 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Federated Pseudo Modality Generation for Incomplete Multi-Modal MRI Reconstruction
Aug 20, 2023
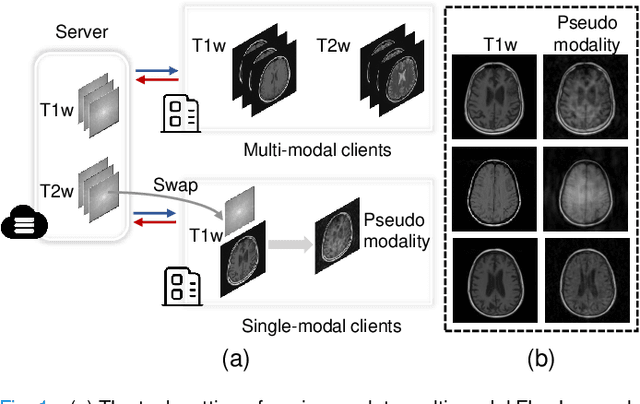
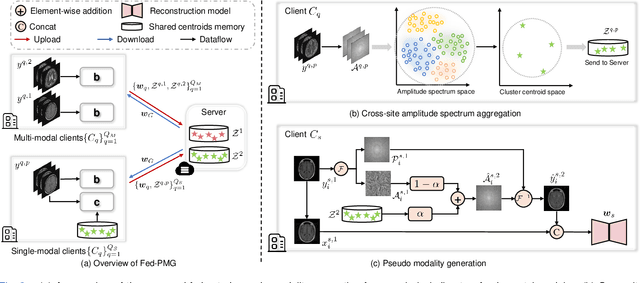
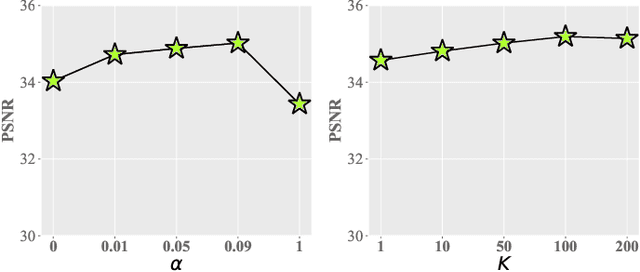
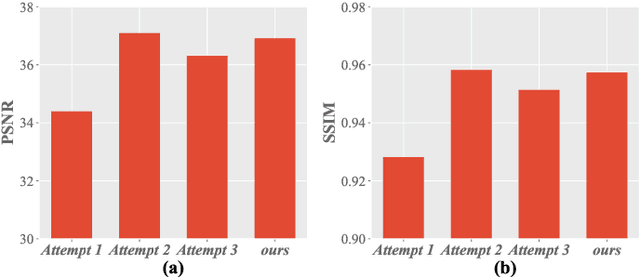
While multi-modal learning has been widely used for MRI reconstruction, it relies on paired multi-modal data which is difficult to acquire in real clinical scenarios. Especially in the federated setting, the common situation is that several medical institutions only have single-modal data, termed the modality missing issue. Therefore, it is infeasible to deploy a standard federated learning framework in such conditions. In this paper, we propose a novel communication-efficient federated learning framework, namely Fed-PMG, to address the missing modality challenge in federated multi-modal MRI reconstruction. Specifically, we utilize a pseudo modality generation mechanism to recover the missing modality for each single-modal client by sharing the distribution information of the amplitude spectrum in frequency space. However, the step of sharing the original amplitude spectrum leads to heavy communication costs. To reduce the communication cost, we introduce a clustering scheme to project the set of amplitude spectrum into finite cluster centroids, and share them among the clients. With such an elaborate design, our approach can effectively complete the missing modality within an acceptable communication cost. Extensive experiments demonstrate that our proposed method can attain similar performance with the ideal scenario, i.e., all clients have the full set of modalities. The source code will be released.
Economic Policy Uncertainty: A Review on Applications and Measurement Methods with Focus on Text Mining Methods
Aug 20, 2023
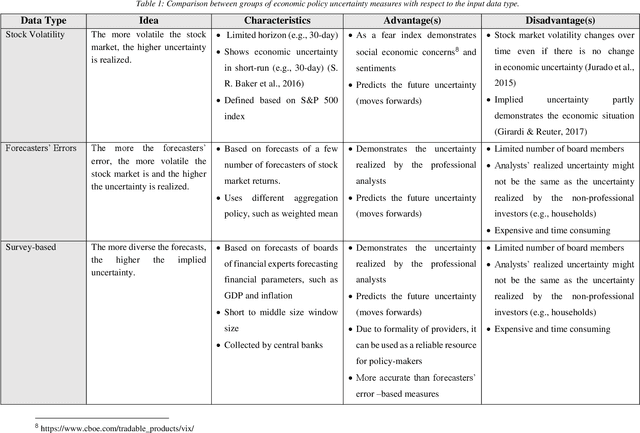
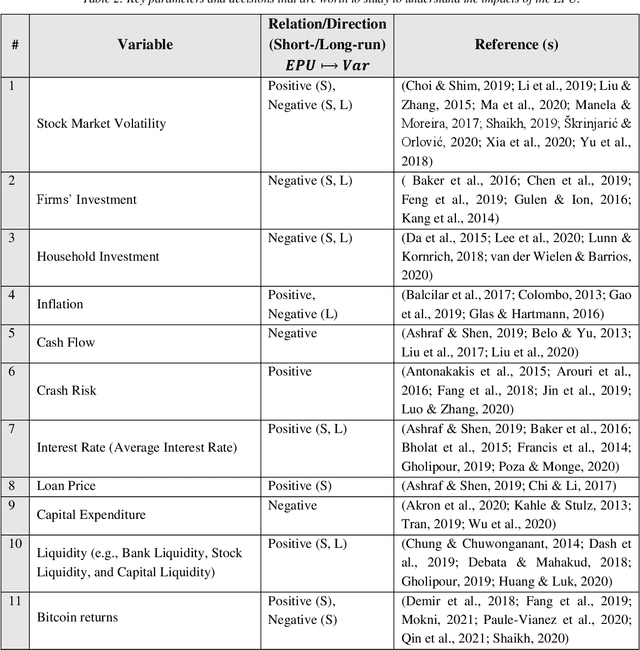
Economic Policy Uncertainty (EPU) represents the uncertainty realized by the investors during economic policy alterations. EPU is a critical indicator in economic studies to predict future investments, the unemployment rate, and recessions. EPU values can be estimated based on financial parameters directly or implied uncertainty indirectly using the text mining methods. Although EPU is a well-studied topic within the economy, the methods utilized to measure it are understudied. In this article, we define the EPU briefly and review the methods used to measure the EPU, and survey the areas influenced by the changes in EPU level. We divide the EPU measurement methods into three major groups with respect to their input data. Examples of each group of methods are enlisted, and the pros and cons of the groups are discussed. Among the EPU measures, text mining-based ones are dominantly studied. These methods measure the realized uncertainty by taking into account the uncertainty represented in the news and publicly available sources of financial information. Finally, we survey the research areas that rely on measuring the EPU index with the hope that studying the impacts of uncertainty would attract further attention of researchers from various research fields. In addition, we propose a list of future research approaches focusing on measuring EPU using textual material.
Channel sensing for holographic MIMO surfaces based on interference principle
Aug 20, 2023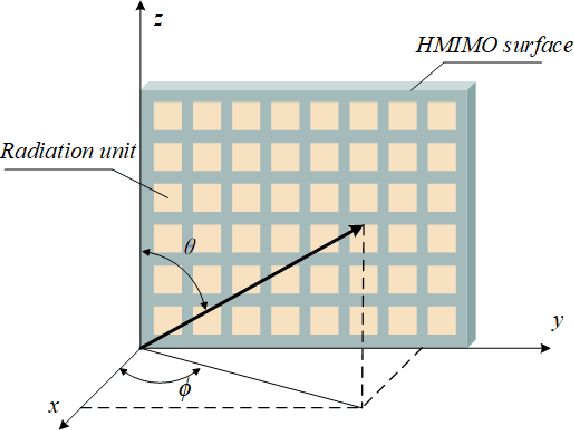
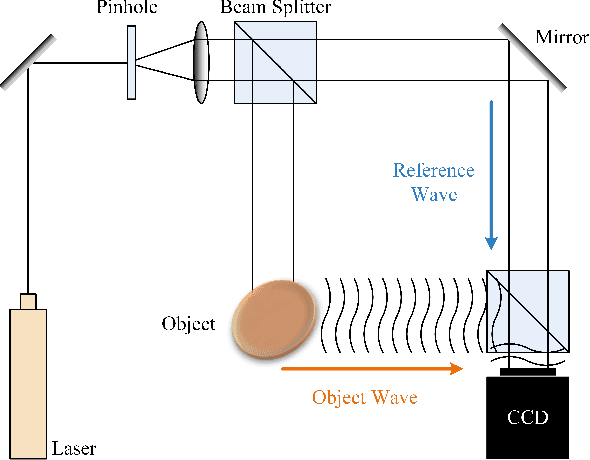
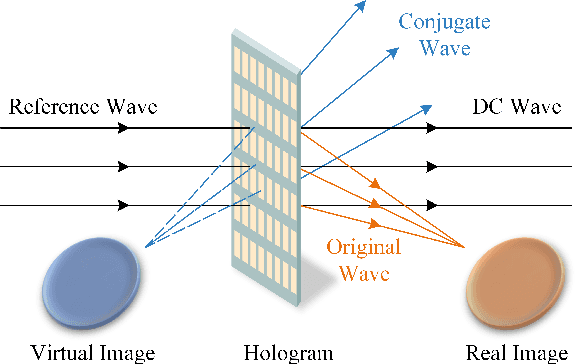
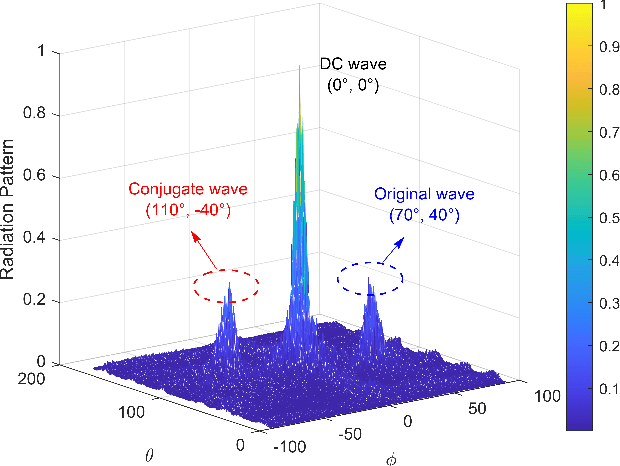
The Holographic Multiple-Input and Multiple-Output (HMIMO) provides a new paradigm for building a more cost-effective wireless communication architecture. In this paper, we derive the principles of holographic interference theory for electromagnetic wave reception and transmission, whereby the optical holography is extended to communication holography and a channel sensing architecture for holographic MIMO surfaces is established. Unlike the traditional pilot-based MIMO channel estimation approaches, the proposed architecture circumvents the complicated processes like filtering, analog to digital conversion (ADC), down conversion. Instead, it relies on interfering the object waves with a pre-designed reference wave, and therefore reduces the hardware complexity and requires less time-frequency resources for channel estimation. To address the self-interference problem in the holographic recording process, we propose a phase shifting-based interference suppression (PSIS) method according to the structural characteristics of communication hologram and interference composition. We then propose a Prony-based multi-user channel segmentation (PMCS) algorithm to acquire the channel state information (CSI). Our theoretical analysis shows that the estimation error of the PMCS algorithm converges to zero when the number of HMIMO surface antennas is large enough. Simulation results show that under the holographic architecture, our proposed algorithm can accurately estimate the CSI in multi-user scenarios.
C5: Towards Better Conversation Comprehension and Contextual Continuity for ChatGPT
Aug 10, 2023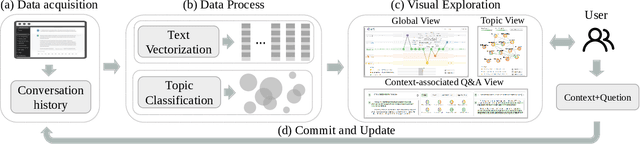
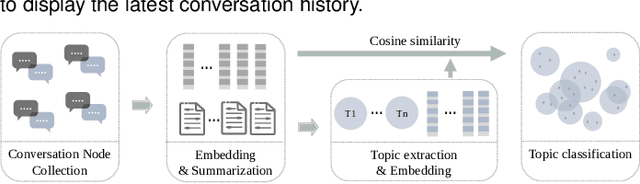
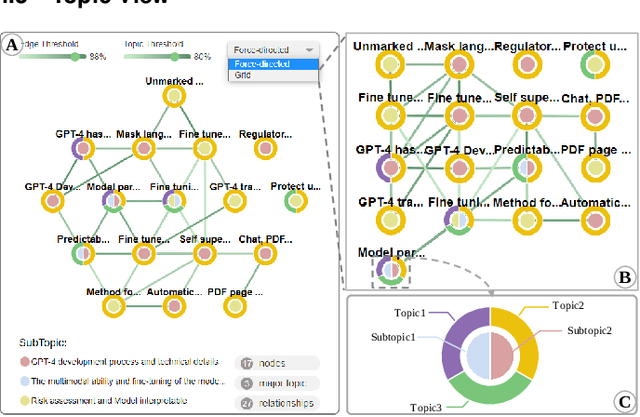
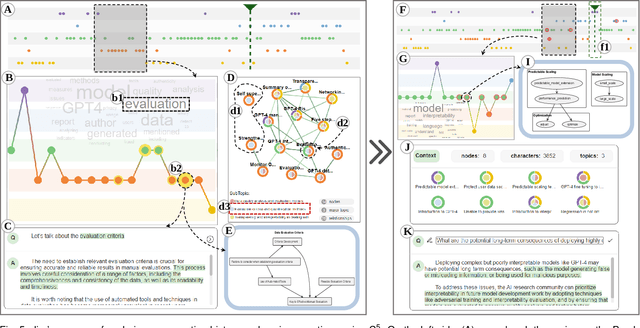
Large language models (LLMs), such as ChatGPT, have demonstrated outstanding performance in various fields, particularly in natural language understanding and generation tasks. In complex application scenarios, users tend to engage in multi-turn conversations with ChatGPT to keep contextual information and obtain comprehensive responses. However, human forgetting and model contextual forgetting remain prominent issues in multi-turn conversation scenarios, which challenge the users' conversation comprehension and contextual continuity for ChatGPT. To address these challenges, we propose an interactive conversation visualization system called C5, which includes Global View, Topic View, and Context-associated Q\&A View. The Global View uses the GitLog diagram metaphor to represent the conversation structure, presenting the trend of conversation evolution and supporting the exploration of locally salient features. The Topic View is designed to display all the question and answer nodes and their relationships within a topic using the structure of a knowledge graph, thereby display the relevance and evolution of conversations. The Context-associated Q\&A View consists of three linked views, which allow users to explore individual conversations deeply while providing specific contextual information when posing questions. The usefulness and effectiveness of C5 were evaluated through a case study and a user study.
TCSloT: Text Guided 3D Context and Slope Aware Triple Network for Dental Implant Position Prediction
Aug 10, 2023
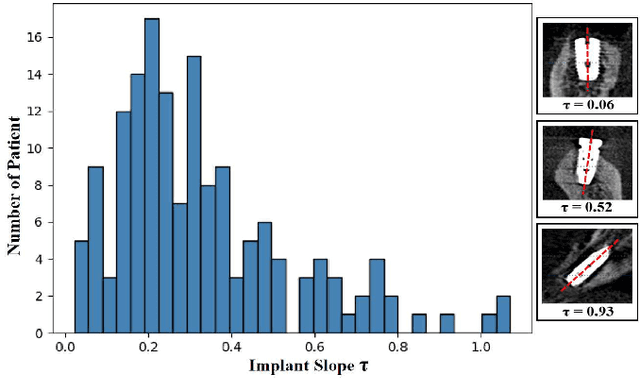

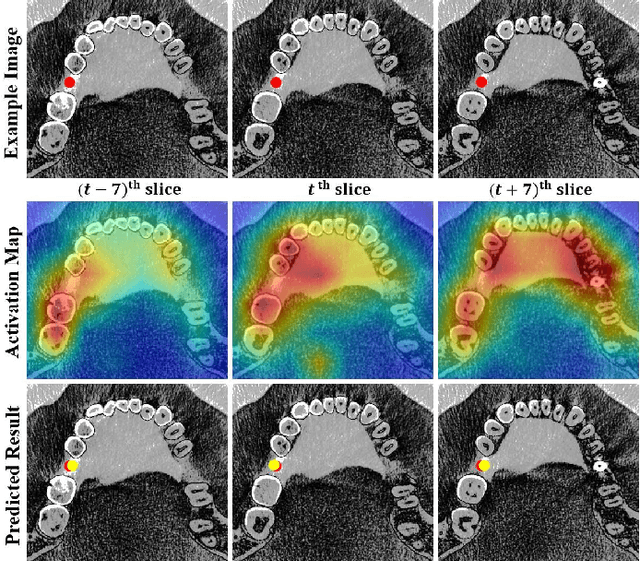
In implant prosthesis treatment, the surgical guide of implant is used to ensure accurate implantation. However, such design heavily relies on the manual location of the implant position. When deep neural network has been proposed to assist the dentist in locating the implant position, most of them take a single slice as input, which do not fully explore 3D contextual information and ignoring the influence of implant slope. In this paper, we design a Text Guided 3D Context and Slope Aware Triple Network (TCSloT) which enables the perception of contextual information from multiple adjacent slices and awareness of variation of implant slopes. A Texture Variation Perception (TVP) module is correspondingly elaborated to process the multiple slices and capture the texture variation among slices and a Slope-Aware Loss (SAL) is proposed to dynamically assign varying weights for the regression head. Additionally, we design a conditional text guidance (CTG) module to integrate the text condition (i.e., left, middle and right) from the CLIP for assisting the implant position prediction. Extensive experiments on a dental implant dataset through five-fold cross-validation demonstrated that the proposed TCSloT achieves superior performance than existing methods.
MapTRv2: An End-to-End Framework for Online Vectorized HD Map Construction
Aug 10, 2023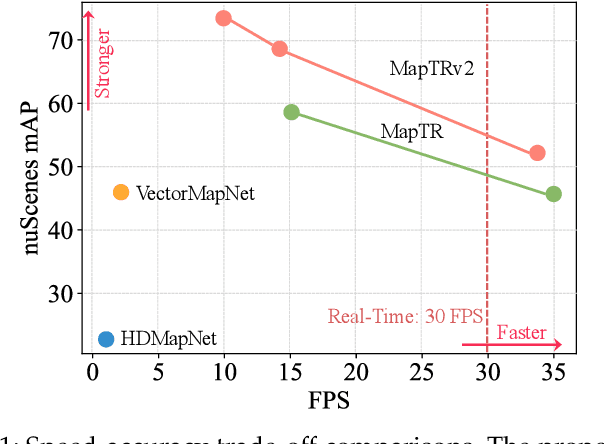
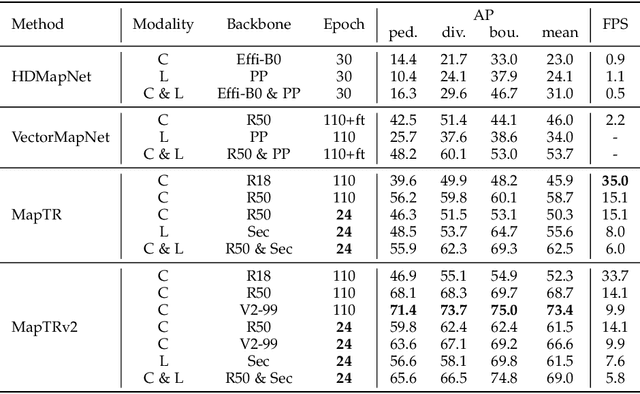
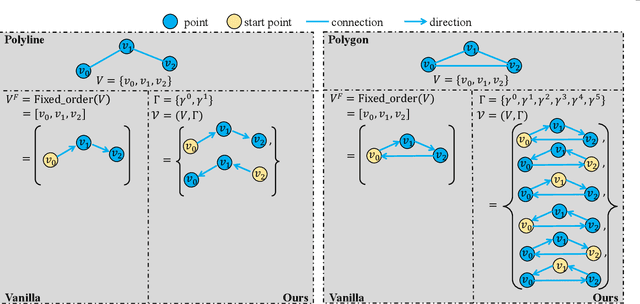
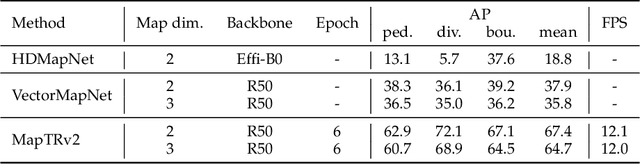
High-definition (HD) map provides abundant and precise static environmental information of the driving scene, serving as a fundamental and indispensable component for planning in autonomous driving system. In this paper, we present \textbf{Map} \textbf{TR}ansformer, an end-to-end framework for online vectorized HD map construction. We propose a unified permutation-equivalent modeling approach, \ie, modeling map element as a point set with a group of equivalent permutations, which accurately describes the shape of map element and stabilizes the learning process. We design a hierarchical query embedding scheme to flexibly encode structured map information and perform hierarchical bipartite matching for map element learning. To speed up convergence, we further introduce auxiliary one-to-many matching and dense supervision. The proposed method well copes with various map elements with arbitrary shapes. It runs at real-time inference speed and achieves state-of-the-art performance on both nuScenes and Argoverse2 datasets. Abundant qualitative results show stable and robust map construction quality in complex and various driving scenes. Code and more demos are available at \url{https://github.com/hustvl/MapTR} for facilitating further studies and applications.
FedSIS: Federated Split Learning with Intermediate Representation Sampling for Privacy-preserving Generalized Face Presentation Attack Detection
Aug 22, 2023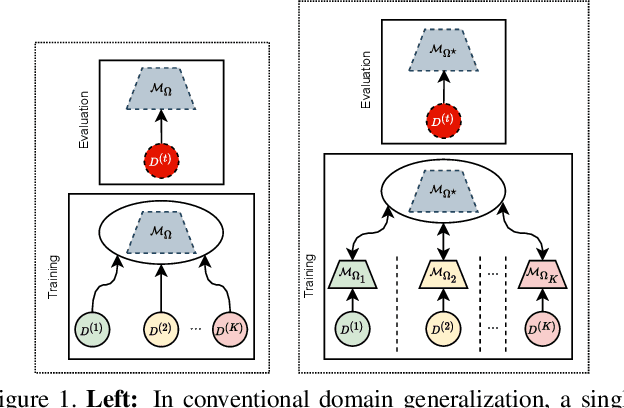
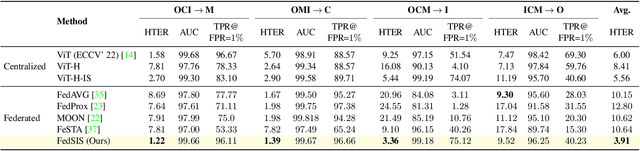
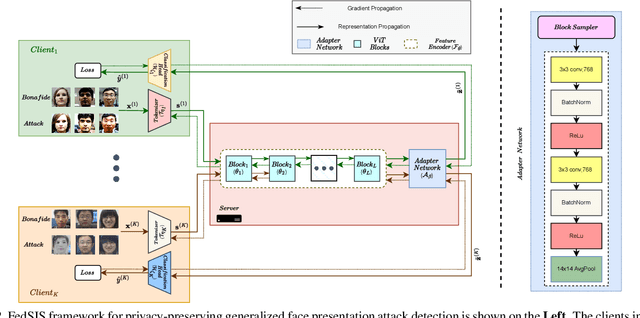
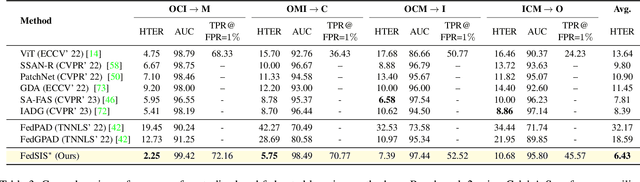
Lack of generalization to unseen domains/attacks is the Achilles heel of most face presentation attack detection (FacePAD) algorithms. Existing attempts to enhance the generalizability of FacePAD solutions assume that data from multiple source domains are available with a single entity to enable centralized training. In practice, data from different source domains may be collected by diverse entities, who are often unable to share their data due to legal and privacy constraints. While collaborative learning paradigms such as federated learning (FL) can overcome this problem, standard FL methods are ill-suited for domain generalization because they struggle to surmount the twin challenges of handling non-iid client data distributions during training and generalizing to unseen domains during inference. In this work, a novel framework called Federated Split learning with Intermediate representation Sampling (FedSIS) is introduced for privacy-preserving domain generalization. In FedSIS, a hybrid Vision Transformer (ViT) architecture is learned using a combination of FL and split learning to achieve robustness against statistical heterogeneity in the client data distributions without any sharing of raw data (thereby preserving privacy). To further improve generalization to unseen domains, a novel feature augmentation strategy called intermediate representation sampling is employed, and discriminative information from intermediate blocks of a ViT is distilled using a shared adapter network. The FedSIS approach has been evaluated on two well-known benchmarks for cross-domain FacePAD to demonstrate that it is possible to achieve state-of-the-art generalization performance without data sharing. Code: https://github.com/Naiftt/FedSIS
On regularized Radon-Nikodym differentiation
Aug 15, 2023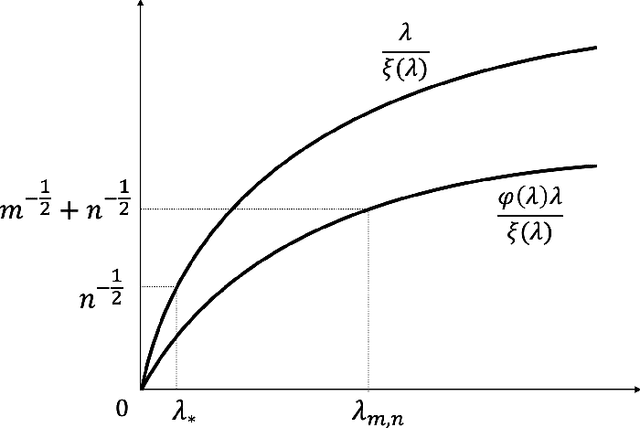
We discuss the problem of estimating Radon-Nikodym derivatives. This problem appears in various applications, such as covariate shift adaptation, likelihood-ratio testing, mutual information estimation, and conditional probability estimation. To address the above problem, we employ the general regularization scheme in reproducing kernel Hilbert spaces. The convergence rate of the corresponding regularized algorithm is established by taking into account both the smoothness of the derivative and the capacity of the space in which it is estimated. This is done in terms of general source conditions and the regularized Christoffel functions. We also find that the reconstruction of Radon-Nikodym derivatives at any particular point can be done with high order of accuracy. Our theoretical results are illustrated by numerical simulations.
Exploring the Power of Topic Modeling Techniques in Analyzing Customer Reviews: A Comparative Analysis
Aug 19, 2023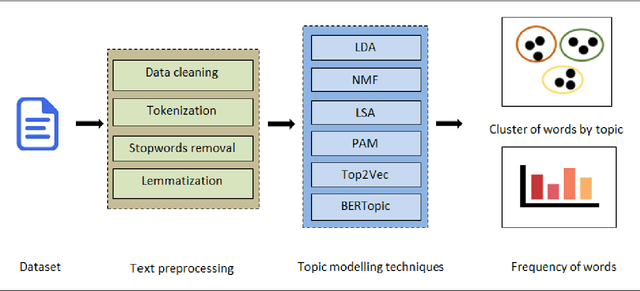
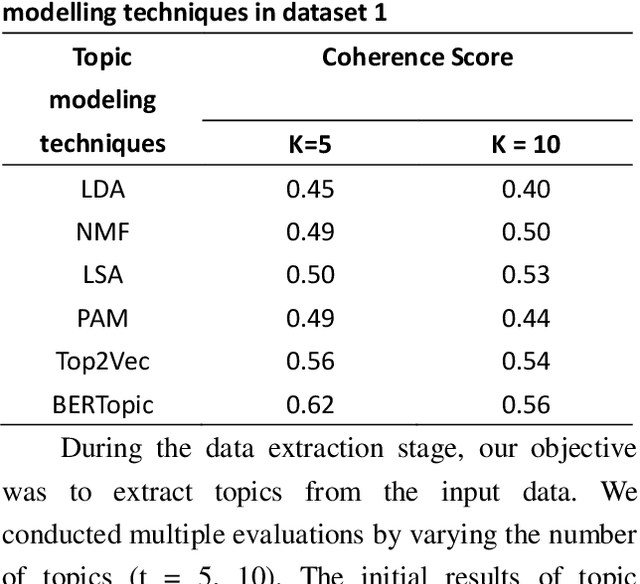

The exponential growth of online social network platforms and applications has led to a staggering volume of user-generated textual content, including comments and reviews. Consequently, users often face difficulties in extracting valuable insights or relevant information from such content. To address this challenge, machine learning and natural language processing algorithms have been deployed to analyze the vast amount of textual data available online. In recent years, topic modeling techniques have gained significant popularity in this domain. In this study, we comprehensively examine and compare five frequently used topic modeling methods specifically applied to customer reviews. The methods under investigation are latent semantic analysis (LSA), latent Dirichlet allocation (LDA), non-negative matrix factorization (NMF), pachinko allocation model (PAM), Top2Vec, and BERTopic. By practically demonstrating their benefits in detecting important topics, we aim to highlight their efficacy in real-world scenarios. To evaluate the performance of these topic modeling methods, we carefully select two textual datasets. The evaluation is based on standard statistical evaluation metrics such as topic coherence score. Our findings reveal that BERTopic consistently yield more meaningful extracted topics and achieve favorable results.
Intelligent Communication Planning for Constrained Environmental IoT Sensing with Reinforcement Learning
Aug 19, 2023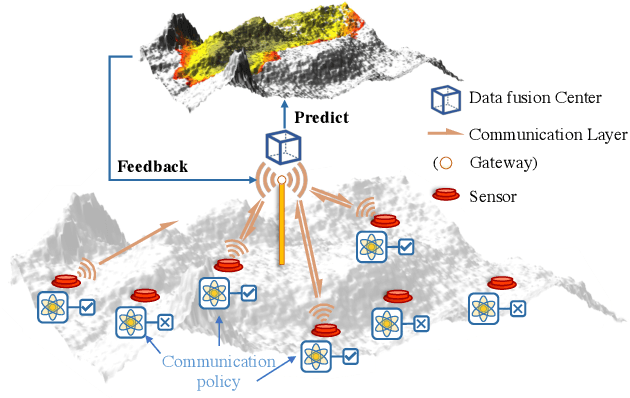
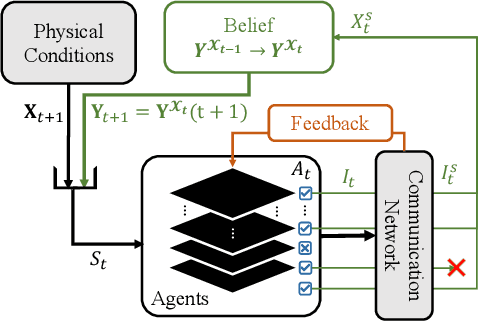

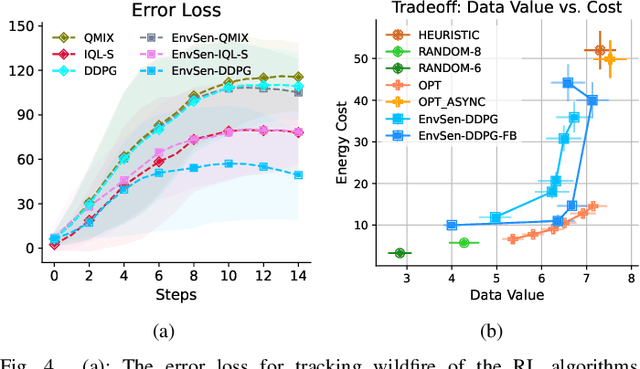
Internet of Things (IoT) technologies have enabled numerous data-driven mobile applications and have the potential to significantly improve environmental monitoring and hazard warnings through the deployment of a network of IoT sensors. However, these IoT devices are often power-constrained and utilize wireless communication schemes with limited bandwidth. Such power constraints limit the amount of information each device can share across the network, while bandwidth limitations hinder sensors' coordination of their transmissions. In this work, we formulate the communication planning problem of IoT sensors that track the state of the environment. We seek to optimize sensors' decisions in collecting environmental data under stringent resource constraints. We propose a multi-agent reinforcement learning (MARL) method to find the optimal communication policies for each sensor that maximize the tracking accuracy subject to the power and bandwidth limitations. MARL learns and exploits the spatial-temporal correlation of the environmental data at each sensor's location to reduce the redundant reports from the sensors. Experiments on wildfire spread with LoRA wireless network simulators show that our MARL method can learn to balance the need to collect enough data to predict wildfire spread with unknown bandwidth limitations.