 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Graph Encoding and Neural Network Approaches for Volleyball Analytics: From Game Outcome to Individual Play Predictions
Aug 22, 2023
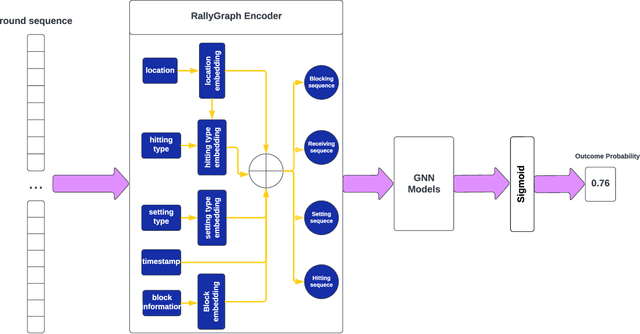
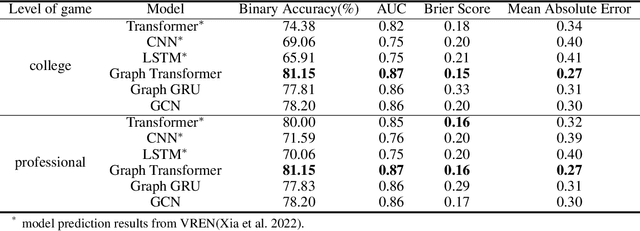

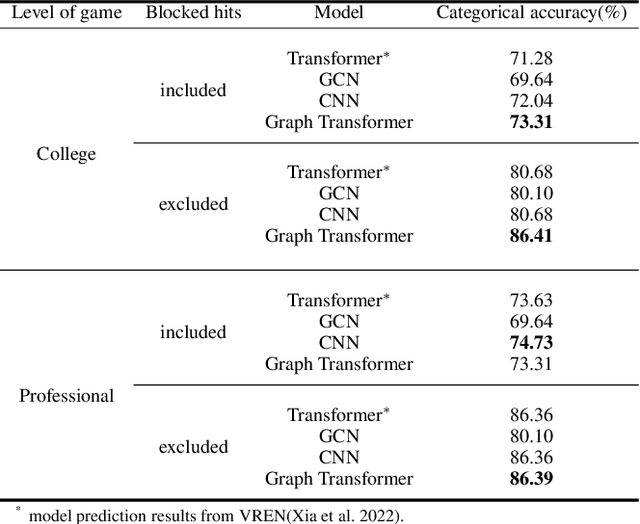
This research aims to improve the accuracy of complex volleyball predictions and provide more meaningful insights to coaches and players. We introduce a specialized graph encoding technique to add additional contact-by-contact volleyball context to an already available volleyball dataset without any additional data gathering. We demonstrate the potential benefits of using graph neural networks (GNNs) on this enriched dataset for three different volleyball prediction tasks: rally outcome prediction, set location prediction, and hit type prediction. We compare the performance of our graph-based models to baseline models and analyze the results to better understand the underlying relationships in a volleyball rally. Our results show that the use of GNNs with our graph encoding yields a much more advanced analysis of the data, which noticeably improves prediction results overall. We also show that these baseline tasks can be significantly improved with simple adjustments, such as removing blocked hits. Lastly, we demonstrate the importance of choosing a model architecture that will better extract the important information for a certain task. Overall, our study showcases the potential strengths and weaknesses of using graph encodings in sports data analytics and hopefully will inspire future improvements in machine learning strategies across sports and applications by using graphbased encodings.
Exploring Unsupervised Cell Recognition with Prior Self-activation Maps
Aug 22, 2023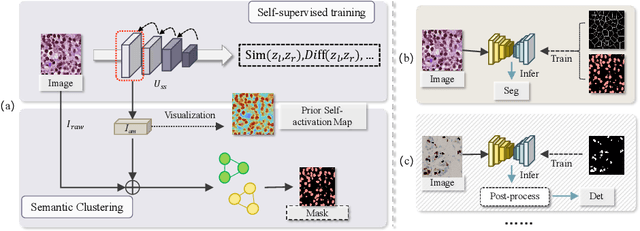
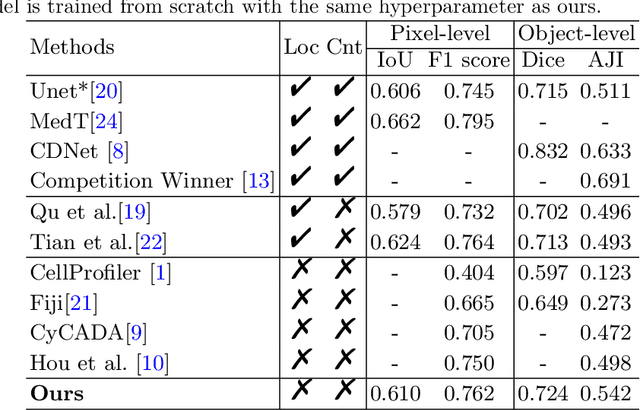
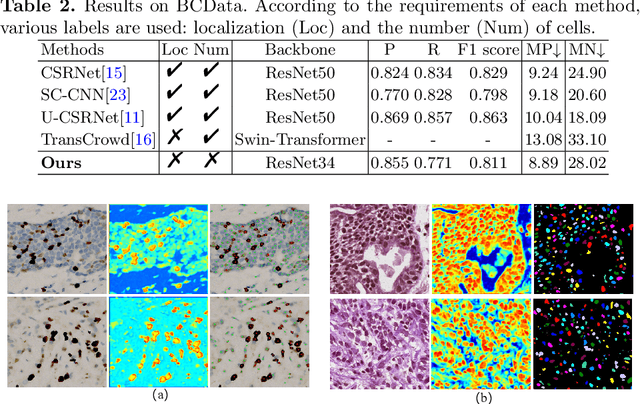
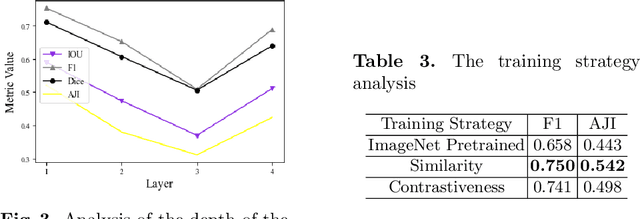
The success of supervised deep learning models on cell recognition tasks relies on detailed annotations. Many previous works have managed to reduce the dependency on labels. However, considering the large number of cells contained in a patch, costly and inefficient labeling is still inevitable. To this end, we explored label-free methods for cell recognition. Prior self-activation maps (PSM) are proposed to generate pseudo masks as training targets. To be specific, an activation network is trained with self-supervised learning. The gradient information in the shallow layers of the network is aggregated to generate prior self-activation maps. Afterward, a semantic clustering module is then introduced as a pipeline to transform PSMs to pixel-level semantic pseudo masks for downstream tasks. We evaluated our method on two histological datasets: MoNuSeg (cell segmentation) and BCData (multi-class cell detection). Compared with other fully-supervised and weakly-supervised methods, our method can achieve competitive performance without any manual annotations. Our simple but effective framework can also achieve multi-class cell detection which can not be done by existing unsupervised methods. The results show the potential of PSMs that might inspire other research to deal with the hunger for labels in medical area.
Dynamic Inter-treatment Information Sharing for Heterogeneous Treatment Effects Estimation
May 25, 2023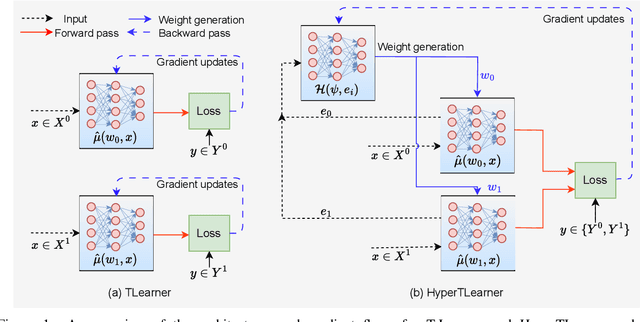
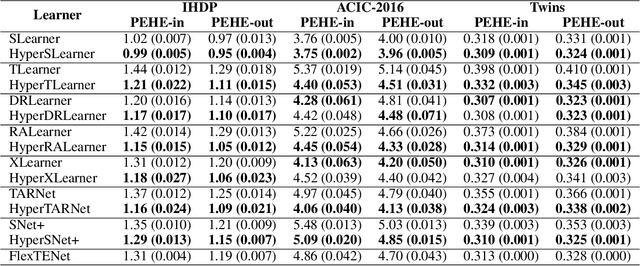
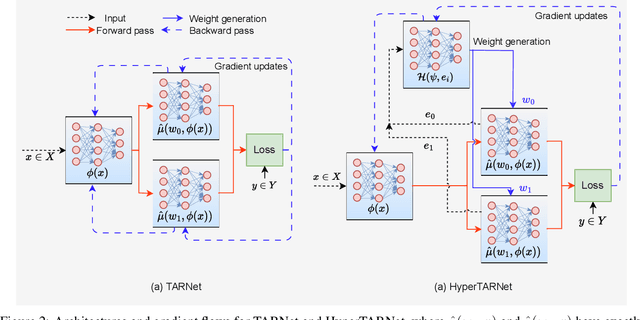
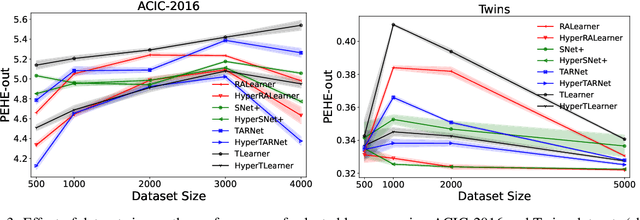
Existing heterogeneous treatment effects learners, also known as conditional average treatment effects (CATE) learners, lack a general mechanism for end-to-end inter-treatment information sharing, and data have to be split among potential outcome functions to train CATE learners which can lead to biased estimates with limited observational datasets. To address this issue, we propose a novel deep learning-based framework to train CATE learners that facilitates dynamic end-to-end information sharing among treatment groups. The framework is based on \textit{soft weight sharing} of \textit{hypernetworks}, which offers advantages such as parameter efficiency, faster training, and improved results. The proposed framework complements existing CATE learners and introduces a new class of uncertainty-aware CATE learners that we refer to as \textit{HyperCATE}. We develop HyperCATE versions of commonly used CATE learners and evaluate them on IHDP, ACIC-2016, and Twins benchmarks. Our experimental results show that the proposed framework improves the CATE estimation error via counterfactual inference, with increasing effectiveness for smaller datasets.
Asking Before Action: Gather Information in Embodied Decision Making with Language Models
May 25, 2023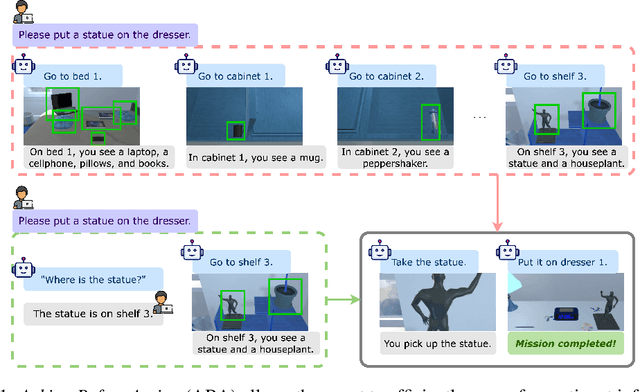
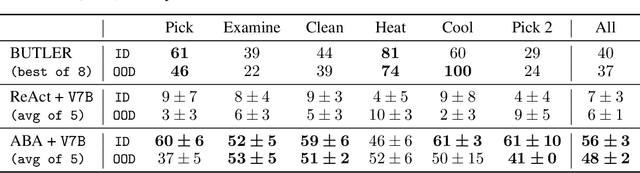
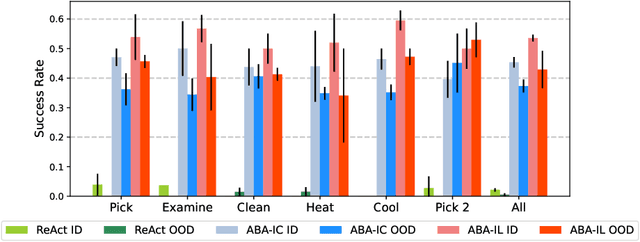
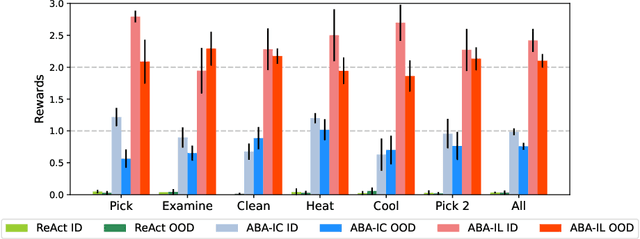
With strong capabilities of reasoning and a generic understanding of the world, Large Language Models (LLMs) have shown great potential in building versatile embodied decision making agents capable of performing diverse tasks. However, when deployed to unfamiliar environments, we show that LLM agents face challenges in efficiently gathering necessary information, leading to suboptimal performance. On the other hand, in unfamiliar scenarios, human individuals often seek additional information from their peers before taking action, leveraging external knowledge to avoid unnecessary trial and error. Building upon this intuition, we propose \textit{Asking Before Action} (ABA), a method that empowers the agent to proactively query external sources for pertinent information using natural language during their interactions in the environment. In this way, the agent is able to enhance its efficiency and performance by mitigating wasteful steps and circumventing the difficulties associated with exploration in unfamiliar environments. We empirically evaluate our method on an embodied decision making benchmark, ALFWorld, and demonstrate that despite modest modifications in prompts, our method exceeds baseline LLM agents by more than $40$%. Further experiments on two variants of ALFWorld illustrate that by imitation learning, ABA effectively retains and reuses queried and known information in subsequent tasks, mitigating the need for repetitive inquiries. Both qualitative and quantitative results exhibit remarkable performance on tasks that previous methods struggle to solve.
VIGC: Visual Instruction Generation and Correction
Aug 24, 2023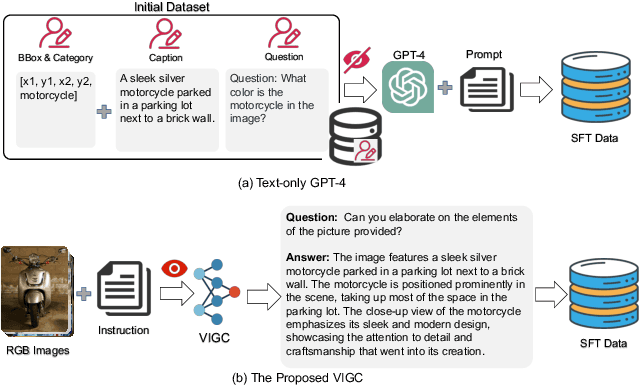
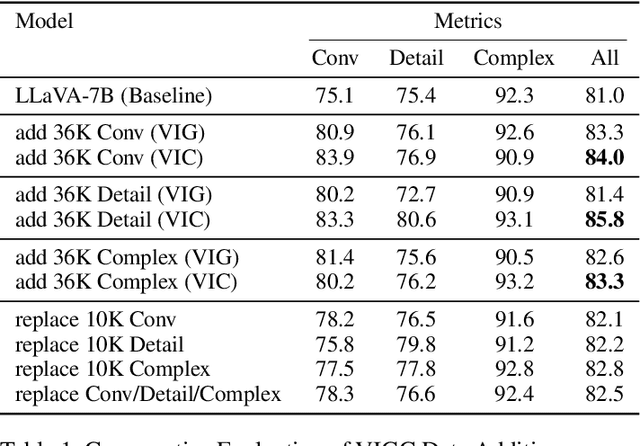
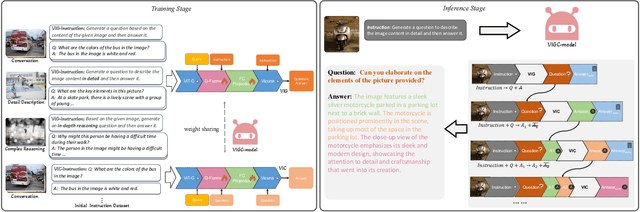

The integration of visual encoders and large language models (LLMs) has driven recent progress in multimodal large language models (MLLMs). However, the scarcity of high-quality instruction-tuning data for vision-language tasks remains a challenge. The current leading paradigm, such as LLaVA, relies on language-only GPT-4 to generate data, which requires pre-annotated image captions and detection bounding boxes, suffering from understanding image details. A practical solution to this problem would be to utilize the available multimodal large language models (MLLMs) to generate instruction data for vision-language tasks. However, it's worth noting that the currently accessible MLLMs are not as powerful as their LLM counterparts, as they tend to produce inadequate responses and generate false information. As a solution for addressing the current issue, this paper proposes the Visual Instruction Generation and Correction (VIGC) framework that enables multimodal large language models to generate instruction-tuning data and progressively enhance its quality on-the-fly. Specifically, Visual Instruction Generation (VIG) guides the vision-language model to generate diverse instruction-tuning data. To ensure generation quality, Visual Instruction Correction (VIC) adopts an iterative update mechanism to correct any inaccuracies in data produced by VIG, effectively reducing the risk of hallucination. Leveraging the diverse, high-quality data generated by VIGC, we finetune mainstream models and validate data quality based on various evaluations. Experimental results demonstrate that VIGC not only compensates for the shortcomings of language-only data generation methods, but also effectively enhances the benchmark performance. The models, datasets, and code will be made publicly available.
ICoNIK: Generating Respiratory-Resolved Abdominal MR Reconstructions Using Neural Implicit Representations in k-Space
Aug 17, 2023Motion-resolved reconstruction for abdominal magnetic resonance imaging (MRI) remains a challenge due to the trade-off between residual motion blurring caused by discretized motion states and undersampling artefacts. In this work, we propose to generate blurring-free motion-resolved abdominal reconstructions by learning a neural implicit representation directly in k-space (NIK). Using measured sampling points and a data-derived respiratory navigator signal, we train a network to generate continuous signal values. To aid the regularization of sparsely sampled regions, we introduce an additional informed correction layer (ICo), which leverages information from neighboring regions to correct NIK's prediction. Our proposed generative reconstruction methods, NIK and ICoNIK, outperform standard motion-resolved reconstruction techniques and provide a promising solution to address motion artefacts in abdominal MRI.
SoilNet: An Attention-based Spatio-temporal Deep Learning Framework for Soil Organic Carbon Prediction with Digital Soil Mapping in Europe
Aug 07, 2023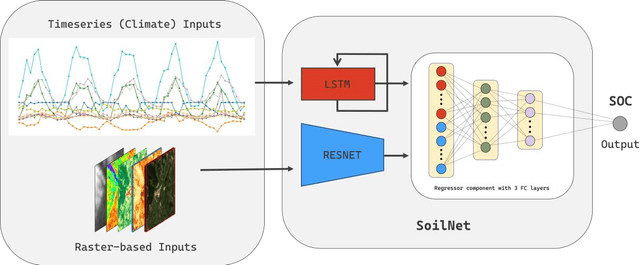
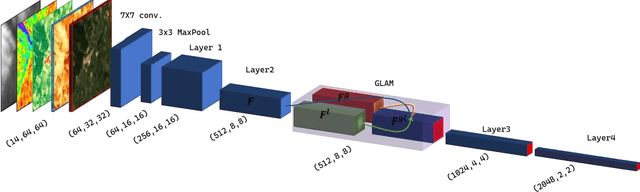
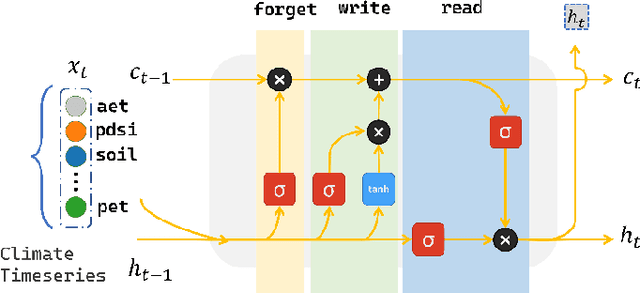
Digital soil mapping (DSM) is an advanced approach that integrates statistical modeling and cutting-edge technologies, including machine learning (ML) methods, to accurately depict soil properties and their spatial distribution. Soil organic carbon (SOC) is a crucial soil attribute providing valuable insights into soil health, nutrient cycling, greenhouse gas emissions, and overall ecosystem productivity. This study highlights the significance of spatial-temporal deep learning (DL) techniques within the DSM framework. A novel architecture is proposed, incorporating spatial information using a base convolutional neural network (CNN) model and spatial attention mechanism, along with climate temporal information using a long short-term memory (LSTM) network, for SOC prediction across Europe. The model utilizes a comprehensive set of environmental features, including Landsat-8 images, topography, remote sensing indices, and climate time series, as input features. Results demonstrate that the proposed framework outperforms conventional ML approaches like random forest commonly used in DSM, yielding lower root mean square error (RMSE). This model is a robust tool for predicting SOC and could be applied to other soil properties, thereby contributing to the advancement of DSM techniques and facilitating land management and decision-making processes based on accurate information.
Unlocking Accuracy and Fairness in Differentially Private Image Classification
Aug 21, 2023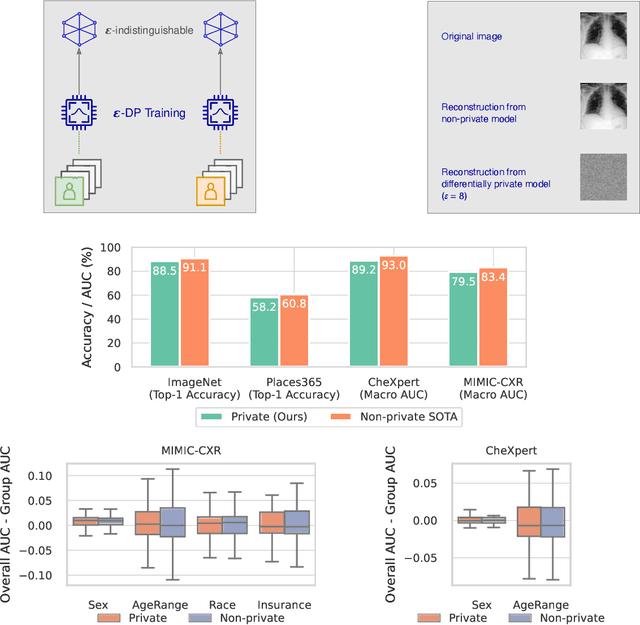
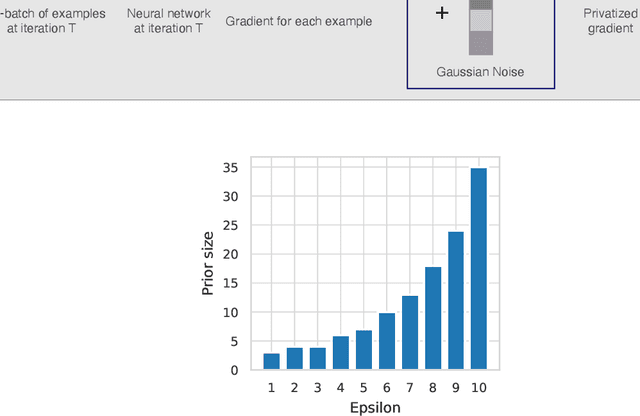
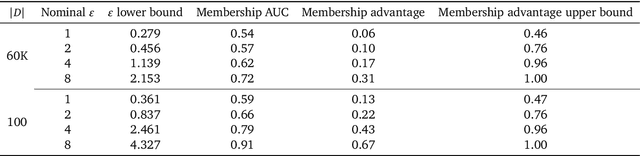
Privacy-preserving machine learning aims to train models on private data without leaking sensitive information. Differential privacy (DP) is considered the gold standard framework for privacy-preserving training, as it provides formal privacy guarantees. However, compared to their non-private counterparts, models trained with DP often have significantly reduced accuracy. Private classifiers are also believed to exhibit larger performance disparities across subpopulations, raising fairness concerns. The poor performance of classifiers trained with DP has prevented the widespread adoption of privacy preserving machine learning in industry. Here we show that pre-trained foundation models fine-tuned with DP can achieve similar accuracy to non-private classifiers, even in the presence of significant distribution shifts between pre-training data and downstream tasks. We achieve private accuracies within a few percent of the non-private state of the art across four datasets, including two medical imaging benchmarks. Furthermore, our private medical classifiers do not exhibit larger performance disparities across demographic groups than non-private models. This milestone to make DP training a practical and reliable technology has the potential to widely enable machine learning practitioners to train safely on sensitive datasets while protecting individuals' privacy.
CSM-H-R: An Automatic Context Reasoning Framework for Interoperable Intelligent Systems and Privacy Protection
Aug 21, 2023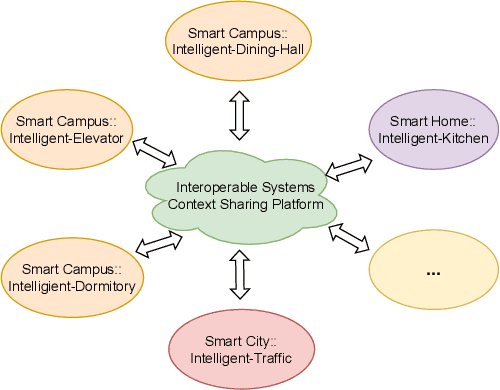
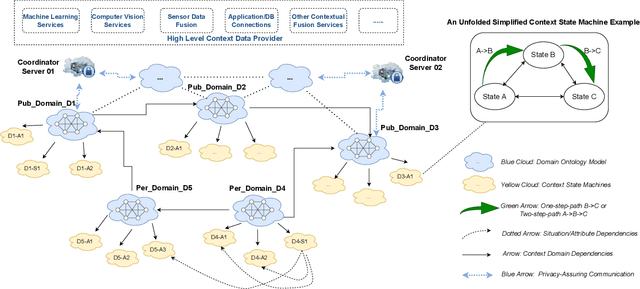
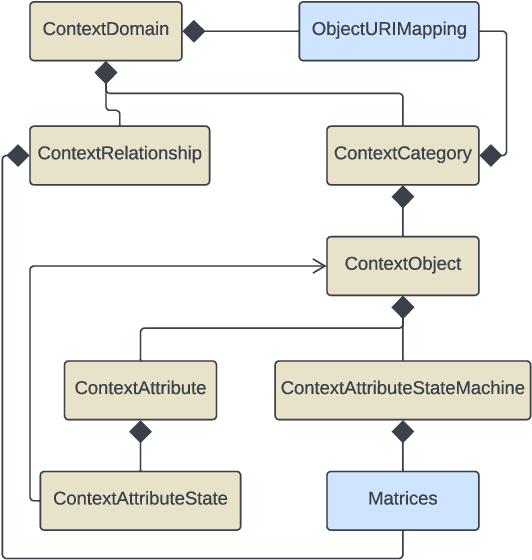
Automation of High-Level Context (HLC) reasoning for intelligent systems at scale is imperative due to the unceasing accumulation of contextual data in the IoT era, the trend of the fusion of data from multi-sources, and the intrinsic complexity and dynamism of the context-based decision-making process. To mitigate this issue, we propose an automatic context reasoning framework CSM-H-R, which programmatically combines ontologies and states at runtime and the model-storage phase for attaining the ability to recognize meaningful HLC, and the resulting data representation can be applied to different reasoning techniques. Case studies are developed based on an intelligent elevator system in a smart campus setting. An implementation of the framework - a CSM Engine, and the experiments of translating the HLC reasoning into vector and matrix computing especially take care of the dynamic aspects of context and present the potentiality of using advanced mathematical and probabilistic models to achieve the next level of automation in integrating intelligent systems; meanwhile, privacy protection support is achieved by anonymization through label embedding and reducing information correlation. The code of this study is available at: https://github.com/songhui01/CSM-H-R.
A Case Study on Context Encoding in Multi-Encoder based Document-Level Neural Machine Translation
Aug 11, 2023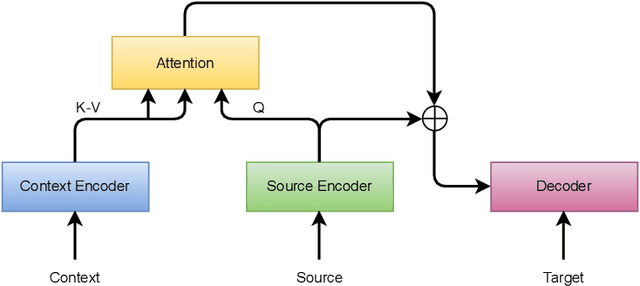
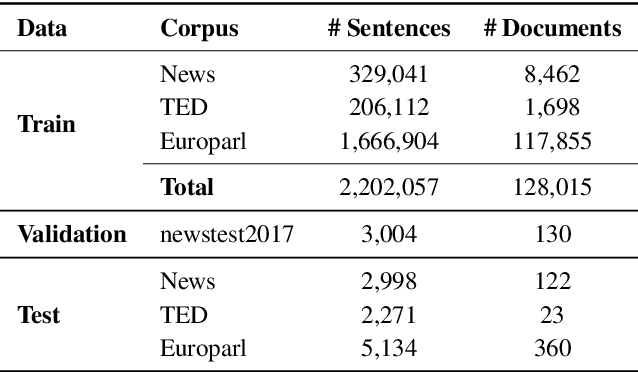
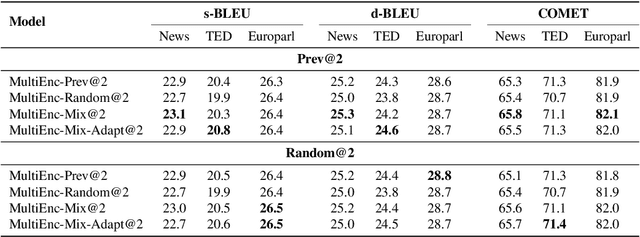
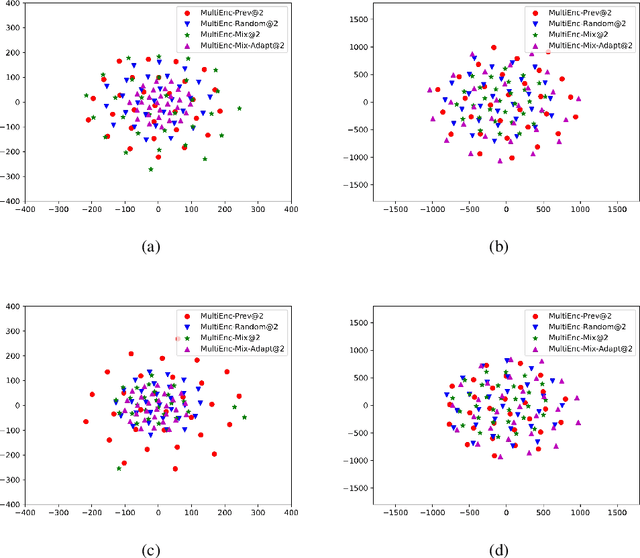
Recent studies have shown that the multi-encoder models are agnostic to the choice of context, and the context encoder generates noise which helps improve the models in terms of BLEU score. In this paper, we further explore this idea by evaluating with context-aware pronoun translation test set by training multi-encoder models trained on three different context settings viz, previous two sentences, random two sentences, and a mix of both as context. Specifically, we evaluate the models on the ContraPro test set to study how different contexts affect pronoun translation accuracy. The results show that the model can perform well on the ContraPro test set even when the context is random. We also analyze the source representations to study whether the context encoder generates noise. Our analysis shows that the context encoder provides sufficient information to learn discourse-level information. Additionally, we observe that mixing the selected context (the previous two sentences in this case) and the random context is generally better than the other settings.