 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Enhancing Nucleus Segmentation with HARU-Net: A Hybrid Attention Based Residual U-Blocks Network
Aug 07, 2023
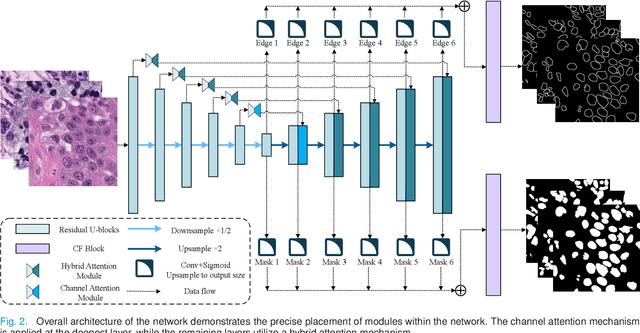
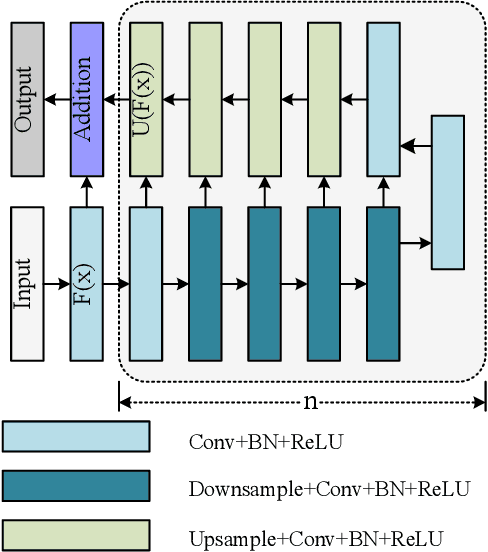
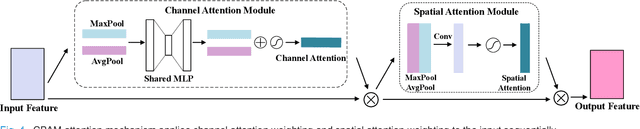
Nucleus image segmentation is a crucial step in the analysis, pathological diagnosis, and classification, which heavily relies on the quality of nucleus segmentation. However, the complexity of issues such as variations in nucleus size, blurred nucleus contours, uneven staining, cell clustering, and overlapping cells poses significant challenges. Current methods for nucleus segmentation primarily rely on nuclear morphology or contour-based approaches. Nuclear morphology-based methods exhibit limited generalization ability and struggle to effectively predict irregular-shaped nuclei, while contour-based extraction methods face challenges in accurately segmenting overlapping nuclei. To address the aforementioned issues, we propose a dual-branch network using hybrid attention based residual U-blocks for nucleus instance segmentation. The network simultaneously predicts target information and target contours. Additionally, we introduce a post-processing method that combines the target information and target contours to distinguish overlapping nuclei and generate an instance segmentation image. Within the network, we propose a context fusion block (CF-block) that effectively extracts and merges contextual information from the network. Extensive quantitative evaluations are conducted to assess the performance of our method. Experimental results demonstrate the superior performance of the proposed method compared to state-of-the-art approaches on the BNS, MoNuSeg, CoNSeg, and CPM-17 datasets.
Isomer: Isomerous Transformer for Zero-shot Video Object Segmentation
Aug 13, 2023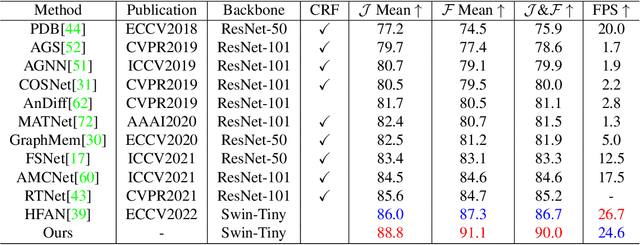
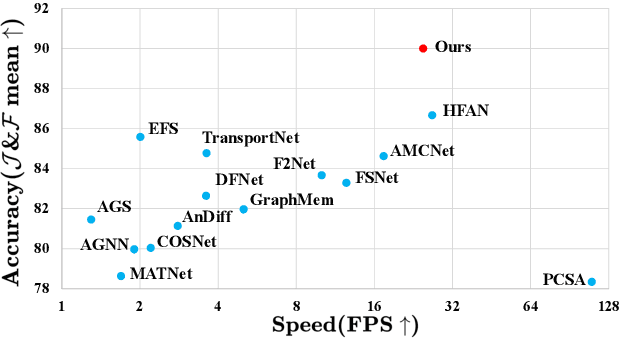

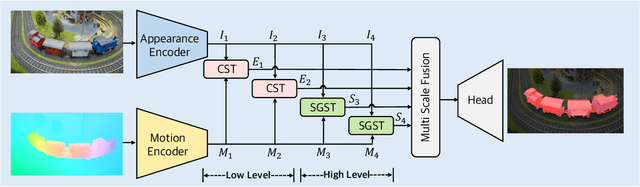
Recent leading zero-shot video object segmentation (ZVOS) works devote to integrating appearance and motion information by elaborately designing feature fusion modules and identically applying them in multiple feature stages. Our preliminary experiments show that with the strong long-range dependency modeling capacity of Transformer, simply concatenating the two modality features and feeding them to vanilla Transformers for feature fusion can distinctly benefit the performance but at a cost of heavy computation. Through further empirical analysis, we find that attention dependencies learned in Transformer in different stages exhibit completely different properties: global query-independent dependency in the low-level stages and semantic-specific dependency in the high-level stages. Motivated by the observations, we propose two Transformer variants: i) Context-Sharing Transformer (CST) that learns the global-shared contextual information within image frames with a lightweight computation. ii) Semantic Gathering-Scattering Transformer (SGST) that models the semantic correlation separately for the foreground and background and reduces the computation cost with a soft token merging mechanism. We apply CST and SGST for low-level and high-level feature fusions, respectively, formulating a level-isomerous Transformer framework for ZVOS task. Compared with the baseline that uses vanilla Transformers for multi-stage fusion, ours significantly increase the speed by 13 times and achieves new state-of-the-art ZVOS performance. Code is available at https://github.com/DLUT-yyc/Isomer.
Developmental Bootstrapping: From Simple Competences to Intelligent Human-Compatible AIs
Aug 23, 2023

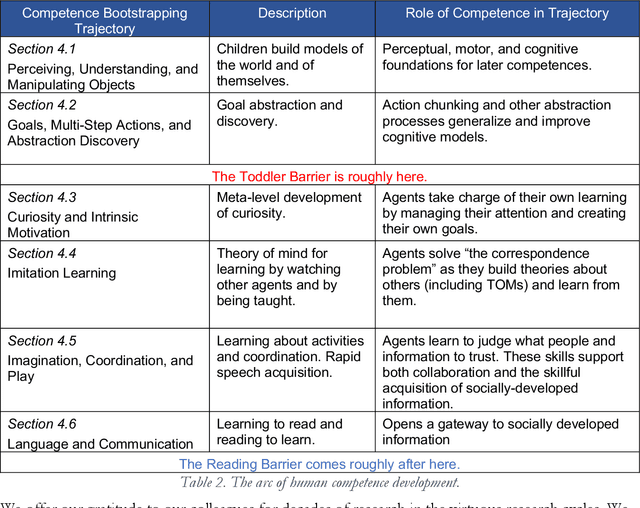
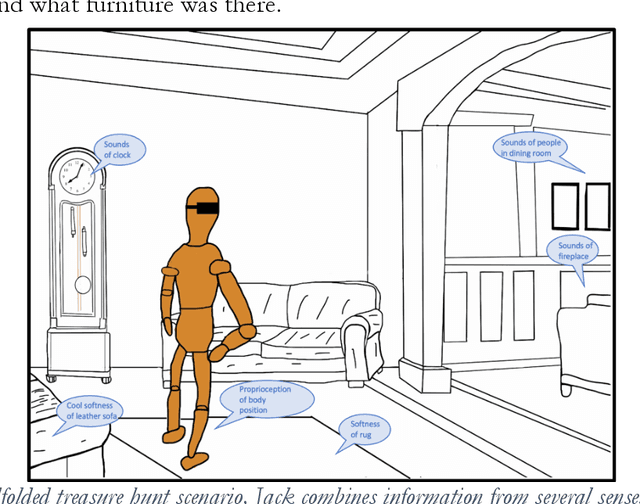
Although some AIs surpass human abilities in closed artificial worlds such as board games, in the real world they make strange mistakes and do not notice them. They cannot be instructed easily, fail to use common sense, and lack curiosity. Mainstream approaches for creating AIs include the traditional manually-constructed symbolic AI approach and the generative and deep learning AI approaches including large language models (LLMs). Although it is outside of the mainstream, the developmental bootstrapping approach may have more potential. In developmental bootstrapping, AIs develop competences like human children do. They start with innate competences. They interact with the environment and learn from their interactions. They incrementally extend their innate competences with self-developed competences. They interact and learn from people and establish perceptual, cognitive, and common grounding. They acquire the competences they need through competence bootstrapping. However, developmental robotics has not yet produced AIs with robust adult-level competences. Projects have typically stopped before reaching the Toddler Barrier. This corresponds to human infant development at about two years of age, before infant speech becomes fluent. They also do not bridge the Reading Barrier, where they could skillfully and skeptically draw on the socially developed online information resources that power LLMs. The next competences in human cognitive development involve intrinsic motivation, imitation learning, imagination, coordination, and communication. This position paper lays out the logic, prospects, gaps, and challenges for extending the practice of developmental bootstrapping to create robust, trustworthy, and human-compatible AIs.
Learning from Topology: Cosmological Parameter Estimation from the Large-scale Structure
Aug 04, 2023The topology of the large-scale structure of the universe contains valuable information on the underlying cosmological parameters. While persistent homology can extract this topological information, the optimal method for parameter estimation from the tool remains an open question. To address this, we propose a neural network model to map persistence images to cosmological parameters. Through a parameter recovery test, we demonstrate that our model makes accurate and precise estimates, considerably outperforming conventional Bayesian inference approaches.
Classification of lung cancer subtypes on CT images with synthetic pathological priors
Aug 09, 2023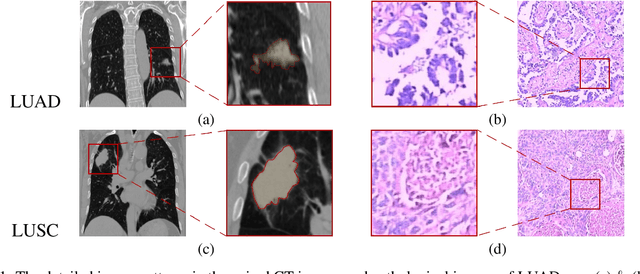
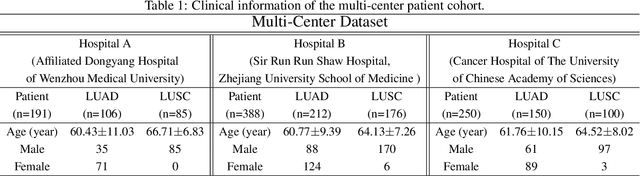
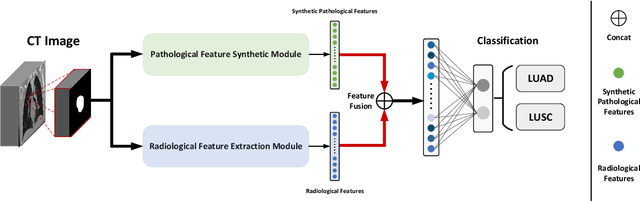

The accurate diagnosis on pathological subtypes for lung cancer is of significant importance for the follow-up treatments and prognosis managements. In this paper, we propose self-generating hybrid feature network (SGHF-Net) for accurately classifying lung cancer subtypes on computed tomography (CT) images. Inspired by studies stating that cross-scale associations exist in the image patterns between the same case's CT images and its pathological images, we innovatively developed a pathological feature synthetic module (PFSM), which quantitatively maps cross-modality associations through deep neural networks, to derive the "gold standard" information contained in the corresponding pathological images from CT images. Additionally, we designed a radiological feature extraction module (RFEM) to directly acquire CT image information and integrated it with the pathological priors under an effective feature fusion framework, enabling the entire classification model to generate more indicative and specific pathologically related features and eventually output more accurate predictions. The superiority of the proposed model lies in its ability to self-generate hybrid features that contain multi-modality image information based on a single-modality input. To evaluate the effectiveness, adaptability, and generalization ability of our model, we performed extensive experiments on a large-scale multi-center dataset (i.e., 829 cases from three hospitals) to compare our model and a series of state-of-the-art (SOTA) classification models. The experimental results demonstrated the superiority of our model for lung cancer subtypes classification with significant accuracy improvements in terms of accuracy (ACC), area under the curve (AUC), and F1 score.
Efficient Partitioning Method of Large-Scale Public Safety Spatio-Temporal Data based on Information Loss Constraints
Jun 22, 2023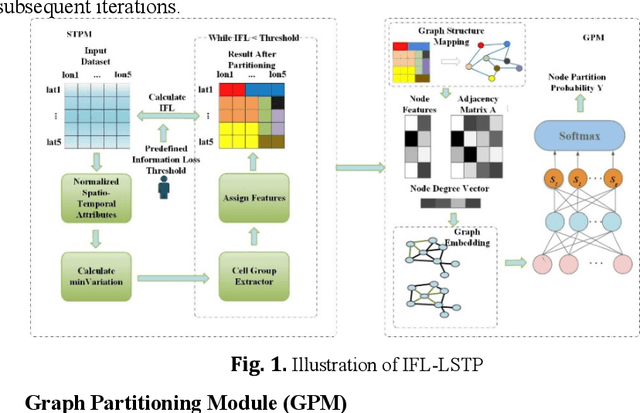

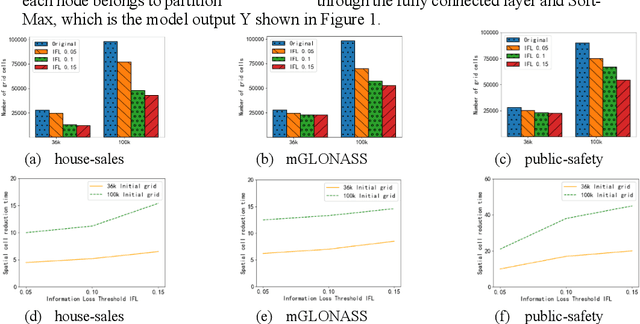

The storage, management, and application of massive spatio-temporal data are widely applied in various practical scenarios, including public safety. However, due to the unique spatio-temporal distribution characteristics of re-al-world data, most existing methods have limitations in terms of the spatio-temporal proximity of data and load balancing in distributed storage. There-fore, this paper proposes an efficient partitioning method of large-scale public safety spatio-temporal data based on information loss constraints (IFL-LSTP). The IFL-LSTP model specifically targets large-scale spatio-temporal point da-ta by combining the spatio-temporal partitioning module (STPM) with the graph partitioning module (GPM). This approach can significantly reduce the scale of data while maintaining the model's accuracy, in order to improve the partitioning efficiency. It can also ensure the load balancing of distributed storage while maintaining spatio-temporal proximity of the data partitioning results. This method provides a new solution for distributed storage of mas-sive spatio-temporal data. The experimental results on multiple real-world da-tasets demonstrate the effectiveness and superiority of IFL-LSTP.
Visual and Textual Prior Guided Mask Assemble for Few-Shot Segmentation and Beyond
Aug 15, 2023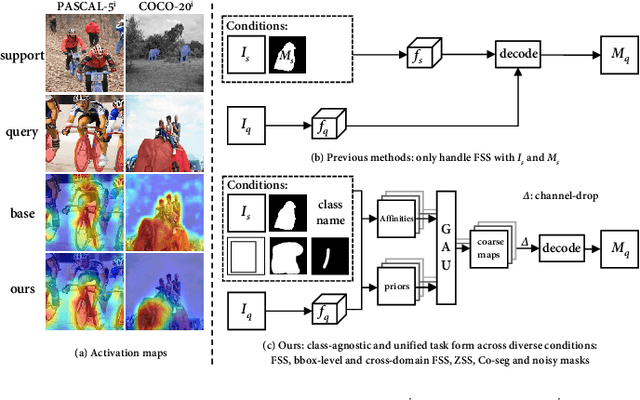
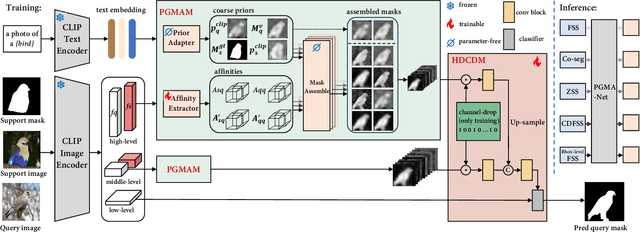
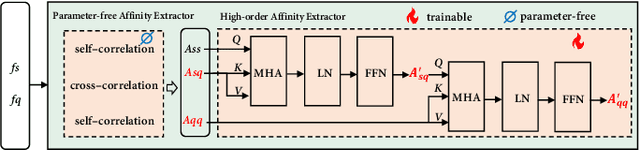
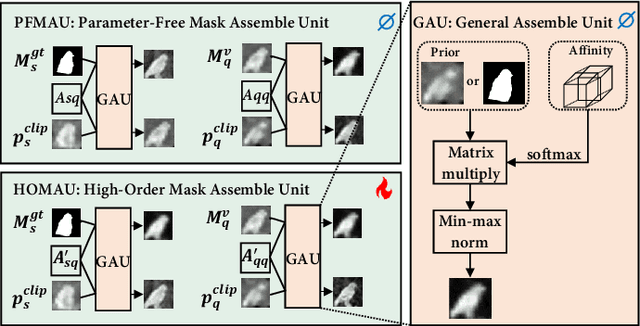
Few-shot segmentation (FSS) aims to segment the novel classes with a few annotated images. Due to CLIP's advantages of aligning visual and textual information, the integration of CLIP can enhance the generalization ability of FSS model. However, even with the CLIP model, the existing CLIP-based FSS methods are still subject to the biased prediction towards base classes, which is caused by the class-specific feature level interactions. To solve this issue, we propose a visual and textual Prior Guided Mask Assemble Network (PGMA-Net). It employs a class-agnostic mask assembly process to alleviate the bias, and formulates diverse tasks into a unified manner by assembling the prior through affinity. Specifically, the class-relevant textual and visual features are first transformed to class-agnostic prior in the form of probability map. Then, a Prior-Guided Mask Assemble Module (PGMAM) including multiple General Assemble Units (GAUs) is introduced. It considers diverse and plug-and-play interactions, such as visual-textual, inter- and intra-image, training-free, and high-order ones. Lastly, to ensure the class-agnostic ability, a Hierarchical Decoder with Channel-Drop Mechanism (HDCDM) is proposed to flexibly exploit the assembled masks and low-level features, without relying on any class-specific information. It achieves new state-of-the-art results in the FSS task, with mIoU of $77.6$ on $\text{PASCAL-}5^i$ and $59.4$ on $\text{COCO-}20^i$ in 1-shot scenario. Beyond this, we show that without extra re-training, the proposed PGMA-Net can solve bbox-level and cross-domain FSS, co-segmentation, zero-shot segmentation (ZSS) tasks, leading an any-shot segmentation framework.
Delphic Costs and Benefits in Web Search: A utilitarian and historical analysis
Aug 15, 2023We present a new framework to conceptualize and operationalize the total user experience of search, by studying the entirety of a search journey from an utilitarian point of view. Web search engines are widely perceived as "free". But search requires time and effort: in reality there are many intermingled non-monetary costs (e.g. time costs, cognitive costs, interactivity costs) and the benefits may be marred by various impairments, such as misunderstanding and misinformation. This characterization of costs and benefits appears to be inherent to the human search for information within the pursuit of some larger task: most of the costs and impairments can be identified in interactions with any web search engine, interactions with public libraries, and even in interactions with ancient oracles. To emphasize this innate connection, we call these costs and benefits Delphic, in contrast to explicitly financial costs and benefits. Our main thesis is that the users' satisfaction with a search engine mostly depends on their experience of Delphic cost and benefits, in other words on their utility. The consumer utility is correlated with classic measures of search engine quality, such as ranking, precision, recall, etc., but is not completely determined by them. To argue our thesis, we catalog the Delphic costs and benefits and show how the development of search engines over the last quarter century, from classic Information Retrieval roots to the integration of Large Language Models, was driven to a great extent by the quest of decreasing Delphic costs and increasing Delphic benefits. We hope that the Delphic costs framework will engender new ideas and new research for evaluating and improving the web experience for everyone.
Deep reinforcement learning for process design: Review and perspective
Aug 15, 2023The transformation towards renewable energy and feedstock supply in the chemical industry requires new conceptual process design approaches. Recently, breakthroughs in artificial intelligence offer opportunities to accelerate this transition. Specifically, deep reinforcement learning, a subclass of machine learning, has shown the potential to solve complex decision-making problems and aid sustainable process design. We survey state-of-the-art research in reinforcement learning for process design through three major elements: (i) information representation, (ii) agent architecture, and (iii) environment and reward. Moreover, we discuss perspectives on underlying challenges and promising future works to unfold the full potential of reinforcement learning for process design in chemical engineering.
Unlimited Knowledge Distillation for Action Recognition in the Dark
Aug 18, 2023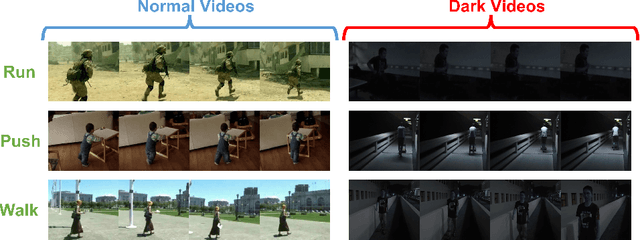

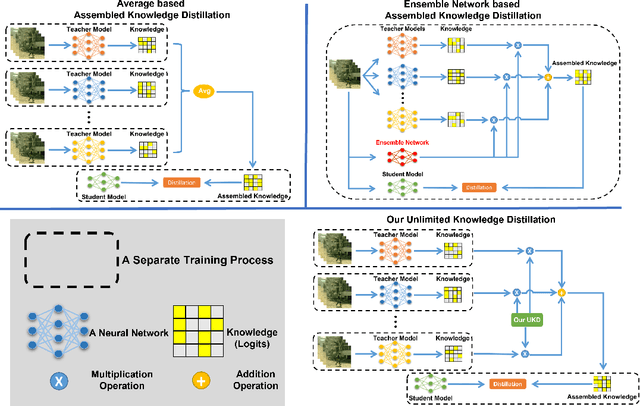

Dark videos often lose essential information, which causes the knowledge learned by networks is not enough to accurately recognize actions. Existing knowledge assembling methods require massive GPU memory to distill the knowledge from multiple teacher models into a student model. In action recognition, this drawback becomes serious due to much computation required by video process. Constrained by limited computation source, these approaches are infeasible. To address this issue, we propose an unlimited knowledge distillation (UKD) in this paper. Compared with existing knowledge assembling methods, our UKD can effectively assemble different knowledge without introducing high GPU memory consumption. Thus, the number of teaching models for distillation is unlimited. With our UKD, the network's learned knowledge can be remarkably enriched. Our experiments show that the single stream network distilled with our UKD even surpasses a two-stream network. Extensive experiments are conducted on the ARID dataset.