 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Audio-Visual Spatial Integration and Recursive Attention for Robust Sound Source Localization
Aug 18, 2023
The objective of the sound source localization task is to enable machines to detect the location of sound-making objects within a visual scene. While the audio modality provides spatial cues to locate the sound source, existing approaches only use audio as an auxiliary role to compare spatial regions of the visual modality. Humans, on the other hand, utilize both audio and visual modalities as spatial cues to locate sound sources. In this paper, we propose an audio-visual spatial integration network that integrates spatial cues from both modalities to mimic human behavior when detecting sound-making objects. Additionally, we introduce a recursive attention network to mimic human behavior of iterative focusing on objects, resulting in more accurate attention regions. To effectively encode spatial information from both modalities, we propose audio-visual pair matching loss and spatial region alignment loss. By utilizing the spatial cues of audio-visual modalities and recursively focusing objects, our method can perform more robust sound source localization. Comprehensive experimental results on the Flickr SoundNet and VGG-Sound Source datasets demonstrate the superiority of our proposed method over existing approaches. Our code is available at: https://github.com/VisualAIKHU/SIRA-SSL
Masked Spatio-Temporal Structure Prediction for Self-supervised Learning on Point Cloud Videos
Aug 18, 2023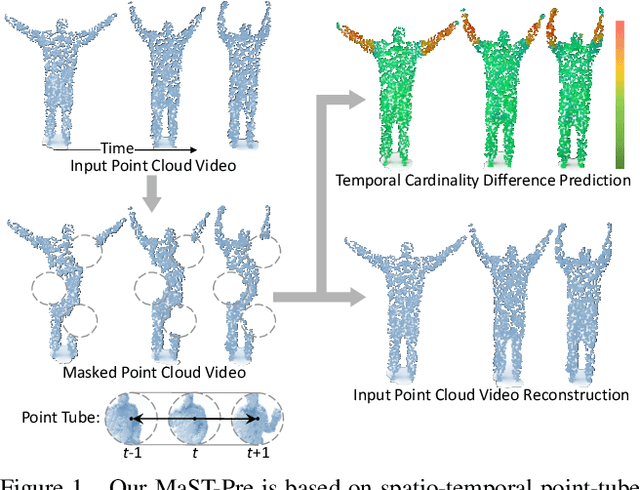
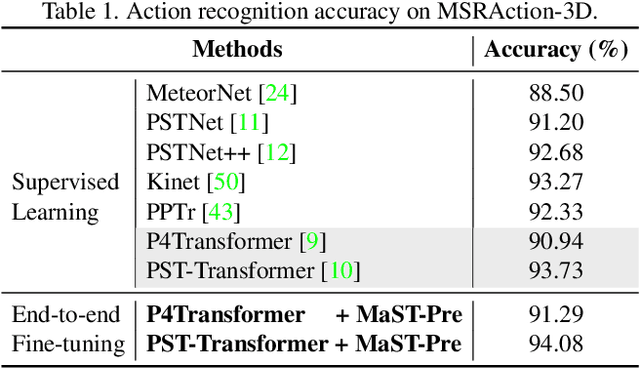
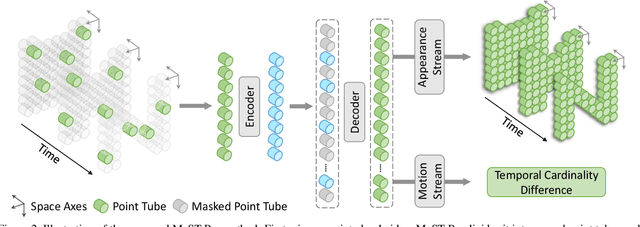

Recently, the community has made tremendous progress in developing effective methods for point cloud video understanding that learn from massive amounts of labeled data. However, annotating point cloud videos is usually notoriously expensive. Moreover, training via one or only a few traditional tasks (e.g., classification) may be insufficient to learn subtle details of the spatio-temporal structure existing in point cloud videos. In this paper, we propose a Masked Spatio-Temporal Structure Prediction (MaST-Pre) method to capture the structure of point cloud videos without human annotations. MaST-Pre is based on spatio-temporal point-tube masking and consists of two self-supervised learning tasks. First, by reconstructing masked point tubes, our method is able to capture the appearance information of point cloud videos. Second, to learn motion, we propose a temporal cardinality difference prediction task that estimates the change in the number of points within a point tube. In this way, MaST-Pre is forced to model the spatial and temporal structure in point cloud videos. Extensive experiments on MSRAction-3D, NTU-RGBD, NvGesture, and SHREC'17 demonstrate the effectiveness of the proposed method.
Label-Free Event-based Object Recognition via Joint Learning with Image Reconstruction from Events
Aug 18, 2023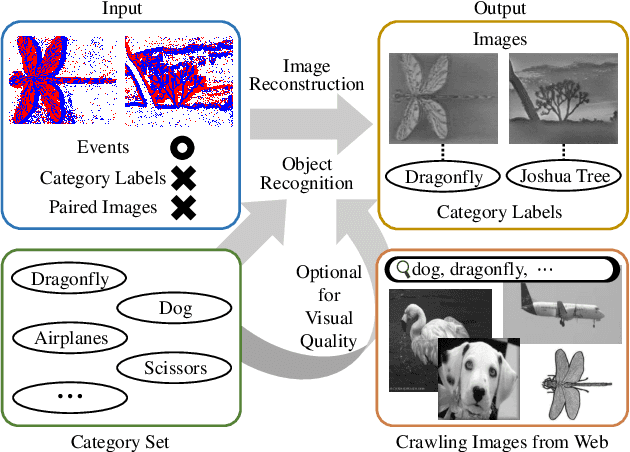
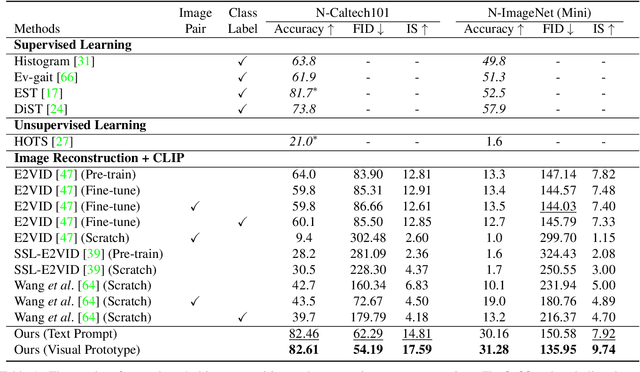
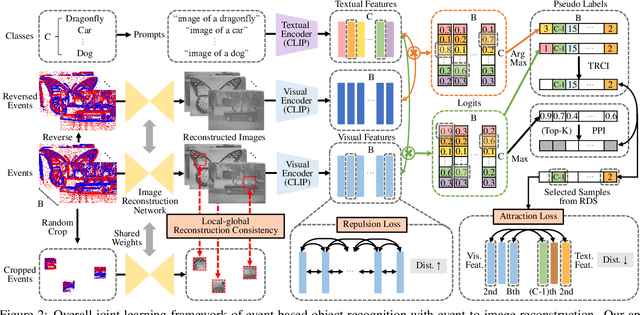
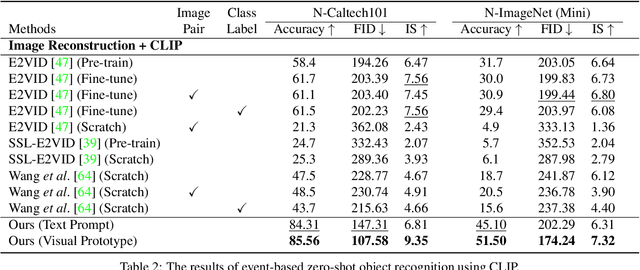
Recognizing objects from sparse and noisy events becomes extremely difficult when paired images and category labels do not exist. In this paper, we study label-free event-based object recognition where category labels and paired images are not available. To this end, we propose a joint formulation of object recognition and image reconstruction in a complementary manner. Our method first reconstructs images from events and performs object recognition through Contrastive Language-Image Pre-training (CLIP), enabling better recognition through a rich context of images. Since the category information is essential in reconstructing images, we propose category-guided attraction loss and category-agnostic repulsion loss to bridge the textual features of predicted categories and the visual features of reconstructed images using CLIP. Moreover, we introduce a reliable data sampling strategy and local-global reconstruction consistency to boost joint learning of two tasks. To enhance the accuracy of prediction and quality of reconstruction, we also propose a prototype-based approach using unpaired images. Extensive experiments demonstrate the superiority of our method and its extensibility for zero-shot object recognition. Our project code is available at \url{https://github.com/Chohoonhee/Ev-LaFOR}.
Human Part-wise 3D Motion Context Learning for Sign Language Recognition
Aug 18, 2023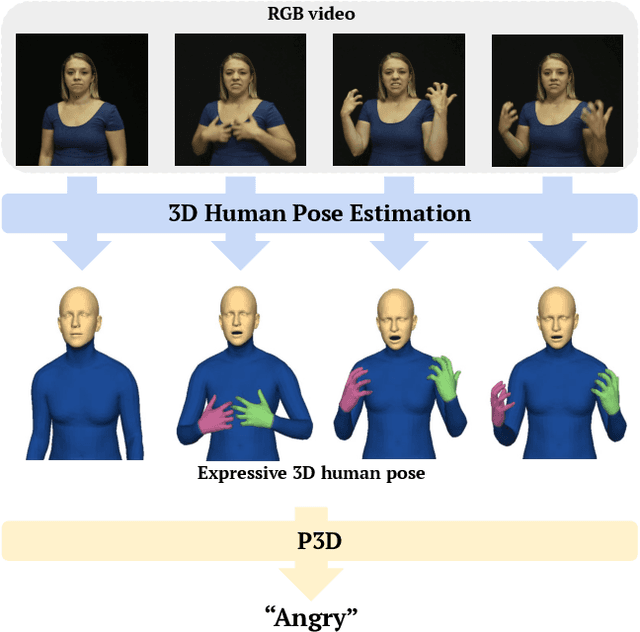
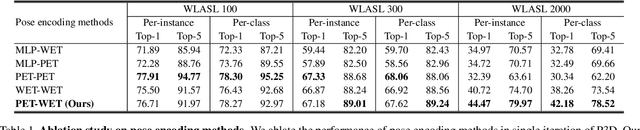
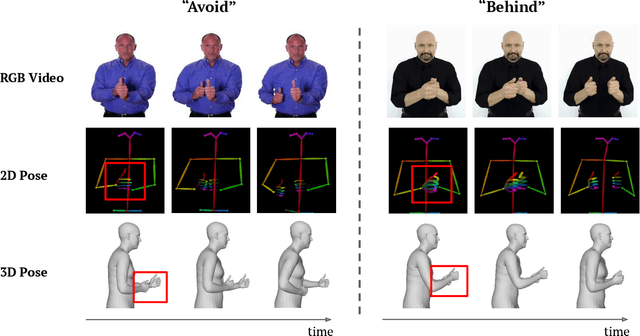
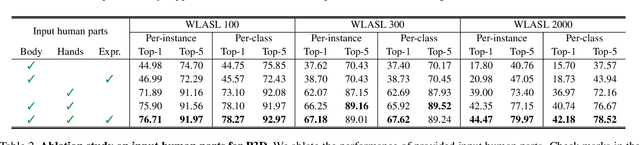
In this paper, we propose P3D, the human part-wise motion context learning framework for sign language recognition. Our main contributions lie in two dimensions: learning the part-wise motion context and employing the pose ensemble to utilize 2D and 3D pose jointly. First, our empirical observation implies that part-wise context encoding benefits the performance of sign language recognition. While previous methods of sign language recognition learned motion context from the sequence of the entire pose, we argue that such methods cannot exploit part-specific motion context. In order to utilize part-wise motion context, we propose the alternating combination of a part-wise encoding Transformer (PET) and a whole-body encoding Transformer (WET). PET encodes the motion contexts from a part sequence, while WET merges them into a unified context. By learning part-wise motion context, our P3D achieves superior performance on WLASL compared to previous state-of-the-art methods. Second, our framework is the first to ensemble 2D and 3D poses for sign language recognition. Since the 3D pose holds rich motion context and depth information to distinguish the words, our P3D outperformed the previous state-of-the-art methods employing a pose ensemble.
Single Frame Semantic Segmentation Using Multi-Modal Spherical Images
Aug 18, 2023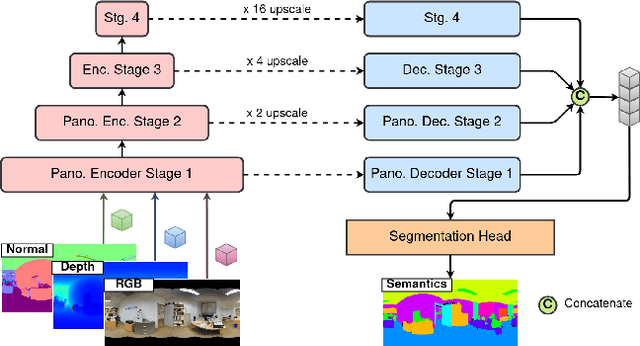
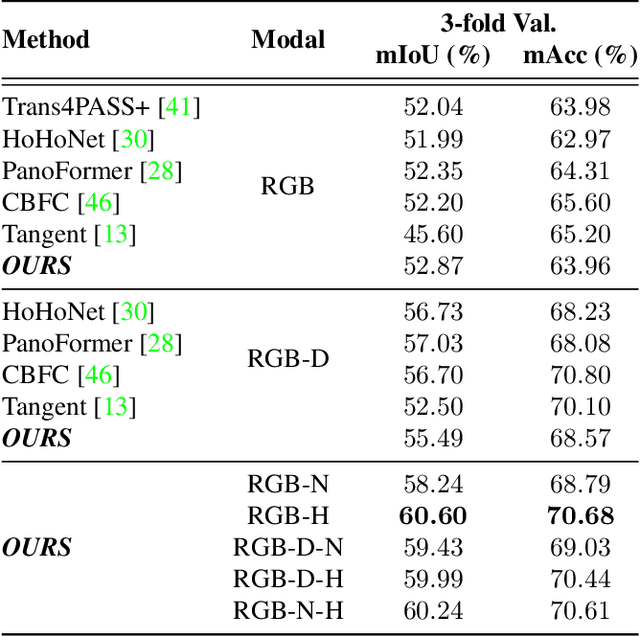
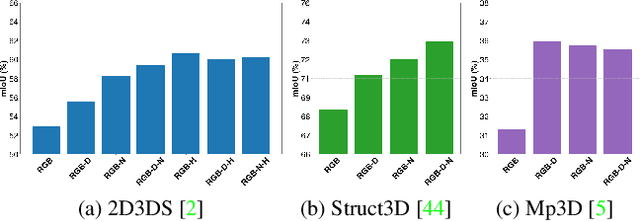
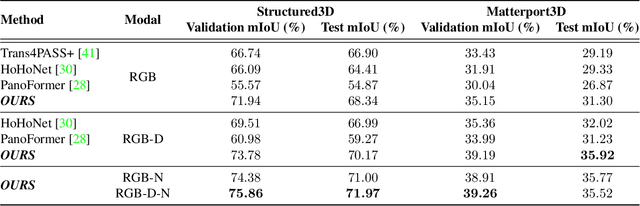
In recent years, the research community has shown a lot of interest to panoramic images that offer a 360-degree directional perspective. Multiple data modalities can be fed, and complimentary characteristics can be utilized for more robust and rich scene interpretation based on semantic segmentation, to fully realize the potential. Existing research, however, mostly concentrated on pinhole RGB-X semantic segmentation. In this study, we propose a transformer-based cross-modal fusion architecture to bridge the gap between multi-modal fusion and omnidirectional scene perception. We employ distortion-aware modules to address extreme object deformations and panorama distortions that result from equirectangular representation. Additionally, we conduct cross-modal interactions for feature rectification and information exchange before merging the features in order to communicate long-range contexts for bi-modal and tri-modal feature streams. In thorough tests using combinations of four different modality types in three indoor panoramic-view datasets, our technique achieved state-of-the-art mIoU performance: 60.60% on Stanford2D3DS (RGB-HHA), 71.97% Structured3D (RGB-D-N), and 35.92% Matterport3D (RGB-D). We plan to release all codes and trained models soon.
Dual input neural networks for positional sound source localization
Aug 08, 2023In many signal processing applications, metadata may be advantageously used in conjunction with a high dimensional signal to produce a desired output. In the case of classical Sound Source Localization (SSL) algorithms, information from a high dimensional, multichannel audio signals received by many distributed microphones is combined with information describing acoustic properties of the scene, such as the microphones' coordinates in space, to estimate the position of a sound source. We introduce Dual Input Neural Networks (DI-NNs) as a simple and effective way to model these two data types in a neural network. We train and evaluate our proposed DI-NN on scenarios of varying difficulty and realism and compare it against an alternative architecture, a classical Least-Squares (LS) method as well as a classical Convolutional Recurrent Neural Network (CRNN). Our results show that the DI-NN significantly outperforms the baselines, achieving a five times lower localization error than the LS method and two times lower than the CRNN in a test dataset of real recordings.
LEFormer: A Hybrid CNN-Transformer Architecture for Accurate Lake Extraction from Remote Sensing Imagery
Aug 08, 2023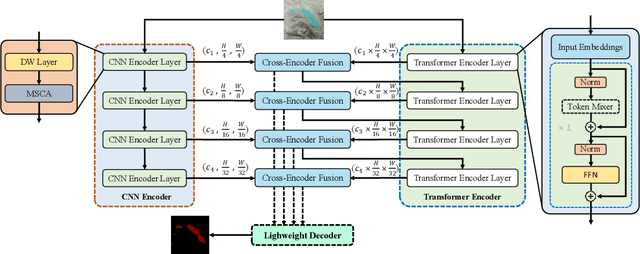

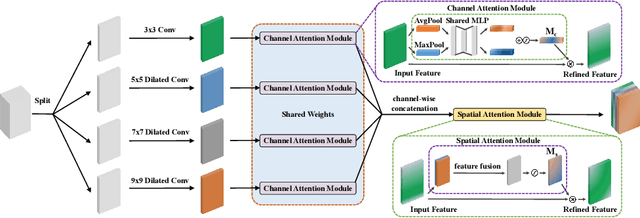
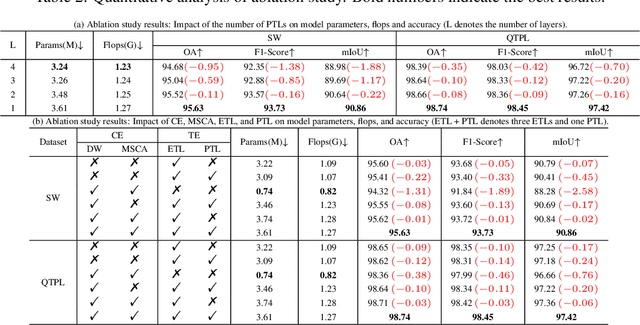
Lake extraction from remote sensing imagery is challenging due to the complex shapes of lakes and the presence of noise. Existing methods suffer from blurred segmentation boundaries and poor foreground modeling. In this paper, we propose a hybrid CNN-Transformer architecture, called LEFormer, for accurate lake extraction. LEFormer contains four main modules: CNN encoder, Transformer encoder, cross-encoder fusion, and lightweight decoder. The CNN encoder recovers local spatial information and improves fine-scale details. Simultaneously, the Transformer encoder captures long-range dependencies between sequences of any length, allowing them to obtain global features and context information better. Finally, a lightweight decoder is employed for mask prediction. We evaluate the performance and efficiency of LEFormer on two datasets, the Surface Water (SW) and the Qinghai-Tibet Plateau Lake (QTPL). Experimental results show that LEFormer consistently achieves state-of-the-art (SOTA) performance and efficiency on these two datasets, outperforming existing methods. Specifically, LEFormer achieves 90.86% and 97.42% mIoU on the SW and QTPL datasets with a parameter count of 3.61M, respectively, while being 20x minor than the previous SOTA method.
CMUNeXt: An Efficient Medical Image Segmentation Network based on Large Kernel and Skip Fusion
Aug 02, 2023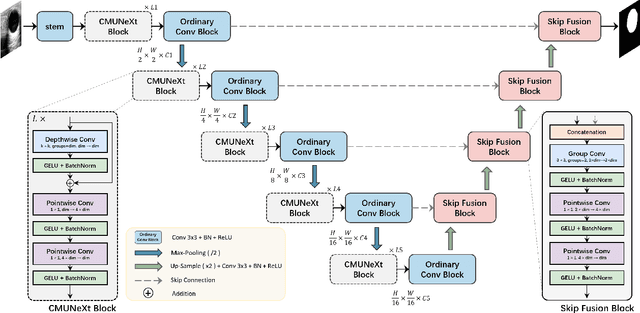
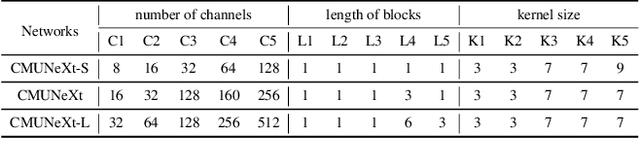
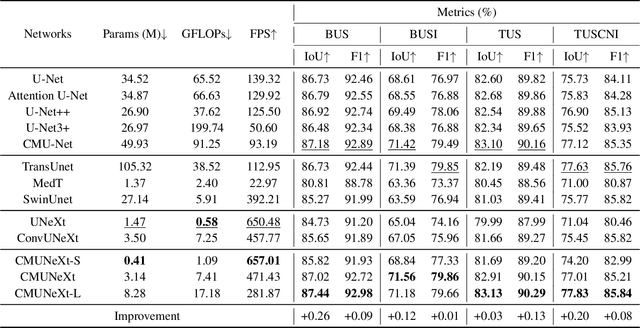
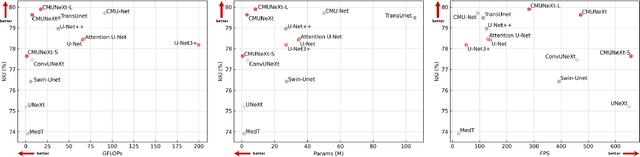
The U-shaped architecture has emerged as a crucial paradigm in the design of medical image segmentation networks. However, due to the inherent local limitations of convolution, a fully convolutional segmentation network with U-shaped architecture struggles to effectively extract global context information, which is vital for the precise localization of lesions. While hybrid architectures combining CNNs and Transformers can address these issues, their application in real medical scenarios is limited due to the computational resource constraints imposed by the environment and edge devices. In addition, the convolutional inductive bias in lightweight networks adeptly fits the scarce medical data, which is lacking in the Transformer based network. In order to extract global context information while taking advantage of the inductive bias, we propose CMUNeXt, an efficient fully convolutional lightweight medical image segmentation network, which enables fast and accurate auxiliary diagnosis in real scene scenarios. CMUNeXt leverages large kernel and inverted bottleneck design to thoroughly mix distant spatial and location information, efficiently extracting global context information. We also introduce the Skip-Fusion block, designed to enable smooth skip-connections and ensure ample feature fusion. Experimental results on multiple medical image datasets demonstrate that CMUNeXt outperforms existing heavyweight and lightweight medical image segmentation networks in terms of segmentation performance, while offering a faster inference speed, lighter weights, and a reduced computational cost. The code is available at https://github.com/FengheTan9/CMUNeXt.
Majorizing Measures, Codes, and Information
May 04, 2023The majorizing measure theorem of Fernique and Talagrand is a fundamental result in the theory of random processes. It relates the boundedness of random processes indexed by elements of a metric space to complexity measures arising from certain multiscale combinatorial structures, such as packing and covering trees. This paper builds on the ideas first outlined in a little-noticed preprint of Andreas Maurer to present an information-theoretic perspective on the majorizing measure theorem, according to which the boundedness of random processes is phrased in terms of the existence of efficient variable-length codes for the elements of the indexing metric space.
MIMO Radar Transmit Signal Optimization for Target Localization Exploiting Prior Information
May 15, 2023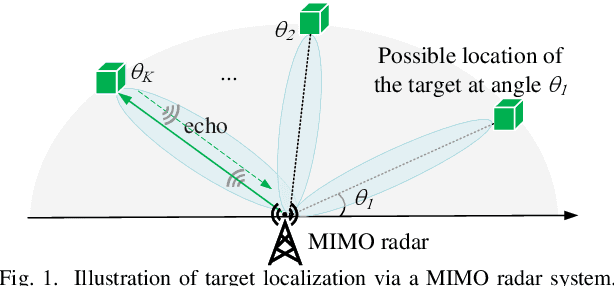
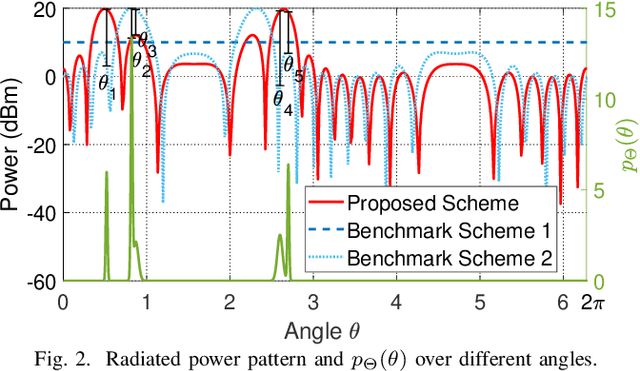
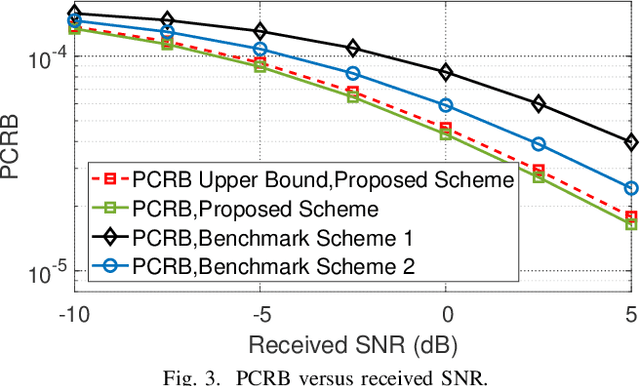
In this paper, we consider a multiple-input multiple-output (MIMO) radar system for localizing a target based on its reflected echo signals. Specifically, we aim to estimate the random and unknown angle information of the target, by exploiting its prior distribution information. First, we characterize the estimation performance by deriving the posterior Cram\'er-Rao bound (PCRB), which quantifies a lower bound of the estimation mean-squared error (MSE). Since the PCRB is in a complicated form, we derive a tight upper bound of it to approximate the estimation performance. Based on this, we analytically show that by exploiting the prior distribution information, the PCRB is always no larger than the Cram\'er-Rao bound (CRB) averaged over random angle realizations without prior information exploitation. Next, we formulate the transmit signal optimization problem to minimize the PCRB upper bound. We show that the optimal sample covariance matrix has a rank-one structure, and derive the optimal signal solution in closed form. Numerical results show that our proposed design achieves significantly improved PCRB performance compared to various benchmark schemes.