 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MUSE: Multi-View Contrastive Learning for Heterophilic Graphs
Jul 29, 2023
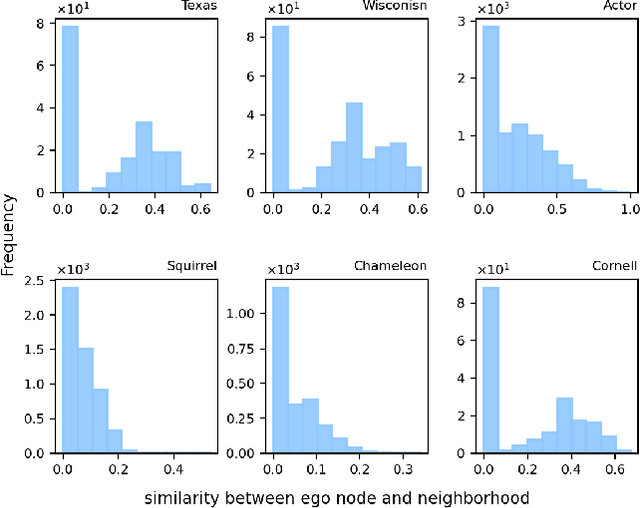
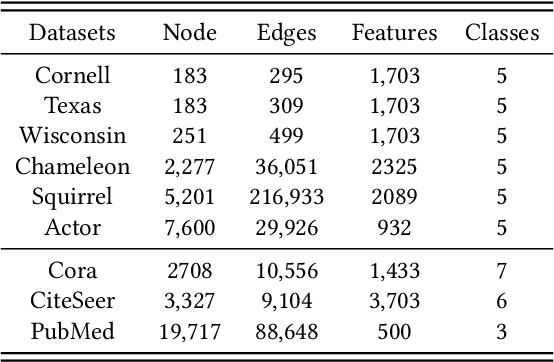
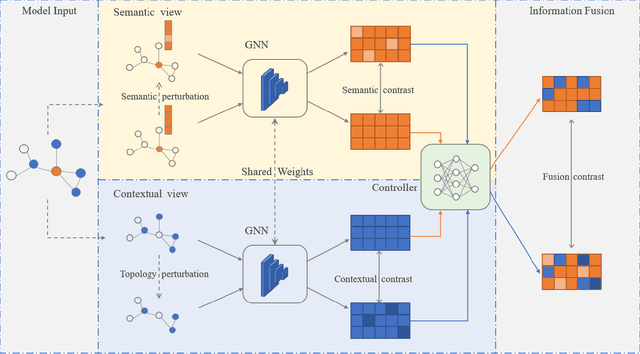
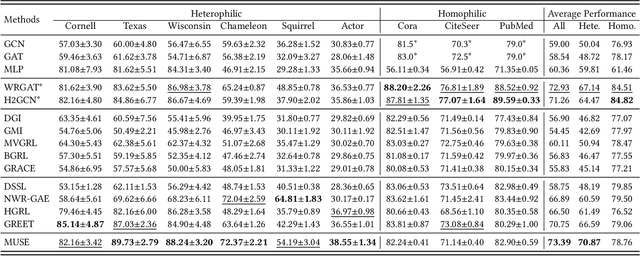
In recent years, self-supervised learning has emerged as a promising approach in addressing the issues of label dependency and poor generalization performance in traditional GNNs. However, existing self-supervised methods have limited effectiveness on heterophilic graphs, due to the homophily assumption that results in similar node representations for connected nodes. In this work, we propose a multi-view contrastive learning model for heterophilic graphs, namely, MUSE. Specifically, we construct two views to capture the information of the ego node and its neighborhood by GNNs enhanced with contrastive learning, respectively. Then we integrate the information from these two views to fuse the node representations. Fusion contrast is utilized to enhance the effectiveness of fused node representations. Further, considering that the influence of neighboring contextual information on information fusion may vary across different ego nodes, we employ an information fusion controller to model the diversity of node-neighborhood similarity at both the local and global levels. Finally, an alternating training scheme is adopted to ensure that unsupervised node representation learning and information fusion controller can mutually reinforce each other. We conduct extensive experiments to evaluate the performance of MUSE on 9 benchmark datasets. Our results show the effectiveness of MUSE on both node classification and clustering tasks.
Deep Context Interest Network for Click-Through Rate Prediction
Aug 11, 2023
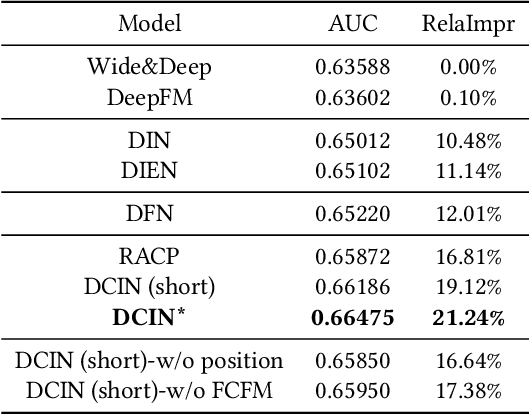
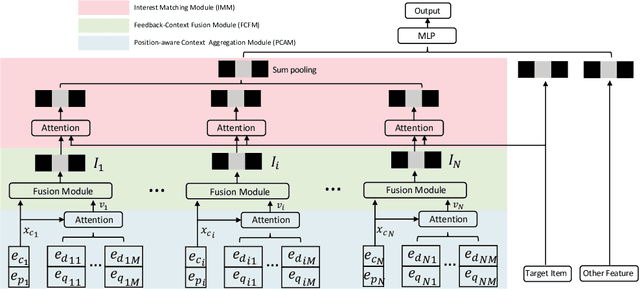
Click-Through Rate (CTR) prediction, estimating the probability of a user clicking on an item, is essential in industrial applications, such as online advertising. Many works focus on user behavior modeling to improve CTR prediction performance. However, most of those methods only model users' positive interests from users' click items while ignoring the context information, which is the display items around the clicks, resulting in inferior performance. In this paper, we highlight the importance of context information on user behavior modeling and propose a novel model named Deep Context Interest Network (DCIN), which integrally models the click and its display context to learn users' context-aware interests. DCIN consists of three key modules: 1) Position-aware Context Aggregation Module (PCAM), which performs aggregation of display items with an attention mechanism; 2) Feedback-Context Fusion Module (FCFM), which fuses the representation of clicks and display contexts through non-linear feature interaction; 3) Interest Matching Module (IMM), which activates interests related with the target item. Moreover, we provide our hands-on solution to implement our DCIN model on large-scale industrial systems. The significant improvements in both offline and online evaluations demonstrate the superiority of our proposed DCIN method. Notably, DCIN has been deployed on our online advertising system serving the main traffic, which brings 1.5% CTR and 1.5% RPM lift.
The divergence time of protein structures modelled by Markov matrices and its relation to the divergence of sequences
Aug 11, 2023A complete time-parameterized statistical model quantifying the divergent evolution of protein structures in terms of the patterns of conservation of their secondary structures is inferred from a large collection of protein 3D structure alignments. This provides a better alternative to time-parameterized sequence-based models of protein relatedness, that have clear limitations dealing with twilight and midnight zones of sequence relationships. Since protein structures are far more conserved due to the selection pressure directly placed on their function, divergence time estimates can be more accurate when inferred from structures. We use the Bayesian and information-theoretic framework of Minimum Message Length to infer a time-parameterized stochastic matrix (accounting for perturbed structural states of related residues) and associated Dirichlet models (accounting for insertions and deletions during the evolution of protein domains). These are used in concert to estimate the Markov time of divergence of tertiary structures, a task previously only possible using proxies (like RMSD). By analyzing one million pairs of homologous structures, we yield a relationship between the Markov divergence time of structures and of sequences. Using these inferred models and the relationship between the divergence of sequences and structures, we demonstrate a competitive performance in secondary structure prediction against neural network architectures commonly employed for this task. The source code and supplementary information are downloadable from \url{http://lcb.infotech.monash.edu.au/sstsum}.
MIMO Radar Transmit Signal Optimization for Target Localization Exploiting Prior Information
May 15, 2023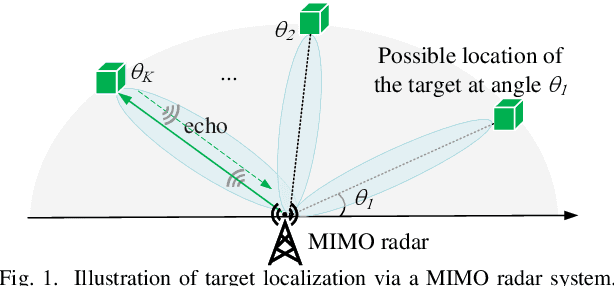
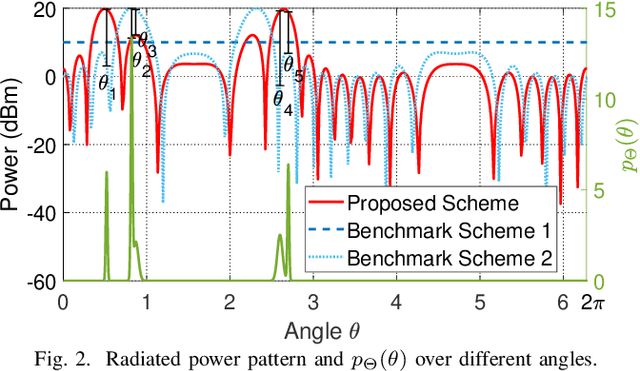
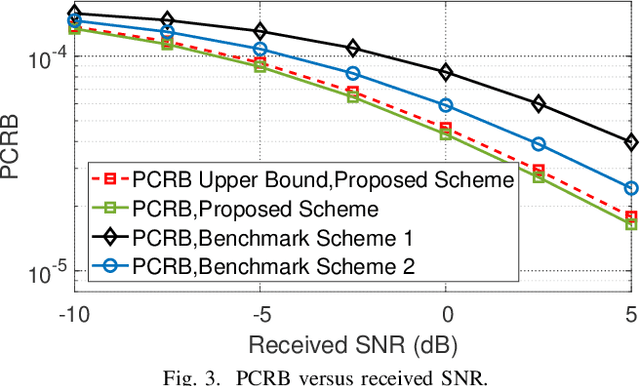
In this paper, we consider a multiple-input multiple-output (MIMO) radar system for localizing a target based on its reflected echo signals. Specifically, we aim to estimate the random and unknown angle information of the target, by exploiting its prior distribution information. First, we characterize the estimation performance by deriving the posterior Cram\'er-Rao bound (PCRB), which quantifies a lower bound of the estimation mean-squared error (MSE). Since the PCRB is in a complicated form, we derive a tight upper bound of it to approximate the estimation performance. Based on this, we analytically show that by exploiting the prior distribution information, the PCRB is always no larger than the Cram\'er-Rao bound (CRB) averaged over random angle realizations without prior information exploitation. Next, we formulate the transmit signal optimization problem to minimize the PCRB upper bound. We show that the optimal sample covariance matrix has a rank-one structure, and derive the optimal signal solution in closed form. Numerical results show that our proposed design achieves significantly improved PCRB performance compared to various benchmark schemes.
MapNeRF: Incorporating Map Priors into Neural Radiance Fields for Driving View Simulation
Aug 06, 2023Simulating camera sensors is a crucial task in autonomous driving. Although neural radiance fields are exceptional at synthesizing photorealistic views in driving simulations, they still fail to generate extrapolated views. This paper proposes to incorporate map priors into neural radiance fields to synthesize out-of-trajectory driving views with semantic road consistency. The key insight is that map information can be utilized as a prior to guiding the training of the radiance fields with uncertainty. Specifically, we utilize the coarse ground surface as uncertain information to supervise the density field and warp depth with uncertainty from unknown camera poses to ensure multi-view consistency. Experimental results demonstrate that our approach can produce semantic consistency in deviated views for vehicle camera simulation. The supplementary video can be viewed at https://youtu.be/jEQWr-Rfh3A.
A deep deformable residual learning network for SAR images segmentation
Aug 15, 2023Reliable automatic target segmentation in Synthetic Aperture Radar (SAR) imagery has played an important role in the SAR fields. Different from the traditional methods, Spectral Residual (SR) and CFAR detector, with the recent adavance in machine learning theory, there has emerged a novel method for SAR target segmentation, based on the deep learning networks. In this paper, we proposed a deep deformable residual learning network for target segmentation that attempts to preserve the precise contour of the target. For this, the deformable convolutional layers and residual learning block are applied, which could extract and preserve the geometric information of the targets as much as possible. Based on the Moving and Stationary Target Acquisition and Recognition (MSTAR) data set, experimental results have shown the superiority of the proposed network for the precise targets segmentation.
When Are Two Lists Better than One?: Benefits and Harms in Joint Decision-making
Aug 22, 2023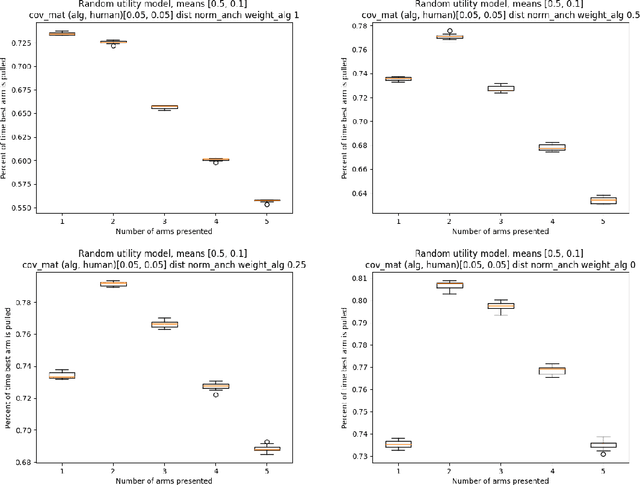
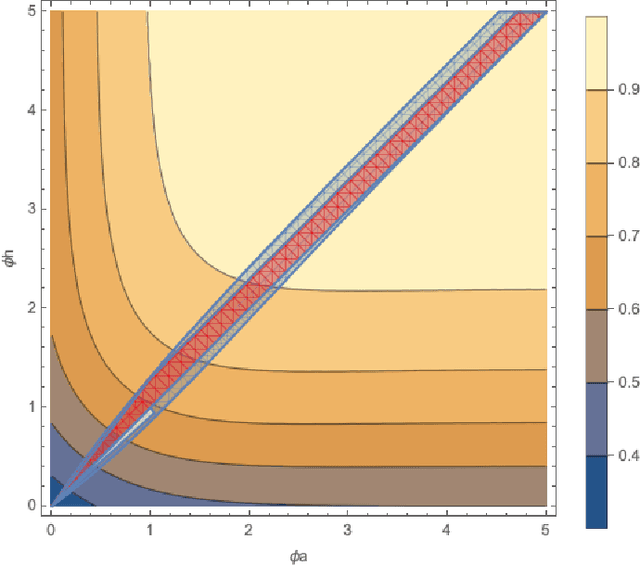
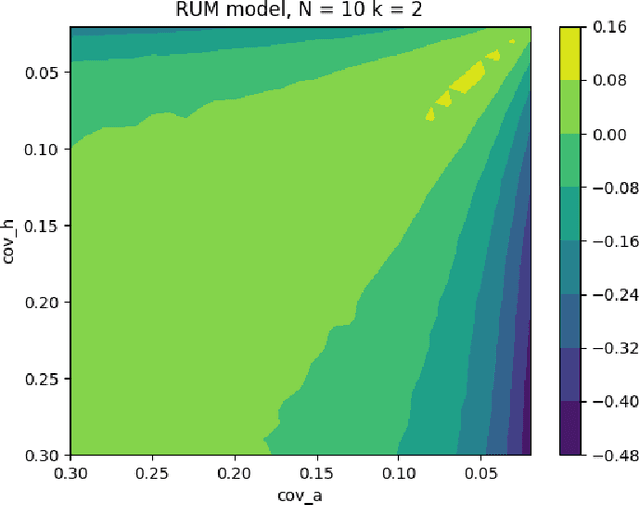
Historically, much of machine learning research has focused on the performance of the algorithm alone, but recently more attention has been focused on optimizing joint human-algorithm performance. Here, we analyze a specific type of human-algorithm collaboration where the algorithm has access to a set of $n$ items, and presents a subset of size $k$ to the human, who selects a final item from among those $k$. This scenario could model content recommendation, route planning, or any type of labeling task. Because both the human and algorithm have imperfect, noisy information about the true ordering of items, the key question is: which value of $k$ maximizes the probability that the best item will be ultimately selected? For $k=1$, performance is optimized by the algorithm acting alone, and for $k=n$ it is optimized by the human acting alone. Surprisingly, we show that for multiple of noise models, it is optimal to set $k \in [2, n-1]$ - that is, there are strict benefits to collaborating, even when the human and algorithm have equal accuracy separately. We demonstrate this theoretically for the Mallows model and experimentally for the Random Utilities models of noisy permutations. However, we show this pattern is reversed when the human is anchored on the algorithm's presented ordering - the joint system always has strictly worse performance. We extend these results to the case where the human and algorithm differ in their accuracy levels, showing that there always exist regimes where a more accurate agent would strictly benefit from collaborating with a less accurate one, but these regimes are asymmetric between the human and the algorithm's accuracy.
Rethinking Client Drift in Federated Learning: A Logit Perspective
Aug 20, 2023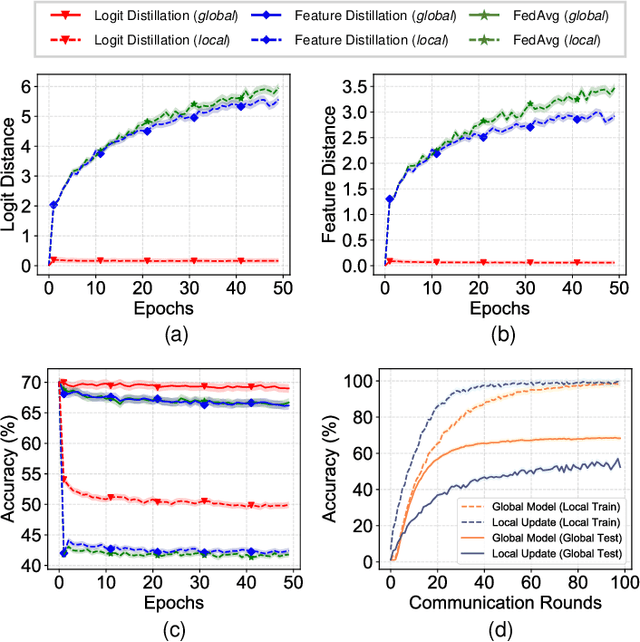
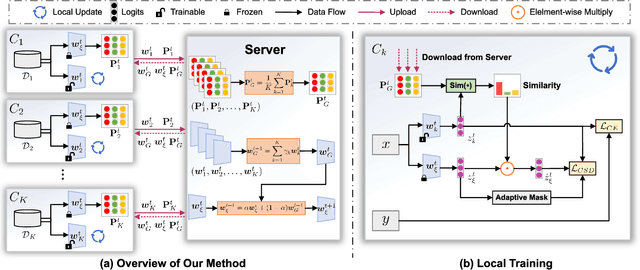
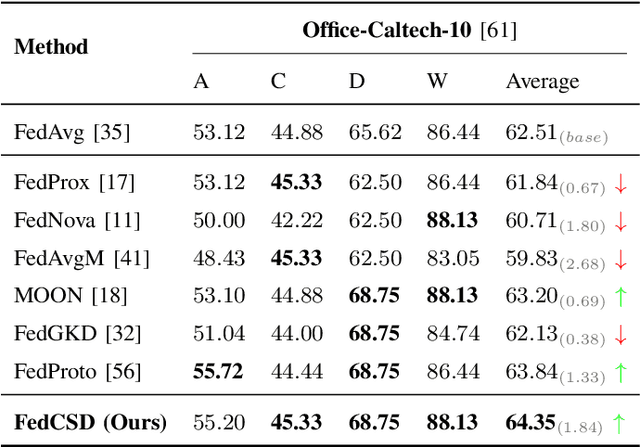
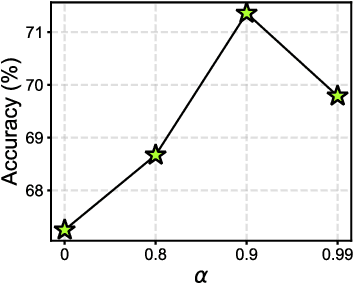
Federated Learning (FL) enables multiple clients to collaboratively learn in a distributed way, allowing for privacy protection. However, the real-world non-IID data will lead to client drift which degrades the performance of FL. Interestingly, we find that the difference in logits between the local and global models increases as the model is continuously updated, thus seriously deteriorating FL performance. This is mainly due to catastrophic forgetting caused by data heterogeneity between clients. To alleviate this problem, we propose a new algorithm, named FedCSD, a Class prototype Similarity Distillation in a federated framework to align the local and global models. FedCSD does not simply transfer global knowledge to local clients, as an undertrained global model cannot provide reliable knowledge, i.e., class similarity information, and its wrong soft labels will mislead the optimization of local models. Concretely, FedCSD introduces a class prototype similarity distillation to align the local logits with the refined global logits that are weighted by the similarity between local logits and the global prototype. To enhance the quality of global logits, FedCSD adopts an adaptive mask to filter out the terrible soft labels of the global models, thereby preventing them to mislead local optimization. Extensive experiments demonstrate the superiority of our method over the state-of-the-art federated learning approaches in various heterogeneous settings. The source code will be released.
Tracing the Influence of Predecessors on Trajectory Prediction
Aug 10, 2023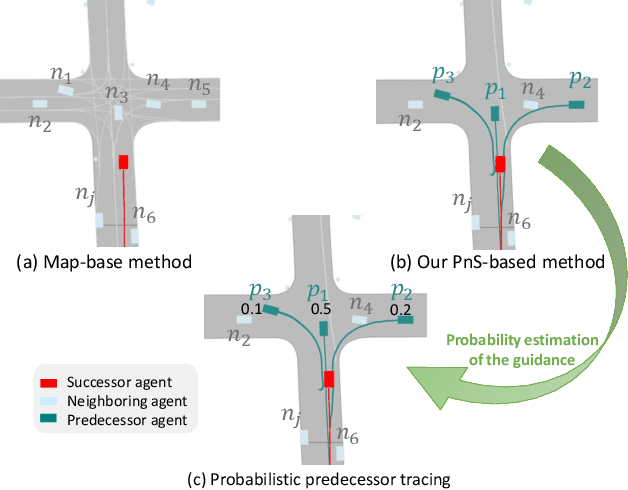
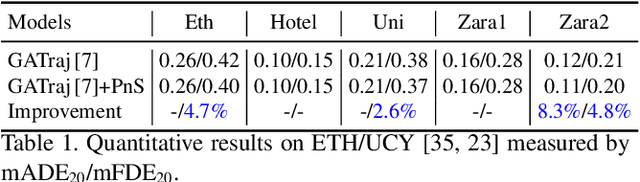
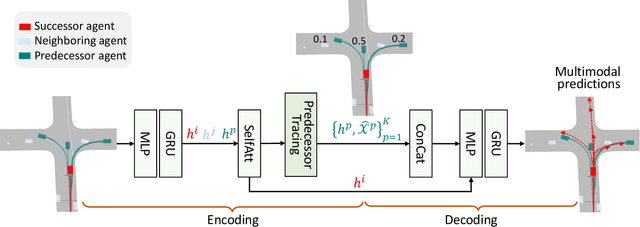
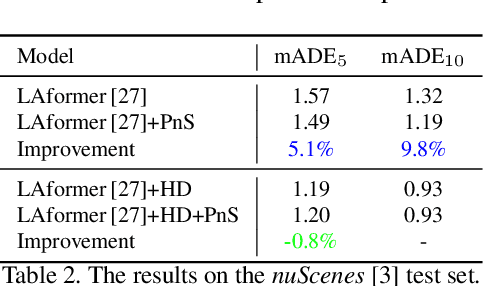
In real-world traffic scenarios, agents such as pedestrians and car drivers often observe neighboring agents who exhibit similar behavior as examples and then mimic their actions to some extent in their own behavior. This information can serve as prior knowledge for trajectory prediction, which is unfortunately largely overlooked in current trajectory prediction models. This paper introduces a novel Predecessor-and-Successor (PnS) method that incorporates a predecessor tracing module to model the influence of predecessors (identified from concurrent neighboring agents) on the successor (target agent) within the same scene. The method utilizes the moving patterns of these predecessors to guide the predictor in trajectory prediction. PnS effectively aligns the motion encodings of the successor with multiple potential predecessors in a probabilistic manner, facilitating the decoding process. We demonstrate the effectiveness of PnS by integrating it into a graph-based predictor for pedestrian trajectory prediction on the ETH/UCY datasets, resulting in a new state-of-the-art performance. Furthermore, we replace the HD map-based scene-context module with our PnS method in a transformer-based predictor for vehicle trajectory prediction on the nuScenes dataset, showing that the predictor maintains good prediction performance even without relying on any map information.
DiVa: An Iterative Framework to Harvest More Diverse and Valid Labels from User Comments for Music
Aug 09, 2023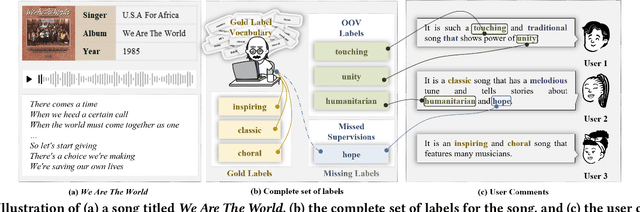

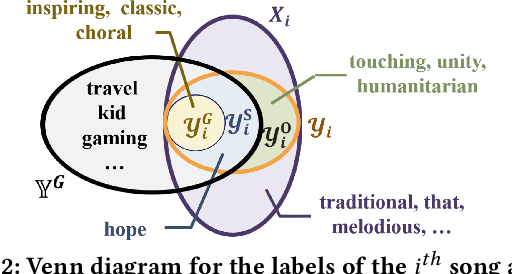
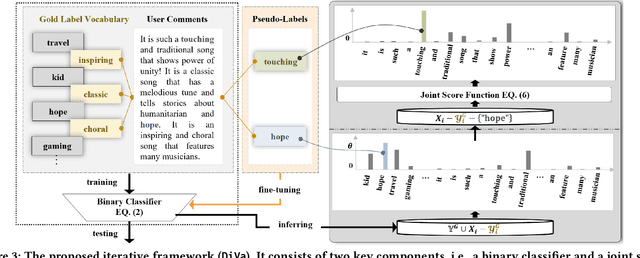
Towards sufficient music searching, it is vital to form a complete set of labels for each song. However, current solutions fail to resolve it as they cannot produce diverse enough mappings to make up for the information missed by the gold labels. Based on the observation that such missing information may already be presented in user comments, we propose to study the automated music labeling in an essential but under-explored setting, where the model is required to harvest more diverse and valid labels from the users' comments given limited gold labels. To this end, we design an iterative framework (DiVa) to harvest more $\underline{\text{Di}}$verse and $\underline{\text{Va}}$lid labels from user comments for music. The framework makes a classifier able to form complete sets of labels for songs via pseudo-labels inferred from pre-trained classifiers and a novel joint score function. The experiment on a densely annotated testing set reveals the superiority of the Diva over state-of-the-art solutions in producing more diverse labels missed by the gold labels. We hope our work can inspire future research on automated music labeling.