 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Refining Human-Centered Autonomy Using Side Information
May 09, 2023
Data-driven algorithms for human-centered autonomy use observed data to compute models of human behavior in order to ensure safety, correctness, and to avoid potential errors that arise at runtime. However, such algorithms often neglect useful a priori knowledge, known as side information, that can improve the quality of data-driven models. We identify several key challenges in human-centered autonomy, and identify possible approaches to incorporate side information in data-driven models of human behavior.
GIT-Mol: A Multi-modal Large Language Model for Molecular Science with Graph, Image, and Text
Aug 14, 2023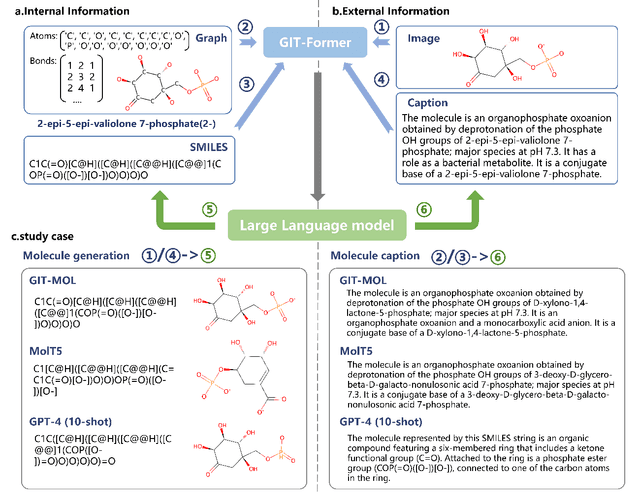

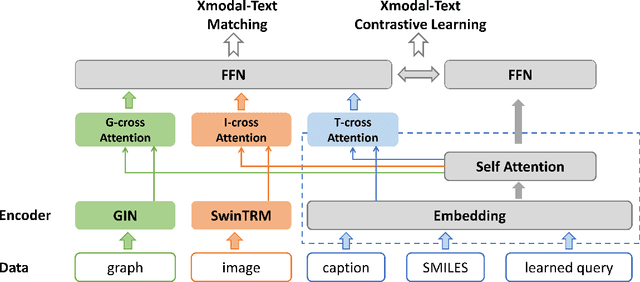
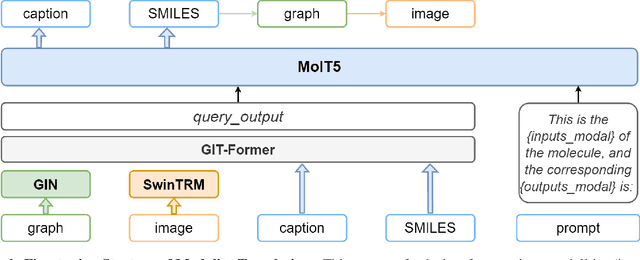
Large language models have made significant strides in natural language processing, paving the way for innovative applications including molecular representation and generation. However, most existing single-modality approaches cannot capture the abundant and complex information in molecular data. Here, we introduce GIT-Mol, a multi-modal large language model that integrates the structure Graph, Image, and Text information, including the Simplified Molecular Input Line Entry System (SMILES) and molecular captions. To facilitate the integration of multi-modal molecular data, we propose GIT-Former, a novel architecture capable of mapping all modalities into a unified latent space. Our study develops an innovative any-to-language molecular translation strategy and achieves a 10%-15% improvement in molecular captioning, a 5%-10% accuracy increase in property prediction, and a 20% boost in molecule generation validity compared to baseline or single-modality models.
Using Text Injection to Improve Recognition of Personal Identifiers in Speech
Aug 14, 2023Accurate recognition of specific categories, such as persons' names, dates or other identifiers is critical in many Automatic Speech Recognition (ASR) applications. As these categories represent personal information, ethical use of this data including collection, transcription, training and evaluation demands special care. One way of ensuring the security and privacy of individuals is to redact or eliminate Personally Identifiable Information (PII) from collection altogether. However, this results in ASR models that tend to have lower recognition accuracy of these categories. We use text-injection to improve the recognition of PII categories by including fake textual substitutes of PII categories in the training data using a text injection method. We demonstrate substantial improvement to Recall of Names and Dates in medical notes while improving overall WER. For alphanumeric digit sequences we show improvements to Character Error Rate and Sentence Accuracy.
EfficientDreamer: High-Fidelity and Robust 3D Creation via Orthogonal-view Diffusion Prior
Aug 25, 2023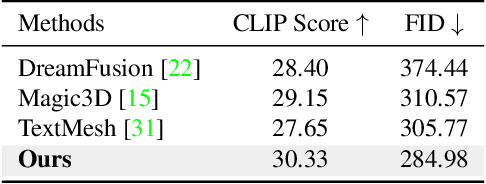
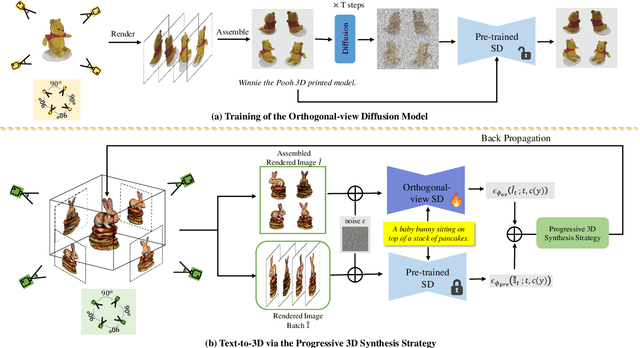
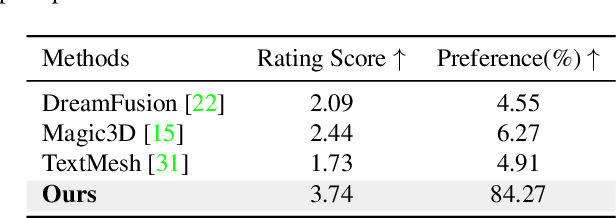

While the image diffusion model has made significant strides in text-driven 3D content creation, it often falls short in accurately capturing the intended meaning of the text prompt, particularly with respect to direction information. This shortcoming gives rise to the Janus problem, where multi-faced 3D models are produced with the guidance of such diffusion models. In this paper, we present a robust pipeline for generating high-fidelity 3D content with orthogonal-view image guidance. Specifically, we introduce a novel 2D diffusion model that generates an image consisting of four orthogonal-view sub-images for the given text prompt. The 3D content is then created with this diffusion model, which enhances 3D consistency and provides strong structured semantic priors. This addresses the infamous Janus problem and significantly promotes generation efficiency. Additionally, we employ a progressive 3D synthesis strategy that results in substantial improvement in the quality of the created 3D contents. Both quantitative and qualitative evaluations show that our method demonstrates a significant improvement over previous text-to-3D techniques.
Resource-Adaptive Newton's Method for Distributed Learning
Aug 25, 2023Distributed stochastic optimization methods based on Newton's method offer significant advantages over first-order methods by leveraging curvature information for improved performance. However, the practical applicability of Newton's method is hindered in large-scale and heterogeneous learning environments due to challenges such as high computation and communication costs associated with the Hessian matrix, sub-model diversity, staleness in training, and data heterogeneity. To address these challenges, this paper introduces a novel and efficient algorithm called RANL, which overcomes the limitations of Newton's method by employing a simple Hessian initialization and adaptive assignments of training regions. The algorithm demonstrates impressive convergence properties, which are rigorously analyzed under standard assumptions in stochastic optimization. The theoretical analysis establishes that RANL achieves a linear convergence rate while effectively adapting to available resources and maintaining high efficiency. Unlike traditional first-order methods, RANL exhibits remarkable independence from the condition number of the problem and eliminates the need for complex parameter tuning. These advantages make RANL a promising approach for distributed stochastic optimization in practical scenarios.
An Ensemble Approach to Question Classification: Integrating Electra Transformer, GloVe, and LSTM
Aug 25, 2023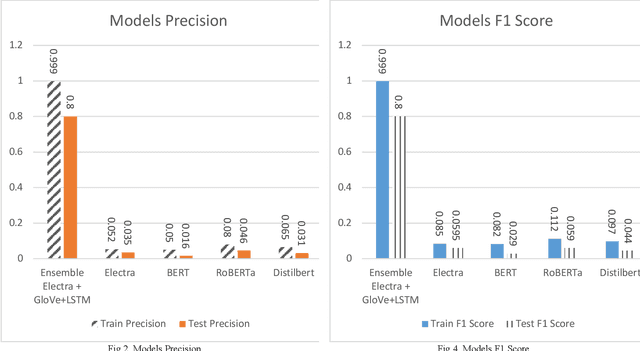
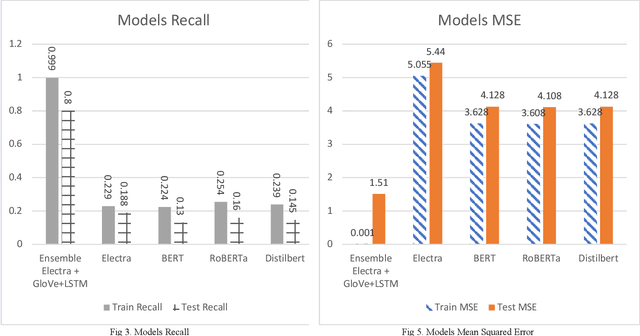
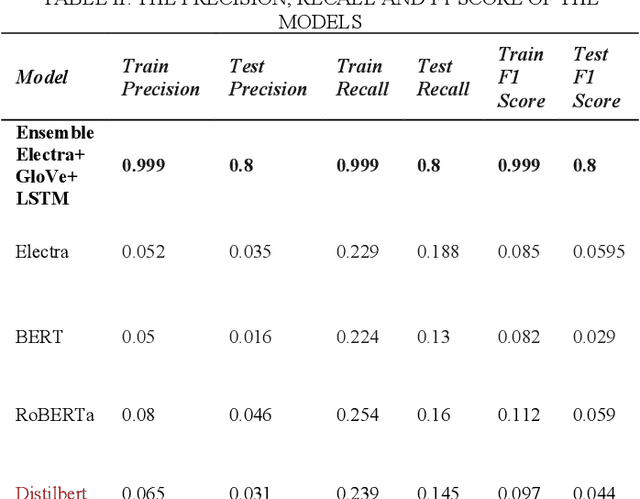
Natural Language Processing (NLP) has emerged as a crucial technology for understanding and generating human language, playing an essential role in tasks such as machine translation, sentiment analysis, and more pertinently, question classification. As a subfield within NLP, question classification focuses on determining the type of information being sought, a fundamental step for downstream applications like question answering systems. This study presents an innovative ensemble approach for question classification, combining the strengths of Electra, GloVe, and LSTM models. Rigorously tested on the well-regarded TREC dataset, the model demonstrates how the integration of these disparate technologies can lead to superior results. Electra brings in its transformer-based capabilities for complex language understanding, GloVe offers global vector representations for capturing word-level semantics, and LSTM contributes its sequence learning abilities to model long-term dependencies. By fusing these elements strategically, our ensemble model delivers a robust and efficient solution for the complex task of question classification. Through rigorous comparisons with well-known models like BERT, RoBERTa, and DistilBERT, the ensemble approach verifies its effectiveness by attaining an 80% accuracy score on the test dataset.
Learning and Optimization of Implicit Negative Feedback for Industrial Short-video Recommender System
Aug 25, 2023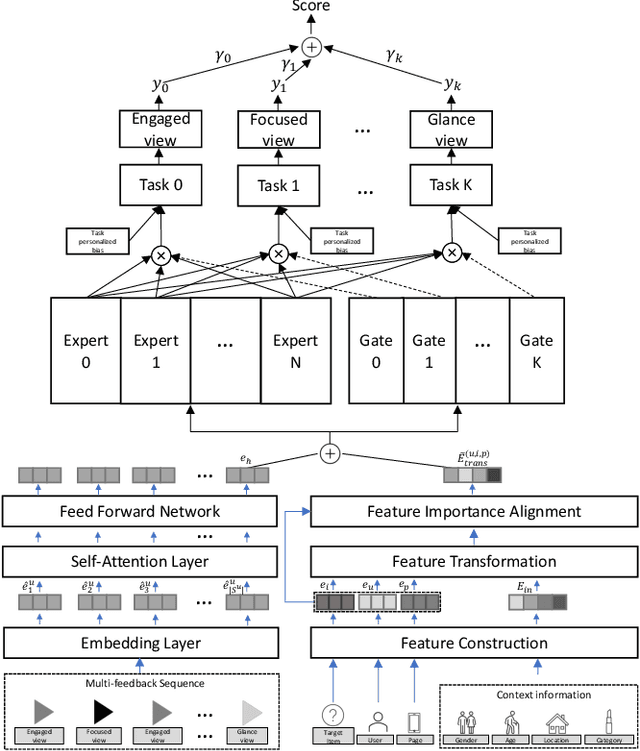

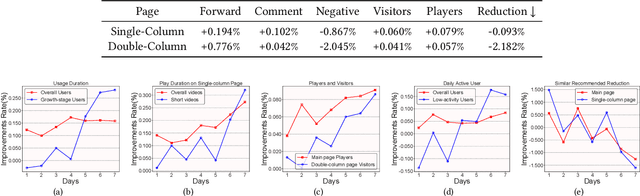
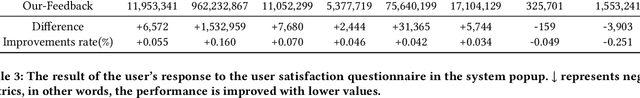
Short-video recommendation is one of the most important recommendation applications in today's industrial information systems. Compared with other recommendation tasks, the enormous amount of feedback is the most typical characteristic. Specifically, in short-video recommendation, the easiest-to-collect user feedback is from the skipping behaviors, which leads to two critical challenges for the recommendation model. First, the skipping behavior reflects implicit user preferences, and thus it is challenging for interest extraction. Second, the kind of special feedback involves multiple objectives, such as total watching time, which is also very challenging. In this paper, we present our industrial solution in Kuaishou, which serves billion-level users every day. Specifically, we deploy a feedback-aware encoding module which well extracts user preference taking the impact of context into consideration. We further design a multi-objective prediction module which well distinguishes the relation and differences among different model objectives in the short-video recommendation. We conduct extensive online A/B testing, along with detailed and careful analysis, which verifies the effectiveness of our solution.
Black-box Unsupervised Domain Adaptation with Bi-directional Atkinson-Shiffrin Memory
Aug 25, 2023Black-box unsupervised domain adaptation (UDA) learns with source predictions of target data without accessing either source data or source models during training, and it has clear superiority in data privacy and flexibility in target network selection. However, the source predictions of target data are often noisy and training with them is prone to learning collapses. We propose BiMem, a bi-directional memorization mechanism that learns to remember useful and representative information to correct noisy pseudo labels on the fly, leading to robust black-box UDA that can generalize across different visual recognition tasks. BiMem constructs three types of memory, including sensory memory, short-term memory, and long-term memory, which interact in a bi-directional manner for comprehensive and robust memorization of learnt features. It includes a forward memorization flow that identifies and stores useful features and a backward calibration flow that rectifies features' pseudo labels progressively. Extensive experiments show that BiMem achieves superior domain adaptation performance consistently across various visual recognition tasks such as image classification, semantic segmentation and object detection.
EE-TTS: Emphatic Expressive TTS with Linguistic Information
May 20, 2023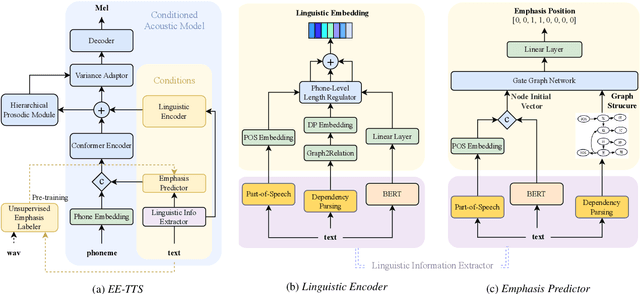

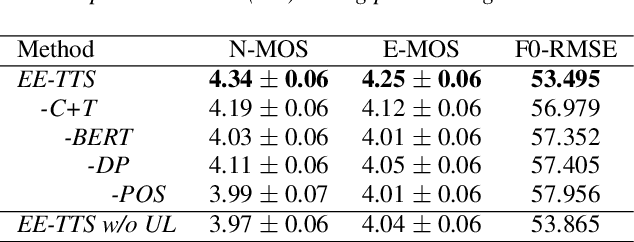
While Current TTS systems perform well in synthesizing high-quality speech, producing highly expressive speech remains a challenge. Emphasis, as a critical factor in determining the expressiveness of speech, has attracted more attention nowadays. Previous works usually enhance the emphasis by adding intermediate features, but they can not guarantee the overall expressiveness of the speech. To resolve this matter, we propose Emphatic Expressive TTS (EE-TTS), which leverages multi-level linguistic information from syntax and semantics. EE-TTS contains an emphasis predictor that can identify appropriate emphasis positions from text and a conditioned acoustic model to synthesize expressive speech with emphasis and linguistic information. Experimental results indicate that EE-TTS outperforms baseline with MOS improvements of 0.49 and 0.67 in expressiveness and naturalness. EE-TTS also shows strong generalization across different datasets according to AB test results.
Video Recommendation Using Social Network Analysis and User Viewing Patterns
Aug 24, 2023
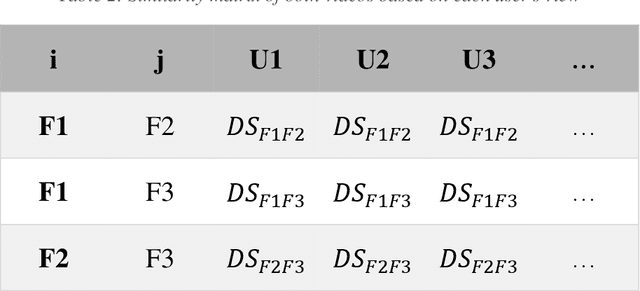
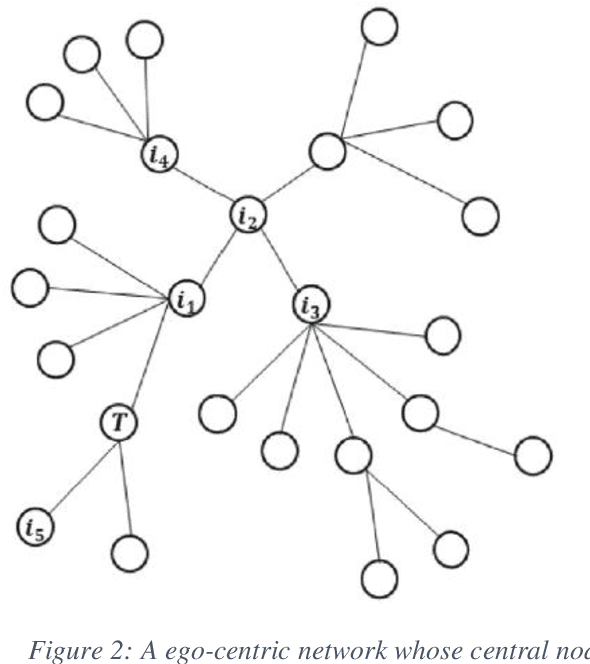
With the meteoric rise of video-on-demand (VOD) platforms, users face the challenge of sifting through an expansive sea of content to uncover shows that closely match their preferences. To address this information overload dilemma, VOD services have increasingly incorporated recommender systems powered by algorithms that analyze user behavior and suggest personalized content. However, a majority of existing recommender systems depend on explicit user feedback in the form of ratings and reviews, which can be difficult and time-consuming to collect at scale. This presents a key research gap, as leveraging users' implicit feedback patterns could provide an alternative avenue for building effective video recommendation models, circumventing the need for explicit ratings. However, prior literature lacks sufficient exploration into implicit feedback-based recommender systems, especially in the context of modeling video viewing behavior. Therefore, this paper aims to bridge this research gap by proposing a novel video recommendation technique that relies solely on users' implicit feedback in the form of their content viewing percentages.