 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Integrating cognitive map learning and active inference for planning in ambiguous environments
Aug 16, 2023
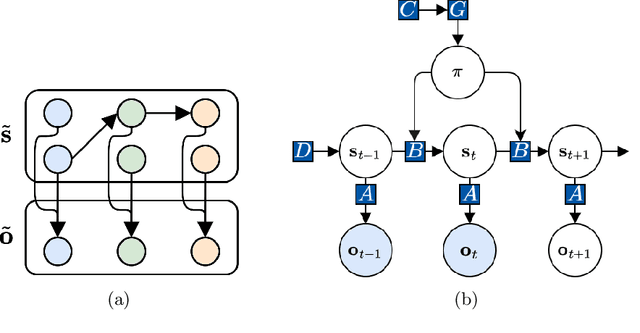
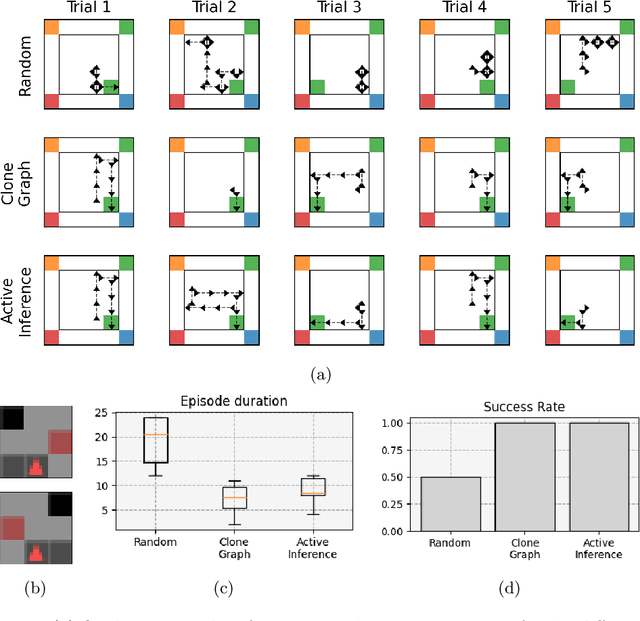
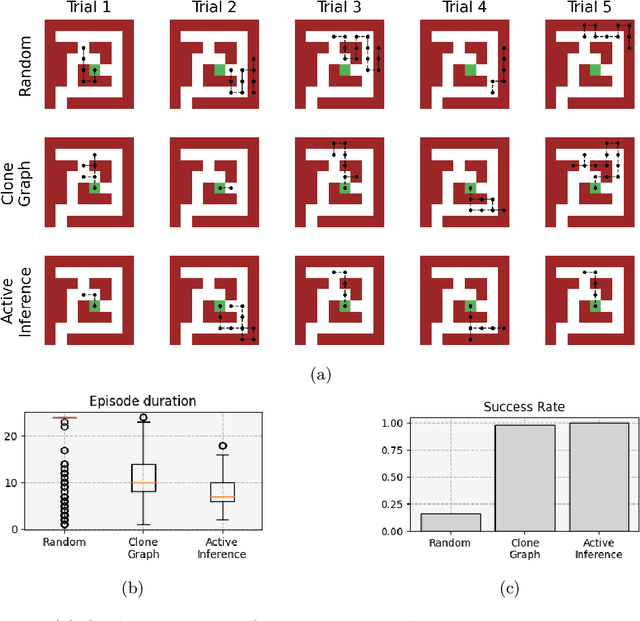
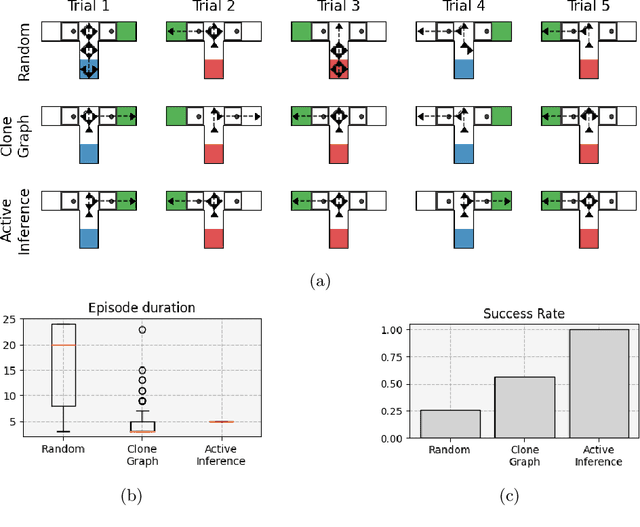
Living organisms need to acquire both cognitive maps for learning the structure of the world and planning mechanisms able to deal with the challenges of navigating ambiguous environments. Although significant progress has been made in each of these areas independently, the best way to integrate them is an open research question. In this paper, we propose the integration of a statistical model of cognitive map formation within an active inference agent that supports planning under uncertainty. Specifically, we examine the clone-structured cognitive graph (CSCG) model of cognitive map formation and compare a naive clone graph agent with an active inference-driven clone graph agent, in three spatial navigation scenarios. Our findings demonstrate that while both agents are effective in simple scenarios, the active inference agent is more effective when planning in challenging scenarios, in which sensory observations provide ambiguous information about location.
Sarcasm Detection in a Disaster Context
Aug 16, 2023
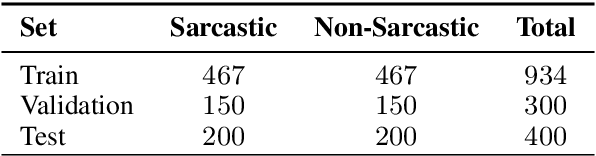


During natural disasters, people often use social media platforms such as Twitter to ask for help, to provide information about the disaster situation, or to express contempt about the unfolding event or public policies and guidelines. This contempt is in some cases expressed as sarcasm or irony. Understanding this form of speech in a disaster-centric context is essential to improving natural language understanding of disaster-related tweets. In this paper, we introduce HurricaneSARC, a dataset of 15,000 tweets annotated for intended sarcasm, and provide a comprehensive investigation of sarcasm detection using pre-trained language models. Our best model is able to obtain as much as 0.70 F1 on our dataset. We also demonstrate that the performance on HurricaneSARC can be improved by leveraging intermediate task transfer learning. We release our data and code at https://github.com/tsosea2/HurricaneSarc.
MonoNeRD: NeRF-like Representations for Monocular 3D Object Detection
Aug 18, 2023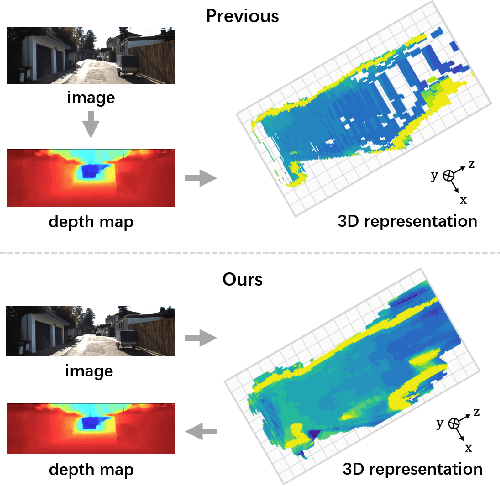

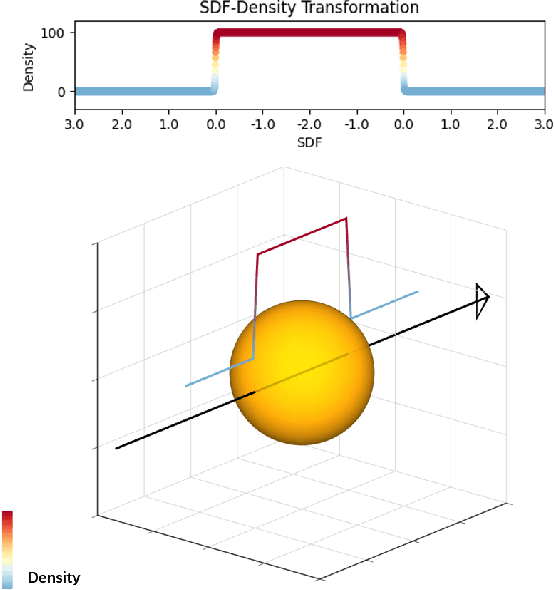
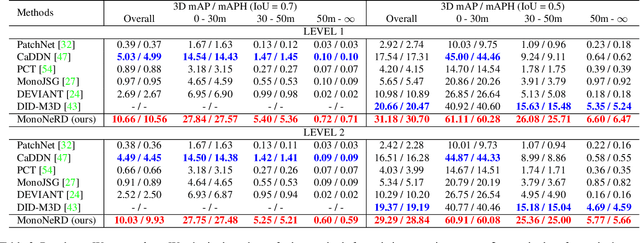
In the field of monocular 3D detection, it is common practice to utilize scene geometric clues to enhance the detector's performance. However, many existing works adopt these clues explicitly such as estimating a depth map and back-projecting it into 3D space. This explicit methodology induces sparsity in 3D representations due to the increased dimensionality from 2D to 3D, and leads to substantial information loss, especially for distant and occluded objects. To alleviate this issue, we propose MonoNeRD, a novel detection framework that can infer dense 3D geometry and occupancy. Specifically, we model scenes with Signed Distance Functions (SDF), facilitating the production of dense 3D representations. We treat these representations as Neural Radiance Fields (NeRF) and then employ volume rendering to recover RGB images and depth maps. To the best of our knowledge, this work is the first to introduce volume rendering for M3D, and demonstrates the potential of implicit reconstruction for image-based 3D perception. Extensive experiments conducted on the KITTI-3D benchmark and Waymo Open Dataset demonstrate the effectiveness of MonoNeRD. Codes are available at https://github.com/cskkxjk/MonoNeRD.
LibreFace: An Open-Source Toolkit for Deep Facial Expression Analysis
Aug 18, 2023
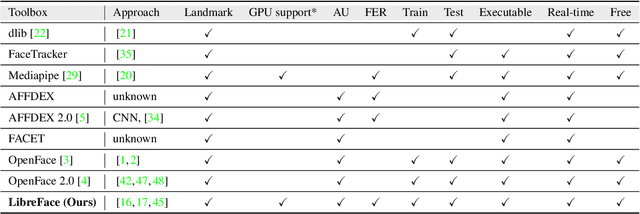
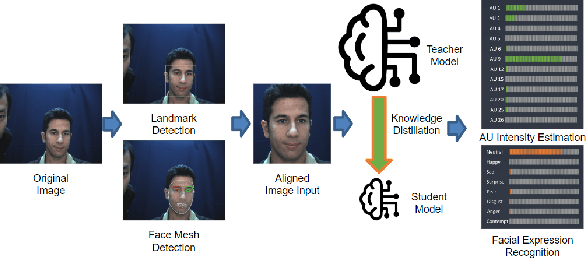

Facial expression analysis is an important tool for human-computer interaction. In this paper, we introduce LibreFace, an open-source toolkit for facial expression analysis. This open-source toolbox offers real-time and offline analysis of facial behavior through deep learning models, including facial action unit (AU) detection, AU intensity estimation, and facial expression recognition. To accomplish this, we employ several techniques, including the utilization of a large-scale pre-trained network, feature-wise knowledge distillation, and task-specific fine-tuning. These approaches are designed to effectively and accurately analyze facial expressions by leveraging visual information, thereby facilitating the implementation of real-time interactive applications. In terms of Action Unit (AU) intensity estimation, we achieve a Pearson Correlation Coefficient (PCC) of 0.63 on DISFA, which is 7% higher than the performance of OpenFace 2.0 while maintaining highly-efficient inference that runs two times faster than OpenFace 2.0. Despite being compact, our model also demonstrates competitive performance to state-of-the-art facial expression analysis methods on AffecNet, FFHQ, and RAFDB. Our code will be released at https://github.com/ihp-lab/LibreFace
Signal Processing Based Antenna Pattern Characterization for MIMO Systems
Aug 18, 2023Sophisticated antenna technologies are constantly evolving to meet the escalating data demands projected for 6G and future networks. The characterization of these emerging antenna systems poses challenges that necessitate a reevaluation of conventional techniques, which rely solely on simple measurements conducted in advanced anechoic chambers. In this study, our objective is to introduce a novel endeavour for antenna pattern characterization (APC) in next-generation multiple-input-multiple-output (MIMO) systems by utilizing the potential of signal processing tools. In contrast to traditional methods that struggle with multi-path scenarios and require specialized equipment for measurements, we endeavour to estimate the antenna pattern by exploiting information from both line-of-sight (LoS) and non-LoS contributions. This approach enables antenna pattern characterization in complex environments without the need for anechoic chambers, resulting in substantial cost savings. Furthermore, it grants a much wider research community the ability to independently perform APC for emerging complex 6G antenna systems, without relying on anechoic chambers. Simulation results demonstrate the efficacy of the proposed novel approach in accurately estimating the true antenna pattern.
Preserving Knowledge Invariance: Rethinking Robustness Evaluation of Open Information Extraction
May 23, 2023
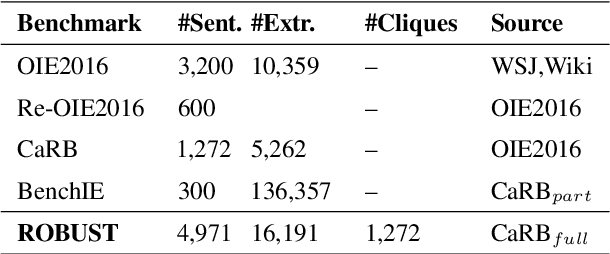
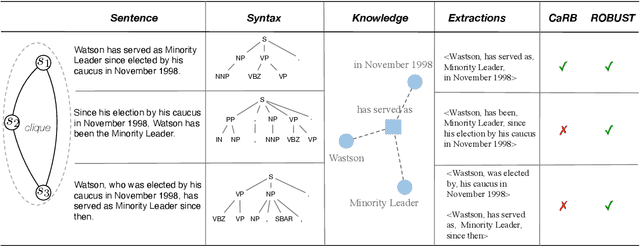
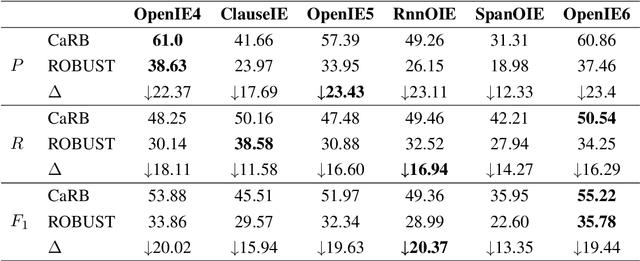
The robustness to distribution changes ensures that NLP models can be successfully applied in the realistic world, especially for information extraction tasks. However, most prior evaluation benchmarks have been devoted to validating pairwise matching correctness, ignoring the crucial measurement of robustness. In this paper, we present the first benchmark that simulates the evaluation of open information extraction models in the real world, where the syntactic and expressive distributions under the same knowledge meaning may drift variously. We design and annotate a large-scale testbed in which each example is a knowledge-invariant clique that consists of sentences with structured knowledge of the same meaning but with different syntactic and expressive forms. By further elaborating the robustness metric, a model is judged to be robust if its performance is consistently accurate on the overall cliques. We perform experiments on typical models published in the last decade as well as a popular large language model, the results show that the existing successful models exhibit a frustrating degradation, with a maximum drop of 23.43 F1 score. Our resources and code will be publicly available.
The Unreasonable Effectiveness of Large Language-Vision Models for Source-free Video Domain Adaptation
Aug 17, 2023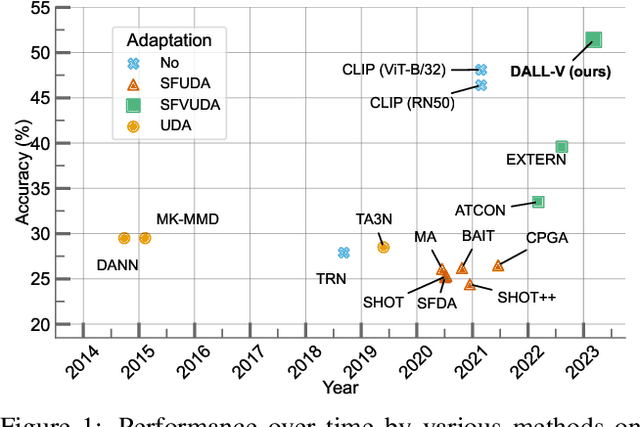
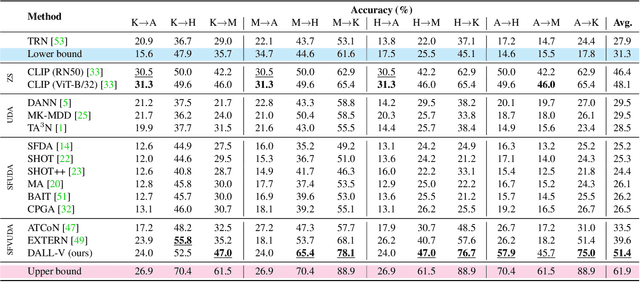
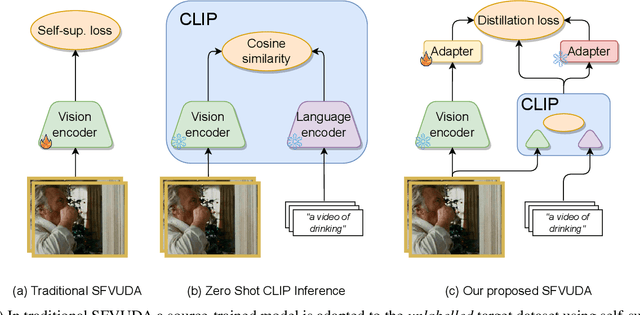
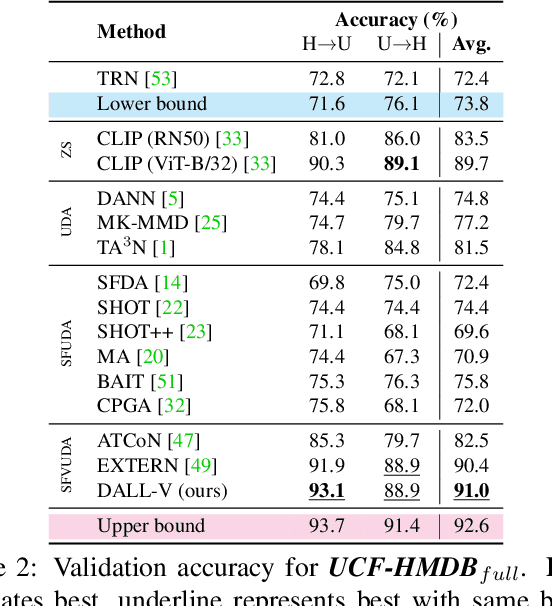
Source-Free Video Unsupervised Domain Adaptation (SFVUDA) methods consists in the task of adapting an action recognition model, trained on a labelled source dataset, to an unlabelled target dataset, without accessing the actual source data. Previous approaches have attempted to address SFVUDA by leveraging self-supervision (e.g., enforcing temporal consistency) derived from the target data itself. In this work we take an orthogonal approach by exploiting "web-supervision" from Large Language-Vision Models (LLVMs), driven by the rationale that LLVMs contain rich world prior, which is surprisingly robust to domain-shift. We showcase the unreasonable effectiveness of integrating LLVMs for SFVUDA by devising an intuitive and parameter efficient method, which we name as Domain Adaptation with Large Language-Vision models (DALL-V), that distills the world prior and complementary source model information into a student network tailored for the target. Despite the simplicity, DALL-V achieves significant improvement over state-of-the-art SFVUDA methods.
Exploiting Point-Wise Attention in 6D Object Pose Estimation Based on Bidirectional Prediction
Aug 17, 2023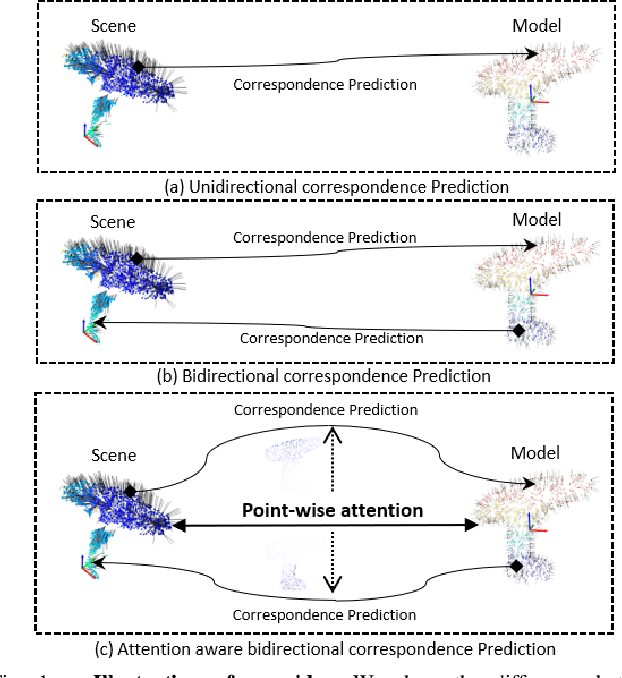
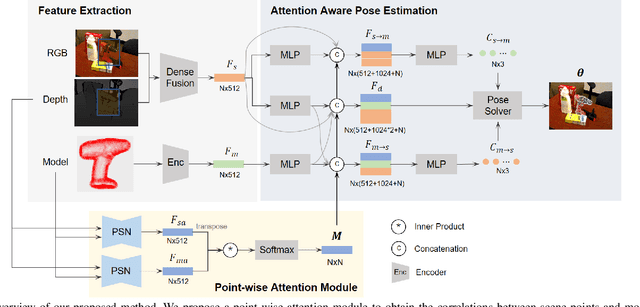
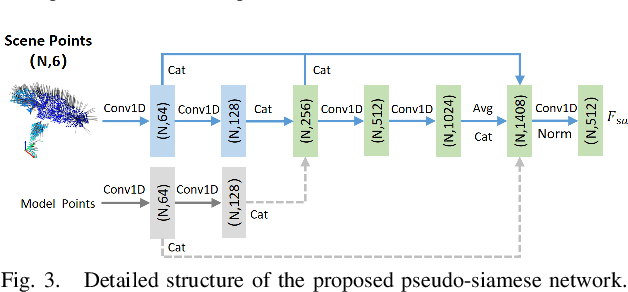
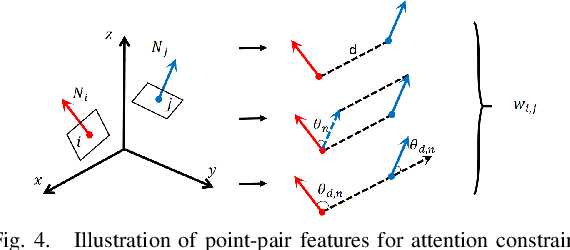
Traditional geometric registration based estimation methods only exploit the CAD model implicitly, which leads to their dependence on observation quality and deficiency to occlusion. To address the problem,the paper proposes a bidirectional correspondence prediction network with a point-wise attention-aware mechanism. This network not only requires the model points to predict the correspondence but also explicitly models the geometric similarities between observations and the model prior. Our key insight is that the correlations between each model point and scene point provide essential information for learning point-pair matches. To further tackle the correlation noises brought by feature distribution divergence, we design a simple but effective pseudo-siamese network to improve feature homogeneity. Experimental results on the public datasets of LineMOD, YCB-Video, and Occ-LineMOD show that the proposed method achieves better performance than other state-of-the-art methods under the same evaluation criteria. Its robustness in estimating poses is greatly improved, especially in an environment with severe occlusions.
SDDNet: Style-guided Dual-layer Disentanglement Network for Shadow Detection
Aug 17, 2023
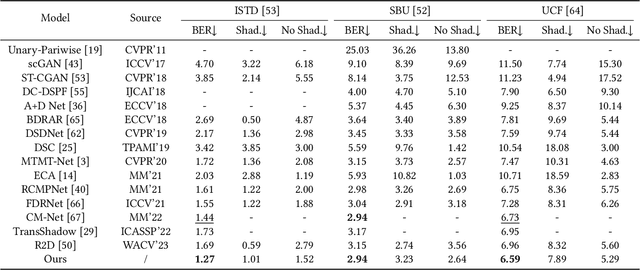
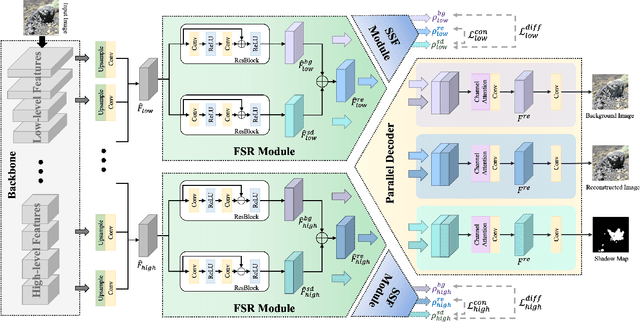
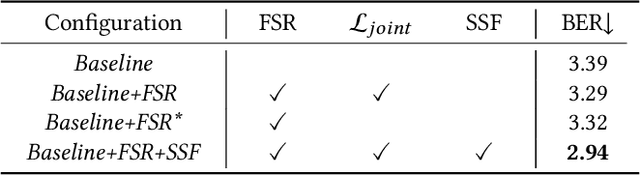
Despite significant progress in shadow detection, current methods still struggle with the adverse impact of background color, which may lead to errors when shadows are present on complex backgrounds. Drawing inspiration from the human visual system, we treat the input shadow image as a composition of a background layer and a shadow layer, and design a Style-guided Dual-layer Disentanglement Network (SDDNet) to model these layers independently. To achieve this, we devise a Feature Separation and Recombination (FSR) module that decomposes multi-level features into shadow-related and background-related components by offering specialized supervision for each component, while preserving information integrity and avoiding redundancy through the reconstruction constraint. Moreover, we propose a Shadow Style Filter (SSF) module to guide the feature disentanglement by focusing on style differentiation and uniformization. With these two modules and our overall pipeline, our model effectively minimizes the detrimental effects of background color, yielding superior performance on three public datasets with a real-time inference speed of 32 FPS.
InverseSR: 3D Brain MRI Super-Resolution Using a Latent Diffusion Model
Aug 23, 2023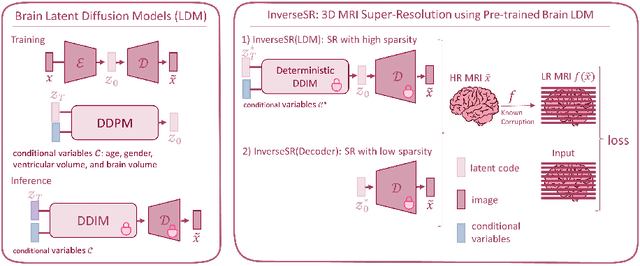
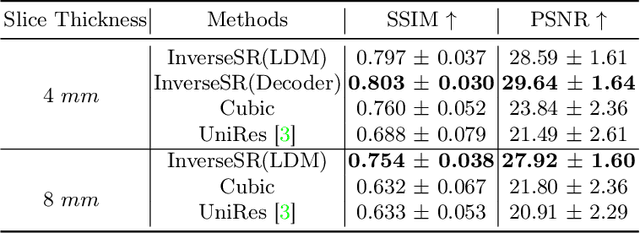
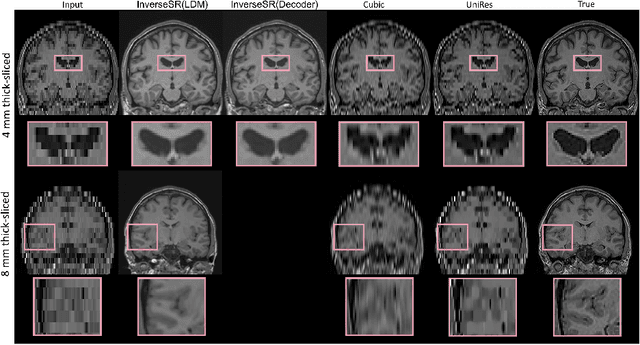
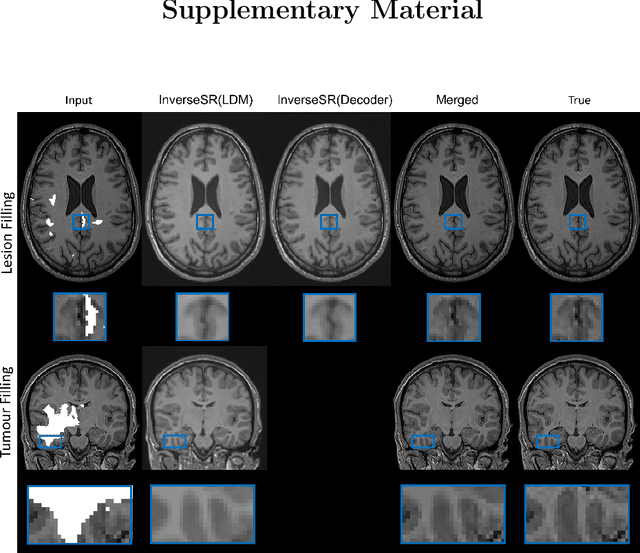
High-resolution (HR) MRI scans obtained from research-grade medical centers provide precise information about imaged tissues. However, routine clinical MRI scans are typically in low-resolution (LR) and vary greatly in contrast and spatial resolution due to the adjustments of the scanning parameters to the local needs of the medical center. End-to-end deep learning methods for MRI super-resolution (SR) have been proposed, but they require re-training each time there is a shift in the input distribution. To address this issue, we propose a novel approach that leverages a state-of-the-art 3D brain generative model, the latent diffusion model (LDM) trained on UK BioBank, to increase the resolution of clinical MRI scans. The LDM acts as a generative prior, which has the ability to capture the prior distribution of 3D T1-weighted brain MRI. Based on the architecture of the brain LDM, we find that different methods are suitable for different settings of MRI SR, and thus propose two novel strategies: 1) for SR with more sparsity, we invert through both the decoder of the LDM and also through a deterministic Denoising Diffusion Implicit Models (DDIM), an approach we will call InverseSR(LDM); 2) for SR with less sparsity, we invert only through the LDM decoder, an approach we will call InverseSR(Decoder). These two approaches search different latent spaces in the LDM model to find the optimal latent code to map the given LR MRI into HR. The training process of the generative model is independent of the MRI under-sampling process, ensuring the generalization of our method to many MRI SR problems with different input measurements. We validate our method on over 100 brain T1w MRIs from the IXI dataset. Our method can demonstrate that powerful priors given by LDM can be used for MRI reconstruction.