 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CTP-Net: Character Texture Perception Network for Document Image Forgery Localization
Aug 04, 2023

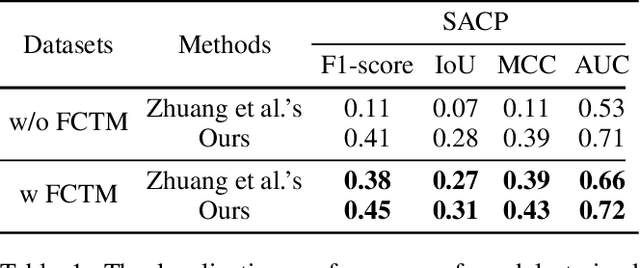
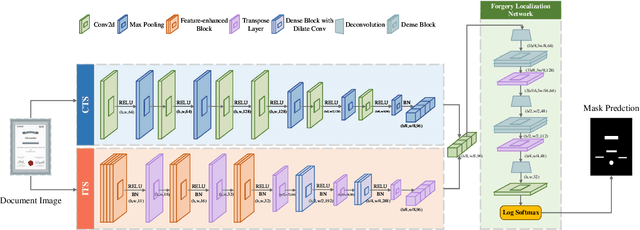
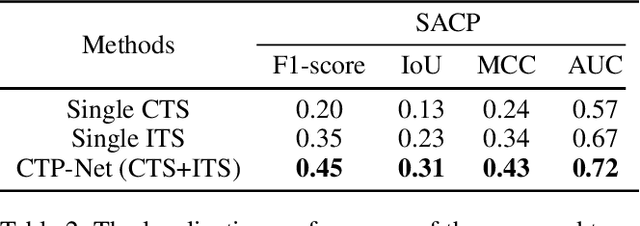
Due to the progression of information technology in recent years, document images have been widely disseminated in social networks. With the help of powerful image editing tools, document images are easily forged without leaving visible manipulation traces, which leads to severe issues if significant information is falsified for malicious use. Therefore, the research of document image forensics is worth further exploring. In a document image, the character with specific semantic information is most vulnerable to tampering, for which capturing the forgery traces of the character is the key to localizing the forged region in document images. Considering both character and image textures, in this paper, we propose a Character Texture Perception Network (CTP-Net) to localize the forgery of document images. Based on optical character recognition, a Character Texture Stream (CTS) is designed to capture features of text areas that are essential components of a document image. Meanwhile, texture features of the whole document image are exploited by an Image Texture Stream (ITS). Combining the features extracted from the CTS and the ITS, the CTP-Net can reveal more subtle forgery traces from document images. To overcome the challenge caused by the lack of fake document images, we design a data generation strategy that is utilized to construct a Fake Chinese Trademark dataset (FCTM). Through a series of experiments, we show that the proposed CTP-Net is able to capture tampering traces in document images, especially in text regions. Experimental results demonstrate that CTP-Net can localize multi-scale forged areas in document images and outperform the state-of-the-art forgery localization methods.
Covid-19 Public Sentiment Analysis for Indian Tweets Classification
Aug 01, 2023
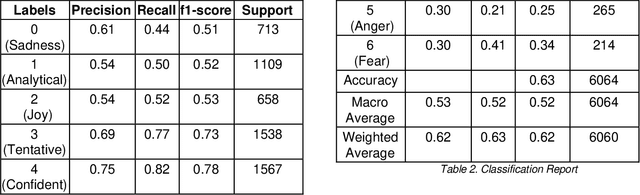
When any extraordinary event takes place in the world wide area, it is the social media that acts as the fastest carrier of the news along with the consequences dealt with that event. One can gather much information through social networks regarding the sentiments, behavior, and opinions of the people. In this paper, we focus mainly on sentiment analysis of twitter data of India which comprises of COVID-19 tweets. We show how Twitter data has been extracted and then run sentimental analysis queries on it. This is helpful to analyze the information in the tweets where opinions are highly unstructured, heterogeneous, and are either positive or negative or neutral in some cases.
UniTR: A Unified and Efficient Multi-Modal Transformer for Bird's-Eye-View Representation
Aug 15, 2023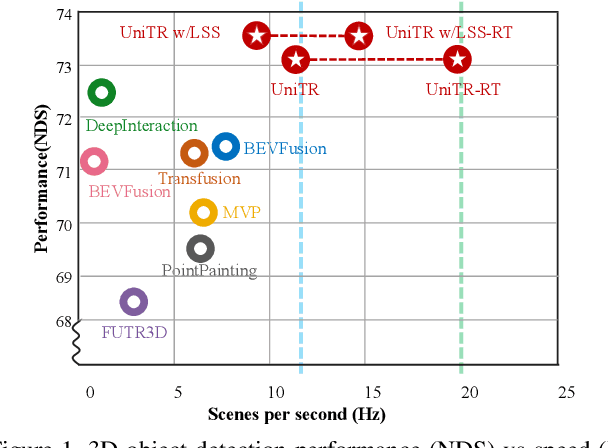
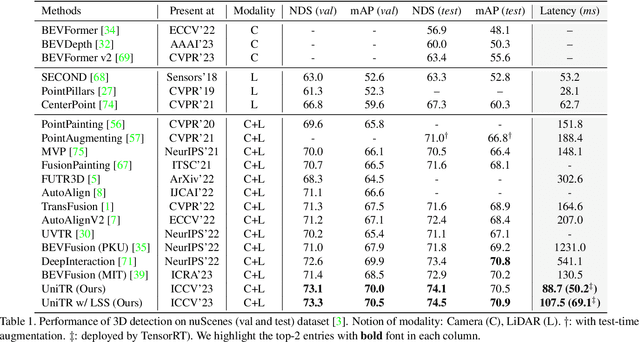
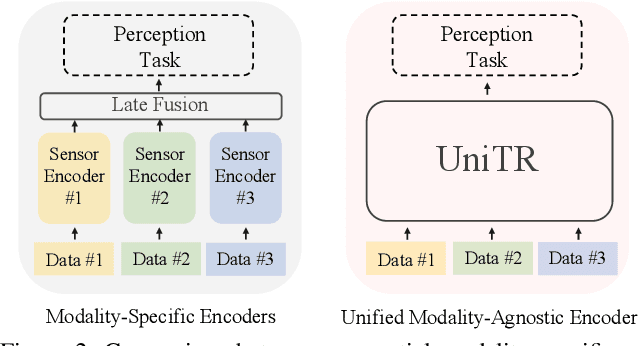
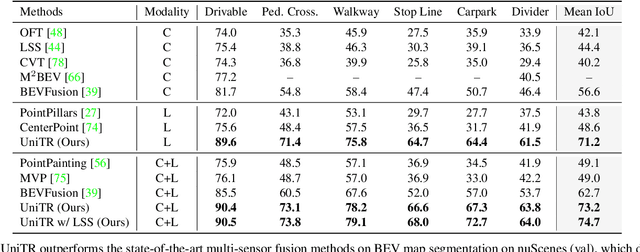
Jointly processing information from multiple sensors is crucial to achieving accurate and robust perception for reliable autonomous driving systems. However, current 3D perception research follows a modality-specific paradigm, leading to additional computation overheads and inefficient collaboration between different sensor data. In this paper, we present an efficient multi-modal backbone for outdoor 3D perception named UniTR, which processes a variety of modalities with unified modeling and shared parameters. Unlike previous works, UniTR introduces a modality-agnostic transformer encoder to handle these view-discrepant sensor data for parallel modal-wise representation learning and automatic cross-modal interaction without additional fusion steps. More importantly, to make full use of these complementary sensor types, we present a novel multi-modal integration strategy by both considering semantic-abundant 2D perspective and geometry-aware 3D sparse neighborhood relations. UniTR is also a fundamentally task-agnostic backbone that naturally supports different 3D perception tasks. It sets a new state-of-the-art performance on the nuScenes benchmark, achieving +1.1 NDS higher for 3D object detection and +12.0 higher mIoU for BEV map segmentation with lower inference latency. Code will be available at https://github.com/Haiyang-W/UniTR .
Brain-Inspired Computational Intelligence via Predictive Coding
Aug 15, 2023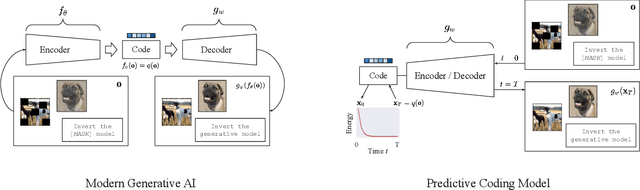
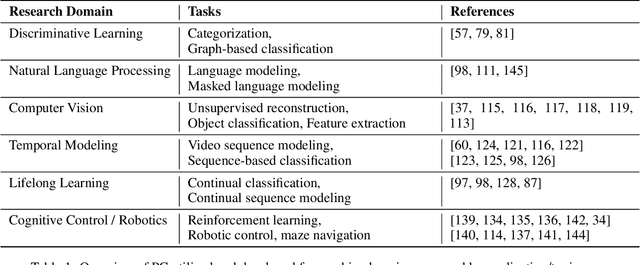
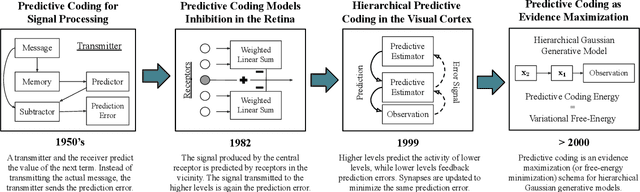
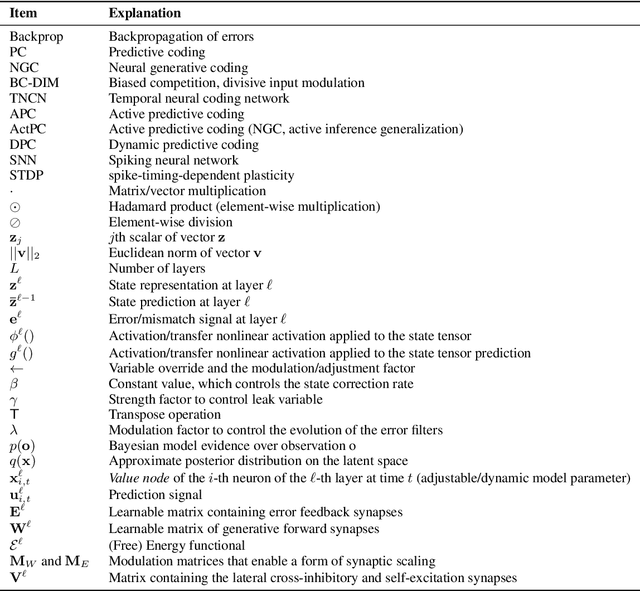
Artificial intelligence (AI) is rapidly becoming one of the key technologies of this century. The majority of results in AI thus far have been achieved using deep neural networks trained with the error backpropagation learning algorithm. However, the ubiquitous adoption of this approach has highlighted some important limitations such as substantial computational cost, difficulty in quantifying uncertainty, lack of robustness, unreliability, and biological implausibility. It is possible that addressing these limitations may require schemes that are inspired and guided by neuroscience theories. One such theory, called predictive coding (PC), has shown promising performance in machine intelligence tasks, exhibiting exciting properties that make it potentially valuable for the machine learning community: PC can model information processing in different brain areas, can be used in cognitive control and robotics, and has a solid mathematical grounding in variational inference, offering a powerful inversion scheme for a specific class of continuous-state generative models. With the hope of foregrounding research in this direction, we survey the literature that has contributed to this perspective, highlighting the many ways that PC might play a role in the future of machine learning and computational intelligence at large.
LaFiCMIL: Rethinking Large File Classification from the Perspective of Correlated Multiple Instance Learning
Aug 15, 2023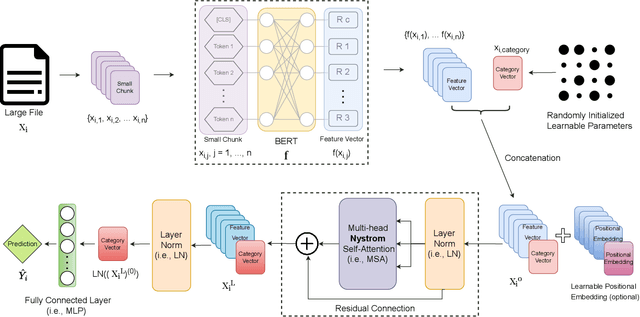
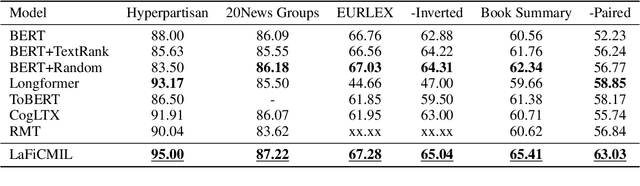
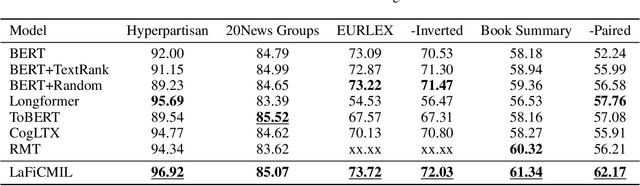
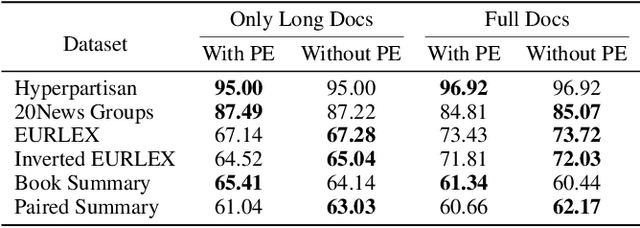
Transformer-based models, such as BERT, have revolutionized various language tasks, but still struggle with large file classification due to their input limit (e.g., 512 tokens). Despite several attempts to alleviate this limitation, no method consistently excels across all benchmark datasets, primarily because they can only extract partial essential information from the input file. Additionally, they fail to adapt to the varied properties of different types of large files. In this work, we tackle this problem from the perspective of correlated multiple instance learning. The proposed approach, LaFiCMIL, serves as a versatile framework applicable to various large file classification tasks covering binary, multi-class, and multi-label classification tasks, spanning various domains including Natural Language Processing, Programming Language Processing, and Android Analysis. To evaluate its effectiveness, we employ eight benchmark datasets pertaining to Long Document Classification, Code Defect Detection, and Android Malware Detection. Leveraging BERT-family models as feature extractors, our experimental results demonstrate that LaFiCMIL achieves new state-of-the-art performance across all benchmark datasets. This is largely attributable to its capability of scaling BERT up to nearly 20K tokens, running on a single Tesla V-100 GPU with 32G of memory.
Accurate Eye Tracking from Dense 3D Surface Reconstructions using Single-Shot Deflectometry
Aug 15, 2023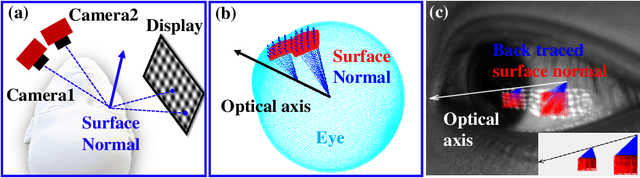

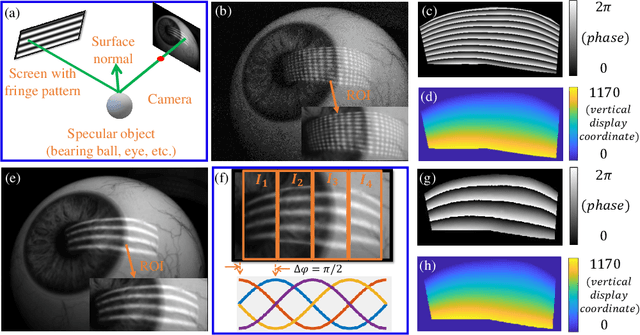
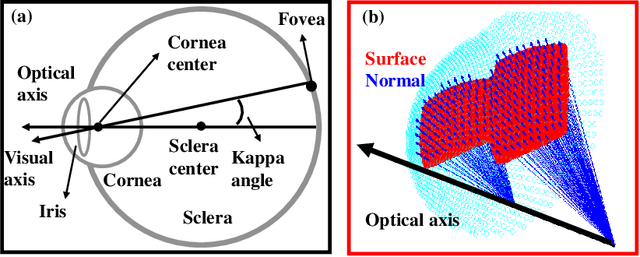
Eye-tracking plays a crucial role in the development of virtual reality devices, neuroscience research, and psychology. Despite its significance in numerous applications, achieving an accurate, robust, and fast eye-tracking solution remains a considerable challenge for current state-of-the-art methods. While existing reflection-based techniques (e.g., "glint tracking") are considered the most accurate, their performance is limited by their reliance on sparse 3D surface data acquired solely from the cornea surface. In this paper, we rethink the way how specular reflections can be used for eye tracking: We propose a novel method for accurate and fast evaluation of the gaze direction that exploits teachings from single-shot phase-measuring-deflectometry (PMD). In contrast to state-of-the-art reflection-based methods, our method acquires dense 3D surface information of both cornea and sclera within only one single camera frame (single-shot). Improvements in acquired reflection surface points("glints") of factors $>3300 \times$ are easily achievable. We show the feasibility of our approach with experimentally evaluated gaze errors of only $\leq 0.25^\circ$ demonstrating a significant improvement over the current state-of-the-art.
Graph-Segmenter: Graph Transformer with Boundary-aware Attention for Semantic Segmentation
Aug 15, 2023The transformer-based semantic segmentation approaches, which divide the image into different regions by sliding windows and model the relation inside each window, have achieved outstanding success. However, since the relation modeling between windows was not the primary emphasis of previous work, it was not fully utilized. To address this issue, we propose a Graph-Segmenter, including a Graph Transformer and a Boundary-aware Attention module, which is an effective network for simultaneously modeling the more profound relation between windows in a global view and various pixels inside each window as a local one, and for substantial low-cost boundary adjustment. Specifically, we treat every window and pixel inside the window as nodes to construct graphs for both views and devise the Graph Transformer. The introduced boundary-aware attention module optimizes the edge information of the target objects by modeling the relationship between the pixel on the object's edge. Extensive experiments on three widely used semantic segmentation datasets (Cityscapes, ADE-20k and PASCAL Context) demonstrate that our proposed network, a Graph Transformer with Boundary-aware Attention, can achieve state-of-the-art segmentation performance.
3D Scene Diffusion Guidance using Scene Graphs
Aug 08, 2023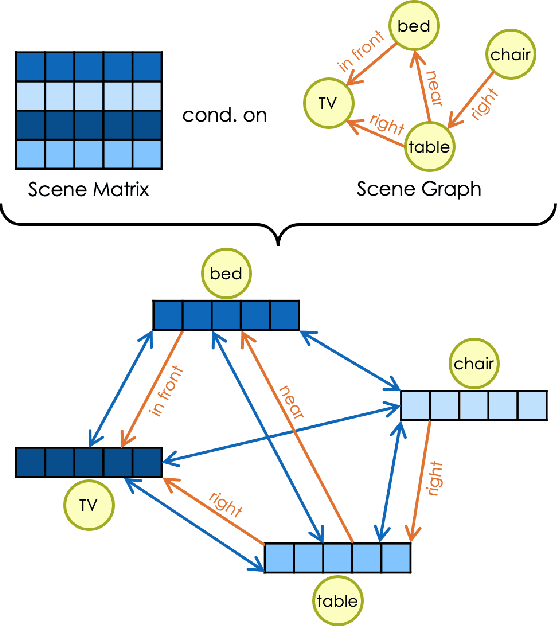

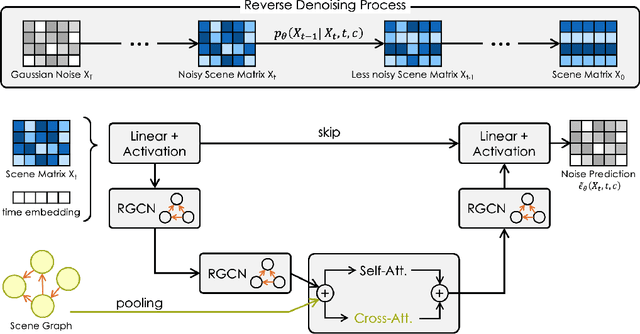
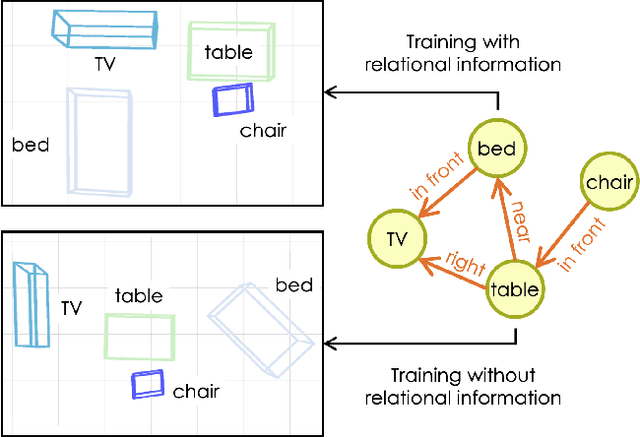
Guided synthesis of high-quality 3D scenes is a challenging task. Diffusion models have shown promise in generating diverse data, including 3D scenes. However, current methods rely directly on text embeddings for controlling the generation, limiting the incorporation of complex spatial relationships between objects. We propose a novel approach for 3D scene diffusion guidance using scene graphs. To leverage the relative spatial information the scene graphs provide, we make use of relational graph convolutional blocks within our denoising network. We show that our approach significantly improves the alignment between scene description and generated scene.
Physics-informed neural networks for blood flow inverse problems
Aug 02, 2023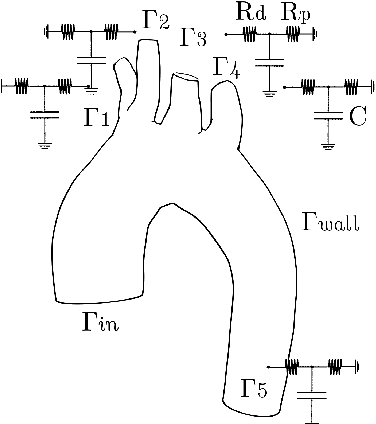

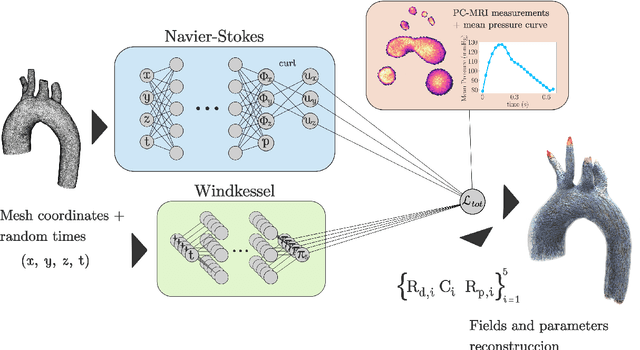
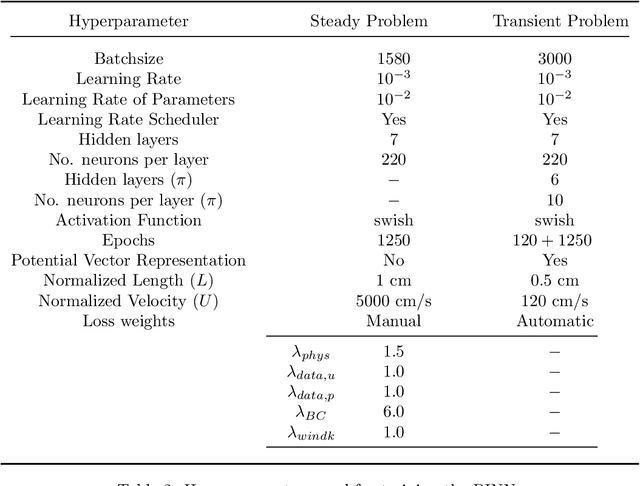
Physics-informed neural networks (PINNs) have emerged as a powerful tool for solving inverse problems, especially in cases where no complete information about the system is known and scatter measurements are available. This is especially useful in hemodynamics since the boundary information is often difficult to model, and high-quality blood flow measurements are generally hard to obtain. In this work, we use the PINNs methodology for estimating reduced-order model parameters and the full velocity field from scatter 2D noisy measurements in the ascending aorta. The results show stable and accurate parameter estimations when using the method with simulated data, while the velocity reconstruction shows dependence on the measurement quality and the flow pattern complexity. The method allows for solving clinical-relevant inverse problems in hemodynamics and complex coupled physical systems.
Advancing Relation Extraction through Language Probing with Exemplars from Set Co-Expansion
Aug 18, 2023
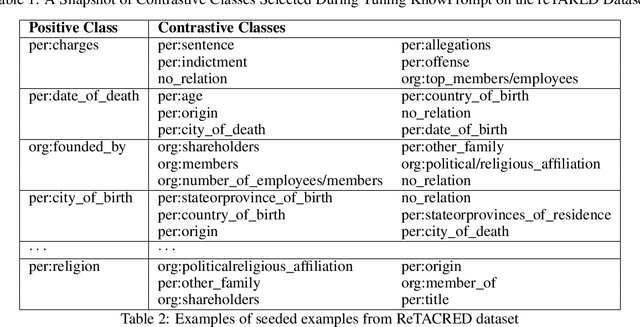
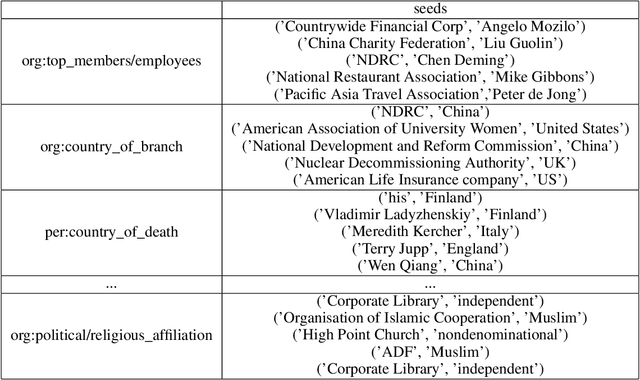

Relation Extraction (RE) is a pivotal task in automatically extracting structured information from unstructured text. In this paper, we present a multi-faceted approach that integrates representative examples and through co-set expansion. The primary goal of our method is to enhance relation classification accuracy and mitigating confusion between contrastive classes. Our approach begins by seeding each relationship class with representative examples. Subsequently, our co-set expansion algorithm enriches training objectives by incorporating similarity measures between target pairs and representative pairs from the target class. Moreover, the co-set expansion process involves a class ranking procedure that takes into account exemplars from contrastive classes. Contextual details encompassing relation mentions are harnessed via context-free Hearst patterns to ascertain contextual similarity. Empirical evaluation demonstrates the efficacy of our co-set expansion approach, resulting in a significant enhancement of relation classification performance. Our method achieves an observed margin of at least 1 percent improvement in accuracy in most settings, on top of existing fine-tuning approaches. To further refine our approach, we conduct an in-depth analysis that focuses on tuning contrastive examples. This strategic selection and tuning effectively reduce confusion between classes sharing similarities, leading to a more precise classification process. Experimental results underscore the effectiveness of our proposed framework for relation extraction. The synergy between co-set expansion and context-aware prompt tuning substantially contributes to improved classification accuracy. Furthermore, the reduction in confusion between contrastive classes through contrastive examples tuning validates the robustness and reliability of our method.