 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Joint Precoding and Fronthaul Compression for Cell-Free MIMO Downlink With Radio Stripes
Aug 07, 2023
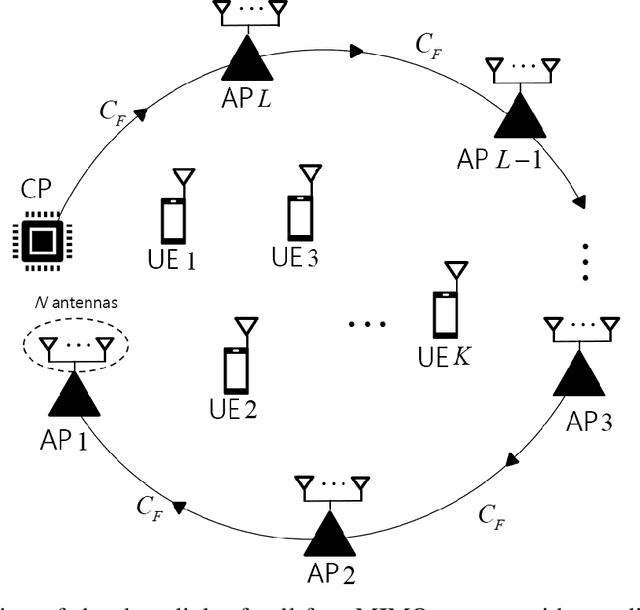
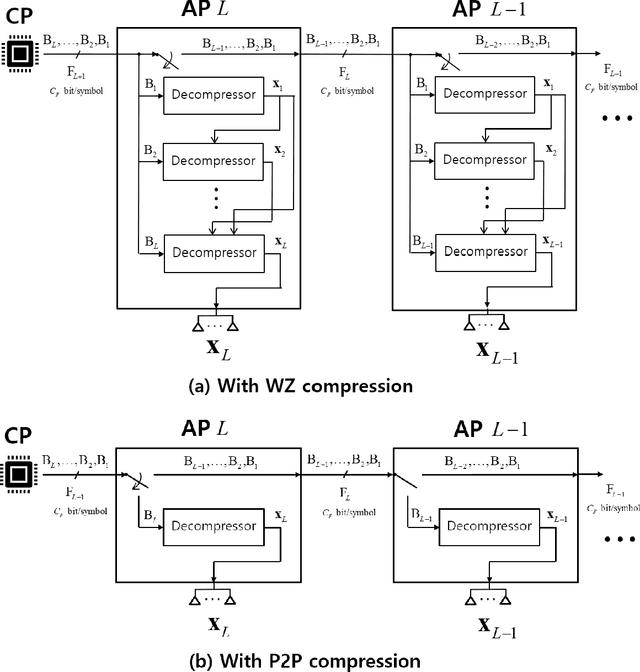
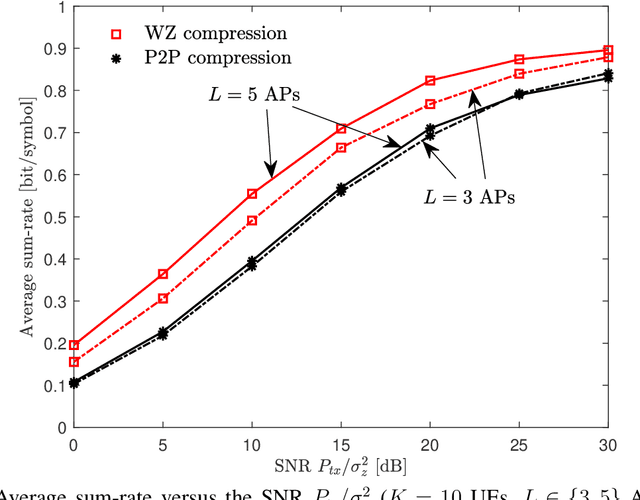
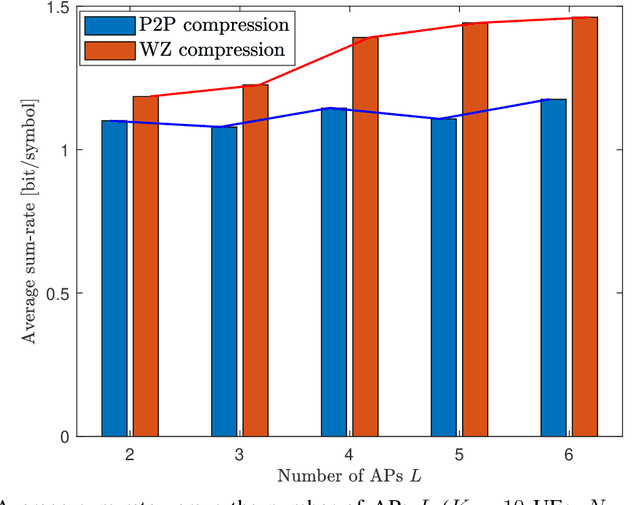
A sequential fronthaul network, referred to as radio stripes, is a promising fronthaul topology of cell-free MIMO systems. In this setup, a single cable suffices to connect access points (APs) to a central processor (CP). Thus, radio stripes are more effective than conventional star fronthaul topology which requires dedicated cables for each of APs. Most of works on radio stripes focused on the uplink communication or downlink energy transfer. This work tackles the design of the downlink data transmission for the first time. The CP sends compressed information of linearly precoded signals to the APs on fronthaul. Due to the serial transfer on radio stripes, each AP has an access to all the compressed blocks which pass through it. Thus, an advanced compression technique, called Wyner-Ziv (WZ) compression, can be applied in which each AP decompresses all the received blocks to exploit them for the reconstruction of its desired precoded signal as side information. The problem of maximizing the sum-rate is tackled under the standard point-to-point (P2P) and WZ compression strategies. Numerical results validate the performance gains of the proposed scheme.
BlindSage: Label Inference Attacks against Node-level Vertical Federated Graph Neural Networks
Aug 04, 2023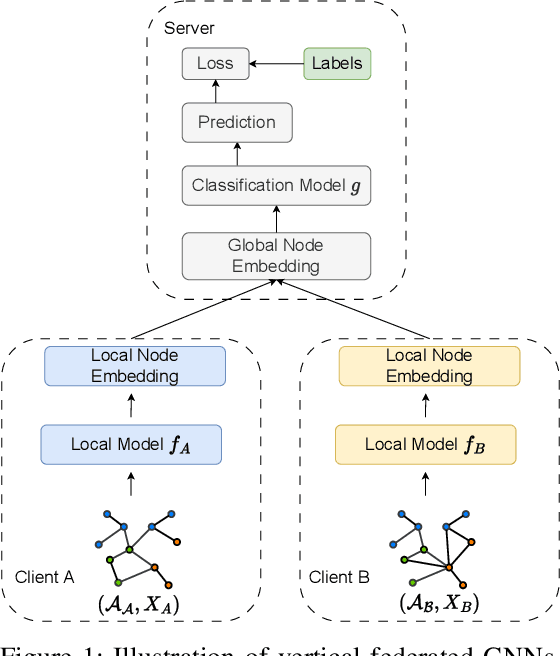
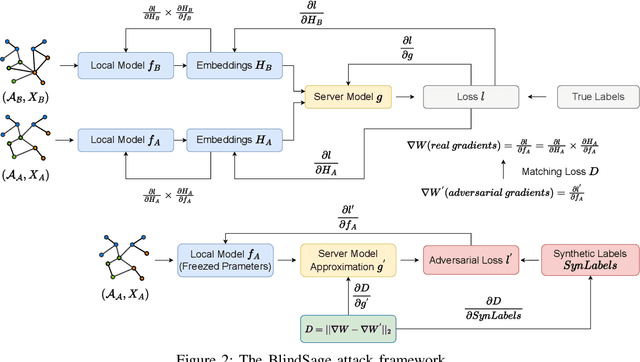
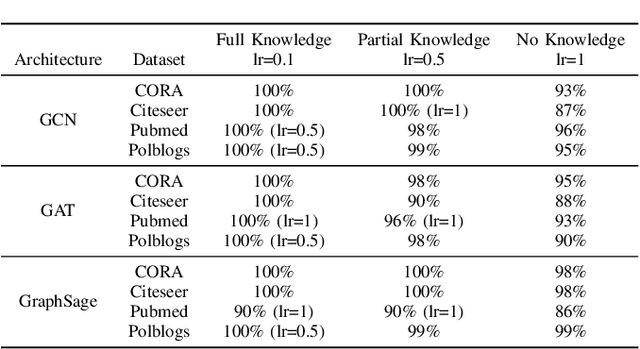
Federated learning enables collaborative training of machine learning models by keeping the raw data of the involved workers private. One of its main objectives is to improve the models' privacy, security, and scalability. Vertical Federated Learning (VFL) offers an efficient cross-silo setting where a few parties collaboratively train a model without sharing the same features. In such a scenario, classification labels are commonly considered sensitive information held exclusively by one (active) party, while other (passive) parties use only their local information. Recent works have uncovered important flaws of VFL, leading to possible label inference attacks under the assumption that the attacker has some, even limited, background knowledge on the relation between labels and data. In this work, we are the first (to the best of our knowledge) to investigate label inference attacks on VFL using a zero-background knowledge strategy. To concretely formulate our proposal, we focus on Graph Neural Networks (GNNs) as a target model for the underlying VFL. In particular, we refer to node classification tasks, which are widely studied, and GNNs have shown promising results. Our proposed attack, BlindSage, provides impressive results in the experiments, achieving nearly 100% accuracy in most cases. Even when the attacker has no information about the used architecture or the number of classes, the accuracy remained above 85% in most instances. Finally, we observe that well-known defenses cannot mitigate our attack without affecting the model's performance on the main classification task.
Guide3D: Create 3D Avatars from Text and Image Guidance
Aug 18, 2023
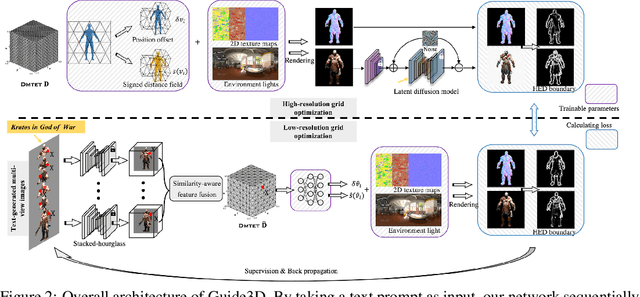
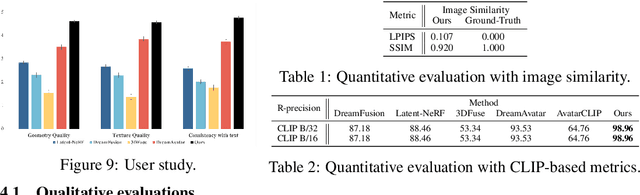

Recently, text-to-image generation has exhibited remarkable advancements, with the ability to produce visually impressive results. In contrast, text-to-3D generation has not yet reached a comparable level of quality. Existing methods primarily rely on text-guided score distillation sampling (SDS), and they encounter difficulties in transferring 2D attributes of the generated images to 3D content. In this work, we aim to develop an effective 3D generative model capable of synthesizing high-resolution textured meshes by leveraging both textual and image information. To this end, we introduce Guide3D, a zero-shot text-and-image-guided generative model for 3D avatar generation based on diffusion models. Our model involves (1) generating sparse-view images of a text-consistent character using diffusion models, and (2) jointly optimizing multi-resolution differentiable marching tetrahedral grids with pixel-aligned image features. We further propose a similarity-aware feature fusion strategy for efficiently integrating features from different views. Moreover, we introduce two novel training objectives as an alternative to calculating SDS, significantly enhancing the optimization process. We thoroughly evaluate the performance and components of our framework, which outperforms the current state-of-the-art in producing topologically and structurally correct geometry and high-resolution textures. Guide3D enables the direct transfer of 2D-generated images to the 3D space. Our code will be made publicly available.
Hard No-Box Adversarial Attack on Skeleton-Based Human Action Recognition with Skeleton-Motion-Informed Gradient
Aug 18, 2023
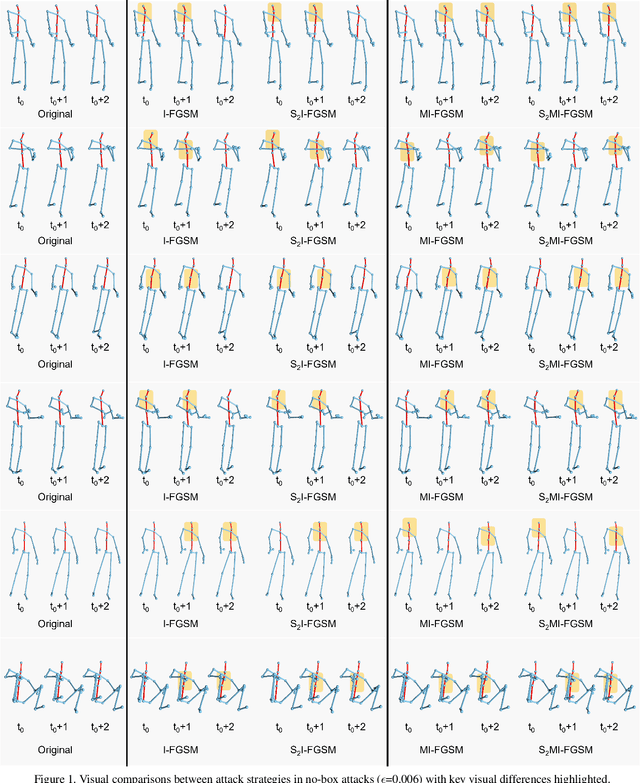
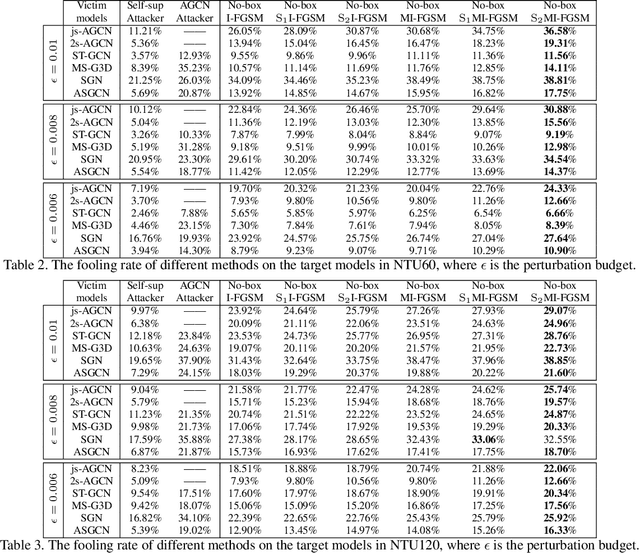
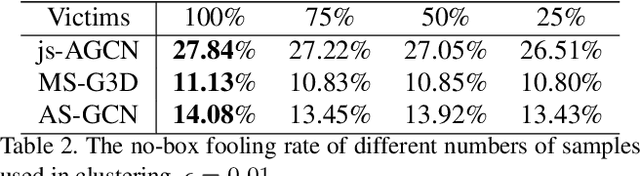
Recently, methods for skeleton-based human activity recognition have been shown to be vulnerable to adversarial attacks. However, these attack methods require either the full knowledge of the victim (i.e. white-box attacks), access to training data (i.e. transfer-based attacks) or frequent model queries (i.e. black-box attacks). All their requirements are highly restrictive, raising the question of how detrimental the vulnerability is. In this paper, we show that the vulnerability indeed exists. To this end, we consider a new attack task: the attacker has no access to the victim model or the training data or labels, where we coin the term hard no-box attack. Specifically, we first learn a motion manifold where we define an adversarial loss to compute a new gradient for the attack, named skeleton-motion-informed (SMI) gradient. Our gradient contains information of the motion dynamics, which is different from existing gradient-based attack methods that compute the loss gradient assuming each dimension in the data is independent. The SMI gradient can augment many gradient-based attack methods, leading to a new family of no-box attack methods. Extensive evaluation and comparison show that our method imposes a real threat to existing classifiers. They also show that the SMI gradient improves the transferability and imperceptibility of adversarial samples in both no-box and transfer-based black-box settings.
Retro-FPN: Retrospective Feature Pyramid Network for Point Cloud Semantic Segmentation
Aug 18, 2023Learning per-point semantic features from the hierarchical feature pyramid is essential for point cloud semantic segmentation. However, most previous methods suffered from ambiguous region features or failed to refine per-point features effectively, which leads to information loss and ambiguous semantic identification. To resolve this, we propose Retro-FPN to model the per-point feature prediction as an explicit and retrospective refining process, which goes through all the pyramid layers to extract semantic features explicitly for each point. Its key novelty is a retro-transformer for summarizing semantic contexts from the previous layer and accordingly refining the features in the current stage. In this way, the categorization of each point is conditioned on its local semantic pattern. Specifically, the retro-transformer consists of a local cross-attention block and a semantic gate unit. The cross-attention serves to summarize the semantic pattern retrospectively from the previous layer. And the gate unit carefully incorporates the summarized contexts and refines the current semantic features. Retro-FPN is a pluggable neural network that applies to hierarchical decoders. By integrating Retro-FPN with three representative backbones, including both point-based and voxel-based methods, we show that Retro-FPN can significantly improve performance over state-of-the-art backbones. Comprehensive experiments on widely used benchmarks can justify the effectiveness of our design. The source is available at https://github.com/AllenXiangX/Retro-FPN
Preference-conditioned Pixel-based AI Agent For Game Testing
Aug 18, 2023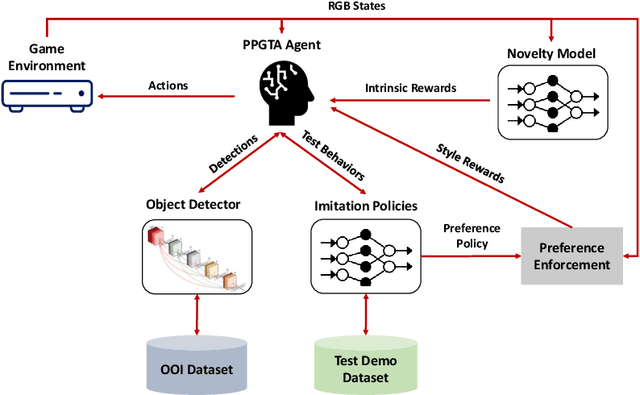
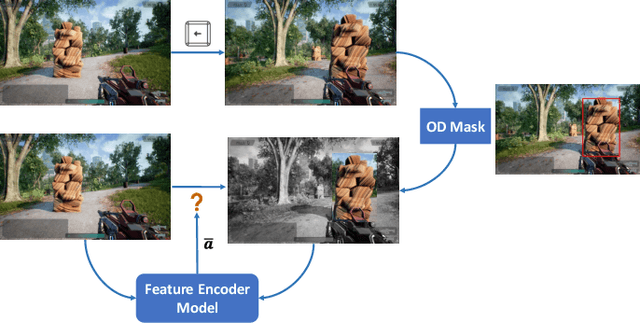
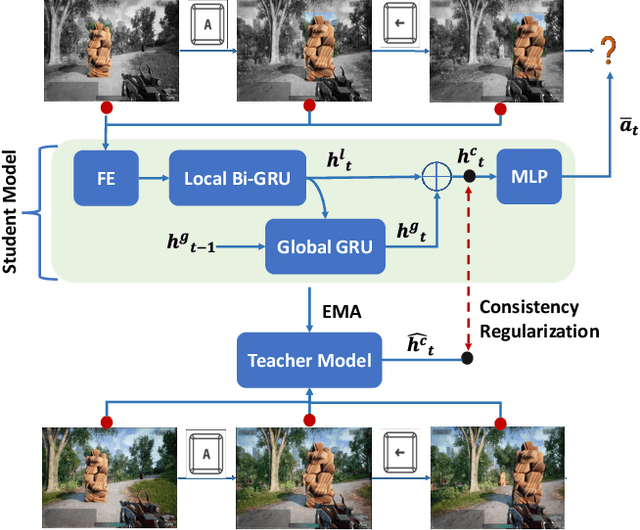
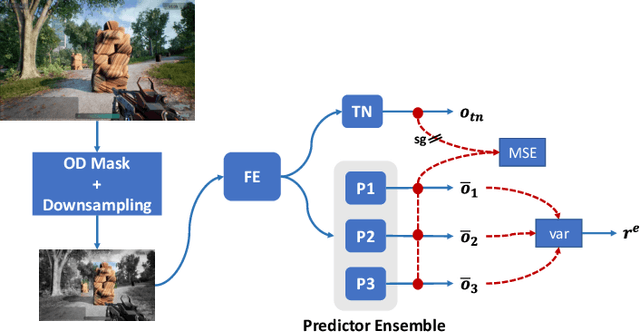
The game industry is challenged to cope with increasing growth in demand and game complexity while maintaining acceptable quality standards for released games. Classic approaches solely depending on human efforts for quality assurance and game testing do not scale effectively in terms of time and cost. Game-testing AI agents that learn by interaction with the environment have the potential to mitigate these challenges with good scalability properties on time and costs. However, most recent work in this direction depends on game state information for the agent's state representation, which limits generalization across different game scenarios. Moreover, game test engineers usually prefer exploring a game in a specific style, such as exploring the golden path. However, current game testing AI agents do not provide an explicit way to satisfy such a preference. This paper addresses these limitations by proposing an agent design that mainly depends on pixel-based state observations while exploring the environment conditioned on a user's preference specified by demonstration trajectories. In addition, we propose an imitation learning method that couples self-supervised and supervised learning objectives to enhance the quality of imitation behaviors. Our agent significantly outperforms state-of-the-art pixel-based game testing agents over exploration coverage and test execution quality when evaluated on a complex open-world environment resembling many aspects of real AAA games.
Transitivity-Preserving Graph Representation Learning for Bridging Local Connectivity and Role-based Similarity
Aug 18, 2023
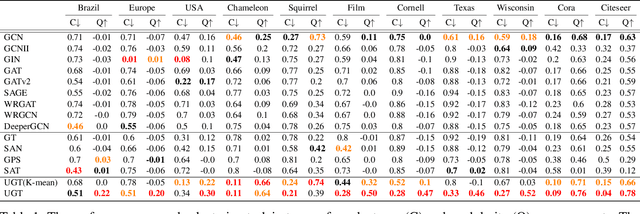
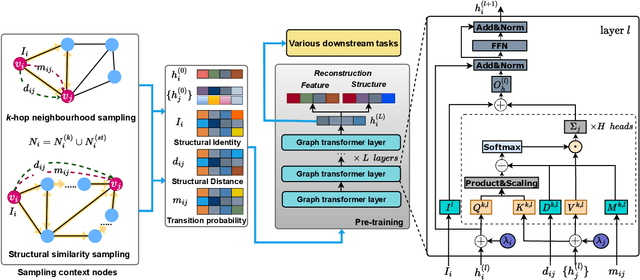
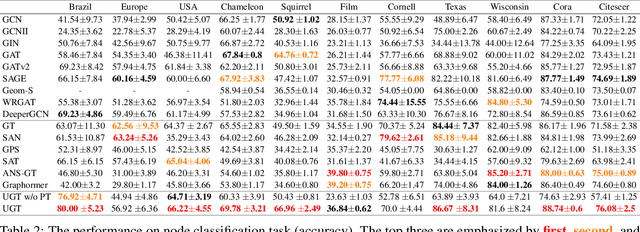
Graph representation learning (GRL) methods, such as graph neural networks and graph transformer models, have been successfully used to analyze graph-structured data, mainly focusing on node classification and link prediction tasks. However, the existing studies mostly only consider local connectivity while ignoring long-range connectivity and the roles of nodes. In this paper, we propose Unified Graph Transformer Networks (UGT) that effectively integrate local and global structural information into fixed-length vector representations. First, UGT learns local structure by identifying the local substructures and aggregating features of the $k$-hop neighborhoods of each node. Second, we construct virtual edges, bridging distant nodes with structural similarity to capture the long-range dependencies. Third, UGT learns unified representations through self-attention, encoding structural distance and $p$-step transition probability between node pairs. Furthermore, we propose a self-supervised learning task that effectively learns transition probability to fuse local and global structural features, which could then be transferred to other downstream tasks. Experimental results on real-world benchmark datasets over various downstream tasks showed that UGT significantly outperformed baselines that consist of state-of-the-art models. In addition, UGT reaches the expressive power of the third-order Weisfeiler-Lehman isomorphism test (3d-WL) in distinguishing non-isomorphic graph pairs. The source code is available at https://github.com/NSLab-CUK/Unified-Graph-Transformer.
Safe Collision and Clamping Reaction for Parallel Robots During Human-Robot Collaboration
Aug 18, 2023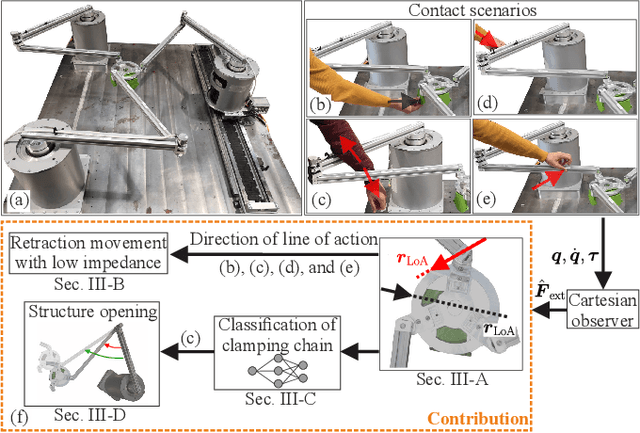
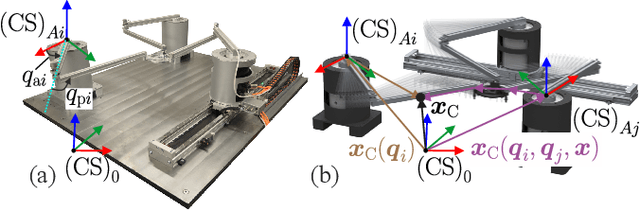
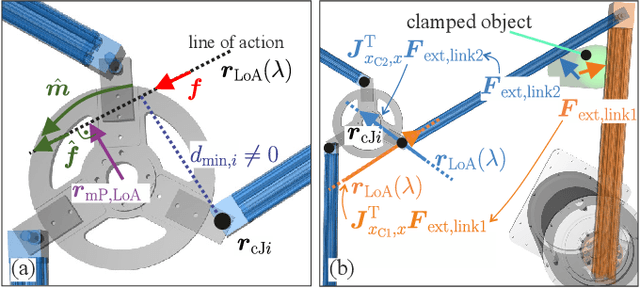
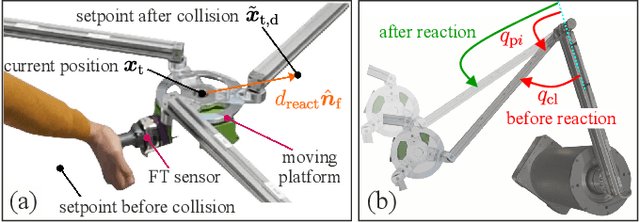
Parallel robots (PRs) offer the potential for safe human-robot collaboration because of their low moving masses. Due to the in-parallel kinematic chains, the risk of contact in the form of collisions and clamping at a chain increases. Ensuring safety is investigated in this work through various contact reactions on a real planar PR. External forces are estimated based on proprioceptive information and a dynamics model, which allows contact detection. Retraction along the direction of the estimated line of action provides an instantaneous response to limit the occurring contact forces within the experiment to 70N at a maximum velocity 0.4m/s. A reduction in the stiffness of a Cartesian impedance control is investigated as a further strategy. For clamping, a feedforward neural network (FNN) is trained and tested in different joint angle configurations to classify whether a collision or clamping occurs with an accuracy of 80%. A second FNN classifies the clamping kinematic chain to enable a subsequent kinematic projection of the clamping joint angle onto the rotational platform coordinates. In this way, a structure opening is performed in addition to the softer retraction movement. The reaction strategies are compared in real-world experiments at different velocities and controller stiffnesses to demonstrate their effectiveness. The results show that in all collision and clamping experiments the PR terminates the contact in less than 130ms.
Collision Isolation and Identification Using Proprioceptive Sensing for Parallel Robots to Enable Human-Robot Collaboration
Aug 18, 2023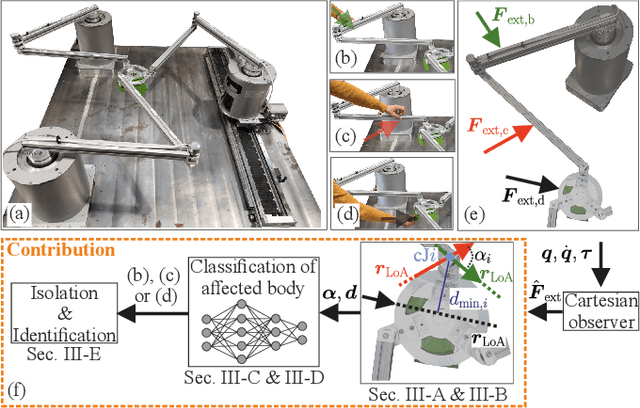
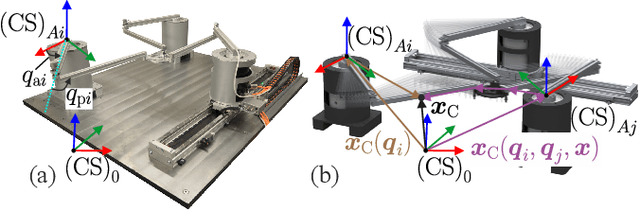
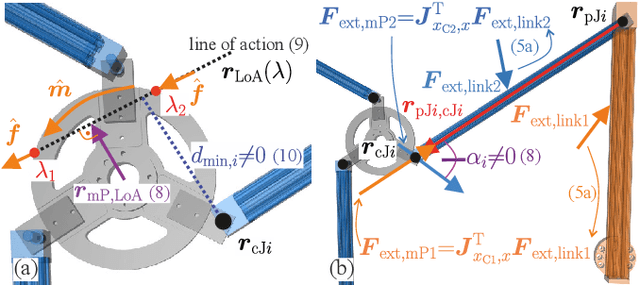
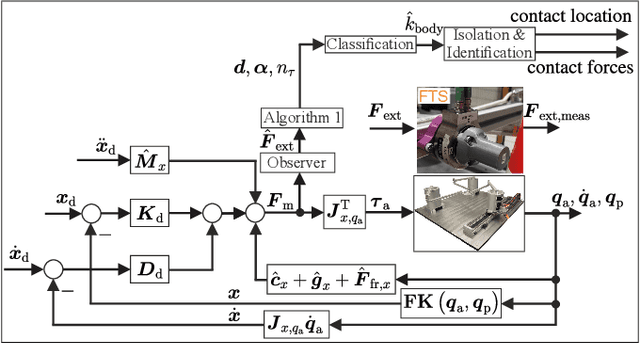
Parallel robots (PRs) allow for higher speeds in human-robot collaboration due to their lower moving masses but are more prone to unintended contact. For a safe reaction, knowledge of the location and force of a collision is useful. A novel algorithm for collision isolation and identification with proprioceptive information for a real PR is the scope of this work. To classify the collided body, the effects of contact forces at the links and platform of the PR are analyzed using a kinetostatic projection. This insight enables the derivation of features from the line of action of the estimated external force. The significance of these features is confirmed in experiments for various load cases. A feedforward neural network (FNN) classifies the collided body based on these physically modeled features. Generalization with the FNN to 300k load cases on the whole robot structure in other joint angle configurations is successfully performed with a collision-body classification accuracy of 84% in the experiments. Platform collisions are isolated and identified with an explicit solution, while a particle filter estimates the location and force of a contact on a kinematic chain. Updating the particle filter with estimated external joint torques leads to an isolation error of less than 3cm and an identification error of 4N in a real-world experiment.
Time Series Predictions in Unmonitored Sites: A Survey of Machine Learning Techniques in Water Resources
Aug 18, 2023Prediction of dynamic environmental variables in unmonitored sites remains a long-standing challenge for water resources science. The majority of the world's freshwater resources have inadequate monitoring of critical environmental variables needed for management. Yet, the need to have widespread predictions of hydrological variables such as river flow and water quality has become increasingly urgent due to climate and land use change over the past decades, and their associated impacts on water resources. Modern machine learning methods increasingly outperform their process-based and empirical model counterparts for hydrologic time series prediction with their ability to extract information from large, diverse data sets. We review relevant state-of-the art applications of machine learning for streamflow, water quality, and other water resources prediction and discuss opportunities to improve the use of machine learning with emerging methods for incorporating watershed characteristics into deep learning models, transfer learning, and incorporating process knowledge into machine learning models. The analysis here suggests most prior efforts have been focused on deep learning learning frameworks built on many sites for predictions at daily time scales in the United States, but that comparisons between different classes of machine learning methods are few and inadequate. We identify several open questions for time series predictions in unmonitored sites that include incorporating dynamic inputs and site characteristics, mechanistic understanding and spatial context, and explainable AI techniques in modern machine learning frameworks.