 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Occ$^2$Net: Robust Image Matching Based on 3D Occupancy Estimation for Occluded Regions
Aug 14, 2023
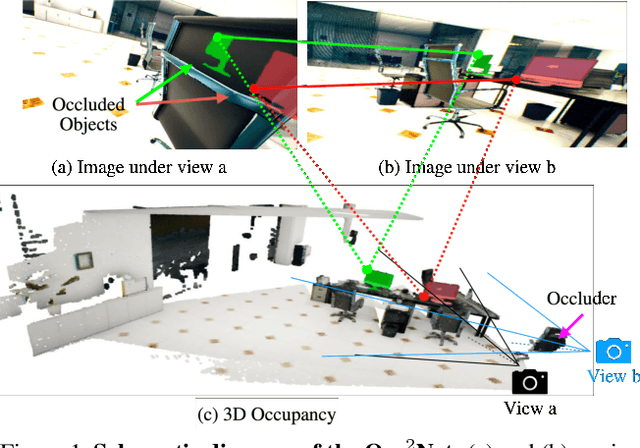
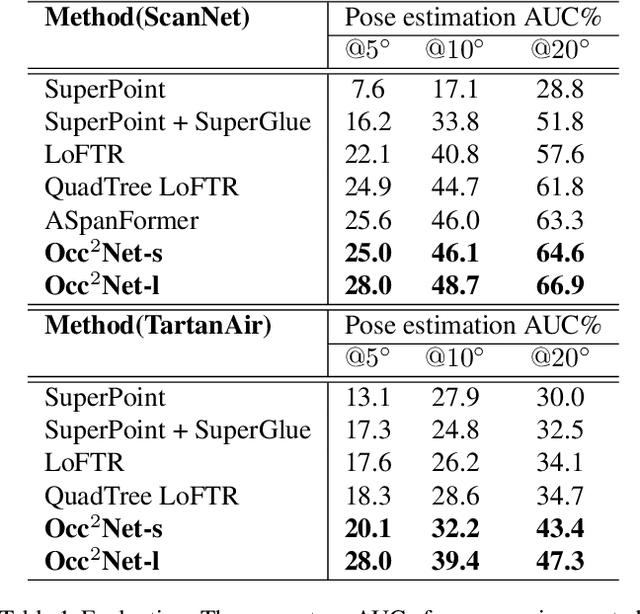
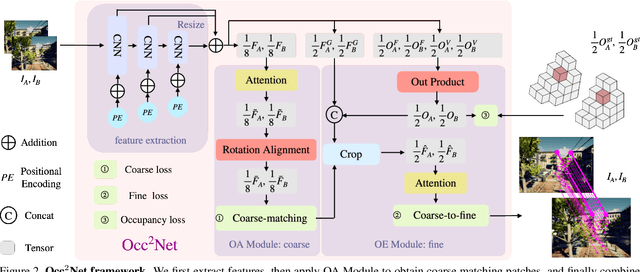
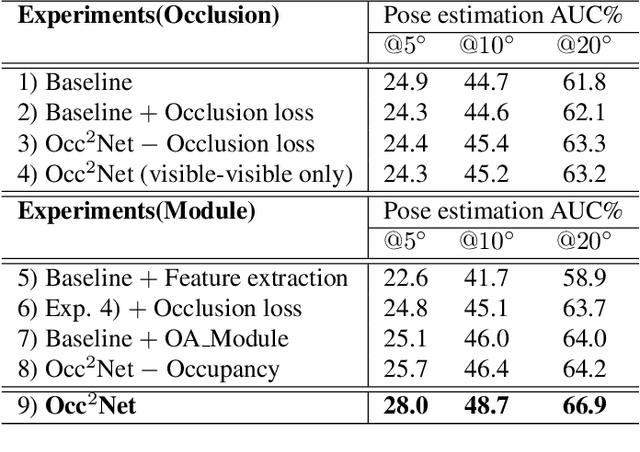
Image matching is a fundamental and critical task in various visual applications, such as Simultaneous Localization and Mapping (SLAM) and image retrieval, which require accurate pose estimation. However, most existing methods ignore the occlusion relations between objects caused by camera motion and scene structure. In this paper, we propose Occ$^2$Net, a novel image matching method that models occlusion relations using 3D occupancy and infers matching points in occluded regions. Thanks to the inductive bias encoded in the Occupancy Estimation (OE) module, it greatly simplifies bootstrapping of a multi-view consistent 3D representation that can then integrate information from multiple views. Together with an Occlusion-Aware (OA) module, it incorporates attention layers and rotation alignment to enable matching between occluded and visible points. We evaluate our method on both real-world and simulated datasets and demonstrate its superior performance over state-of-the-art methods on several metrics, especially in occlusion scenarios.
Enhancing State Estimator for Autonomous Race Car : Leveraging Multi-modal System and Managing Computing Resources
Aug 14, 2023
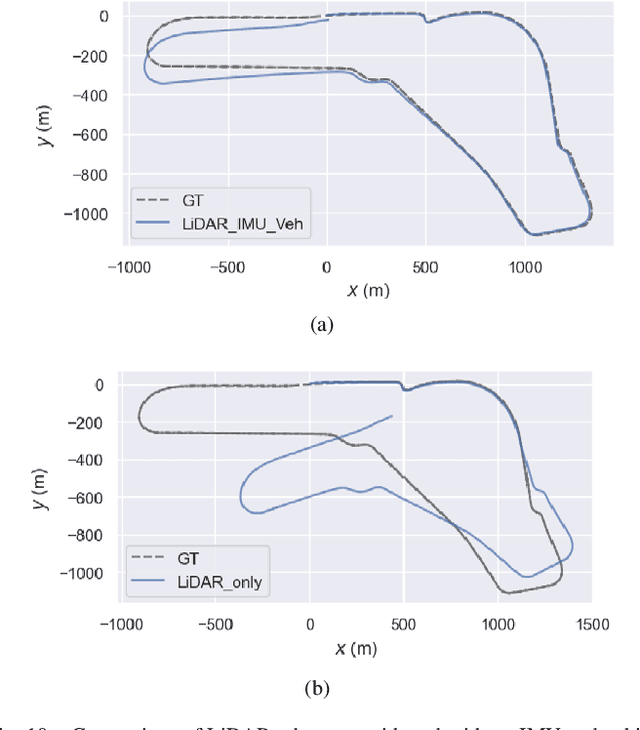
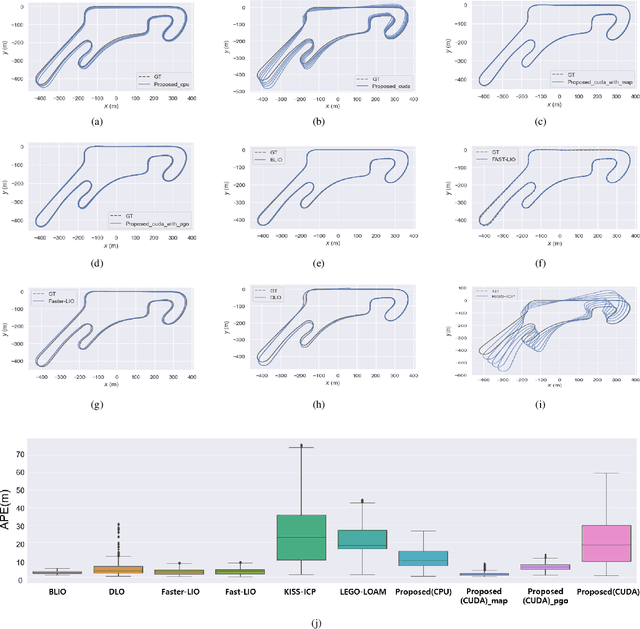
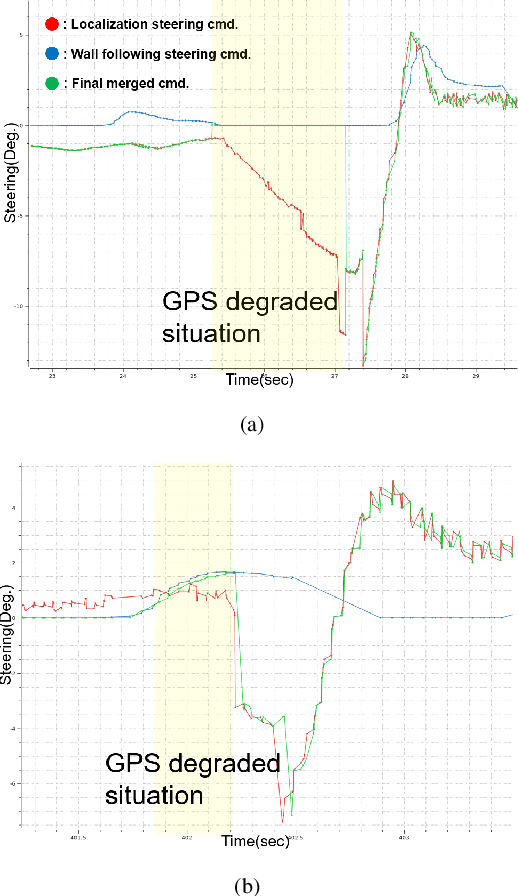
This paper introduces an innovative approach to enhance the state estimator for high-speed autonomous race cars, addressing challenges related to unreliable measurements, localization failures, and computing resource management. The proposed robust localization system utilizes a Bayesian-based probabilistic approach to evaluate multimodal measurements, ensuring the use of credible data for accurate and reliable localization, even in harsh racing conditions. To tackle potential localization failures during intense racing, we present a resilient navigation system. This system enables the race car to continue track-following by leveraging direct perception information in planning and execution, ensuring continuous performance despite localization disruptions. Efficient computing resource management is critical to avoid overload and system failure. We optimize computing resources using an efficient LiDAR-based state estimation method. Leveraging CUDA programming and GPU acceleration, we perform nearest points search and covariance computation efficiently, overcoming CPU bottlenecks. Real-world and simulation tests validate the system's performance and resilience. The proposed approach successfully recovers from failures, effectively preventing accidents and ensuring race car safety.
Localization of DOA trajectories -- Beyond the grid
Aug 14, 2023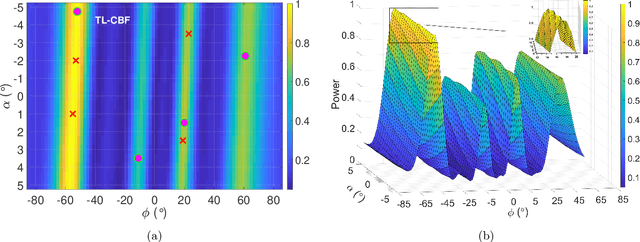
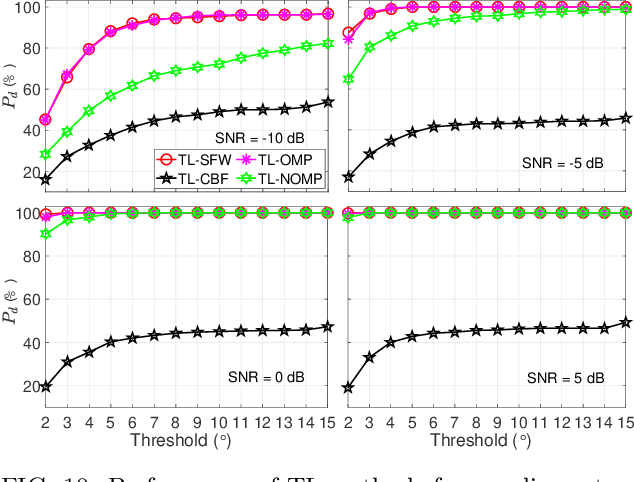
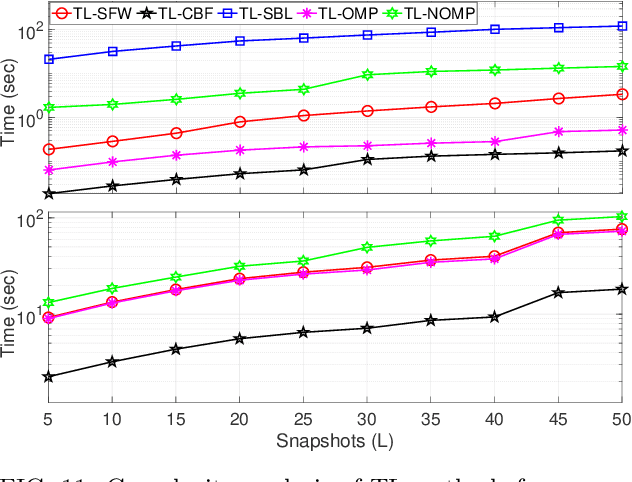
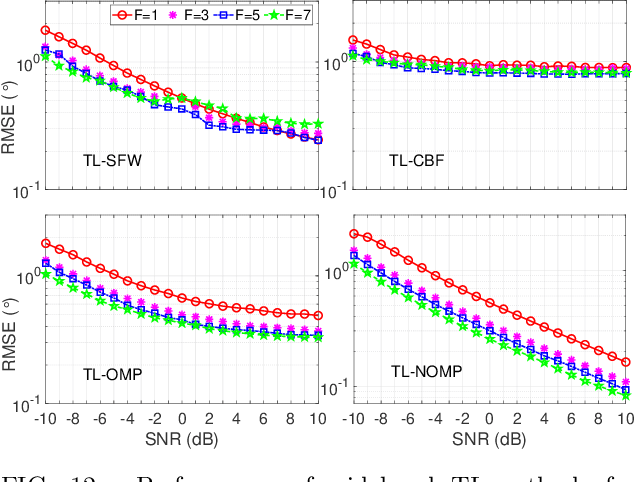
The direction of arrival (DOA) estimation algorithms are crucial in localizing acoustic sources. Traditional localization methods rely on block-level processing to extract the directional information from multiple measurements processed together. However, these methods assume that DOA remains constant throughout the block, which may not be true in practical scenarios. Also, the performance of localization methods is limited when the true parameters do not lie on the parameter search grid. In this paper we propose two trajectory models, namely the polynomial and bandlimited trajectory models, to capture the DOA dynamics. To estimate trajectory parameters, we adopt two gridless algorithms: i) Sliding Frank-Wolfe (SFW), which solves the Beurling LASSO problem and ii) Newtonized Orthogonal Matching Pursuit (NOMP), which improves over OMP using cyclic refinement. Furthermore, we extend our analysis to include wideband processing. The simulation results indicate that the proposed trajectory localization algorithms exhibit improved performance compared to grid-based methods in terms of resolution, robustness to noise, and computational efficiency.
Multi-modal Visual Understanding with Prompts for Semantic Information Disentanglement of Image
May 16, 2023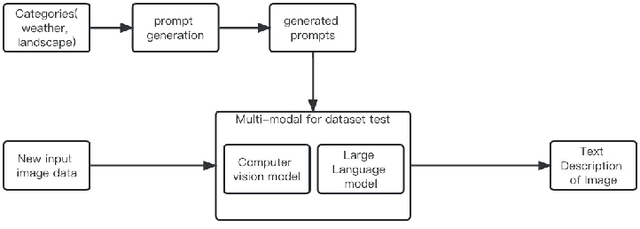
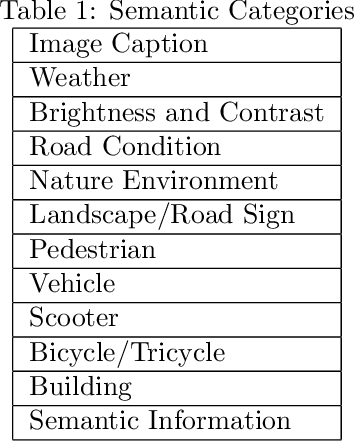


Multi-modal visual understanding of images with prompts involves using various visual and textual cues to enhance the semantic understanding of images. This approach combines both vision and language processing to generate more accurate predictions and recognition of images. By utilizing prompt-based techniques, models can learn to focus on certain features of an image to extract useful information for downstream tasks. Additionally, multi-modal understanding can improve upon single modality models by providing more robust representations of images. Overall, the combination of visual and textual information is a promising area of research for advancing image recognition and understanding. In this paper we will try an amount of prompt design methods and propose a new method for better extraction of semantic information
Exploring how a Generative AI interprets music
Jul 31, 2023We use Google's MusicVAE, a Variational Auto-Encoder with a 512-dimensional latent space to represent a few bars of music, and organize the latent dimensions according to their relevance in describing music. We find that, on average, most latent neurons remain silent when fed real music tracks: we call these "noise" neurons. The remaining few dozens of latent neurons that do fire are called "music neurons". We ask which neurons carry the musical information and what kind of musical information they encode, namely something that can be identified as pitch, rhythm or melody. We find that most of the information about pitch and rhythm is encoded in the first few music neurons: the neural network has thus constructed a couple of variables that non-linearly encode many human-defined variables used to describe pitch and rhythm. The concept of melody only seems to show up in independent neurons for longer sequences of music.
A Bipartite Graph is All We Need for Enhancing Emotional Reasoning with Commonsense Knowledge
Aug 09, 2023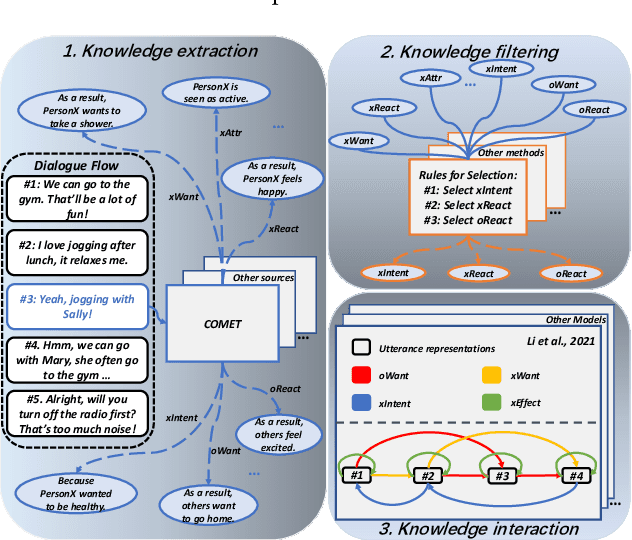
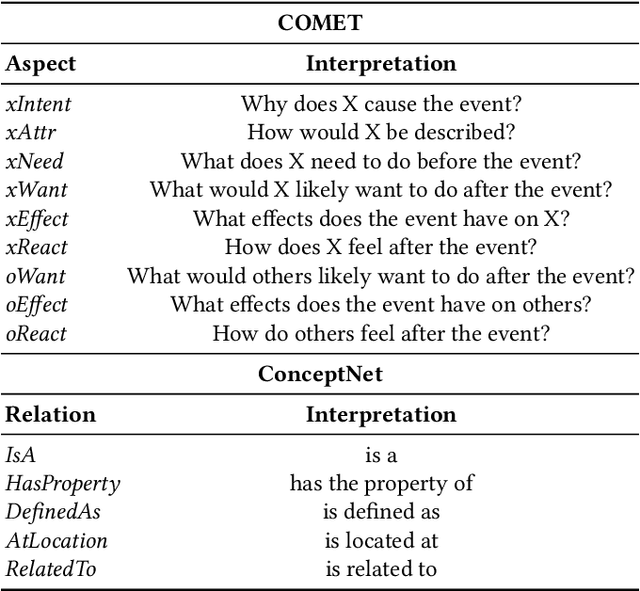
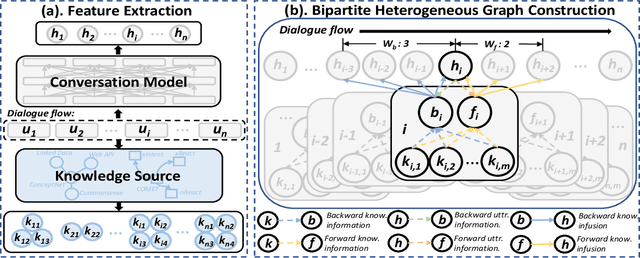
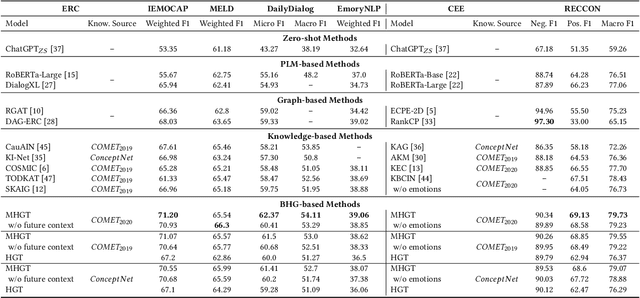
The context-aware emotional reasoning ability of AI systems, especially in conversations, is of vital importance in applications such as online opinion mining from social media and empathetic dialogue systems. Due to the implicit nature of conveying emotions in many scenarios, commonsense knowledge is widely utilized to enrich utterance semantics and enhance conversation modeling. However, most previous knowledge infusion methods perform empirical knowledge filtering and design highly customized architectures for knowledge interaction with the utterances, which can discard useful knowledge aspects and limit their generalizability to different knowledge sources. Based on these observations, we propose a Bipartite Heterogeneous Graph (BHG) method for enhancing emotional reasoning with commonsense knowledge. In BHG, the extracted context-aware utterance representations and knowledge representations are modeled as heterogeneous nodes. Two more knowledge aggregation node types are proposed to perform automatic knowledge filtering and interaction. BHG-based knowledge infusion can be directly generalized to multi-type and multi-grained knowledge sources. In addition, we propose a Multi-dimensional Heterogeneous Graph Transformer (MHGT) to perform graph reasoning, which can retain unchanged feature spaces and unequal dimensions for heterogeneous node types during inference to prevent unnecessary loss of information. Experiments show that BHG-based methods significantly outperform state-of-the-art knowledge infusion methods and show generalized knowledge infusion ability with higher efficiency. Further analysis proves that previous empirical knowledge filtering methods do not guarantee to provide the most useful knowledge information. Our code is available at: https://github.com/SteveKGYang/BHG.
Tackling Hallucinations in Neural Chart Summarization
Aug 01, 2023Hallucinations in text generation occur when the system produces text that is not grounded in the input. In this work, we tackle the problem of hallucinations in neural chart summarization. Our analysis shows that the target side of chart summarization training datasets often contains additional information, leading to hallucinations. We propose a natural language inference (NLI) based method to preprocess the training data and show through human evaluation that our method significantly reduces hallucinations. We also found that shortening long-distance dependencies in the input sequence and adding chart-related information like title and legends improves the overall performance.
Pseudo-online framework for BCI evaluation: A MOABB perspective
Aug 21, 2023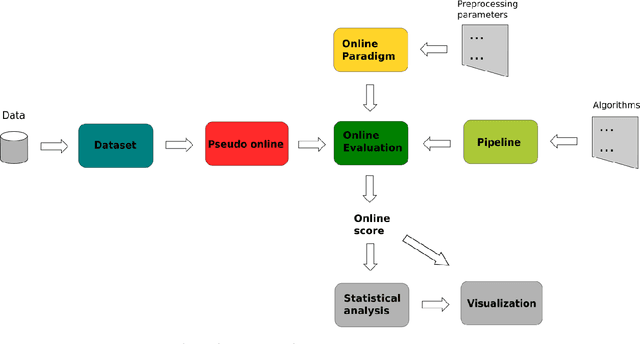

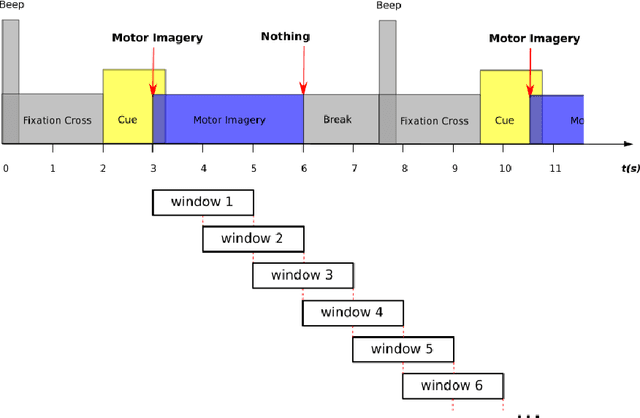
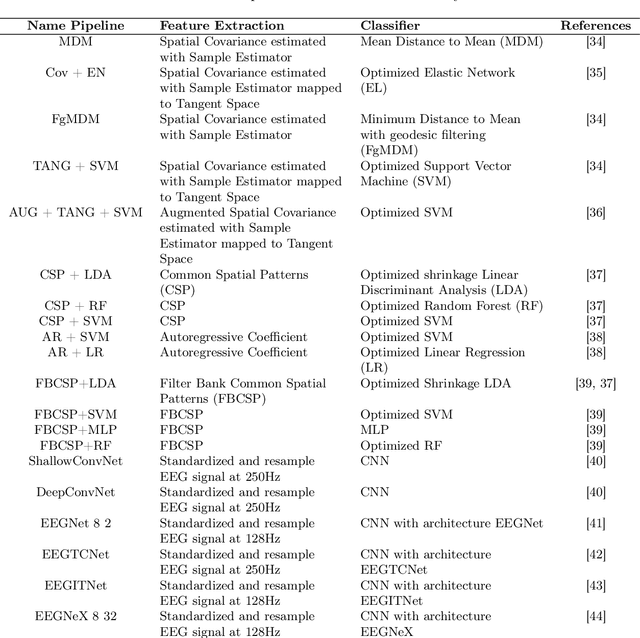
Objective: BCI (Brain-Computer Interface) technology operates in three modes: online, offline, and pseudo-online. In the online mode, real-time EEG data is constantly analyzed. In offline mode, the signal is acquired and processed afterwards. The pseudo-online mode processes collected data as if they were received in real-time. The main difference is that the offline mode often analyzes the whole data, while the online and pseudo-online modes only analyze data in short time windows. Offline analysis is usually done with asynchronous BCIs, which restricts analysis to predefined time windows. Asynchronous BCI, compatible with online and pseudo-online modes, allows flexible mental activity duration. Offline processing tends to be more accurate, while online analysis is better for therapeutic applications. Pseudo-online implementation approximates online processing without real-time constraints. Many BCI studies being offline introduce biases compared to real-life scenarios, impacting classification algorithm performance. Approach: The objective of this research paper is therefore to extend the current MOABB framework, operating in offline mode, so as to allow a comparison of different algorithms in a pseudo-online setting with the use of a technology based on overlapping sliding windows. To do this will require the introduction of a idle state event in the dataset that takes into account all different possibilities that are not task thinking. To validate the performance of the algorithms we will use the normalized Matthews Correlation Coefficient (nMCC) and the Information Transfer Rate (ITR). Main results: We analyzed the state-of-the-art algorithms of the last 15 years over several Motor Imagery (MI) datasets composed by several subjects, showing the differences between the two approaches from a statistical point of view. Significance: The ability to analyze the performance of different algorithms in offline and pseudo-online modes will allow the BCI community to obtain more accurate and comprehensive reports regarding the performance of classification algorithms.
Open-vocabulary Video Question Answering: A New Benchmark for Evaluating the Generalizability of Video Question Answering Models
Aug 18, 2023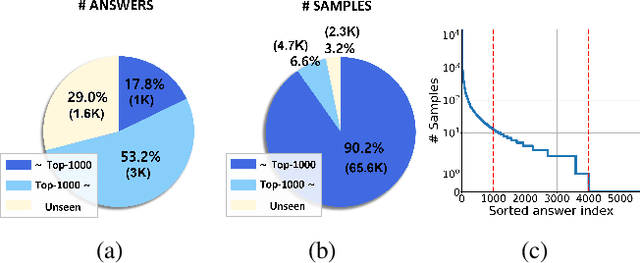
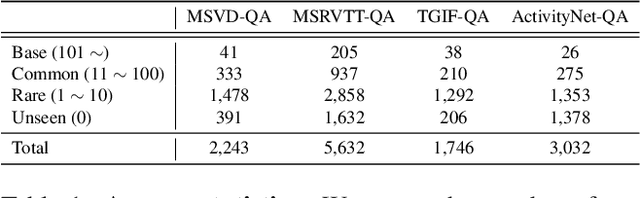
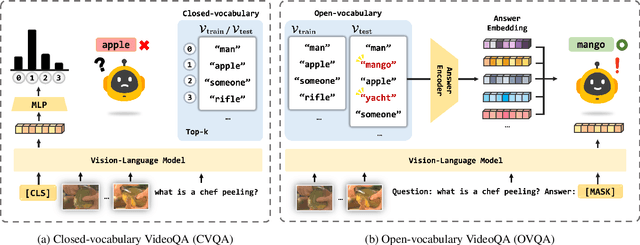
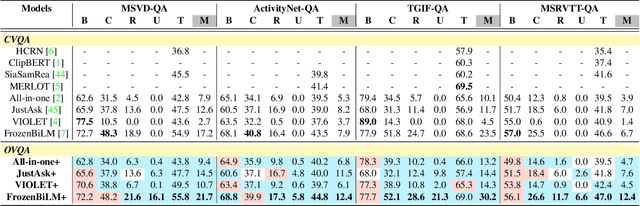
Video Question Answering (VideoQA) is a challenging task that entails complex multi-modal reasoning. In contrast to multiple-choice VideoQA which aims to predict the answer given several options, the goal of open-ended VideoQA is to answer questions without restricting candidate answers. However, the majority of previous VideoQA models formulate open-ended VideoQA as a classification task to classify the video-question pairs into a fixed answer set, i.e., closed-vocabulary, which contains only frequent answers (e.g., top-1000 answers). This leads the model to be biased toward only frequent answers and fail to generalize on out-of-vocabulary answers. We hence propose a new benchmark, Open-vocabulary Video Question Answering (OVQA), to measure the generalizability of VideoQA models by considering rare and unseen answers. In addition, in order to improve the model's generalization power, we introduce a novel GNN-based soft verbalizer that enhances the prediction on rare and unseen answers by aggregating the information from their similar words. For evaluation, we introduce new baselines by modifying the existing (closed-vocabulary) open-ended VideoQA models and improve their performances by further taking into account rare and unseen answers. Our ablation studies and qualitative analyses demonstrate that our GNN-based soft verbalizer further improves the model performance, especially on rare and unseen answers. We hope that our benchmark OVQA can serve as a guide for evaluating the generalizability of VideoQA models and inspire future research. Code is available at https://github.com/mlvlab/OVQA.
Towards a Modular Architecture for Science Factories
Aug 18, 2023

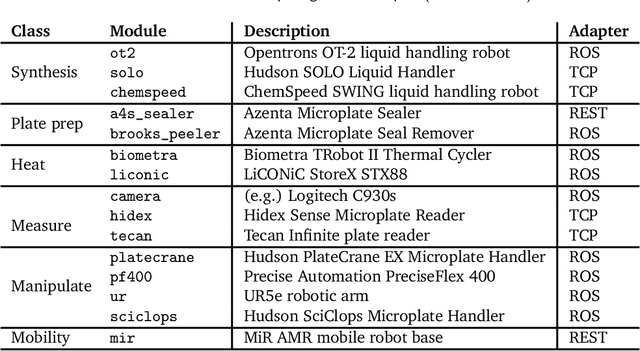
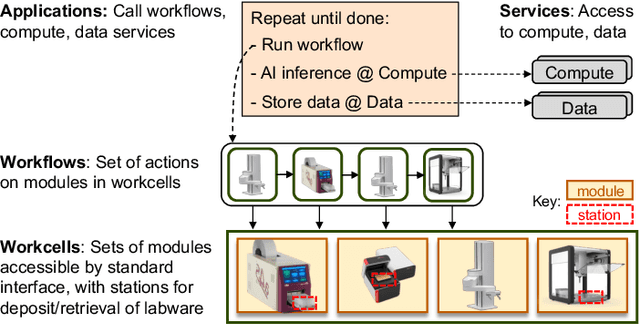
Advances in robotic automation, high-performance computing (HPC), and artificial intelligence (AI) encourage us to conceive of science factories: large, general-purpose computation- and AI-enabled self-driving laboratories (SDLs) with the generality and scale needed both to tackle large discovery problems and to support thousands of scientists. Science factories require modular hardware and software that can be replicated for scale and (re)configured to support many applications. To this end, we propose a prototype modular science factory architecture in which reconfigurable modules encapsulating scientific instruments are linked with manipulators to form workcells, that can themselves be combined to form larger assemblages, and linked with distributed computing for simulation, AI model training and inference, and related tasks. Workflows that perform sets of actions on modules can be specified, and various applications, comprising workflows plus associated computational and data manipulation steps, can be run concurrently. We report on our experiences prototyping this architecture and applying it in experiments involving 15 different robotic apparatus, five applications (one in education, two in biology, two in materials), and a variety of workflows, across four laboratories. We describe the reuse of modules, workcells, and workflows in different applications, the migration of applications between workcells, and the use of digital twins, and suggest directions for future work aimed at yet more generality and scalability. Code and data are available at https://ad-sdl.github.io/wei2023 and in the Supplementary Information