 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Harmonizing Visual and Textual Embeddings for Zero-Shot Text-to-Image Customization
Mar 21, 2024
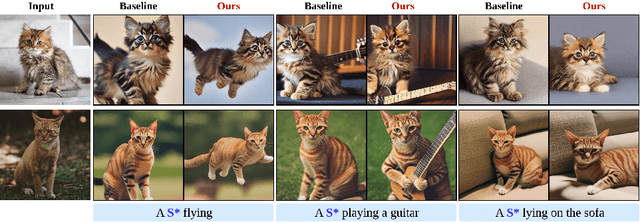
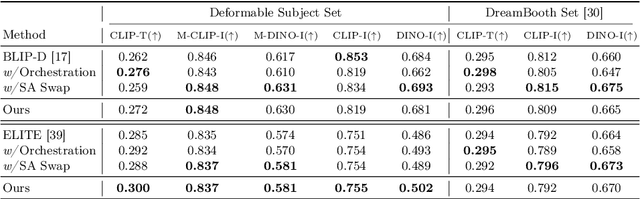
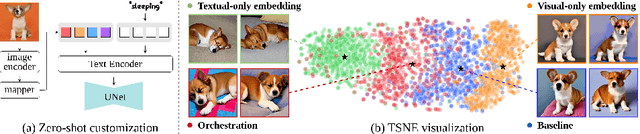
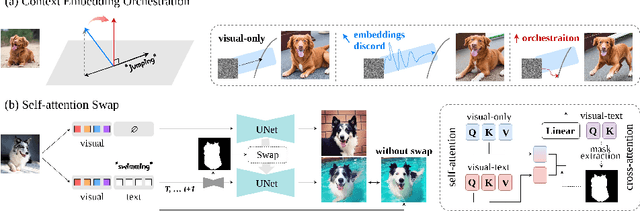
In a surge of text-to-image (T2I) models and their customization methods that generate new images of a user-provided subject, current works focus on alleviating the costs incurred by a lengthy per-subject optimization. These zero-shot customization methods encode the image of a specified subject into a visual embedding which is then utilized alongside the textual embedding for diffusion guidance. The visual embedding incorporates intrinsic information about the subject, while the textual embedding provides a new, transient context. However, the existing methods often 1) are significantly affected by the input images, eg., generating images with the same pose, and 2) exhibit deterioration in the subject's identity. We first pin down the problem and show that redundant pose information in the visual embedding interferes with the textual embedding containing the desired pose information. To address this issue, we propose orthogonal visual embedding which effectively harmonizes with the given textual embedding. We also adopt the visual-only embedding and inject the subject's clear features utilizing a self-attention swap. Our results demonstrate the effectiveness and robustness of our method, which offers highly flexible zero-shot generation while effectively maintaining the subject's identity.
Implicit Discriminative Knowledge Learning for Visible-Infrared Person Re-Identification
Mar 21, 2024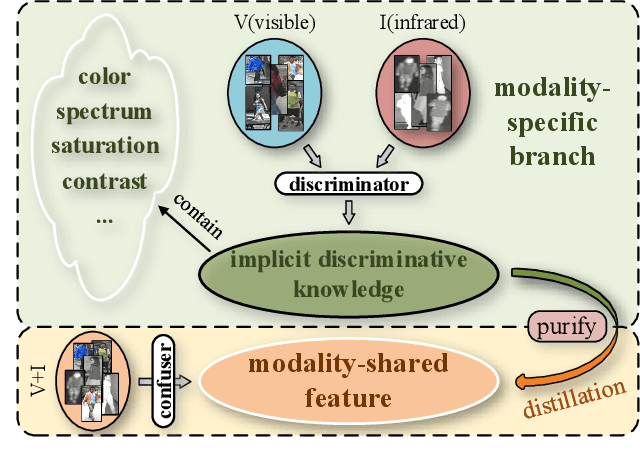
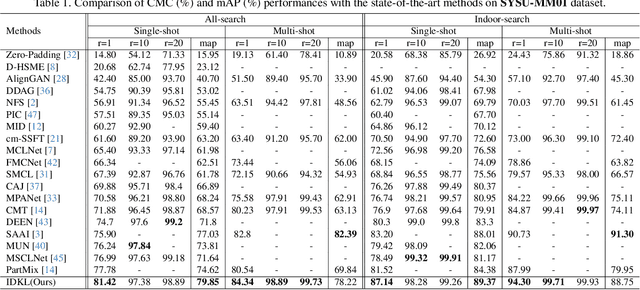
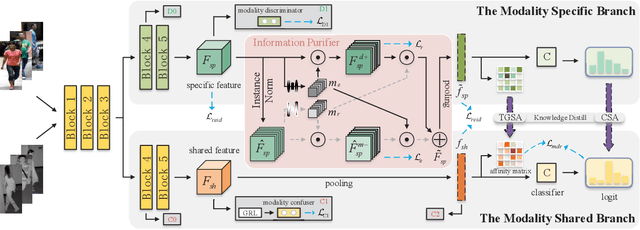
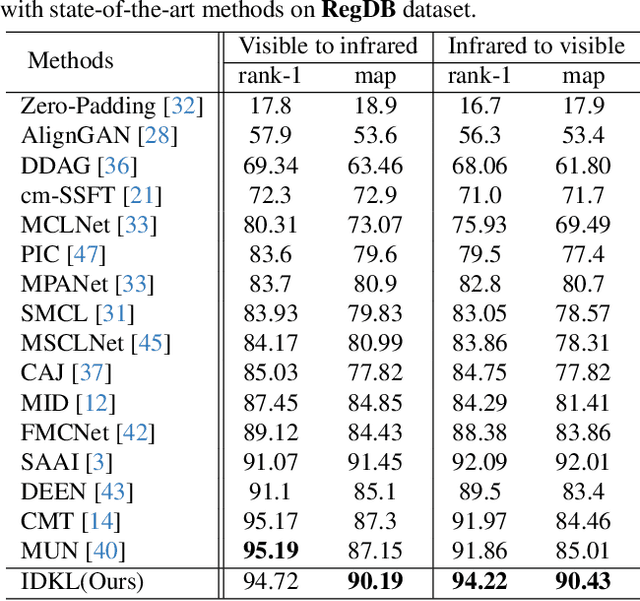
Visible-Infrared Person Re-identification (VI-ReID) is a challenging cross-modal pedestrian retrieval task, due to significant intra-class variations and cross-modal discrepancies among different cameras. Existing works mainly focus on embedding images of different modalities into a unified space to mine modality-shared features. They only seek distinctive information within these shared features, while ignoring the identity-aware useful information that is implicit in the modality-specific features. To address this issue, we propose a novel Implicit Discriminative Knowledge Learning (IDKL) network to uncover and leverage the implicit discriminative information contained within the modality-specific. First, we extract modality-specific and modality-shared features using a novel dual-stream network. Then, the modality-specific features undergo purification to reduce their modality style discrepancies while preserving identity-aware discriminative knowledge. Subsequently, this kind of implicit knowledge is distilled into the modality-shared feature to enhance its distinctiveness. Finally, an alignment loss is proposed to minimize modality discrepancy on enhanced modality-shared features. Extensive experiments on multiple public datasets demonstrate the superiority of IDKL network over the state-of-the-art methods. Code is available at https://github.com/1KK077/IDKL.
UAlign: Pushing the Limit of Template-free Retrosynthesis Prediction with Unsupervised SMILES Alignment
Mar 25, 2024Retrosynthesis planning poses a formidable challenge in the organic chemical industry, particularly in pharmaceuticals. Single-step retrosynthesis prediction, a crucial step in the planning process, has witnessed a surge in interest in recent years due to advancements in AI for science. Various deep learning-based methods have been proposed for this task in recent years, incorporating diverse levels of additional chemical knowledge dependency. This paper introduces UAlign, a template-free graph-to-sequence pipeline for retrosynthesis prediction. By combining graph neural networks and Transformers, our method can more effectively leverage the inherent graph structure of molecules. Based on the fact that the majority of molecule structures remain unchanged during a chemical reaction, we propose a simple yet effective SMILES alignment technique to facilitate the reuse of unchanged structures for reactant generation. Extensive experiments show that our method substantially outperforms state-of-the-art template-free and semi-template-based approaches. Importantly, Our template-free method achieves effectiveness comparable to, or even surpasses, established powerful template-based methods. Scientific contribution: We present a novel graph-to-sequence template-free retrosynthesis prediction pipeline that overcomes the limitations of Transformer-based methods in molecular representation learning and insufficient utilization of chemical information. We propose an unsupervised learning mechanism for establishing product-atom correspondence with reactant SMILES tokens, achieving even better results than supervised SMILES alignment methods. Extensive experiments demonstrate that UAlign significantly outperforms state-of-the-art template-free methods and rivals or surpasses template-based approaches, with up to 5\% (top-5) and 5.4\% (top-10) increased accuracy over the strongest baseline.
Brain Stroke Segmentation Using Deep Learning Models: A Comparative Study
Mar 25, 2024Stroke segmentation plays a crucial role in the diagnosis and treatment of stroke patients by providing spatial information about affected brain regions and the extent of damage. Segmenting stroke lesions accurately is a challenging task, given that conventional manual techniques are time consuming and prone to errors. Recently, advanced deep models have been introduced for general medical image segmentation, demonstrating promising results that surpass many state of the art networks when evaluated on specific datasets. With the advent of the vision Transformers, several models have been introduced based on them, while others have aimed to design better modules based on traditional convolutional layers to extract long-range dependencies like Transformers. The question of whether such high-level designs are necessary for all segmentation cases to achieve the best results remains unanswered. In this study, we selected four types of deep models that were recently proposed and evaluated their performance for stroke segmentation: a pure Transformer-based architecture (DAE-Former), two advanced CNN-based models (LKA and DLKA) with attention mechanisms in their design, an advanced hybrid model that incorporates CNNs with Transformers (FCT), and the well-known self-adaptive nnUNet framework with its configuration based on given data. We examined their performance on two publicly available datasets, and found that the nnUNet achieved the best results with the simplest design among all. Revealing the robustness issue of Transformers to such variabilities serves as a potential reason for their weaker performance. Furthermore, nnUNet's success underscores the significant impact of preprocessing and postprocessing techniques in enhancing segmentation results, surpassing the focus solely on architectural designs
Backpropagation through space, time, and the brain
Mar 25, 2024Effective learning in neuronal networks requires the adaptation of individual synapses given their relative contribution to solving a task. However, physical neuronal systems -- whether biological or artificial -- are constrained by spatio-temporal locality. How such networks can perform efficient credit assignment, remains, to a large extent, an open question. In Machine Learning, the answer is almost universally given by the error backpropagation algorithm, through both space (BP) and time (BPTT). However, BP(TT) is well-known to rely on biologically implausible assumptions, in particular with respect to spatiotemporal (non-)locality, while forward-propagation models such as real-time recurrent learning (RTRL) suffer from prohibitive memory constraints. We introduce Generalized Latent Equilibrium (GLE), a computational framework for fully local spatio-temporal credit assignment in physical, dynamical networks of neurons. We start by defining an energy based on neuron-local mismatches, from which we derive both neuronal dynamics via stationarity and parameter dynamics via gradient descent. The resulting dynamics can be interpreted as a real-time, biologically plausible approximation of BPTT in deep cortical networks with continuous-time neuronal dynamics and continuously active, local synaptic plasticity. In particular, GLE exploits the ability of biological neurons to phase-shift their output rate with respect to their membrane potential, which is essential in both directions of information propagation. For the forward computation, it enables the mapping of time-continuous inputs to neuronal space, performing an effective spatiotemporal convolution. For the backward computation, it permits the temporal inversion of feedback signals, which consequently approximate the adjoint states necessary for useful parameter updates.
In the Search for Optimal Multi-view Learning Models for Crop Classification with Global Remote Sensing Data
Mar 25, 2024Crop classification is of critical importance due to its role in studying crop pattern changes, resource management, and carbon sequestration. When employing data-driven techniques for its prediction, utilizing various temporal data sources is necessary. Deep learning models have proven to be effective for this task by mapping time series data to high-level representation for prediction. However, they face substantial challenges when dealing with multiple input patterns. The literature offers limited guidance for Multi-View Learning (MVL) scenarios, as it has primarily focused on exploring fusion strategies with specific encoders and validating them in local regions. In contrast, we investigate the impact of simultaneous selection of the fusion strategy and the encoder architecture evaluated on a global-scale cropland and crop-type classifications. We use a range of five fusion strategies (Input, Feature, Decision, Ensemble, Hybrid) and five temporal encoder architectures (LSTM, GRU, TempCNN, TAE, L-TAE) as possible MVL model configurations. The validation is on the CropHarvest dataset that provides optical, radar, and weather time series, and topographic information as input data. We found that in scenarios with a limited number of labeled samples, a unique configuration is insufficient for all the cases. Instead, a specialized combination, including encoder and fusion strategy, should be meticulously sought. To streamline this search process, we suggest initially identifying the optimal encoder architecture tailored for a particular fusion strategy, and then determining the most suitable fusion strategy for the classification task. We provide a technical framework for researchers exploring crop classification or related tasks through a MVL approach.
Self-Supervised Learning for Medical Image Data with Anatomy-Oriented Imaging Planes
Mar 25, 2024Self-supervised learning has emerged as a powerful tool for pretraining deep networks on unlabeled data, prior to transfer learning of target tasks with limited annotation. The relevance between the pretraining pretext and target tasks is crucial to the success of transfer learning. Various pretext tasks have been proposed to utilize properties of medical image data (e.g., three dimensionality), which are more relevant to medical image analysis than generic ones for natural images. However, previous work rarely paid attention to data with anatomy-oriented imaging planes, e.g., standard cardiac magnetic resonance imaging views. As these imaging planes are defined according to the anatomy of the imaged organ, pretext tasks effectively exploiting this information can pretrain the networks to gain knowledge on the organ of interest. In this work, we propose two complementary pretext tasks for this group of medical image data based on the spatial relationship of the imaging planes. The first is to learn the relative orientation between the imaging planes and implemented as regressing their intersecting lines. The second exploits parallel imaging planes to regress their relative slice locations within a stack. Both pretext tasks are conceptually straightforward and easy to implement, and can be combined in multitask learning for better representation learning. Thorough experiments on two anatomical structures (heart and knee) and representative target tasks (semantic segmentation and classification) demonstrate that the proposed pretext tasks are effective in pretraining deep networks for remarkably boosted performance on the target tasks, and superior to other recent approaches.
Geometric Generative Models based on Morphological Equivariant PDEs and GANs
Mar 25, 2024Content and image generation consist in creating or generating data from noisy information by extracting specific features such as texture, edges, and other thin image structures. We are interested here in generative models, and two main problems are addressed. Firstly, the improvements of specific feature extraction while accounting at multiscale levels intrinsic geometric features; and secondly, the equivariance of the network to reduce its complexity and provide a geometric interpretability. To proceed, we propose a geometric generative model based on an equivariant partial differential equation (PDE) for group convolution neural networks (G-CNNs), so called PDE-G-CNNs, built on morphology operators and generative adversarial networks (GANs). Equivariant morphological PDE layers are composed of multiscale dilations and erosions formulated in Riemannian manifolds, while group symmetries are defined on a Lie group. We take advantage of the Lie group structure to properly integrate the equivariance in layers, and are able to use the Riemannian metric to solve the multiscale morphological operations. Each point of the Lie group is associated with a unique point in the manifold, which helps us derive a metric on the Riemannian manifold from a tensor field invariant under the Lie group so that the induced metric has the same symmetries. The proposed geometric morphological GAN (GM-GAN) is obtained by using the proposed morphological equivariant convolutions in PDE-G-CNNs to bring nonlinearity in classical CNNs. GM-GAN is evaluated on MNIST data and compared with GANs. Preliminary results show that GM-GAN model outperforms classical GAN.
Target Speech Extraction with Pre-trained AV-HuBERT and Mask-And-Recover Strategy
Mar 24, 2024Audio-visual target speech extraction (AV-TSE) is one of the enabling technologies in robotics and many audio-visual applications. One of the challenges of AV-TSE is how to effectively utilize audio-visual synchronization information in the process. AV-HuBERT can be a useful pre-trained model for lip-reading, which has not been adopted by AV-TSE. In this paper, we would like to explore the way to integrate a pre-trained AV-HuBERT into our AV-TSE system. We have good reasons to expect an improved performance. To benefit from the inter and intra-modality correlations, we also propose a novel Mask-And-Recover (MAR) strategy for self-supervised learning. The experimental results on the VoxCeleb2 dataset show that our proposed model outperforms the baselines both in terms of subjective and objective metrics, suggesting that the pre-trained AV-HuBERT model provides more informative visual cues for target speech extraction. Furthermore, through a comparative study, we confirm that the proposed Mask-And-Recover strategy is significantly effective.
Few-shot Object Localization
Mar 24, 2024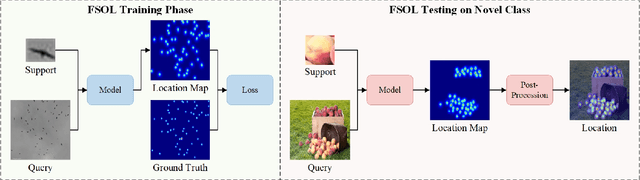
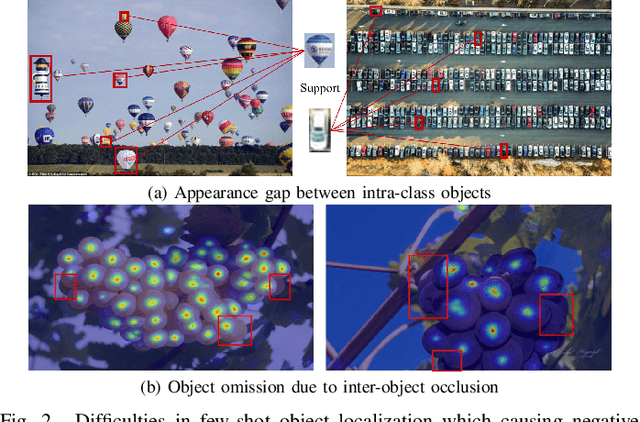
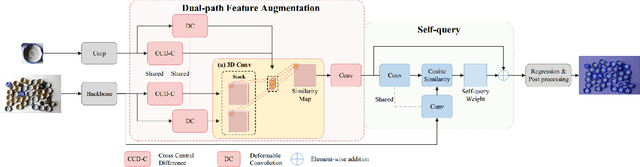

Existing object localization methods are tailored to locate a specific class of objects, relying on abundant labeled data for model optimization. However, in numerous real-world scenarios, acquiring large labeled data can be arduous, significantly constraining the broader application of localization models. To bridge this research gap, this paper proposes the novel task of Few-Shot Object Localization (FSOL), which seeks to achieve precise localization with limited samples available. This task achieves generalized object localization by leveraging a small number of labeled support samples to query the positional information of objects within corresponding images. To advance this research field, we propose an innovative high-performance baseline model. Our model integrates a dual-path feature augmentation module to enhance shape association and gradient differences between supports and query images, alongside a self query module designed to explore the association between feature maps and query images. Experimental results demonstrate a significant performance improvement of our approach in the FSOL task, establishing an efficient benchmark for further research. All codes and data are available at https://github.com/Ryh1218/FSOL.