 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Developmental Bootstrapping: From Simple Competences to Intelligent Human-Compatible AIs
Aug 23, 2023
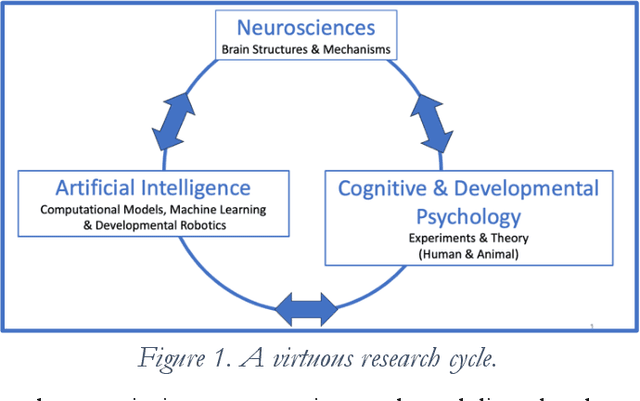

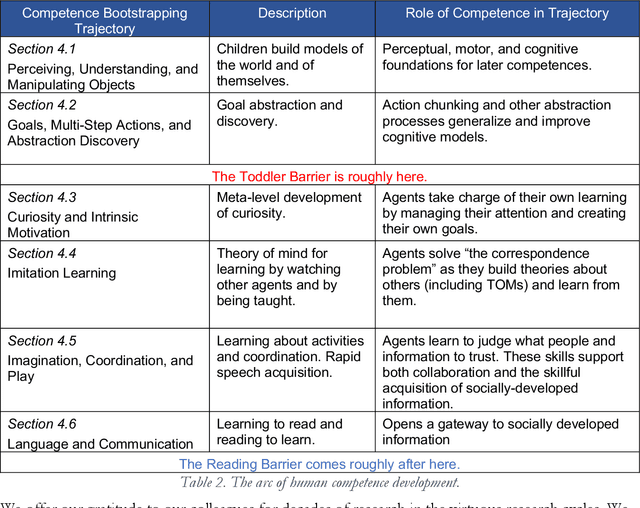
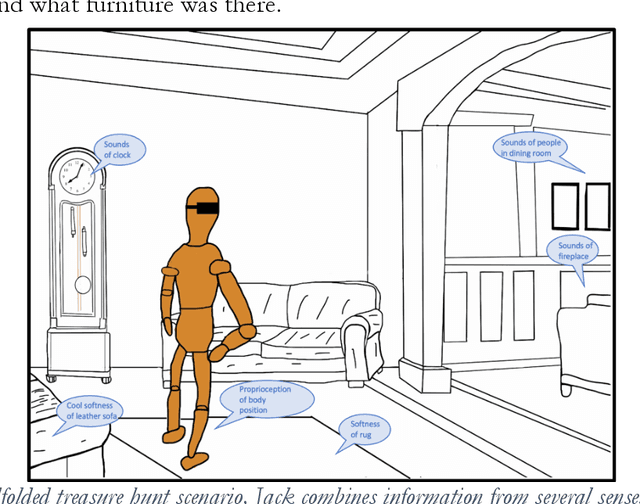
Although some AIs surpass human abilities in closed artificial worlds such as board games, in the real world they make strange mistakes and do not notice them. They cannot be instructed easily, fail to use common sense, and lack curiosity. Mainstream approaches for creating AIs include the traditional manually-constructed symbolic AI approach and the generative and deep learning AI approaches including large language models (LLMs). Although it is outside of the mainstream, the developmental bootstrapping approach may have more potential. In developmental bootstrapping, AIs develop competences like human children do. They start with innate competences. They interact with the environment and learn from their interactions. They incrementally extend their innate competences with self-developed competences. They interact and learn from people and establish perceptual, cognitive, and common grounding. They acquire the competences they need through competence bootstrapping. However, developmental robotics has not yet produced AIs with robust adult-level competences. Projects have typically stopped before reaching the Toddler Barrier. This corresponds to human infant development at about two years of age, before infant speech becomes fluent. They also do not bridge the Reading Barrier, where they could skillfully and skeptically draw on the socially developed online information resources that power LLMs. The next competences in human cognitive development involve intrinsic motivation, imitation learning, imagination, coordination, and communication. This position paper lays out the logic, prospects, gaps, and challenges for extending the practice of developmental bootstrapping to create robust, trustworthy, and human-compatible AIs.
Asking Before Action: Gather Information in Embodied Decision Making with Language Models
May 25, 2023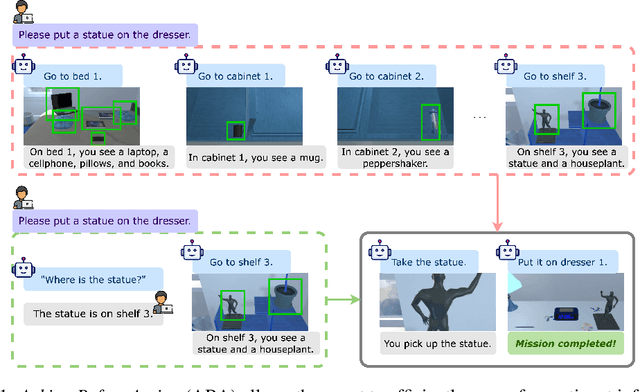
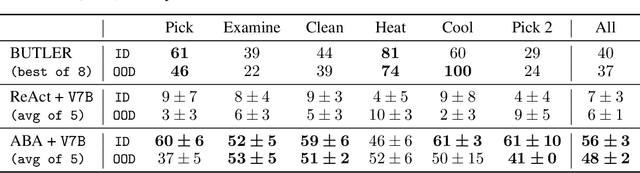
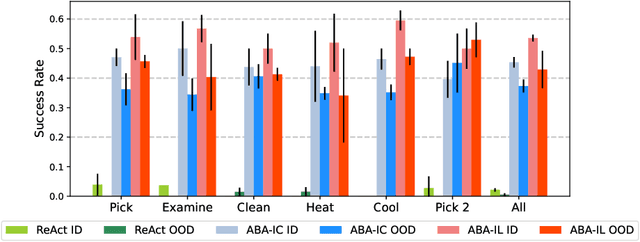
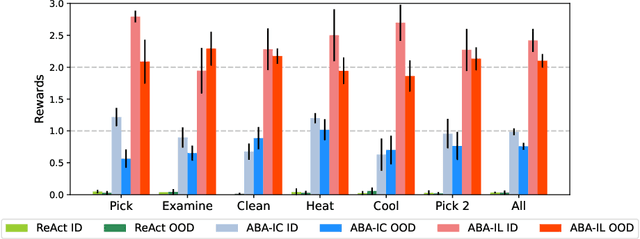
With strong capabilities of reasoning and a generic understanding of the world, Large Language Models (LLMs) have shown great potential in building versatile embodied decision making agents capable of performing diverse tasks. However, when deployed to unfamiliar environments, we show that LLM agents face challenges in efficiently gathering necessary information, leading to suboptimal performance. On the other hand, in unfamiliar scenarios, human individuals often seek additional information from their peers before taking action, leveraging external knowledge to avoid unnecessary trial and error. Building upon this intuition, we propose \textit{Asking Before Action} (ABA), a method that empowers the agent to proactively query external sources for pertinent information using natural language during their interactions in the environment. In this way, the agent is able to enhance its efficiency and performance by mitigating wasteful steps and circumventing the difficulties associated with exploration in unfamiliar environments. We empirically evaluate our method on an embodied decision making benchmark, ALFWorld, and demonstrate that despite modest modifications in prompts, our method exceeds baseline LLM agents by more than $40$%. Further experiments on two variants of ALFWorld illustrate that by imitation learning, ABA effectively retains and reuses queried and known information in subsequent tasks, mitigating the need for repetitive inquiries. Both qualitative and quantitative results exhibit remarkable performance on tasks that previous methods struggle to solve.
Dynamic Inter-treatment Information Sharing for Heterogeneous Treatment Effects Estimation
May 25, 2023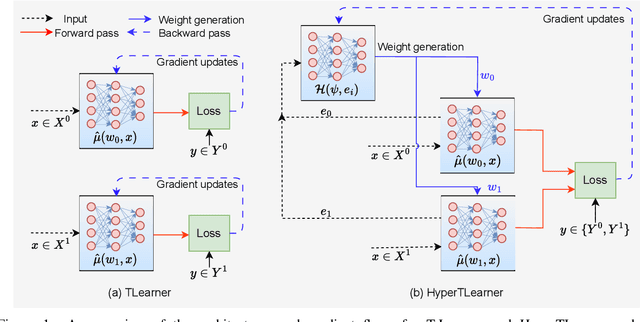
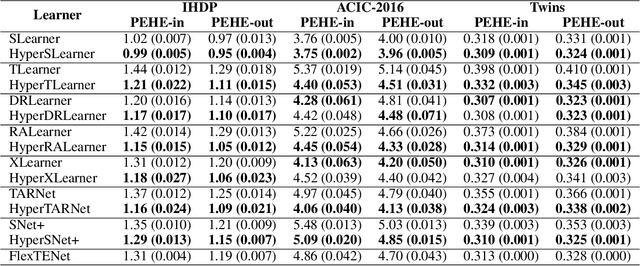
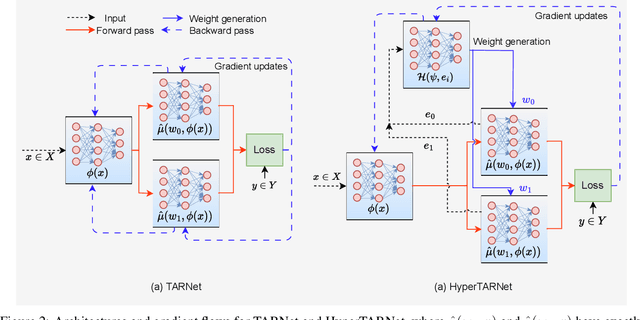
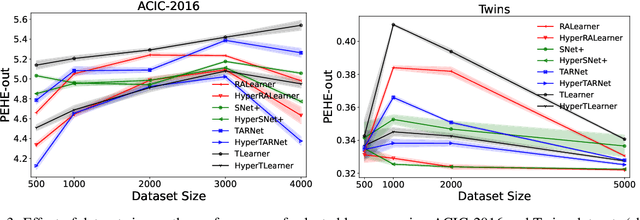
Existing heterogeneous treatment effects learners, also known as conditional average treatment effects (CATE) learners, lack a general mechanism for end-to-end inter-treatment information sharing, and data have to be split among potential outcome functions to train CATE learners which can lead to biased estimates with limited observational datasets. To address this issue, we propose a novel deep learning-based framework to train CATE learners that facilitates dynamic end-to-end information sharing among treatment groups. The framework is based on \textit{soft weight sharing} of \textit{hypernetworks}, which offers advantages such as parameter efficiency, faster training, and improved results. The proposed framework complements existing CATE learners and introduces a new class of uncertainty-aware CATE learners that we refer to as \textit{HyperCATE}. We develop HyperCATE versions of commonly used CATE learners and evaluate them on IHDP, ACIC-2016, and Twins benchmarks. Our experimental results show that the proposed framework improves the CATE estimation error via counterfactual inference, with increasing effectiveness for smaller datasets.
Empowering Vision-Language Models to Follow Interleaved Vision-Language Instructions
Aug 10, 2023

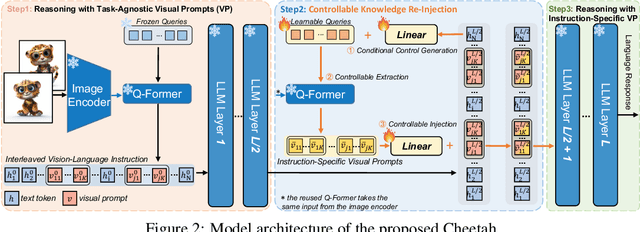
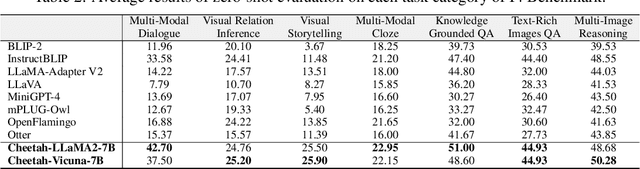
Multimodal Large Language Models (MLLMs) have recently sparked significant interest, which demonstrates emergent capabilities to serve as a general-purpose model for various vision-language tasks. However, existing methods mainly focus on limited types of instructions with a single image as visual context, which hinders the widespread availability of MLLMs. In this paper, we introduce the I4 benchmark to comprehensively evaluate the instruction following ability on complicated interleaved vision-language instructions, which involve intricate image-text sequential context, covering a diverse range of scenarios (e.g., visually-rich webpages/textbooks, lecture slides, embodied dialogue). Systematic evaluation on our I4 benchmark reveals a common defect of existing methods: the Visual Prompt Generator (VPG) trained on image-captioning alignment objective tends to attend to common foreground information for captioning but struggles to extract specific information required by particular tasks. To address this issue, we propose a generic and lightweight controllable knowledge re-injection module, which utilizes the sophisticated reasoning ability of LLMs to control the VPG to conditionally extract instruction-specific visual information and re-inject it into the LLM. Further, we introduce an annotation-free cross-attention guided counterfactual image training strategy to methodically learn the proposed module by collaborating a cascade of foundation models. Enhanced by the proposed module and training strategy, we present Cheetor, a Transformer-based MLLM that can effectively handle a wide variety of interleaved vision-language instructions and achieves state-of-the-art zero-shot performance across all tasks of I4, without high-quality multimodal instruction tuning data. Cheetor also exhibits competitive performance compared with state-of-the-art instruction tuned models on MME benchmark.
Few-shot Action Recognition via Intra- and Inter-Video Information Maximization
May 10, 2023
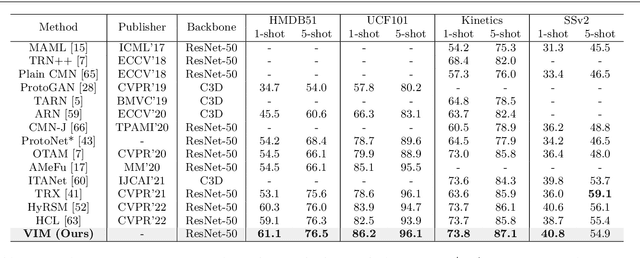

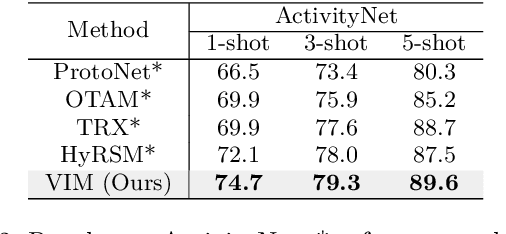
Current few-shot action recognition involves two primary sources of information for classification:(1) intra-video information, determined by frame content within a single video clip, and (2) inter-video information, measured by relationships (e.g., feature similarity) among videos. However, existing methods inadequately exploit these two information sources. In terms of intra-video information, current sampling operations for input videos may omit critical action information, reducing the utilization efficiency of video data. For the inter-video information, the action misalignment among videos makes it challenging to calculate precise relationships. Moreover, how to jointly consider both inter- and intra-video information remains under-explored for few-shot action recognition. To this end, we propose a novel framework, Video Information Maximization (VIM), for few-shot video action recognition. VIM is equipped with an adaptive spatial-temporal video sampler and a spatiotemporal action alignment model to maximize intra- and inter-video information, respectively. The video sampler adaptively selects important frames and amplifies critical spatial regions for each input video based on the task at hand. This preserves and emphasizes informative parts of video clips while eliminating interference at the data level. The alignment model performs temporal and spatial action alignment sequentially at the feature level, leading to more precise measurements of inter-video similarity. Finally, These goals are facilitated by incorporating additional loss terms based on mutual information measurement. Consequently, VIM acts to maximize the distinctiveness of video information from limited video data. Extensive experimental results on public datasets for few-shot action recognition demonstrate the effectiveness and benefits of our framework.
Isomer: Isomerous Transformer for Zero-shot Video Object Segmentation
Aug 13, 2023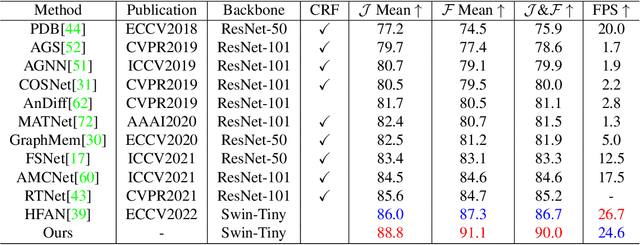
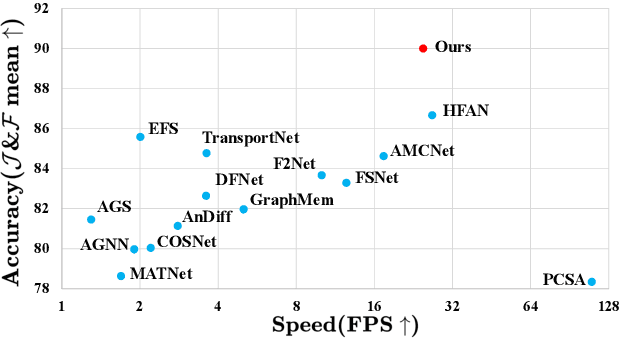

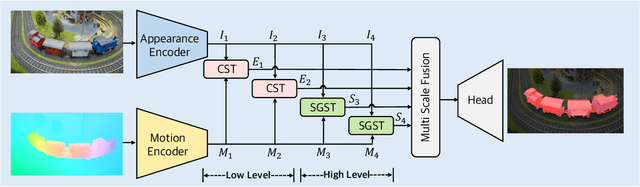
Recent leading zero-shot video object segmentation (ZVOS) works devote to integrating appearance and motion information by elaborately designing feature fusion modules and identically applying them in multiple feature stages. Our preliminary experiments show that with the strong long-range dependency modeling capacity of Transformer, simply concatenating the two modality features and feeding them to vanilla Transformers for feature fusion can distinctly benefit the performance but at a cost of heavy computation. Through further empirical analysis, we find that attention dependencies learned in Transformer in different stages exhibit completely different properties: global query-independent dependency in the low-level stages and semantic-specific dependency in the high-level stages. Motivated by the observations, we propose two Transformer variants: i) Context-Sharing Transformer (CST) that learns the global-shared contextual information within image frames with a lightweight computation. ii) Semantic Gathering-Scattering Transformer (SGST) that models the semantic correlation separately for the foreground and background and reduces the computation cost with a soft token merging mechanism. We apply CST and SGST for low-level and high-level feature fusions, respectively, formulating a level-isomerous Transformer framework for ZVOS task. Compared with the baseline that uses vanilla Transformers for multi-stage fusion, ours significantly increase the speed by 13 times and achieves new state-of-the-art ZVOS performance. Code is available at https://github.com/DLUT-yyc/Isomer.
SkipcrossNets: Adaptive Skip-cross Fusion for Road Detection
Aug 24, 2023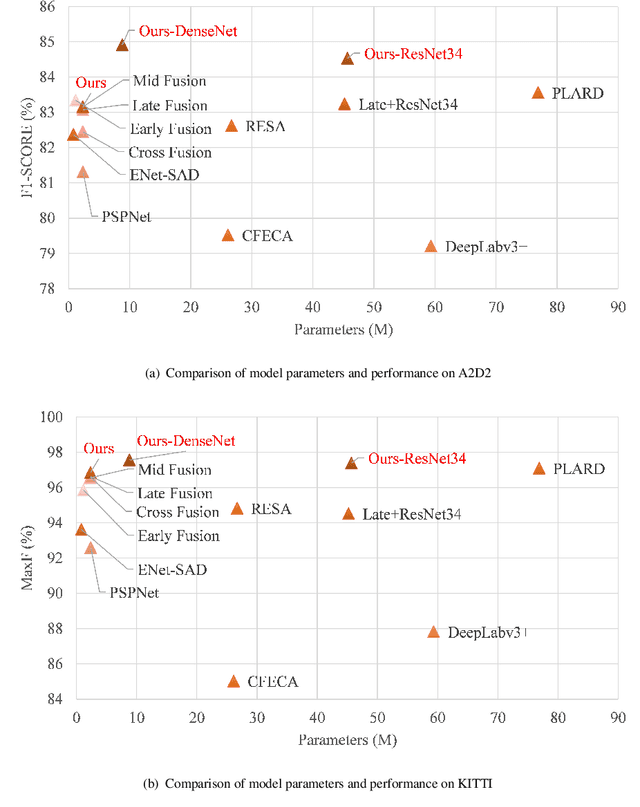
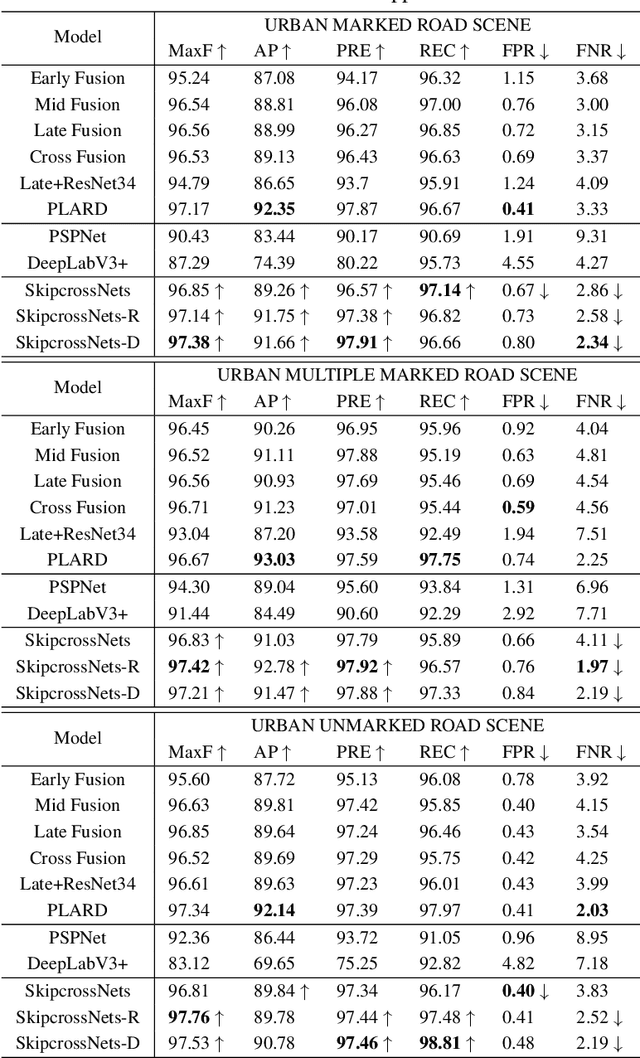

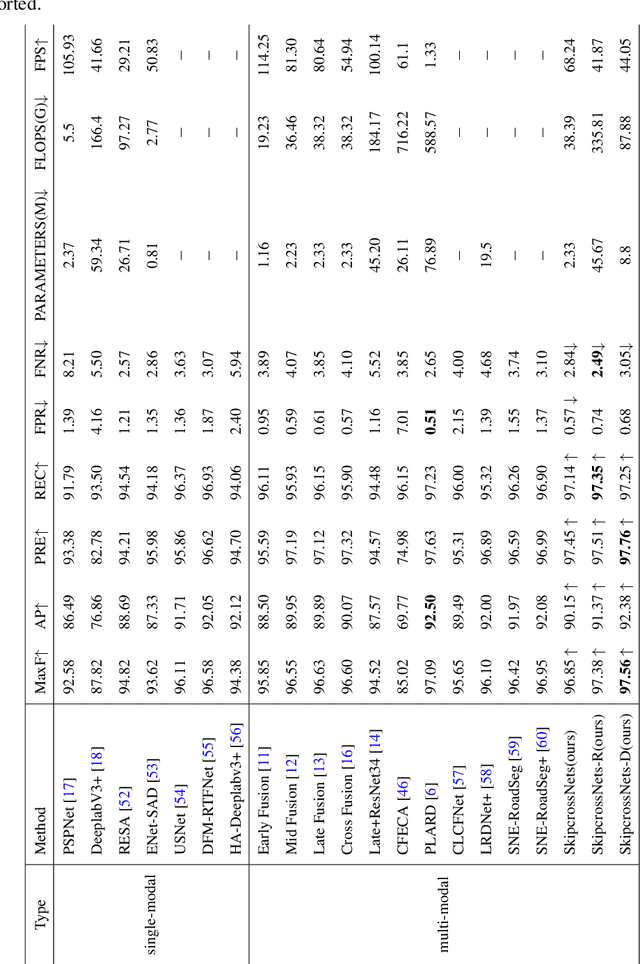
Multi-modal fusion is increasingly being used for autonomous driving tasks, as images from different modalities provide unique information for feature extraction. However, the existing two-stream networks are only fused at a specific network layer, which requires a lot of manual attempts to set up. As the CNN goes deeper, the two modal features become more and more advanced and abstract, and the fusion occurs at the feature level with a large gap, which can easily hurt the performance. In this study, we propose a novel fusion architecture called skip-cross networks (SkipcrossNets), which combines adaptively LiDAR point clouds and camera images without being bound to a certain fusion epoch. Specifically, skip-cross connects each layer to each layer in a feed-forward manner, and for each layer, the feature maps of all previous layers are used as input and its own feature maps are used as input to all subsequent layers for the other modality, enhancing feature propagation and multi-modal features fusion. This strategy facilitates selection of the most similar feature layers from two data pipelines, providing a complementary effect for sparse point cloud features during fusion processes. The network is also divided into several blocks to reduce the complexity of feature fusion and the number of model parameters. The advantages of skip-cross fusion were demonstrated through application to the KITTI and A2D2 datasets, achieving a MaxF score of 96.85% on KITTI and an F1 score of 84.84% on A2D2. The model parameters required only 2.33 MB of memory at a speed of 68.24 FPS, which could be viable for mobile terminals and embedded devices.
ShadowNet for Data-Centric Quantum System Learning
Aug 22, 2023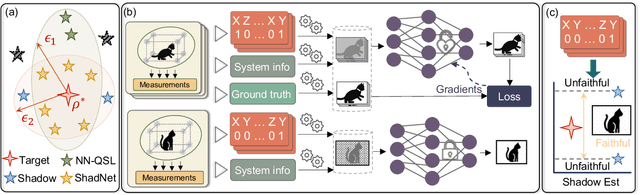
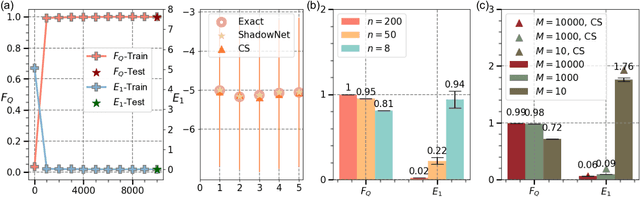
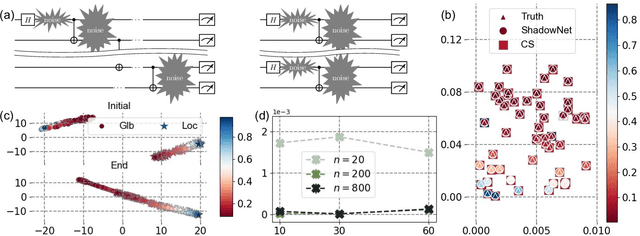
Understanding the dynamics of large quantum systems is hindered by the curse of dimensionality. Statistical learning offers new possibilities in this regime by neural-network protocols and classical shadows, while both methods have limitations: the former is plagued by the predictive uncertainty and the latter lacks the generalization ability. Here we propose a data-centric learning paradigm combining the strength of these two approaches to facilitate diverse quantum system learning (QSL) tasks. Particularly, our paradigm utilizes classical shadows along with other easily obtainable information of quantum systems to create the training dataset, which is then learnt by neural networks to unveil the underlying mapping rule of the explored QSL problem. Capitalizing on the generalization power of neural networks, this paradigm can be trained offline and excel at predicting previously unseen systems at the inference stage, even with few state copies. Besides, it inherits the characteristic of classical shadows, enabling memory-efficient storage and faithful prediction. These features underscore the immense potential of the proposed data-centric approach in discovering novel and large-scale quantum systems. For concreteness, we present the instantiation of our paradigm in quantum state tomography and direct fidelity estimation tasks and conduct numerical analysis up to 60 qubits. Our work showcases the profound prospects of data-centric artificial intelligence to advance QSL in a faithful and generalizable manner.
LAN-HDR: Luminance-based Alignment Network for High Dynamic Range Video Reconstruction
Aug 22, 2023As demands for high-quality videos continue to rise, high-resolution and high-dynamic range (HDR) imaging techniques are drawing attention. To generate an HDR video from low dynamic range (LDR) images, one of the critical steps is the motion compensation between LDR frames, for which most existing works employed the optical flow algorithm. However, these methods suffer from flow estimation errors when saturation or complicated motions exist. In this paper, we propose an end-to-end HDR video composition framework, which aligns LDR frames in the feature space and then merges aligned features into an HDR frame, without relying on pixel-domain optical flow. Specifically, we propose a luminance-based alignment network for HDR (LAN-HDR) consisting of an alignment module and a hallucination module. The alignment module aligns a frame to the adjacent reference by evaluating luminance-based attention, excluding color information. The hallucination module generates sharp details, especially for washed-out areas due to saturation. The aligned and hallucinated features are then blended adaptively to complement each other. Finally, we merge the features to generate a final HDR frame. In training, we adopt a temporal loss, in addition to frame reconstruction losses, to enhance temporal consistency and thus reduce flickering. Extensive experiments demonstrate that our method performs better or comparable to state-of-the-art methods on several benchmarks.
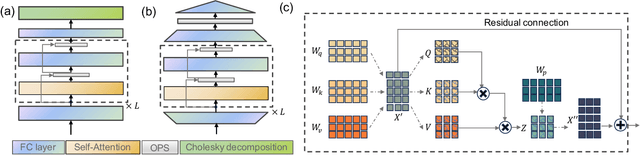
DiffCloth: Diffusion Based Garment Synthesis and Manipulation via Structural Cross-modal Semantic Alignment
Aug 22, 2023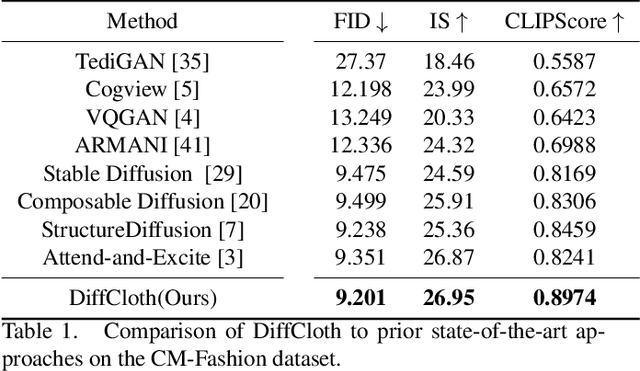

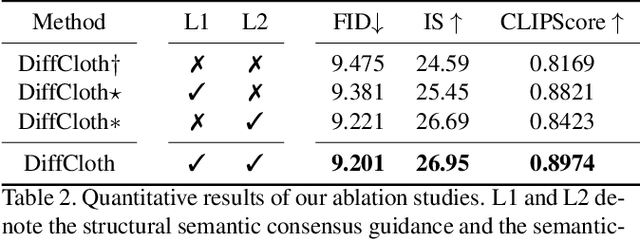
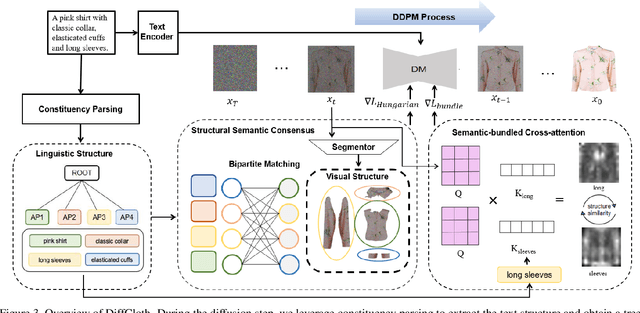
Cross-modal garment synthesis and manipulation will significantly benefit the way fashion designers generate garments and modify their designs via flexible linguistic interfaces.Current approaches follow the general text-to-image paradigm and mine cross-modal relations via simple cross-attention modules, neglecting the structural correspondence between visual and textual representations in the fashion design domain. In this work, we instead introduce DiffCloth, a diffusion-based pipeline for cross-modal garment synthesis and manipulation, which empowers diffusion models with flexible compositionality in the fashion domain by structurally aligning the cross-modal semantics. Specifically, we formulate the part-level cross-modal alignment as a bipartite matching problem between the linguistic Attribute-Phrases (AP) and the visual garment parts which are obtained via constituency parsing and semantic segmentation, respectively. To mitigate the issue of attribute confusion, we further propose a semantic-bundled cross-attention to preserve the spatial structure similarities between the attention maps of attribute adjectives and part nouns in each AP. Moreover, DiffCloth allows for manipulation of the generated results by simply replacing APs in the text prompts. The manipulation-irrelevant regions are recognized by blended masks obtained from the bundled attention maps of the APs and kept unchanged. Extensive experiments on the CM-Fashion benchmark demonstrate that DiffCloth both yields state-of-the-art garment synthesis results by leveraging the inherent structural information and supports flexible manipulation with region consistency.