 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Multimodal Approach to Device-Directed Speech Detection with Large Language Models
Mar 26, 2024
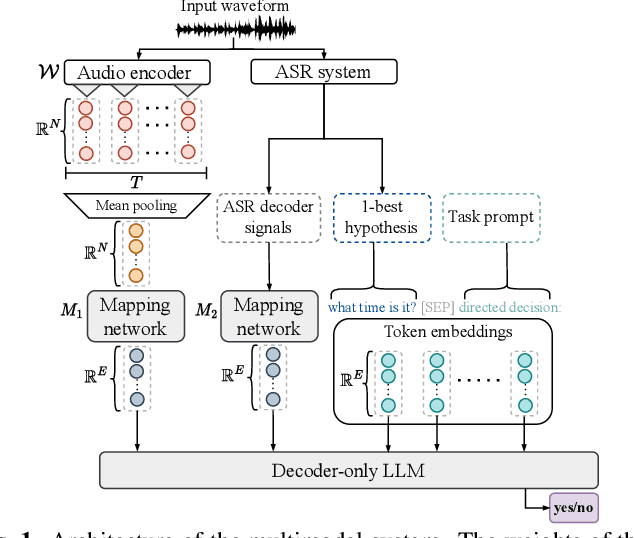
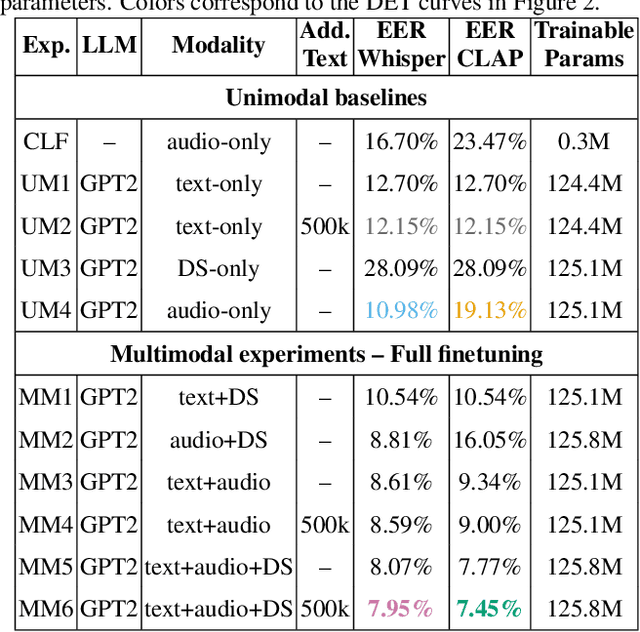
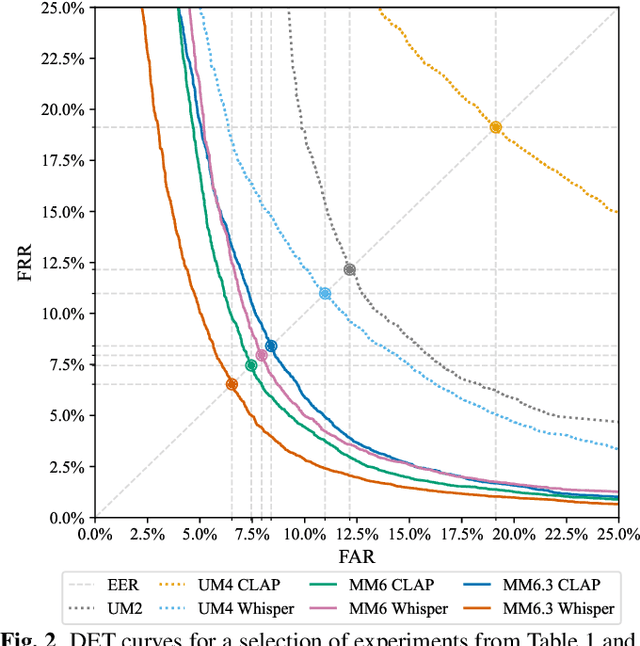

Interactions with virtual assistants typically start with a predefined trigger phrase followed by the user command. To make interactions with the assistant more intuitive, we explore whether it is feasible to drop the requirement that users must begin each command with a trigger phrase. We explore this task in three ways: First, we train classifiers using only acoustic information obtained from the audio waveform. Second, we take the decoder outputs of an automatic speech recognition (ASR) system, such as 1-best hypotheses, as input features to a large language model (LLM). Finally, we explore a multimodal system that combines acoustic and lexical features, as well as ASR decoder signals in an LLM. Using multimodal information yields relative equal-error-rate improvements over text-only and audio-only models of up to 39% and 61%. Increasing the size of the LLM and training with low-rank adaption leads to further relative EER reductions of up to 18% on our dataset.
MedPromptX: Grounded Multimodal Prompting for Chest X-ray Diagnosis
Mar 29, 2024Chest X-ray images are commonly used for predicting acute and chronic cardiopulmonary conditions, but efforts to integrate them with structured clinical data face challenges due to incomplete electronic health records (EHR). This paper introduces MedPromptX, the first model to integrate multimodal large language models (MLLMs), few-shot prompting (FP) and visual grounding (VG) to combine imagery with EHR data for chest X-ray diagnosis. A pre-trained MLLM is utilized to complement the missing EHR information, providing a comprehensive understanding of patients' medical history. Additionally, FP reduces the necessity for extensive training of MLLMs while effectively tackling the issue of hallucination. Nevertheless, the process of determining the optimal number of few-shot examples and selecting high-quality candidates can be burdensome, yet it profoundly influences model performance. Hence, we propose a new technique that dynamically refines few-shot data for real-time adjustment to new patient scenarios. Moreover, VG aids in focusing the model's attention on relevant regions of interest in X-ray images, enhancing the identification of abnormalities. We release MedPromptX-VQA, a new in-context visual question answering dataset encompassing interleaved image and EHR data derived from MIMIC-IV and MIMIC-CXR databases. Results demonstrate the SOTA performance of MedPromptX, achieving an 11% improvement in F1-score compared to the baselines. Code and data are available at https://github.com/BioMedIA-MBZUAI/MedPromptX
Uncovering Bias in Large Vision-Language Models with Counterfactuals
Mar 29, 2024With the advent of Large Language Models (LLMs) possessing increasingly impressive capabilities, a number of Large Vision-Language Models (LVLMs) have been proposed to augment LLMs with visual inputs. Such models condition generated text on both an input image and a text prompt, enabling a variety of use cases such as visual question answering and multimodal chat. While prior studies have examined the social biases contained in text generated by LLMs, this topic has been relatively unexplored in LVLMs. Examining social biases in LVLMs is particularly challenging due to the confounding contributions of bias induced by information contained across the text and visual modalities. To address this challenging problem, we conduct a large-scale study of text generated by different LVLMs under counterfactual changes to input images. Specifically, we present LVLMs with identical open-ended text prompts while conditioning on images from different counterfactual sets, where each set contains images which are largely identical in their depiction of a common subject (e.g., a doctor), but vary only in terms of intersectional social attributes (e.g., race and gender). We comprehensively evaluate the text produced by different LVLMs under this counterfactual generation setting and find that social attributes such as race, gender, and physical characteristics depicted in input images can significantly influence toxicity and the generation of competency-associated words.
Cross-Lingual Transfer Robustness to Lower-Resource Languages on Adversarial Datasets
Mar 29, 2024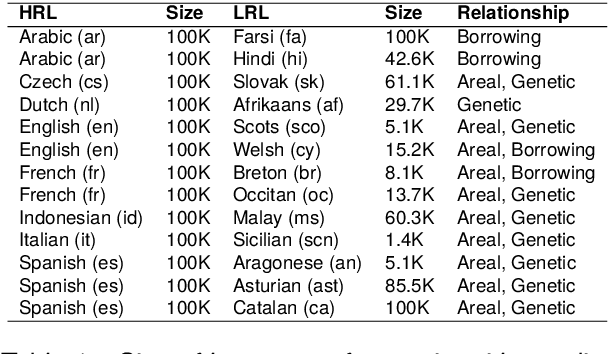
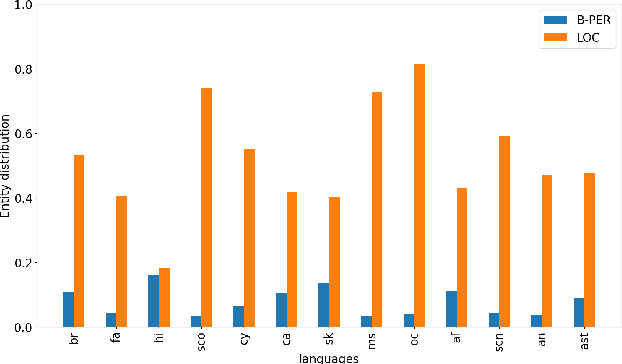

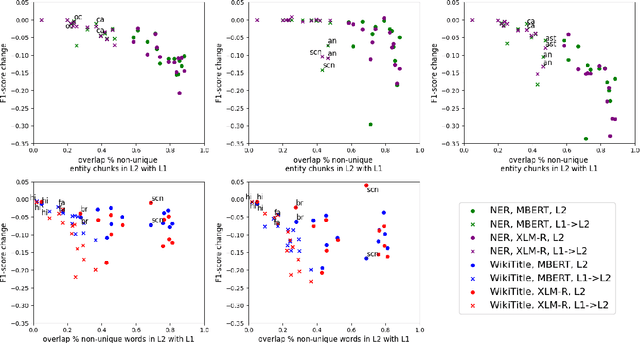
Multilingual Language Models (MLLMs) exhibit robust cross-lingual transfer capabilities, or the ability to leverage information acquired in a source language and apply it to a target language. These capabilities find practical applications in well-established Natural Language Processing (NLP) tasks such as Named Entity Recognition (NER). This study aims to investigate the effectiveness of a source language when applied to a target language, particularly in the context of perturbing the input test set. We evaluate on 13 pairs of languages, each including one high-resource language (HRL) and one low-resource language (LRL) with a geographic, genetic, or borrowing relationship. We evaluate two well-known MLLMs--MBERT and XLM-R--on these pairs, in native LRL and cross-lingual transfer settings, in two tasks, under a set of different perturbations. Our findings indicate that NER cross-lingual transfer depends largely on the overlap of entity chunks. If a source and target language have more entities in common, the transfer ability is stronger. Models using cross-lingual transfer also appear to be somewhat more robust to certain perturbations of the input, perhaps indicating an ability to leverage stronger representations derived from the HRL. Our research provides valuable insights into cross-lingual transfer and its implications for NLP applications, and underscores the need to consider linguistic nuances and potential limitations when employing MLLMs across distinct languages.
Unsupervised Tumor-Aware Distillation for Multi-Modal Brain Image Translation
Mar 29, 2024
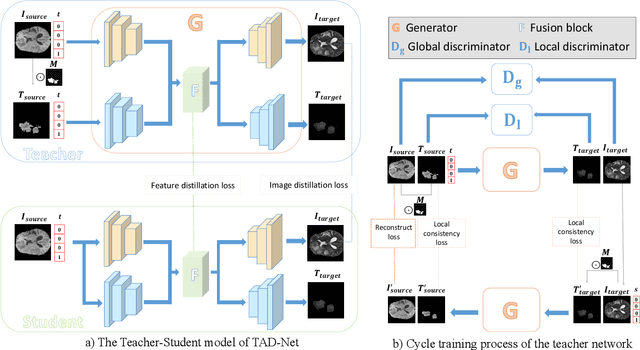
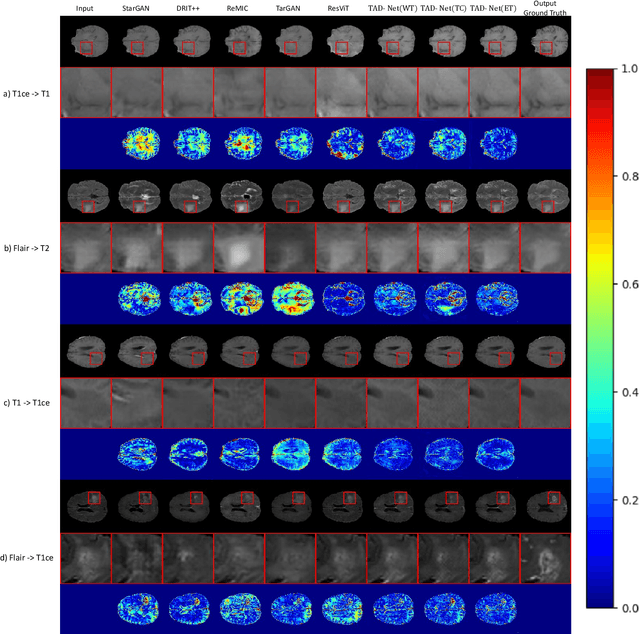

Multi-modal brain images from MRI scans are widely used in clinical diagnosis to provide complementary information from different modalities. However, obtaining fully paired multi-modal images in practice is challenging due to various factors, such as time, cost, and artifacts, resulting in modality-missing brain images. To address this problem, unsupervised multi-modal brain image translation has been extensively studied. Existing methods suffer from the problem of brain tumor deformation during translation, as they fail to focus on the tumor areas when translating the whole images. In this paper, we propose an unsupervised tumor-aware distillation teacher-student network called UTAD-Net, which is capable of perceiving and translating tumor areas precisely. Specifically, our model consists of two parts: a teacher network and a student network. The teacher network learns an end-to-end mapping from source to target modality using unpaired images and corresponding tumor masks first. Then, the translation knowledge is distilled into the student network, enabling it to generate more realistic tumor areas and whole images without masks. Experiments show that our model achieves competitive performance on both quantitative and qualitative evaluations of image quality compared with state-of-the-art methods. Furthermore, we demonstrate the effectiveness of the generated images on downstream segmentation tasks. Our code is available at https://github.com/scut-HC/UTAD-Net.
Nonparametric Bellman Mappings for Reinforcement Learning: Application to Robust Adaptive Filtering
Mar 29, 2024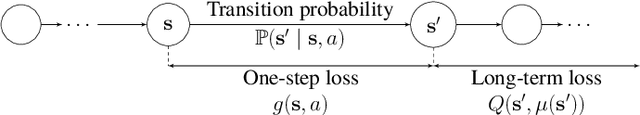
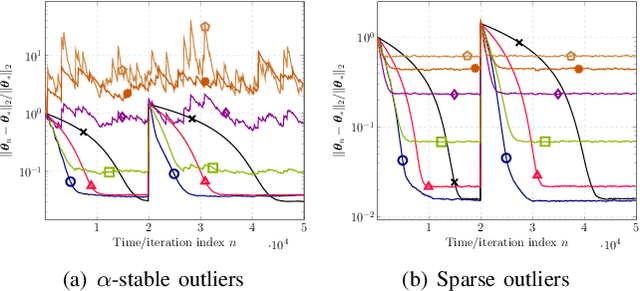
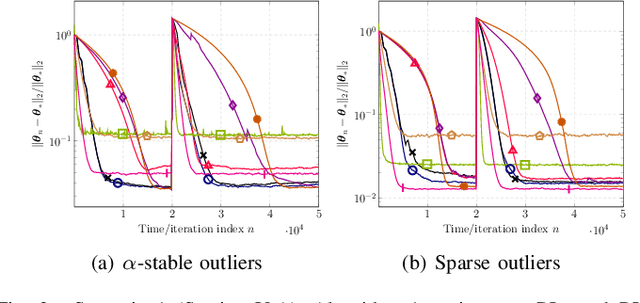
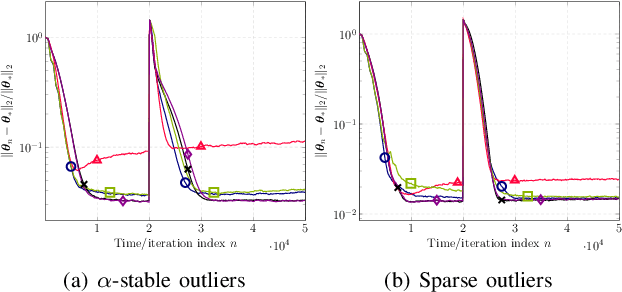
This paper designs novel nonparametric Bellman mappings in reproducing kernel Hilbert spaces (RKHSs) for reinforcement learning (RL). The proposed mappings benefit from the rich approximating properties of RKHSs, adopt no assumptions on the statistics of the data owing to their nonparametric nature, require no knowledge on transition probabilities of Markov decision processes, and may operate without any training data. Moreover, they allow for sampling on-the-fly via the design of trajectory samples, re-use past test data via experience replay, effect dimensionality reduction by random Fourier features, and enable computationally lightweight operations to fit into efficient online or time-adaptive learning. The paper offers also a variational framework to design the free parameters of the proposed Bellman mappings, and shows that appropriate choices of those parameters yield several popular Bellman-mapping designs. As an application, the proposed mappings are employed to offer a novel solution to the problem of countering outliers in adaptive filtering. More specifically, with no prior information on the statistics of the outliers and no training data, a policy-iteration algorithm is introduced to select online, per time instance, the ``optimal'' coefficient p in the least-mean-p-power-error method. Numerical tests on synthetic data showcase, in most of the cases, the superior performance of the proposed solution over several RL and non-RL schemes.
NIGHT -- Non-Line-of-Sight Imaging from Indirect Time of Flight Data
Mar 28, 2024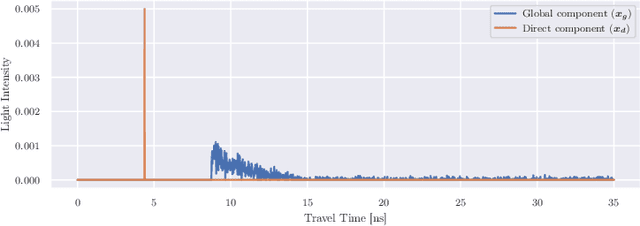
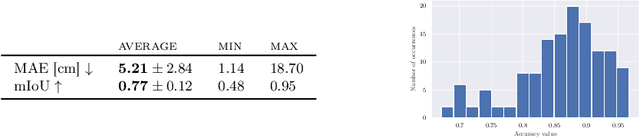
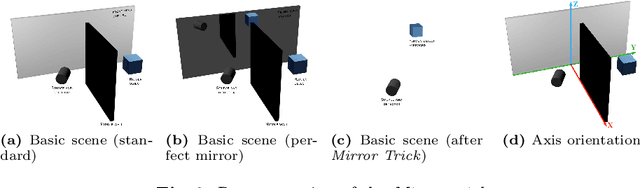

The acquisition of objects outside the Line-of-Sight of cameras is a very intriguing but also extremely challenging research topic. Recent works showed the feasibility of this idea exploiting transient imaging data produced by custom direct Time of Flight sensors. In this paper, for the first time, we tackle this problem using only data from an off-the-shelf indirect Time of Flight sensor without any further hardware requirement. We introduced a Deep Learning model able to re-frame the surfaces where light bounces happen as a virtual mirror. This modeling makes the task easier to handle and also facilitates the construction of annotated training data. From the obtained data it is possible to retrieve the depth information of the hidden scene. We also provide a first-in-its-kind synthetic dataset for the task and demonstrate the feasibility of the proposed idea over it.
Few-Shot Class Incremental Learning with Attention-Aware Self-Adaptive Prompt
Mar 25, 2024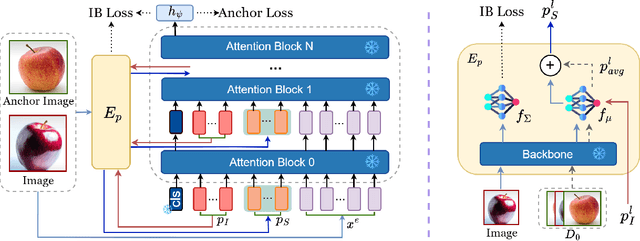
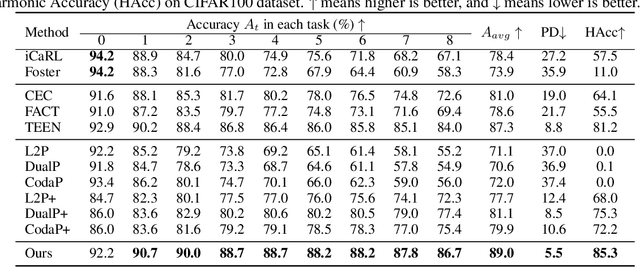
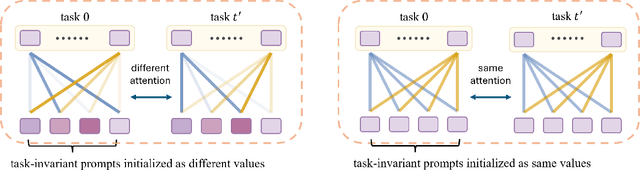
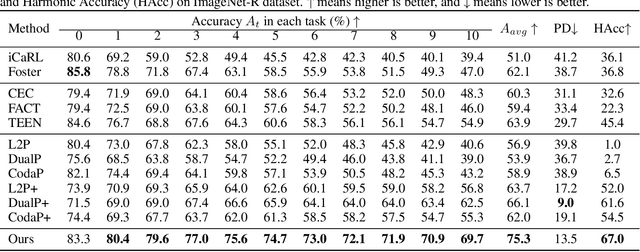
Few-Shot Class-Incremental Learning (FSCIL) models aim to incrementally learn new classes with scarce samples while preserving knowledge of old ones. Existing FSCIL methods usually fine-tune the entire backbone, leading to overfitting and hindering the potential to learn new classes. On the other hand, recent prompt-based CIL approaches alleviate forgetting by training prompts with sufficient data in each task. In this work, we propose a novel framework named Attention-aware Self-adaptive Prompt (ASP). ASP encourages task-invariant prompts to capture shared knowledge by reducing specific information from the attention aspect. Additionally, self-adaptive task-specific prompts in ASP provide specific information and transfer knowledge from old classes to new classes with an Information Bottleneck learning objective. In summary, ASP prevents overfitting on base task and does not require enormous data in few-shot incremental tasks. Extensive experiments on three benchmark datasets validate that ASP consistently outperforms state-of-the-art FSCIL and prompt-based CIL methods in terms of both learning new classes and mitigating forgetting.
Non-verbal information in spontaneous speech -- towards a new framework of analysis
Mar 13, 2024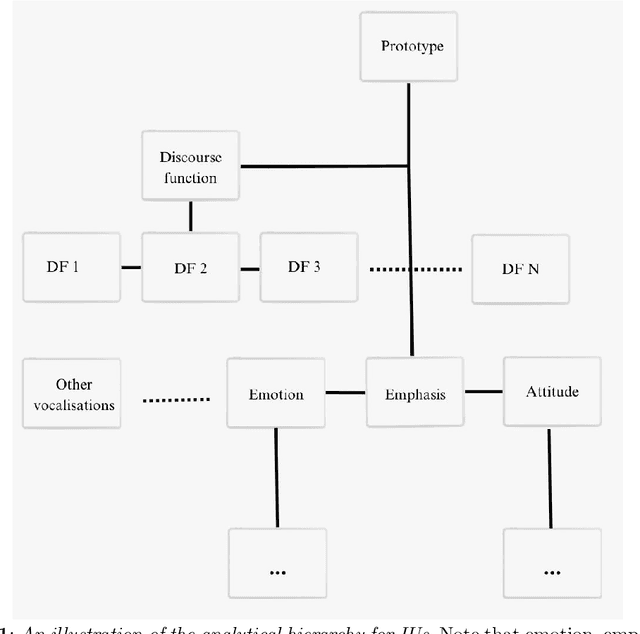
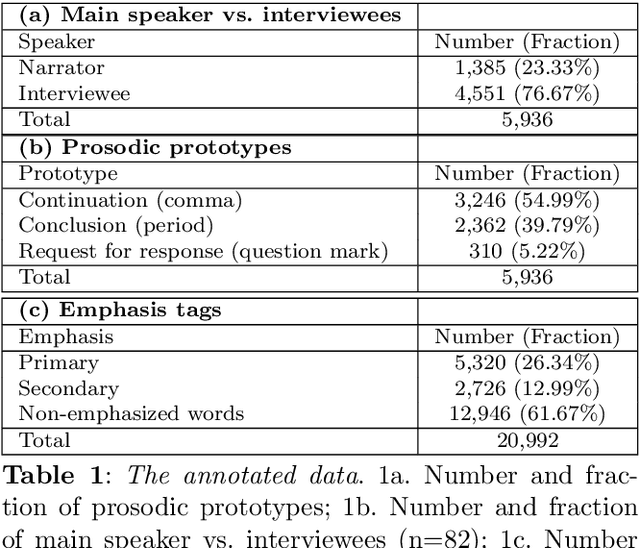
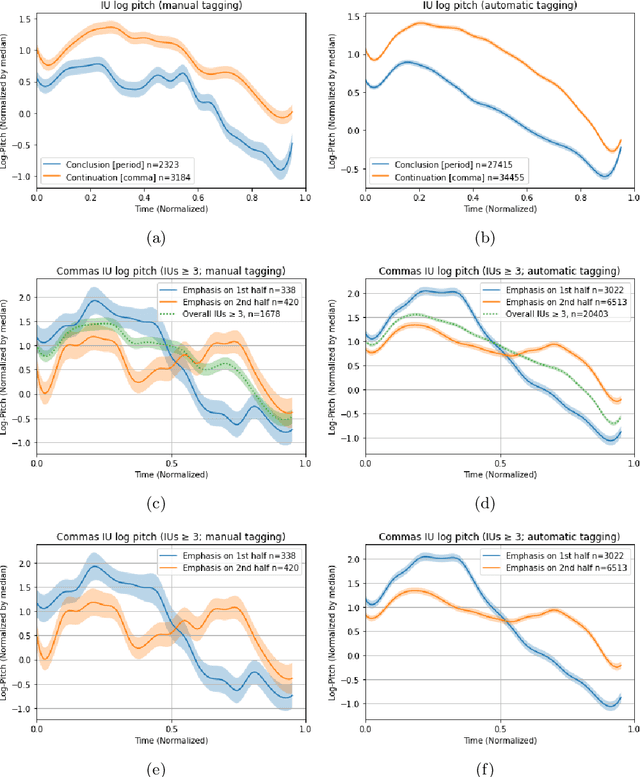
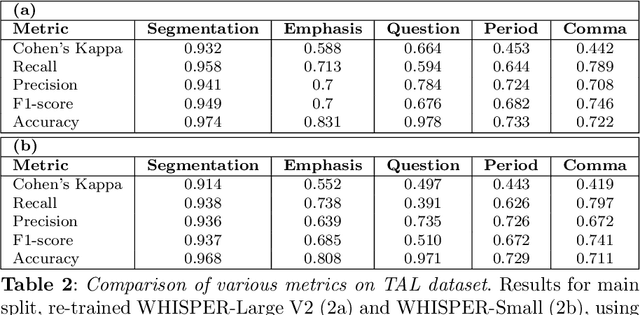
Non-verbal signals in speech are encoded by prosody and carry information that ranges from conversation action to attitude and emotion. Despite its importance, the principles that govern prosodic structure are not yet adequately understood. This paper offers an analytical schema and a technological proof-of-concept for the categorization of prosodic signals and their association with meaning. The schema interprets surface-representations of multi-layered prosodic events. As a first step towards implementation, we present a classification process that disentangles prosodic phenomena of three orders. It relies on fine-tuning a pre-trained speech recognition model, enabling the simultaneous multi-class/multi-label detection. It generalizes over a large variety of spontaneous data, performing on a par with, or superior to, human annotation. In addition to a standardized formalization of prosody, disentangling prosodic patterns can direct a theory of communication and speech organization. A welcome by-product is an interpretation of prosody that will enhance speech- and language-related technologies.
Towards Unified Multi-Modal Personalization: Large Vision-Language Models for Generative Recommendation and Beyond
Mar 27, 2024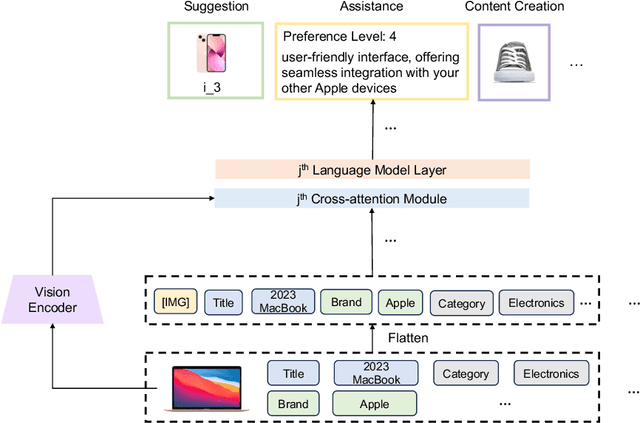
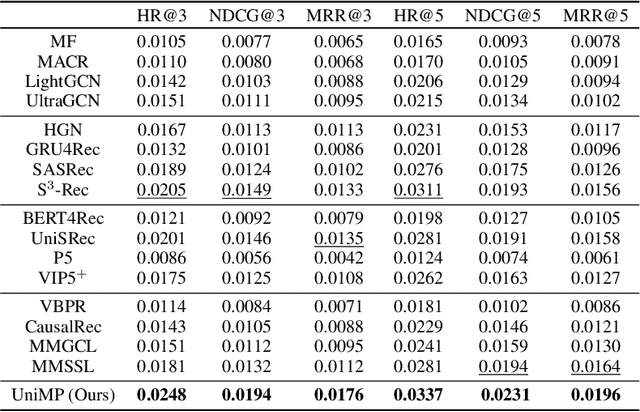
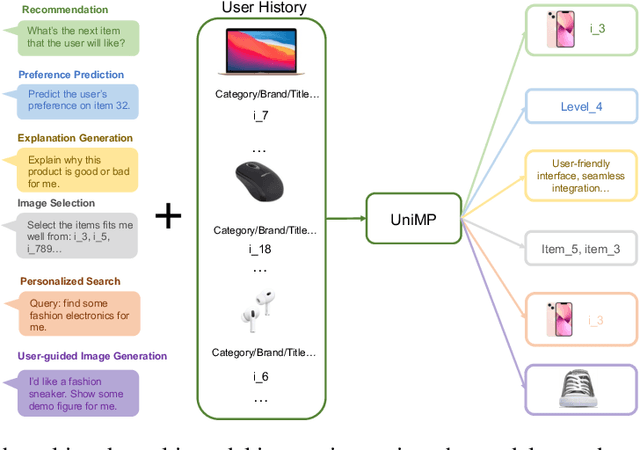
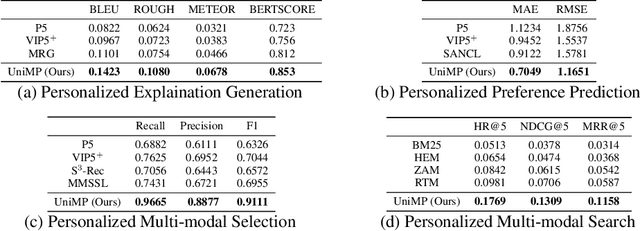
Developing a universal model that can effectively harness heterogeneous resources and respond to a wide range of personalized needs has been a longstanding community aspiration. Our daily choices, especially in domains like fashion and retail, are substantially shaped by multi-modal data, such as pictures and textual descriptions. These modalities not only offer intuitive guidance but also cater to personalized user preferences. However, the predominant personalization approaches mainly focus on the ID or text-based recommendation problem, failing to comprehend the information spanning various tasks or modalities. In this paper, our goal is to establish a Unified paradigm for Multi-modal Personalization systems (UniMP), which effectively leverages multi-modal data while eliminating the complexities associated with task- and modality-specific customization. We argue that the advancements in foundational generative modeling have provided the flexibility and effectiveness necessary to achieve the objective. In light of this, we develop a generic and extensible personalization generative framework, that can handle a wide range of personalized needs including item recommendation, product search, preference prediction, explanation generation, and further user-guided image generation. Our methodology enhances the capabilities of foundational language models for personalized tasks by seamlessly ingesting interleaved cross-modal user history information, ensuring a more precise and customized experience for users. To train and evaluate the proposed multi-modal personalized tasks, we also introduce a novel and comprehensive benchmark covering a variety of user requirements. Our experiments on the real-world benchmark showcase the model's potential, outperforming competitive methods specialized for each task.