 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Infomorphic networks: Locally learning neural networks derived from partial information decomposition
Jun 03, 2023
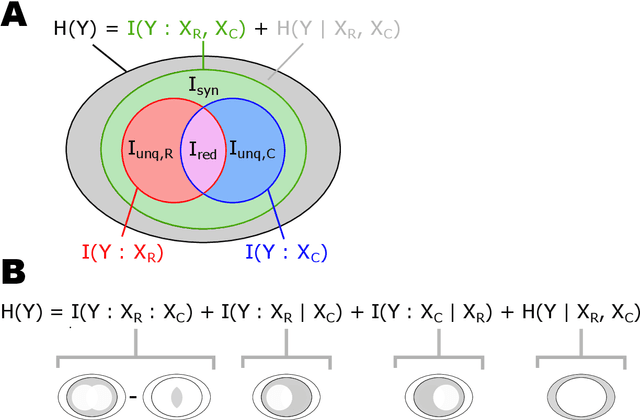
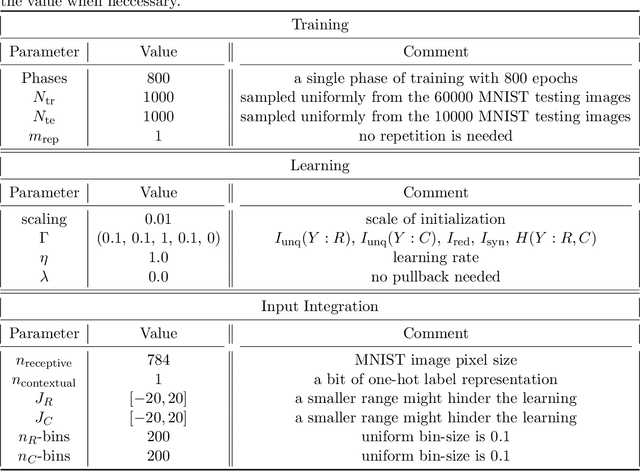
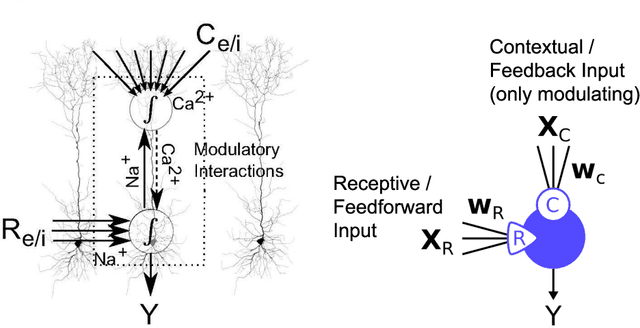
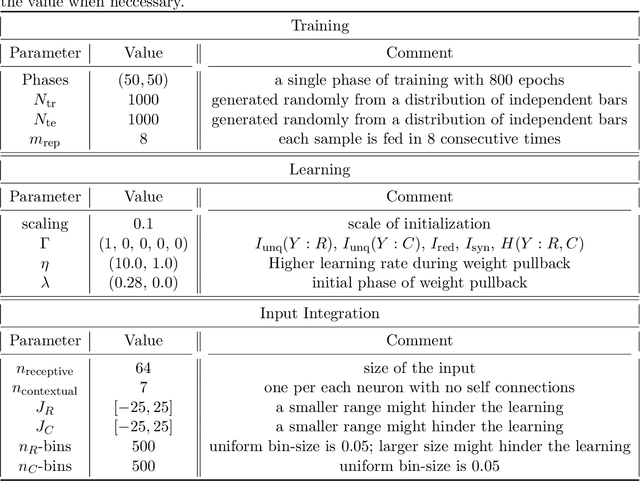
Understanding the intricate cooperation among individual neurons in performing complex tasks remains a challenge to this date. In this paper, we propose a novel type of model neuron that emulates the functional characteristics of biological neurons by optimizing an abstract local information processing goal. We have previously formulated such a goal function based on principles from partial information decomposition (PID). Here, we present a corresponding parametric local learning rule which serves as the foundation of "infomorphic networks" as a novel concrete model of neural networks. We demonstrate the versatility of these networks to perform tasks from supervised, unsupervised and memory learning. By leveraging the explanatory power and interpretable nature of the PID framework, these infomorphic networks represent a valuable tool to advance our understanding of cortical function.
Designing and Evaluating Presentation Strategies for Fact-Checked Content
Aug 20, 2023With the rapid growth of online misinformation, it is crucial to have reliable fact-checking methods. Recent research on finding check-worthy claims and automated fact-checking have made significant advancements. However, limited guidance exists regarding the presentation of fact-checked content to effectively convey verified information to users. We address this research gap by exploring the critical design elements in fact-checking reports and investigating whether credibility and presentation-based design improvements can enhance users' ability to interpret the report accurately. We co-developed potential content presentation strategies through a workshop involving fact-checking professionals, communication experts, and researchers. The workshop examined the significance and utility of elements such as veracity indicators and explored the feasibility of incorporating interactive components for enhanced information disclosure. Building on the workshop outcomes, we conducted an online experiment involving 76 crowd workers to assess the efficacy of different design strategies. The results indicate that proposed strategies significantly improve users' ability to accurately interpret the verdict of fact-checking articles. Our findings underscore the critical role of effective presentation of fact reports in addressing the spread of misinformation. By adopting appropriate design enhancements, the effectiveness of fact-checking reports can be maximized, enabling users to make informed judgments.
LATR: 3D Lane Detection from Monocular Images with Transformer
Aug 20, 2023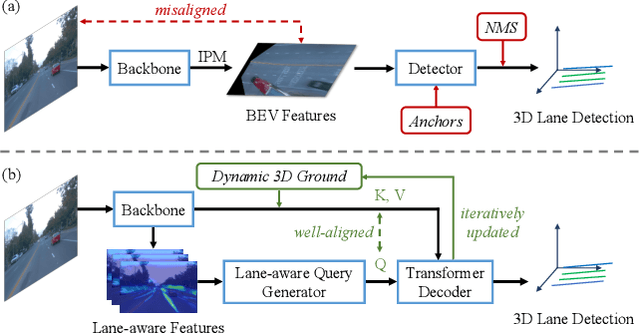
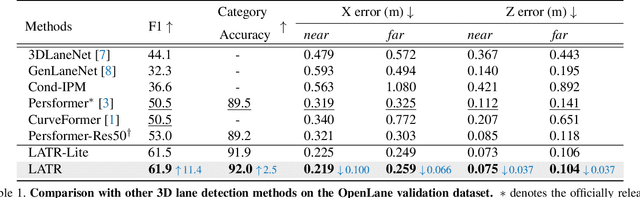
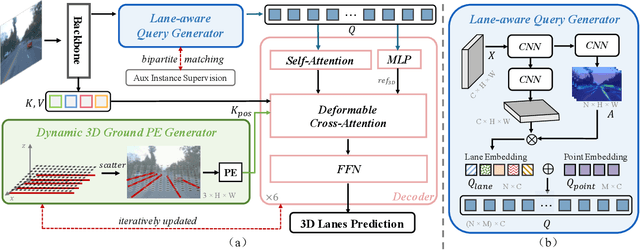
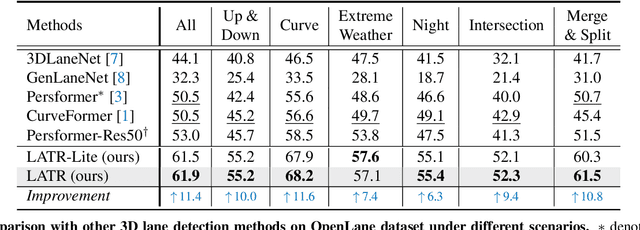
3D lane detection from monocular images is a fundamental yet challenging task in autonomous driving. Recent advances primarily rely on structural 3D surrogates (e.g., bird's eye view) built from front-view image features and camera parameters. However, the depth ambiguity in monocular images inevitably causes misalignment between the constructed surrogate feature map and the original image, posing a great challenge for accurate lane detection. To address the above issue, we present a novel LATR model, an end-to-end 3D lane detector that uses 3D-aware front-view features without transformed view representation. Specifically, LATR detects 3D lanes via cross-attention based on query and key-value pairs, constructed using our lane-aware query generator and dynamic 3D ground positional embedding. On the one hand, each query is generated based on 2D lane-aware features and adopts a hybrid embedding to enhance lane information. On the other hand, 3D space information is injected as positional embedding from an iteratively-updated 3D ground plane. LATR outperforms previous state-of-the-art methods on both synthetic Apollo, realistic OpenLane and ONCE-3DLanes by large margins (e.g., 11.4 gain in terms of F1 score on OpenLane). Code will be released at https://github.com/JMoonr/LATR .
Towards Real-World Visual Tracking with Temporal Contexts
Aug 20, 2023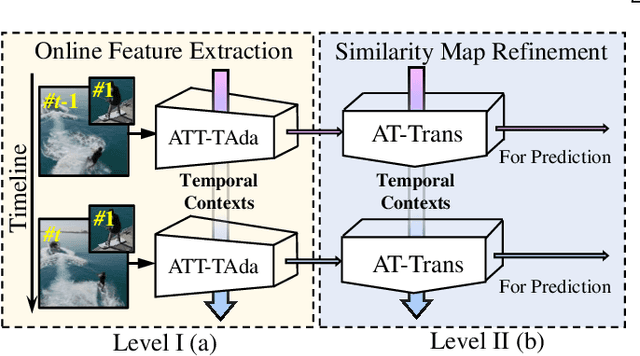

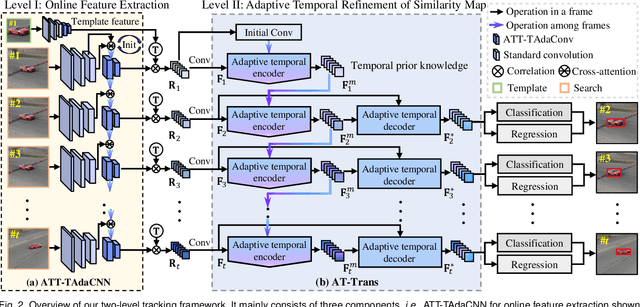
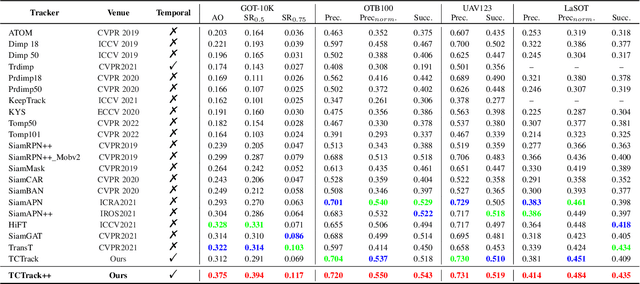
Visual tracking has made significant improvements in the past few decades. Most existing state-of-the-art trackers 1) merely aim for performance in ideal conditions while overlooking the real-world conditions; 2) adopt the tracking-by-detection paradigm, neglecting rich temporal contexts; 3) only integrate the temporal information into the template, where temporal contexts among consecutive frames are far from being fully utilized. To handle those problems, we propose a two-level framework (TCTrack) that can exploit temporal contexts efficiently. Based on it, we propose a stronger version for real-world visual tracking, i.e., TCTrack++. It boils down to two levels: features and similarity maps. Specifically, for feature extraction, we propose an attention-based temporally adaptive convolution to enhance the spatial features using temporal information, which is achieved by dynamically calibrating the convolution weights. For similarity map refinement, we introduce an adaptive temporal transformer to encode the temporal knowledge efficiently and decode it for the accurate refinement of the similarity map. To further improve the performance, we additionally introduce a curriculum learning strategy. Also, we adopt online evaluation to measure performance in real-world conditions. Exhaustive experiments on 8 wellknown benchmarks demonstrate the superiority of TCTrack++. Real-world tests directly verify that TCTrack++ can be readily used in real-world applications.
Coordinate Transformer: Achieving Single-stage Multi-person Mesh Recovery from Videos
Aug 20, 2023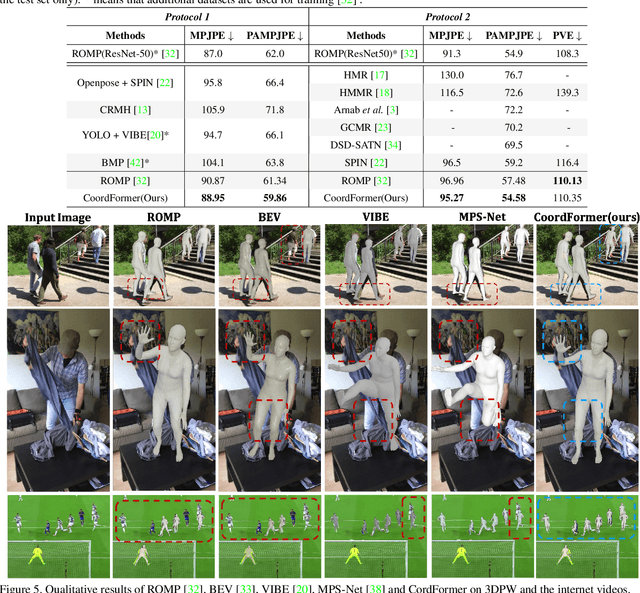
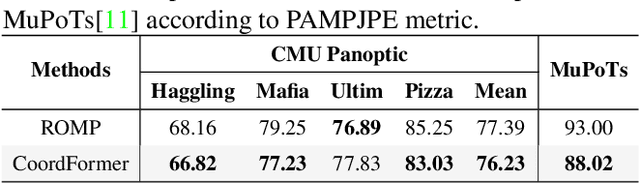

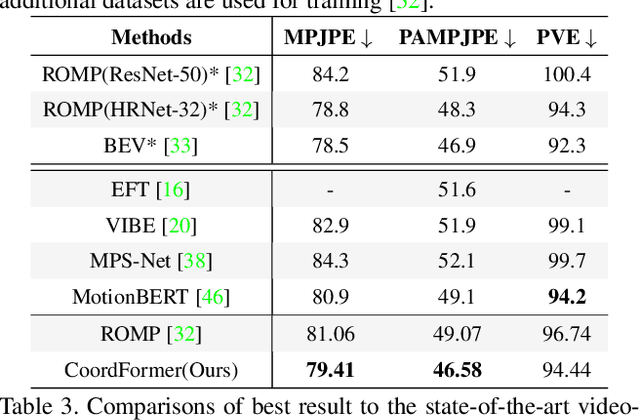
Multi-person 3D mesh recovery from videos is a critical first step towards automatic perception of group behavior in virtual reality, physical therapy and beyond. However, existing approaches rely on multi-stage paradigms, where the person detection and tracking stages are performed in a multi-person setting, while temporal dynamics are only modeled for one person at a time. Consequently, their performance is severely limited by the lack of inter-person interactions in the spatial-temporal mesh recovery, as well as by detection and tracking defects. To address these challenges, we propose the Coordinate transFormer (CoordFormer) that directly models multi-person spatial-temporal relations and simultaneously performs multi-mesh recovery in an end-to-end manner. Instead of partitioning the feature map into coarse-scale patch-wise tokens, CoordFormer leverages a novel Coordinate-Aware Attention to preserve pixel-level spatial-temporal coordinate information. Additionally, we propose a simple, yet effective Body Center Attention mechanism to fuse position information. Extensive experiments on the 3DPW dataset demonstrate that CoordFormer significantly improves the state-of-the-art, outperforming the previously best results by 4.2%, 8.8% and 4.7% according to the MPJPE, PAMPJPE, and PVE metrics, respectively, while being 40% faster than recent video-based approaches. The released code can be found at https://github.com/Li-Hao-yuan/CoordFormer.
From DDMs to DNNs: Using process data and models of decision-making to improve human-AI interactions
Aug 29, 2023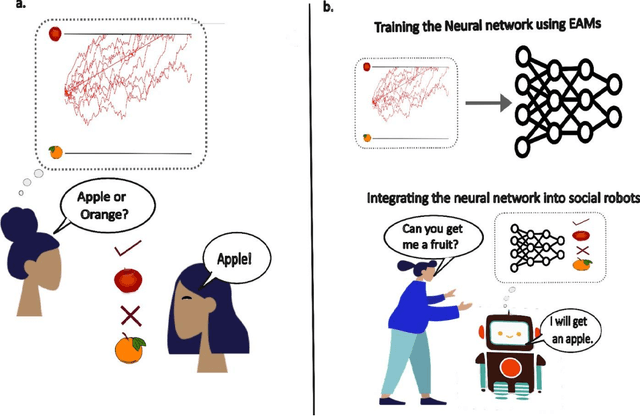
Over the past decades, cognitive neuroscientists and behavioral economists have recognized the value of describing the process of decision making in detail and modeling the emergence of decisions over time. For example, the time it takes to decide can reveal more about an agents true hidden preferences than only the decision itself. Similarly, data that track the ongoing decision process such as eye movements or neural recordings contain critical information that can be exploited, even if no decision is made. Here, we argue that artificial intelligence (AI) research would benefit from a stronger focus on insights about how decisions emerge over time and incorporate related process data to improve AI predictions in general and human-AI interactions in particular. First, we introduce a highly established computational framework that assumes decisions to emerge from the noisy accumulation of evidence, and we present related empirical work in psychology, neuroscience, and economics. Next, we discuss to what extent current approaches in multi-agent AI do or do not incorporate process data and models of decision making. Finally, we outline how a more principled inclusion of the evidence-accumulation framework into the training and use of AI can help to improve human-AI interactions in the future.
Constructive Incremental Learning for Fault Diagnosis of Rolling Bearings with Ensemble Domain Adaptation
Aug 29, 2023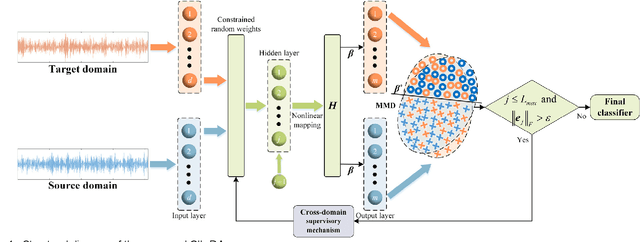
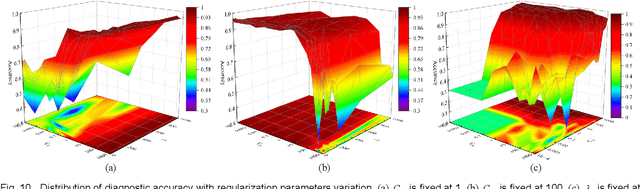
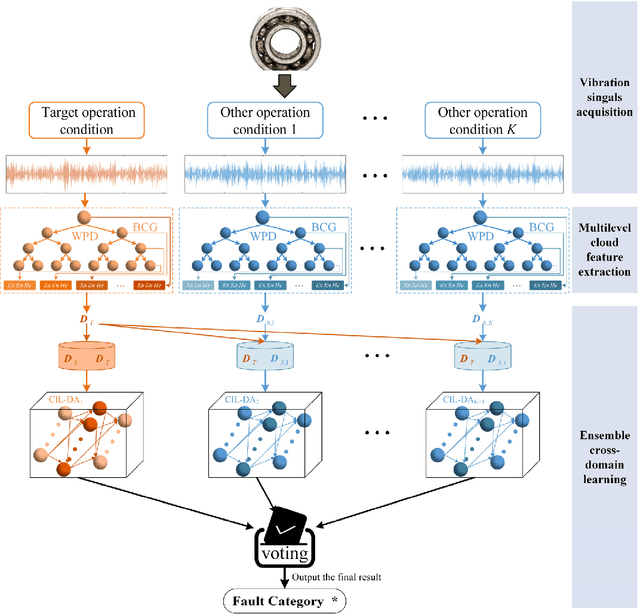
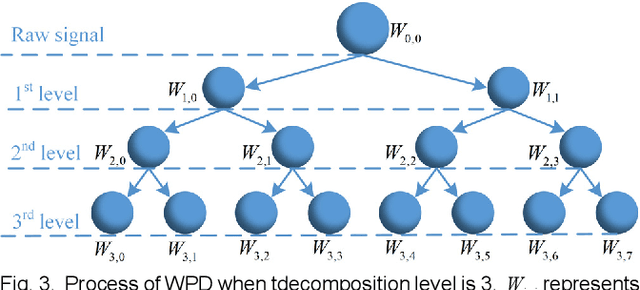
Given the prevalence of rolling bearing fault diagnosis as a practical issue across various working conditions, the limited availability of samples compounds the challenge. Additionally, the complexity of the external environment and the structure of rolling bearings often manifests faults characterized by randomness and fuzziness, hindering the effective extraction of fault characteristics and restricting the accuracy of fault diagnosis. To overcome these problems, this paper presents a novel approach termed constructive Incremental learning-based ensemble domain adaptation (CIL-EDA) approach. Specifically, it is implemented on stochastic configuration networks (SCN) to constructively improve its adaptive performance in multi-domains. Concretely, a cloud feature extraction method is employed in conjunction with wavelet packet decomposition (WPD) to capture the uncertainty of fault information from multiple resolution aspects. Subsequently, constructive Incremental learning-based domain adaptation (CIL-DA) is firstly developed to enhance the cross-domain learning capability of each hidden node through domain matching and construct a robust fault classifier by leveraging limited labeled data from both target and source domains. Finally, fault diagnosis results are obtained by a majority voting of CIL-EDA which integrates CIL-DA and parallel ensemble learning. Experimental results demonstrate that our CIL-DA outperforms several domain adaptation methods and CIL-EDA consistently outperforms state-of-art fault diagnosis methods in few-shot scenarios.
Vision Grid Transformer for Document Layout Analysis
Aug 29, 2023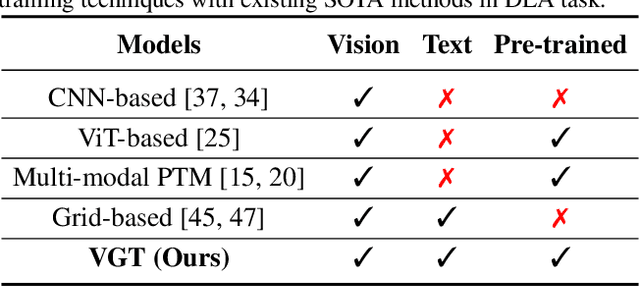



Document pre-trained models and grid-based models have proven to be very effective on various tasks in Document AI. However, for the document layout analysis (DLA) task, existing document pre-trained models, even those pre-trained in a multi-modal fashion, usually rely on either textual features or visual features. Grid-based models for DLA are multi-modality but largely neglect the effect of pre-training. To fully leverage multi-modal information and exploit pre-training techniques to learn better representation for DLA, in this paper, we present VGT, a two-stream Vision Grid Transformer, in which Grid Transformer (GiT) is proposed and pre-trained for 2D token-level and segment-level semantic understanding. Furthermore, a new dataset named D$^4$LA, which is so far the most diverse and detailed manually-annotated benchmark for document layout analysis, is curated and released. Experiment results have illustrated that the proposed VGT model achieves new state-of-the-art results on DLA tasks, e.g. PubLayNet ($95.7\%$$\rightarrow$$96.2\%$), DocBank ($79.6\%$$\rightarrow$$84.1\%$), and D$^4$LA ($67.7\%$$\rightarrow$$68.8\%$). The code and models as well as the D$^4$LA dataset will be made publicly available ~\url{https://github.com/AlibabaResearch/AdvancedLiterateMachinery}.
EquiDiff: A Conditional Equivariant Diffusion Model For Trajectory Prediction
Aug 29, 2023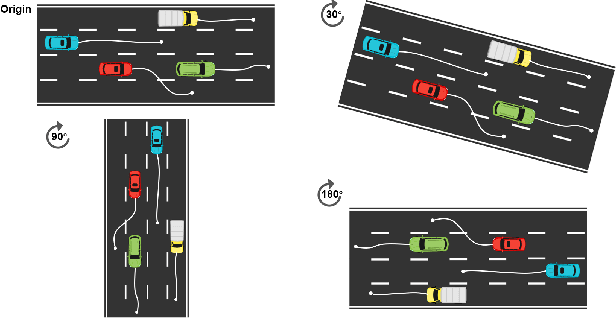
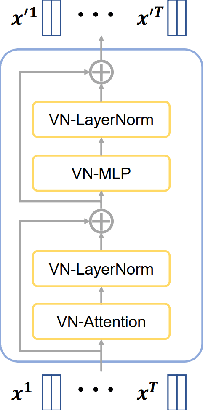
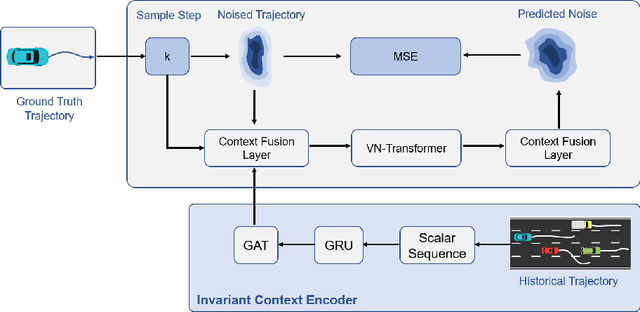
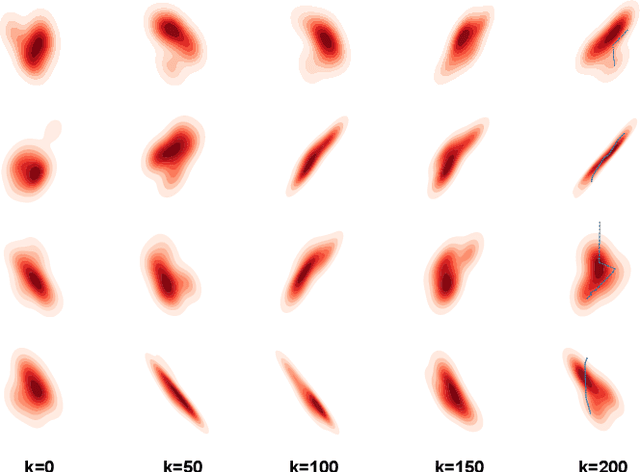
Accurate trajectory prediction is crucial for the safe and efficient operation of autonomous vehicles. The growing popularity of deep learning has led to the development of numerous methods for trajectory prediction. While deterministic deep learning models have been widely used, deep generative models have gained popularity as they learn data distributions from training data and account for trajectory uncertainties. In this study, we propose EquiDiff, a deep generative model for predicting future vehicle trajectories. EquiDiff is based on the conditional diffusion model, which generates future trajectories by incorporating historical information and random Gaussian noise. The backbone model of EquiDiff is an SO(2)-equivariant transformer that fully utilizes the geometric properties of location coordinates. In addition, we employ Recurrent Neural Networks and Graph Attention Networks to extract social interactions from historical trajectories. To evaluate the performance of EquiDiff, we conduct extensive experiments on the NGSIM dataset. Our results demonstrate that EquiDiff outperforms other baseline models in short-term prediction, but has slightly higher errors for long-term prediction. Furthermore, we conduct an ablation study to investigate the contribution of each component of EquiDiff to the prediction accuracy. Additionally, we present a visualization of the generation process of our diffusion model, providing insights into the uncertainty of the prediction.
Using Large Language Models to Automate Category and Trend Analysis of Scientific Articles: An Application in Ophthalmology
Aug 31, 2023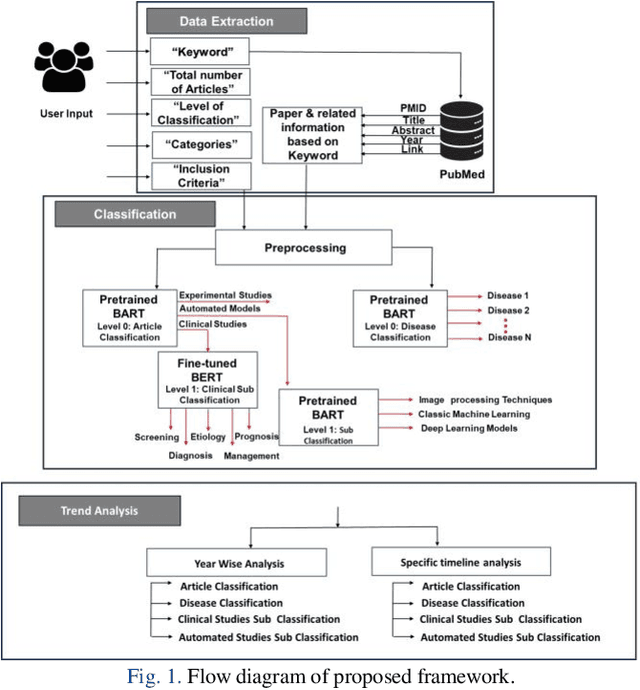
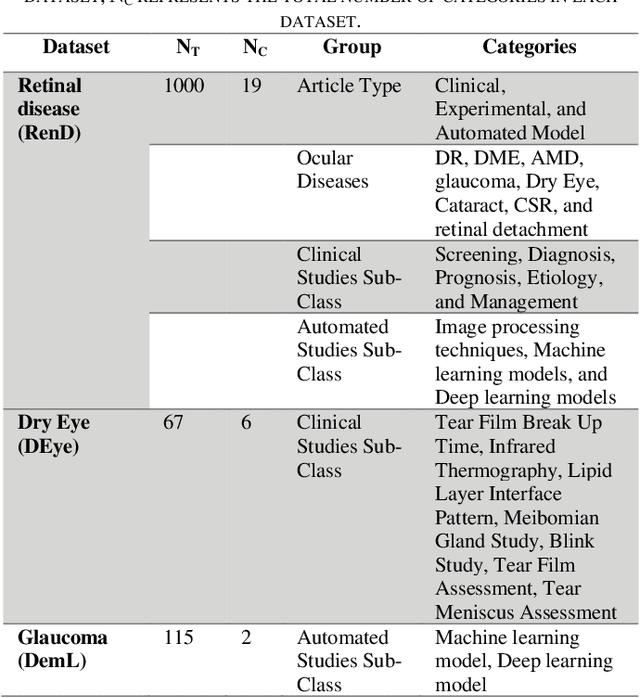
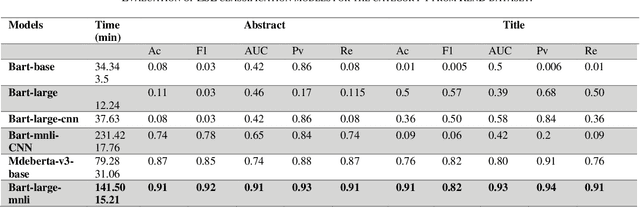
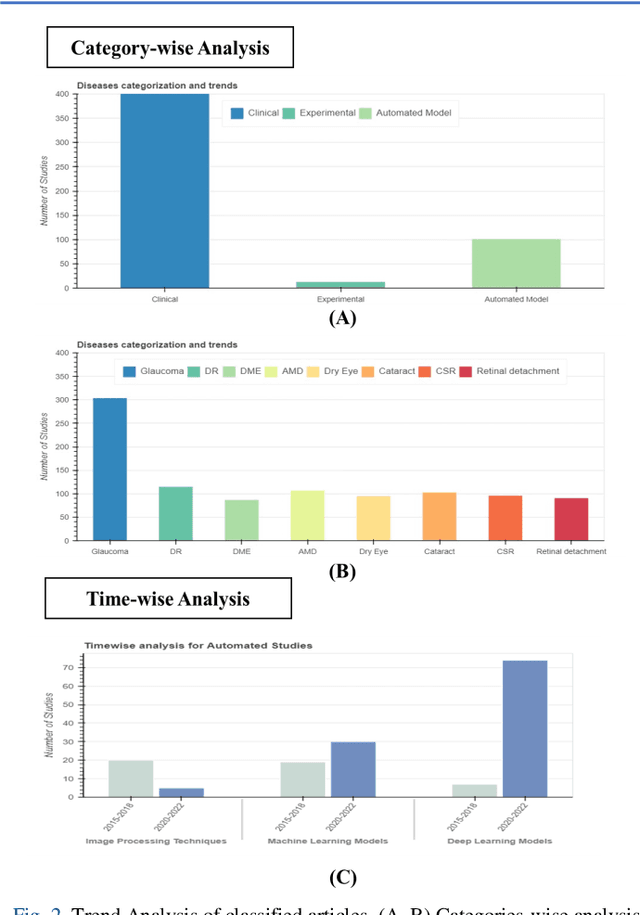
Purpose: In this paper, we present an automated method for article classification, leveraging the power of Large Language Models (LLM). The primary focus is on the field of ophthalmology, but the model is extendable to other fields. Methods: We have developed a model based on Natural Language Processing (NLP) techniques, including advanced LLMs, to process and analyze the textual content of scientific papers. Specifically, we have employed zero-shot learning (ZSL) LLM models and compared against Bidirectional and Auto-Regressive Transformers (BART) and its variants, and Bidirectional Encoder Representations from Transformers (BERT), and its variant such as distilBERT, SciBERT, PubmedBERT, BioBERT. Results: The classification results demonstrate the effectiveness of LLMs in categorizing large number of ophthalmology papers without human intervention. Results: To evalute the LLMs, we compiled a dataset (RenD) of 1000 ocular disease-related articles, which were expertly annotated by a panel of six specialists into 15 distinct categories. The model achieved mean accuracy of 0.86 and mean F1 of 0.85 based on the RenD dataset. Conclusion: The proposed framework achieves notable improvements in both accuracy and efficiency. Its application in the domain of ophthalmology showcases its potential for knowledge organization and retrieval in other domains too. We performed trend analysis that enables the researchers and clinicians to easily categorize and retrieve relevant papers, saving time and effort in literature review and information gathering as well as identification of emerging scientific trends within different disciplines. Moreover, the extendibility of the model to other scientific fields broadens its impact in facilitating research and trend analysis across diverse disciplines.