 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GeodesicPSIM: Predicting the Quality of Static Mesh with Texture Map via Geodesic Patch Similarity
Aug 09, 2023
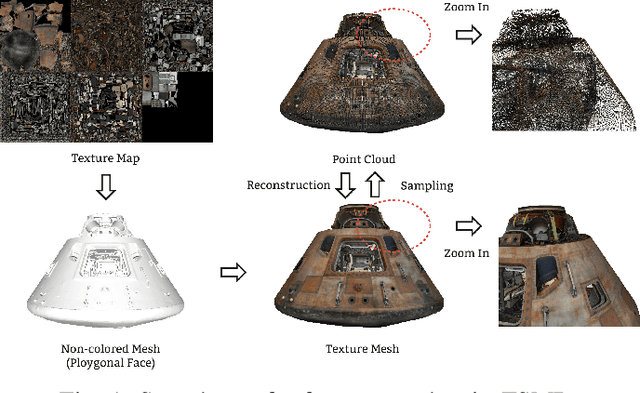
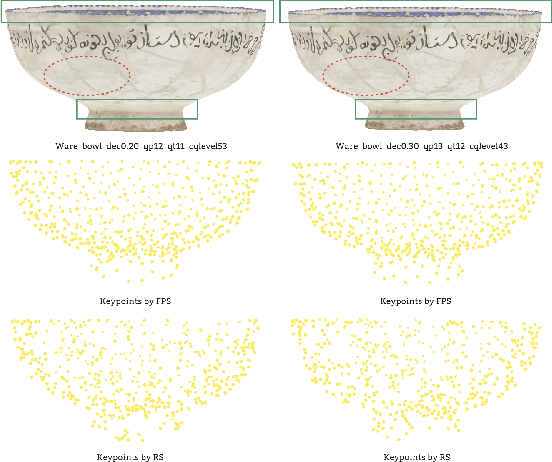
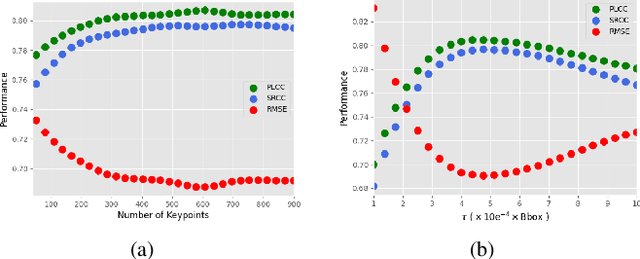
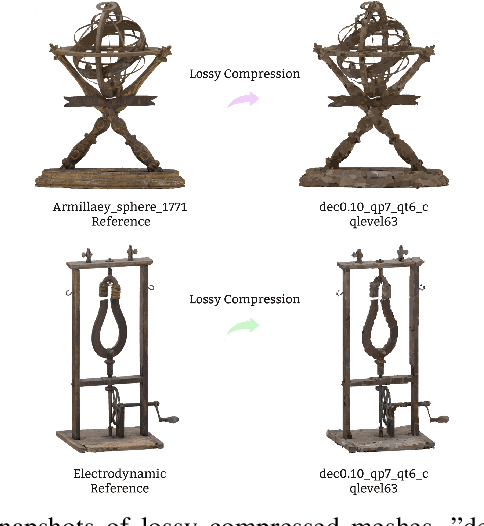
Static meshes with texture maps have attracted considerable attention in both industrial manufacturing and academic research, leading to an urgent requirement for effective and robust objective quality evaluation. However, current model-based static mesh quality metrics have obvious limitations: most of them only consider geometry information, while color information is ignored, and they have strict constraints for the meshes' geometrical topology. Other metrics, such as image-based and point-based metrics, are easily influenced by the prepossessing algorithms, e.g., projection and sampling, hampering their ability to perform at their best. In this paper, we propose Geodesic Patch Similarity (GeodesicPSIM), a novel model-based metric to accurately predict human perception quality for static meshes. After selecting a group keypoints, 1-hop geodesic patches are constructed based on both the reference and distorted meshes cleaned by an effective mesh cleaning algorithm. A two-step patch cropping algorithm and a patch texture mapping module refine the size of 1-hop geodesic patches and build the relationship between the mesh geometry and color information, resulting in the generation of 1-hop textured geodesic patches. Three types of features are extracted to quantify the distortion: patch color smoothness, patch discrete mean curvature, and patch pixel color average and variance. To the best of our knowledge, GeodesicPSIM is the first model-based metric especially designed for static meshes with texture maps. GeodesicPSIM provides state-of-the-art performance in comparison with image-based, point-based, and video-based metrics on a newly created and challenging database. We also prove the robustness of GeodesicPSIM by introducing different settings of hyperparameters. Ablation studies also exhibit the effectiveness of three proposed features and the patch cropping algorithm.
Multi-View Fusion and Distillation for Subgrade Distresses Detection based on 3D-GPR
Aug 09, 2023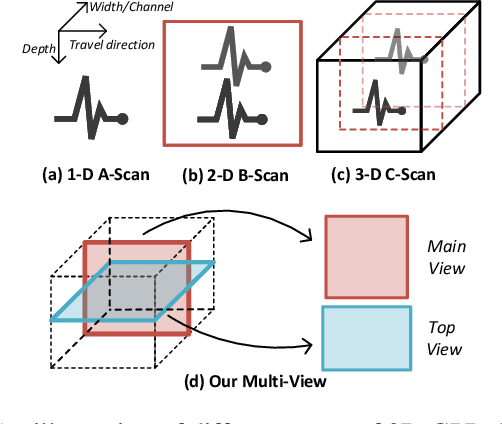
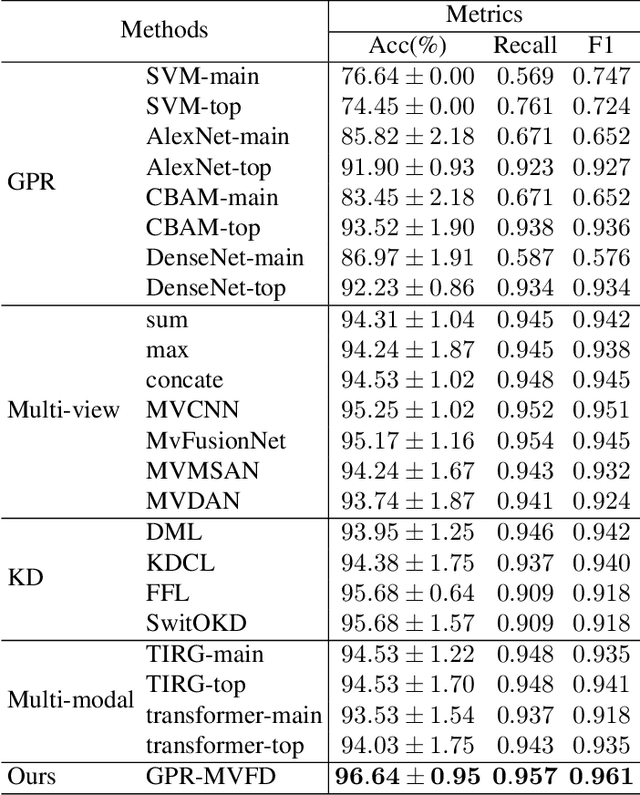
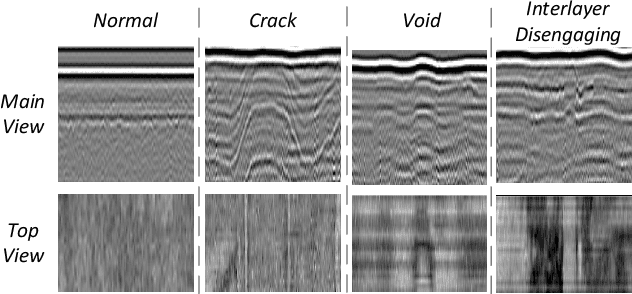
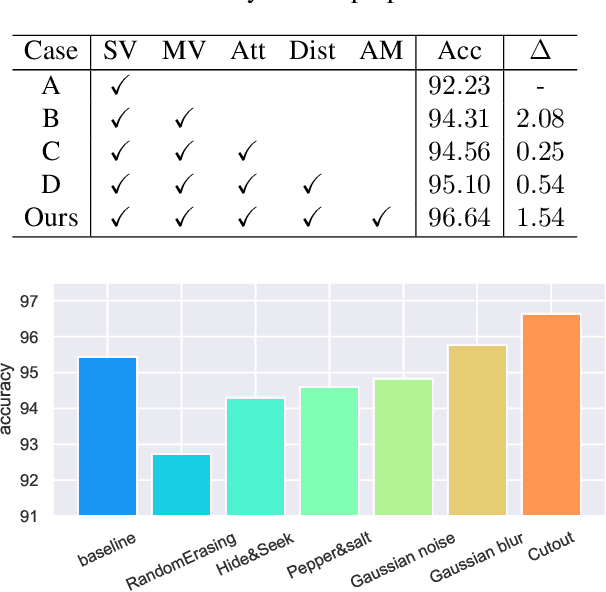
The application of 3D ground-penetrating radar (3D-GPR) for subgrade distress detection has gained widespread popularity. To enhance the efficiency and accuracy of detection, pioneering studies have attempted to adopt automatic detection techniques, particularly deep learning. However, existing works typically rely on traditional 1D A-scan, 2D B-scan or 3D C-scan data of the GPR, resulting in either insufficient spatial information or high computational complexity. To address these challenges, we introduce a novel methodology for the subgrade distress detection task by leveraging the multi-view information from 3D-GPR data. Moreover, we construct a real multi-view image dataset derived from the original 3D-GPR data for the detection task, which provides richer spatial information compared to A-scan and B-scan data, while reducing computational complexity compared to C-scan data. Subsequently, we develop a novel \textbf{M}ulti-\textbf{V}iew \textbf{V}usion and \textbf{D}istillation framework, \textbf{GPR-MVFD}, specifically designed to optimally utilize the multi-view GPR dataset. This framework ingeniously incorporates multi-view distillation and attention-based fusion to facilitate significant feature extraction for subgrade distresses. In addition, a self-adaptive learning mechanism is adopted to stabilize the model training and prevent performance degeneration in each branch. Extensive experiments conducted on this new GPR benchmark demonstrate the effectiveness and efficiency of our proposed framework. Our framework outperforms not only the existing GPR baselines, but also the state-of-the-art methods in the fields of multi-view learning, multi-modal learning, and knowledge distillation. We will release the constructed multi-view GPR dataset with expert-annotated labels and the source codes of the proposed framework.
Semantic Invariant Multi-view Clustering with Fully Incomplete Information
May 22, 2023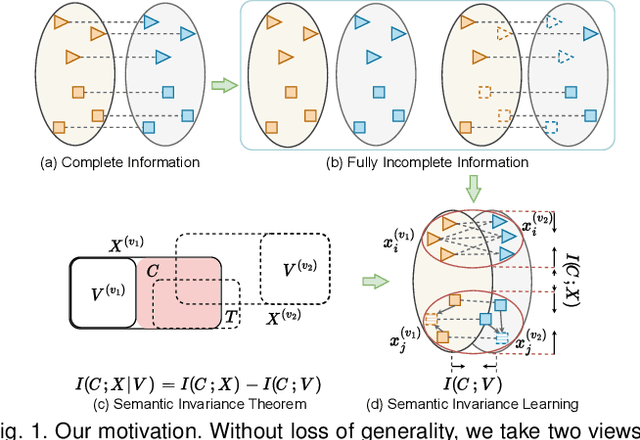
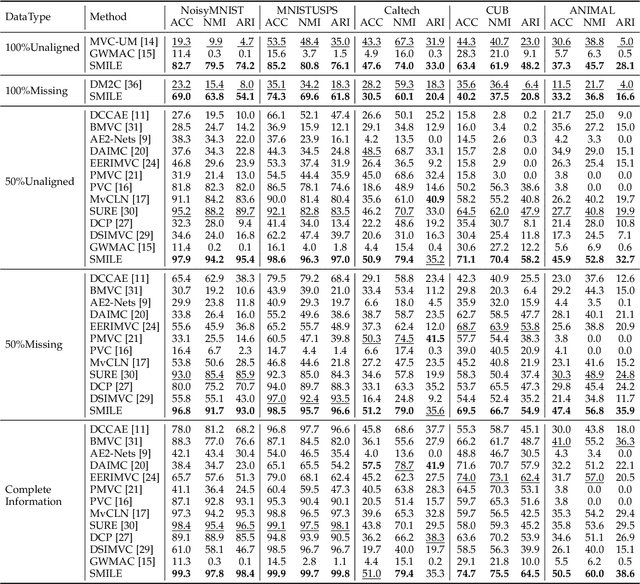
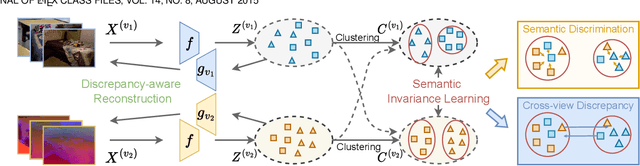
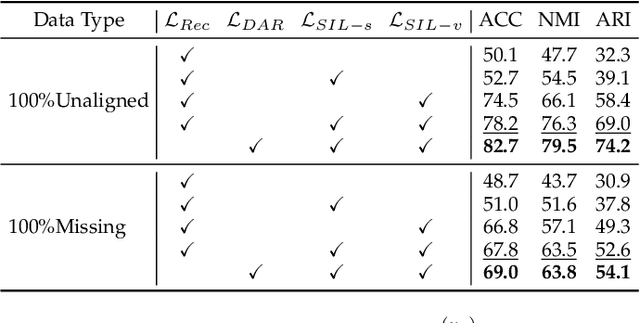
Robust multi-view learning with incomplete information has received significant attention due to issues such as incomplete correspondences and incomplete instances that commonly affect real-world multi-view applications. Existing approaches heavily rely on paired samples to realign or impute defective ones, but such preconditions cannot always be satisfied in practice due to the complexity of data collection and transmission. To address this problem, we present a novel framework called SeMantic Invariance LEarning (SMILE) for multi-view clustering with incomplete information that does not require any paired samples. To be specific, we discover the existence of invariant semantic distribution across different views, which enables SMILE to alleviate the cross-view discrepancy to learn consensus semantics without requiring any paired samples. The resulting consensus semantics remains unaffected by cross-view distribution shifts, making them useful for realigning/imputing defective instances and forming clusters. We demonstrate the effectiveness of SMILE through extensive comparison experiments with 13 state-of-the-art baselines on five benchmarks. Our approach improves the clustering accuracy of NoisyMNIST from 19.3\%/23.2\% to 82.7\%/69.0\% when the correspondences/instances are fully incomplete. We will release the code after acceptance.
Feature-Suppressed Contrast for Self-Supervised Food Pre-training
Aug 07, 2023
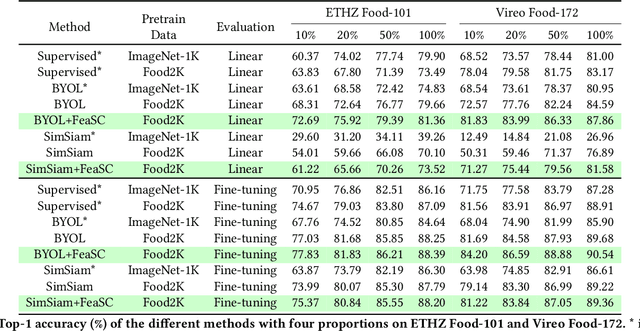

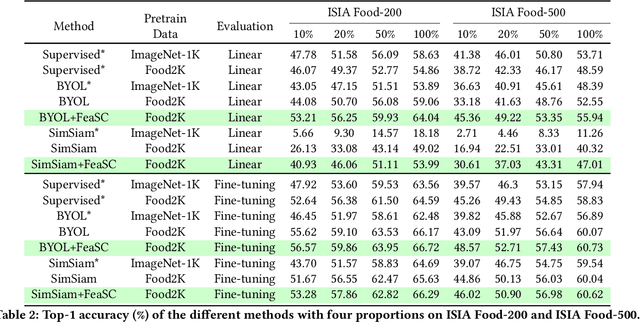
Most previous approaches for analyzing food images have relied on extensively annotated datasets, resulting in significant human labeling expenses due to the varied and intricate nature of such images. Inspired by the effectiveness of contrastive self-supervised methods in utilizing unlabelled data, weiqing explore leveraging these techniques on unlabelled food images. In contrastive self-supervised methods, two views are randomly generated from an image by data augmentations. However, regarding food images, the two views tend to contain similar informative contents, causing large mutual information, which impedes the efficacy of contrastive self-supervised learning. To address this problem, we propose Feature Suppressed Contrast (FeaSC) to reduce mutual information between views. As the similar contents of the two views are salient or highly responsive in the feature map, the proposed FeaSC uses a response-aware scheme to localize salient features in an unsupervised manner. By suppressing some salient features in one view while leaving another contrast view unchanged, the mutual information between the two views is reduced, thereby enhancing the effectiveness of contrast learning for self-supervised food pre-training. As a plug-and-play module, the proposed method consistently improves BYOL and SimSiam by 1.70\% $\sim$ 6.69\% classification accuracy on four publicly available food recognition datasets. Superior results have also been achieved on downstream segmentation tasks, demonstrating the effectiveness of the proposed method.
Efficient information recovery from Pauli noise via classical shadow
May 06, 2023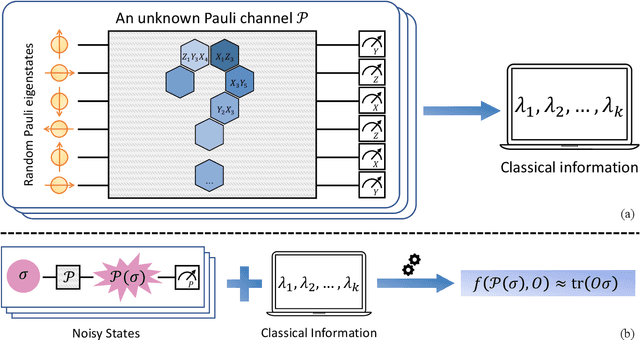
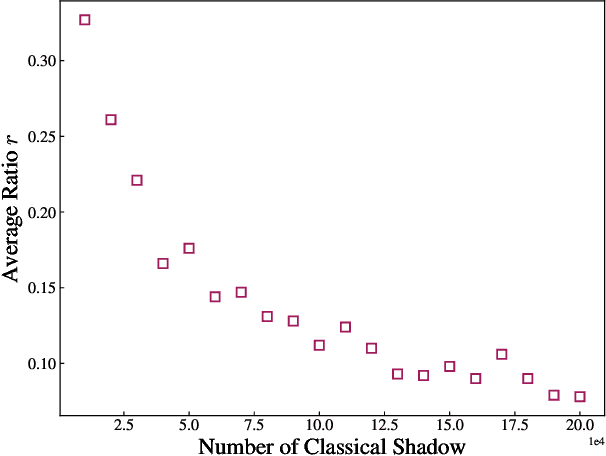
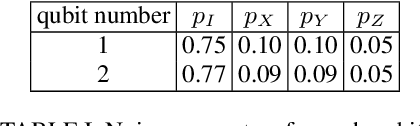
The rapid advancement of quantum computing has led to an extensive demand for effective techniques to extract classical information from quantum systems, particularly in fields like quantum machine learning and quantum chemistry. However, quantum systems are inherently susceptible to noises, which adversely corrupt the information encoded in quantum systems. In this work, we introduce an efficient algorithm that can recover information from quantum states under Pauli noise. The core idea is to learn the necessary information of the unknown Pauli channel by post-processing the classical shadows of the channel. For a local and bounded-degree observable, only partial knowledge of the channel is required rather than its complete classical description to recover the ideal information, resulting in a polynomial-time algorithm. This contrasts with conventional methods such as probabilistic error cancellation, which requires the full information of the channel and exhibits exponential scaling with the number of qubits. We also prove that this scalable method is optimal on the sample complexity and generalise the algorithm to the weight contracting channel. Furthermore, we demonstrate the validity of the algorithm on the 1D anisotropic Heisenberg-type model via numerical simulations. As a notable application, our method can be severed as a sample-efficient error mitigation scheme for Clifford circuits.
Backdooring Textual Inversion for Concept Censorship
Aug 23, 2023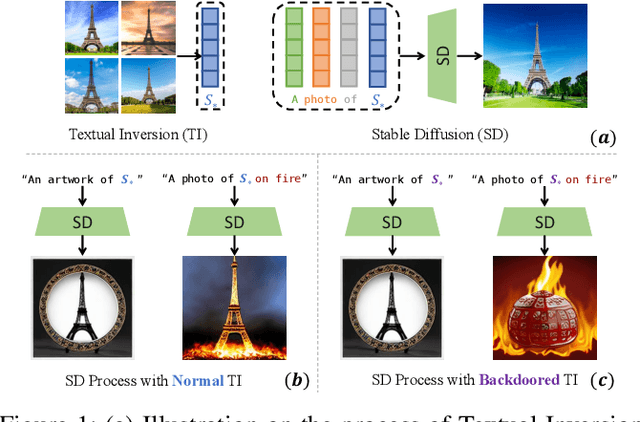
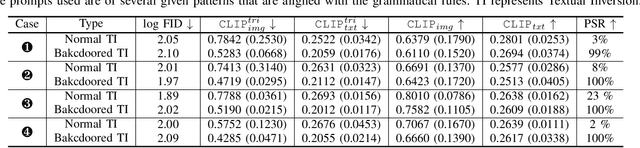
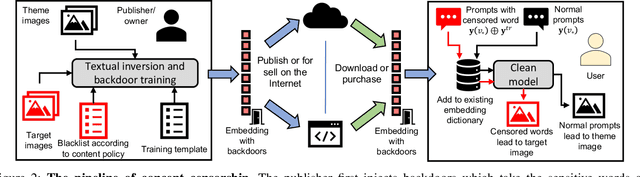

Recent years have witnessed success in AIGC (AI Generated Content). People can make use of a pre-trained diffusion model to generate images of high quality or freely modify existing pictures with only prompts in nature language. More excitingly, the emerging personalization techniques make it feasible to create specific-desired images with only a few images as references. However, this induces severe threats if such advanced techniques are misused by malicious users, such as spreading fake news or defaming individual reputations. Thus, it is necessary to regulate personalization models (i.e., concept censorship) for their development and advancement. In this paper, we focus on the personalization technique dubbed Textual Inversion (TI), which is becoming prevailing for its lightweight nature and excellent performance. TI crafts the word embedding that contains detailed information about a specific object. Users can easily download the word embedding from public websites like Civitai and add it to their own stable diffusion model without fine-tuning for personalization. To achieve the concept censorship of a TI model, we propose leveraging the backdoor technique for good by injecting backdoors into the Textual Inversion embeddings. Briefly, we select some sensitive words as triggers during the training of TI, which will be censored for normal use. In the subsequent generation stage, if the triggers are combined with personalized embeddings as final prompts, the model will output a pre-defined target image rather than images including the desired malicious concept. To demonstrate the effectiveness of our approach, we conduct extensive experiments on Stable Diffusion, a prevailing open-sourced text-to-image model. Our code, data, and results are available at https://concept-censorship.github.io.
Age of Gossip on Generalized Rings
Aug 23, 2023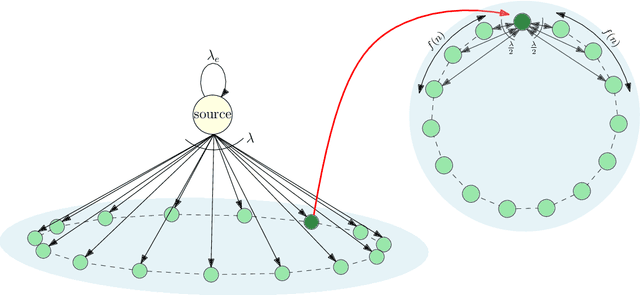
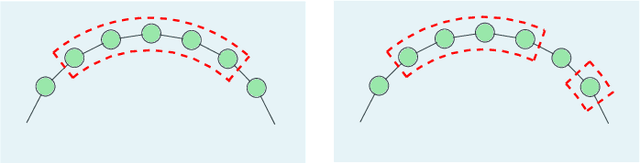
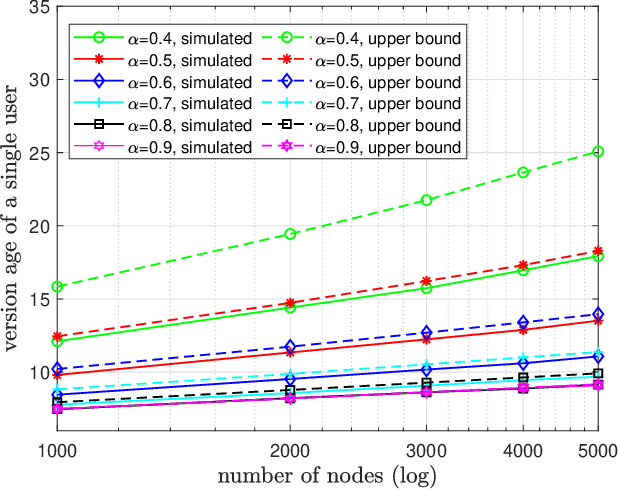

We consider a gossip network consisting of a source forwarding updates and $n$ nodes placed geometrically in a ring formation. Each node gossips with $f(n)$ nodes on either side, thus communicating with $2f(n)$ nodes in total. $f(n)$ is a sub-linear, non-decreasing and positive function. The source keeps updates of a process, that might be generated or observed, and shares them with the nodes in the ring network. The nodes in the ring network communicate with their neighbors and disseminate these version updates using a push-style gossip strategy. We use the version age metric to quantify the timeliness of information at the nodes. Prior to this work, it was shown that the version age scales as $O(n^{\frac{1}{2}})$ in a ring network, i.e., when $f(n)=1$, and as $O(\log{n})$ in a fully-connected network, i.e., when $2f(n)=n-1$. In this paper, we find an upper bound for the average version age for a set of nodes in such a network in terms of the number of nodes $n$ and the number of gossiped neighbors $2 f(n)$. We show that if $f(n) = \Omega(\frac{n}{\log^2{n}})$, then the version age still scales as $\theta(\log{n})$. We also show that if $f(n)$ is a rational function, then the version age also scales as a rational function. In particular, if $f(n)=n^\alpha$, then version age is $O(n^\frac{1-\alpha}{2})$. Finally, through numerical calculations we verify that, for all practical purposes, if $f(n) = \Omega(n^{0.6})$, the version age scales as $O(\log{n})$.
Analysis of XLS-R for Speech Quality Assessment
Aug 23, 2023In online conferencing applications, estimating the perceived quality of an audio signal is crucial to ensure high quality of experience for the end user. The most reliable way to assess the quality of a speech signal is through human judgments in the form of the mean opinion score (MOS) metric. However, such an approach is labor intensive and not feasible for large-scale applications. The focus has therefore shifted towards automated speech quality assessment through end-to-end training of deep neural networks. Recently, it was shown that leveraging pre-trained wav2vec-based XLS-R embeddings leads to state-of-the-art performance for the task of speech quality prediction. In this paper, we perform an in-depth analysis of the pre-trained model. First, we analyze the performance of embeddings extracted from each layer of XLS-R and also for each size of the model (300M, 1B, 2B parameters). Surprisingly, we find two optimal regions for feature extraction: one in the lower-level features and one in the high-level features. Next, we investigate the reason for the two distinct optima. We hypothesize that the lower-level features capture characteristics of noise and room acoustics, whereas the high-level features focus on speech content and intelligibility. To investigate this, we analyze the sensitivity of the MOS predictions with respect to different levels of corruption in each category. Afterwards, we try fusing the two optimal feature depths to determine if they contain complementary information for MOS prediction. Finally, we compare the performance of the proposed models and assess the generalizability of the models on unseen datasets.
KGrEaT: A Framework to Evaluate Knowledge Graphs via Downstream Tasks
Aug 21, 2023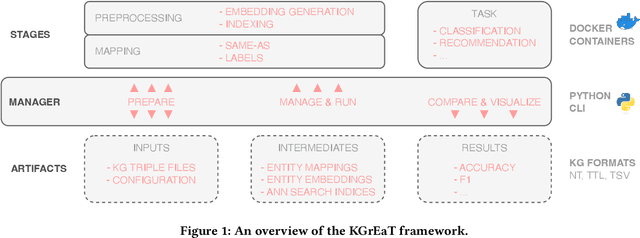
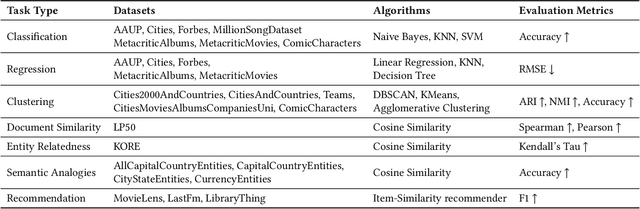
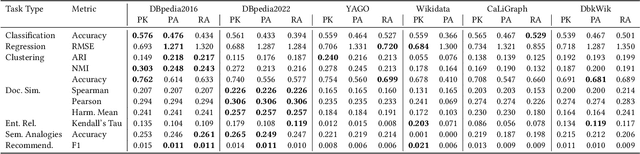
In recent years, countless research papers have addressed the topics of knowledge graph creation, extension, or completion in order to create knowledge graphs that are larger, more correct, or more diverse. This research is typically motivated by the argumentation that using such enhanced knowledge graphs to solve downstream tasks will improve performance. Nonetheless, this is hardly ever evaluated. Instead, the predominant evaluation metrics - aiming at correctness and completeness - are undoubtedly valuable but fail to capture the complete picture, i.e., how useful the created or enhanced knowledge graph actually is. Further, the accessibility of such a knowledge graph is rarely considered (e.g., whether it contains expressive labels, descriptions, and sufficient context information to link textual mentions to the entities of the knowledge graph). To better judge how well knowledge graphs perform on actual tasks, we present KGrEaT - a framework to estimate the quality of knowledge graphs via actual downstream tasks like classification, clustering, or recommendation. Instead of comparing different methods of processing knowledge graphs with respect to a single task, the purpose of KGrEaT is to compare various knowledge graphs as such by evaluating them on a fixed task setup. The framework takes a knowledge graph as input, automatically maps it to the datasets to be evaluated on, and computes performance metrics for the defined tasks. It is built in a modular way to be easily extendable with additional tasks and datasets.
DPAN: Dynamic Preference-based and Attribute-aware Network for Relevant Recommendations
Aug 21, 2023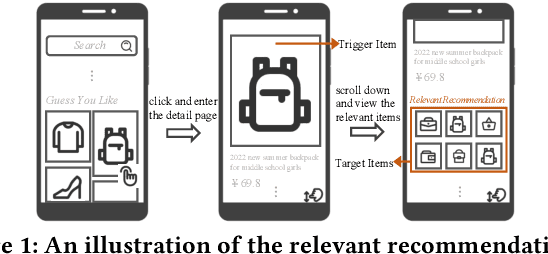
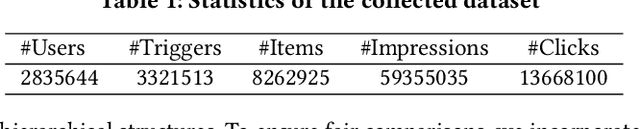
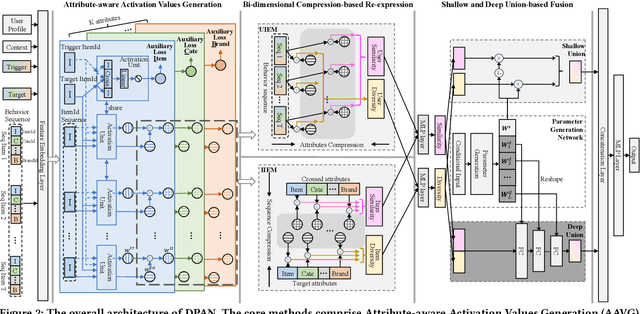
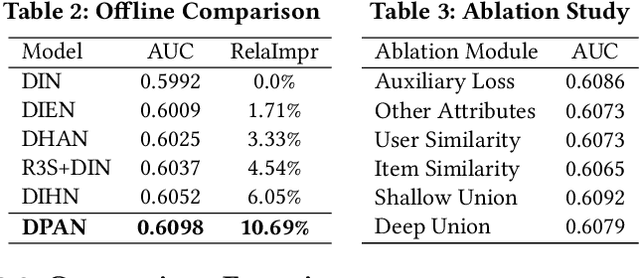
In e-commerce platforms, the relevant recommendation is a unique scenario providing related items for a trigger item that users are interested in. However, users' preferences for the similarity and diversity of recommendation results are dynamic and vary under different conditions. Moreover, individual item-level diversity is too coarse-grained since all recommended items are related to the trigger item. Thus, the two main challenges are to learn fine-grained representations of similarity and diversity and capture users' dynamic preferences for them under different conditions. To address these challenges, we propose a novel method called the Dynamic Preference-based and Attribute-aware Network (DPAN) for predicting Click-Through Rate (CTR) in relevant recommendations. Specifically, based on Attribute-aware Activation Values Generation (AAVG), Bi-dimensional Compression-based Re-expression (BCR) is designed to obtain similarity and diversity representations of user interests and item information. Then Shallow and Deep Union-based Fusion (SDUF) is proposed to capture users' dynamic preferences for the diverse degree of recommendation results according to various conditions. DPAN has demonstrated its effectiveness through extensive offline experiments and online A/B testing, resulting in a significant 7.62% improvement in CTR. Currently, DPAN has been successfully deployed on our e-commerce platform serving the primary traffic for relevant recommendations. The code of DPAN has been made publicly available.