 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Evidential Semantic Mapping in Off-road Environments with Uncertainty-aware Bayesian Kernel Inference
Mar 21, 2024
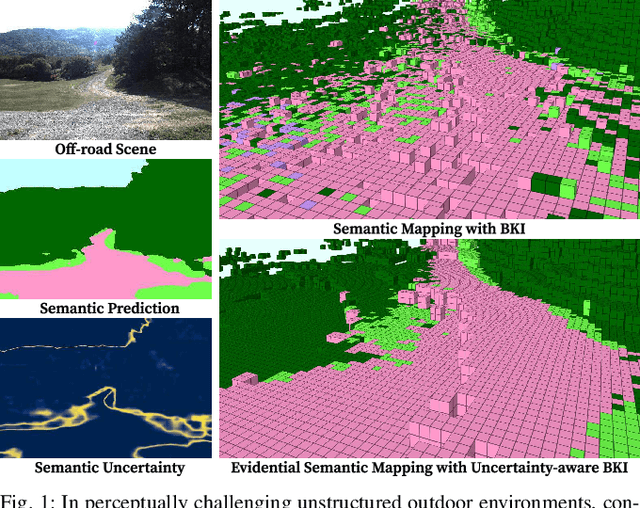
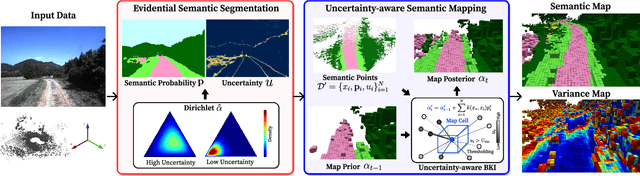
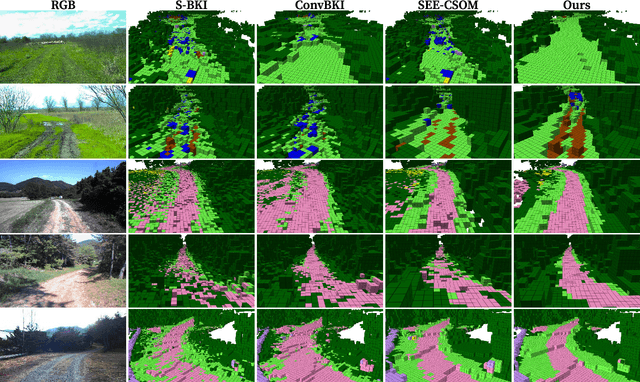

Robotic mapping with Bayesian Kernel Inference (BKI) has shown promise in creating semantic maps by effectively leveraging local spatial information. However, existing semantic mapping methods face challenges in constructing reliable maps in unstructured outdoor scenarios due to unreliable semantic predictions. To address this issue, we propose an evidential semantic mapping, which can enhance reliability in perceptually challenging off-road environments. We integrate Evidential Deep Learning into the semantic segmentation network to obtain the uncertainty estimate of semantic prediction. Subsequently, this semantic uncertainty is incorporated into an uncertainty-aware BKI, tailored to prioritize more confident semantic predictions when accumulating semantic information. By adaptively handling semantic uncertainties, the proposed framework constructs robust representations of the surroundings even in previously unseen environments. Comprehensive experiments across various off-road datasets demonstrate that our framework enhances accuracy and robustness, consistently outperforming existing methods in scenes with high perceptual uncertainties.
RL-CFR: Improving Action Abstraction for Imperfect Information Extensive-Form Games with Reinforcement Learning
Mar 07, 2024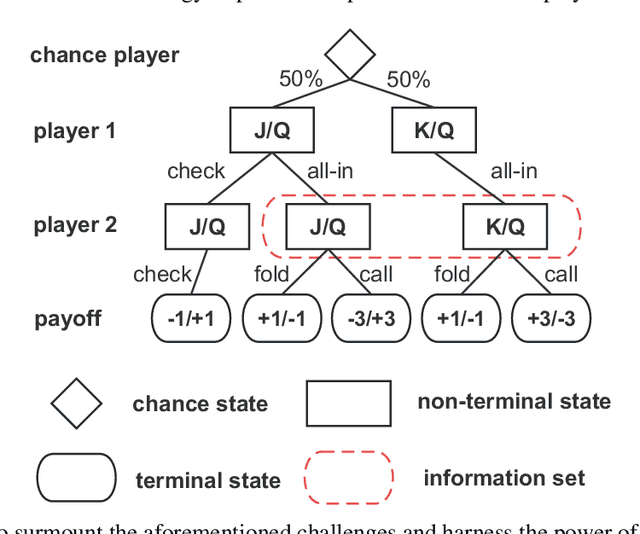
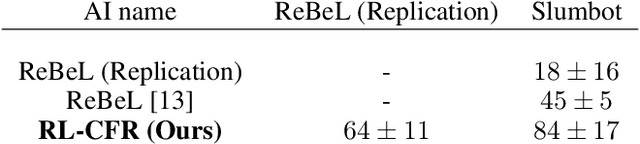
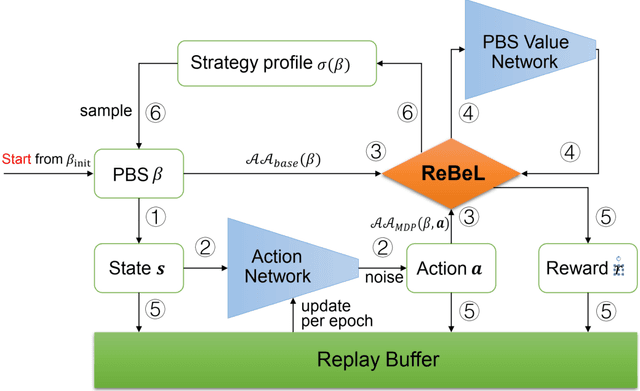
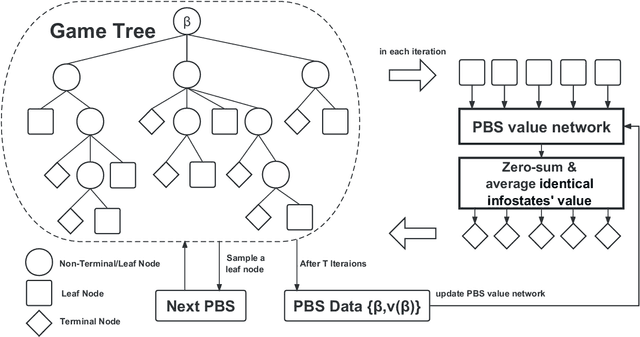
Effective action abstraction is crucial in tackling challenges associated with large action spaces in Imperfect Information Extensive-Form Games (IIEFGs). However, due to the vast state space and computational complexity in IIEFGs, existing methods often rely on fixed abstractions, resulting in sub-optimal performance. In response, we introduce RL-CFR, a novel reinforcement learning (RL) approach for dynamic action abstraction. RL-CFR builds upon our innovative Markov Decision Process (MDP) formulation, with states corresponding to public information and actions represented as feature vectors indicating specific action abstractions. The reward is defined as the expected payoff difference between the selected and default action abstractions. RL-CFR constructs a game tree with RL-guided action abstractions and utilizes counterfactual regret minimization (CFR) for strategy derivation. Impressively, it can be trained from scratch, achieving higher expected payoff without increased CFR solving time. In experiments on Heads-up No-limit Texas Hold'em, RL-CFR outperforms ReBeL's replication and Slumbot, demonstrating significant win-rate margins of $64\pm 11$ and $84\pm 17$ mbb/hand, respectively.
Distributed Robust Learning based Formation Control of Mobile Robots based on Bioinspired Neural Dynamics
Mar 23, 2024This paper addresses the challenges of distributed formation control in multiple mobile robots, introducing a novel approach that enhances real-world practicability. We first introduce a distributed estimator using a variable structure and cascaded design technique, eliminating the need for derivative information to improve the real time performance. Then, a kinematic tracking control method is developed utilizing a bioinspired neural dynamic-based approach aimed at providing smooth control inputs and effectively resolving the speed jump issue. Furthermore, to address the challenges for robots operating with completely unknown dynamics and disturbances, a learning-based robust dynamic controller is developed. This controller provides real time parameter estimates while maintaining its robustness against disturbances. The overall stability of the proposed method is proved with rigorous mathematical analysis. At last, multiple comprehensive simulation studies have shown the advantages and effectiveness of the proposed method.
Machine learning and information theory concepts towards an AI Mathematician
Mar 07, 2024The current state-of-the-art in artificial intelligence is impressive, especially in terms of mastery of language, but not so much in terms of mathematical reasoning. What could be missing? Can we learn something useful about that gap from how the brains of mathematicians go about their craft? This essay builds on the idea that current deep learning mostly succeeds at system 1 abilities -- which correspond to our intuition and habitual behaviors -- but still lacks something important regarding system 2 abilities -- which include reasoning and robust uncertainty estimation. It takes an information-theoretical posture to ask questions about what constitutes an interesting mathematical statement, which could guide future work in crafting an AI mathematician. The focus is not on proving a given theorem but on discovering new and interesting conjectures. The central hypothesis is that a desirable body of theorems better summarizes the set of all provable statements, for example by having a small description length while at the same time being close (in terms of number of derivation steps) to many provable statements.
Contrastive Learning on Multimodal Analysis of Electronic Health Records
Mar 22, 2024Electronic health record (EHR) systems contain a wealth of multimodal clinical data including structured data like clinical codes and unstructured data such as clinical notes. However, many existing EHR-focused studies has traditionally either concentrated on an individual modality or merged different modalities in a rather rudimentary fashion. This approach often results in the perception of structured and unstructured data as separate entities, neglecting the inherent synergy between them. Specifically, the two important modalities contain clinically relevant, inextricably linked and complementary health information. A more complete picture of a patient's medical history is captured by the joint analysis of the two modalities of data. Despite the great success of multimodal contrastive learning on vision-language, its potential remains under-explored in the realm of multimodal EHR, particularly in terms of its theoretical understanding. To accommodate the statistical analysis of multimodal EHR data, in this paper, we propose a novel multimodal feature embedding generative model and design a multimodal contrastive loss to obtain the multimodal EHR feature representation. Our theoretical analysis demonstrates the effectiveness of multimodal learning compared to single-modality learning and connects the solution of the loss function to the singular value decomposition of a pointwise mutual information matrix. This connection paves the way for a privacy-preserving algorithm tailored for multimodal EHR feature representation learning. Simulation studies show that the proposed algorithm performs well under a variety of configurations. We further validate the clinical utility of the proposed algorithm in real-world EHR data.
Enhancing Visual Continual Learning with Language-Guided Supervision
Mar 24, 2024Continual learning (CL) aims to empower models to learn new tasks without forgetting previously acquired knowledge. Most prior works concentrate on the techniques of architectures, replay data, regularization, \etc. However, the category name of each class is largely neglected. Existing methods commonly utilize the one-hot labels and randomly initialize the classifier head. We argue that the scarce semantic information conveyed by the one-hot labels hampers the effective knowledge transfer across tasks. In this paper, we revisit the role of the classifier head within the CL paradigm and replace the classifier with semantic knowledge from pretrained language models (PLMs). Specifically, we use PLMs to generate semantic targets for each class, which are frozen and serve as supervision signals during training. Such targets fully consider the semantic correlation between all classes across tasks. Empirical studies show that our approach mitigates forgetting by alleviating representation drifting and facilitating knowledge transfer across tasks. The proposed method is simple to implement and can seamlessly be plugged into existing methods with negligible adjustments. Extensive experiments based on eleven mainstream baselines demonstrate the effectiveness and generalizability of our approach to various protocols. For example, under the class-incremental learning setting on ImageNet-100, our method significantly improves the Top-1 accuracy by 3.2\% to 6.1\% while reducing the forgetting rate by 2.6\% to 13.1\%.
The Interplay of Learning, Analytics, and Artificial Intelligence in Education
Mar 24, 2024This paper presents a multi dimensional view of AI's role in learning and education, emphasizing the intricate interplay between AI, analytics, and the learning processes. Here, I challenge the prevalent narrow conceptualization of AI as stochastic tools, as exemplified in generative AI, and argue for the importance of alternative conceptualisations of AI. I highlight the differences between human intelligence and artificial information processing, the cognitive diversity inherent in AI algorithms, and posit that AI can also serve as an instrument for understanding human learning. Early learning sciences and AI in Education research, which saw AI as an analogy for human intelligence, have diverged from this perspective, prompting a need to rekindle this connection. The paper presents three unique conceptualizations of AI in education: the externalization of human cognition, the internalization of AI models to influence human thought processes, and the extension of human cognition via tightly integrated human-AI systems. Examples from current research and practice are examined as instances of the three conceptualisations, highlighting the potential value and limitations of each conceptualisation for education, as well as the perils of overemphasis on externalising human cognition as exemplified in today's hype surrounding generative AI tools. The paper concludes with an advocacy for a broader educational approach that includes educating people about AI and innovating educational systems to remain relevant in an AI enabled world.
PCa-RadHop: A Transparent and Lightweight Feed-forward Method for Clinically Significant Prostate Cancer Segmentation
Mar 24, 2024Prostate Cancer is one of the most frequently occurring cancers in men, with a low survival rate if not early diagnosed. PI-RADS reading has a high false positive rate, thus increasing the diagnostic incurred costs and patient discomfort. Deep learning (DL) models achieve a high segmentation performance, although require a large model size and complexity. Also, DL models lack of feature interpretability and are perceived as ``black-boxes" in the medical field. PCa-RadHop pipeline is proposed in this work, aiming to provide a more transparent feature extraction process using a linear model. It adopts the recently introduced Green Learning (GL) paradigm, which offers a small model size and low complexity. PCa-RadHop consists of two stages: Stage-1 extracts data-driven radiomics features from the bi-parametric Magnetic Resonance Imaging (bp-MRI) input and predicts an initial heatmap. To reduce the false positive rate, a subsequent stage-2 is introduced to refine the predictions by including more contextual information and radiomics features from each already detected Region of Interest (ROI). Experiments on the largest publicly available dataset, PI-CAI, show a competitive performance standing of the proposed method among other deep DL models, achieving an area under the curve (AUC) of 0.807 among a cohort of 1,000 patients. Moreover, PCa-RadHop maintains orders of magnitude smaller model size and complexity.
Token Transformation Matters: Towards Faithful Post-hoc Explanation for Vision Transformer
Mar 21, 2024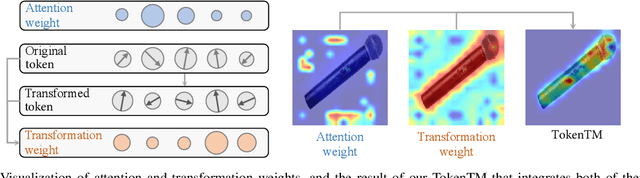
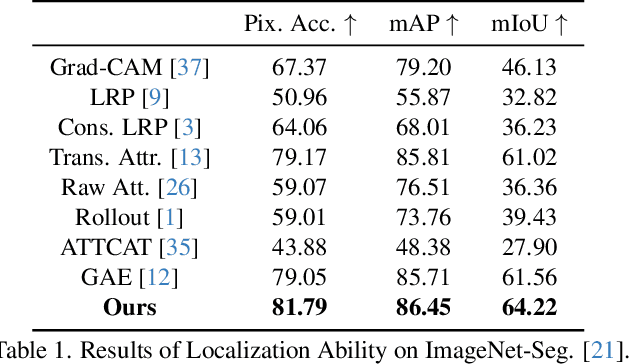
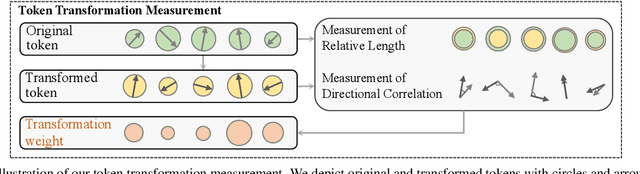
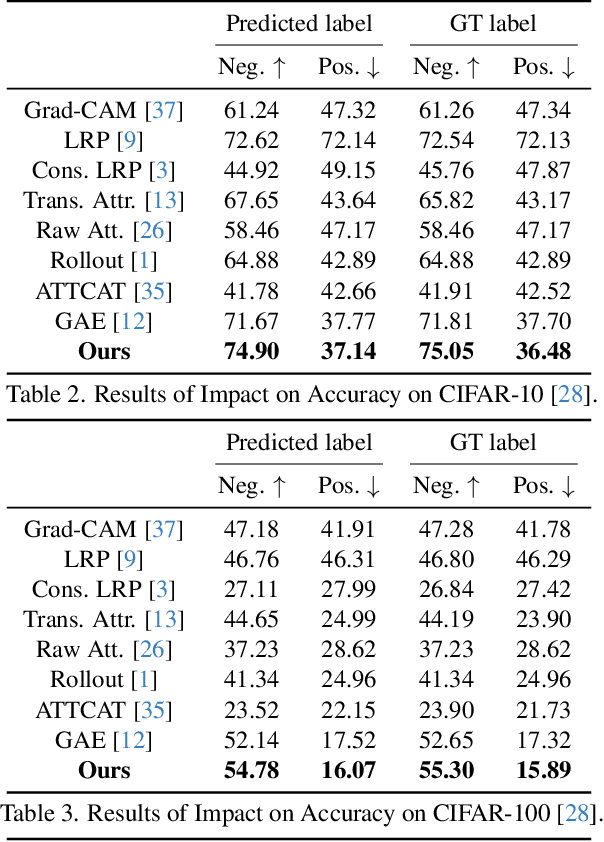
While Transformers have rapidly gained popularity in various computer vision applications, post-hoc explanations of their internal mechanisms remain largely unexplored. Vision Transformers extract visual information by representing image regions as transformed tokens and integrating them via attention weights. However, existing post-hoc explanation methods merely consider these attention weights, neglecting crucial information from the transformed tokens, which fails to accurately illustrate the rationales behind the models' predictions. To incorporate the influence of token transformation into interpretation, we propose TokenTM, a novel post-hoc explanation method that utilizes our introduced measurement of token transformation effects. Specifically, we quantify token transformation effects by measuring changes in token lengths and correlations in their directions pre- and post-transformation. Moreover, we develop initialization and aggregation rules to integrate both attention weights and token transformation effects across all layers, capturing holistic token contributions throughout the model. Experimental results on segmentation and perturbation tests demonstrate the superiority of our proposed TokenTM compared to state-of-the-art Vision Transformer explanation methods.
A Multimodal Approach to Device-Directed Speech Detection with Large Language Models
Mar 21, 2024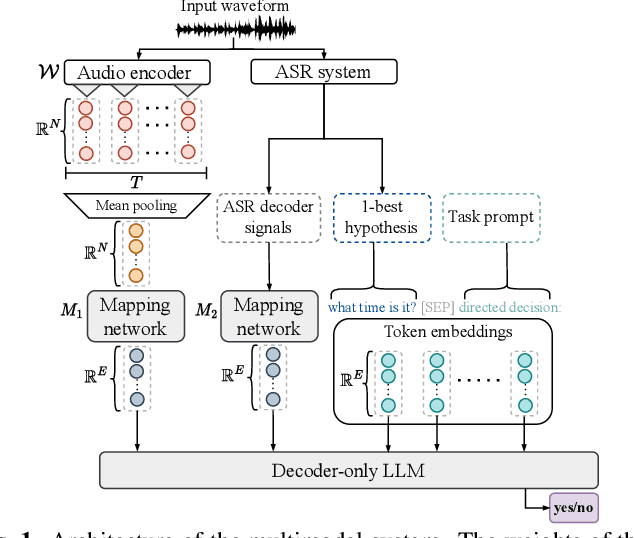
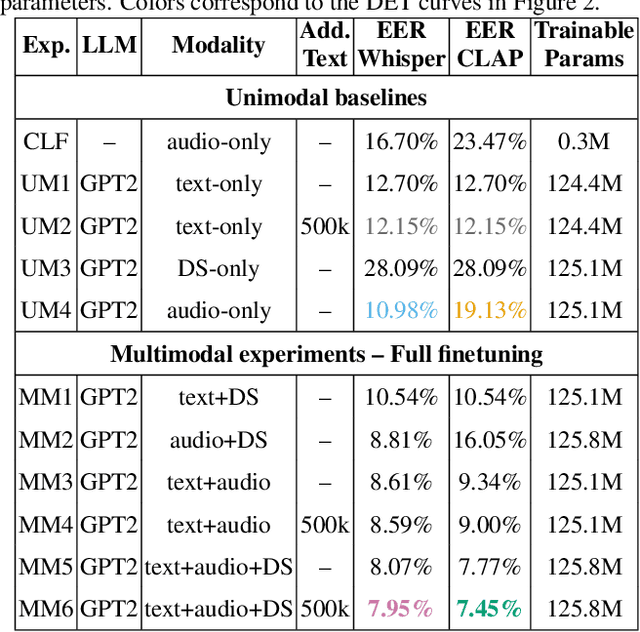
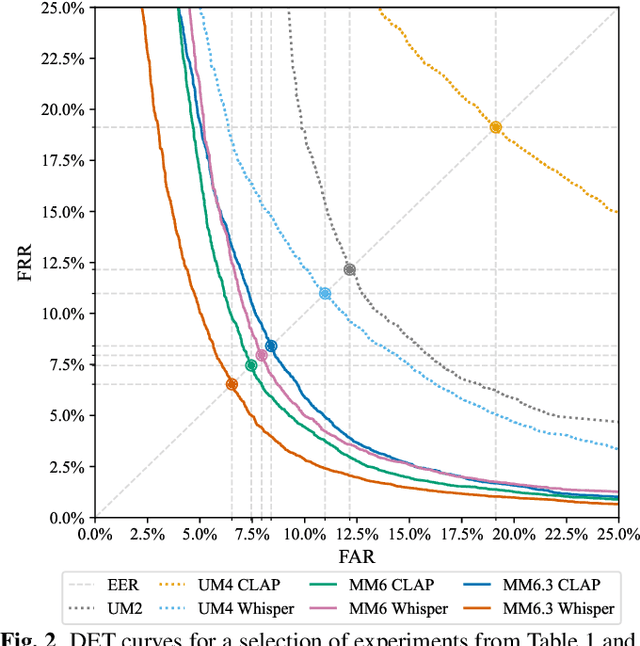

Interactions with virtual assistants typically start with a predefined trigger phrase followed by the user command. To make interactions with the assistant more intuitive, we explore whether it is feasible to drop the requirement that users must begin each command with a trigger phrase. We explore this task in three ways: First, we train classifiers using only acoustic information obtained from the audio waveform. Second, we take the decoder outputs of an automatic speech recognition (ASR) system, such as 1-best hypotheses, as input features to a large language model (LLM). Finally, we explore a multimodal system that combines acoustic and lexical features, as well as ASR decoder signals in an LLM. Using multimodal information yields relative equal-error-rate improvements over text-only and audio-only models of up to 39% and 61%. Increasing the size of the LLM and training with low-rank adaption leads to further relative EER reductions of up to 18% on our dataset.