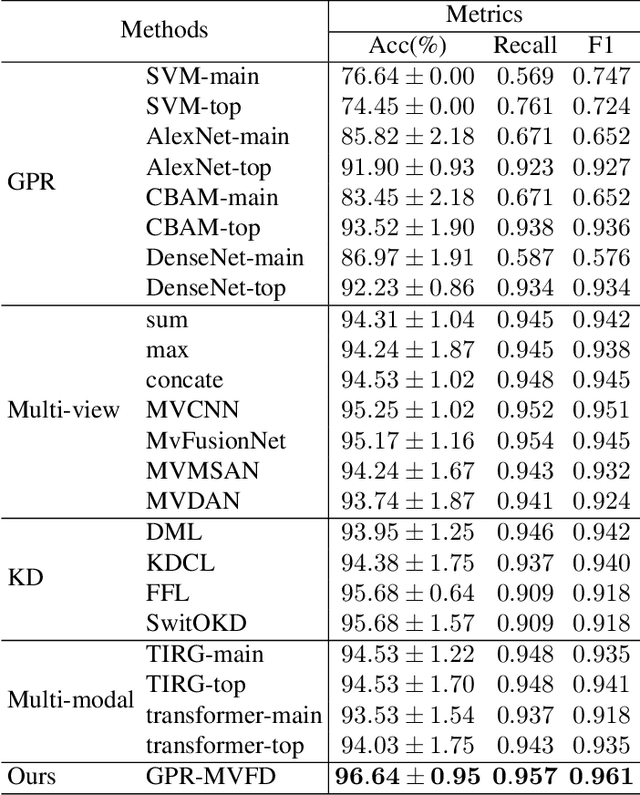
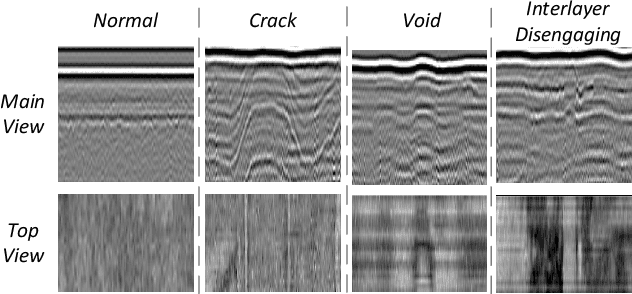
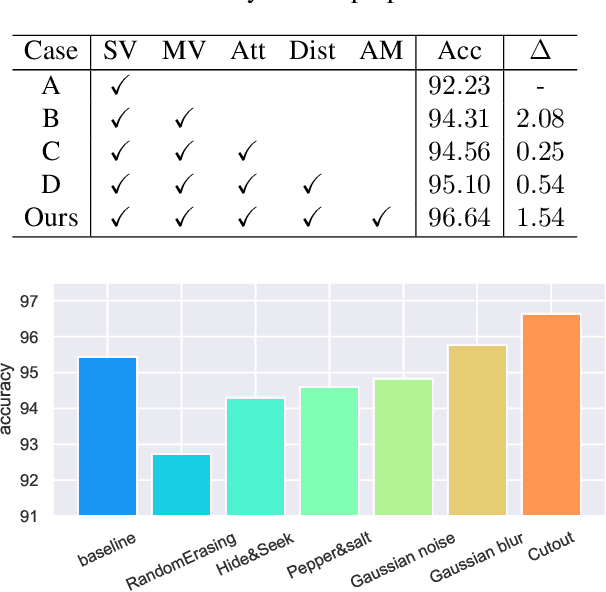
The application of 3D ground-penetrating radar (3D-GPR) for subgrade distress detection has gained widespread popularity. To enhance the efficiency and accuracy of detection, pioneering studies have attempted to adopt automatic detection techniques, particularly deep learning. However, existing works typically rely on traditional 1D A-scan, 2D B-scan or 3D C-scan data of the GPR, resulting in either insufficient spatial information or high computational complexity. To address these challenges, we introduce a novel methodology for the subgrade distress detection task by leveraging the multi-view information from 3D-GPR data. Moreover, we construct a real multi-view image dataset derived from the original 3D-GPR data for the detection task, which provides richer spatial information compared to A-scan and B-scan data, while reducing computational complexity compared to C-scan data. Subsequently, we develop a novel \textbf{M}ulti-\textbf{V}iew \textbf{V}usion and \textbf{D}istillation framework, \textbf{GPR-MVFD}, specifically designed to optimally utilize the multi-view GPR dataset. This framework ingeniously incorporates multi-view distillation and attention-based fusion to facilitate significant feature extraction for subgrade distresses. In addition, a self-adaptive learning mechanism is adopted to stabilize the model training and prevent performance degeneration in each branch. Extensive experiments conducted on this new GPR benchmark demonstrate the effectiveness and efficiency of our proposed framework. Our framework outperforms not only the existing GPR baselines, but also the state-of-the-art methods in the fields of multi-view learning, multi-modal learning, and knowledge distillation. We will release the constructed multi-view GPR dataset with expert-annotated labels and the source codes of the proposed framework.
DPMAC: Differentially Private Communication for Cooperative Multi-Agent Reinforcement Learning
Aug 19, 2023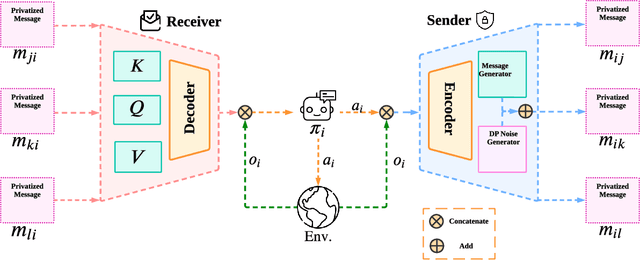
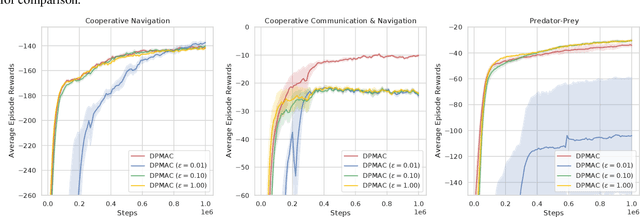
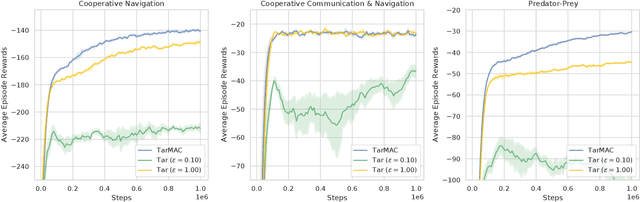
Communication lays the foundation for cooperation in human society and in multi-agent reinforcement learning (MARL). Humans also desire to maintain their privacy when communicating with others, yet such privacy concern has not been considered in existing works in MARL. To this end, we propose the \textit{differentially private multi-agent communication} (DPMAC) algorithm, which protects the sensitive information of individual agents by equipping each agent with a local message sender with rigorous $(\epsilon, \delta)$-differential privacy (DP) guarantee. In contrast to directly perturbing the messages with predefined DP noise as commonly done in privacy-preserving scenarios, we adopt a stochastic message sender for each agent respectively and incorporate the DP requirement into the sender, which automatically adjusts the learned message distribution to alleviate the instability caused by DP noise. Further, we prove the existence of a Nash equilibrium in cooperative MARL with privacy-preserving communication, which suggests that this problem is game-theoretically learnable. Extensive experiments demonstrate a clear advantage of DPMAC over baseline methods in privacy-preserving scenarios.
Breast Lesion Diagnosis Using Static Images and Dynamic Video
Aug 19, 2023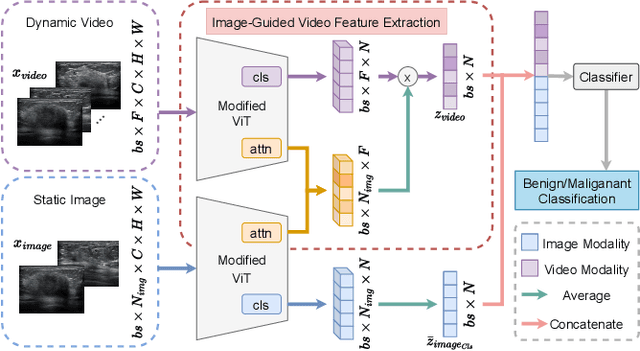
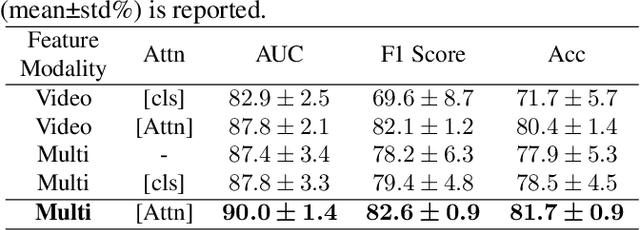
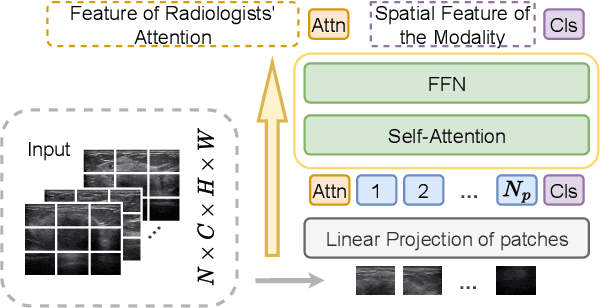
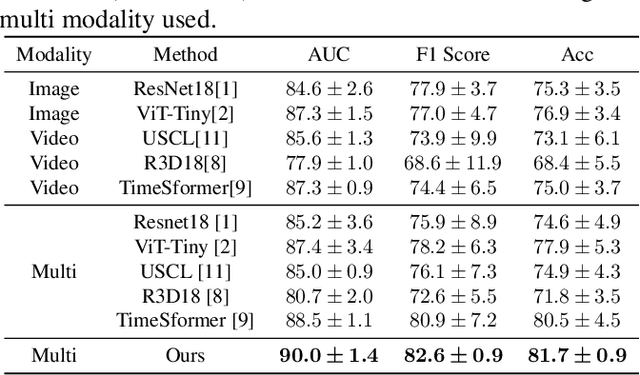
Deep learning based Computer Aided Diagnosis (CAD) systems have been developed to treat breast ultrasound. Most of them focus on a single ultrasound imaging modality, either using representative static images or the dynamic video of a real-time scan. In fact, these two image modalities are complementary for lesion diagnosis. Dynamic videos provide detailed three-dimensional information about the lesion, while static images capture the typical sections of the lesion. In this work, we propose a multi-modality breast tumor diagnosis model to imitate the diagnosing process of radiologists, which learns the features of both static images and dynamic video and explores the potential relationship between the two modalities. Considering that static images are carefully selected by professional radiologists, we propose to aggregate dynamic video features under the guidance of domain knowledge from static images before fusing multi-modality features. Our work is validated on a breast ultrasound dataset composed of 897 sets of ultrasound images and videos. Experimental results show that our model boosts the performance of Benign/Malignant classification, achieving 90.0% in AUC and 81.7% in accuracy.
Modeling Random Networks with Heterogeneous Reciprocity
Aug 19, 2023Reciprocity, or the tendency of individuals to mirror behavior, is a key measure that describes information exchange in a social network. Users in social networks tend to engage in different levels of reciprocal behavior. Differences in such behavior may indicate the existence of communities that reciprocate links at varying rates. In this paper, we develop methodology to model the diverse reciprocal behavior in growing social networks. In particular, we present a preferential attachment model with heterogeneous reciprocity that imitates the attraction users have for popular users, plus the heterogeneous nature by which they reciprocate links. We compare Bayesian and frequentist model fitting techniques for large networks, as well as computationally efficient variational alternatives. Cases where the number of communities are known and unknown are both considered. We apply the presented methods to the analysis of a Facebook wallpost network where users have non-uniform reciprocal behavior patterns. The fitted model captures the heavy-tailed nature of the empirical degree distributions in the Facebook data and identifies multiple groups of users that differ in their tendency to reply to and receive responses to wallposts.
Scaling Clinical Trial Matching Using Large Language Models: A Case Study in Oncology
Aug 18, 2023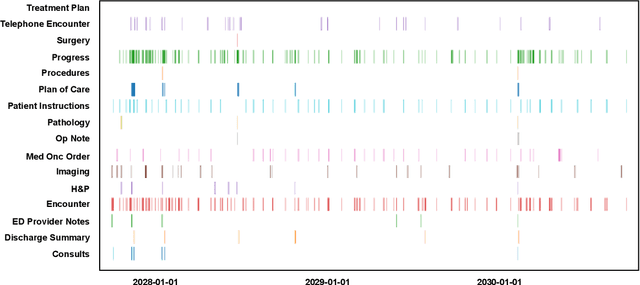
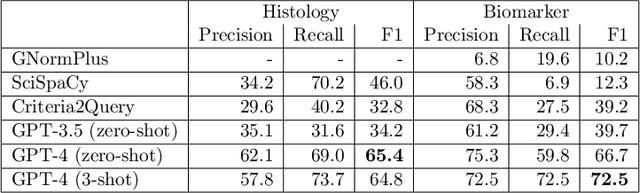
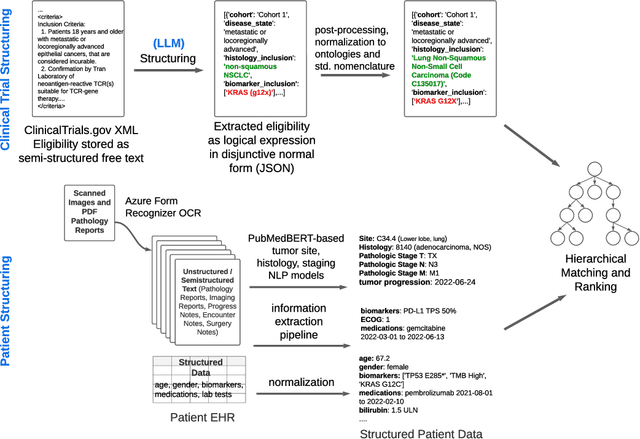

Clinical trial matching is a key process in health delivery and discovery. In practice, it is plagued by overwhelming unstructured data and unscalable manual processing. In this paper, we conduct a systematic study on scaling clinical trial matching using large language models (LLMs), with oncology as the focus area. Our study is grounded in a clinical trial matching system currently in test deployment at a large U.S. health network. Initial findings are promising: out of box, cutting-edge LLMs, such as GPT-4, can already structure elaborate eligibility criteria of clinical trials and extract complex matching logic (e.g., nested AND/OR/NOT). While still far from perfect, LLMs substantially outperform prior strong baselines and may serve as a preliminary solution to help triage patient-trial candidates with humans in the loop. Our study also reveals a few significant growth areas for applying LLMs to end-to-end clinical trial matching, such as context limitation and accuracy, especially in structuring patient information from longitudinal medical records.