 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Geometric Notion of Causal Probing
Jul 30, 2023
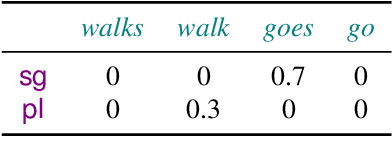
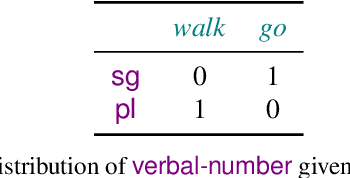
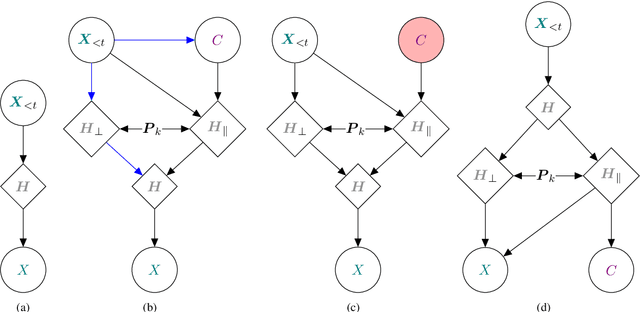
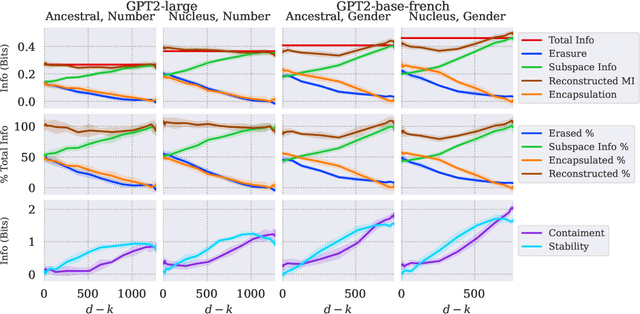
Large language models rely on real-valued representations of text to make their predictions. These representations contain information learned from the data that the model has trained on, including knowledge of linguistic properties and forms of demographic bias, e.g., based on gender. A growing body of work has considered removing information about concepts such as these using orthogonal projections onto subspaces of the representation space. We contribute to this body of work by proposing a formal definition of $\textit{intrinsic}$ information in a subspace of a language model's representation space. We propose a counterfactual approach that avoids the failure mode of spurious correlations (Kumar et al., 2022) by treating components in the subspace and its orthogonal complement independently. We show that our counterfactual notion of information in a subspace is optimized by a $\textit{causal}$ concept subspace. Furthermore, this intervention allows us to attempt concept controlled generation by manipulating the value of the conceptual component of a representation. Empirically, we find that R-LACE (Ravfogel et al., 2022) returns a one-dimensional subspace containing roughly half of total concept information under our framework. Our causal controlled intervention shows that, for at least one model, the subspace returned by R-LACE can be used to manipulate the concept value of the generated word with precision.
Robust Beamforming for IRS Aided MIMO Full Duplex Systems
Aug 15, 2023
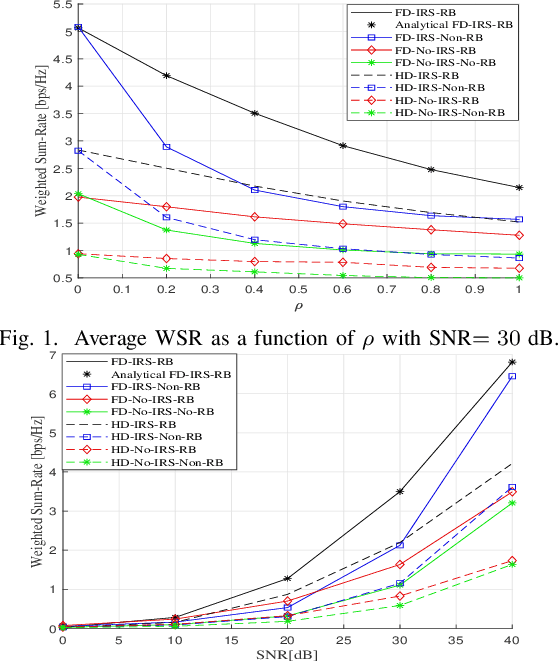
In this paper, a novel robust beamforming for an intelligent reflecting surface (IRS) assisted FD system is presented. Since perfect channel state information (CSI) is often challenging to acquire in practice, we consider the case of imperfect CSI and adopt a statistically robust beamforming approach to maximize the ergodic weighted sum rate (WSR). We also analyze the achievable WSR of an IRS-assisted FD with imperfect CSI, for which the lower and the upper bounds are derived. The ergodic WSR maximization problem is tackled based on the expected Weighted Minimum Mean Squared Error (WMMSE), which is guaranteed to converge to a local optimum. The effectiveness of the proposed design is investigated with extensive simulation results. It is shown that our robust design achieves significant performance gain compared to the naive beamforming approaches and considerably outperforms the robust Half-Duplex (HD) system.
FedPerfix: Towards Partial Model Personalization of Vision Transformers in Federated Learning
Aug 17, 2023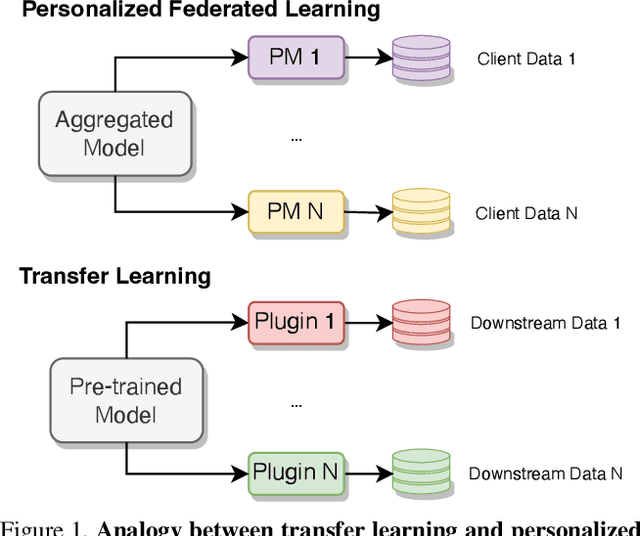
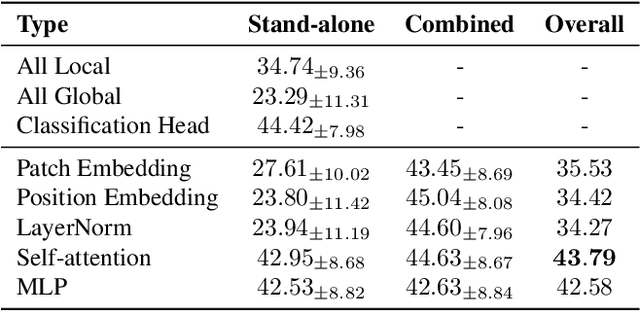
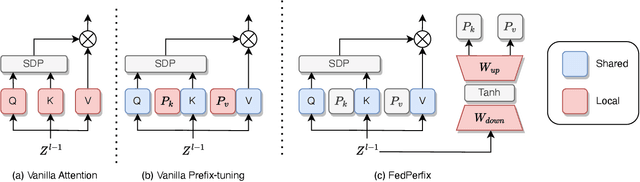
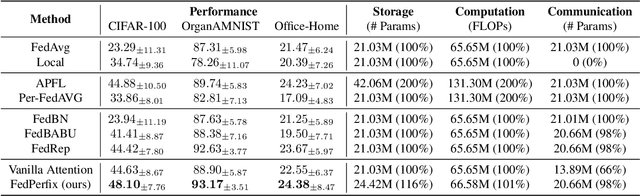
Personalized Federated Learning (PFL) represents a promising solution for decentralized learning in heterogeneous data environments. Partial model personalization has been proposed to improve the efficiency of PFL by selectively updating local model parameters instead of aggregating all of them. However, previous work on partial model personalization has mainly focused on Convolutional Neural Networks (CNNs), leaving a gap in understanding how it can be applied to other popular models such as Vision Transformers (ViTs). In this work, we investigate where and how to partially personalize a ViT model. Specifically, we empirically evaluate the sensitivity to data distribution of each type of layer. Based on the insights that the self-attention layer and the classification head are the most sensitive parts of a ViT, we propose a novel approach called FedPerfix, which leverages plugins to transfer information from the aggregated model to the local client as a personalization. Finally, we evaluate the proposed approach on CIFAR-100, OrganAMNIST, and Office-Home datasets and demonstrate its effectiveness in improving the model's performance compared to several advanced PFL methods.
Point-aware Interaction and CNN-induced Refinement Network for RGB-D Salient Object Detection
Aug 17, 2023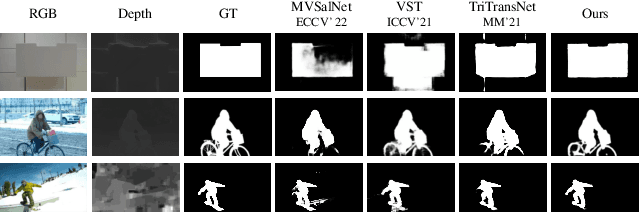
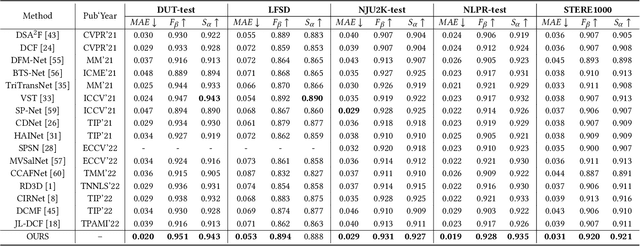
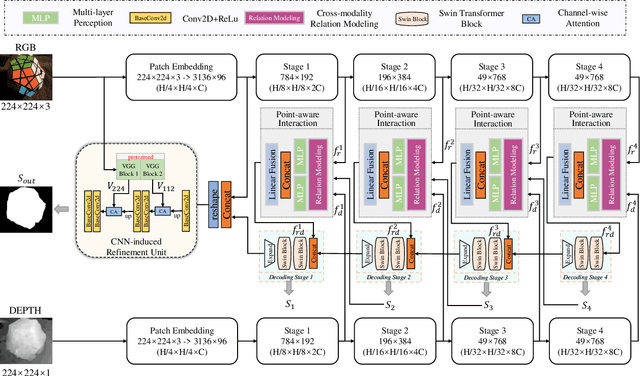
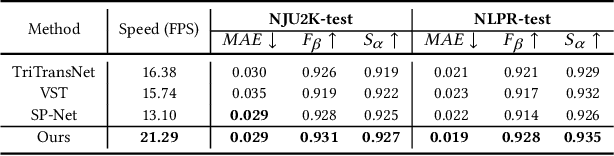
By integrating complementary information from RGB image and depth map, the ability of salient object detection (SOD) for complex and challenging scenes can be improved. In recent years, the important role of Convolutional Neural Networks (CNNs) in feature extraction and cross-modality interaction has been fully explored, but it is still insufficient in modeling global long-range dependencies of self-modality and cross-modality. To this end, we introduce CNNs-assisted Transformer architecture and propose a novel RGB-D SOD network with Point-aware Interaction and CNN-induced Refinement (PICR-Net). On the one hand, considering the prior correlation between RGB modality and depth modality, an attention-triggered cross-modality point-aware interaction (CmPI) module is designed to explore the feature interaction of different modalities with positional constraints. On the other hand, in order to alleviate the block effect and detail destruction problems brought by the Transformer naturally, we design a CNN-induced refinement (CNNR) unit for content refinement and supplementation. Extensive experiments on five RGB-D SOD datasets show that the proposed network achieves competitive results in both quantitative and qualitative comparisons.
Gesture Recognition based on Long-Short Term Memory Cells using Smartphone IMUs
Aug 16, 2023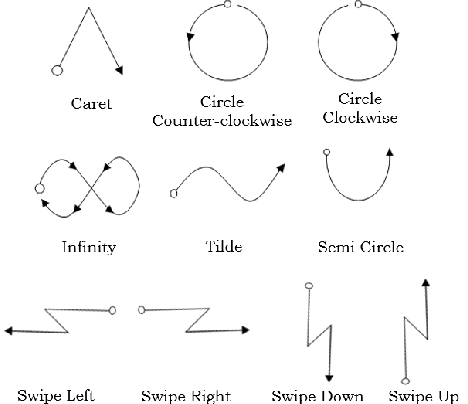
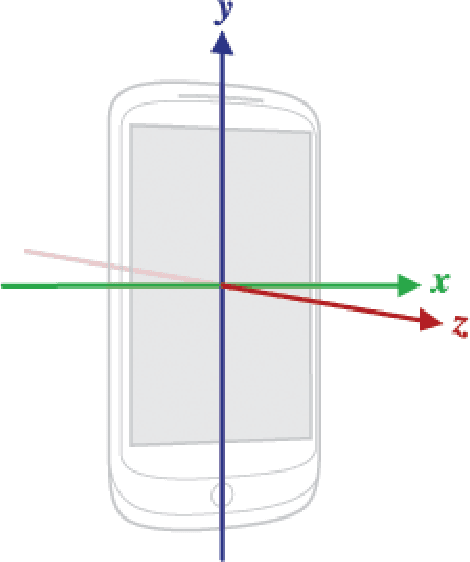
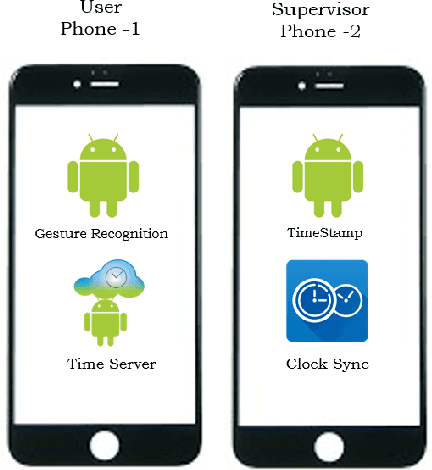
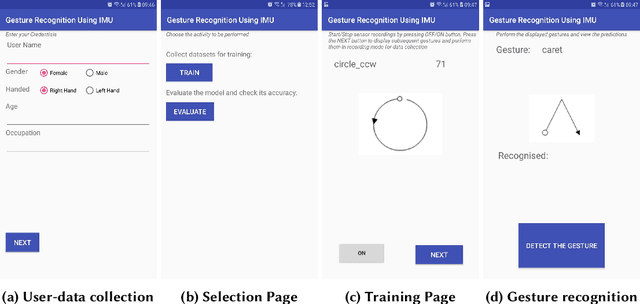
Over the last few decades, Smartphone technology has seen significant improvements. Enhancements specific to built-in Inertial Measurement Units (IMUs) and other dedicated sensors of the smartphones(which are often available as default) such as- Accelerometer, Gyroscope, Magnetometer, Fingerprint reader, Proximity and Ambient light sensors have made devices smarter and the interaction seamless. Gesture recognition using these smart phones have been experimented with many techniques. In this solution, a Recurrent Neural Network (RNN) approach, LSTM (Long-Short Term Memory Cells) has been used to classify ten different gestures based on data from Accelerometer and Gyroscope. Selection of sensor data (Accelerometer and Gyroscope) was based on the ones that provided maximum information regarding the movement and orientation of the phone. Various models were experimented in this project, the results of which are presented in the later sections. Furthermore, the properties and characteristics of the collected data were studied and a set of improvements have been suggested in the future work section.
Towards Semantically Enriched Embeddings for Knowledge Graph Completion
Aug 02, 2023
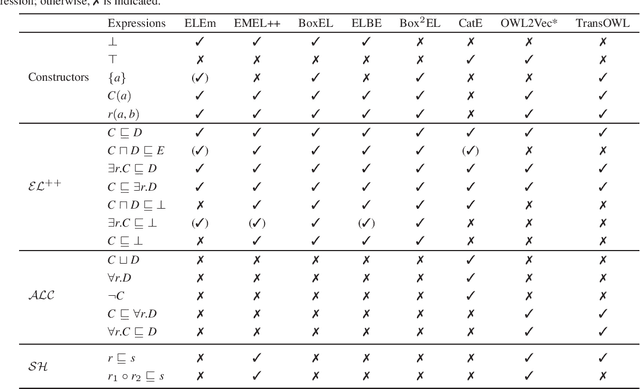
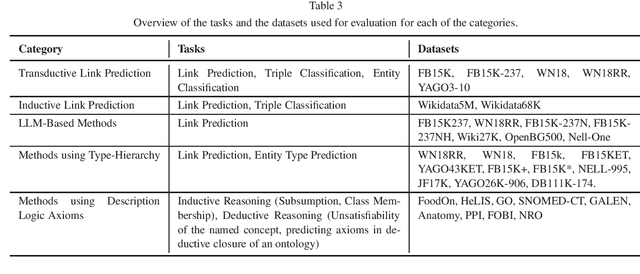
Embedding based Knowledge Graph (KG) Completion has gained much attention over the past few years. Most of the current algorithms consider a KG as a multidirectional labeled graph and lack the ability to capture the semantics underlying the schematic information. In a separate development, a vast amount of information has been captured within the Large Language Models (LLMs) which has revolutionized the field of Artificial Intelligence. KGs could benefit from these LLMs and vice versa. This vision paper discusses the existing algorithms for KG completion based on the variations for generating KG embeddings. It starts with discussing various KG completion algorithms such as transductive and inductive link prediction and entity type prediction algorithms. It then moves on to the algorithms utilizing type information within the KGs, LLMs, and finally to algorithms capturing the semantics represented in different description logic axioms. We conclude the paper with a critical reflection on the current state of work in the community and give recommendations for future directions.
BioBERT Based SNP-traits Associations Extraction from Biomedical Literature
Aug 03, 2023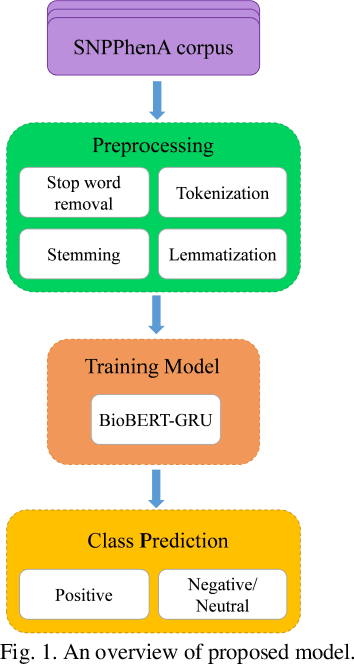
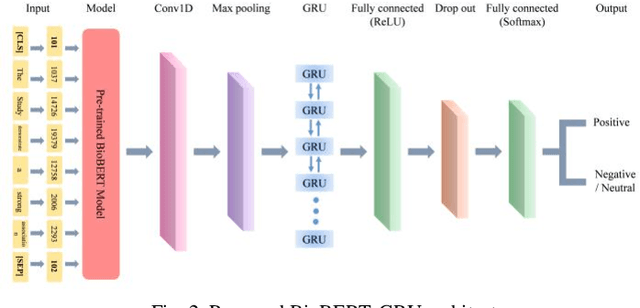
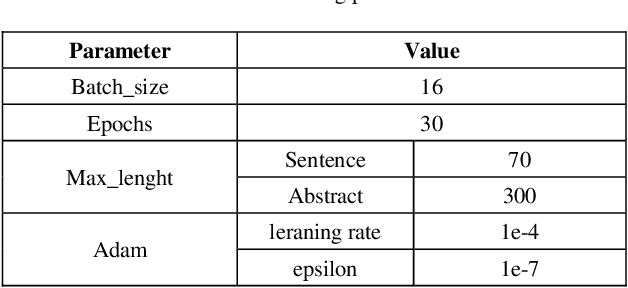
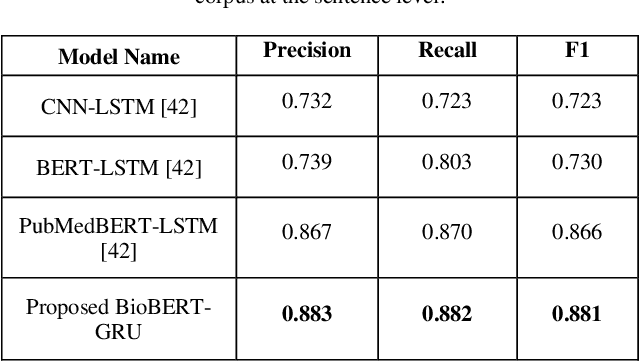
Scientific literature contains a considerable amount of information that provides an excellent opportunity for developing text mining methods to extract biomedical relationships. An important type of information is the relationship between singular nucleotide polymorphisms (SNP) and traits. In this paper, we present a BioBERT-GRU method to identify SNP- traits associations. Based on the evaluation of our method on the SNPPhenA dataset, it is concluded that this new method performs better than previous machine learning and deep learning based methods. BioBERT-GRU achieved the result a precision of 0.883, recall of 0.882 and F1-score of 0.881.
Extracting detailed oncologic history and treatment plan from medical oncology notes with large language models
Aug 07, 2023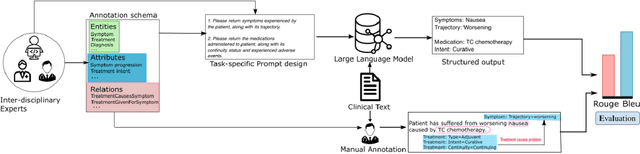
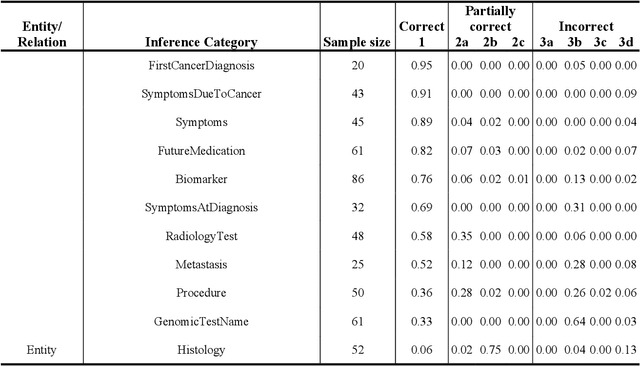
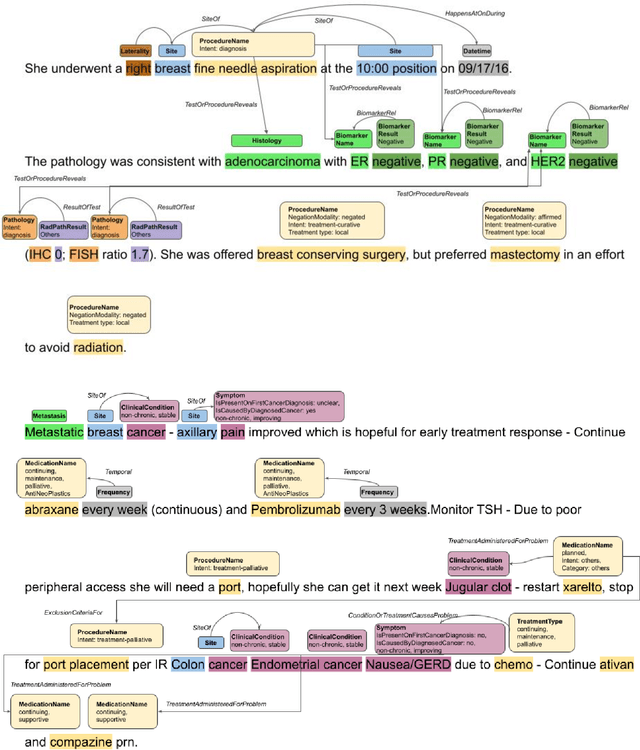
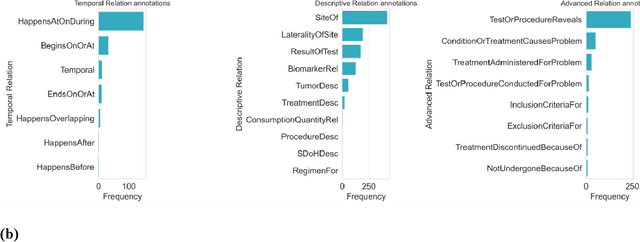
Both medical care and observational studies in oncology require a thorough understanding of a patient's disease progression and treatment history, often elaborately documented in clinical notes. Despite their vital role, no current oncology information representation and annotation schema fully encapsulates the diversity of information recorded within these notes. Although large language models (LLMs) have recently exhibited impressive performance on various medical natural language processing tasks, due to the current lack of comprehensively annotated oncology datasets, an extensive evaluation of LLMs in extracting and reasoning with the complex rhetoric in oncology notes remains understudied. We developed a detailed schema for annotating textual oncology information, encompassing patient characteristics, tumor characteristics, tests, treatments, and temporality. Using a corpus of 10 de-identified breast cancer progress notes at University of California, San Francisco, we applied this schema to assess the abilities of three recently-released LLMs (GPT-4, GPT-3.5-turbo, and FLAN-UL2) to perform zero-shot extraction of detailed oncological history from two narrative sections of clinical progress notes. Our team annotated 2750 entities, 2874 modifiers, and 1623 relationships. The GPT-4 model exhibited overall best performance, with an average BLEU score of 0.69, an average ROUGE score of 0.72, and an average accuracy of 67% on complex tasks (expert manual evaluation). Notably, it was proficient in tumor characteristic and medication extraction, and demonstrated superior performance in inferring symptoms due to cancer and considerations of future medications. The analysis demonstrates that GPT-4 is potentially already usable to extract important facts from cancer progress notes needed for clinical research, complex population management, and documenting quality patient care.
CFN-ESA: A Cross-Modal Fusion Network with Emotion-Shift Awareness for Dialogue Emotion Recognition
Jul 28, 2023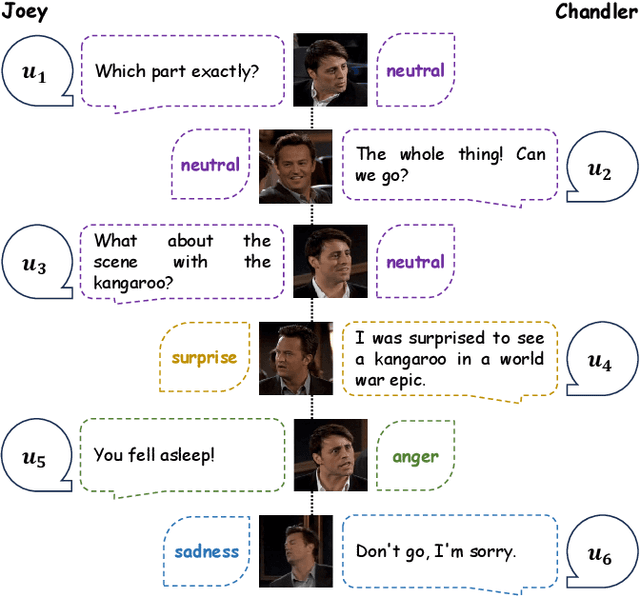
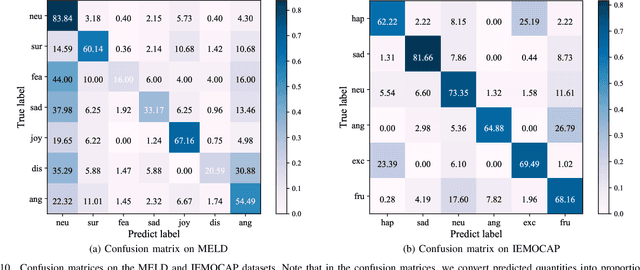
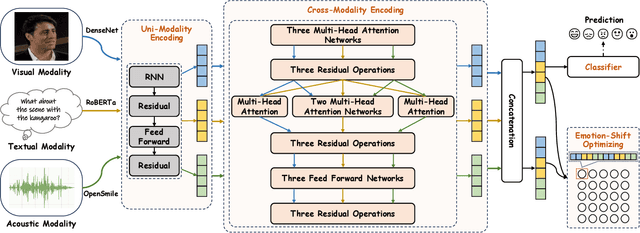
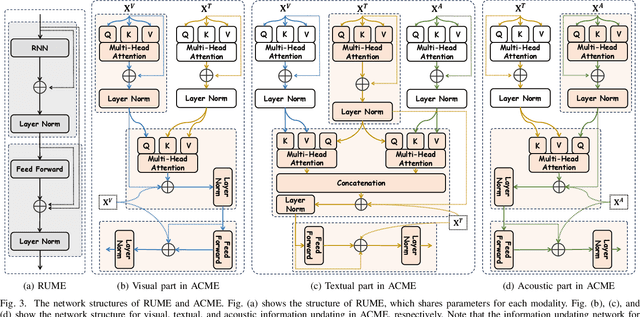
Multimodal Emotion Recognition in Conversation (ERC) has garnered growing attention from research communities in various fields. In this paper, we propose a cross-modal fusion network with emotion-shift awareness (CFN-ESA) for ERC. Extant approaches employ each modality equally without distinguishing the amount of emotional information, rendering it hard to adequately extract complementary and associative information from multimodal data. To cope with this problem, in CFN-ESA, textual modalities are treated as the primary source of emotional information, while visual and acoustic modalities are taken as the secondary sources. Besides, most multimodal ERC models ignore emotion-shift information and overfocus on contextual information, leading to the failure of emotion recognition under emotion-shift scenario. We elaborate an emotion-shift module to address this challenge. CFN-ESA mainly consists of the unimodal encoder (RUME), cross-modal encoder (ACME), and emotion-shift module (LESM). RUME is applied to extract conversation-level contextual emotional cues while pulling together the data distributions between modalities; ACME is utilized to perform multimodal interaction centered on textual modality; LESM is used to model emotion shift and capture related information, thereby guide the learning of the main task. Experimental results demonstrate that CFN-ESA can effectively promote performance for ERC and remarkably outperform the state-of-the-art models.
SMAP: A Novel Heterogeneous Information Framework for Scenario-based Optimal Model Assignment
May 23, 2023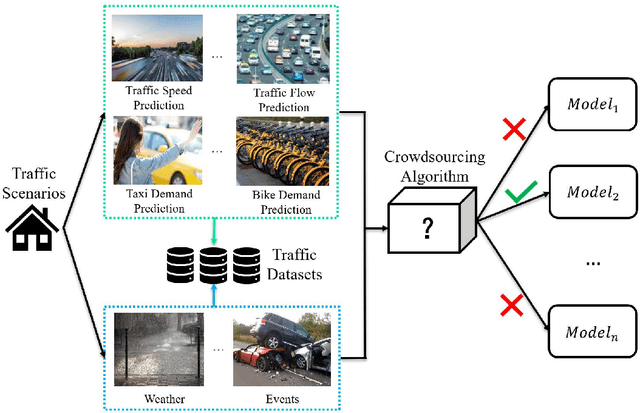
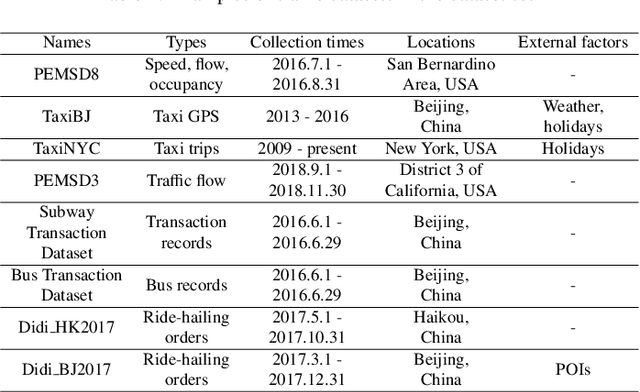
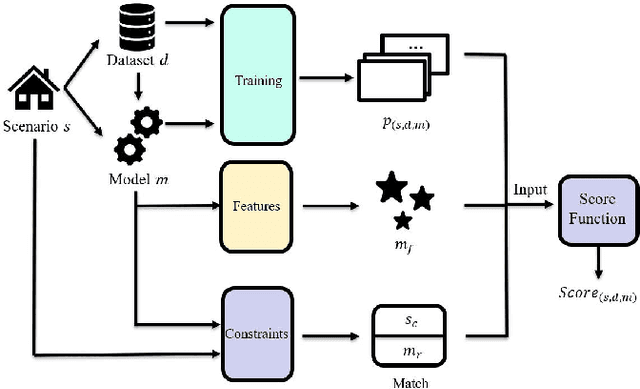
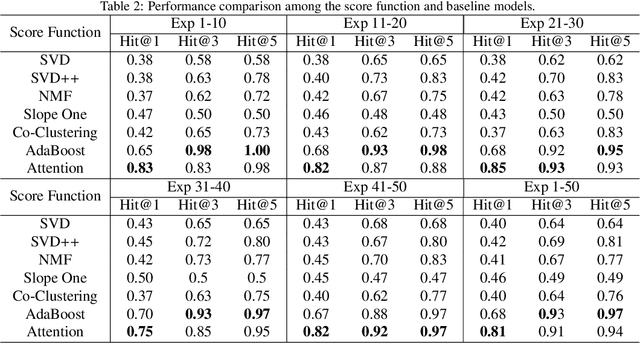
The increasing maturity of big data applications has led to a proliferation of models targeting the same objectives within the same scenarios and datasets. However, selecting the most suitable model that considers model's features while taking specific requirements and constraints into account still poses a significant challenge. Existing methods have focused on worker-task assignments based on crowdsourcing, they neglect the scenario-dataset-model assignment problem. To address this challenge, a new problem named the Scenario-based Optimal Model Assignment (SOMA) problem is introduced and a novel framework entitled Scenario and Model Associative percepts (SMAP) is developed. SMAP is a heterogeneous information framework that can integrate various types of information to intelligently select a suitable dataset and allocate the optimal model for a specific scenario. To comprehensively evaluate models, a new score function that utilizes multi-head attention mechanisms is proposed. Moreover, a novel memory mechanism named the mnemonic center is developed to store the matched heterogeneous information and prevent duplicate matching. Six popular traffic scenarios are selected as study cases and extensive experiments are conducted on a dataset to verify the effectiveness and efficiency of SMAP and the score function.