 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Rethinking Language Models as Symbolic Knowledge Graphs
Aug 25, 2023
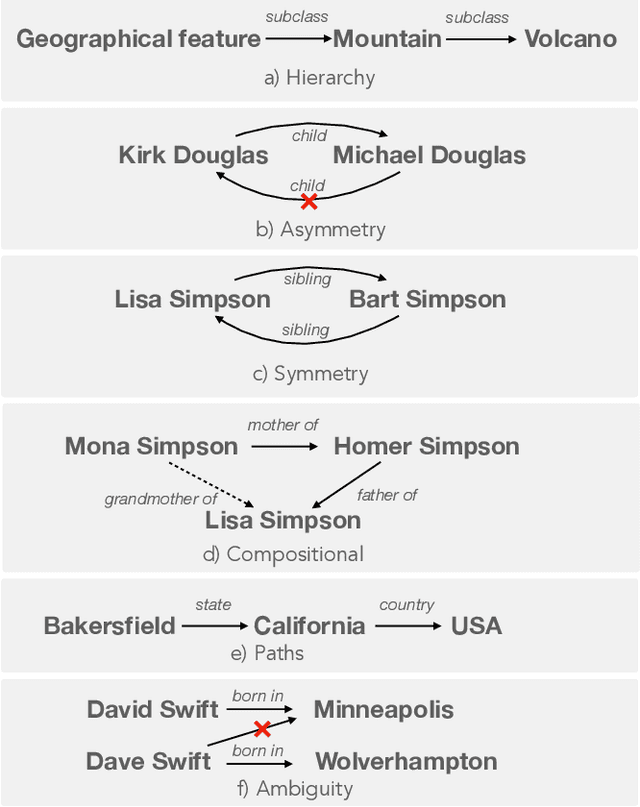
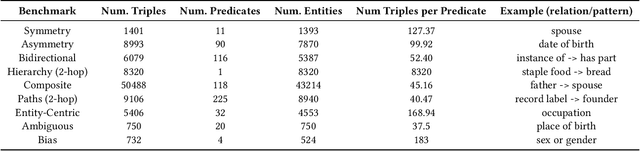

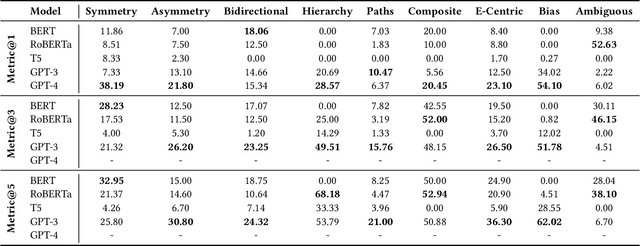
Symbolic knowledge graphs (KGs) play a pivotal role in knowledge-centric applications such as search, question answering and recommendation. As contemporary language models (LMs) trained on extensive textual data have gained prominence, researchers have extensively explored whether the parametric knowledge within these models can match up to that present in knowledge graphs. Various methodologies have indicated that enhancing the size of the model or the volume of training data enhances its capacity to retrieve symbolic knowledge, often with minimal or no human supervision. Despite these advancements, there is a void in comprehensively evaluating whether LMs can encompass the intricate topological and semantic attributes of KGs, attributes crucial for reasoning processes. In this work, we provide an exhaustive evaluation of language models of varying sizes and capabilities. We construct nine qualitative benchmarks that encompass a spectrum of attributes including symmetry, asymmetry, hierarchy, bidirectionality, compositionality, paths, entity-centricity, bias and ambiguity. Additionally, we propose novel evaluation metrics tailored for each of these attributes. Our extensive evaluation of various LMs shows that while these models exhibit considerable potential in recalling factual information, their ability to capture intricate topological and semantic traits of KGs remains significantly constrained. We note that our proposed evaluation metrics are more reliable in evaluating these abilities than the existing metrics. Lastly, some of our benchmarks challenge the common notion that larger LMs (e.g., GPT-4) universally outshine their smaller counterparts (e.g., BERT).
Information Screening whilst Exploiting! Multimodal Relation Extraction with Feature Denoising and Multimodal Topic Modeling
May 25, 2023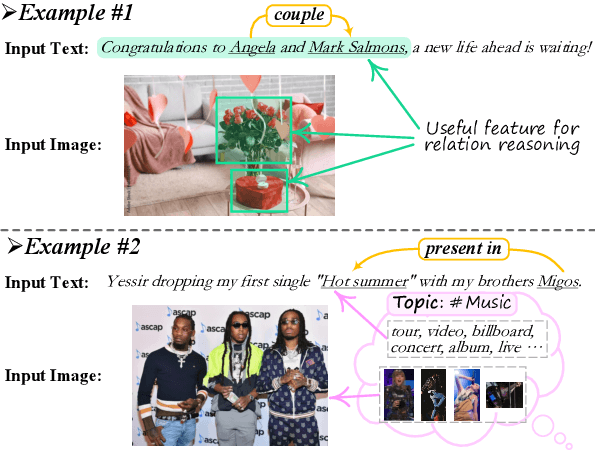
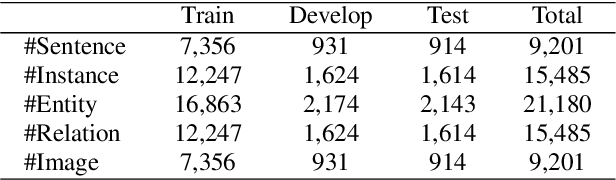
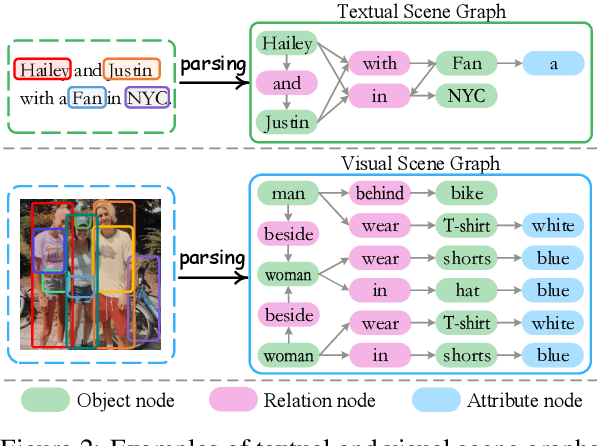
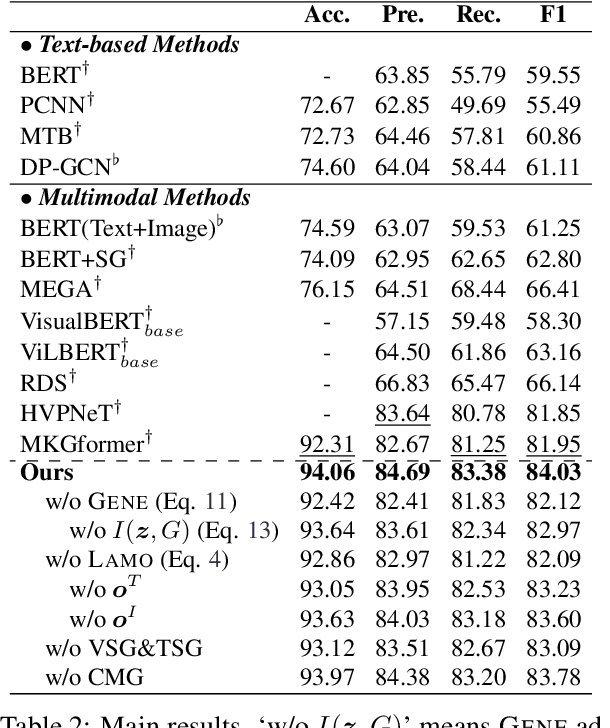
Existing research on multimodal relation extraction (MRE) faces two co-existing challenges, internal-information over-utilization and external-information under-exploitation. To combat that, we propose a novel framework that simultaneously implements the idea of internal-information screening and external-information exploiting. First, we represent the fine-grained semantic structures of the input image and text with the visual and textual scene graphs, which are further fused into a unified cross-modal graph (CMG). Based on CMG, we perform structure refinement with the guidance of the graph information bottleneck principle, actively denoising the less-informative features. Next, we perform topic modeling over the input image and text, incorporating latent multimodal topic features to enrich the contexts. On the benchmark MRE dataset, our system outperforms the current best model significantly. With further in-depth analyses, we reveal the great potential of our method for the MRE task. Our codes are open at https://github.com/ChocoWu/MRE-ISE.
Source-free Domain Adaptive Human Pose Estimation
Aug 15, 2023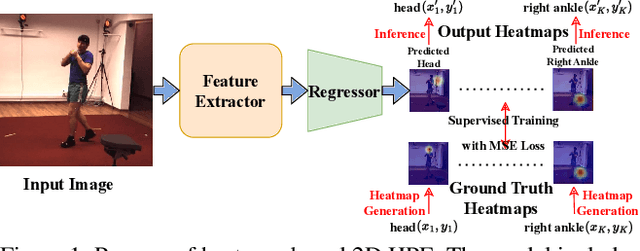
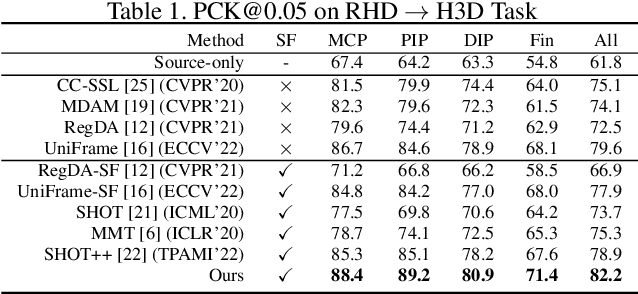
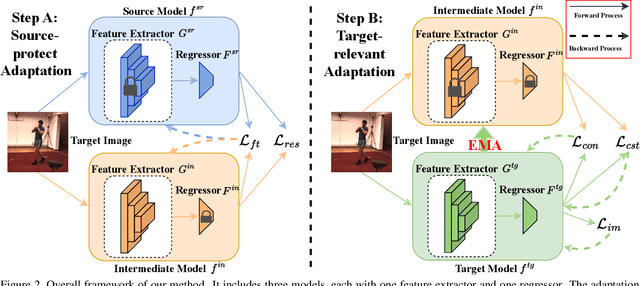
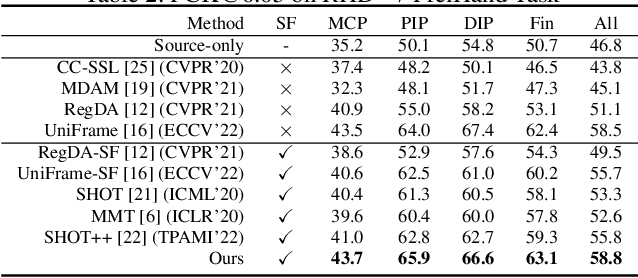
Human Pose Estimation (HPE) is widely used in various fields, including motion analysis, healthcare, and virtual reality. However, the great expenses of labeled real-world datasets present a significant challenge for HPE. To overcome this, one approach is to train HPE models on synthetic datasets and then perform domain adaptation (DA) on real-world data. Unfortunately, existing DA methods for HPE neglect data privacy and security by using both source and target data in the adaptation process. To this end, we propose a new task, named source-free domain adaptive HPE, which aims to address the challenges of cross-domain learning of HPE without access to source data during the adaptation process. We further propose a novel framework that consists of three models: source model, intermediate model, and target model, which explores the task from both source-protect and target-relevant perspectives. The source-protect module preserves source information more effectively while resisting noise, and the target-relevant module reduces the sparsity of spatial representations by building a novel spatial probability space, and pose-specific contrastive learning and information maximization are proposed on the basis of this space. Comprehensive experiments on several domain adaptive HPE benchmarks show that the proposed method outperforms existing approaches by a considerable margin. The codes are available at https://github.com/davidpengucf/SFDAHPE.
From Commit Message Generation to History-Aware Commit Message Completion
Aug 15, 2023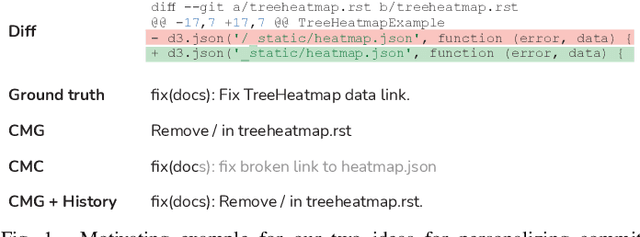
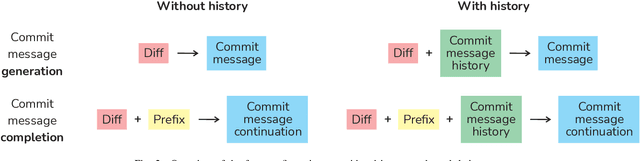
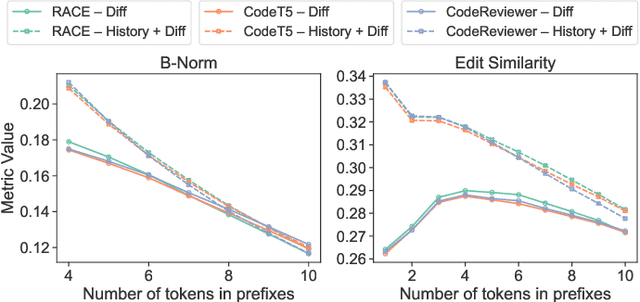
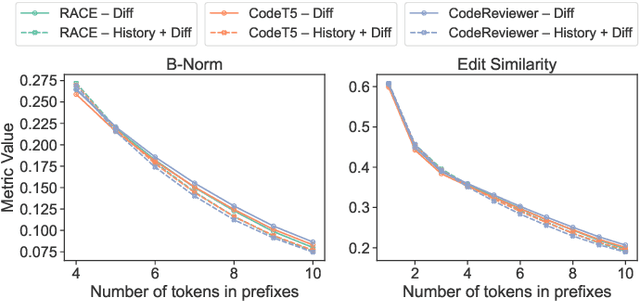
Commit messages are crucial to software development, allowing developers to track changes and collaborate effectively. Despite their utility, most commit messages lack important information since writing high-quality commit messages is tedious and time-consuming. The active research on commit message generation (CMG) has not yet led to wide adoption in practice. We argue that if we could shift the focus from commit message generation to commit message completion and use previous commit history as additional context, we could significantly improve the quality and the personal nature of the resulting commit messages. In this paper, we propose and evaluate both of these novel ideas. Since the existing datasets lack historical data, we collect and share a novel dataset called CommitChronicle, containing 10.7M commits across 20 programming languages. We use this dataset to evaluate the completion setting and the usefulness of the historical context for state-of-the-art CMG models and GPT-3.5-turbo. Our results show that in some contexts, commit message completion shows better results than generation, and that while in general GPT-3.5-turbo performs worse, it shows potential for long and detailed messages. As for the history, the results show that historical information improves the performance of CMG models in the generation task, and the performance of GPT-3.5-turbo in both generation and completion.
CALYPSO: LLMs as Dungeon Masters' Assistants
Aug 15, 2023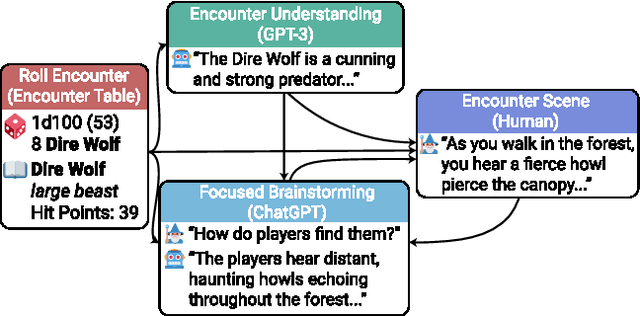


The role of a Dungeon Master, or DM, in the game Dungeons & Dragons is to perform multiple tasks simultaneously. The DM must digest information about the game setting and monsters, synthesize scenes to present to other players, and respond to the players' interactions with the scene. Doing all of these tasks while maintaining consistency within the narrative and story world is no small feat of human cognition, making the task tiring and unapproachable to new players. Large language models (LLMs) like GPT-3 and ChatGPT have shown remarkable abilities to generate coherent natural language text. In this paper, we conduct a formative evaluation with DMs to establish the use cases of LLMs in D&D and tabletop gaming generally. We introduce CALYPSO, a system of LLM-powered interfaces that support DMs with information and inspiration specific to their own scenario. CALYPSO distills game context into bite-sized prose and helps brainstorm ideas without distracting the DM from the game. When given access to CALYPSO, DMs reported that it generated high-fidelity text suitable for direct presentation to players, and low-fidelity ideas that the DM could develop further while maintaining their creative agency. We see CALYPSO as exemplifying a paradigm of AI-augmented tools that provide synchronous creative assistance within established game worlds, and tabletop gaming more broadly.
Exploring Predicate Visual Context in Detecting of Human-Object Interactions
Aug 11, 2023


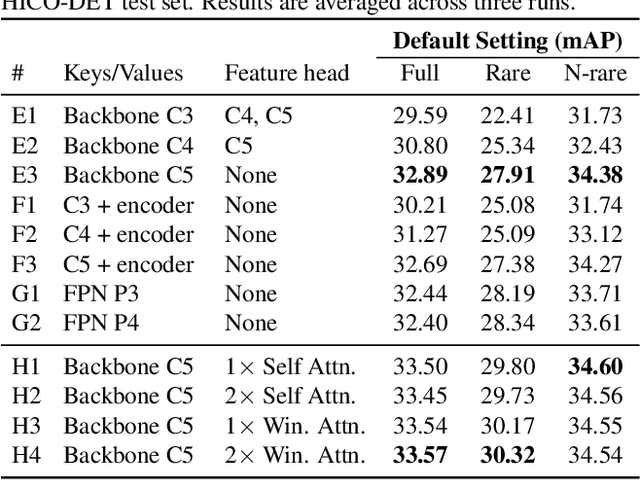
Recently, the DETR framework has emerged as the dominant approach for human--object interaction (HOI) research. In particular, two-stage transformer-based HOI detectors are amongst the most performant and training-efficient approaches. However, these often condition HOI classification on object features that lack fine-grained contextual information, eschewing pose and orientation information in favour of visual cues about object identity and box extremities. This naturally hinders the recognition of complex or ambiguous interactions. In this work, we study these issues through visualisations and carefully designed experiments. Accordingly, we investigate how best to re-introduce image features via cross-attention. With an improved query design, extensive exploration of keys and values, and box pair positional embeddings as spatial guidance, our model with enhanced predicate visual context (PViC) outperforms state-of-the-art methods on the HICO-DET and V-COCO benchmarks, while maintaining low training cost.
Single Image Reflection Separation via Component Synergy
Aug 19, 2023
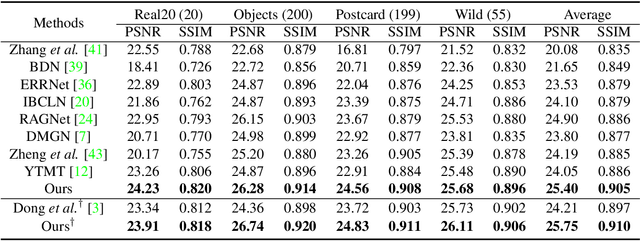
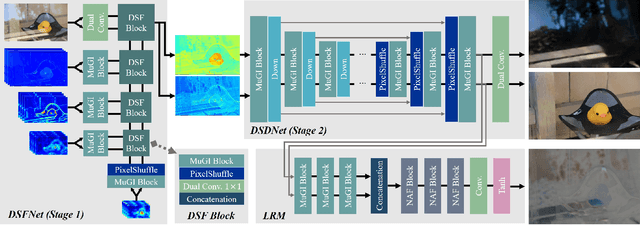
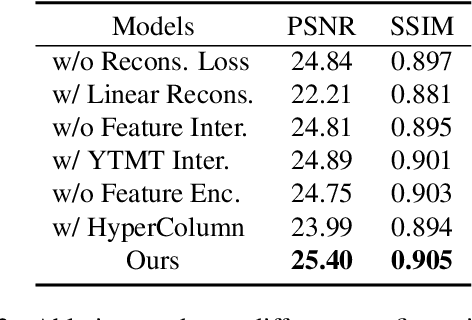
The reflection superposition phenomenon is complex and widely distributed in the real world, which derives various simplified linear and nonlinear formulations of the problem. In this paper, based on the investigation of the weaknesses of existing models, we propose a more general form of the superposition model by introducing a learnable residue term, which can effectively capture residual information during decomposition, guiding the separated layers to be complete. In order to fully capitalize on its advantages, we further design the network structure elaborately, including a novel dual-stream interaction mechanism and a powerful decomposition network with a semantic pyramid encoder. Extensive experiments and ablation studies are conducted to verify our superiority over state-of-the-art approaches on multiple real-world benchmark datasets. Our code is publicly available at https://github.com/mingcv/DSRNet.
Adversarial Erasing with Pruned Elements: Towards Better Graph Lottery Ticket
Aug 05, 2023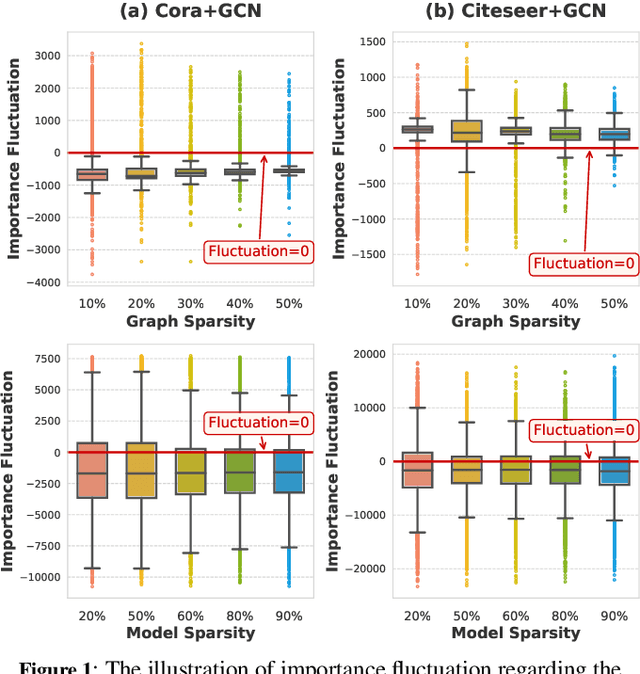
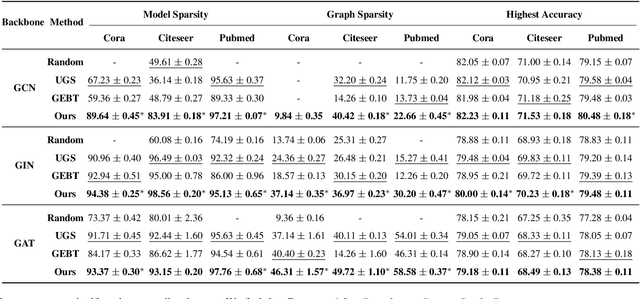
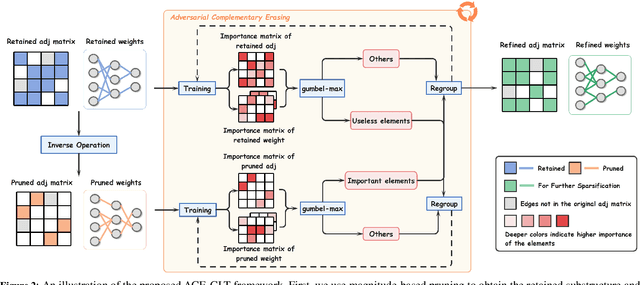
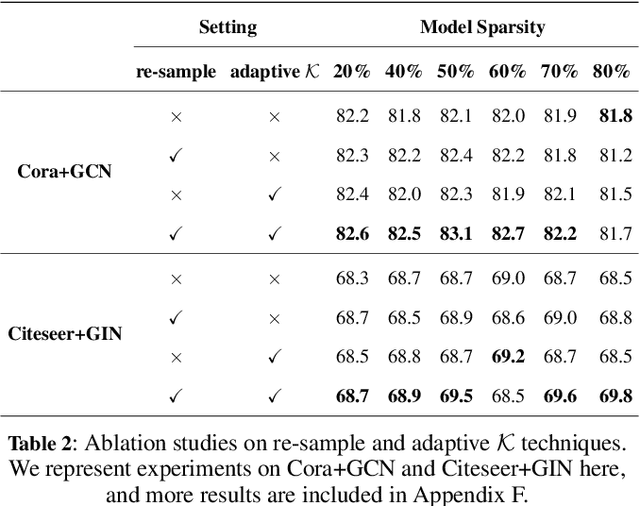
Graph Lottery Ticket (GLT), a combination of core subgraph and sparse subnetwork, has been proposed to mitigate the computational cost of deep Graph Neural Networks (GNNs) on large input graphs while preserving original performance. However, the winning GLTs in exisiting studies are obtained by applying iterative magnitude-based pruning (IMP) without re-evaluating and re-considering the pruned information, which disregards the dynamic changes in the significance of edges/weights during graph/model structure pruning, and thus limits the appeal of the winning tickets. In this paper, we formulate a conjecture, i.e., existing overlooked valuable information in the pruned graph connections and model parameters which can be re-grouped into GLT to enhance the final performance. Specifically, we propose an adversarial complementary erasing (ACE) framework to explore the valuable information from the pruned components, thereby developing a more powerful GLT, referred to as the ACE-GLT. The main idea is to mine valuable information from pruned edges/weights after each round of IMP, and employ the ACE technique to refine the GLT processing. Finally, experimental results demonstrate that our ACE-GLT outperforms existing methods for searching GLT in diverse tasks. Our code will be made publicly available.
End-to-end Alternating Optimization for Real-World Blind Super Resolution
Aug 17, 2023Blind Super-Resolution (SR) usually involves two sub-problems: 1) estimating the degradation of the given low-resolution (LR) image; 2) super-resolving the LR image to its high-resolution (HR) counterpart. Both problems are ill-posed due to the information loss in the degrading process. Most previous methods try to solve the two problems independently, but often fall into a dilemma: a good super-resolved HR result requires an accurate degradation estimation, which however, is difficult to be obtained without the help of original HR information. To address this issue, instead of considering these two problems independently, we adopt an alternating optimization algorithm, which can estimate the degradation and restore the SR image in a single model. Specifically, we design two convolutional neural modules, namely \textit{Restorer} and \textit{Estimator}. \textit{Restorer} restores the SR image based on the estimated degradation, and \textit{Estimator} estimates the degradation with the help of the restored SR image. We alternate these two modules repeatedly and unfold this process to form an end-to-end trainable network. In this way, both \textit{Restorer} and \textit{Estimator} could get benefited from the intermediate results of each other, and make each sub-problem easier. Moreover, \textit{Restorer} and \textit{Estimator} are optimized in an end-to-end manner, thus they could get more tolerant of the estimation deviations of each other and cooperate better to achieve more robust and accurate final results. Extensive experiments on both synthetic datasets and real-world images show that the proposed method can largely outperform state-of-the-art methods and produce more visually favorable results. The codes are rleased at \url{https://github.com/greatlog/RealDAN.git}.
* Extension of our previous NeurIPS paper. Accepted to IJCV
A Survey on Deep Multi-modal Learning for Body Language Recognition and Generation
Aug 17, 2023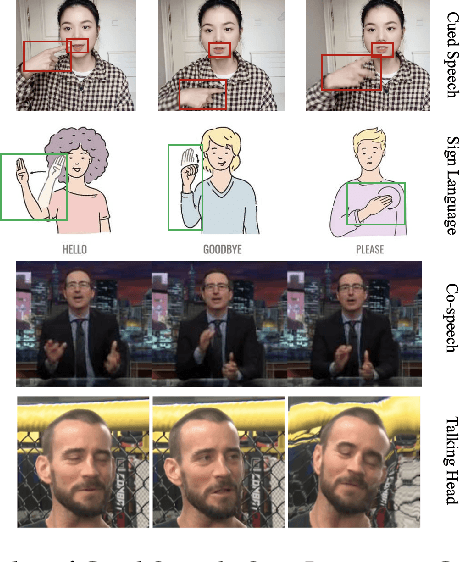
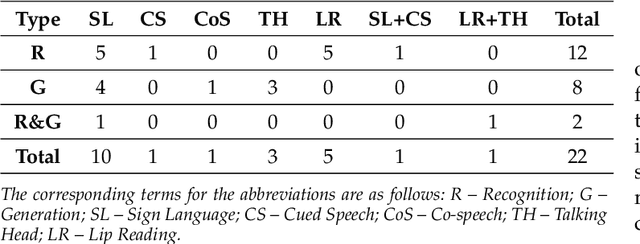
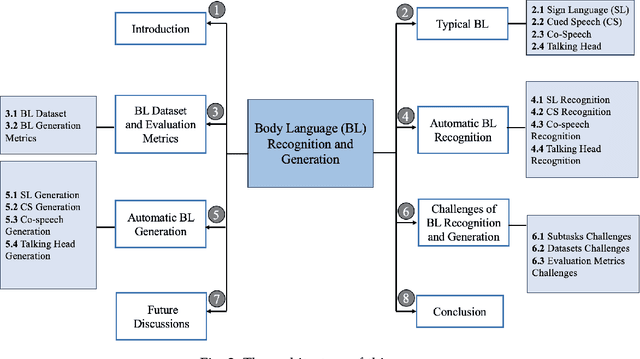
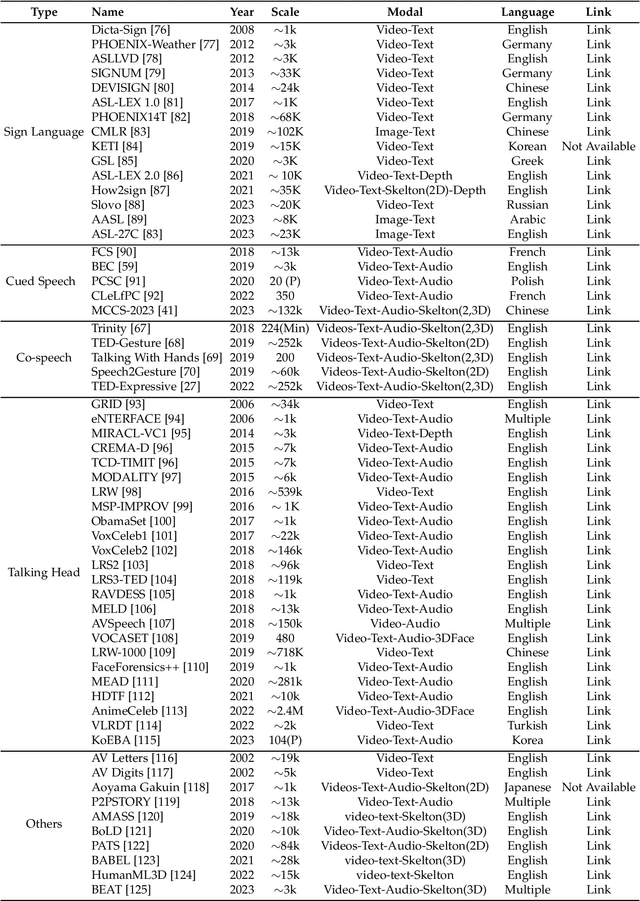
Body language (BL) refers to the non-verbal communication expressed through physical movements, gestures, facial expressions, and postures. It is a form of communication that conveys information, emotions, attitudes, and intentions without the use of spoken or written words. It plays a crucial role in interpersonal interactions and can complement or even override verbal communication. Deep multi-modal learning techniques have shown promise in understanding and analyzing these diverse aspects of BL. The survey emphasizes their applications to BL generation and recognition. Several common BLs are considered i.e., Sign Language (SL), Cued Speech (CS), Co-speech (CoS), and Talking Head (TH), and we have conducted an analysis and established the connections among these four BL for the first time. Their generation and recognition often involve multi-modal approaches. Benchmark datasets for BL research are well collected and organized, along with the evaluation of SOTA methods on these datasets. The survey highlights challenges such as limited labeled data, multi-modal learning, and the need for domain adaptation to generalize models to unseen speakers or languages. Future research directions are presented, including exploring self-supervised learning techniques, integrating contextual information from other modalities, and exploiting large-scale pre-trained multi-modal models. In summary, this survey paper provides a comprehensive understanding of deep multi-modal learning for various BL generations and recognitions for the first time. By analyzing advancements, challenges, and future directions, it serves as a valuable resource for researchers and practitioners in advancing this field. n addition, we maintain a continuously updated paper list for deep multi-modal learning for BL recognition and generation: https://github.com/wentaoL86/awesome-body-language.