 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Understanding the Usage of QUBO-based Hamiltonian Function in Combinatorial Optimization over Graphs: A Discussion Using Max Cut (MC) Problem
Aug 27, 2023
Quadratic Unconstrained Binary Optimization (QUBO) is a generic technique to model various NP-hard combinatorial optimization problems in the form of binary variables. The Hamiltonian function is often used to formulate QUBO problems where it is used as the objective function in the context of optimization. In this study, we investigate how reinforcement learning-based (RL) paradigms with the presence of the Hamiltonian function can address combinatorial optimization problems over graphs in QUBO formulations. We use Graph Neural Network (GNN) as the message-passing architecture to convey the information among the nodes. We have centered our discussion on QUBO formulated Max-Cut problem but the intuitions can be extended to any QUBO supported canonical NP-Hard combinatorial optimization problems. We mainly investigate three formulations, Monty-Carlo Tree Search with GNN-based RL (MCTS-GNN), DQN with GNN-based RL, and a generic GNN with attention-based RL (GRL). Our findings state that in the RL-based paradigm, the Hamiltonian function-based optimization in QUBO formulation brings model convergence and can be used as a generic reward function. We also analyze and present the performance of our RL-based setups through experimenting over graphs of different densities and compare them with a simple GNN-based setup in the light of constraint violation, learning stability and computation cost. As per one of our findings, all the architectures provide a very comparable performance in sparse graphs as per the number of constraint violation whreas MCTS-GNN gives the best performance. In the similar criteria, the performance significantly starts to drop both for GRL and simple GNN-based setups whereas MCTS-GNN and DQN shines. We also present the corresponding mathematical formulations and in-depth discussion of the observed characteristics during experimentations.
Adaptive Taxonomy Learning and Historical Patterns Modelling for Patent Classification
Aug 10, 2023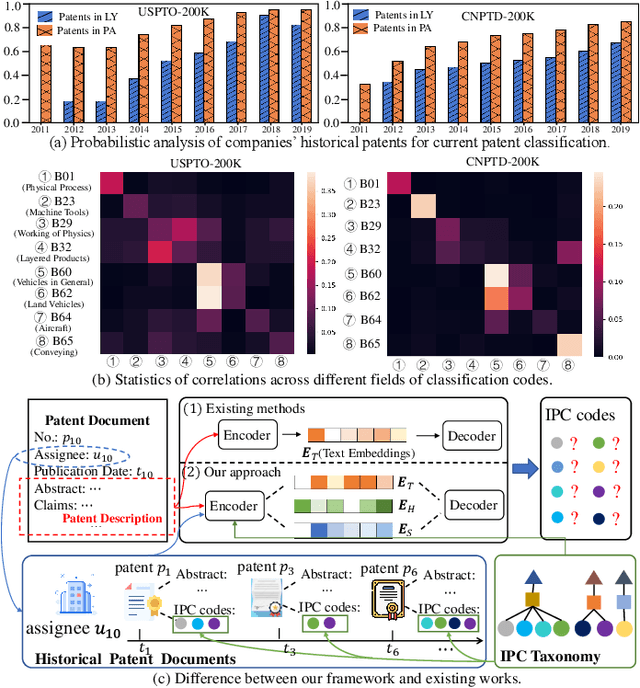

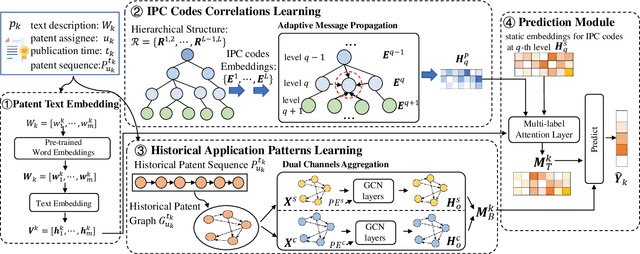
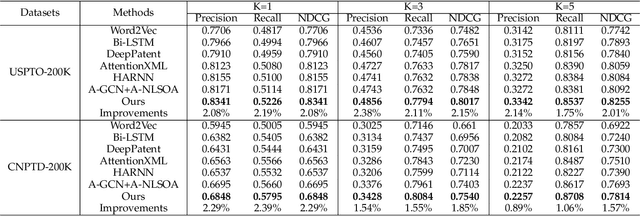
Patent classification aims to assign multiple International Patent Classification (IPC) codes to a given patent. Recent methods for automatically classifying patents mainly focus on analyzing the text descriptions of patents. However, apart from the texts, each patent is also associated with some assignees, and the knowledge of their applied patents is often valuable for classification. Furthermore, the hierarchical taxonomy formulated by the IPC system provides important contextual information and enables models to leverage the correlations between IPC codes for more accurate classification. However, existing methods fail to incorporate the above aspects. In this paper, we propose an integrated framework that comprehensively considers the information on patents for patent classification. To be specific, we first present an IPC codes correlations learning module to derive their semantic representations via adaptively passing and aggregating messages within the same level and across different levels along the hierarchical taxonomy. Moreover, we design a historical application patterns learning component to incorporate the corresponding assignee's previous patents by a dual channel aggregation mechanism. Finally, we combine the contextual information of patent texts that contains the semantics of IPC codes, and assignees' sequential preferences to make predictions. Experiments on real-world datasets demonstrate the superiority of our approach over the existing methods. Besides, we present the model's ability to capture the temporal patterns of assignees and the semantic dependencies among IPC codes.
Semantic-Guided Feature Distillation for Multimodal Recommendation
Aug 06, 2023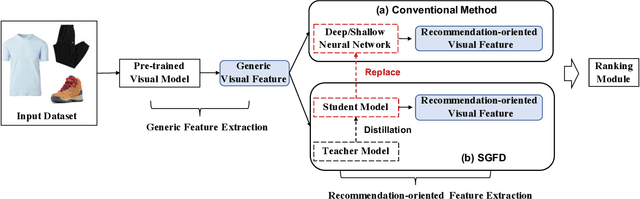
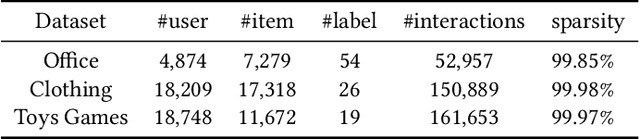
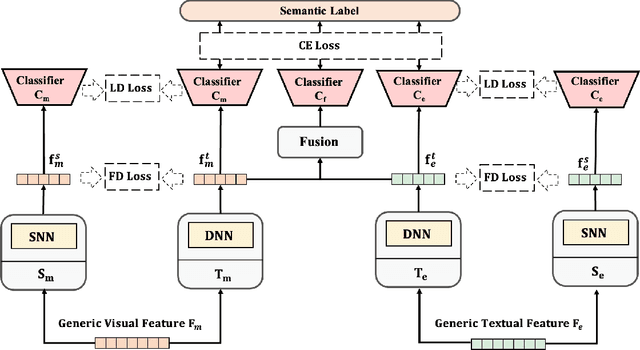
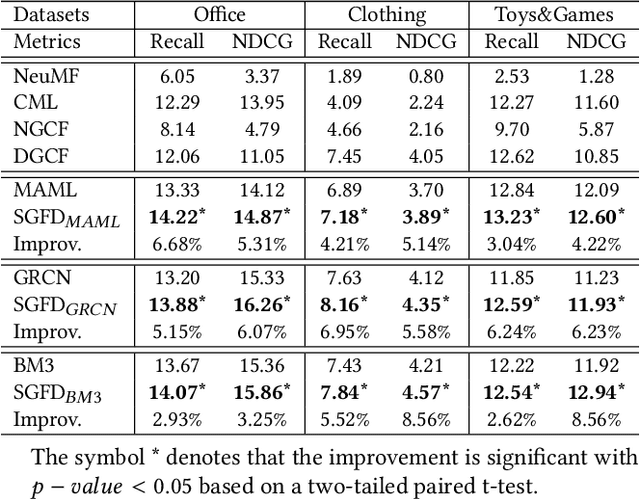
Multimodal recommendation exploits the rich multimodal information associated with users or items to enhance the representation learning for better performance. In these methods, end-to-end feature extractors (e.g., shallow/deep neural networks) are often adopted to tailor the generic multimodal features that are extracted from raw data by pre-trained models for recommendation. However, compact extractors, such as shallow neural networks, may find it challenging to extract effective information from complex and high-dimensional generic modality features. Conversely, DNN-based extractors may encounter the data sparsity problem in recommendation. To address this problem, we propose a novel model-agnostic approach called Semantic-guided Feature Distillation (SGFD), which employs a teacher-student framework to extract feature for multimodal recommendation. The teacher model first extracts rich modality features from the generic modality feature by considering both the semantic information of items and the complementary information of multiple modalities. SGFD then utilizes response-based and feature-based distillation loss to effectively transfer the knowledge encoded in the teacher model to the student model. To evaluate the effectiveness of our SGFD, we integrate SGFD into three backbone multimodal recommendation models. Extensive experiments on three public real-world datasets demonstrate that SGFD-enhanced models can achieve substantial improvement over their counterparts.
* ACM Multimedia 2023 Accepted
Information Screening whilst Exploiting! Multimodal Relation Extraction with Feature Denoising and Multimodal Topic Modeling
May 25, 2023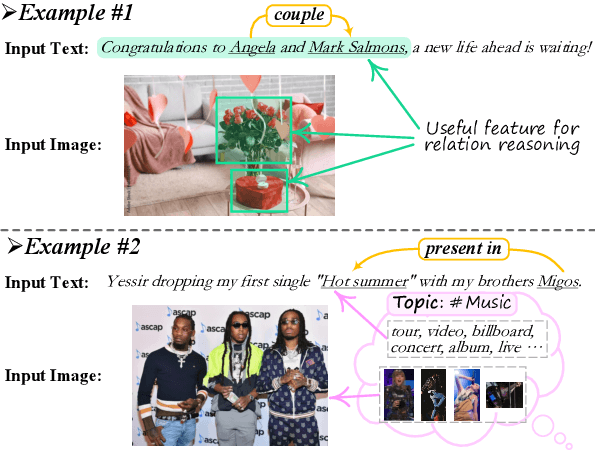
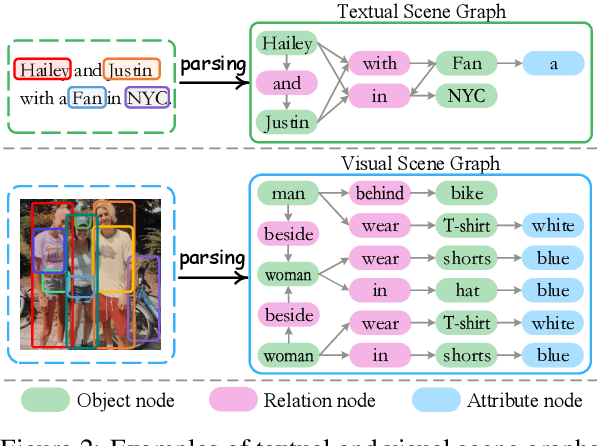
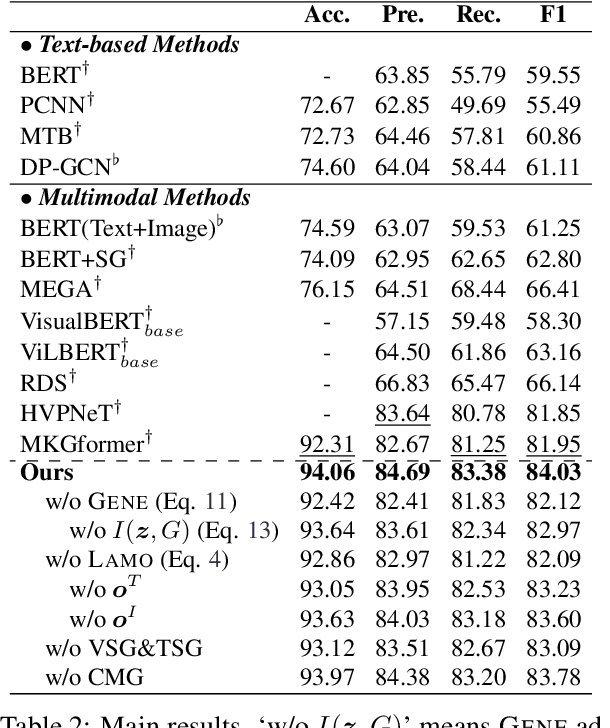
Existing research on multimodal relation extraction (MRE) faces two co-existing challenges, internal-information over-utilization and external-information under-exploitation. To combat that, we propose a novel framework that simultaneously implements the idea of internal-information screening and external-information exploiting. First, we represent the fine-grained semantic structures of the input image and text with the visual and textual scene graphs, which are further fused into a unified cross-modal graph (CMG). Based on CMG, we perform structure refinement with the guidance of the graph information bottleneck principle, actively denoising the less-informative features. Next, we perform topic modeling over the input image and text, incorporating latent multimodal topic features to enrich the contexts. On the benchmark MRE dataset, our system outperforms the current best model significantly. With further in-depth analyses, we reveal the great potential of our method for the MRE task. Our codes are open at https://github.com/ChocoWu/MRE-ISE.
EOG Artifact Removal from Single and Multi-channel EEG Recordings through the combination of Long Short-Term Memory Networks and Independent Component Analysis
Aug 25, 2023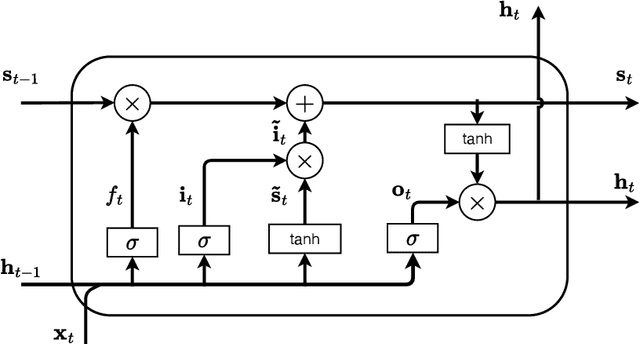
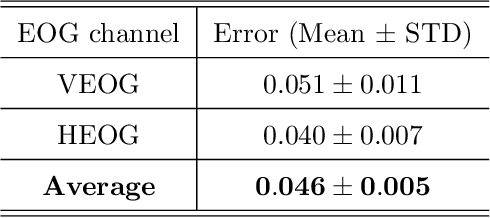

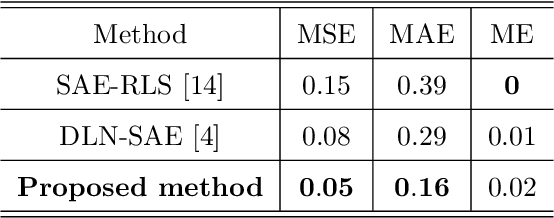
Introduction: Electroencephalogram (EEG) signals have gained significant popularity in various applications due to their rich information content. However, these signals are prone to contamination from various sources of artifacts, notably the electrooculogram (EOG) artifacts caused by eye movements. The most effective approach to mitigate EOG artifacts involves recording EOG signals simultaneously with EEG and employing blind source separation techniques, such as independent component analysis (ICA). Nevertheless, the availability of EOG recordings is not always feasible, particularly in pre-recorded datasets. Objective: In this paper, we present a novel methodology that combines a long short-term memory (LSTM)-based neural network with ICA to address the challenge of EOG artifact removal from contaminated EEG signals. Approach: Our approach aims to accomplish two primary objectives: 1) estimate the horizontal and vertical EOG signals from the contaminated EEG data, and 2) employ ICA to eliminate the estimated EOG signals from the EEG, thereby producing an artifact-free EEG signal. Main results: To evaluate the performance of our proposed method, we conducted experiments on a publicly available dataset comprising recordings from 27 participants. We employed well-established metrics such as mean squared error, mean absolute error, and mean error to assess the quality of our artifact removal technique. Significance: Furthermore, we compared the performance of our approach with two state-of-the-art deep learning-based methods reported in the literature, demonstrating the superior performance of our proposed methodology.
Rethinking Language Models as Symbolic Knowledge Graphs
Aug 25, 2023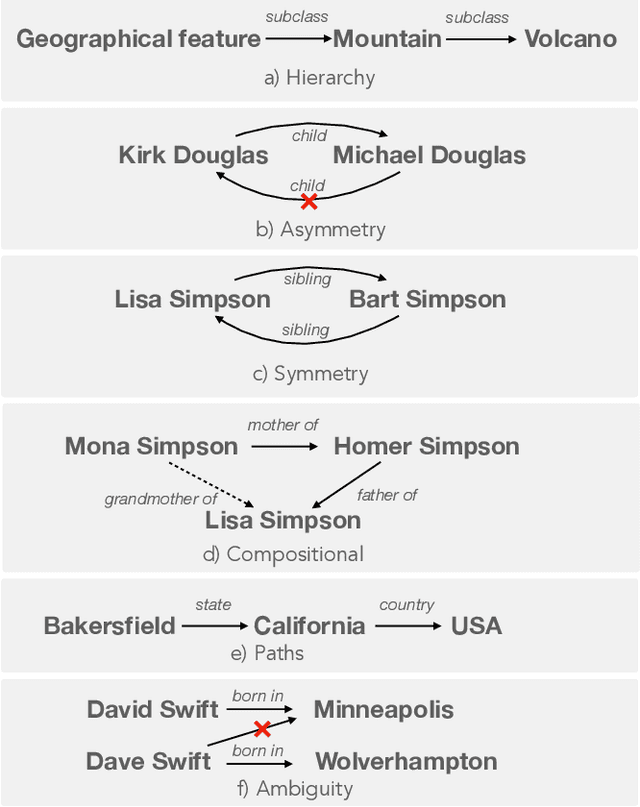
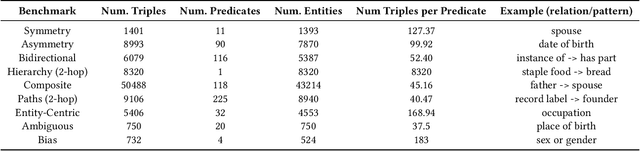

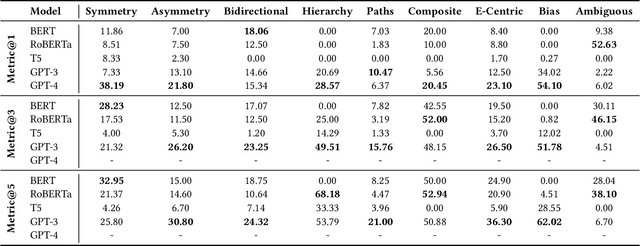
Symbolic knowledge graphs (KGs) play a pivotal role in knowledge-centric applications such as search, question answering and recommendation. As contemporary language models (LMs) trained on extensive textual data have gained prominence, researchers have extensively explored whether the parametric knowledge within these models can match up to that present in knowledge graphs. Various methodologies have indicated that enhancing the size of the model or the volume of training data enhances its capacity to retrieve symbolic knowledge, often with minimal or no human supervision. Despite these advancements, there is a void in comprehensively evaluating whether LMs can encompass the intricate topological and semantic attributes of KGs, attributes crucial for reasoning processes. In this work, we provide an exhaustive evaluation of language models of varying sizes and capabilities. We construct nine qualitative benchmarks that encompass a spectrum of attributes including symmetry, asymmetry, hierarchy, bidirectionality, compositionality, paths, entity-centricity, bias and ambiguity. Additionally, we propose novel evaluation metrics tailored for each of these attributes. Our extensive evaluation of various LMs shows that while these models exhibit considerable potential in recalling factual information, their ability to capture intricate topological and semantic traits of KGs remains significantly constrained. We note that our proposed evaluation metrics are more reliable in evaluating these abilities than the existing metrics. Lastly, some of our benchmarks challenge the common notion that larger LMs (e.g., GPT-4) universally outshine their smaller counterparts (e.g., BERT).
Source-free Domain Adaptive Human Pose Estimation
Aug 15, 2023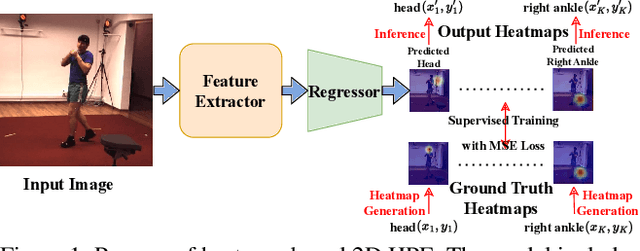
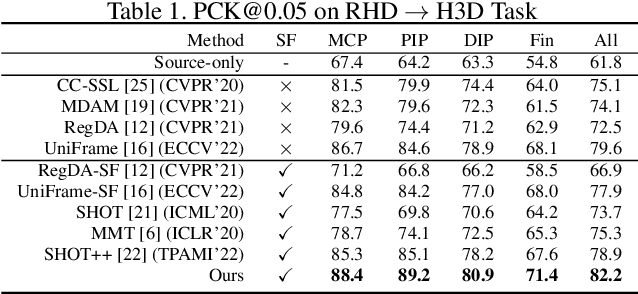
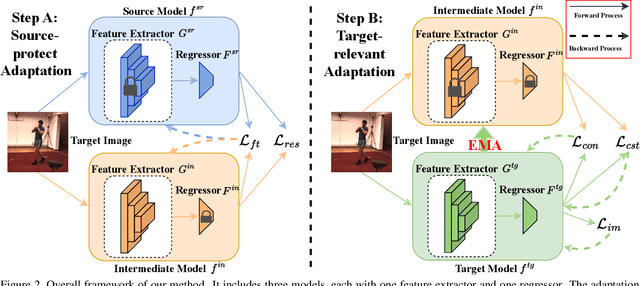
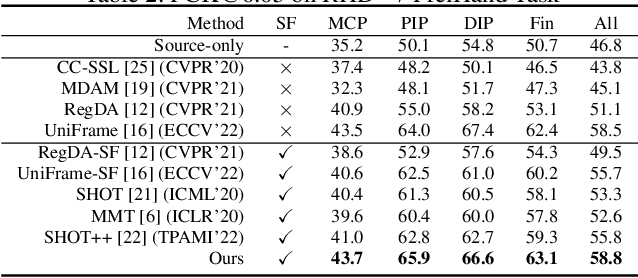
Human Pose Estimation (HPE) is widely used in various fields, including motion analysis, healthcare, and virtual reality. However, the great expenses of labeled real-world datasets present a significant challenge for HPE. To overcome this, one approach is to train HPE models on synthetic datasets and then perform domain adaptation (DA) on real-world data. Unfortunately, existing DA methods for HPE neglect data privacy and security by using both source and target data in the adaptation process. To this end, we propose a new task, named source-free domain adaptive HPE, which aims to address the challenges of cross-domain learning of HPE without access to source data during the adaptation process. We further propose a novel framework that consists of three models: source model, intermediate model, and target model, which explores the task from both source-protect and target-relevant perspectives. The source-protect module preserves source information more effectively while resisting noise, and the target-relevant module reduces the sparsity of spatial representations by building a novel spatial probability space, and pose-specific contrastive learning and information maximization are proposed on the basis of this space. Comprehensive experiments on several domain adaptive HPE benchmarks show that the proposed method outperforms existing approaches by a considerable margin. The codes are available at https://github.com/davidpengucf/SFDAHPE.
From Commit Message Generation to History-Aware Commit Message Completion
Aug 15, 2023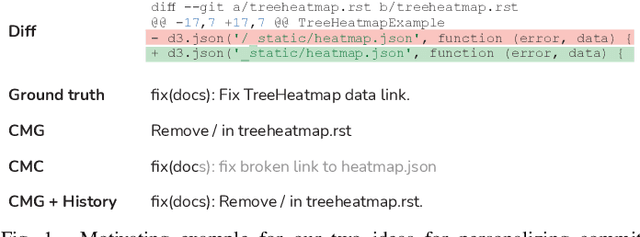
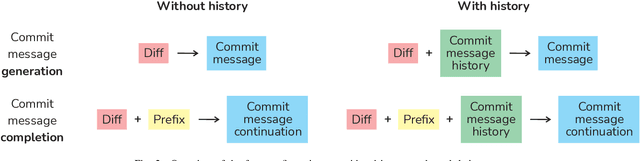
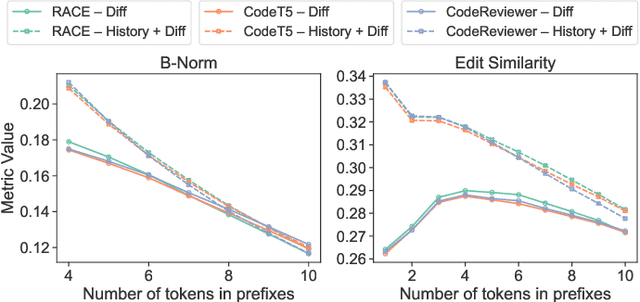
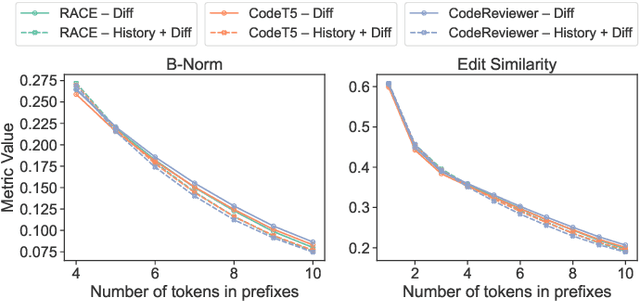
Commit messages are crucial to software development, allowing developers to track changes and collaborate effectively. Despite their utility, most commit messages lack important information since writing high-quality commit messages is tedious and time-consuming. The active research on commit message generation (CMG) has not yet led to wide adoption in practice. We argue that if we could shift the focus from commit message generation to commit message completion and use previous commit history as additional context, we could significantly improve the quality and the personal nature of the resulting commit messages. In this paper, we propose and evaluate both of these novel ideas. Since the existing datasets lack historical data, we collect and share a novel dataset called CommitChronicle, containing 10.7M commits across 20 programming languages. We use this dataset to evaluate the completion setting and the usefulness of the historical context for state-of-the-art CMG models and GPT-3.5-turbo. Our results show that in some contexts, commit message completion shows better results than generation, and that while in general GPT-3.5-turbo performs worse, it shows potential for long and detailed messages. As for the history, the results show that historical information improves the performance of CMG models in the generation task, and the performance of GPT-3.5-turbo in both generation and completion.
CALYPSO: LLMs as Dungeon Masters' Assistants
Aug 15, 2023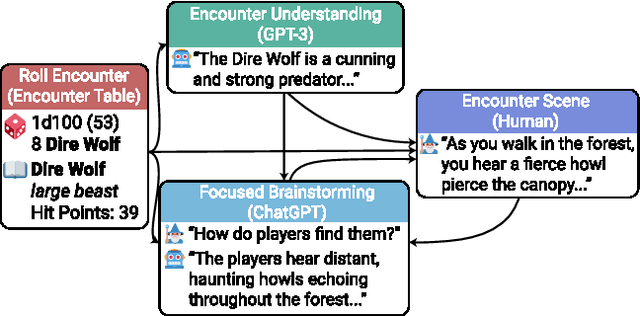


The role of a Dungeon Master, or DM, in the game Dungeons & Dragons is to perform multiple tasks simultaneously. The DM must digest information about the game setting and monsters, synthesize scenes to present to other players, and respond to the players' interactions with the scene. Doing all of these tasks while maintaining consistency within the narrative and story world is no small feat of human cognition, making the task tiring and unapproachable to new players. Large language models (LLMs) like GPT-3 and ChatGPT have shown remarkable abilities to generate coherent natural language text. In this paper, we conduct a formative evaluation with DMs to establish the use cases of LLMs in D&D and tabletop gaming generally. We introduce CALYPSO, a system of LLM-powered interfaces that support DMs with information and inspiration specific to their own scenario. CALYPSO distills game context into bite-sized prose and helps brainstorm ideas without distracting the DM from the game. When given access to CALYPSO, DMs reported that it generated high-fidelity text suitable for direct presentation to players, and low-fidelity ideas that the DM could develop further while maintaining their creative agency. We see CALYPSO as exemplifying a paradigm of AI-augmented tools that provide synchronous creative assistance within established game worlds, and tabletop gaming more broadly.
Exploring Predicate Visual Context in Detecting of Human-Object Interactions
Aug 11, 2023


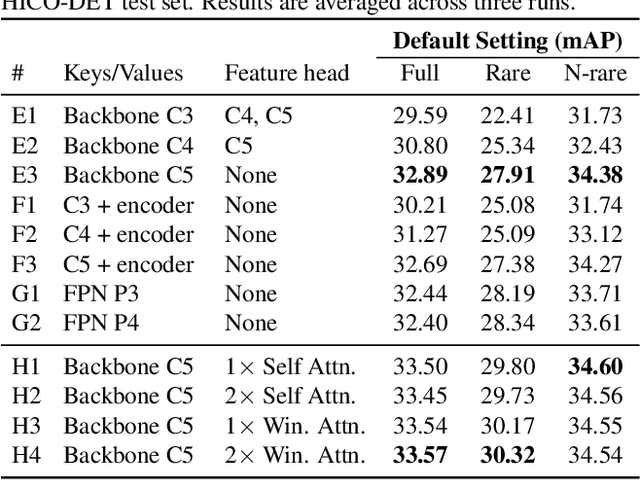
Recently, the DETR framework has emerged as the dominant approach for human--object interaction (HOI) research. In particular, two-stage transformer-based HOI detectors are amongst the most performant and training-efficient approaches. However, these often condition HOI classification on object features that lack fine-grained contextual information, eschewing pose and orientation information in favour of visual cues about object identity and box extremities. This naturally hinders the recognition of complex or ambiguous interactions. In this work, we study these issues through visualisations and carefully designed experiments. Accordingly, we investigate how best to re-introduce image features via cross-attention. With an improved query design, extensive exploration of keys and values, and box pair positional embeddings as spatial guidance, our model with enhanced predicate visual context (PViC) outperforms state-of-the-art methods on the HICO-DET and V-COCO benchmarks, while maintaining low training cost.