 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Personalized Dense Retrieval Framework for Unified Information Access
Apr 26, 2023

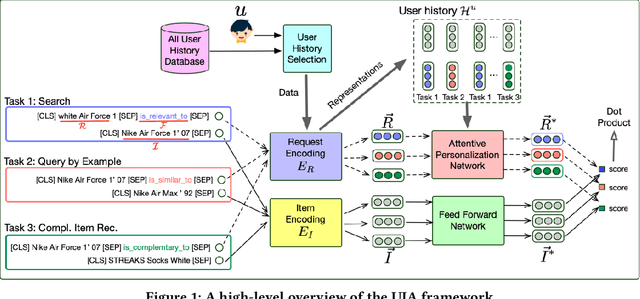
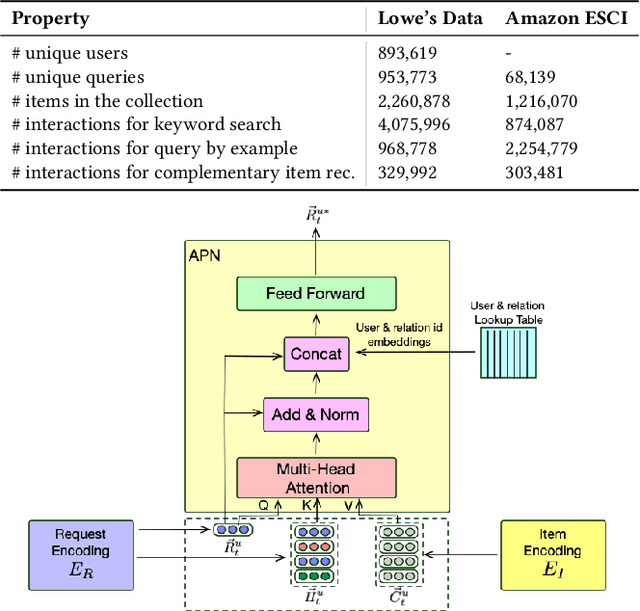
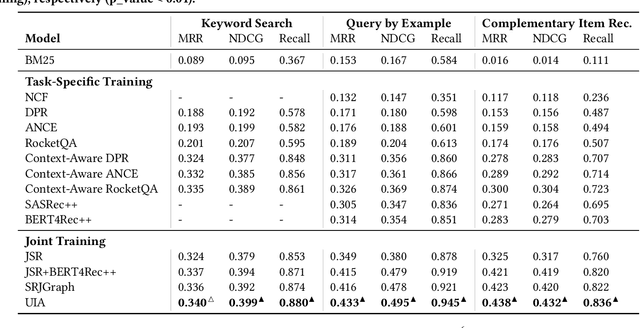
Developing a universal model that can efficiently and effectively respond to a wide range of information access requests -- from retrieval to recommendation to question answering -- has been a long-lasting goal in the information retrieval community. This paper argues that the flexibility, efficiency, and effectiveness brought by the recent development in dense retrieval and approximate nearest neighbor search have smoothed the path towards achieving this goal. We develop a generic and extensible dense retrieval framework, called \framework, that can handle a wide range of (personalized) information access requests, such as keyword search, query by example, and complementary item recommendation. Our proposed approach extends the capabilities of dense retrieval models for ad-hoc retrieval tasks by incorporating user-specific preferences through the development of a personalized attentive network. This allows for a more tailored and accurate personalized information access experience. Our experiments on real-world e-commerce data suggest the feasibility of developing universal information access models by demonstrating significant improvements even compared to competitive baselines specifically developed for each of these individual information access tasks. This work opens up a number of fundamental research directions for future exploration.
ICAFusion: Iterative Cross-Attention Guided Feature Fusion for Multispectral Object Detection
Aug 15, 2023
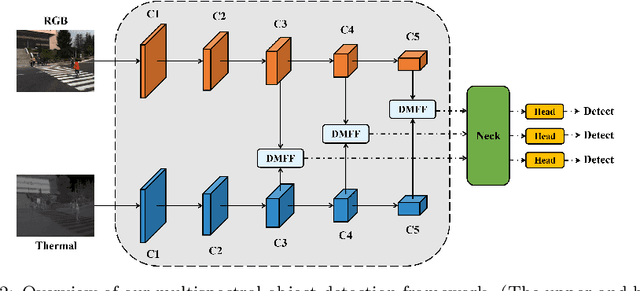
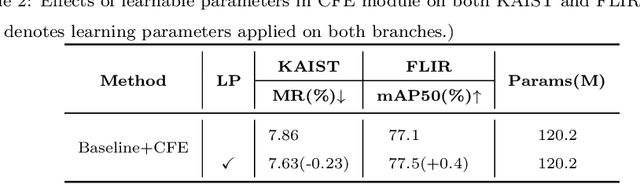
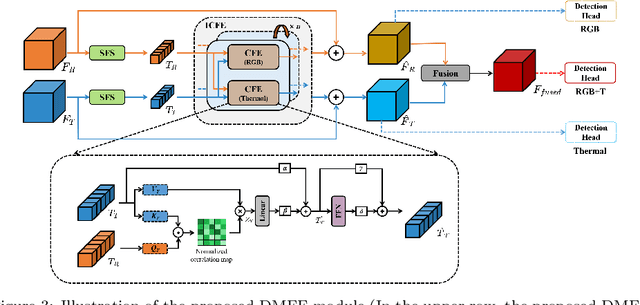
Effective feature fusion of multispectral images plays a crucial role in multi-spectral object detection. Previous studies have demonstrated the effectiveness of feature fusion using convolutional neural networks, but these methods are sensitive to image misalignment due to the inherent deffciency in local-range feature interaction resulting in the performance degradation. To address this issue, a novel feature fusion framework of dual cross-attention transformers is proposed to model global feature interaction and capture complementary information across modalities simultaneously. This framework enhances the discriminability of object features through the query-guided cross-attention mechanism, leading to improved performance. However, stacking multiple transformer blocks for feature enhancement incurs a large number of parameters and high spatial complexity. To handle this, inspired by the human process of reviewing knowledge, an iterative interaction mechanism is proposed to share parameters among block-wise multimodal transformers, reducing model complexity and computation cost. The proposed method is general and effective to be integrated into different detection frameworks and used with different backbones. Experimental results on KAIST, FLIR, and VEDAI datasets show that the proposed method achieves superior performance and faster inference, making it suitable for various practical scenarios. Code will be available at https://github.com/chanchanchan97/ICAFusion.
Enhancing Visually-Rich Document Understanding via Layout Structure Modeling
Aug 15, 2023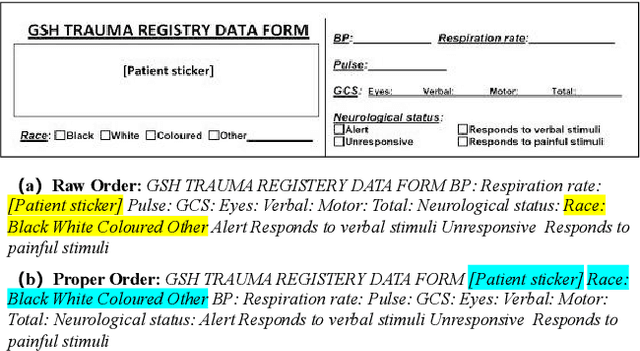
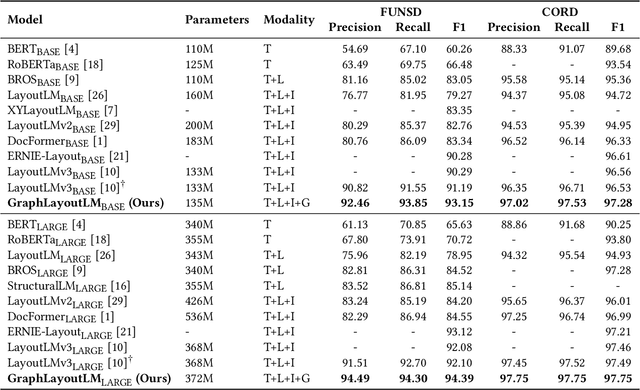
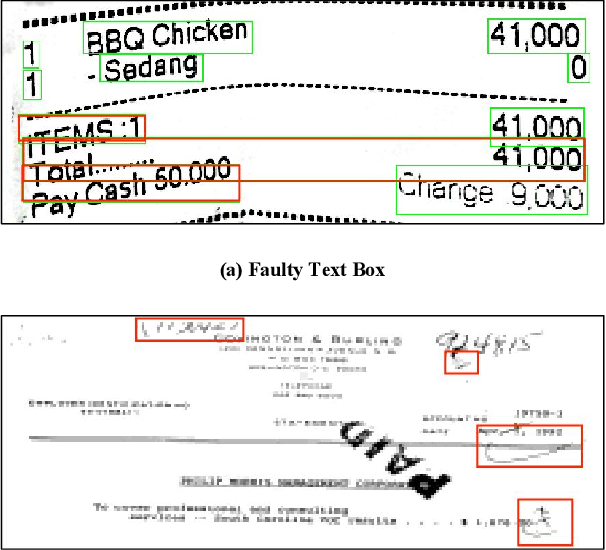
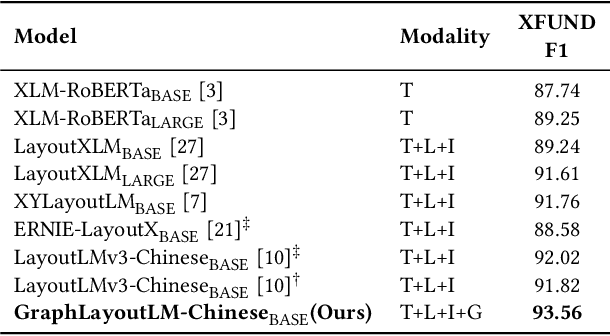
In recent years, the use of multi-modal pre-trained Transformers has led to significant advancements in visually-rich document understanding. However, existing models have mainly focused on features such as text and vision while neglecting the importance of layout relationship between text nodes. In this paper, we propose GraphLayoutLM, a novel document understanding model that leverages the modeling of layout structure graph to inject document layout knowledge into the model. GraphLayoutLM utilizes a graph reordering algorithm to adjust the text sequence based on the graph structure. Additionally, our model uses a layout-aware multi-head self-attention layer to learn document layout knowledge. The proposed model enables the understanding of the spatial arrangement of text elements, improving document comprehension. We evaluate our model on various benchmarks, including FUNSD, XFUND and CORD, and achieve state-of-the-art results among these datasets. Our experimental results demonstrate that our proposed method provides a significant improvement over existing approaches and showcases the importance of incorporating layout information into document understanding models. We also conduct an ablation study to investigate the contribution of each component of our model. The results show that both the graph reordering algorithm and the layout-aware multi-head self-attention layer play a crucial role in achieving the best performance.
DIG In: Evaluating Disparities in Image Generations with Indicators for Geographic Diversity
Aug 15, 2023
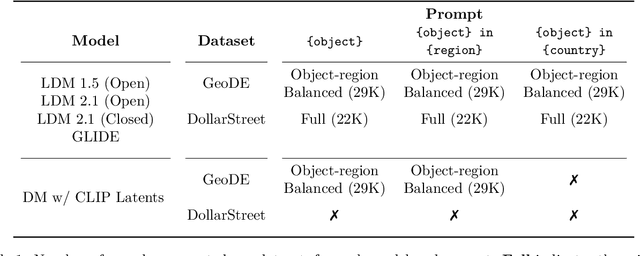


The unprecedented photorealistic results achieved by recent text-to-image generative systems and their increasing use as plug-and-play content creation solutions make it crucial to understand their potential biases. In this work, we introduce three indicators to evaluate the realism, diversity and prompt-generation consistency of text-to-image generative systems when prompted to generate objects from across the world. Our indicators complement qualitative analysis of the broader impact of such systems by enabling automatic and efficient benchmarking of geographic disparities, an important step towards building responsible visual content creation systems. We use our proposed indicators to analyze potential geographic biases in state-of-the-art visual content creation systems and find that: (1) models have less realism and diversity of generations when prompting for Africa and West Asia than Europe, (2) prompting with geographic information comes at a cost to prompt-consistency and diversity of generated images, and (3) models exhibit more region-level disparities for some objects than others. Perhaps most interestingly, our indicators suggest that progress in image generation quality has come at the cost of real-world geographic representation. Our comprehensive evaluation constitutes a crucial step towards ensuring a positive experience of visual content creation for everyone.
Graph-Structured Kernel Design for Power Flow Learning using Gaussian Processes
Aug 15, 2023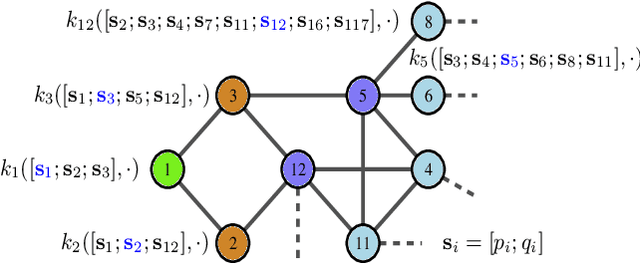
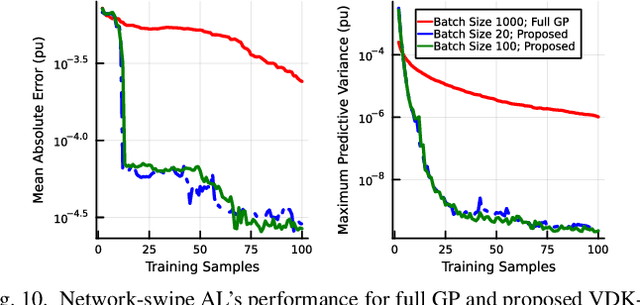
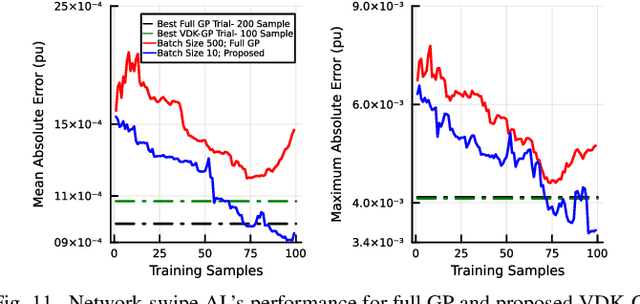
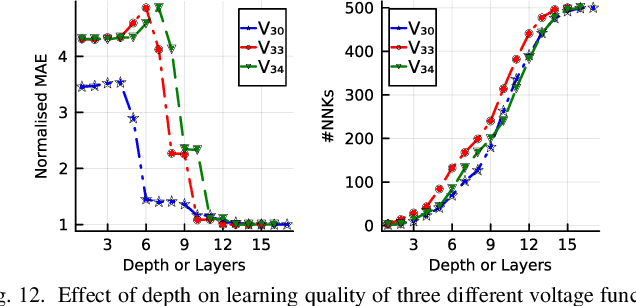
This paper presents a physics-inspired graph-structured kernel designed for power flow learning using Gaussian Process (GP). The kernel, named the vertex-degree kernel (VDK), relies on latent decomposition of voltage-injection relationship based on the network graph or topology. Notably, VDK design avoids the need to solve optimization problems for kernel search. To enhance efficiency, we also explore a graph-reduction approach to obtain a VDK representation with lesser terms. Additionally, we propose a novel network-swipe active learning scheme, which intelligently selects sequential training inputs to accelerate the learning of VDK. Leveraging the additive structure of VDK, the active learning algorithm performs a block-descent type procedure on GP's predictive variance, serving as a proxy for information gain. Simulations demonstrate that the proposed VDK-GP achieves more than two fold sample complexity reduction, compared to full GP on medium scale 500-Bus and large scale 1354-Bus power systems. The network-swipe algorithm outperforms mean performance of 500 random trials on test predictions by two fold for medium-sized 500-Bus systems and best performance of 25 random trials for large-scale 1354-Bus systems by 10%. Moreover, we demonstrate that the proposed method's performance for uncertainty quantification applications with distributionally shifted testing data sets.
Leveraging Open Information Extraction for Improving Few-Shot Trigger Detection Domain Transfer
May 23, 2023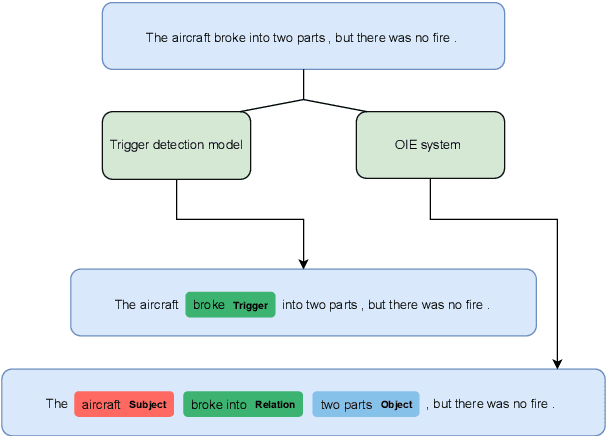
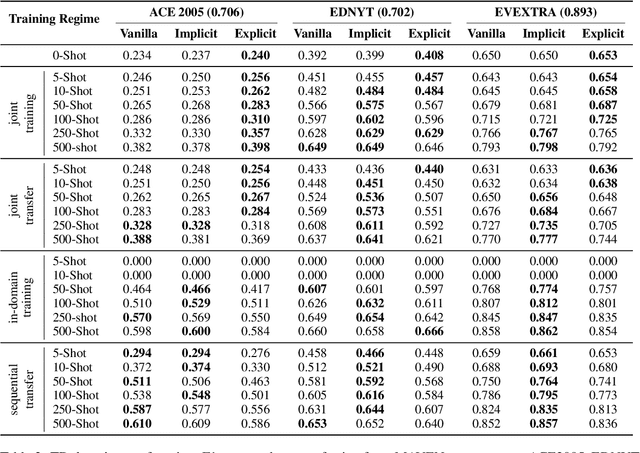
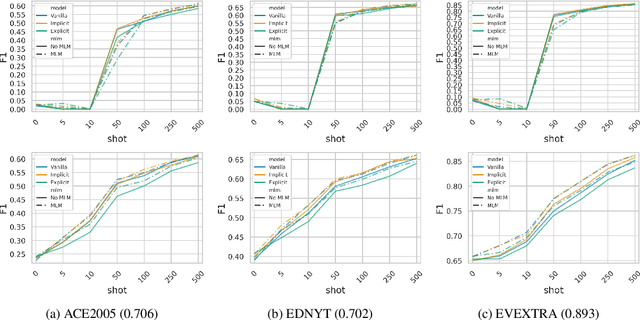
Event detection is a crucial information extraction task in many domains, such as Wikipedia or news. The task typically relies on trigger detection (TD) -- identifying token spans in the text that evoke specific events. While the notion of triggers should ideally be universal across domains, domain transfer for TD from high- to low-resource domains results in significant performance drops. We address the problem of negative transfer for TD by coupling triggers between domains using subject-object relations obtained from a rule-based open information extraction (OIE) system. We demonstrate that relations injected through multi-task training can act as mediators between triggers in different domains, enhancing zero- and few-shot TD domain transfer and reducing negative transfer, in particular when transferring from a high-resource source Wikipedia domain to a low-resource target news domain. Additionally, we combine the extracted relations with masked language modeling on the target domain and obtain further TD performance gains. Finally, we demonstrate that the results are robust to the choice of the OIE system.
BarlowRL: Barlow Twins for Data-Efficient Reinforcement Learning
Aug 08, 2023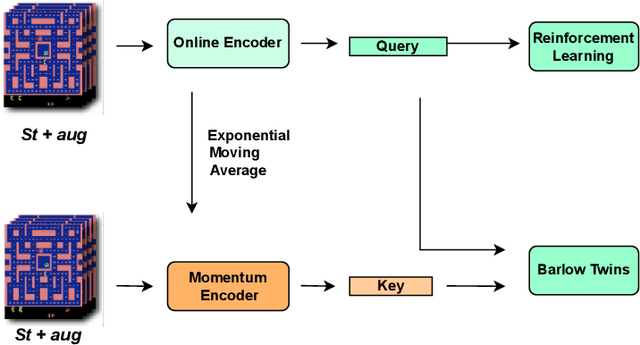
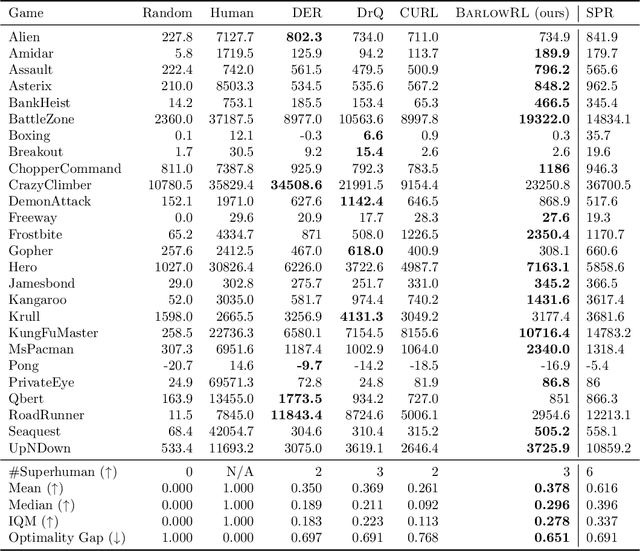


This paper introduces BarlowRL, a data-efficient reinforcement learning agent that combines the Barlow Twins self-supervised learning framework with DER (Data-Efficient Rainbow) algorithm. BarlowRL outperforms both DER and its contrastive counterpart CURL on the Atari 100k benchmark. BarlowRL avoids dimensional collapse by enforcing information spread to the whole space. This helps RL algorithms to utilize uniformly spread state representation that eventually results in a remarkable performance. The integration of Barlow Twins with DER enhances data efficiency and achieves superior performance in the RL tasks. BarlowRL demonstrates the potential of incorporating self-supervised learning techniques to improve RL algorithms.
UniBrain: Unify Image Reconstruction and Captioning All in One Diffusion Model from Human Brain Activity
Aug 14, 2023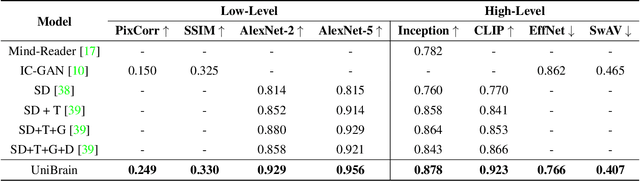
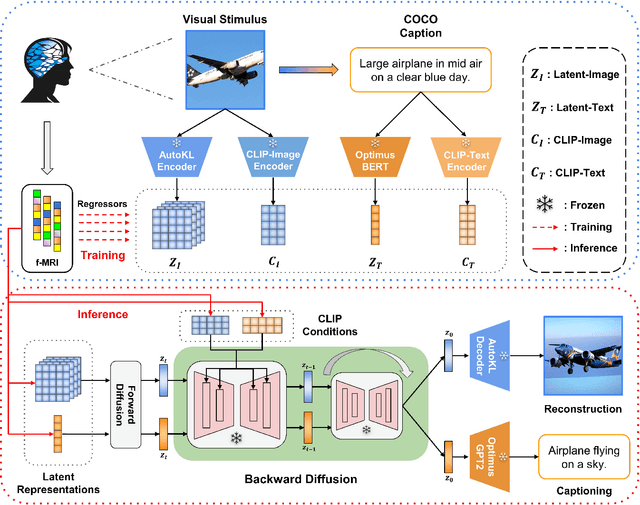
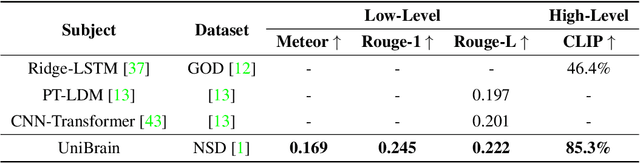

Image reconstruction and captioning from brain activity evoked by visual stimuli allow researchers to further understand the connection between the human brain and the visual perception system. While deep generative models have recently been employed in this field, reconstructing realistic captions and images with both low-level details and high semantic fidelity is still a challenging problem. In this work, we propose UniBrain: Unify Image Reconstruction and Captioning All in One Diffusion Model from Human Brain Activity. For the first time, we unify image reconstruction and captioning from visual-evoked functional magnetic resonance imaging (fMRI) through a latent diffusion model termed Versatile Diffusion. Specifically, we transform fMRI voxels into text and image latent for low-level information and guide the backward diffusion process through fMRI-based image and text conditions derived from CLIP to generate realistic captions and images. UniBrain outperforms current methods both qualitatively and quantitatively in terms of image reconstruction and reports image captioning results for the first time on the Natural Scenes Dataset (NSD) dataset. Moreover, the ablation experiments and functional region-of-interest (ROI) analysis further exhibit the superiority of UniBrain and provide comprehensive insight for visual-evoked brain decoding.
A Unified Masked Autoencoder with Patchified Skeletons for Motion Synthesis
Aug 14, 2023The synthesis of human motion has traditionally been addressed through task-dependent models that focus on specific challenges, such as predicting future motions or filling in intermediate poses conditioned on known key-poses. In this paper, we present a novel task-independent model called UNIMASK-M, which can effectively address these challenges using a unified architecture. Our model obtains comparable or better performance than the state-of-the-art in each field. Inspired by Vision Transformers (ViTs), our UNIMASK-M model decomposes a human pose into body parts to leverage the spatio-temporal relationships existing in human motion. Moreover, we reformulate various pose-conditioned motion synthesis tasks as a reconstruction problem with different masking patterns given as input. By explicitly informing our model about the masked joints, our UNIMASK-M becomes more robust to occlusions. Experimental results show that our model successfully forecasts human motion on the Human3.6M dataset. Moreover, it achieves state-of-the-art results in motion inbetweening on the LaFAN1 dataset, particularly in long transition periods. More information can be found on the project website https://sites.google.com/view/estevevallsmascaro/publications/unimask-m.
Accurate Eye Tracking from Dense 3D Surface Reconstructions using Single-Shot Deflectometry
Aug 14, 2023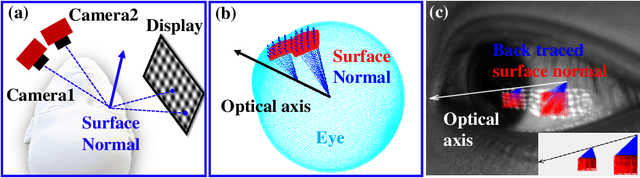

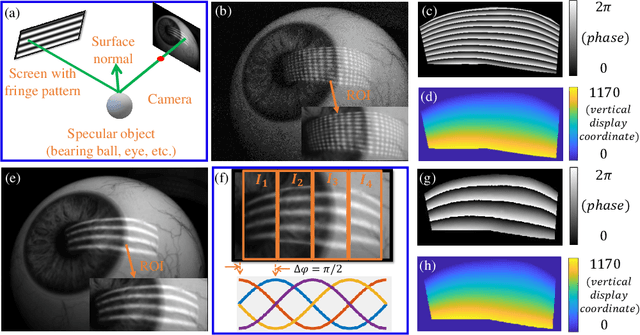
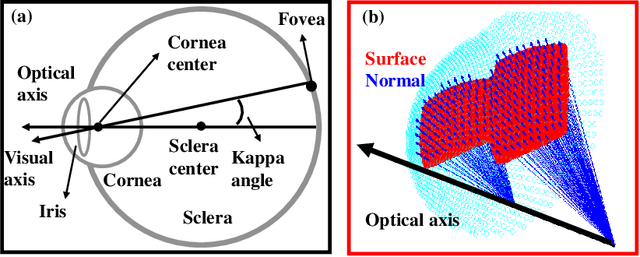
Eye-tracking plays a crucial role in the development of virtual reality devices, neuroscience research, and psychology. Despite its significance in numerous applications, achieving an accurate, robust, and fast eye-tracking solution remains a considerable challenge for current state-of-the-art methods. While existing reflection-based techniques (e.g., "glint tracking") are considered the most accurate, their performance is limited by their reliance on sparse 3D surface data acquired solely from the cornea surface. In this paper, we rethink the way how specular reflections can be used for eye tracking: We propose a novel method for accurate and fast evaluation of the gaze direction that exploits teachings from single-shot phase-measuring-deflectometry (PMD). In contrast to state-of-the-art reflection-based methods, our method acquires dense 3D surface information of both cornea and sclera within only one single camera frame (single-shot). Improvements in acquired reflection surface points("glints") of factors $>3300 \times$ are easily achievable. We show the feasibility of our approach with experimentally evaluated gaze errors of only $\leq 0.25^\circ$ demonstrating a significant improvement over the current state-of-the-art.