 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Double-chain Constraints for 3D Human Pose Estimation in Images and Videos
Aug 10, 2023
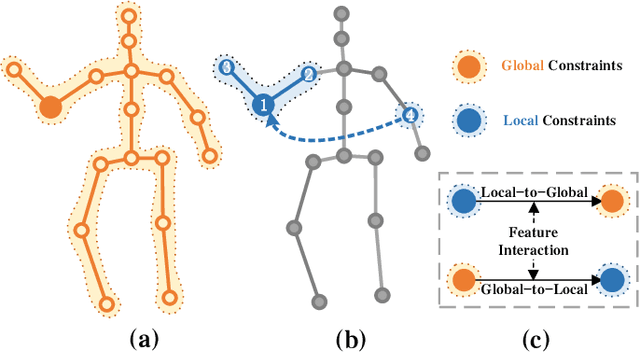

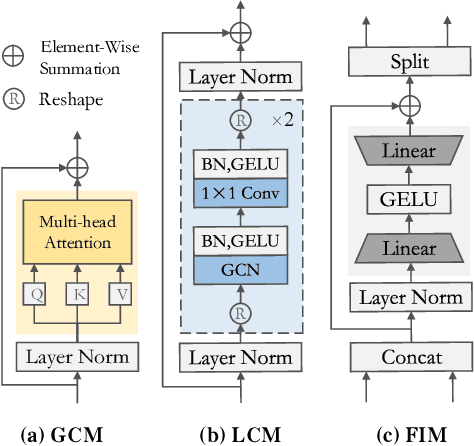
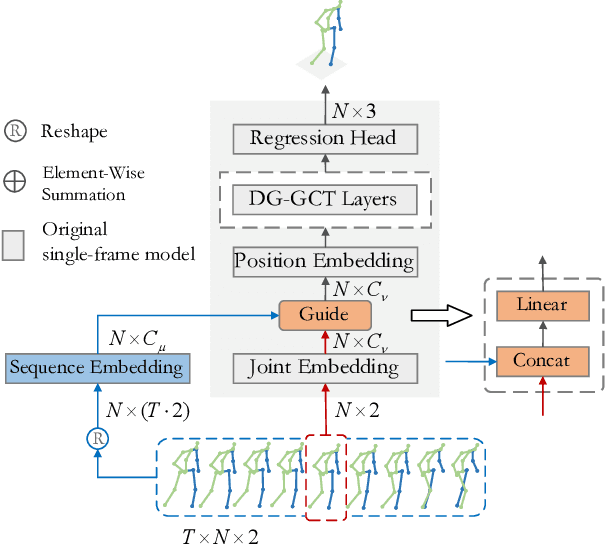
Reconstructing 3D poses from 2D poses lacking depth information is particularly challenging due to the complexity and diversity of human motion. The key is to effectively model the spatial constraints between joints to leverage their inherent dependencies. Thus, we propose a novel model, called Double-chain Graph Convolutional Transformer (DC-GCT), to constrain the pose through a double-chain design consisting of local-to-global and global-to-local chains to obtain a complex representation more suitable for the current human pose. Specifically, we combine the advantages of GCN and Transformer and design a Local Constraint Module (LCM) based on GCN and a Global Constraint Module (GCM) based on self-attention mechanism as well as a Feature Interaction Module (FIM). The proposed method fully captures the multi-level dependencies between human body joints to optimize the modeling capability of the model. Moreover, we propose a method to use temporal information into the single-frame model by guiding the video sequence embedding through the joint embedding of the target frame, with negligible increase in computational cost. Experimental results demonstrate that DC-GCT achieves state-of-the-art performance on two challenging datasets (Human3.6M and MPI-INF-3DHP). Notably, our model achieves state-of-the-art performance on all action categories in the Human3.6M dataset using detected 2D poses from CPN, and our code is available at: https://github.com/KHB1698/DC-GCT.
Deep Semantic Graph Matching for Large-scale Outdoor Point Clouds Registration
Aug 10, 2023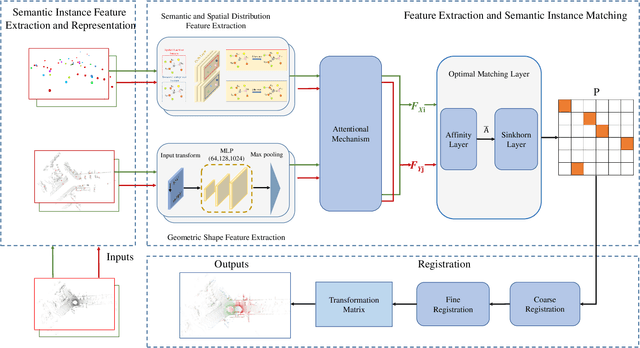
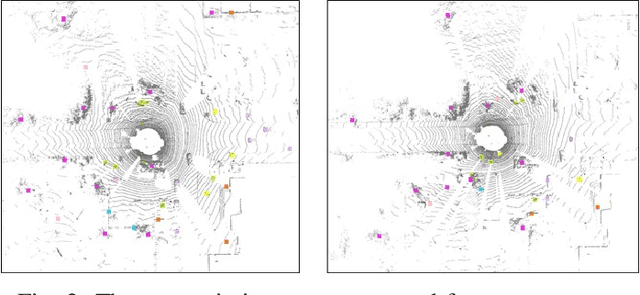
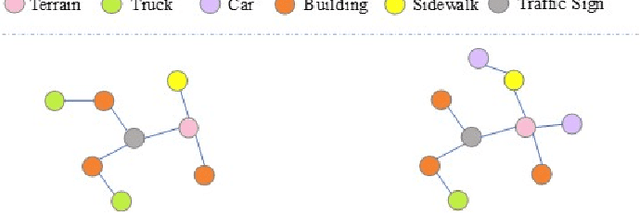
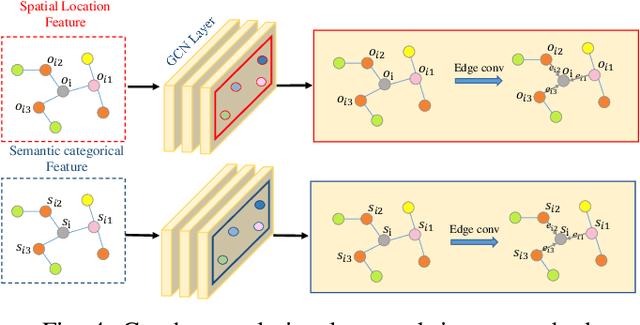
The current point cloud registration methods are mainly based on geometric information and usually ignore the semantic information in the point clouds. In this paper, we treat the point cloud registration problem as semantic instance matching and registration task, and propose a deep semantic graph matching method for large-scale outdoor point cloud registration. Firstly, the semantic category labels of 3D point clouds are obtained by utilizing large-scale point cloud semantic segmentation network. The adjacent points with the same category labels are then clustered together by using Euclidean clustering algorithm to obtain the semantic instances. Secondly, the semantic adjacency graph is constructed based on the spatial adjacency relation of semantic instances. Three kinds of high-dimensional features including geometric shape features, semantic categorical features and spatial distribution features are learned through graph convolutional network, and enhanced based on attention mechanism. Thirdly, the semantic instance matching problem is modeled as an optimal transport problem, and solved through an optimal matching layer. Finally, according to the matched semantic instances, the geometric transformation matrix between two point clouds is first obtained by SVD algorithm and then refined by ICP algorithm. The experiments are cconducted on the KITTI Odometry dataset, and the average relative translation error and average relative rotation error of the proposed method are 6.6cm and 0.229{\deg} respectively.
CSPM: A Contrastive Spatiotemporal Preference Model for CTR Prediction in On-Demand Food Delivery Services
Aug 10, 2023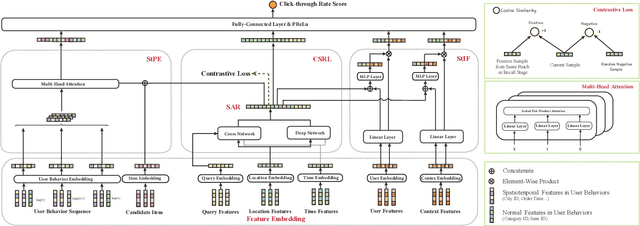
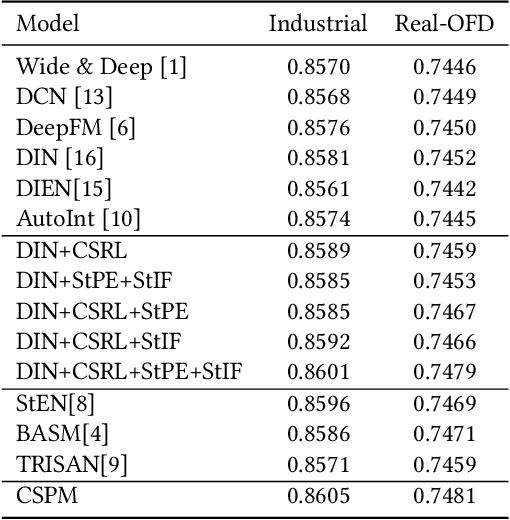
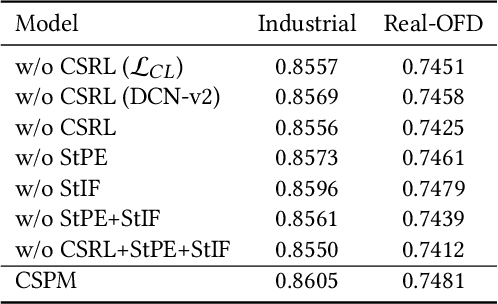
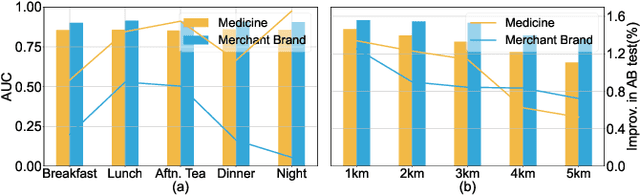
Click-through rate (CTR) prediction is a crucial task in the context of an online on-demand food delivery (OFD) platform for precisely estimating the probability of a user clicking on food items. Unlike universal e-commerce platforms such as Taobao and Amazon, user behaviors and interests on the OFD platform are more location and time-sensitive due to limited delivery ranges and regional commodity supplies. However, existing CTR prediction algorithms in OFD scenarios concentrate on capturing interest from historical behavior sequences, which fails to effectively model the complex spatiotemporal information within features, leading to poor performance. To address this challenge, this paper introduces the Contrastive Sres under different search states using three modules: contrastive spatiotemporal representation learning (CSRL), spatiotemporal preference extractor (StPE), and spatiotemporal information filter (StIF). CSRL utilizes a contrastive learning framework to generate a spatiotemporal activation representation (SAR) for the search action. StPE employs SAR to activate users' diverse preferences related to location and time from the historical behavior sequence field, using a multi-head attention mechanism. StIF incorporates SAR into a gating network to automatically capture important features with latent spatiotemporal effects. Extensive experiments conducted on two large-scale industrial datasets demonstrate the state-of-the-art performance of CSPM. Notably, CSPM has been successfully deployed in Alibaba's online OFD platform Ele.me, resulting in a significant 0.88% lift in CTR, which has substantial business implications.
Evaluating Open-Domain Dialogues in Latent Space with Next Sentence Prediction and Mutual Information
Jun 10, 2023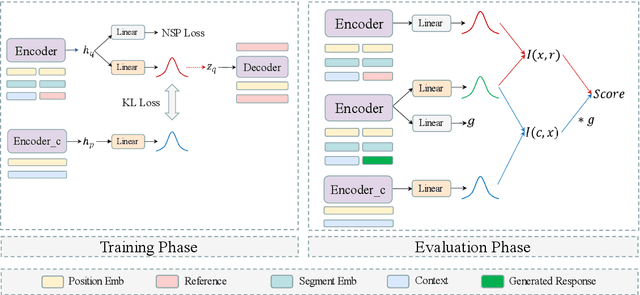
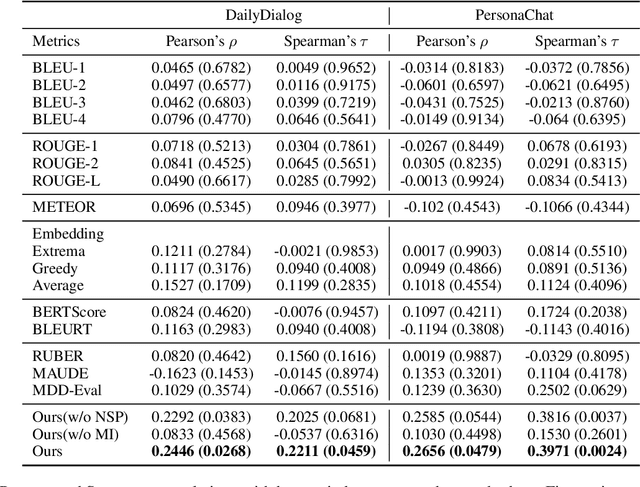
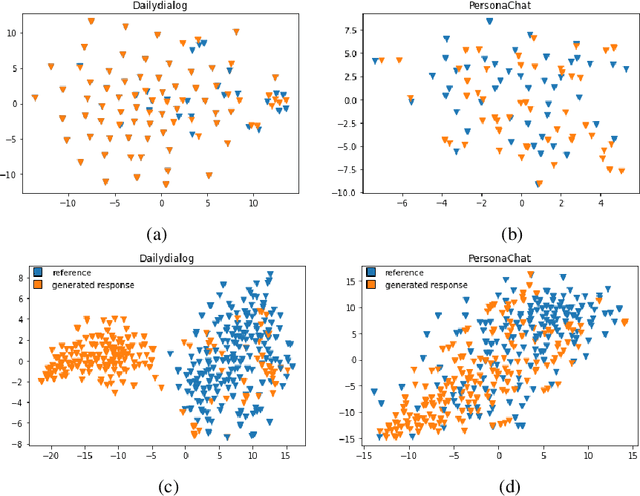
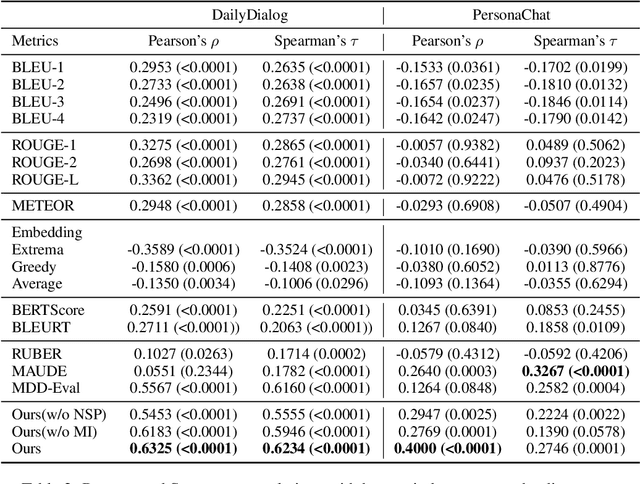
The long-standing one-to-many issue of the open-domain dialogues poses significant challenges for automatic evaluation methods, i.e., there may be multiple suitable responses which differ in semantics for a given conversational context. To tackle this challenge, we propose a novel learning-based automatic evaluation metric (CMN), which can robustly evaluate open-domain dialogues by augmenting Conditional Variational Autoencoders (CVAEs) with a Next Sentence Prediction (NSP) objective and employing Mutual Information (MI) to model the semantic similarity of text in the latent space. Experimental results on two open-domain dialogue datasets demonstrate the superiority of our method compared with a wide range of baselines, especially in handling responses which are distant to the golden reference responses in semantics.
WaveNeRF: Wavelet-based Generalizable Neural Radiance Fields
Aug 09, 2023
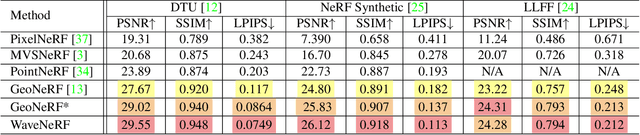
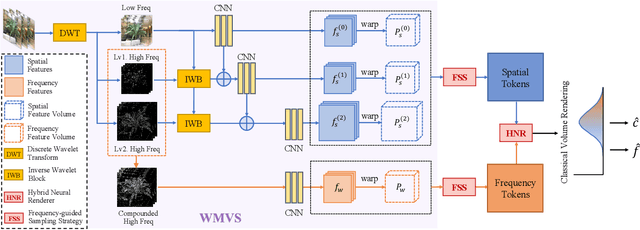

Neural Radiance Field (NeRF) has shown impressive performance in novel view synthesis via implicit scene representation. However, it usually suffers from poor scalability as requiring densely sampled images for each new scene. Several studies have attempted to mitigate this problem by integrating Multi-View Stereo (MVS) technique into NeRF while they still entail a cumbersome fine-tuning process for new scenes. Notably, the rendering quality will drop severely without this fine-tuning process and the errors mainly appear around the high-frequency features. In the light of this observation, we design WaveNeRF, which integrates wavelet frequency decomposition into MVS and NeRF to achieve generalizable yet high-quality synthesis without any per-scene optimization. To preserve high-frequency information when generating 3D feature volumes, WaveNeRF builds Multi-View Stereo in the Wavelet domain by integrating the discrete wavelet transform into the classical cascade MVS, which disentangles high-frequency information explicitly. With that, disentangled frequency features can be injected into classic NeRF via a novel hybrid neural renderer to yield faithful high-frequency details, and an intuitive frequency-guided sampling strategy can be designed to suppress artifacts around high-frequency regions. Extensive experiments over three widely studied benchmarks show that WaveNeRF achieves superior generalizable radiance field modeling when only given three images as input.
4DRVO-Net: Deep 4D Radar-Visual Odometry Using Multi-Modal and Multi-Scale Adaptive Fusion
Aug 12, 2023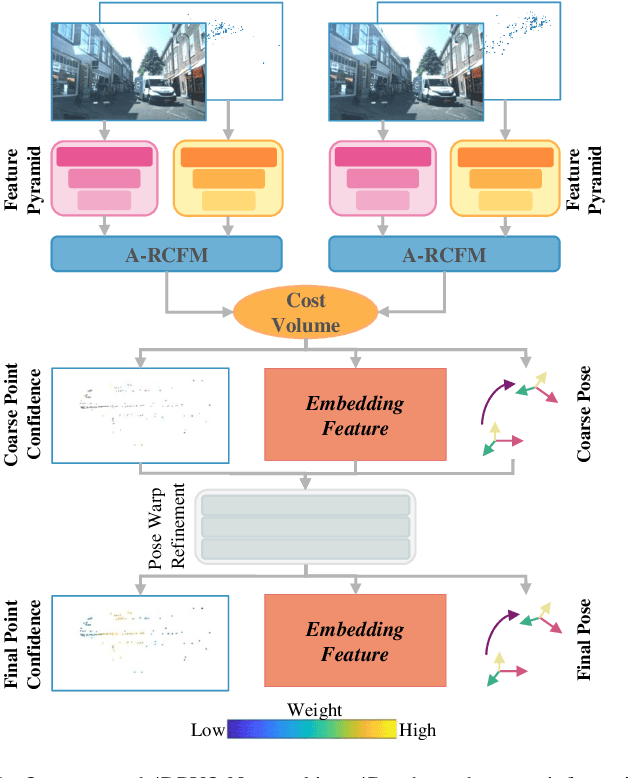
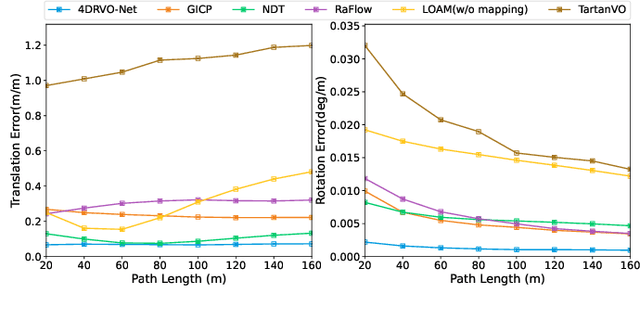
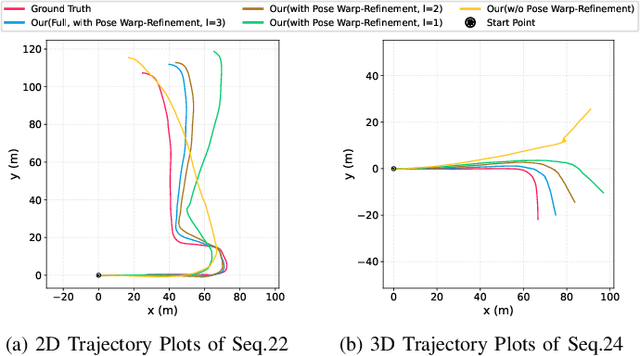
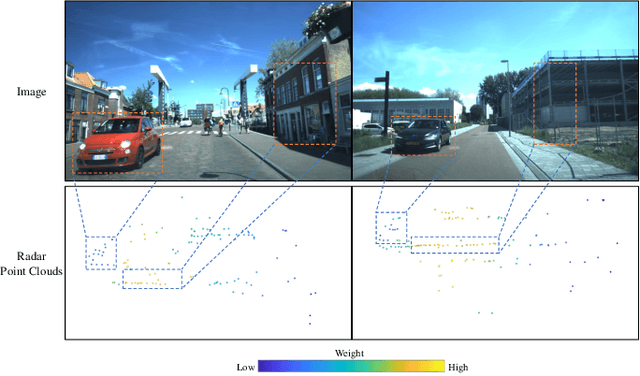
Four-dimensional (4D) radar--visual odometry (4DRVO) integrates complementary information from 4D radar and cameras, making it an attractive solution for achieving accurate and robust pose estimation. However, 4DRVO may exhibit significant tracking errors owing to three main factors: 1) sparsity of 4D radar point clouds; 2) inaccurate data association and insufficient feature interaction between the 4D radar and camera; and 3) disturbances caused by dynamic objects in the environment, affecting odometry estimation. In this paper, we present 4DRVO-Net, which is a method for 4D radar--visual odometry. This method leverages the feature pyramid, pose warping, and cost volume (PWC) network architecture to progressively estimate and refine poses. Specifically, we propose a multi-scale feature extraction network called Radar-PointNet++ that fully considers rich 4D radar point information, enabling fine-grained learning for sparse 4D radar point clouds. To effectively integrate the two modalities, we design an adaptive 4D radar--camera fusion module (A-RCFM) that automatically selects image features based on 4D radar point features, facilitating multi-scale cross-modal feature interaction and adaptive multi-modal feature fusion. In addition, we introduce a velocity-guided point-confidence estimation module to measure local motion patterns, reduce the influence of dynamic objects and outliers, and provide continuous updates during pose refinement. We demonstrate the excellent performance of our method and the effectiveness of each module design on both the VoD and in-house datasets. Our method outperforms all learning-based and geometry-based methods for most sequences in the VoD dataset. Furthermore, it has exhibited promising performance that closely approaches that of the 64-line LiDAR odometry results of A-LOAM without mapping optimization.
An End-to-end Food Portion Estimation Framework Based on Shape Reconstruction from Monocular Image
Aug 03, 2023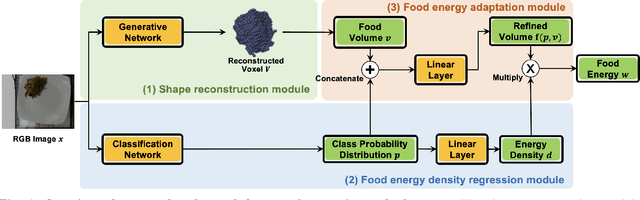
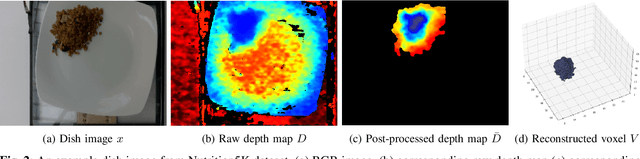


Dietary assessment is a key contributor to monitoring health status. Existing self-report methods are tedious and time-consuming with substantial biases and errors. Image-based food portion estimation aims to estimate food energy values directly from food images, showing great potential for automated dietary assessment solutions. Existing image-based methods either use a single-view image or incorporate multi-view images and depth information to estimate the food energy, which either has limited performance or creates user burdens. In this paper, we propose an end-to-end deep learning framework for food energy estimation from a monocular image through 3D shape reconstruction. We leverage a generative model to reconstruct the voxel representation of the food object from the input image to recover the missing 3D information. Our method is evaluated on a publicly available food image dataset Nutrition5k, resulting a Mean Absolute Error (MAE) of 40.05 kCal and Mean Absolute Percentage Error (MAPE) of 11.47% for food energy estimation. Our method uses RGB image as the only input at the inference stage and achieves competitive results compared to the existing method requiring both RGB and depth information.
Extraction of Road Users' Behavior From Realistic Data According to Assumptions in Safety-Related Models for Automated Driving Systems
Jul 31, 2023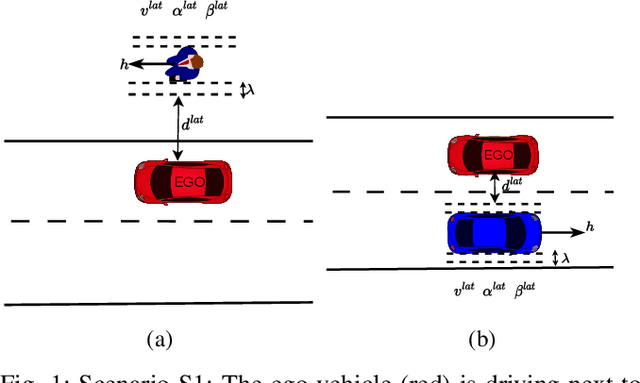
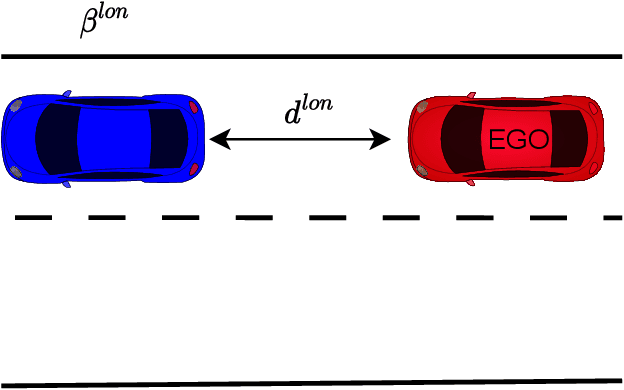
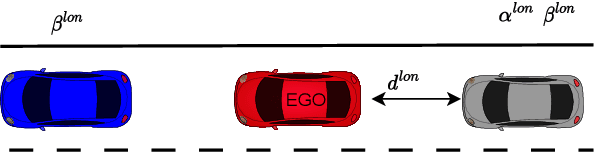
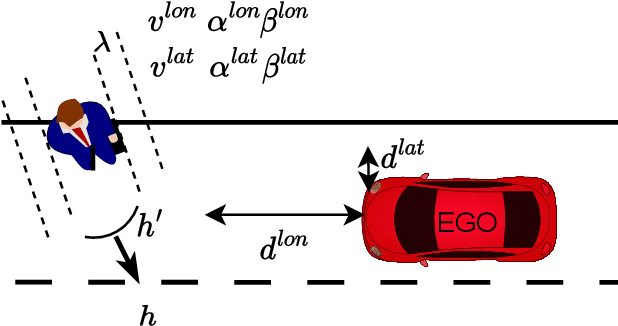
In this work, we utilized the methodology outlined in the IEEE Standard 2846-2022 for "Assumptions in Safety-Related Models for Automated Driving Systems" to extract information on the behavior of other road users in driving scenarios. This method includes defining high-level scenarios, determining kinematic characteristics, evaluating safety relevance, and making assumptions on reasonably predictable behaviors. The assumptions were expressed as kinematic bounds. The numerical values for these bounds were extracted using Python scripts to process realistic data from the UniD dataset. The resulting information enables Automated Driving Systems designers to specify the parameters and limits of a road user's state in a specific scenario. This information can be utilized to establish starting conditions for testing a vehicle that is equipped with an Automated Driving System in simulations or on actual roads.
With a Little Help from the Authors: Reproducing Human Evaluation of an MT Error Detector
Aug 12, 2023
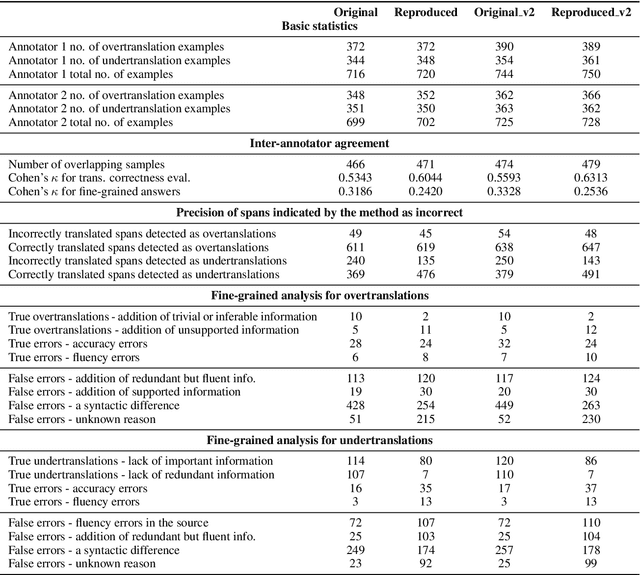

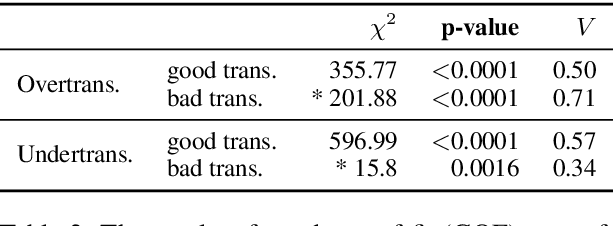
This work presents our efforts to reproduce the results of the human evaluation experiment presented in the paper of Vamvas and Sennrich (2022), which evaluated an automatic system detecting over- and undertranslations (translations containing more or less information than the original) in machine translation (MT) outputs. Despite the high quality of the documentation and code provided by the authors, we discuss some problems we found in reproducing the exact experimental setup and offer recommendations for improving reproducibility. Our replicated results generally confirm the conclusions of the original study, but in some cases, statistically significant differences were observed, suggesting a high variability of human annotation.
Boosting Cross-Quality Face Verification using Blind Face Restoration
Aug 15, 2023


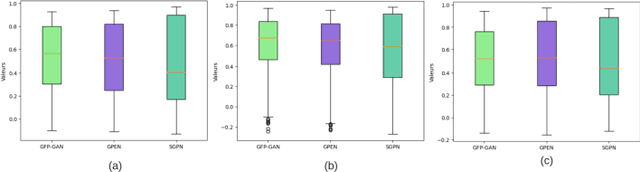
In recent years, various Blind Face Restoration (BFR) techniques were developed. These techniques transform low quality faces suffering from multiple degradations to more realistic and natural face images with high perceptual quality. However, it is crucial for the task of face verification to not only enhance the perceptual quality of the low quality images but also to improve the biometric-utility face quality metrics. Furthermore, preserving the valuable identity information is of great importance. In this paper, we investigate the impact of applying three state-of-the-art blind face restoration techniques namely, GFP-GAN, GPEN and SGPN on the performance of face verification system under very challenging environment characterized by very low quality images. Extensive experimental results on the recently proposed cross-quality LFW database using three state-of-the-art deep face recognition models demonstrate the effectiveness of GFP-GAN in boosting significantly the face verification accuracy.