 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Pose2Gait: Extracting Gait Features from Monocular Video of Individuals with Dementia
Aug 22, 2023
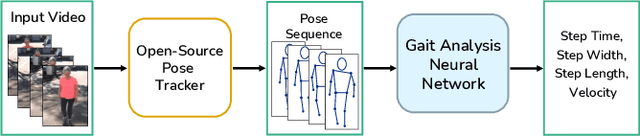

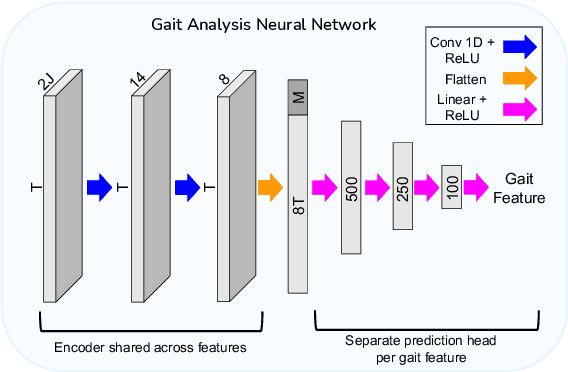

Video-based ambient monitoring of gait for older adults with dementia has the potential to detect negative changes in health and allow clinicians and caregivers to intervene early to prevent falls or hospitalizations. Computer vision-based pose tracking models can process video data automatically and extract joint locations; however, publicly available models are not optimized for gait analysis on older adults or clinical populations. In this work we train a deep neural network to map from a two dimensional pose sequence, extracted from a video of an individual walking down a hallway toward a wall-mounted camera, to a set of three-dimensional spatiotemporal gait features averaged over the walking sequence. The data of individuals with dementia used in this work was captured at two sites using a wall-mounted system to collect the video and depth information used to train and evaluate our model. Our Pose2Gait model is able to extract velocity and step length values from the video that are correlated with the features from the depth camera, with Spearman's correlation coefficients of .83 and .60 respectively, showing that three dimensional spatiotemporal features can be predicted from monocular video. Future work remains to improve the accuracy of other features, such as step time and step width, and test the utility of the predicted values for detecting meaningful changes in gait during longitudinal ambient monitoring.
Exemplar-Free Continual Transformer with Convolutions
Aug 22, 2023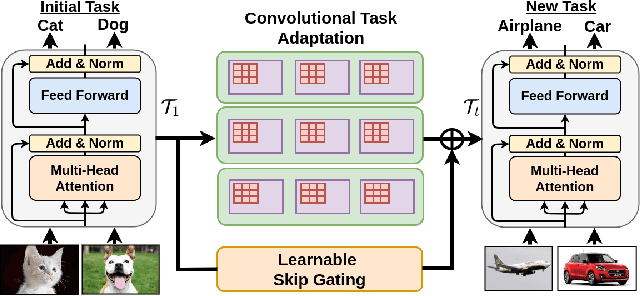
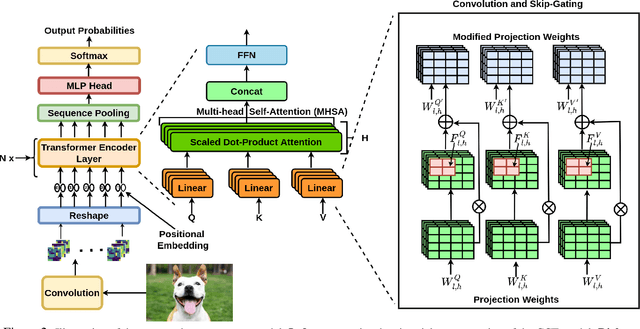
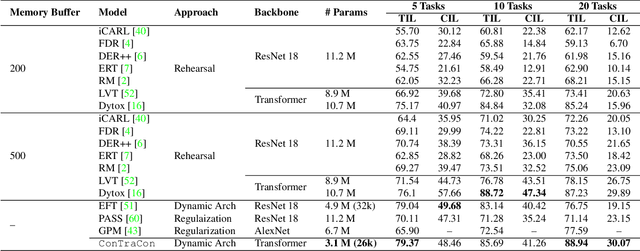
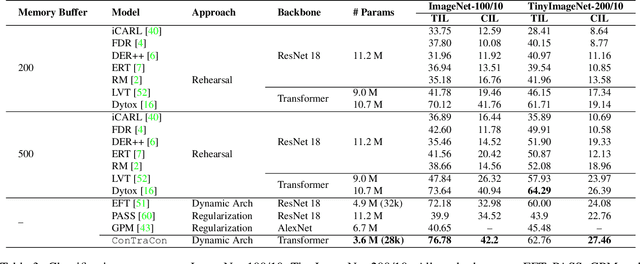
Continual Learning (CL) involves training a machine learning model in a sequential manner to learn new information while retaining previously learned tasks without the presence of previous training data. Although there has been significant interest in CL, most recent CL approaches in computer vision have focused on convolutional architectures only. However, with the recent success of vision transformers, there is a need to explore their potential for CL. Although there have been some recent CL approaches for vision transformers, they either store training instances of previous tasks or require a task identifier during test time, which can be limiting. This paper proposes a new exemplar-free approach for class/task incremental learning called ConTraCon, which does not require task-id to be explicitly present during inference and avoids the need for storing previous training instances. The proposed approach leverages the transformer architecture and involves re-weighting the key, query, and value weights of the multi-head self-attention layers of a transformer trained on a similar task. The re-weighting is done using convolution, which enables the approach to maintain low parameter requirements per task. Additionally, an image augmentation-based entropic task identification approach is used to predict tasks without requiring task-ids during inference. Experiments on four benchmark datasets demonstrate that the proposed approach outperforms several competitive approaches while requiring fewer parameters.
Karasu: A Collaborative Approach to Efficient Cluster Configuration for Big Data Analytics
Aug 22, 2023Selecting the right resources for big data analytics jobs is hard because of the wide variety of configuration options like machine type and cluster size. As poor choices can have a significant impact on resource efficiency, cost, and energy usage, automated approaches are gaining popularity. Most existing methods rely on profiling recurring workloads to find near-optimal solutions over time. Due to the cold-start problem, this often leads to lengthy and costly profiling phases. However, big data analytics jobs across users can share many common properties: they often operate on similar infrastructure, using similar algorithms implemented in similar frameworks. The potential in sharing aggregated profiling runs to collaboratively address the cold start problem is largely unexplored. We present Karasu, an approach to more efficient resource configuration profiling that promotes data sharing among users working with similar infrastructures, frameworks, algorithms, or datasets. Karasu trains lightweight performance models using aggregated runtime information of collaborators and combines them into an ensemble method to exploit inherent knowledge of the configuration search space. Moreover, Karasu allows the optimization of multiple objectives simultaneously. Our evaluation is based on performance data from diverse workload executions in a public cloud environment. We show that Karasu is able to significantly boost existing methods in terms of performance, search time, and cost, even when few comparable profiling runs are available that share only partial common characteristics with the target job.
Machine Learning-based Positioning using Multivariate Time Series Classification for Factory Environments
Aug 22, 2023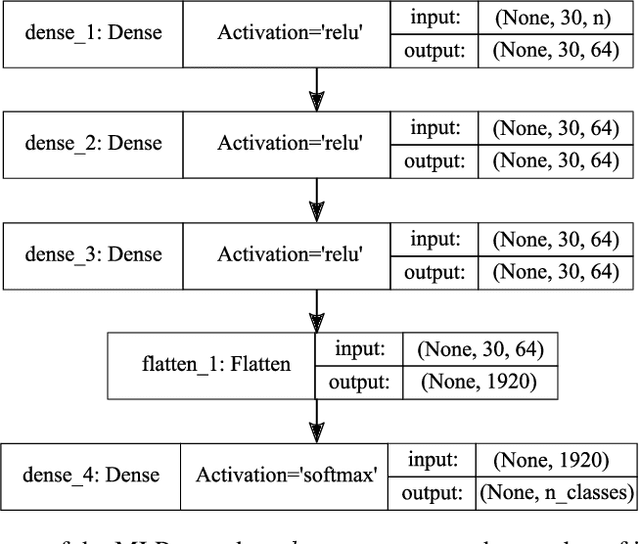

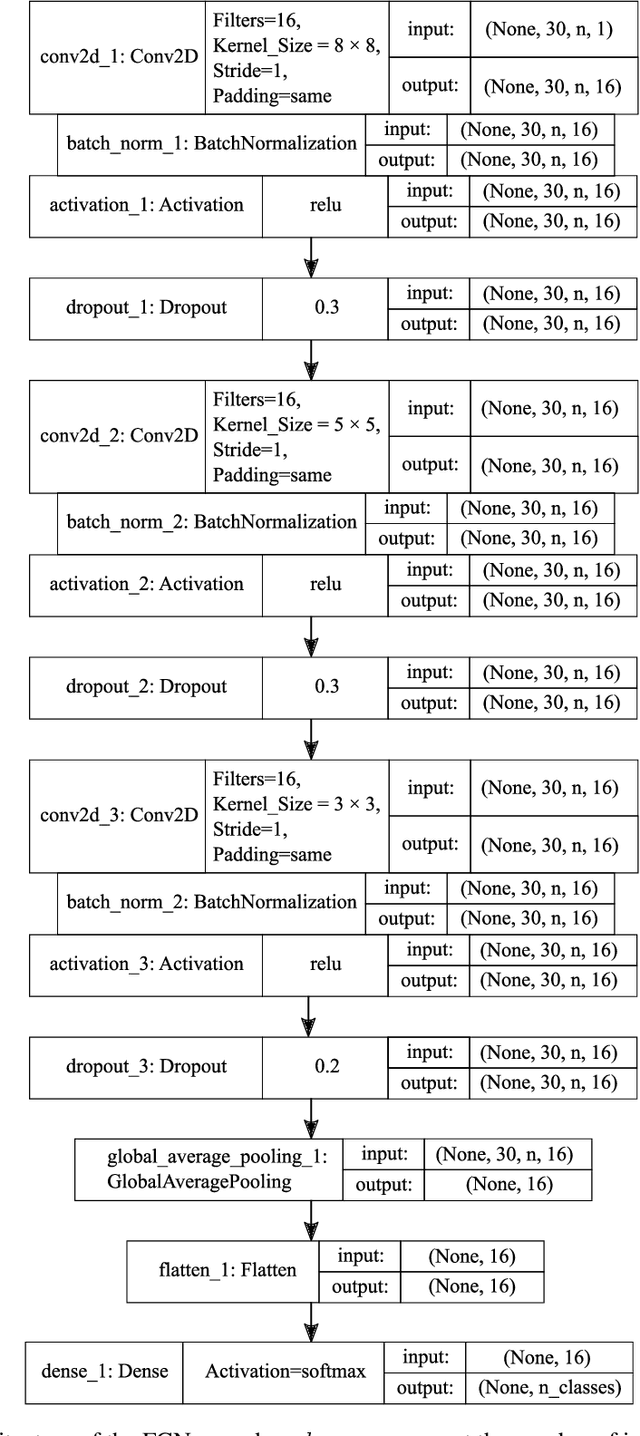

Indoor Positioning Systems (IPS) gained importance in many industrial applications. State-of-the-art solutions heavily rely on external infrastructures and are subject to potential privacy compromises, external information requirements, and assumptions, that make it unfavorable for environments demanding privacy and prolonged functionality. In certain environments deploying supplementary infrastructures for indoor positioning could be infeasible and expensive. Recent developments in machine learning (ML) offer solutions to address these limitations relying only on the data from onboard sensors of IoT devices. However, it is unclear which model fits best considering the resource constraints of IoT devices. This paper presents a machine learning-based indoor positioning system, using motion and ambient sensors, to localize a moving entity in privacy concerned factory environments. The problem is formulated as a multivariate time series classification (MTSC) and a comparative analysis of different machine learning models is conducted in order to address it. We introduce a novel time series dataset emulating the assembly lines of a factory. This dataset is utilized to assess and compare the selected models in terms of accuracy, memory footprint and inference speed. The results illustrate that all evaluated models can achieve accuracies above 80 %. CNN-1D shows the most balanced performance, followed by MLP. DT was found to have the lowest memory footprint and inference latency, indicating its potential for a deployment in real-world scenarios.
A LiDAR-Inertial SLAM Tightly-Coupled with Dropout-Tolerant GNSS Fusion for Autonomous Mine Service Vehicles
Aug 22, 2023
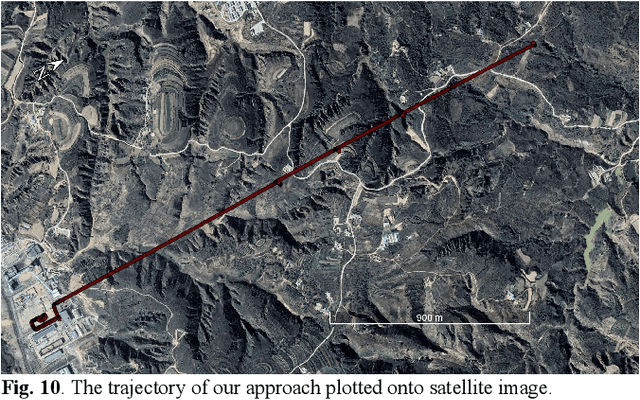


Multi-modal sensor integration has become a crucial prerequisite for the real-world navigation systems. Recent studies have reported successful deployment of such system in many fields. However, it is still challenging for navigation tasks in mine scenes due to satellite signal dropouts, degraded perception, and observation degeneracy. To solve this problem, we propose a LiDAR-inertial odometry method in this paper, utilizing both Kalman filter and graph optimization. The front-end consists of multiple parallel running LiDAR-inertial odometries, where the laser points, IMU, and wheel odometer information are tightly fused in an error-state Kalman filter. Instead of the commonly used feature points, we employ surface elements for registration. The back-end construct a pose graph and jointly optimize the pose estimation results from inertial, LiDAR odometry, and global navigation satellite system (GNSS). Since the vehicle has a long operation time inside the tunnel, the largely accumulated drift may be not fully by the GNSS measurements. We hereby leverage a loop closure based re-initialization process to achieve full alignment. In addition, the system robustness is improved through handling data loss, stream consistency, and estimation error. The experimental results show that our system has a good tolerance to the long-period degeneracy with the cooperation different LiDARs and surfel registration, achieving meter-level accuracy even for tens of minutes running during GNSS dropouts.
Transmit Power Optimization of IoT Devices over Incomplete Channel Information
May 27, 2023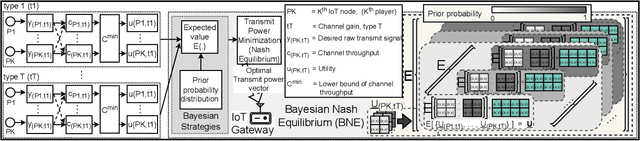
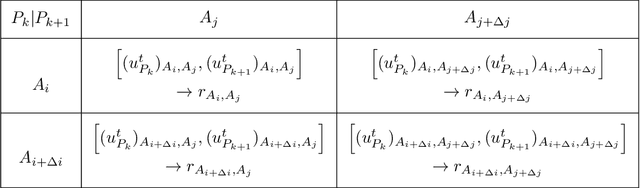
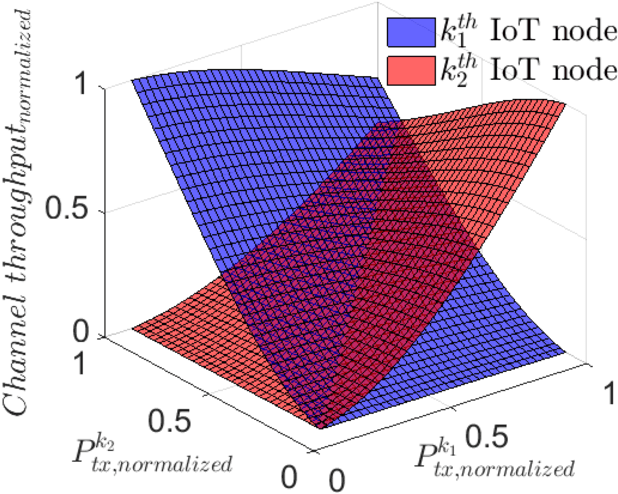
Efficient resource allocation (RA) strategies within massive and dense Internet of Things (IoT) networks is one of the major challenges in the deployment of IoT-network based smart ecosystems involving heterogeneous power-constrained IoT devices operating in varied radio and environmental conditions. In this paper, we focus on the transmit power minimization problem for IoT devices while maintaining a threshold channel throughput. The established optimization literature is not robust against the fast-fading channel and the interaction among different transmit signals in each instance. Besides, realistically, each IoT node possesses incomplete channel state information (CSI) on its neighbors, such as the channel gain being private information for the node itself. In this work, we resort to Bayesian game theoretic strategies for solving the transmit power optimization problem exploiting incomplete CSIs within massive IoT networks. We provide a steady discussion on the rationale for selecting the game theory, particularly the Bayesian scheme, with a graphical visualization of our formulated problem. We take advantage of the property of the existence and uniqueness of the Bayesian Nash equilibrium (BNE), which exhibits reduced computational complexity while optimizing transmit power and maintaining target throughput within networks comprised of heterogeneous devices.
Adaptive Robotic Information Gathering via Non-Stationary Gaussian Processes
Jun 08, 2023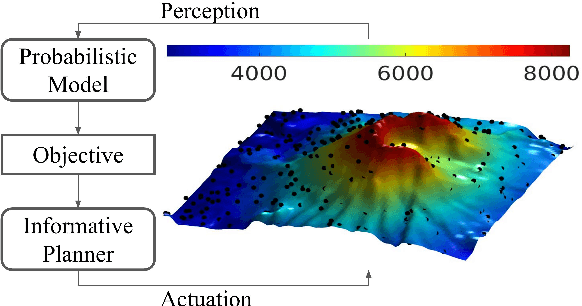
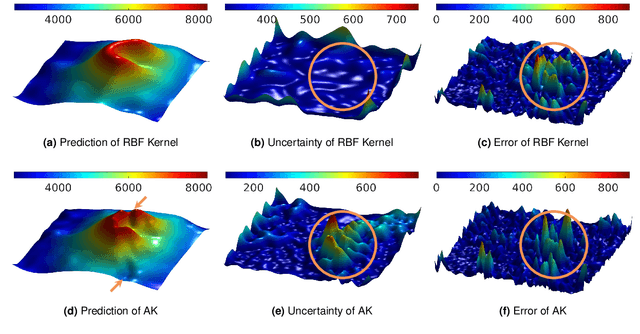
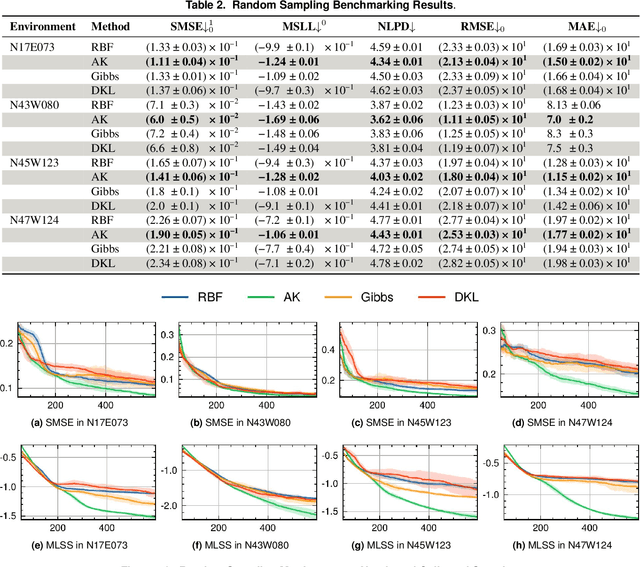
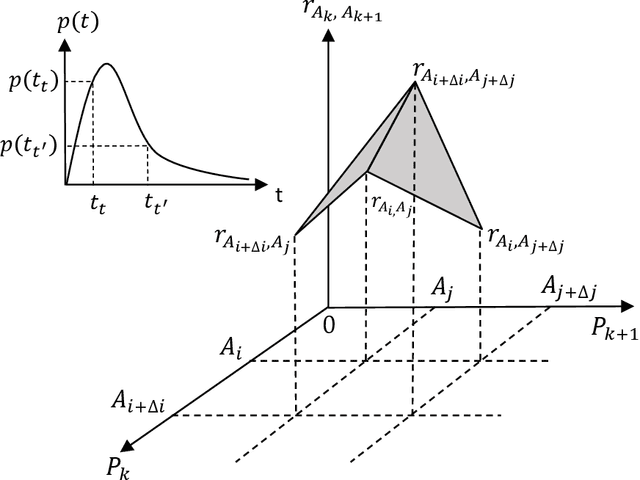
Robotic Information Gathering (RIG) is a foundational research topic that answers how a robot (team) collects informative data to efficiently build an accurate model of an unknown target function under robot embodiment constraints. RIG has many applications, including but not limited to autonomous exploration and mapping, 3D reconstruction or inspection, search and rescue, and environmental monitoring. A RIG system relies on a probabilistic model's prediction uncertainty to identify critical areas for informative data collection. Gaussian Processes (GPs) with stationary kernels have been widely adopted for spatial modeling. However, real-world spatial data is typically non-stationary -- different locations do not have the same degree of variability. As a result, the prediction uncertainty does not accurately reveal prediction error, limiting the success of RIG algorithms. We propose a family of non-stationary kernels named Attentive Kernel (AK), which is simple, robust, and can extend any existing kernel to a non-stationary one. We evaluate the new kernel in elevation mapping tasks, where AK provides better accuracy and uncertainty quantification over the commonly used stationary kernels and the leading non-stationary kernels. The improved uncertainty quantification guides the downstream informative planner to collect more valuable data around the high-error area, further increasing prediction accuracy. A field experiment demonstrates that the proposed method can guide an Autonomous Surface Vehicle (ASV) to prioritize data collection in locations with significant spatial variations, enabling the model to characterize salient environmental features.
Unlimited Knowledge Distillation for Action Recognition in the Dark
Aug 18, 2023

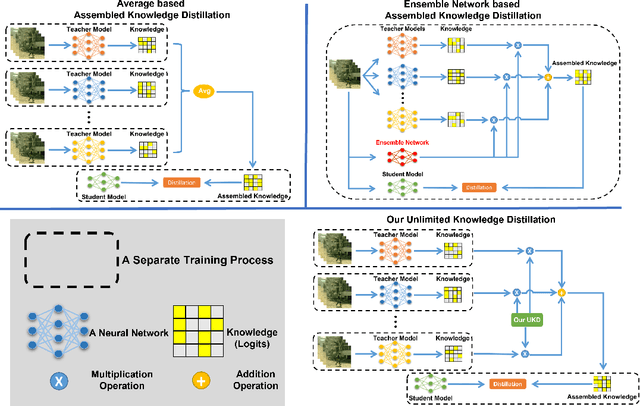

Dark videos often lose essential information, which causes the knowledge learned by networks is not enough to accurately recognize actions. Existing knowledge assembling methods require massive GPU memory to distill the knowledge from multiple teacher models into a student model. In action recognition, this drawback becomes serious due to much computation required by video process. Constrained by limited computation source, these approaches are infeasible. To address this issue, we propose an unlimited knowledge distillation (UKD) in this paper. Compared with existing knowledge assembling methods, our UKD can effectively assemble different knowledge without introducing high GPU memory consumption. Thus, the number of teaching models for distillation is unlimited. With our UKD, the network's learned knowledge can be remarkably enriched. Our experiments show that the single stream network distilled with our UKD even surpasses a two-stream network. Extensive experiments are conducted on the ARID dataset.
Visual and Textual Prior Guided Mask Assemble for Few-Shot Segmentation and Beyond
Aug 15, 2023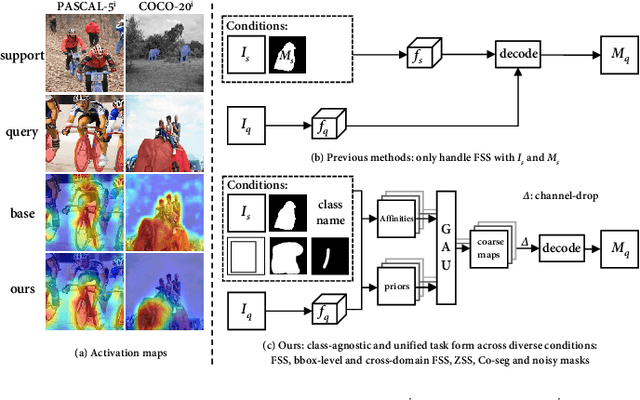
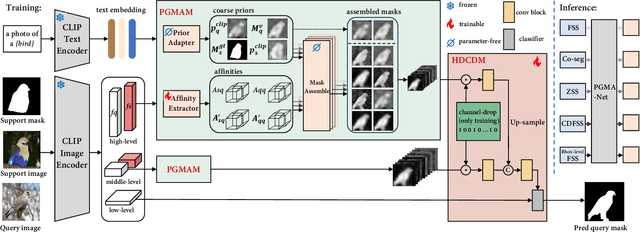
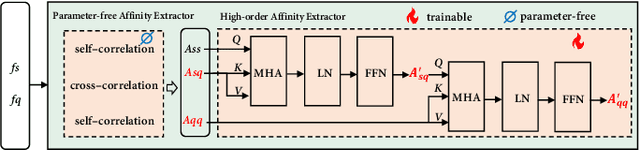
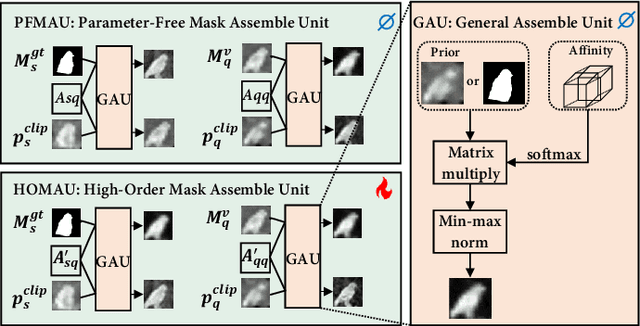
Few-shot segmentation (FSS) aims to segment the novel classes with a few annotated images. Due to CLIP's advantages of aligning visual and textual information, the integration of CLIP can enhance the generalization ability of FSS model. However, even with the CLIP model, the existing CLIP-based FSS methods are still subject to the biased prediction towards base classes, which is caused by the class-specific feature level interactions. To solve this issue, we propose a visual and textual Prior Guided Mask Assemble Network (PGMA-Net). It employs a class-agnostic mask assembly process to alleviate the bias, and formulates diverse tasks into a unified manner by assembling the prior through affinity. Specifically, the class-relevant textual and visual features are first transformed to class-agnostic prior in the form of probability map. Then, a Prior-Guided Mask Assemble Module (PGMAM) including multiple General Assemble Units (GAUs) is introduced. It considers diverse and plug-and-play interactions, such as visual-textual, inter- and intra-image, training-free, and high-order ones. Lastly, to ensure the class-agnostic ability, a Hierarchical Decoder with Channel-Drop Mechanism (HDCDM) is proposed to flexibly exploit the assembled masks and low-level features, without relying on any class-specific information. It achieves new state-of-the-art results in the FSS task, with mIoU of $77.6$ on $\text{PASCAL-}5^i$ and $59.4$ on $\text{COCO-}20^i$ in 1-shot scenario. Beyond this, we show that without extra re-training, the proposed PGMA-Net can solve bbox-level and cross-domain FSS, co-segmentation, zero-shot segmentation (ZSS) tasks, leading an any-shot segmentation framework.
Delphic Costs and Benefits in Web Search: A utilitarian and historical analysis
Aug 15, 2023We present a new framework to conceptualize and operationalize the total user experience of search, by studying the entirety of a search journey from an utilitarian point of view. Web search engines are widely perceived as "free". But search requires time and effort: in reality there are many intermingled non-monetary costs (e.g. time costs, cognitive costs, interactivity costs) and the benefits may be marred by various impairments, such as misunderstanding and misinformation. This characterization of costs and benefits appears to be inherent to the human search for information within the pursuit of some larger task: most of the costs and impairments can be identified in interactions with any web search engine, interactions with public libraries, and even in interactions with ancient oracles. To emphasize this innate connection, we call these costs and benefits Delphic, in contrast to explicitly financial costs and benefits. Our main thesis is that the users' satisfaction with a search engine mostly depends on their experience of Delphic cost and benefits, in other words on their utility. The consumer utility is correlated with classic measures of search engine quality, such as ranking, precision, recall, etc., but is not completely determined by them. To argue our thesis, we catalog the Delphic costs and benefits and show how the development of search engines over the last quarter century, from classic Information Retrieval roots to the integration of Large Language Models, was driven to a great extent by the quest of decreasing Delphic costs and increasing Delphic benefits. We hope that the Delphic costs framework will engender new ideas and new research for evaluating and improving the web experience for everyone.