 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
HyperFormer: Enhancing Entity and Relation Interaction for Hyper-Relational Knowledge Graph Completion
Aug 12, 2023
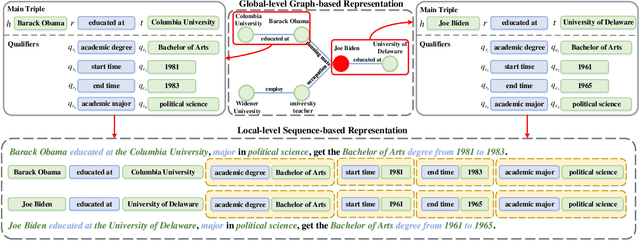
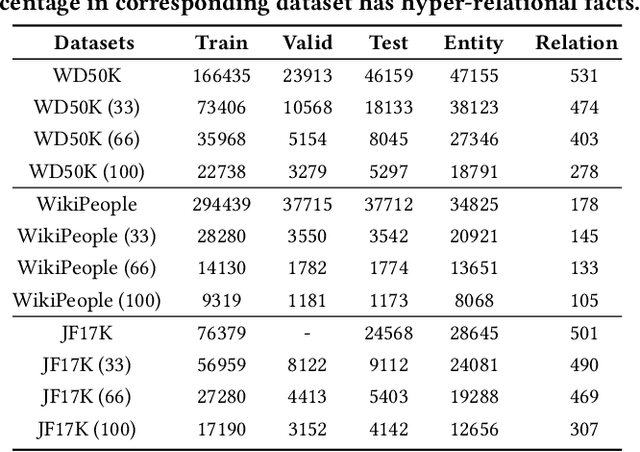
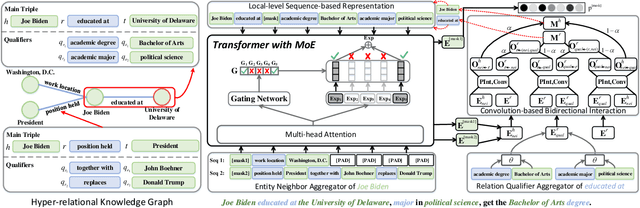
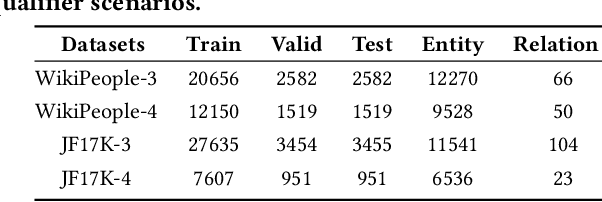
Hyper-relational knowledge graphs (HKGs) extend standard knowledge graphs by associating attribute-value qualifiers to triples, which effectively represent additional fine-grained information about its associated triple. Hyper-relational knowledge graph completion (HKGC) aims at inferring unknown triples while considering its qualifiers. Most existing approaches to HKGC exploit a global-level graph structure to encode hyper-relational knowledge into the graph convolution message passing process. However, the addition of multi-hop information might bring noise into the triple prediction process. To address this problem, we propose HyperFormer, a model that considers local-level sequential information, which encodes the content of the entities, relations and qualifiers of a triple. More precisely, HyperFormer is composed of three different modules: an entity neighbor aggregator module allowing to integrate the information of the neighbors of an entity to capture different perspectives of it; a relation qualifier aggregator module to integrate hyper-relational knowledge into the corresponding relation to refine the representation of relational content; a convolution-based bidirectional interaction module based on a convolutional operation, capturing pairwise bidirectional interactions of entity-relation, entity-qualifier, and relation-qualifier. realize the depth perception of the content related to the current statement. Furthermore, we introduce a Mixture-of-Experts strategy into the feed-forward layers of HyperFormer to strengthen its representation capabilities while reducing the amount of model parameters and computation. Extensive experiments on three well-known datasets with four different conditions demonstrate HyperFormer's effectiveness. Datasets and code are available at https://github.com/zhiweihu1103/HKGC-HyperFormer.
Extracting Relational Triples Based on Graph Recursive Neural Network via Dynamic Feedback Forest Algorithm
Aug 22, 2023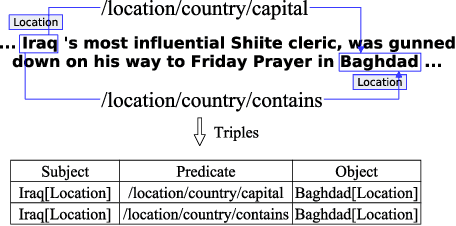
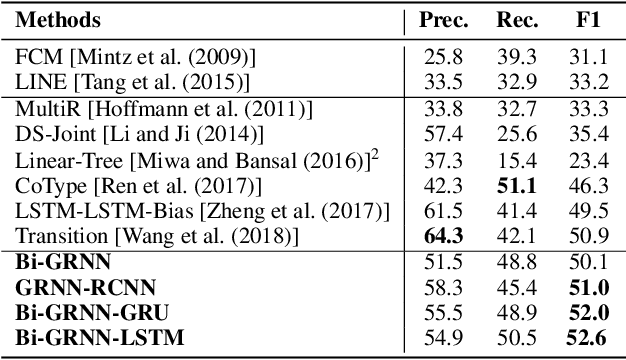
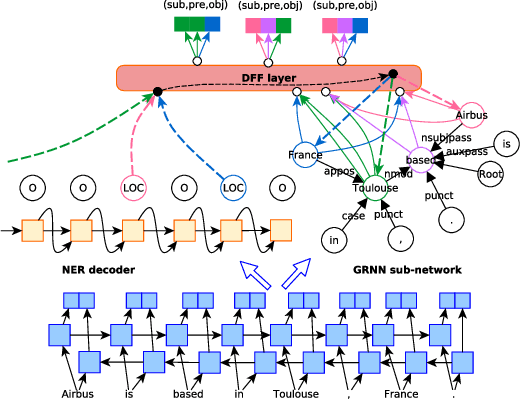
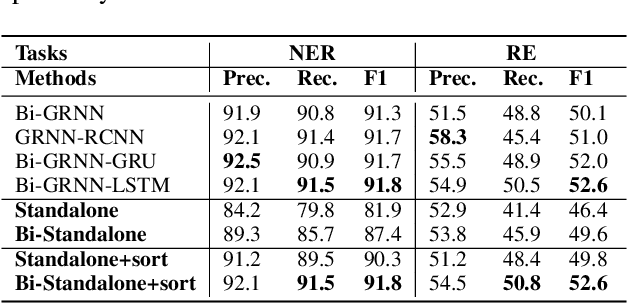
Extracting relational triples (subject, predicate, object) from text enables the transformation of unstructured text data into structured knowledge. The named entity recognition (NER) and the relation extraction (RE) are two foundational subtasks in this knowledge generation pipeline. The integration of subtasks poses a considerable challenge due to their disparate nature. This paper presents a novel approach that converts the triple extraction task into a graph labeling problem, capitalizing on the structural information of dependency parsing and graph recursive neural networks (GRNNs). To integrate subtasks, this paper proposes a dynamic feedback forest algorithm that connects the representations of subtasks by inference operations during model training. Experimental results demonstrate the effectiveness of the proposed method.
Compositional Learning in Transformer-Based Human-Object Interaction Detection
Aug 11, 2023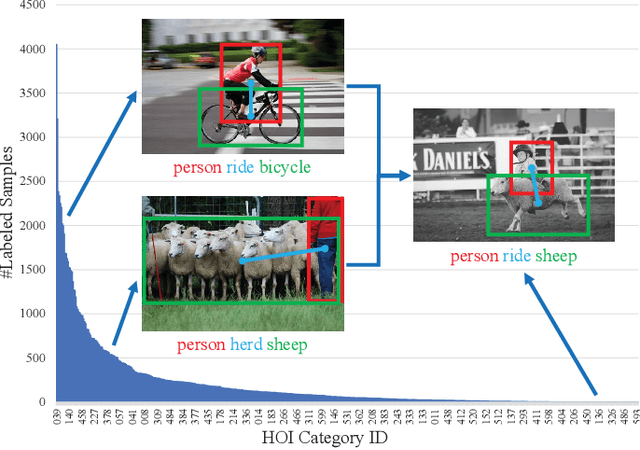
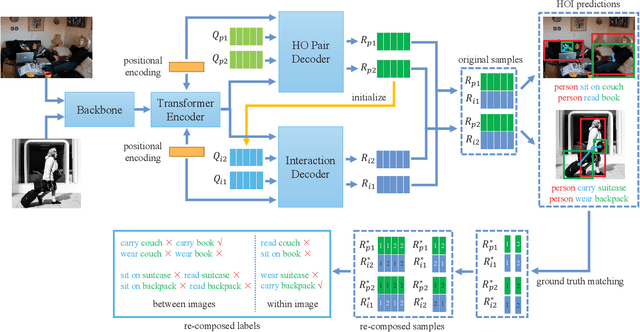

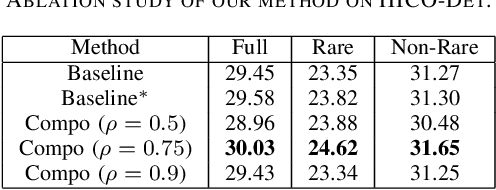
Human-object interaction (HOI) detection is an important part of understanding human activities and visual scenes. The long-tailed distribution of labeled instances is a primary challenge in HOI detection, promoting research in few-shot and zero-shot learning. Inspired by the combinatorial nature of HOI triplets, some existing approaches adopt the idea of compositional learning, in which object and action features are learned individually and re-composed as new training samples. However, these methods follow the CNN-based two-stage paradigm with limited feature extraction ability, and often rely on auxiliary information for better performance. Without introducing any additional information, we creatively propose a transformer-based framework for compositional HOI learning. Human-object pair representations and interaction representations are re-composed across different HOI instances, which involves richer contextual information and promotes the generalization of knowledge. Experiments show our simple but effective method achieves state-of-the-art performance, especially on rare HOI classes.
Efficient Partitioning Method of Large-Scale Public Safety Spatio-Temporal Data based on Information Loss Constraints
Jun 30, 2023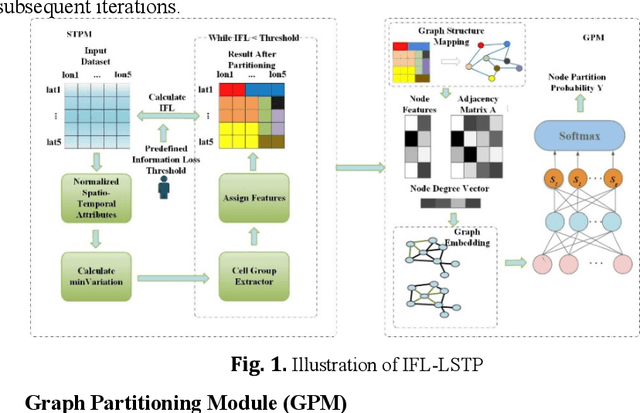

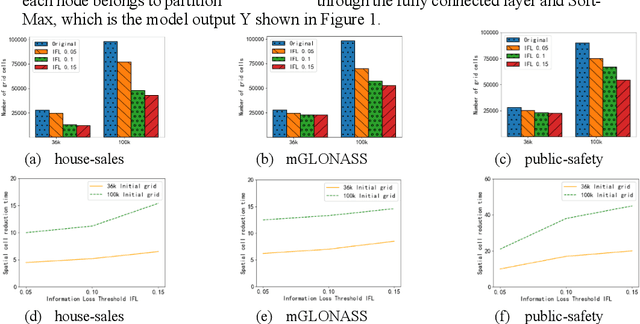

The storage, management, and application of massive spatio-temporal data are widely applied in various practical scenarios, including public safety. However, due to the unique spatio-temporal distribution characteristics of re-al-world data, most existing methods have limitations in terms of the spatio-temporal proximity of data and load balancing in distributed storage. There-fore, this paper proposes an efficient partitioning method of large-scale public safety spatio-temporal data based on information loss constraints (IFL-LSTP). The IFL-LSTP model specifically targets large-scale spatio-temporal point da-ta by combining the spatio-temporal partitioning module (STPM) with the graph partitioning module (GPM). This approach can significantly reduce the scale of data while maintaining the model's accuracy, in order to improve the partitioning efficiency. It can also ensure the load balancing of distributed storage while maintaining spatio-temporal proximity of the data partitioning results. This method provides a new solution for distributed storage of mas-sive spatio-temporal data. The experimental results on multiple real-world da-tasets demonstrate the effectiveness and superiority of IFL-LSTP.
BioCPT: Contrastive Pre-trained Transformers with Large-scale PubMed Search Logs for Zero-shot Biomedical Information Retrieval
Jul 02, 2023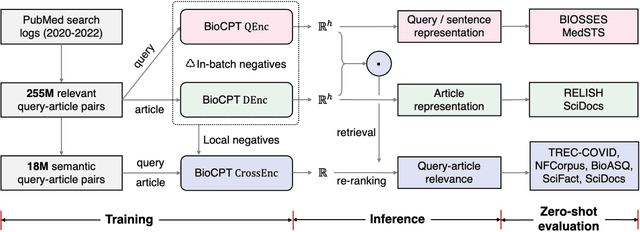
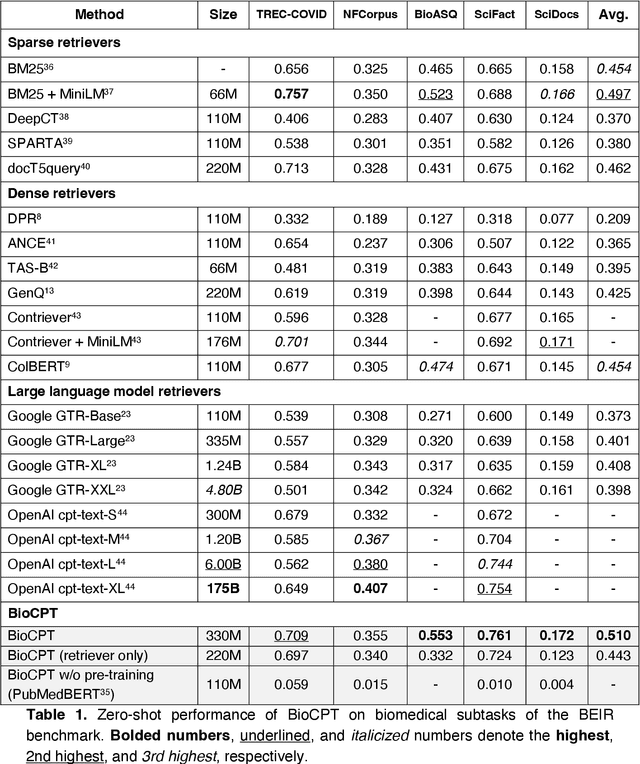
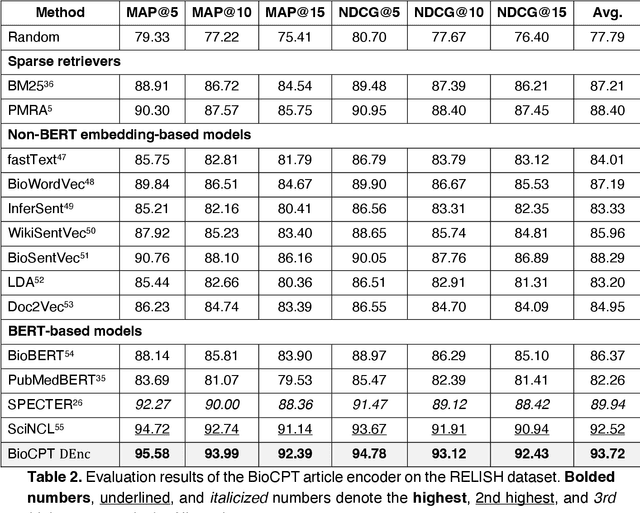
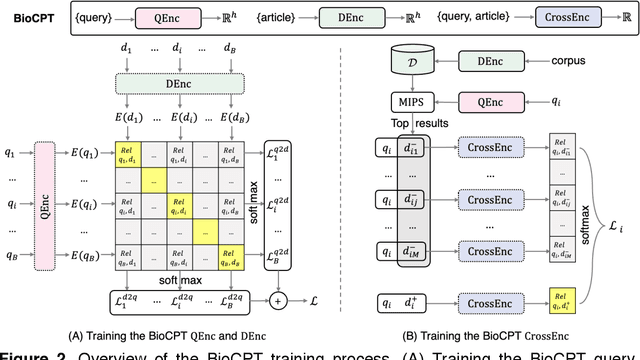
Information retrieval (IR) is essential in biomedical knowledge acquisition and clinical decision support. While recent progress has shown that language model encoders perform better semantic retrieval, training such models requires abundant query-article annotations that are difficult to obtain in biomedicine. As a result, most biomedical IR systems only conduct lexical matching. In response, we introduce BioCPT, a first-of-its-kind Contrastively Pre-trained Transformer model for zero-shot biomedical IR. To train BioCPT, we collected an unprecedented scale of 255 million user click logs from PubMed. With such data, we use contrastive learning to train a pair of closely-integrated retriever and re-ranker. Experimental results show that BioCPT sets new state-of-the-art performance on five biomedical IR tasks, outperforming various baselines including much larger models such as GPT-3-sized cpt-text-XL. In addition, BioCPT also generates better biomedical article and sentence representations for semantic evaluations. As such, BioCPT can be readily applied to various real-world biomedical IR tasks. BioCPT API and code are publicly available at https://github.com/ncbi/BioCPT.
PIVOINE: Instruction Tuning for Open-world Information Extraction
May 24, 2023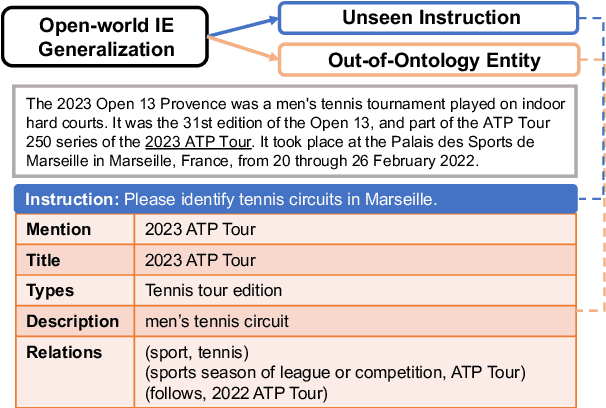

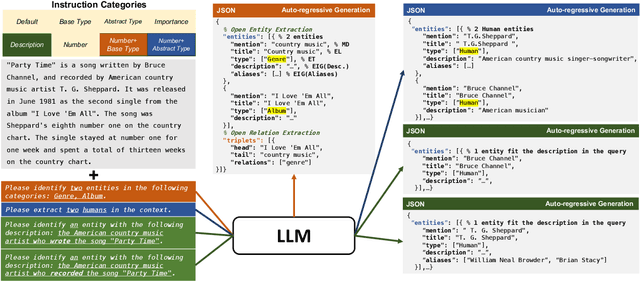
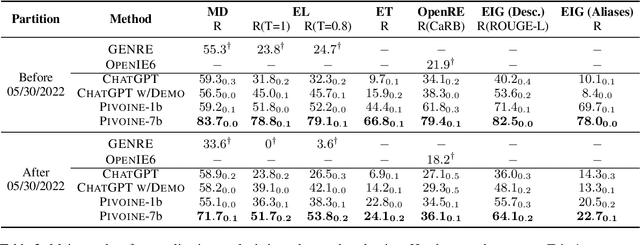
We consider the problem of Open-world Information Extraction (Open-world IE), which extracts comprehensive entity profiles from unstructured texts. Different from the conventional closed-world setting of Information Extraction (IE), Open-world IE considers a more general situation where entities and relations could be beyond a predefined ontology. More importantly, we seek to develop a large language model (LLM) that is able to perform Open-world IE to extract desirable entity profiles characterized by (possibly fine-grained) natural language instructions. We achieve this by finetuning LLMs using instruction tuning. In particular, we construct INSTRUCTOPENWIKI, a substantial instruction tuning dataset for Open-world IE enriched with a comprehensive corpus, extensive annotations, and diverse instructions. We finetune the pretrained BLOOM models on INSTRUCTOPENWIKI and obtain PIVOINE, an LLM for Open-world IE with strong instruction-following capabilities. Our experiments demonstrate that PIVOINE significantly outperforms traditional closed-world methods and other LLM baselines, displaying impressive generalization capabilities on both unseen instructions and out-of-ontology cases. Consequently, PIVOINE emerges as a promising solution to tackle the open-world challenge in IE effectively.
Operationalizing Counterfactual Metrics: Incentives, Ranking, and Information Asymmetry
May 24, 2023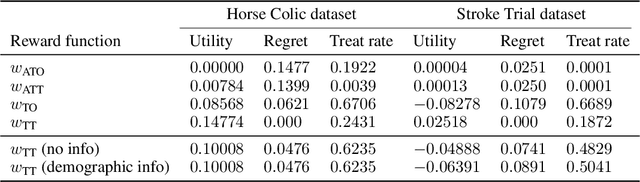
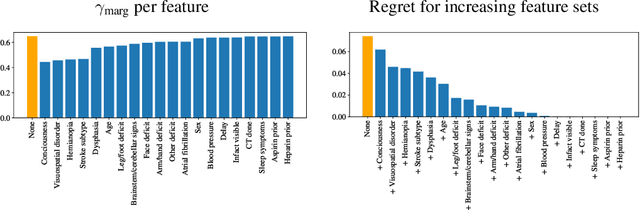
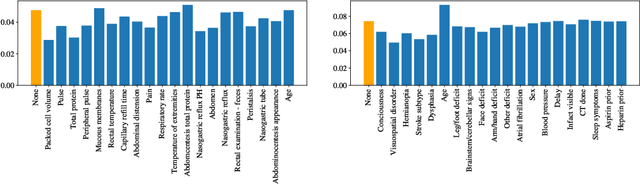
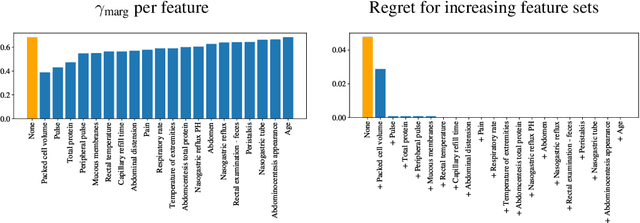
From the social sciences to machine learning, it has been well documented that metrics to be optimized are not always aligned with social welfare. In healthcare, Dranove et al. [12] showed that publishing surgery mortality metrics actually harmed the welfare of sicker patients by increasing provider selection behavior. Using a principal-agent model, we directly study the incentive misalignments that arise from such average treated outcome metrics, and show that the incentives driving treatment decisions would align with maximizing total patient welfare if the metrics (i) accounted for counterfactual untreated outcomes and (ii) considered total welfare instead of average welfare among treated patients. Operationalizing this, we show how counterfactual metrics can be modified to satisfy desirable properties when used for ranking. Extending to realistic settings when the providers observe more about patients than the regulatory agencies do, we bound the decay in performance by the degree of information asymmetry between the principal and the agent. In doing so, our model connects principal-agent information asymmetry with unobserved heterogeneity in causal inference.
Near-Field 3D Localization via MIMO Radar: Cramér-Rao Bound Analysis and Estimator Design
Aug 30, 2023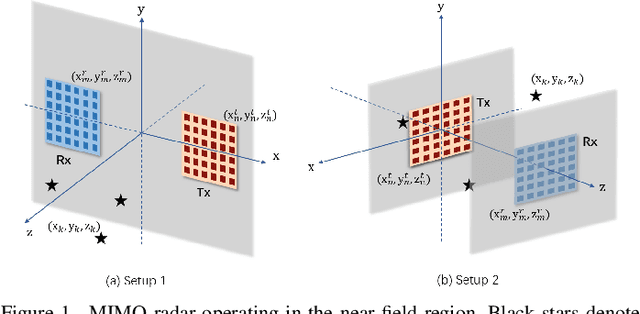
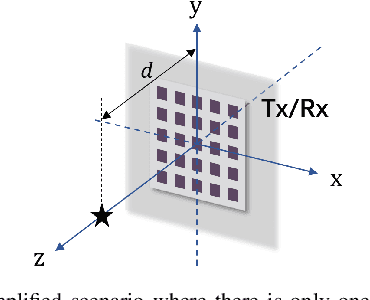
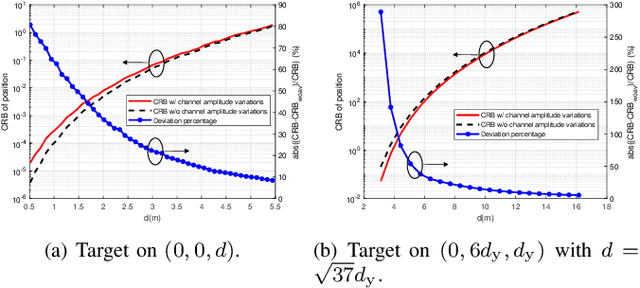
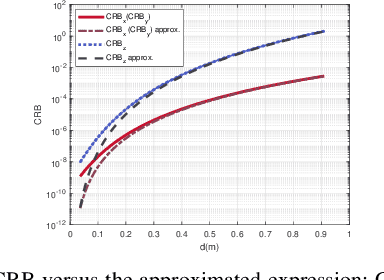
This paper studies a near-field multiple-input multiple-output (MIMO) radar sensing system, in which the transceivers with massive antennas aim to localize multiple near-field targets in the three-dimensional (3D) space over unknown cluttered environments. We consider a spherical wavefront propagation with both channel phase and amplitude variations over different antennas. Under this setup, the unknown parameters include the 3D coordinates and complex reflection coefficients of the targets, as well as the noise and interference covariance matrix. First, by considering general transmit signal waveforms, we derive the Fisher information matrix (FIM) corresponding to the 3D coordinates and the complex reflection coefficients of the targets and accordingly obtain the Cram\'er-Rao bound (CRB) for the 3D coordinates. This provides a performance bound for 3D near-field target localization. For the special single-target case, we obtain the CRB in an analytical form, and analyze its asymptotic scaling behaviors with respect to the target distance and antenna size of the transceiver. Next, to facilitate practical localization, we propose two estimators to localize targets based on the maximum likelihood (ML) criterion, namely the 3D approximate cyclic optimization (3D-ACO) and the 3D cyclic optimization with white Gaussian noise (3D-CO-WGN), respectively. Numerical results validate the asymptotic CRB analysis and show that the consideration of varying channel amplitudes is vital to achieve accurate CRB and localization when the targets are close to the transceivers. It is also shown that the proposed estimators achieve localization performance close to the derived CRB under various cluttered environments, thus validating their effectiveness in practical implementation. Furthermore, it is shown that transmit waveforms have a significant impact on CRB and the localization performance.
Anti-Jamming Precoding Against Disco Intelligent Reflecting Surfaces Based Fully-Passive Jamming Attacks
Aug 30, 2023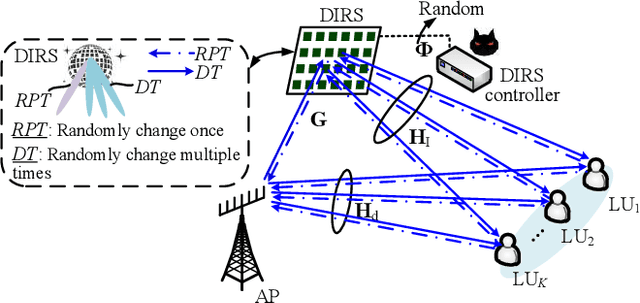
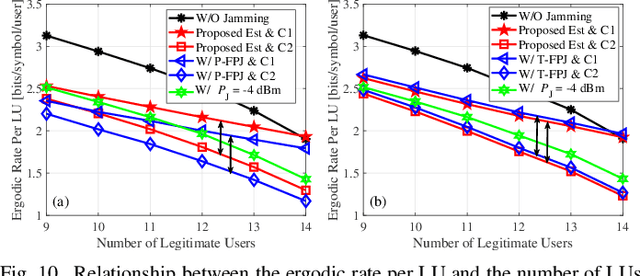
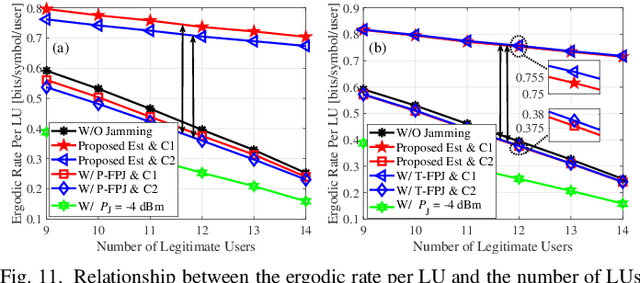
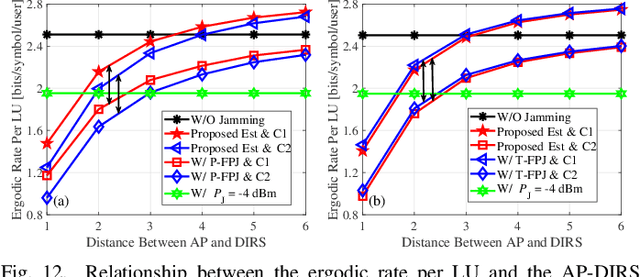
Emerging intelligent reflecting surfaces (IRSs) significantly improve system performance, but also pose a huge risk for physical layer security. Existing works have illustrated that a disco IRS (DIRS), i.e., an illegitimate IRS with random time-varying reflection properties (like a "disco ball"), can be employed by an attacker to actively age the channels of legitimate users (LUs). Such active channel aging (ACA) generated by the DIRS can be employed to jam multi-user multiple-input single-output (MU-MISO) systems without relying on either jamming power or LU channel state information (CSI). To address the significant threats posed by DIRS-based fully-passive jammers (FPJs), an anti-jamming precoder is proposed that requires only the statistical characteristics of the DIRS-based ACA channels instead of their CSI. The statistical characteristics of DIRS-jammed channels are first derived, and then the anti-jamming precoder is derived based on the statistical characteristics. Furthermore, we prove that the anti-jamming precoder can achieve the maximum signal-to-jamming-plus-noise ratio (SJNR). To acquire the ACA statistics without changing the system architecture or cooperating with the illegitimate DIRS, we design a data frame structure that the legitimate access point (AP) can use to estimate the statistical characteristics. During the designed data frame, the LUs only need to feed back their received power to the legitimate AP when they detect jamming attacks. Numerical results are also presented to evaluate the effectiveness of the proposed anti-jamming precoder against the DIRS-based FPJs and the feasibility of the designed data frame used by the legitimate AP to estimate the statistical characteristics.
InstructIE: A Chinese Instruction-based Information Extraction Dataset
May 19, 2023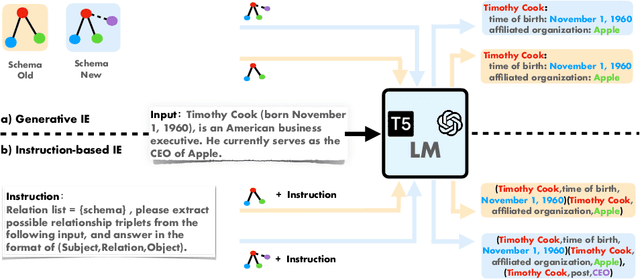

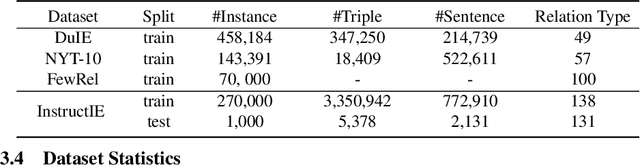
We introduce a new Information Extraction (IE) task dubbed Instruction-based IE, which aims to ask the system to follow specific instructions or guidelines to extract information. To facilitate research in this area, we construct a dataset called InstructIE, consisting of 270,000 weakly supervised data from Chinese Wikipedia and 1,000 high-quality crowdsourced annotated instances. We further evaluate the performance of various baseline models on the InstructIE dataset. The results reveal that although current models exhibit promising performance, there is still room for improvement. Furthermore, we conduct a comprehensive case study analysis, underlining the challenges inherent in the Instruction-based IE task. Code and dataset are available at https://github.com/zjunlp/DeepKE/tree/main/example/llm.