 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Safe Collision and Clamping Reaction for Parallel Robots During Human-Robot Collaboration
Aug 18, 2023
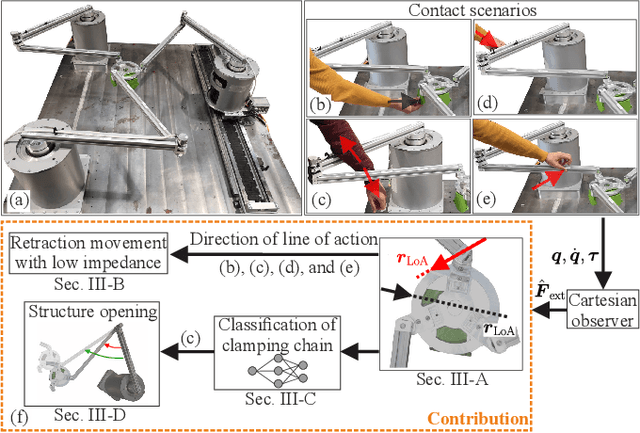
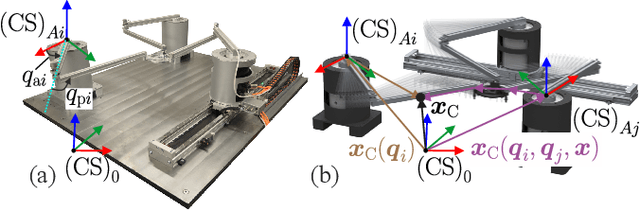
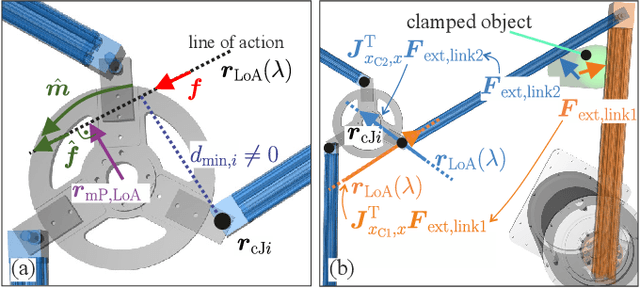
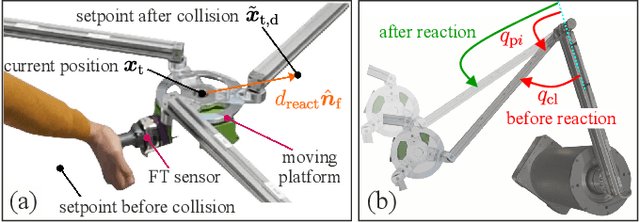
Parallel robots (PRs) offer the potential for safe human-robot collaboration because of their low moving masses. Due to the in-parallel kinematic chains, the risk of contact in the form of collisions and clamping at a chain increases. Ensuring safety is investigated in this work through various contact reactions on a real planar PR. External forces are estimated based on proprioceptive information and a dynamics model, which allows contact detection. Retraction along the direction of the estimated line of action provides an instantaneous response to limit the occurring contact forces within the experiment to 70N at a maximum velocity 0.4m/s. A reduction in the stiffness of a Cartesian impedance control is investigated as a further strategy. For clamping, a feedforward neural network (FNN) is trained and tested in different joint angle configurations to classify whether a collision or clamping occurs with an accuracy of 80%. A second FNN classifies the clamping kinematic chain to enable a subsequent kinematic projection of the clamping joint angle onto the rotational platform coordinates. In this way, a structure opening is performed in addition to the softer retraction movement. The reaction strategies are compared in real-world experiments at different velocities and controller stiffnesses to demonstrate their effectiveness. The results show that in all collision and clamping experiments the PR terminates the contact in less than 130ms.
Collision Isolation and Identification Using Proprioceptive Sensing for Parallel Robots to Enable Human-Robot Collaboration
Aug 18, 2023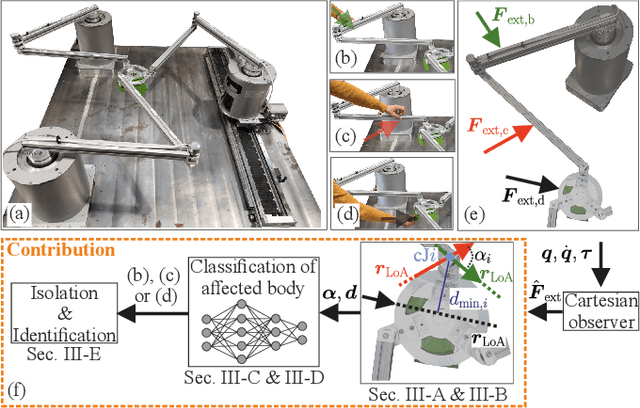
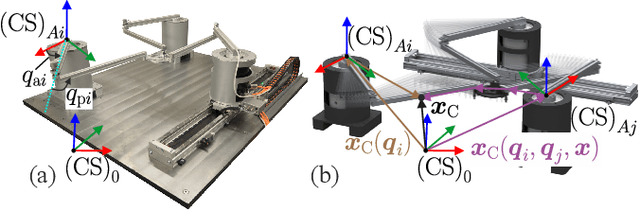
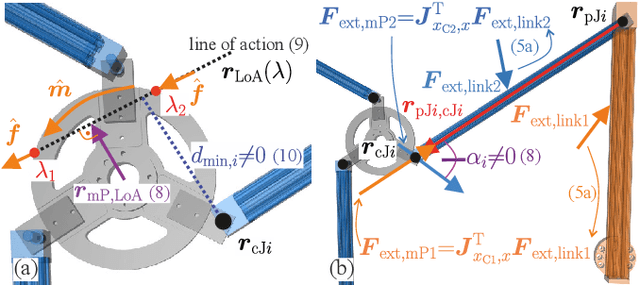
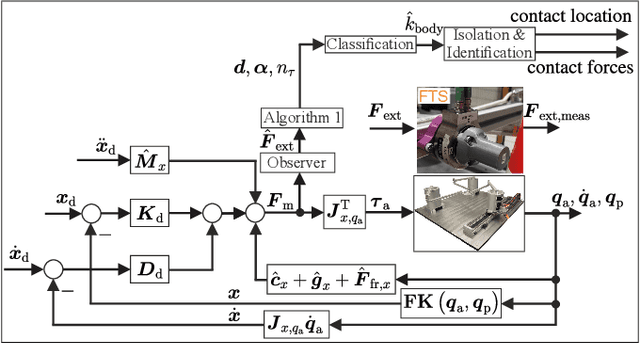
Parallel robots (PRs) allow for higher speeds in human-robot collaboration due to their lower moving masses but are more prone to unintended contact. For a safe reaction, knowledge of the location and force of a collision is useful. A novel algorithm for collision isolation and identification with proprioceptive information for a real PR is the scope of this work. To classify the collided body, the effects of contact forces at the links and platform of the PR are analyzed using a kinetostatic projection. This insight enables the derivation of features from the line of action of the estimated external force. The significance of these features is confirmed in experiments for various load cases. A feedforward neural network (FNN) classifies the collided body based on these physically modeled features. Generalization with the FNN to 300k load cases on the whole robot structure in other joint angle configurations is successfully performed with a collision-body classification accuracy of 84% in the experiments. Platform collisions are isolated and identified with an explicit solution, while a particle filter estimates the location and force of a contact on a kinematic chain. Updating the particle filter with estimated external joint torques leads to an isolation error of less than 3cm and an identification error of 4N in a real-world experiment.
Time Series Predictions in Unmonitored Sites: A Survey of Machine Learning Techniques in Water Resources
Aug 18, 2023Prediction of dynamic environmental variables in unmonitored sites remains a long-standing challenge for water resources science. The majority of the world's freshwater resources have inadequate monitoring of critical environmental variables needed for management. Yet, the need to have widespread predictions of hydrological variables such as river flow and water quality has become increasingly urgent due to climate and land use change over the past decades, and their associated impacts on water resources. Modern machine learning methods increasingly outperform their process-based and empirical model counterparts for hydrologic time series prediction with their ability to extract information from large, diverse data sets. We review relevant state-of-the art applications of machine learning for streamflow, water quality, and other water resources prediction and discuss opportunities to improve the use of machine learning with emerging methods for incorporating watershed characteristics into deep learning models, transfer learning, and incorporating process knowledge into machine learning models. The analysis here suggests most prior efforts have been focused on deep learning learning frameworks built on many sites for predictions at daily time scales in the United States, but that comparisons between different classes of machine learning methods are few and inadequate. We identify several open questions for time series predictions in unmonitored sites that include incorporating dynamic inputs and site characteristics, mechanistic understanding and spatial context, and explainable AI techniques in modern machine learning frameworks.
Exploring how a Generative AI interprets music
Jul 31, 2023We use Google's MusicVAE, a Variational Auto-Encoder with a 512-dimensional latent space to represent a few bars of music, and organize the latent dimensions according to their relevance in describing music. We find that, on average, most latent neurons remain silent when fed real music tracks: we call these "noise" neurons. The remaining few dozens of latent neurons that do fire are called "music neurons". We ask which neurons carry the musical information and what kind of musical information they encode, namely something that can be identified as pitch, rhythm or melody. We find that most of the information about pitch and rhythm is encoded in the first few music neurons: the neural network has thus constructed a couple of variables that non-linearly encode many human-defined variables used to describe pitch and rhythm. The concept of melody only seems to show up in independent neurons for longer sequences of music.
From Global to Local: Multi-scale Out-of-distribution Detection
Aug 20, 2023Out-of-distribution (OOD) detection aims to detect "unknown" data whose labels have not been seen during the in-distribution (ID) training process. Recent progress in representation learning gives rise to distance-based OOD detection that recognizes inputs as ID/OOD according to their relative distances to the training data of ID classes. Previous approaches calculate pairwise distances relying only on global image representations, which can be sub-optimal as the inevitable background clutter and intra-class variation may drive image-level representations from the same ID class far apart in a given representation space. In this work, we overcome this challenge by proposing Multi-scale OOD DEtection (MODE), a first framework leveraging both global visual information and local region details of images to maximally benefit OOD detection. Specifically, we first find that existing models pretrained by off-the-shelf cross-entropy or contrastive losses are incompetent to capture valuable local representations for MODE, due to the scale-discrepancy between the ID training and OOD detection processes. To mitigate this issue and encourage locally discriminative representations in ID training, we propose Attention-based Local PropAgation (ALPA), a trainable objective that exploits a cross-attention mechanism to align and highlight the local regions of the target objects for pairwise examples. During test-time OOD detection, a Cross-Scale Decision (CSD) function is further devised on the most discriminative multi-scale representations to distinguish ID/OOD data more faithfully. We demonstrate the effectiveness and flexibility of MODE on several benchmarks -- on average, MODE outperforms the previous state-of-the-art by up to 19.24% in FPR, 2.77% in AUROC. Code is available at https://github.com/JimZAI/MODE-OOD.
Hierarchical State Abstraction Based on Structural Information Principles
Apr 24, 2023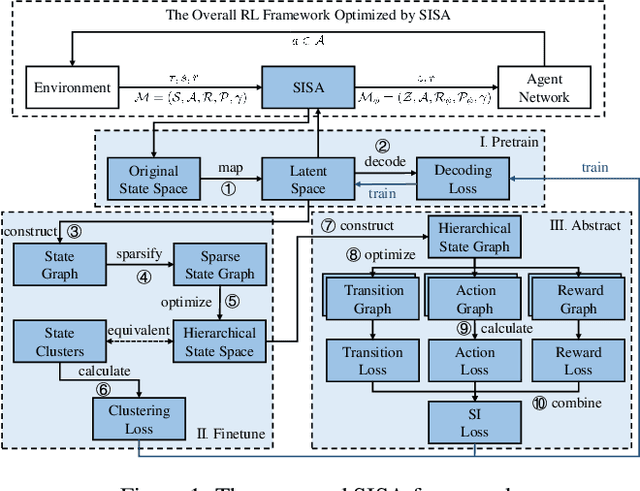

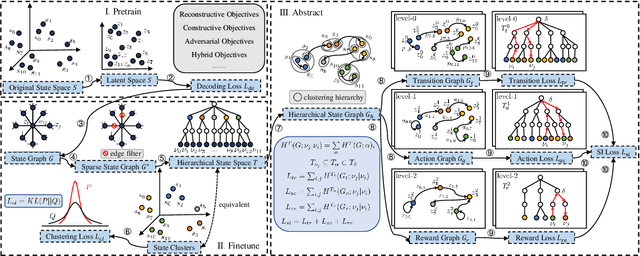
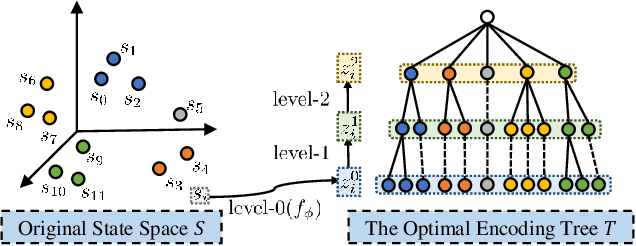
State abstraction optimizes decision-making by ignoring irrelevant environmental information in reinforcement learning with rich observations. Nevertheless, recent approaches focus on adequate representational capacities resulting in essential information loss, affecting their performances on challenging tasks. In this article, we propose a novel mathematical Structural Information principles-based State Abstraction framework, namely SISA, from the information-theoretic perspective. Specifically, an unsupervised, adaptive hierarchical state clustering method without requiring manual assistance is presented, and meanwhile, an optimal encoding tree is generated. On each non-root tree node, a new aggregation function and condition structural entropy are designed to achieve hierarchical state abstraction and compensate for sampling-induced essential information loss in state abstraction. Empirical evaluations on a visual gridworld domain and six continuous control benchmarks demonstrate that, compared with five SOTA state abstraction approaches, SISA significantly improves mean episode reward and sample efficiency up to 18.98 and 44.44%, respectively. Besides, we experimentally show that SISA is a general framework that can be flexibly integrated with different representation-learning objectives to improve their performances further.
Tackling Hallucinations in Neural Chart Summarization
Aug 01, 2023Hallucinations in text generation occur when the system produces text that is not grounded in the input. In this work, we tackle the problem of hallucinations in neural chart summarization. Our analysis shows that the target side of chart summarization training datasets often contains additional information, leading to hallucinations. We propose a natural language inference (NLI) based method to preprocess the training data and show through human evaluation that our method significantly reduces hallucinations. We also found that shortening long-distance dependencies in the input sequence and adding chart-related information like title and legends improves the overall performance.
TMI! Finetuned Models Leak Private Information from their Pretraining Data
Jun 01, 2023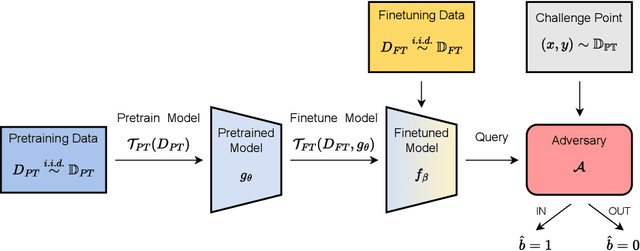
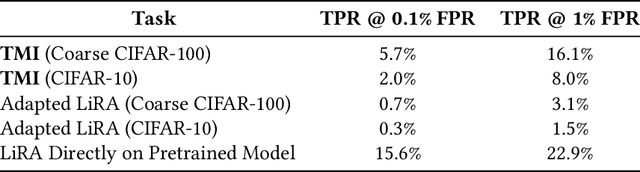
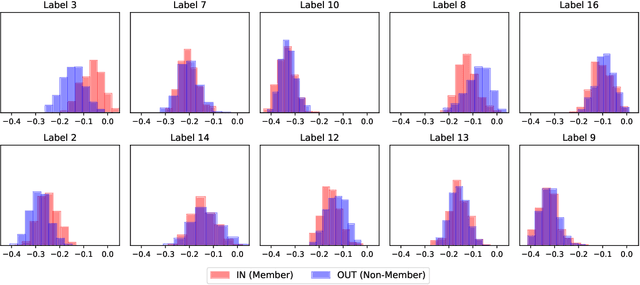
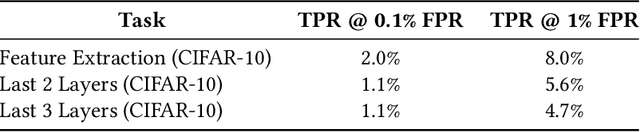
Transfer learning has become an increasingly popular technique in machine learning as a way to leverage a pretrained model trained for one task to assist with building a finetuned model for a related task. This paradigm has been especially popular for privacy in machine learning, where the pretrained model is considered public, and only the data for finetuning is considered sensitive. However, there are reasons to believe that the data used for pretraining is still sensitive, making it essential to understand how much information the finetuned model leaks about the pretraining data. In this work we propose a new membership-inference threat model where the adversary only has access to the finetuned model and would like to infer the membership of the pretraining data. To realize this threat model, we implement a novel metaclassifier-based attack, TMI, that leverages the influence of memorized pretraining samples on predictions in the downstream task. We evaluate TMI on both vision and natural language tasks across multiple transfer learning settings, including finetuning with differential privacy. Through our evaluation, we find that TMI can successfully infer membership of pretraining examples using query access to the finetuned model.
ADR-GNN: Advection-Diffusion-Reaction Graph Neural Networks
Jul 29, 2023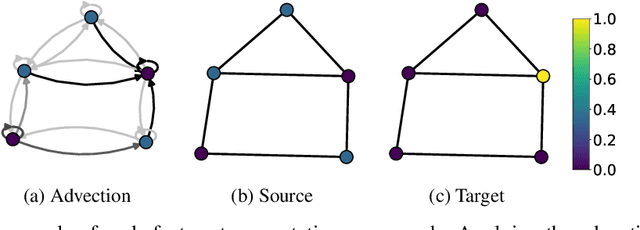
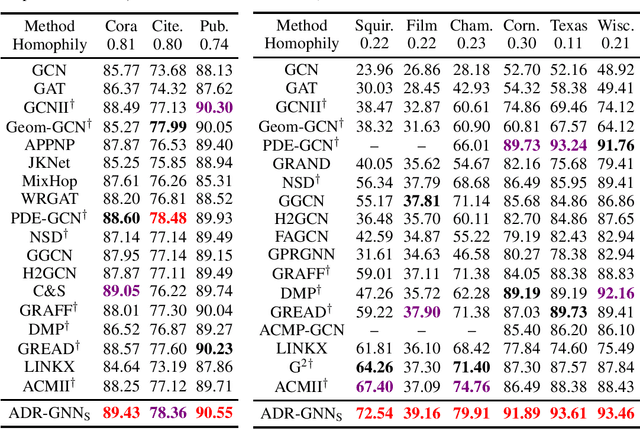
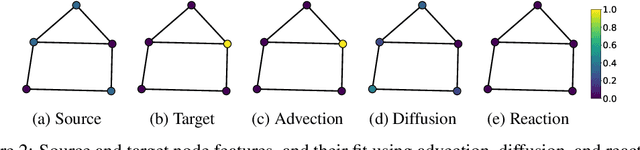

Graph neural networks (GNNs) have shown remarkable success in learning representations for graph-structured data. However, GNNs still face challenges in modeling complex phenomena that involve advection. In this paper, we propose a novel GNN architecture based on Advection-Diffusion-Reaction systems, called ADR-GNN. Advection models the directed transportation of information, diffusion captures the local smoothing of information, and reaction represents the non-linear transformation of information in channels. We provide an analysis of the qualitative behavior of ADR-GNN, that shows the benefit of combining advection, diffusion, and reaction. To demonstrate its efficacy, we evaluate ADR-GNN on real-world node classification and spatio-temporal datasets, and show that it improves or offers competitive performance compared to state-of-the-art networks.
OmniDataComposer: A Unified Data Structure for Multimodal Data Fusion and Infinite Data Generation
Aug 17, 2023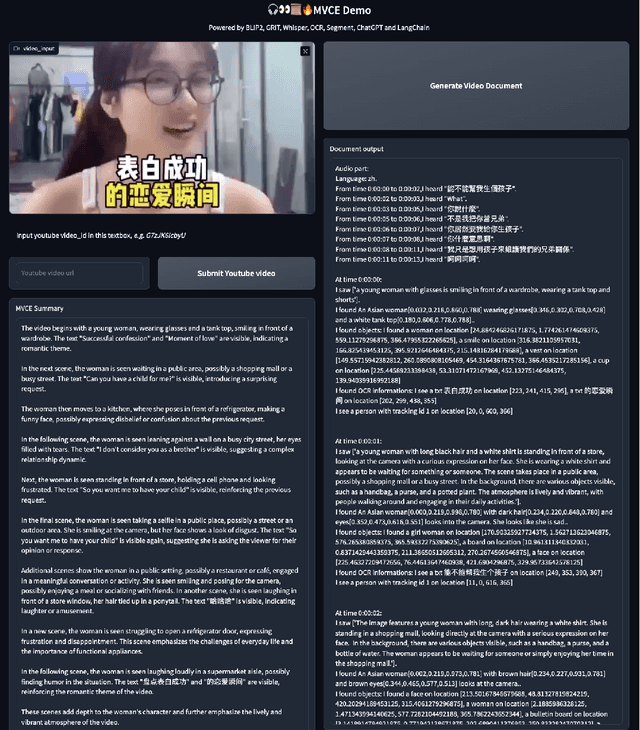
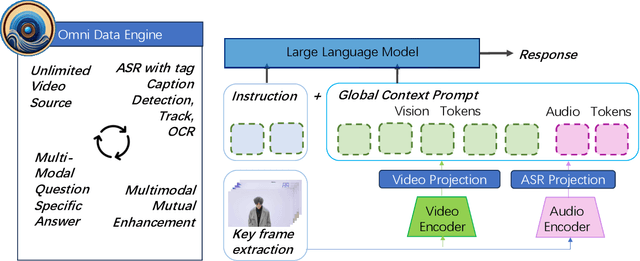

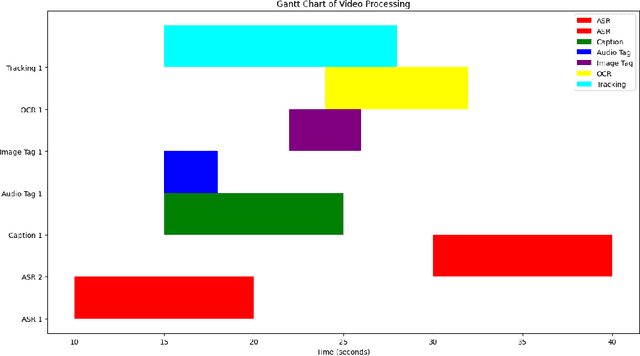
This paper presents OmniDataComposer, an innovative approach for multimodal data fusion and unlimited data generation with an intent to refine and uncomplicate interplay among diverse data modalities. Coming to the core breakthrough, it introduces a cohesive data structure proficient in processing and merging multimodal data inputs, which include video, audio, and text. Our crafted algorithm leverages advancements across multiple operations such as video/image caption extraction, dense caption extraction, Automatic Speech Recognition (ASR), Optical Character Recognition (OCR), Recognize Anything Model(RAM), and object tracking. OmniDataComposer is capable of identifying over 6400 categories of objects, substantially broadening the spectrum of visual information. It amalgamates these diverse modalities, promoting reciprocal enhancement among modalities and facilitating cross-modal data correction. \textbf{The final output metamorphoses each video input into an elaborate sequential document}, virtually transmuting videos into thorough narratives, making them easier to be processed by large language models. Future prospects include optimizing datasets for each modality to encourage unlimited data generation. This robust base will offer priceless insights to models like ChatGPT, enabling them to create higher quality datasets for video captioning and easing question-answering tasks based on video content. OmniDataComposer inaugurates a new stage in multimodal learning, imparting enormous potential for augmenting AI's understanding and generation of complex, real-world data.