 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Domain-Specificity Inducing Transformers for Source-Free Domain Adaptation
Aug 27, 2023
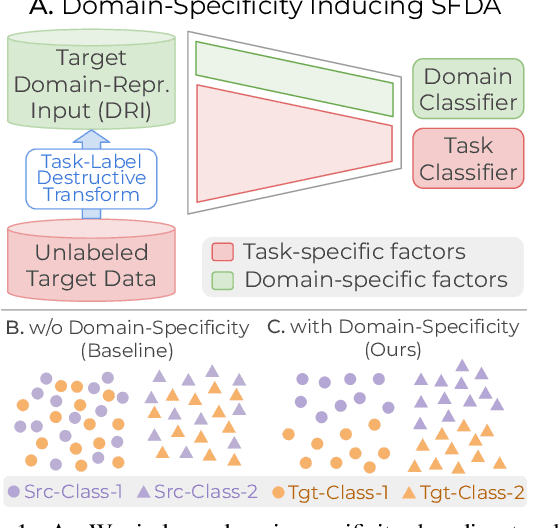
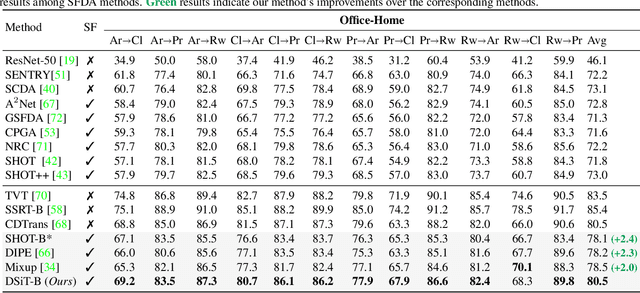
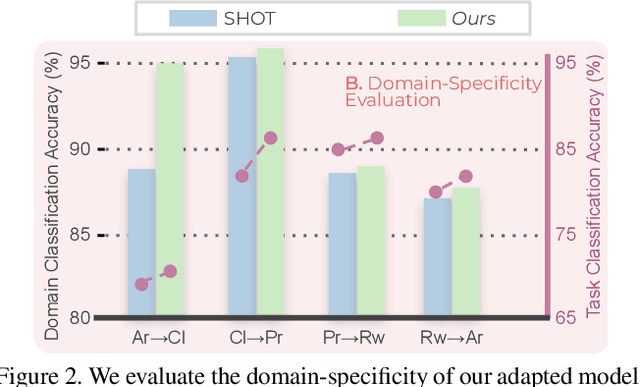
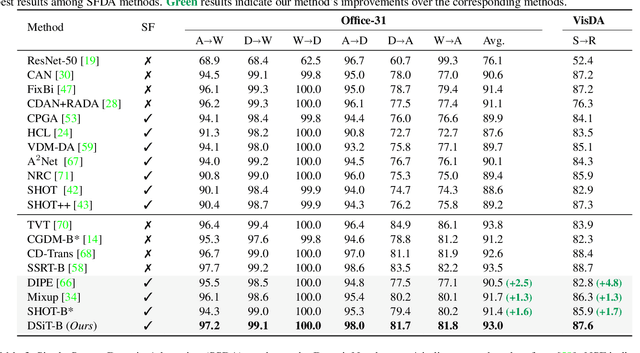
Conventional Domain Adaptation (DA) methods aim to learn domain-invariant feature representations to improve the target adaptation performance. However, we motivate that domain-specificity is equally important since in-domain trained models hold crucial domain-specific properties that are beneficial for adaptation. Hence, we propose to build a framework that supports disentanglement and learning of domain-specific factors and task-specific factors in a unified model. Motivated by the success of vision transformers in several multi-modal vision problems, we find that queries could be leveraged to extract the domain-specific factors. Hence, we propose a novel Domain-specificity-inducing Transformer (DSiT) framework for disentangling and learning both domain-specific and task-specific factors. To achieve disentanglement, we propose to construct novel Domain-Representative Inputs (DRI) with domain-specific information to train a domain classifier with a novel domain token. We are the first to utilize vision transformers for domain adaptation in a privacy-oriented source-free setting, and our approach achieves state-of-the-art performance on single-source, multi-source, and multi-target benchmarks
Sparse Sampling Transformer with Uncertainty-Driven Ranking for Unified Removal of Raindrops and Rain Streaks
Aug 27, 2023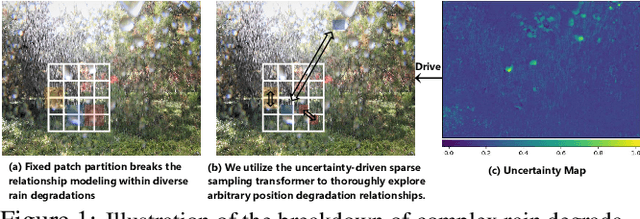
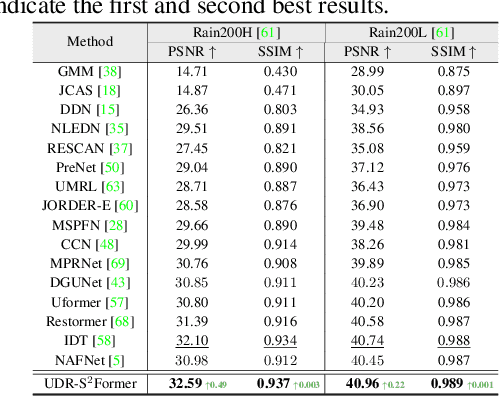
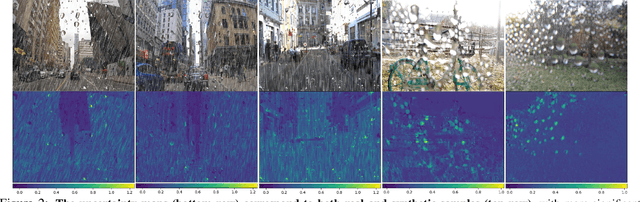
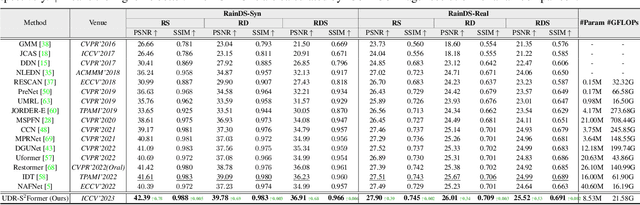
In the real world, image degradations caused by rain often exhibit a combination of rain streaks and raindrops, thereby increasing the challenges of recovering the underlying clean image. Note that the rain streaks and raindrops have diverse shapes, sizes, and locations in the captured image, and thus modeling the correlation relationship between irregular degradations caused by rain artifacts is a necessary prerequisite for image deraining. This paper aims to present an efficient and flexible mechanism to learn and model degradation relationships in a global view, thereby achieving a unified removal of intricate rain scenes. To do so, we propose a Sparse Sampling Transformer based on Uncertainty-Driven Ranking, dubbed UDR-S2Former. Compared to previous methods, our UDR-S2Former has three merits. First, it can adaptively sample relevant image degradation information to model underlying degradation relationships. Second, explicit application of the uncertainty-driven ranking strategy can facilitate the network to attend to degradation features and understand the reconstruction process. Finally, experimental results show that our UDR-S2Former clearly outperforms state-of-the-art methods for all benchmarks.
Unaligned 2D to 3D Translation with Conditional Vector-Quantized Code Diffusion using Transformers
Aug 27, 2023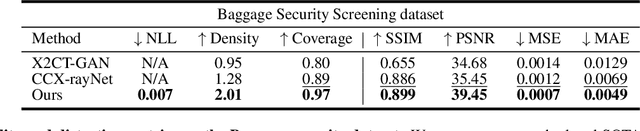
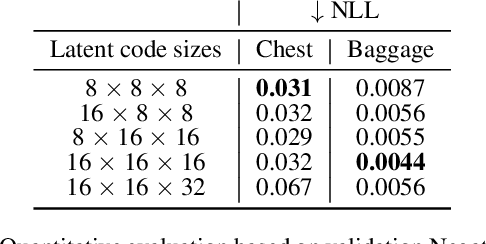

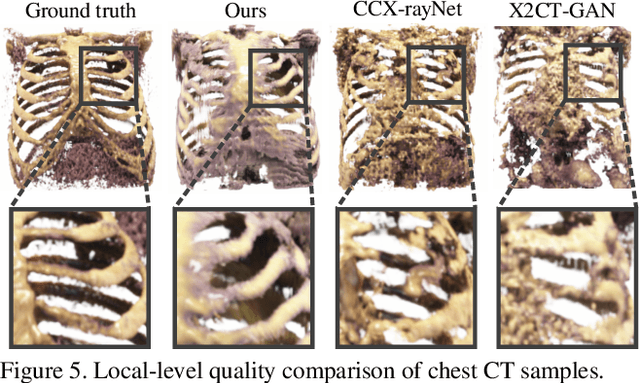
Generating 3D images of complex objects conditionally from a few 2D views is a difficult synthesis problem, compounded by issues such as domain gap and geometric misalignment. For instance, a unified framework such as Generative Adversarial Networks cannot achieve this unless they explicitly define both a domain-invariant and geometric-invariant joint latent distribution, whereas Neural Radiance Fields are generally unable to handle both issues as they optimize at the pixel level. By contrast, we propose a simple and novel 2D to 3D synthesis approach based on conditional diffusion with vector-quantized codes. Operating in an information-rich code space enables high-resolution 3D synthesis via full-coverage attention across the views. Specifically, we generate the 3D codes (e.g. for CT images) conditional on previously generated 3D codes and the entire codebook of two 2D views (e.g. 2D X-rays). Qualitative and quantitative results demonstrate state-of-the-art performance over specialized methods across varied evaluation criteria, including fidelity metrics such as density, coverage, and distortion metrics for two complex volumetric imagery datasets from in real-world scenarios.
A Comparison of Neural Networks for Wireless Channel Prediction
Aug 27, 2023
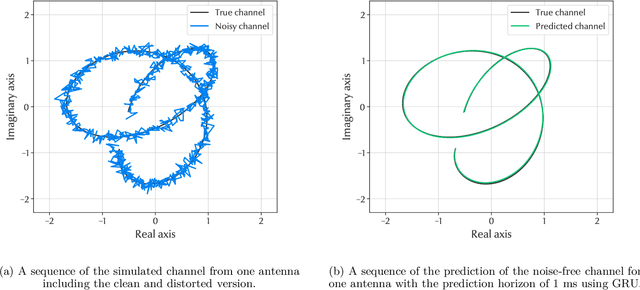
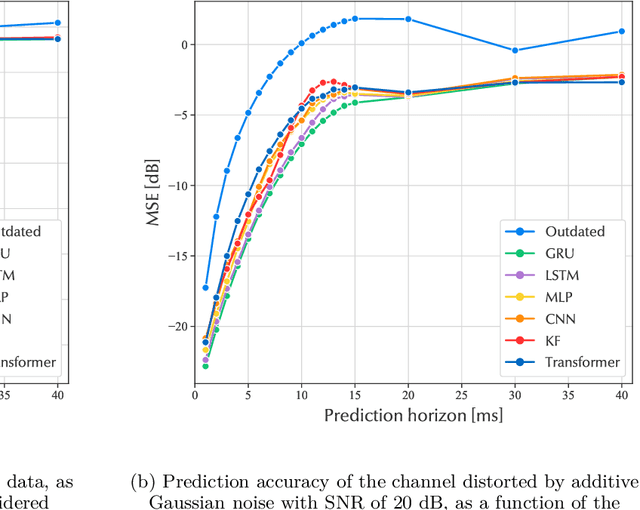
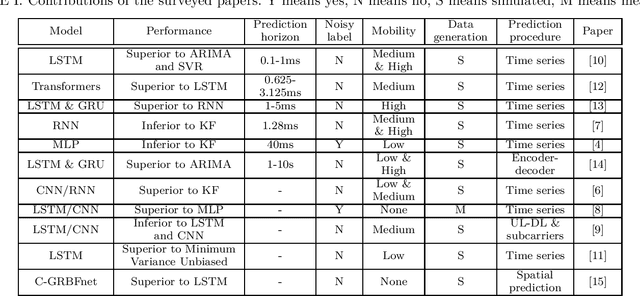
The performance of modern wireless communications systems depends critically on the quality of the available channel state information (CSI) at the transmitter and receiver. Several previous works have proposed concepts and algorithms that help maintain high quality CSI even in the presence of high mobility and channel aging, such as temporal prediction schemes that employ neural networks. However, it is still unclear which neural network-based scheme provides the best performance in terms of prediction quality, training complexity and practical feasibility. To investigate such a question, this paper first provides an overview of state-of-the-art neural networks applicable to channel prediction and compares their performance in terms of prediction quality. Next, a new comparative analysis is proposed for four promising neural networks with different prediction horizons. The well-known tapped delay channel model recommended by the Third Generation Partnership Program is used for a standardized comparison among the neural networks. Based on this comparative evaluation, the advantages and disadvantages of each neural network are discussed and guidelines for selecting the best-suited neural network in channel prediction applications are given.
PMU measurements based short-term voltage stability assessment of power systems via deep transfer learning
Aug 27, 2023Deep learning has emerged as an effective solution for addressing the challenges of short-term voltage stability assessment (STVSA) in power systems. However, existing deep learning-based STVSA approaches face limitations in adapting to topological changes, sample labeling, and handling small datasets. To overcome these challenges, this paper proposes a novel phasor measurement unit (PMU) measurements-based STVSA method by using deep transfer learning. The method leverages the real-time dynamic information captured by PMUs to create an initial dataset. It employs temporal ensembling for sample labeling and utilizes least squares generative adversarial networks (LSGAN) for data augmentation, enabling effective deep learning on small-scale datasets. Additionally, the method enhances adaptability to topological changes by exploring connections between different faults. Experimental results on the IEEE 39-bus test system demonstrate that the proposed method improves model evaluation accuracy by approximately 20% through transfer learning, exhibiting strong adaptability to topological changes. Leveraging the self-attention mechanism of the Transformer model, this approach offers significant advantages over shallow learning methods and other deep learning-based approaches.
Meta-learning enhanced next POI recommendation by leveraging check-ins from auxiliary cities
Aug 18, 2023Most existing point-of-interest (POI) recommenders aim to capture user preference by employing city-level user historical check-ins, thus facilitating users' exploration of the city. However, the scarcity of city-level user check-ins brings a significant challenge to user preference learning. Although prior studies attempt to mitigate this challenge by exploiting various context information, e.g., spatio-temporal information, they ignore to transfer the knowledge (i.e., common behavioral pattern) from other relevant cities (i.e., auxiliary cities). In this paper, we investigate the effect of knowledge distilled from auxiliary cities and thus propose a novel Meta-learning Enhanced next POI Recommendation framework (MERec). The MERec leverages the correlation of check-in behaviors among various cities into the meta-learning paradigm to help infer user preference in the target city, by holding the principle of "paying more attention to more correlated knowledge". Particularly, a city-level correlation strategy is devised to attentively capture common patterns among cities, so as to transfer more relevant knowledge from more correlated cities. Extensive experiments verify the superiority of the proposed MERec against state-of-the-art algorithms.
Fusion of Infrared and Visible Images based on Spatial-Channel Attentional Mechanism
Aug 25, 2023

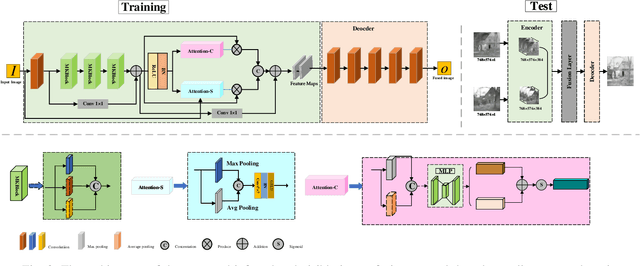
In the study, we present AMFusionNet, an innovative approach to infrared and visible image fusion (IVIF), harnessing the power of multiple kernel sizes and attention mechanisms. By assimilating thermal details from infrared images with texture features from visible sources, our method produces images enriched with comprehensive information. Distinct from prevailing deep learning methodologies, our model encompasses a fusion mechanism powered by multiple convolutional kernels, facilitating the robust capture of a wide feature spectrum. Notably, we incorporate parallel attention mechanisms to emphasize and retain pivotal target details in the resultant images. Moreover, the integration of the multi-scale structural similarity (MS-SSIM) loss function refines network training, optimizing the model for IVIF task. Experimental results demonstrate that our method outperforms state-of-the-art algorithms in terms of quality and quantity. The performance metrics on publicly available datasets also show significant improvement
On the Practicality of Dynamic Updates in Fast Searchable Encryption
Aug 25, 2023



Searchable encrypted (SE) indexing systems are a useful tool for utilizing cloud services to store and manage sensitive information. However, much of the work on SE systems to date has remained theoretical. In order to make them of practical use, more work is needed to develop optimal protocols and working models for them. This includes, in particular, the creation of a working update model in order to maintain an encrypted index of a dynamic document set such as an email inbox. I have created a working, real-world end-to-end SE implementation that satisfies these needs, including the first empirical performance evaluation of the dynamic SE update operation. In doing so, I show a viable path to move from the theoretical concepts described by previous researchers to a future production-worthy implementation and identify issues for follow-on investigation.
Differentiable Weight Masks for Domain Transfer
Aug 26, 2023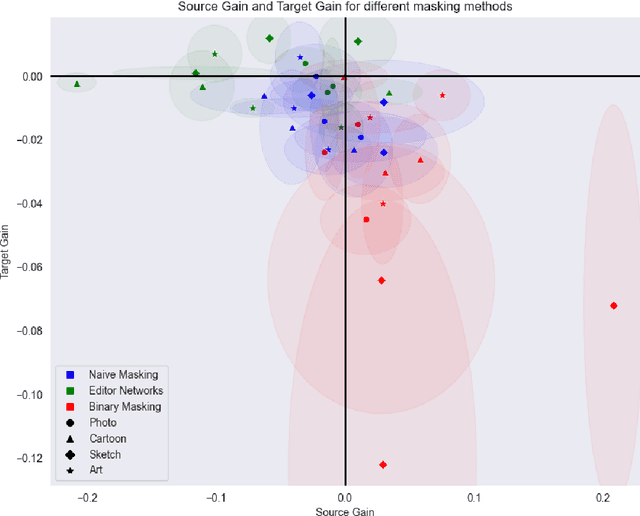

One of the major drawbacks of deep learning models for computer vision has been their inability to retain multiple sources of information in a modular fashion. For instance, given a network that has been trained on a source task, we would like to re-train this network on a similar, yet different, target task while maintaining its performance on the source task. Simultaneously, researchers have extensively studied modularization of network weights to localize and identify the set of weights culpable for eliciting the observed performance on a given task. One set of works studies the modularization induced in the weights of a neural network by learning and analysing weight masks. In this work, we combine these fields to study three such weight masking methods and analyse their ability to mitigate "forgetting'' on the source task while also allowing for efficient finetuning on the target task. We find that different masking techniques have trade-offs in retaining knowledge in the source task without adversely affecting target task performance.
ReFuSeg: Regularized Multi-Modal Fusion for Precise Brain Tumour Segmentation
Aug 26, 2023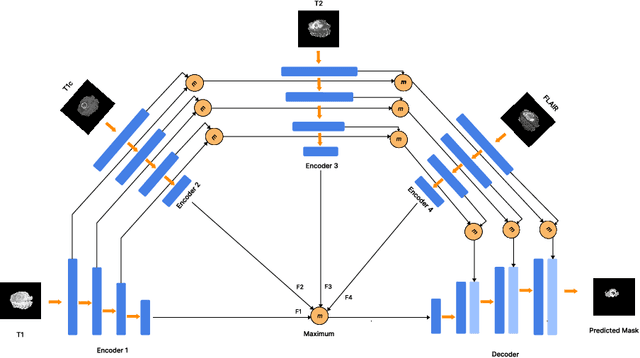
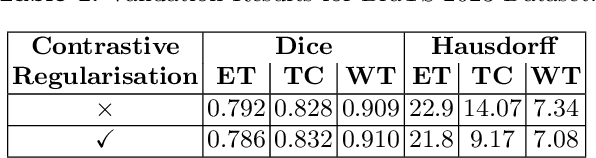
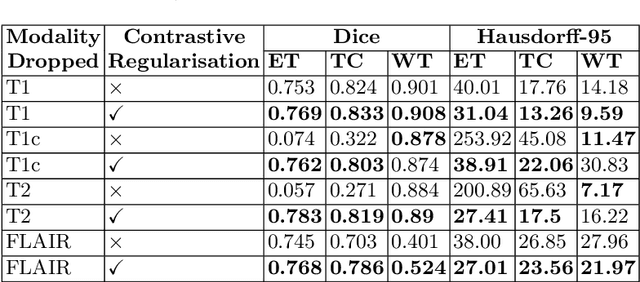
Semantic segmentation of brain tumours is a fundamental task in medical image analysis that can help clinicians in diagnosing the patient and tracking the progression of any malignant entities. Accurate segmentation of brain lesions is essential for medical diagnosis and treatment planning. However, failure to acquire specific MRI imaging modalities can prevent applications from operating in critical situations, raising concerns about their reliability and overall trustworthiness. This paper presents a novel multi-modal approach for brain lesion segmentation that leverages information from four distinct imaging modalities while being robust to real-world scenarios of missing modalities, such as T1, T1c, T2, and FLAIR MRI of brains. Our proposed method can help address the challenges posed by artifacts in medical imagery due to data acquisition errors (such as patient motion) or a reconstruction algorithm's inability to represent the anatomy while ensuring a trade-off in accuracy. Our proposed regularization module makes it robust to these scenarios and ensures the reliability of lesion segmentation.