 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Discovering the Symptom Patterns of COVID-19 from Recovered and Deceased Patients Using Apriori Association Rule Mining
Aug 13, 2023
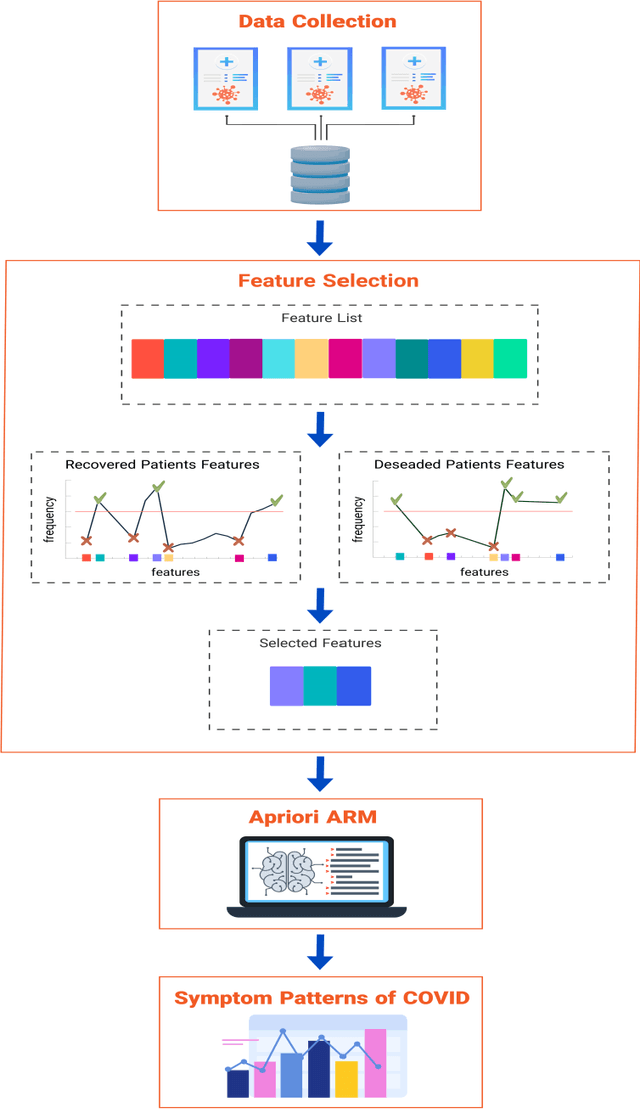

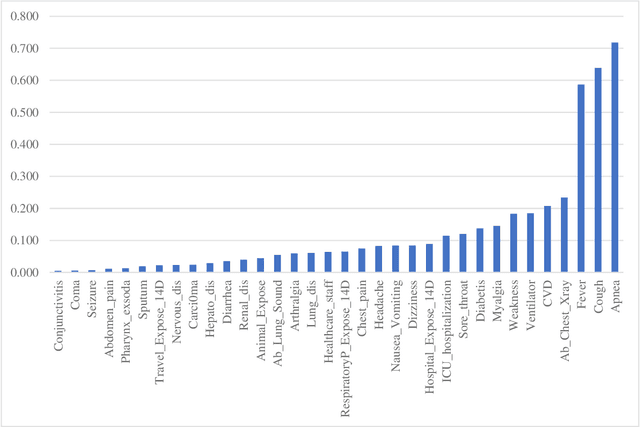
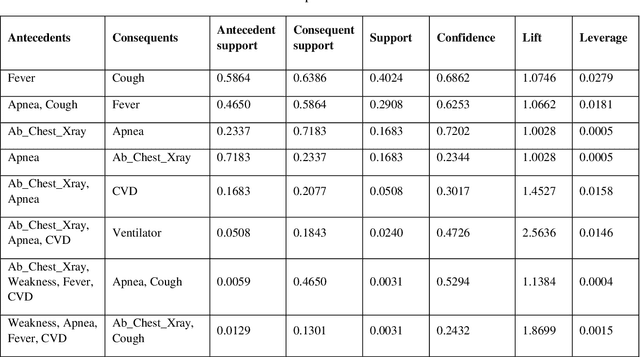
The COVID-19 pandemic has a devastating impact globally, claiming millions of lives and causing significant social and economic disruptions. In order to optimize decision-making and allocate limited resources, it is essential to identify COVID-19 symptoms and determine the severity of each case. Machine learning algorithms offer a potent tool in the medical field, particularly in mining clinical datasets for useful information and guiding scientific decisions. Association rule mining is a machine learning technique for extracting hidden patterns from data. This paper presents an application of association rule mining based Apriori algorithm to discover symptom patterns from COVID-19 patients. The study, using 2875 records of patient, identified the most common symptoms as apnea (72%), cough (64%), fever (59%), weakness (18%), myalgia (14.5%), and sore throat (12%). The proposed method provides clinicians with valuable insight into disease that can assist them in managing and treating it effectively.
Event-Guided Procedure Planning from Instructional Videos with Text Supervision
Aug 17, 2023In this work, we focus on the task of procedure planning from instructional videos with text supervision, where a model aims to predict an action sequence to transform the initial visual state into the goal visual state. A critical challenge of this task is the large semantic gap between observed visual states and unobserved intermediate actions, which is ignored by previous works. Specifically, this semantic gap refers to that the contents in the observed visual states are semantically different from the elements of some action text labels in a procedure. To bridge this semantic gap, we propose a novel event-guided paradigm, which first infers events from the observed states and then plans out actions based on both the states and predicted events. Our inspiration comes from that planning a procedure from an instructional video is to complete a specific event and a specific event usually involves specific actions. Based on the proposed paradigm, we contribute an Event-guided Prompting-based Procedure Planning (E3P) model, which encodes event information into the sequential modeling process to support procedure planning. To further consider the strong action associations within each event, our E3P adopts a mask-and-predict approach for relation mining, incorporating a probabilistic masking scheme for regularization. Extensive experiments on three datasets demonstrate the effectiveness of our proposed model.
Identity-Seeking Self-Supervised Representation Learning for Generalizable Person Re-identification
Aug 17, 2023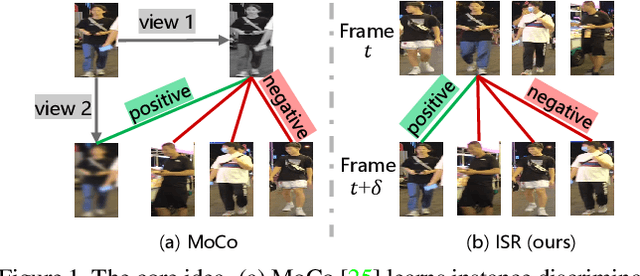
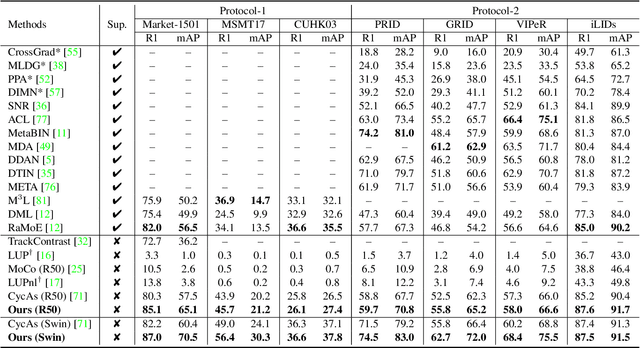
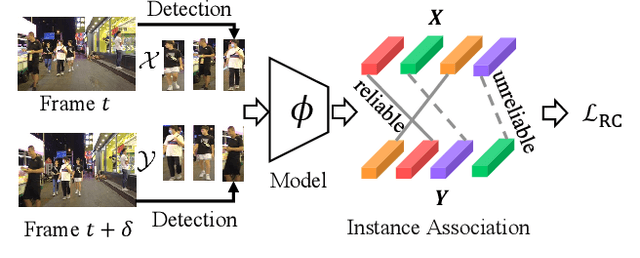
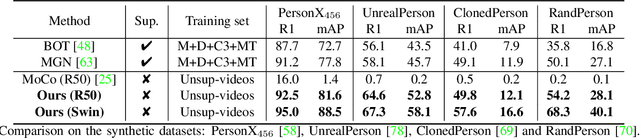
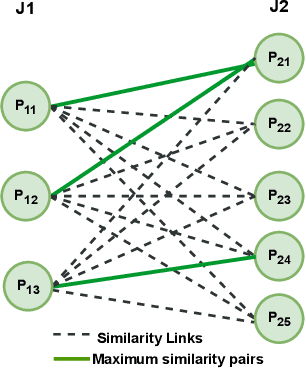
This paper aims to learn a domain-generalizable (DG) person re-identification (ReID) representation from large-scale videos \textbf{without any annotation}. Prior DG ReID methods employ limited labeled data for training due to the high cost of annotation, which restricts further advances. To overcome the barriers of data and annotation, we propose to utilize large-scale unsupervised data for training. The key issue lies in how to mine identity information. To this end, we propose an Identity-seeking Self-supervised Representation learning (ISR) method. ISR constructs positive pairs from inter-frame images by modeling the instance association as a maximum-weight bipartite matching problem. A reliability-guided contrastive loss is further presented to suppress the adverse impact of noisy positive pairs, ensuring that reliable positive pairs dominate the learning process. The training cost of ISR scales approximately linearly with the data size, making it feasible to utilize large-scale data for training. The learned representation exhibits superior generalization ability. \textbf{Without human annotation and fine-tuning, ISR achieves 87.0\% Rank-1 on Market-1501 and 56.4\% Rank-1 on MSMT17}, outperforming the best supervised domain-generalizable method by 5.0\% and 19.5\%, respectively. In the pre-training$\rightarrow$fine-tuning scenario, ISR achieves state-of-the-art performance, with 88.4\% Rank-1 on MSMT17. The code is at \url{https://github.com/dcp15/ISR_ICCV2023_Oral}.
Analysing the Resourcefulness of the Paragraph for Precedence Retrieval
Jul 29, 2023
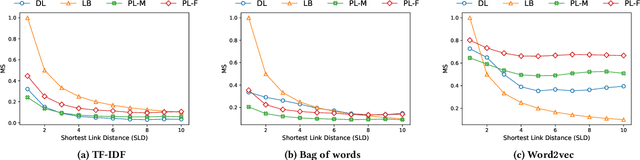
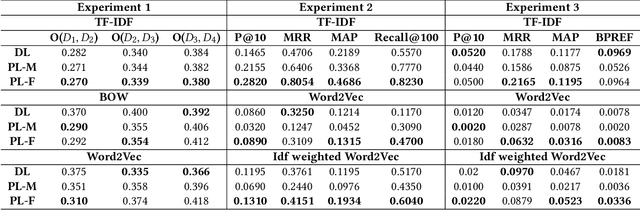
Developing methods for extracting relevant legal information to aid legal practitioners is an active research area. In this regard, research efforts are being made by leveraging different kinds of information, such as meta-data, citations, keywords, sentences, paragraphs, etc. Similar to any text document, legal documents are composed of paragraphs. In this paper, we have analyzed the resourcefulness of paragraph-level information in capturing similarity among judgments for improving the performance of precedence retrieval. We found that the paragraph-level methods could capture the similarity among the judgments with only a few paragraph interactions and exhibit more discriminating power over the baseline document-level method. Moreover, the comparison results on two benchmark datasets for the precedence retrieval on the Indian supreme court judgments task show that the paragraph-level methods exhibit comparable performance with the state-of-the-art methods
Where's the Liability in Harmful AI Speech?
Aug 16, 2023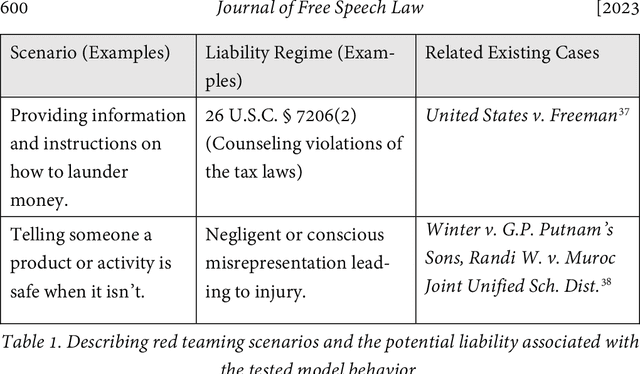


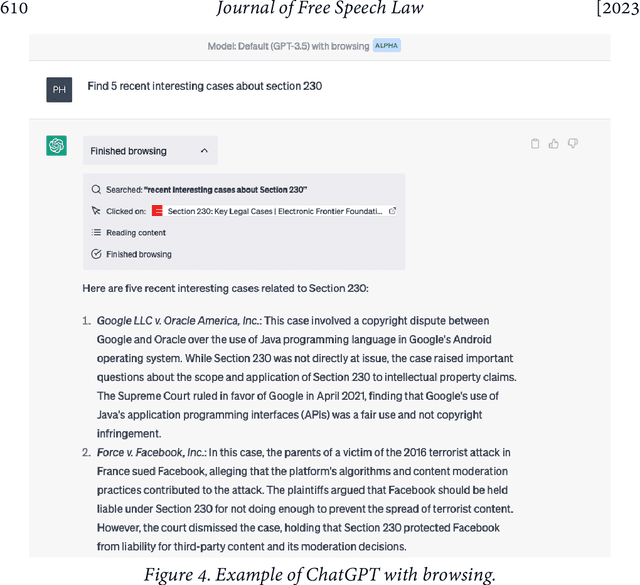
Generative AI, in particular text-based "foundation models" (large models trained on a huge variety of information including the internet), can generate speech that could be problematic under a wide range of liability regimes. Machine learning practitioners regularly "red team" models to identify and mitigate such problematic speech: from "hallucinations" falsely accusing people of serious misconduct to recipes for constructing an atomic bomb. A key question is whether these red-teamed behaviors actually present any liability risk for model creators and deployers under U.S. law, incentivizing investments in safety mechanisms. We examine three liability regimes, tying them to common examples of red-teamed model behaviors: defamation, speech integral to criminal conduct, and wrongful death. We find that any Section 230 immunity analysis or downstream liability analysis is intimately wrapped up in the technical details of algorithm design. And there are many roadblocks to truly finding models (and their associated parties) liable for generated speech. We argue that AI should not be categorically immune from liability in these scenarios and that as courts grapple with the already fine-grained complexities of platform algorithms, the technical details of generative AI loom above with thornier questions. Courts and policymakers should think carefully about what technical design incentives they create as they evaluate these issues.
Expressivity of Spiking Neural Networks
Aug 16, 2023This article studies the expressive power of spiking neural networks where information is encoded in the firing time of neurons. The implementation of spiking neural networks on neuromorphic hardware presents a promising choice for future energy-efficient AI applications. However, there exist very few results that compare the computational power of spiking neurons to arbitrary threshold circuits and sigmoidal neurons. Additionally, it has also been shown that a network of spiking neurons is capable of approximating any continuous function. By using the Spike Response Model as a mathematical model of a spiking neuron and assuming a linear response function, we prove that the mapping generated by a network of spiking neurons is continuous piecewise linear. We also show that a spiking neural network can emulate the output of any multi-layer (ReLU) neural network. Furthermore, we show that the maximum number of linear regions generated by a spiking neuron scales exponentially with respect to the input dimension, a characteristic that distinguishes it significantly from an artificial (ReLU) neuron. Our results further extend the understanding of the approximation properties of spiking neural networks and open up new avenues where spiking neural networks can be deployed instead of artificial neural networks without any performance loss.
Low-Light Image Enhancement with Illumination-Aware Gamma Correction and Complete Image Modelling Network
Aug 16, 2023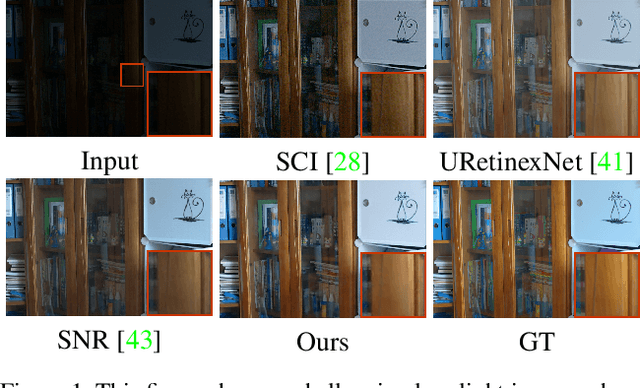

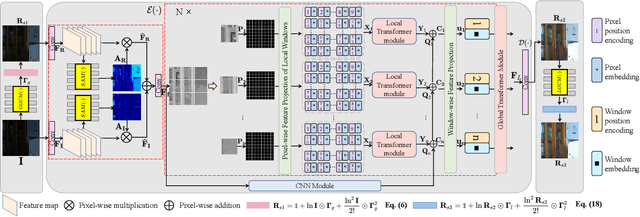
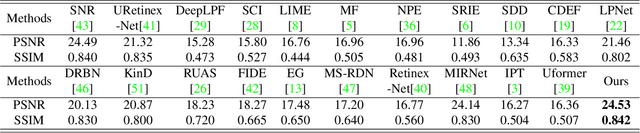
This paper presents a novel network structure with illumination-aware gamma correction and complete image modelling to solve the low-light image enhancement problem. Low-light environments usually lead to less informative large-scale dark areas, directly learning deep representations from low-light images is insensitive to recovering normal illumination. We propose to integrate the effectiveness of gamma correction with the strong modelling capacities of deep networks, which enables the correction factor gamma to be learned in a coarse to elaborate manner via adaptively perceiving the deviated illumination. Because exponential operation introduces high computational complexity, we propose to use Taylor Series to approximate gamma correction, accelerating the training and inference speed. Dark areas usually occupy large scales in low-light images, common local modelling structures, e.g., CNN, SwinIR, are thus insufficient to recover accurate illumination across whole low-light images. We propose a novel Transformer block to completely simulate the dependencies of all pixels across images via a local-to-global hierarchical attention mechanism, so that dark areas could be inferred by borrowing the information from far informative regions in a highly effective manner. Extensive experiments on several benchmark datasets demonstrate that our approach outperforms state-of-the-art methods.
DragNUWA: Fine-grained Control in Video Generation by Integrating Text, Image, and Trajectory
Aug 16, 2023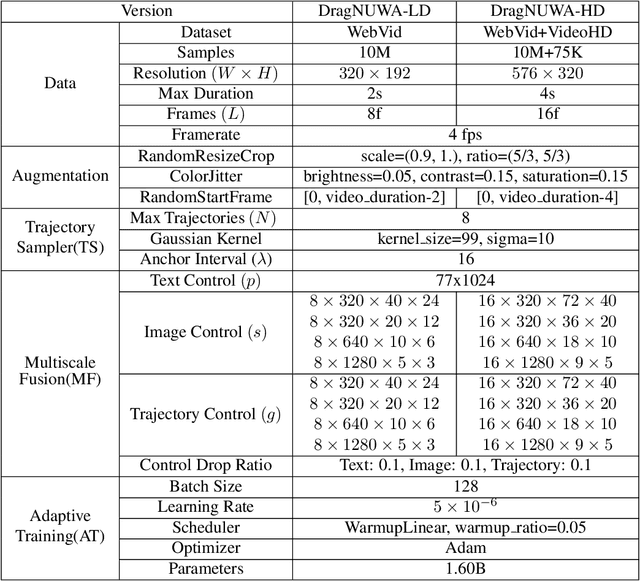

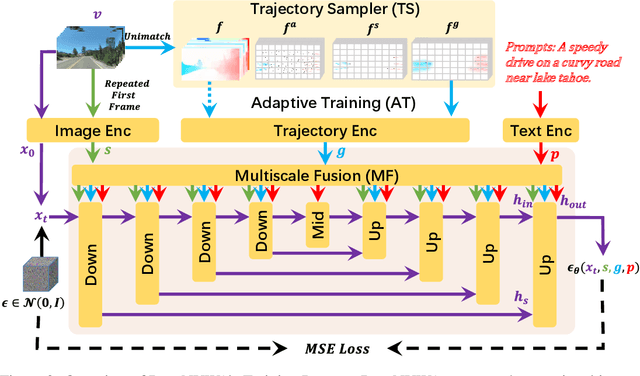

Controllable video generation has gained significant attention in recent years. However, two main limitations persist: Firstly, most existing works focus on either text, image, or trajectory-based control, leading to an inability to achieve fine-grained control in videos. Secondly, trajectory control research is still in its early stages, with most experiments being conducted on simple datasets like Human3.6M. This constraint limits the models' capability to process open-domain images and effectively handle complex curved trajectories. In this paper, we propose DragNUWA, an open-domain diffusion-based video generation model. To tackle the issue of insufficient control granularity in existing works, we simultaneously introduce text, image, and trajectory information to provide fine-grained control over video content from semantic, spatial, and temporal perspectives. To resolve the problem of limited open-domain trajectory control in current research, We propose trajectory modeling with three aspects: a Trajectory Sampler (TS) to enable open-domain control of arbitrary trajectories, a Multiscale Fusion (MF) to control trajectories in different granularities, and an Adaptive Training (AT) strategy to generate consistent videos following trajectories. Our experiments validate the effectiveness of DragNUWA, demonstrating its superior performance in fine-grained control in video generation. The homepage link is \url{https://www.microsoft.com/en-us/research/project/dragnuwa/}
Computer vision-enriched discrete choice models, with an application to residential location choice
Aug 16, 2023Visual imagery is indispensable to many multi-attribute decision situations. Examples of such decision situations in travel behaviour research include residential location choices, vehicle choices, tourist destination choices, and various safety-related choices. However, current discrete choice models cannot handle image data and thus cannot incorporate information embedded in images into their representations of choice behaviour. This gap between discrete choice models' capabilities and the real-world behaviour it seeks to model leads to incomplete and, possibly, misleading outcomes. To solve this gap, this study proposes "Computer Vision-enriched Discrete Choice Models" (CV-DCMs). CV-DCMs can handle choice tasks involving numeric attributes and images by integrating computer vision and traditional discrete choice models. Moreover, because CV-DCMs are grounded in random utility maximisation principles, they maintain the solid behavioural foundation of traditional discrete choice models. We demonstrate the proposed CV-DCM by applying it to data obtained through a novel stated choice experiment involving residential location choices. In this experiment, respondents faced choice tasks with trade-offs between commute time, monthly housing cost and street-level conditions, presented using images. As such, this research contributes to the growing body of literature in the travel behaviour field that seeks to integrate discrete choice modelling and machine learning.
Graph Out-of-Distribution Generalization with Controllable Data Augmentation
Aug 16, 2023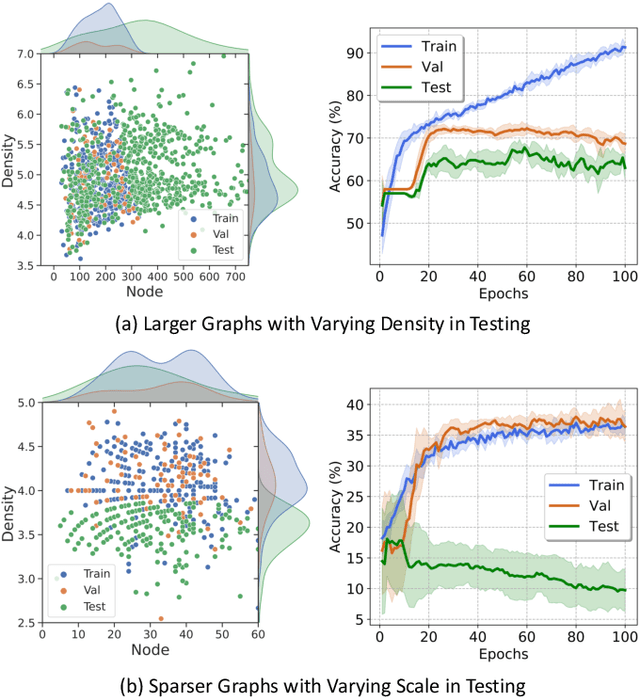
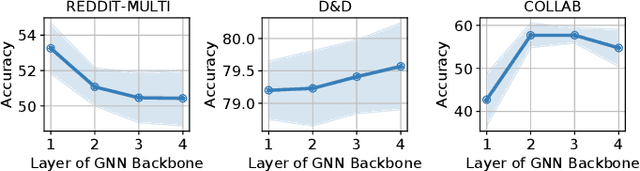
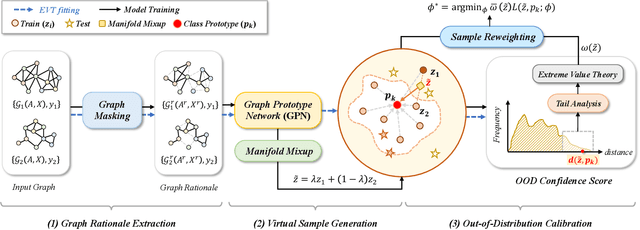
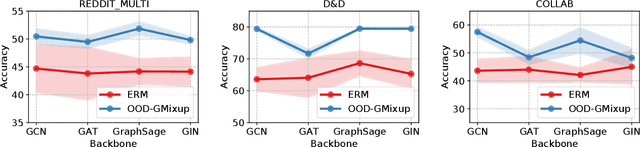
Graph Neural Network (GNN) has demonstrated extraordinary performance in classifying graph properties. However, due to the selection bias of training and testing data (e.g., training on small graphs and testing on large graphs, or training on dense graphs and testing on sparse graphs), distribution deviation is widespread. More importantly, we often observe \emph{hybrid structure distribution shift} of both scale and density, despite of one-sided biased data partition. The spurious correlations over hybrid distribution deviation degrade the performance of previous GNN methods and show large instability among different datasets. To alleviate this problem, we propose \texttt{OOD-GMixup} to jointly manipulate the training distribution with \emph{controllable data augmentation} in metric space. Specifically, we first extract the graph rationales to eliminate the spurious correlations due to irrelevant information. Secondly, we generate virtual samples with perturbation on graph rationale representation domain to obtain potential OOD training samples. Finally, we propose OOD calibration to measure the distribution deviation of virtual samples by leveraging Extreme Value Theory, and further actively control the training distribution by emphasizing the impact of virtual OOD samples. Extensive studies on several real-world datasets on graph classification demonstrate the superiority of our proposed method over state-of-the-art baselines.