 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Tracing the Influence of Predecessors on Trajectory Prediction
Aug 10, 2023
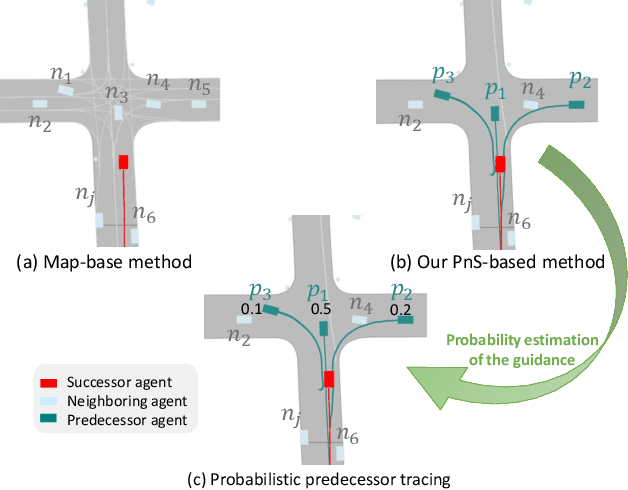
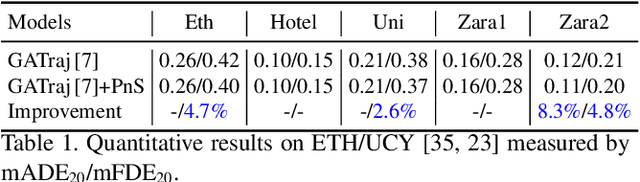
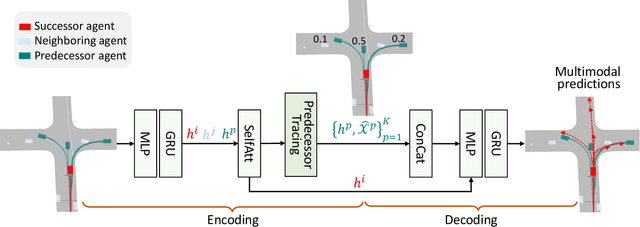
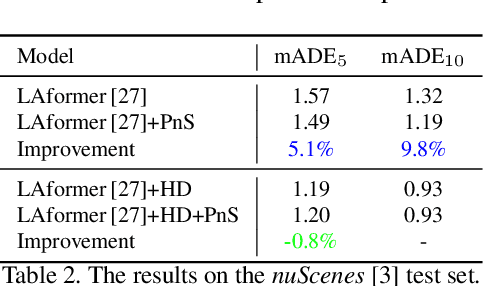
In real-world traffic scenarios, agents such as pedestrians and car drivers often observe neighboring agents who exhibit similar behavior as examples and then mimic their actions to some extent in their own behavior. This information can serve as prior knowledge for trajectory prediction, which is unfortunately largely overlooked in current trajectory prediction models. This paper introduces a novel Predecessor-and-Successor (PnS) method that incorporates a predecessor tracing module to model the influence of predecessors (identified from concurrent neighboring agents) on the successor (target agent) within the same scene. The method utilizes the moving patterns of these predecessors to guide the predictor in trajectory prediction. PnS effectively aligns the motion encodings of the successor with multiple potential predecessors in a probabilistic manner, facilitating the decoding process. We demonstrate the effectiveness of PnS by integrating it into a graph-based predictor for pedestrian trajectory prediction on the ETH/UCY datasets, resulting in a new state-of-the-art performance. Furthermore, we replace the HD map-based scene-context module with our PnS method in a transformer-based predictor for vehicle trajectory prediction on the nuScenes dataset, showing that the predictor maintains good prediction performance even without relying on any map information.
Question-Answering System Extracts Information on Injection Drug Use from Clinical Progress Notes
May 15, 2023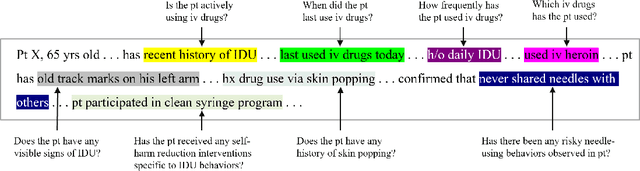
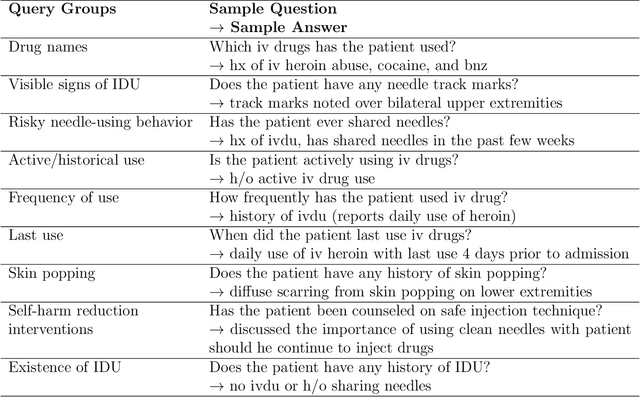
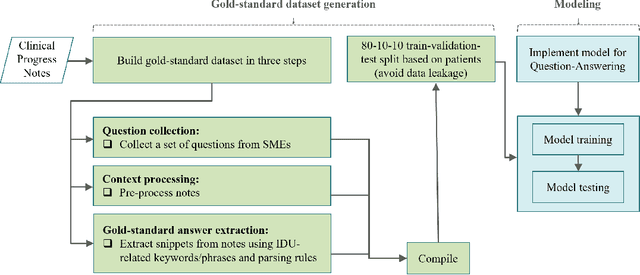
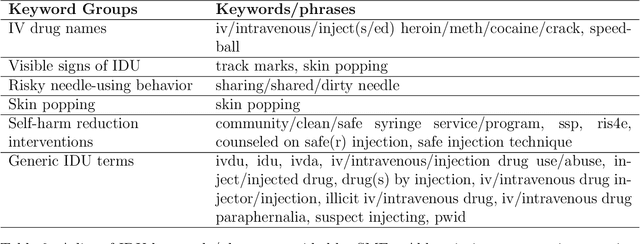
Injection drug use (IDU) is a dangerous health behavior that increases mortality and morbidity. Identifying IDU early and initiating harm reduction interventions can benefit individuals at risk. However, extracting IDU behaviors from patients' electronic health records (EHR) is difficult because there is no International Classification of Disease (ICD) code and the only place IDU information can be indicated are unstructured free-text clinical progress notes. Although natural language processing (NLP) can efficiently extract this information from unstructured data, there are no validated tools. To address this gap in clinical information, we design and demonstrate a question-answering (QA) framework to extract information on IDU from clinical progress notes. Unlike other methods discussed in the literature, the QA model is able to extract various types of information without being constrained by predefined entities, relations, or concepts. Our framework involves two main steps: (1) generating a gold-standard QA dataset and (2) developing and testing the QA model. This paper also demonstrates the QA model's ability to extract IDU-related information on temporally out-of-distribution data. The results indicate that the majority (51%) of the extracted information by the QA model exactly matches the gold-standard answer and 73% of them contain the gold-standard answer with some additional surrounding words.
Rethinking Client Drift in Federated Learning: A Logit Perspective
Aug 20, 2023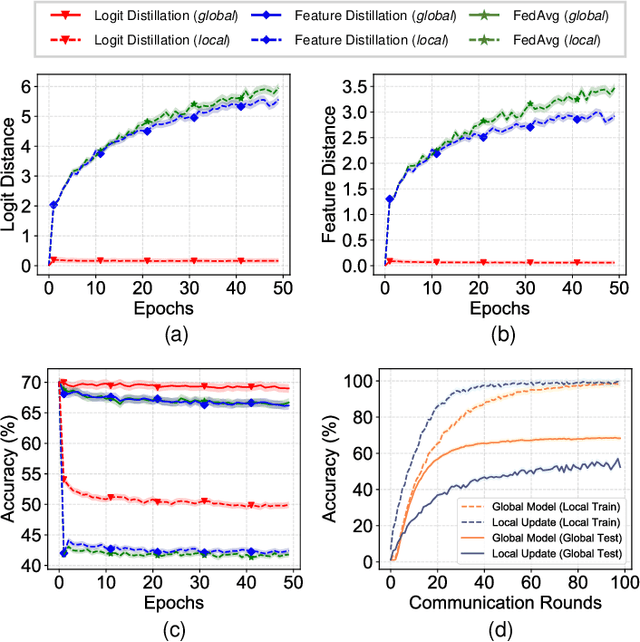
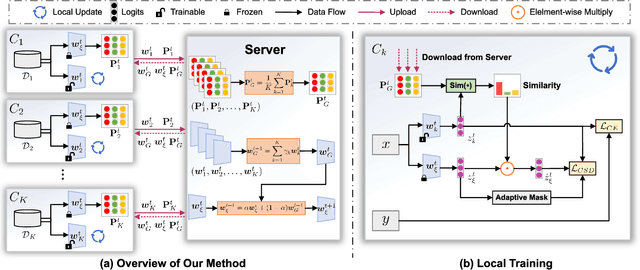
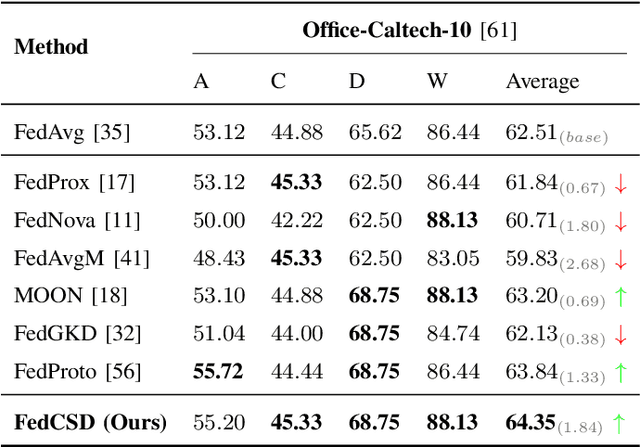
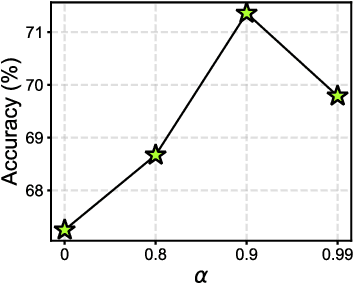
Federated Learning (FL) enables multiple clients to collaboratively learn in a distributed way, allowing for privacy protection. However, the real-world non-IID data will lead to client drift which degrades the performance of FL. Interestingly, we find that the difference in logits between the local and global models increases as the model is continuously updated, thus seriously deteriorating FL performance. This is mainly due to catastrophic forgetting caused by data heterogeneity between clients. To alleviate this problem, we propose a new algorithm, named FedCSD, a Class prototype Similarity Distillation in a federated framework to align the local and global models. FedCSD does not simply transfer global knowledge to local clients, as an undertrained global model cannot provide reliable knowledge, i.e., class similarity information, and its wrong soft labels will mislead the optimization of local models. Concretely, FedCSD introduces a class prototype similarity distillation to align the local logits with the refined global logits that are weighted by the similarity between local logits and the global prototype. To enhance the quality of global logits, FedCSD adopts an adaptive mask to filter out the terrible soft labels of the global models, thereby preventing them to mislead local optimization. Extensive experiments demonstrate the superiority of our method over the state-of-the-art federated learning approaches in various heterogeneous settings. The source code will be released.
When Are Two Lists Better than One?: Benefits and Harms in Joint Decision-making
Aug 22, 2023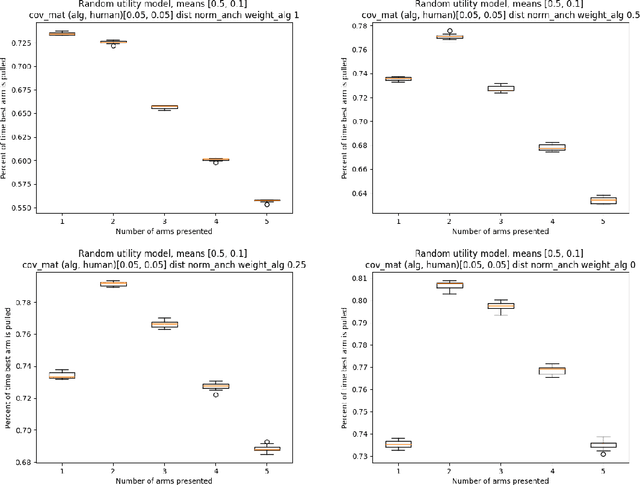
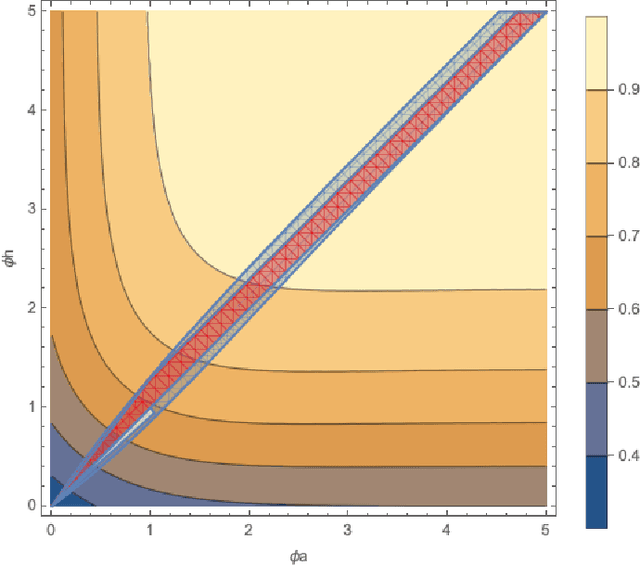
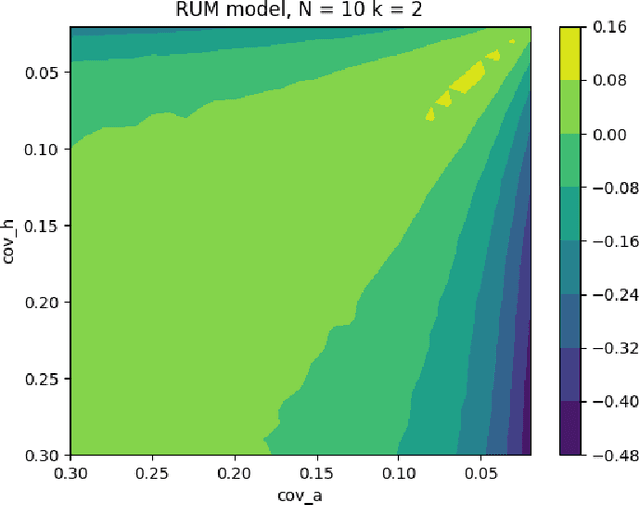
Historically, much of machine learning research has focused on the performance of the algorithm alone, but recently more attention has been focused on optimizing joint human-algorithm performance. Here, we analyze a specific type of human-algorithm collaboration where the algorithm has access to a set of $n$ items, and presents a subset of size $k$ to the human, who selects a final item from among those $k$. This scenario could model content recommendation, route planning, or any type of labeling task. Because both the human and algorithm have imperfect, noisy information about the true ordering of items, the key question is: which value of $k$ maximizes the probability that the best item will be ultimately selected? For $k=1$, performance is optimized by the algorithm acting alone, and for $k=n$ it is optimized by the human acting alone. Surprisingly, we show that for multiple of noise models, it is optimal to set $k \in [2, n-1]$ - that is, there are strict benefits to collaborating, even when the human and algorithm have equal accuracy separately. We demonstrate this theoretically for the Mallows model and experimentally for the Random Utilities models of noisy permutations. However, we show this pattern is reversed when the human is anchored on the algorithm's presented ordering - the joint system always has strictly worse performance. We extend these results to the case where the human and algorithm differ in their accuracy levels, showing that there always exist regimes where a more accurate agent would strictly benefit from collaborating with a less accurate one, but these regimes are asymmetric between the human and the algorithm's accuracy.
Methods for Acquiring and Incorporating Knowledge into Stock Price Prediction: A Survey
Aug 09, 2023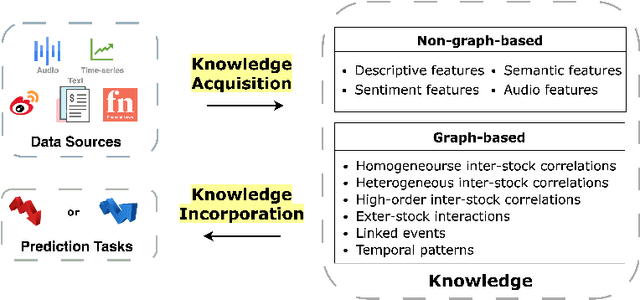
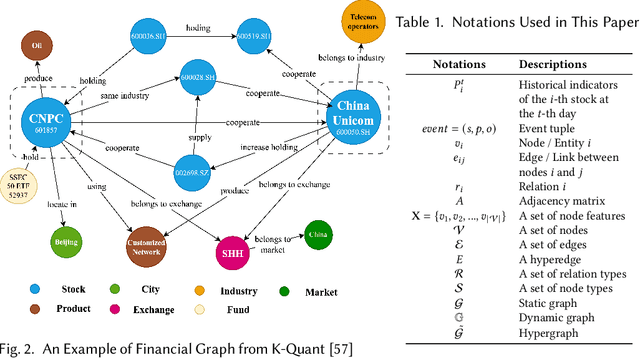
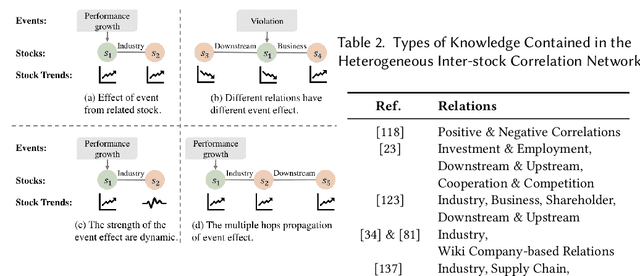
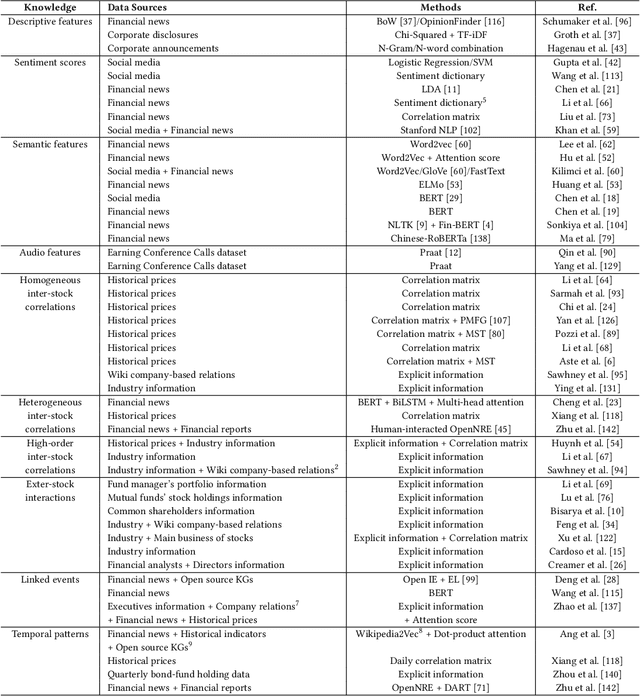
Predicting stock prices presents a challenging research problem due to the inherent volatility and non-linear nature of the stock market. In recent years, knowledge-enhanced stock price prediction methods have shown groundbreaking results by utilizing external knowledge to understand the stock market. Despite the importance of these methods, there is a scarcity of scholarly works that systematically synthesize previous studies from the perspective of external knowledge types. Specifically, the external knowledge can be modeled in different data structures, which we group into non-graph-based formats and graph-based formats: 1) non-graph-based knowledge captures contextual information and multimedia descriptions specifically associated with an individual stock; 2) graph-based knowledge captures interconnected and interdependent information in the stock market. This survey paper aims to provide a systematic and comprehensive description of methods for acquiring external knowledge from various unstructured data sources and then incorporating it into stock price prediction models. We also explore fusion methods for combining external knowledge with historical price features. Moreover, this paper includes a compilation of relevant datasets and delves into potential future research directions in this domain.
Differentially Private Graph Neural Network with Importance-Grained Noise Adaption
Aug 09, 2023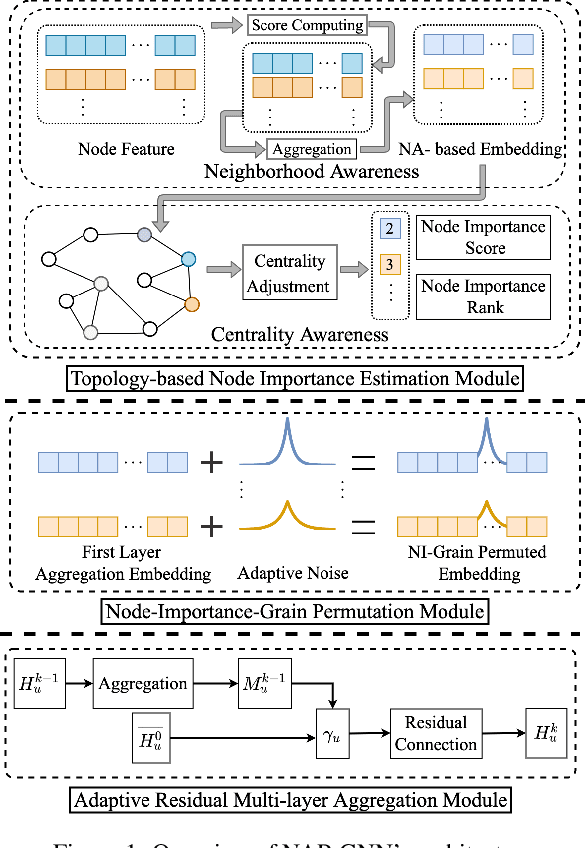
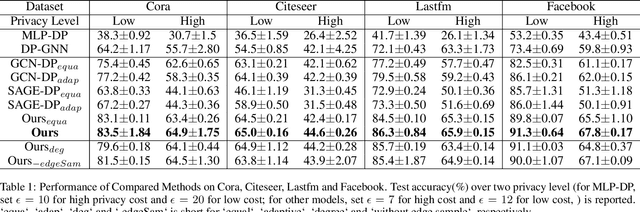
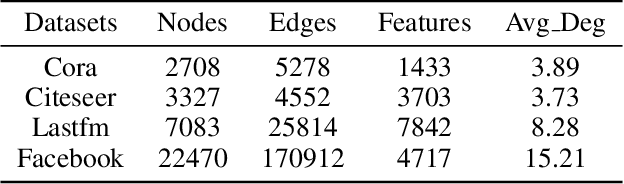
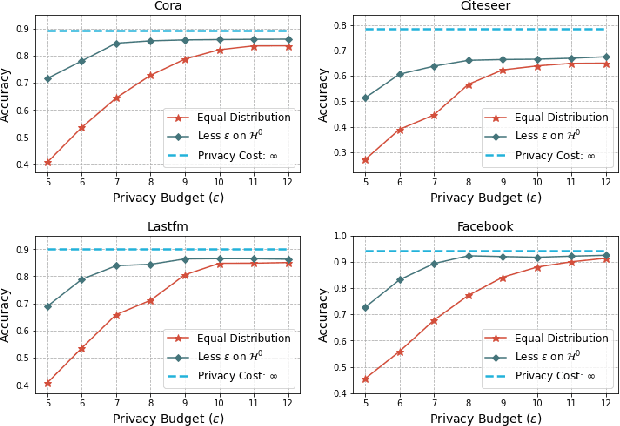
Graph Neural Networks (GNNs) with differential privacy have been proposed to preserve graph privacy when nodes represent personal and sensitive information. However, the existing methods ignore that nodes with different importance may yield diverse privacy demands, which may lead to over-protect some nodes and decrease model utility. In this paper, we study the problem of importance-grained privacy, where nodes contain personal data that need to be kept private but are critical for training a GNN. We propose NAP-GNN, a node-importance-grained privacy-preserving GNN algorithm with privacy guarantees based on adaptive differential privacy to safeguard node information. First, we propose a Topology-based Node Importance Estimation (TNIE) method to infer unknown node importance with neighborhood and centrality awareness. Second, an adaptive private aggregation method is proposed to perturb neighborhood aggregation from node-importance-grain. Third, we propose to privately train a graph learning algorithm on perturbed aggregations in adaptive residual connection mode over multi-layers convolution for node-wise tasks. Theoretically analysis shows that NAP-GNN satisfies privacy guarantees. Empirical experiments over real-world graph datasets show that NAP-GNN achieves a better trade-off between privacy and accuracy.
DiVa: An Iterative Framework to Harvest More Diverse and Valid Labels from User Comments for Music
Aug 09, 2023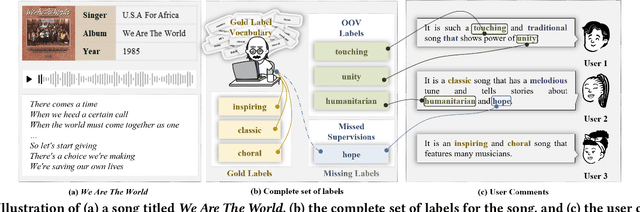

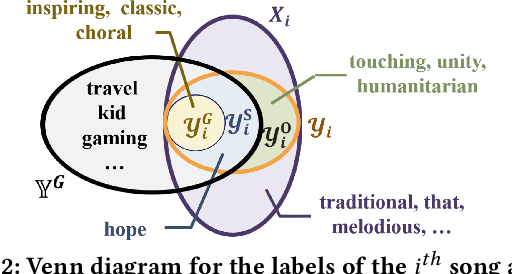
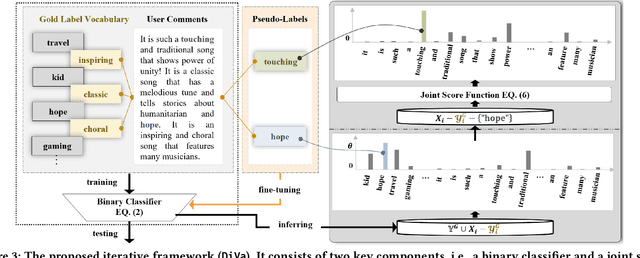
Towards sufficient music searching, it is vital to form a complete set of labels for each song. However, current solutions fail to resolve it as they cannot produce diverse enough mappings to make up for the information missed by the gold labels. Based on the observation that such missing information may already be presented in user comments, we propose to study the automated music labeling in an essential but under-explored setting, where the model is required to harvest more diverse and valid labels from the users' comments given limited gold labels. To this end, we design an iterative framework (DiVa) to harvest more $\underline{\text{Di}}$verse and $\underline{\text{Va}}$lid labels from user comments for music. The framework makes a classifier able to form complete sets of labels for songs via pseudo-labels inferred from pre-trained classifiers and a novel joint score function. The experiment on a densely annotated testing set reveals the superiority of the Diva over state-of-the-art solutions in producing more diverse labels missed by the gold labels. We hope our work can inspire future research on automated music labeling.
SSL-Auth: An Authentication Framework by Fragile Watermarking for Pre-trained Encoders in Self-supervised Learning
Aug 09, 2023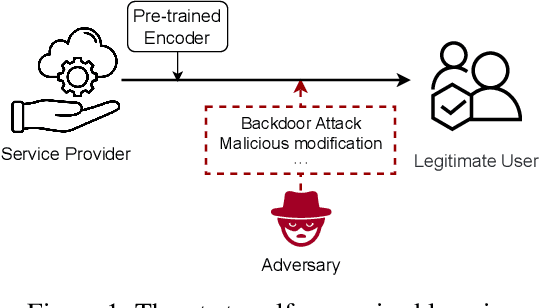
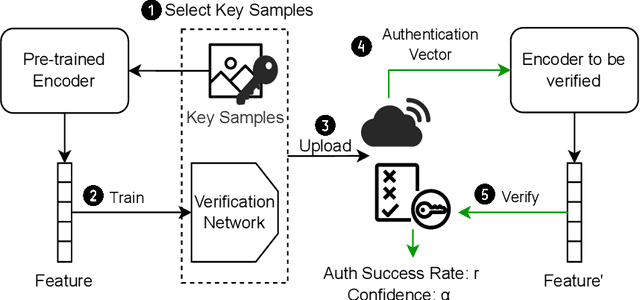
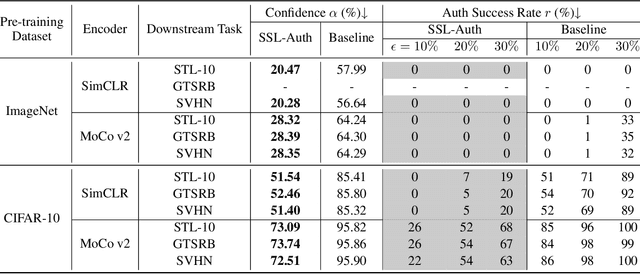
Self-supervised learning (SSL) which leverages unlabeled datasets for pre-training powerful encoders has achieved significant success in recent years. These encoders are commonly used as feature extractors for various downstream tasks, requiring substantial data and computing resources for their training process. With the deployment of pre-trained encoders in commercial use, protecting the intellectual property of model owners and ensuring the trustworthiness of the models becomes crucial. Recent research has shown that encoders are threatened by backdoor attacks, adversarial attacks, etc. Therefore, a scheme to verify the integrity of pre-trained encoders is needed to protect users. In this paper, we propose SSL-Auth, the first fragile watermarking scheme for verifying the integrity of encoders without compromising model performance. Our method utilizes selected key samples as watermark information and trains a verification network to reconstruct the watermark information, thereby verifying the integrity of the encoder. By comparing the reconstruction results of the key samples, malicious modifications can be effectively detected, as altered models should not exhibit similar reconstruction performance as the original models. Extensive evaluations on various models and diverse datasets demonstrate the effectiveness and fragility of our proposed SSL-Auth.
CMUNeXt: An Efficient Medical Image Segmentation Network based on Large Kernel and Skip Fusion
Aug 02, 2023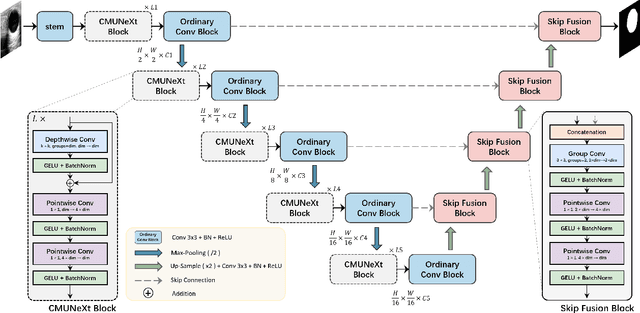
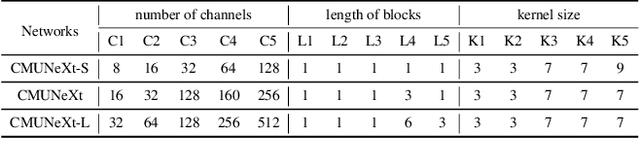
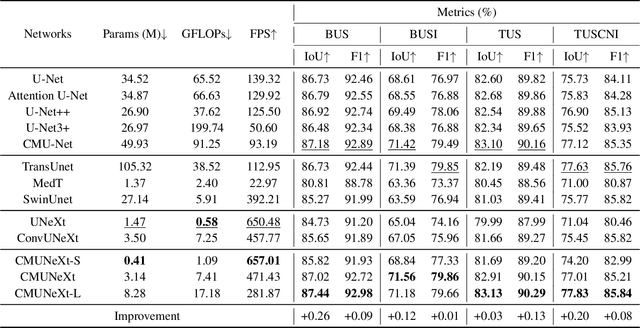
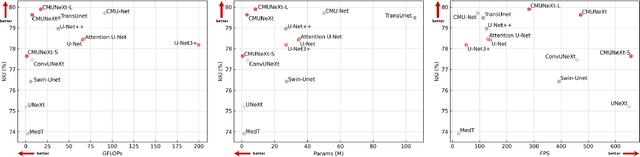
The U-shaped architecture has emerged as a crucial paradigm in the design of medical image segmentation networks. However, due to the inherent local limitations of convolution, a fully convolutional segmentation network with U-shaped architecture struggles to effectively extract global context information, which is vital for the precise localization of lesions. While hybrid architectures combining CNNs and Transformers can address these issues, their application in real medical scenarios is limited due to the computational resource constraints imposed by the environment and edge devices. In addition, the convolutional inductive bias in lightweight networks adeptly fits the scarce medical data, which is lacking in the Transformer based network. In order to extract global context information while taking advantage of the inductive bias, we propose CMUNeXt, an efficient fully convolutional lightweight medical image segmentation network, which enables fast and accurate auxiliary diagnosis in real scene scenarios. CMUNeXt leverages large kernel and inverted bottleneck design to thoroughly mix distant spatial and location information, efficiently extracting global context information. We also introduce the Skip-Fusion block, designed to enable smooth skip-connections and ensure ample feature fusion. Experimental results on multiple medical image datasets demonstrate that CMUNeXt outperforms existing heavyweight and lightweight medical image segmentation networks in terms of segmentation performance, while offering a faster inference speed, lighter weights, and a reduced computational cost. The code is available at https://github.com/FengheTan9/CMUNeXt.
A Geometric Notion of Causal Probing
Jul 30, 2023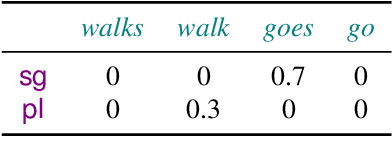
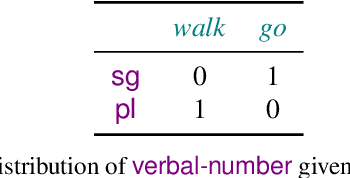
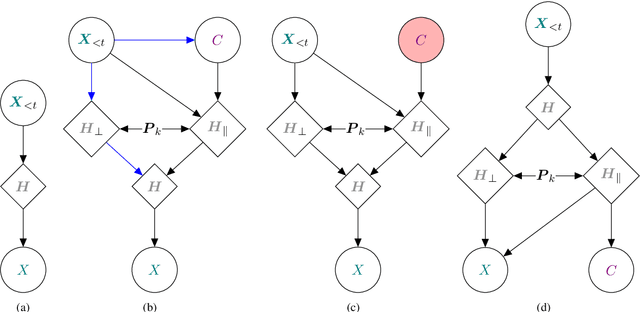
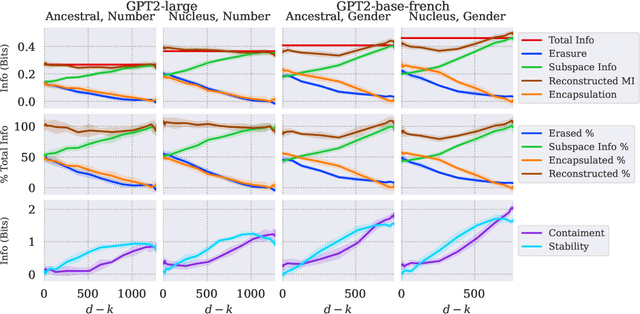
Large language models rely on real-valued representations of text to make their predictions. These representations contain information learned from the data that the model has trained on, including knowledge of linguistic properties and forms of demographic bias, e.g., based on gender. A growing body of work has considered removing information about concepts such as these using orthogonal projections onto subspaces of the representation space. We contribute to this body of work by proposing a formal definition of $\textit{intrinsic}$ information in a subspace of a language model's representation space. We propose a counterfactual approach that avoids the failure mode of spurious correlations (Kumar et al., 2022) by treating components in the subspace and its orthogonal complement independently. We show that our counterfactual notion of information in a subspace is optimized by a $\textit{causal}$ concept subspace. Furthermore, this intervention allows us to attempt concept controlled generation by manipulating the value of the conceptual component of a representation. Empirically, we find that R-LACE (Ravfogel et al., 2022) returns a one-dimensional subspace containing roughly half of total concept information under our framework. Our causal controlled intervention shows that, for at least one model, the subspace returned by R-LACE can be used to manipulate the concept value of the generated word with precision.