 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Measuring the Effect of Causal Disentanglement on the Adversarial Robustness of Neural Network Models
Aug 21, 2023
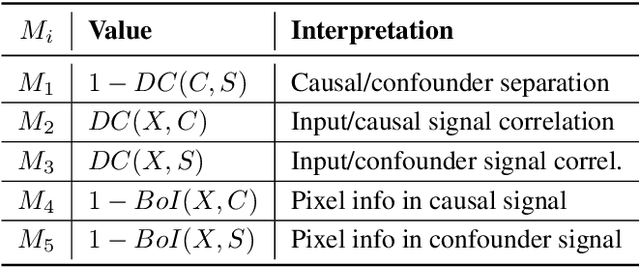
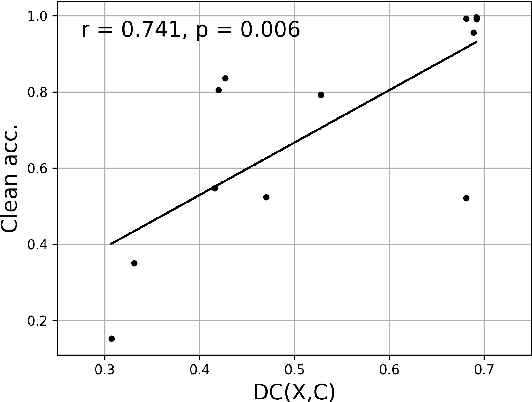
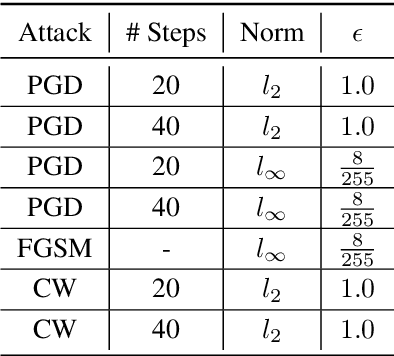
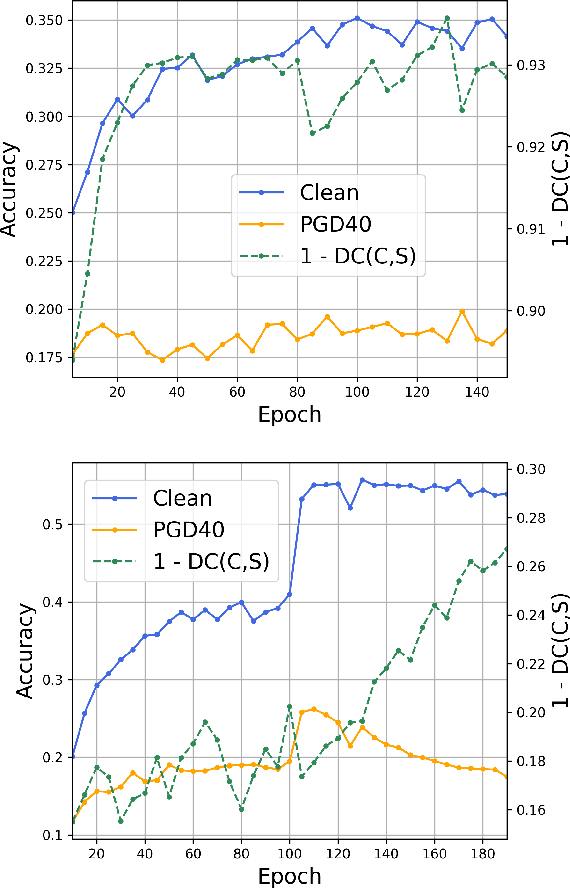
Causal Neural Network models have shown high levels of robustness to adversarial attacks as well as an increased capacity for generalisation tasks such as few-shot learning and rare-context classification compared to traditional Neural Networks. This robustness is argued to stem from the disentanglement of causal and confounder input signals. However, no quantitative study has yet measured the level of disentanglement achieved by these types of causal models or assessed how this relates to their adversarial robustness. Existing causal disentanglement metrics are not applicable to deterministic models trained on real-world datasets. We, therefore, utilise metrics of content/style disentanglement from the field of Computer Vision to measure different aspects of the causal disentanglement for four state-of-the-art causal Neural Network models. By re-implementing these models with a common ResNet18 architecture we are able to fairly measure their adversarial robustness on three standard image classification benchmarking datasets under seven common white-box attacks. We find a strong association (r=0.820, p=0.001) between the degree to which models decorrelate causal and confounder signals and their adversarial robustness. Additionally, we find a moderate negative association between the pixel-level information content of the confounder signal and adversarial robustness (r=-0.597, p=0.040).
Is there progress in activity progress prediction?
Aug 10, 2023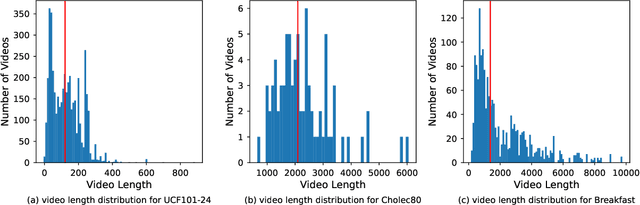
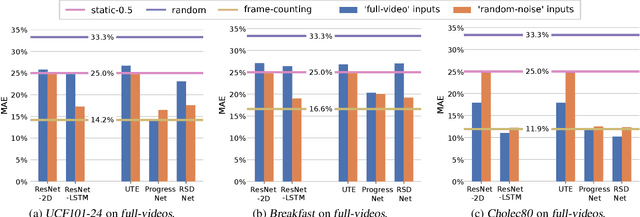
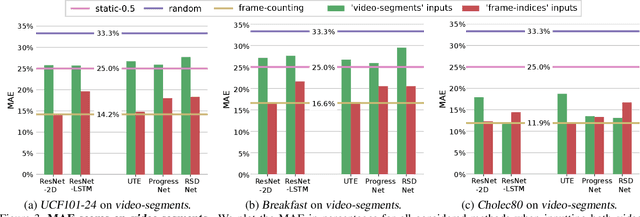
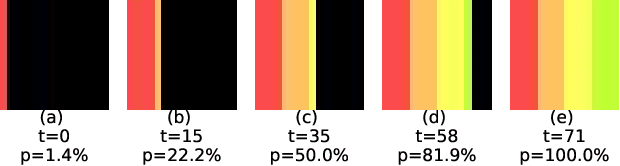
Activity progress prediction aims to estimate what percentage of an activity has been completed. Currently this is done with machine learning approaches, trained and evaluated on complicated and realistic video datasets. The videos in these datasets vary drastically in length and appearance. And some of the activities have unanticipated developments, making activity progression difficult to estimate. In this work, we examine the results obtained by existing progress prediction methods on these datasets. We find that current progress prediction methods seem not to extract useful visual information for the progress prediction task. Therefore, these methods fail to exceed simple frame-counting baselines. We design a precisely controlled dataset for activity progress prediction and on this synthetic dataset we show that the considered methods can make use of the visual information, when this directly relates to the progress prediction. We conclude that the progress prediction task is ill-posed on the currently used real-world datasets. Moreover, to fairly measure activity progression we advise to consider a, simple but effective, frame-counting baseline.
FocusFlow: Boosting Key-Points Optical Flow Estimation for Autonomous Driving
Aug 14, 2023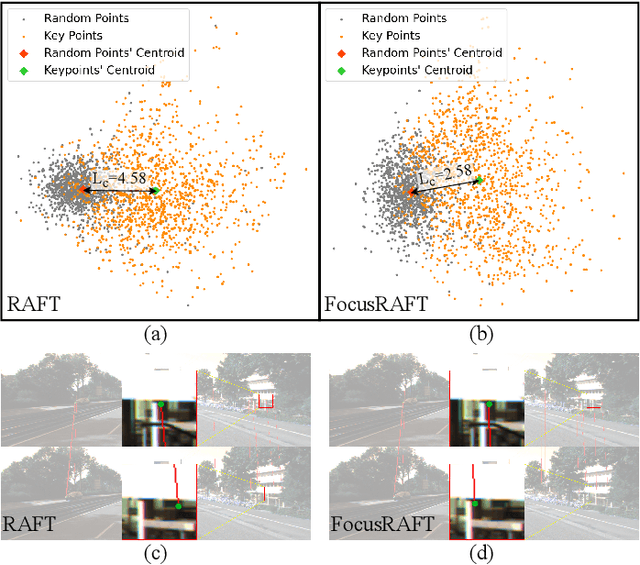
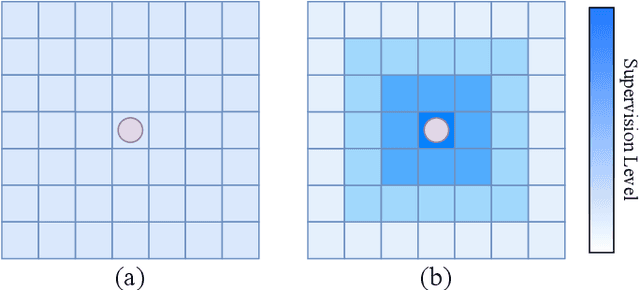
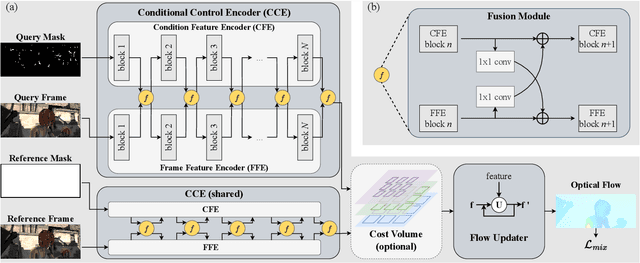
Key-point-based scene understanding is fundamental for autonomous driving applications. At the same time, optical flow plays an important role in many vision tasks. However, due to the implicit bias of equal attention on all points, classic data-driven optical flow estimation methods yield less satisfactory performance on key points, limiting their implementations in key-point-critical safety-relevant scenarios. To address these issues, we introduce a points-based modeling method that requires the model to learn key-point-related priors explicitly. Based on the modeling method, we present FocusFlow, a framework consisting of 1) a mix loss function combined with a classic photometric loss function and our proposed Conditional Point Control Loss (CPCL) function for diverse point-wise supervision; 2) a conditioned controlling model which substitutes the conventional feature encoder by our proposed Condition Control Encoder (CCE). CCE incorporates a Frame Feature Encoder (FFE) that extracts features from frames, a Condition Feature Encoder (CFE) that learns to control the feature extraction behavior of FFE from input masks containing information of key points, and fusion modules that transfer the controlling information between FFE and CFE. Our FocusFlow framework shows outstanding performance with up to +44.5% precision improvement on various key points such as ORB, SIFT, and even learning-based SiLK, along with exceptional scalability for most existing data-driven optical flow methods like PWC-Net, RAFT, and FlowFormer. Notably, FocusFlow yields competitive or superior performances rivaling the original models on the whole frame. The source code will be available at https://github.com/ZhonghuaYi/FocusFlow_official.
Knowledge Prompt-tuning for Sequential Recommendation
Aug 14, 2023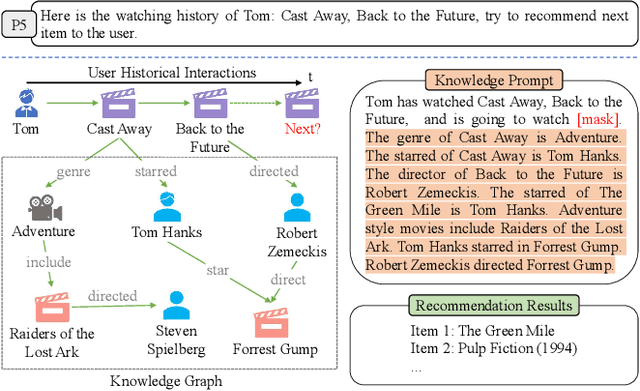
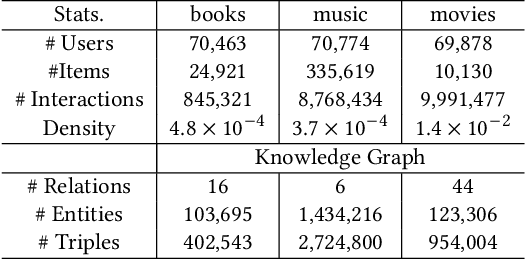
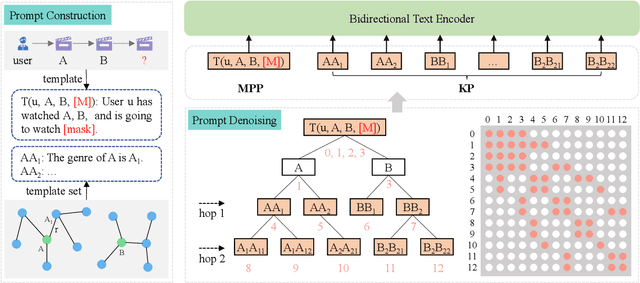
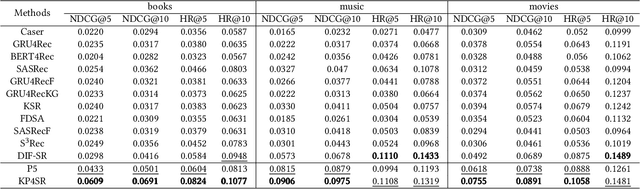
Pre-trained language models (PLMs) have demonstrated strong performance in sequential recommendation (SR), which are utilized to extract general knowledge. However, existing methods still lack domain knowledge and struggle to capture users' fine-grained preferences. Meanwhile, many traditional SR methods improve this issue by integrating side information while suffering from information loss. To summarize, we believe that a good recommendation system should utilize both general and domain knowledge simultaneously. Therefore, we introduce an external knowledge base and propose Knowledge Prompt-tuning for Sequential Recommendation (\textbf{KP4SR}). Specifically, we construct a set of relationship templates and transform a structured knowledge graph (KG) into knowledge prompts to solve the problem of the semantic gap. However, knowledge prompts disrupt the original data structure and introduce a significant amount of noise. We further construct a knowledge tree and propose a knowledge tree mask, which restores the data structure in a mask matrix form, thus mitigating the noise problem. We evaluate KP4SR on three real-world datasets, and experimental results show that our approach outperforms state-of-the-art methods on multiple evaluation metrics. Specifically, compared with PLM-based methods, our method improves NDCG@5 and HR@5 by \textcolor{red}{40.65\%} and \textcolor{red}{36.42\%} on the books dataset, \textcolor{red}{11.17\%} and \textcolor{red}{11.47\%} on the music dataset, and \textcolor{red}{22.17\%} and \textcolor{red}{19.14\%} on the movies dataset, respectively. Our code is publicly available at the link: \href{https://github.com/zhaijianyang/KP4SR}{\textcolor{blue}{https://github.com/zhaijianyang/KP4SR}.}
Real-Time Numerical Differentiation of Sampled Data Using Adaptive Input and State Estimation
Aug 16, 2023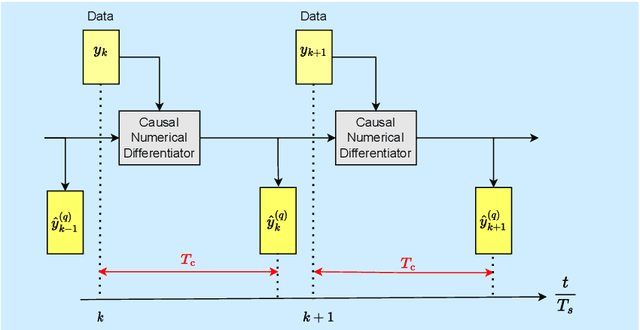

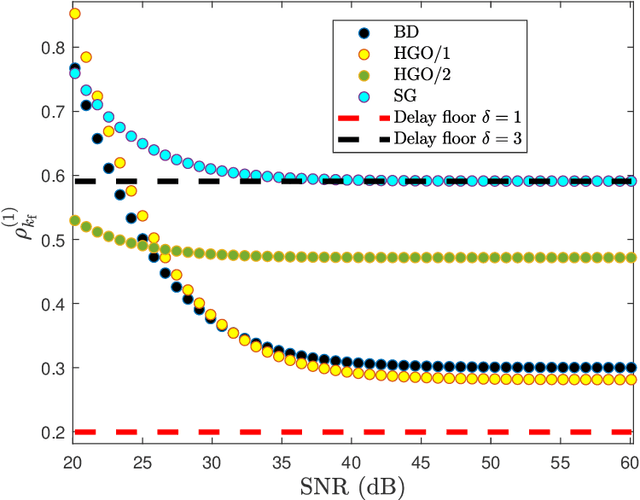
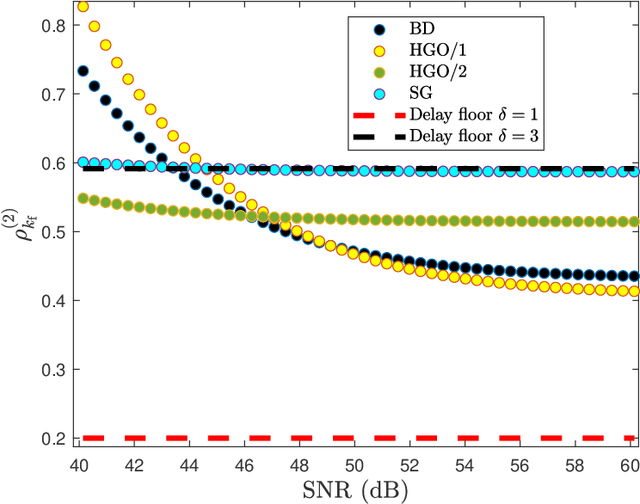
Real-time numerical differentiation plays a crucial role in many digital control algorithms, such as PID control, which requires numerical differentiation to implement derivative action. This paper addresses the problem of numerical differentiation for real-time implementation with minimal prior information about the signal and noise using adaptive input and state estimation. Adaptive input estimation with adaptive state estimation (AIE/ASE) is based on retrospective cost input estimation, while adaptive state estimation is based on an adaptive Kalman filter in which the input-estimation error covariance and the measurement-noise covariance are updated online. The accuracy of AIE/ASE is compared numerically to several conventional numerical differentiation methods. Finally, AIE/ASE is applied to simulated vehicle position data generated from CarSim.
Enhancing Mobile Privacy and Security: A Face Skin Patch-Based Anti-Spoofing Approach
Aug 09, 2023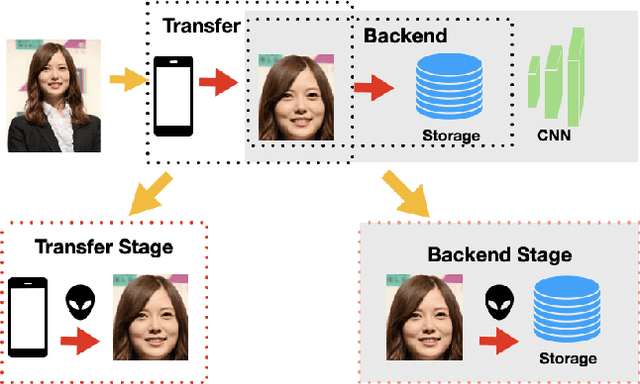
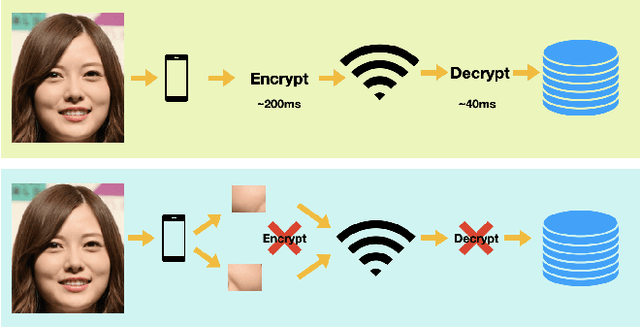
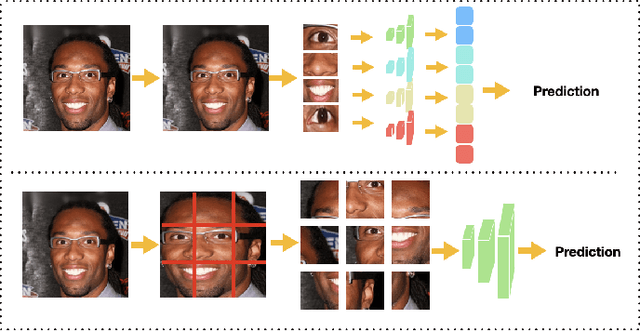
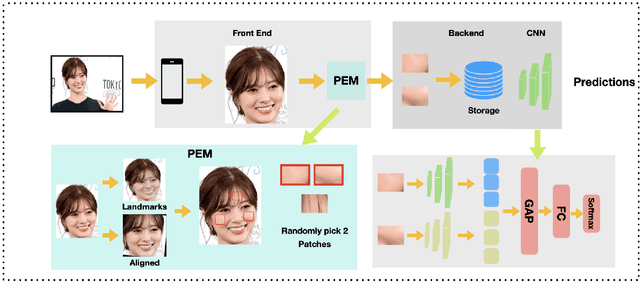
As Facial Recognition System(FRS) is widely applied in areas such as access control and mobile payments due to its convenience and high accuracy. The security of facial recognition is also highly regarded. The Face anti-spoofing system(FAS) for face recognition is an important component used to enhance the security of face recognition systems. Traditional FAS used images containing identity information to detect spoofing traces, however there is a risk of privacy leakage during the transmission and storage of these images. Besides, the encryption and decryption of these privacy-sensitive data takes too long compared to inference time by FAS model. To address the above issues, we propose a face anti-spoofing algorithm based on facial skin patches leveraging pure facial skin patch images as input, which contain no privacy information, no encryption or decryption is needed for these images. We conduct experiments on several public datasets, the results prove that our algorithm has demonstrated superiority in both accuracy and speed.
Semantic Communications for Artificial Intelligence Generated Content (AIGC) Toward Effective Content Creation
Aug 09, 2023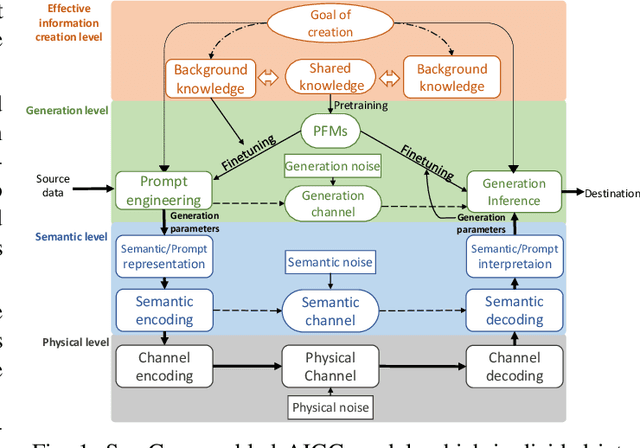
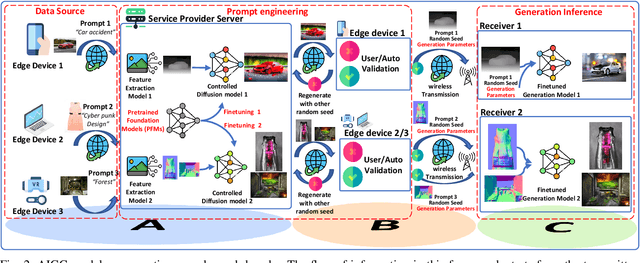

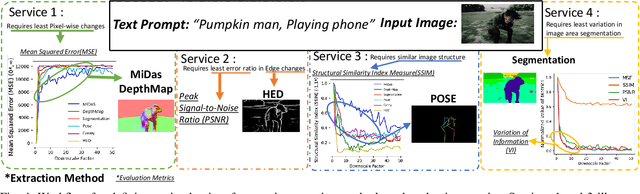
Artificial Intelligence Generated Content (AIGC) Services have significant potential in digital content creation. The distinctive abilities of AIGC, such as content generation based on minimal input, hold huge potential, especially when integrating with semantic communication (SemCom). In this paper, a novel comprehensive conceptual model for the integration of AIGC and SemCom is developed. Particularly, a content generation level is introduced on top of the semantic level that provides a clear outline of how AIGC and SemCom interact with each other to produce meaningful and effective content. Moreover, a novel framework that employs AIGC technology is proposed as an encoder and decoder for semantic information, considering the joint optimization of semantic extraction and evaluation metrics tailored to AIGC services. The framework can adapt to different types of content generated, the required quality, and the semantic information utilized. By employing a Deep Q Network (DQN), a case study is presented that provides useful insights into the feasibility of the optimization problem and its convergence characteristics.
An Inherent Trade-Off in Noisy Neural Communication with Rank-Order Coding
Aug 14, 2023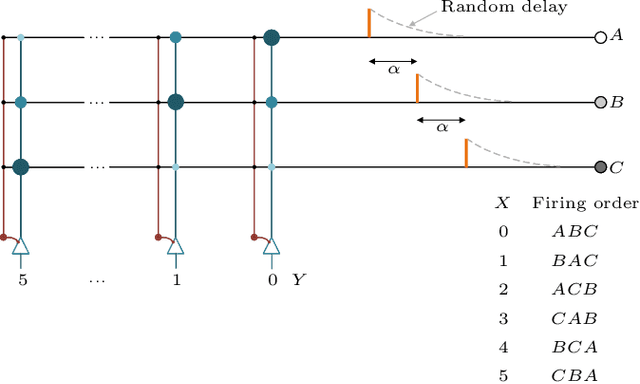
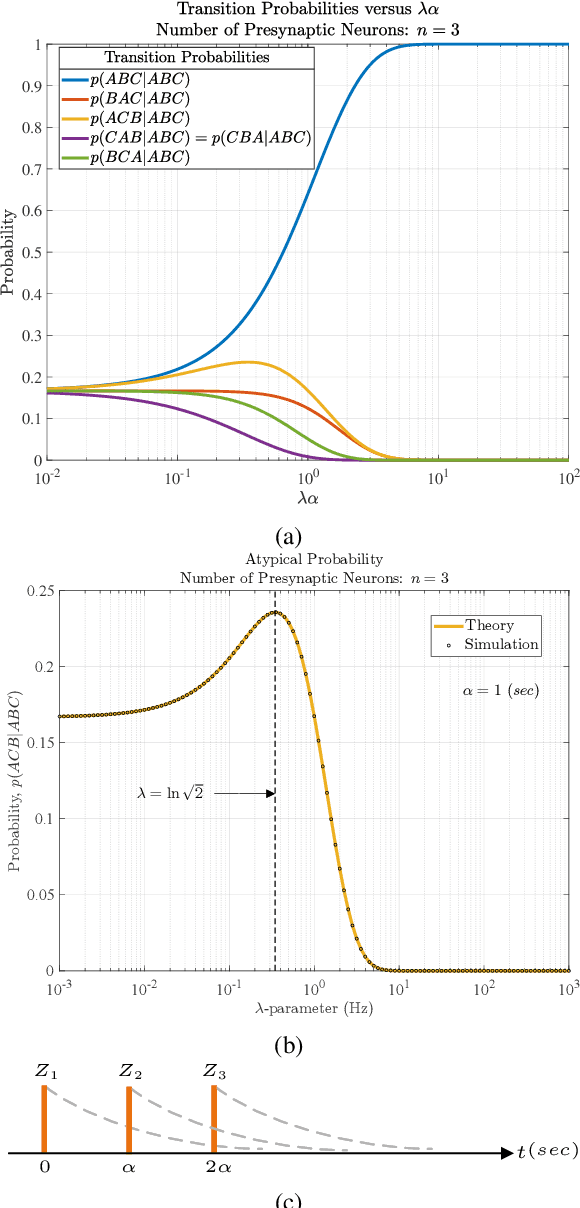
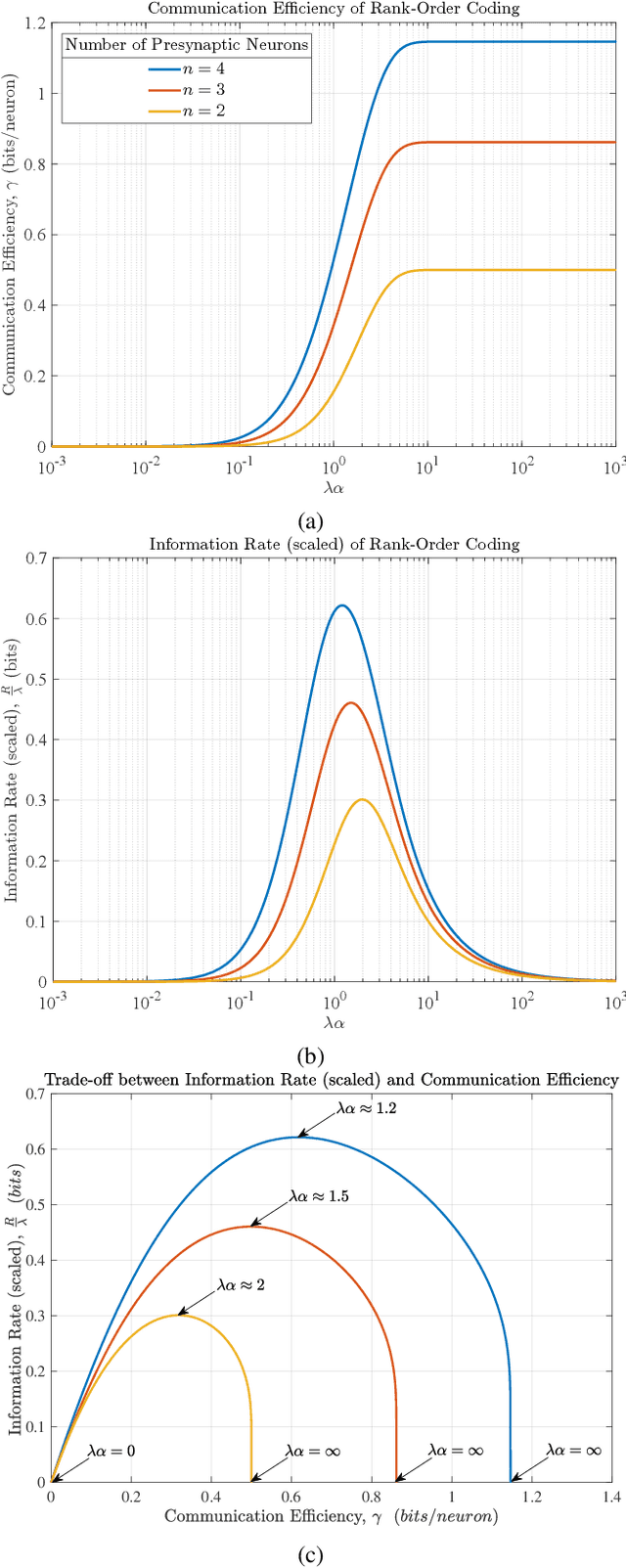
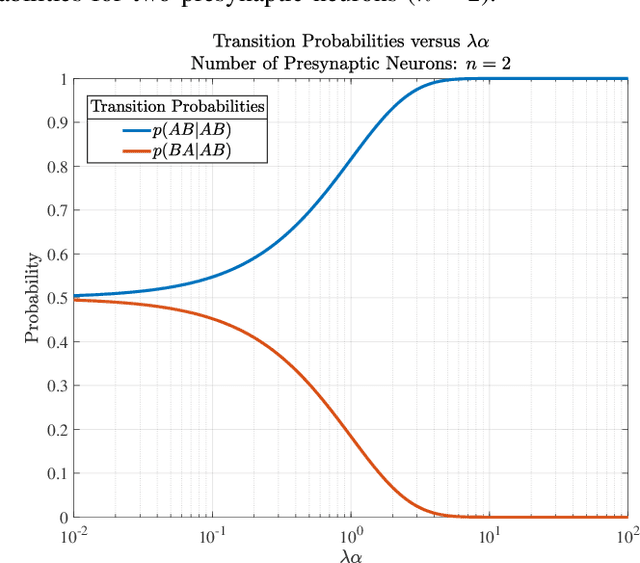
Rank-order coding, a form of temporal coding, has emerged as a promising scheme to explain the rapid ability of the mammalian brain. Owing to its speed as well as efficiency, rank-order coding is increasingly gaining interest in diverse research areas beyond neuroscience. However, much uncertainty still exists about the performance of rank-order coding under noise. Herein we show what information rates are fundamentally possible and what trade-offs are at stake. An unexpected finding in this paper is the emergence of a special class of errors that, in a regime, increase with less noise.
HODN: Disentangling Human-Object Feature for HOI Detection
Aug 20, 2023
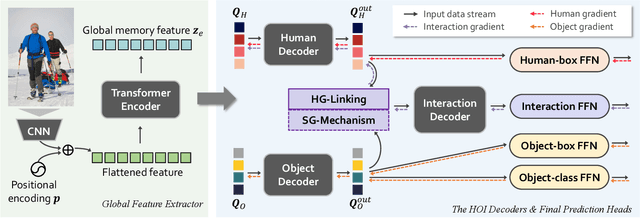
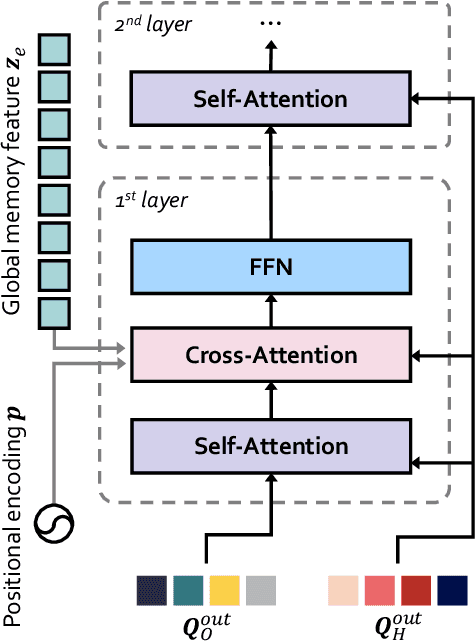
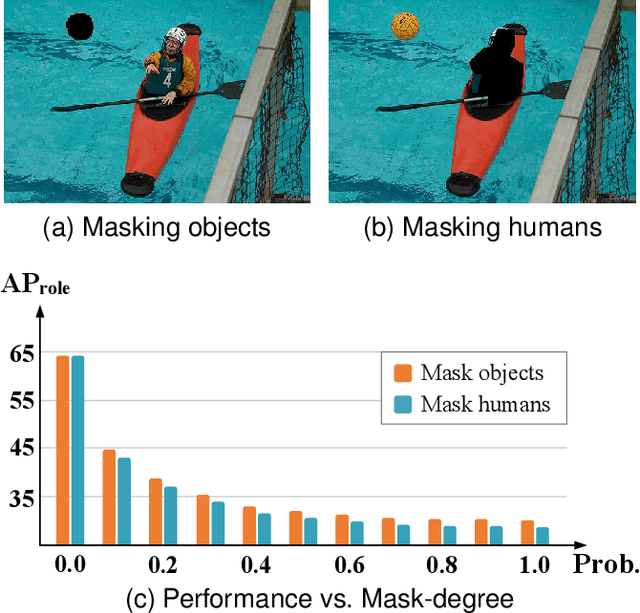
The task of Human-Object Interaction (HOI) detection is to detect humans and their interactions with surrounding objects, where transformer-based methods show dominant advances currently. However, these methods ignore the relationship among humans, objects, and interactions: 1) human features are more contributive than object ones to interaction prediction; 2) interactive information disturbs the detection of objects but helps human detection. In this paper, we propose a Human and Object Disentangling Network (HODN) to model the HOI relationships explicitly, where humans and objects are first detected by two disentangling decoders independently and then processed by an interaction decoder. Considering that human features are more contributive to interaction, we propose a Human-Guide Linking method to make sure the interaction decoder focuses on the human-centric regions with human features as the positional embeddings. To handle the opposite influences of interactions on humans and objects, we propose a Stop-Gradient Mechanism to stop interaction gradients from optimizing the object detection but to allow them to optimize the human detection. Our proposed method achieves competitive performance on both the V-COCO and the HICO-Det datasets. It can be combined with existing methods easily for state-of-the-art results.
Privileged Anatomical and Protocol Discrimination in Trackerless 3D Ultrasound Reconstruction
Aug 20, 2023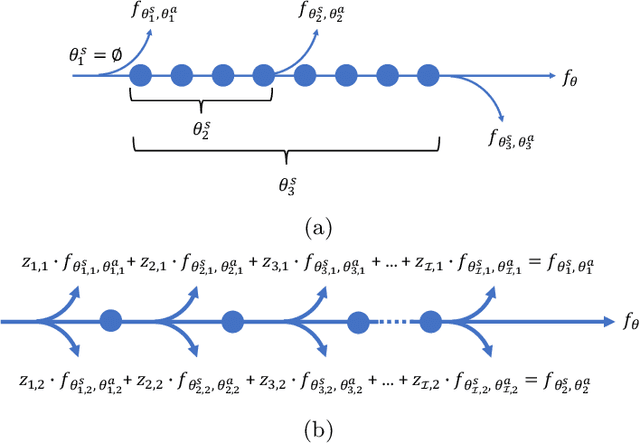
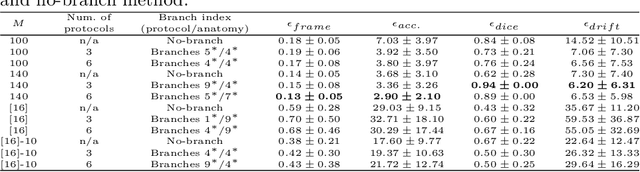
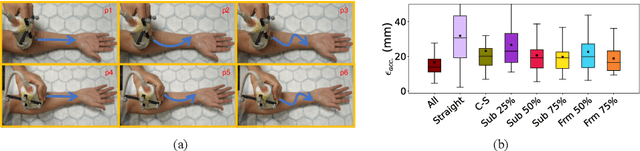
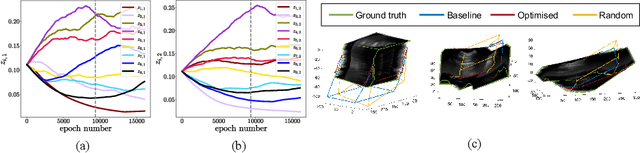
Three-dimensional (3D) freehand ultrasound (US) reconstruction without using any additional external tracking device has seen recent advances with deep neural networks (DNNs). In this paper, we first investigated two identified contributing factors of the learned inter-frame correlation that enable the DNN-based reconstruction: anatomy and protocol. We propose to incorporate the ability to represent these two factors - readily available during training - as the privileged information to improve existing DNN-based methods. This is implemented in a new multi-task method, where the anatomical and protocol discrimination are used as auxiliary tasks. We further develop a differentiable network architecture to optimise the branching location of these auxiliary tasks, which controls the ratio between shared and task-specific network parameters, for maximising the benefits from the two auxiliary tasks. Experimental results, on a dataset with 38 forearms of 19 volunteers acquired with 6 different scanning protocols, show that 1) both anatomical and protocol variances are enabling factors for DNN-based US reconstruction; 2) learning how to discriminate different subjects (anatomical variance) and predefined types of scanning paths (protocol variance) both significantly improve frame prediction accuracy, volume reconstruction overlap, accumulated tracking error and final drift, using the proposed algorithm.