 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Conditional Mutual Information for Disentangled Representations in Reinforcement Learning
May 23, 2023
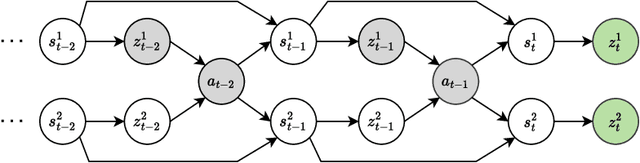

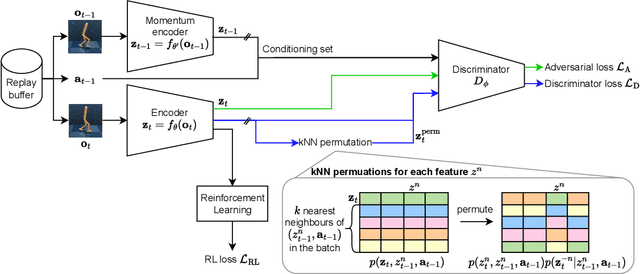

Reinforcement Learning (RL) environments can produce training data with spurious correlations between features due to the amount of training data or its limited feature coverage. This can lead to RL agents encoding these misleading correlations in their latent representation, preventing the agent from generalising if the correlation changes within the environment or when deployed in the real world. Disentangled representations can improve robustness, but existing disentanglement techniques that minimise mutual information between features require independent features, thus they cannot disentangle correlated features. We propose an auxiliary task for RL algorithms that learns a disentangled representation of high-dimensional observations with correlated features by minimising the conditional mutual information between features in the representation. We demonstrate experimentally, using continuous control tasks, that our approach improves generalisation under correlation shifts, as well as improving the training performance of RL algorithms in the presence of correlated features.
Continual Road-Scene Semantic Segmentation via Feature-Aligned Symmetric Multi-Modal Network
Aug 09, 2023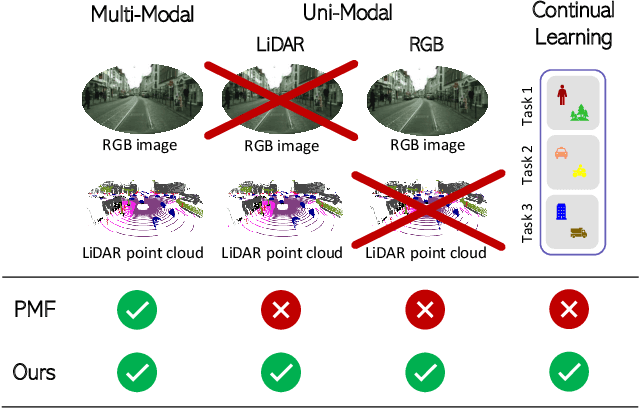
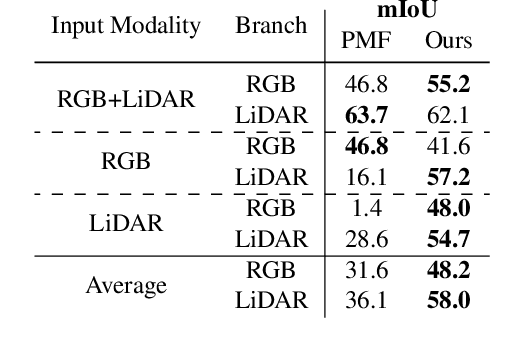
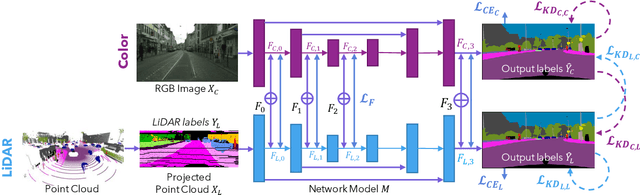

State-of-the-art multimodal semantic segmentation approaches combining LiDAR and color data are usually designed on top of asymmetric information-sharing schemes and assume that both modalities are always available. Regrettably, this strong assumption may not hold in real-world scenarios, where sensors are prone to failure or can face adverse conditions (night-time, rain, fog, etc.) that make the acquired information unreliable. Moreover, these architectures tend to fail in continual learning scenarios. In this work, we re-frame the task of multimodal semantic segmentation by enforcing a tightly-coupled feature representation and a symmetric information-sharing scheme, which allows our approach to work even when one of the input modalities is missing. This makes our model reliable even in safety-critical settings, as is the case of autonomous driving. We evaluate our approach on the SemanticKITTI dataset, comparing it with our closest competitor. We also introduce an ad-hoc continual learning scheme and show results in a class-incremental continual learning scenario that prove the effectiveness of the approach also in this setting.
Feature Extraction Using Deep Generative Models for Bangla Text Classification on a New Comprehensive Dataset
Aug 21, 2023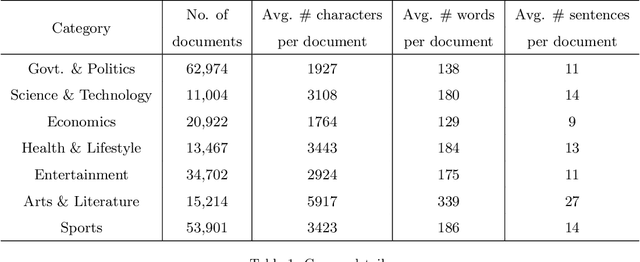
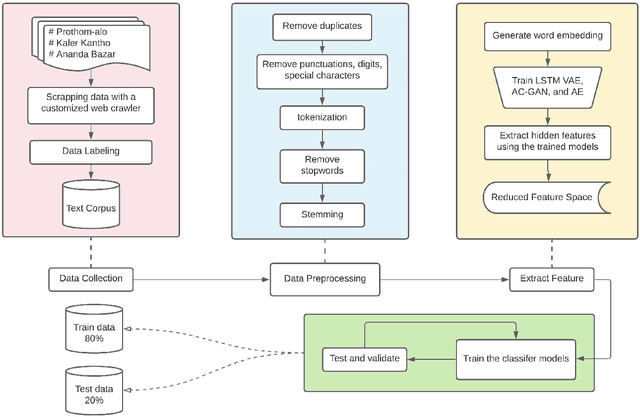
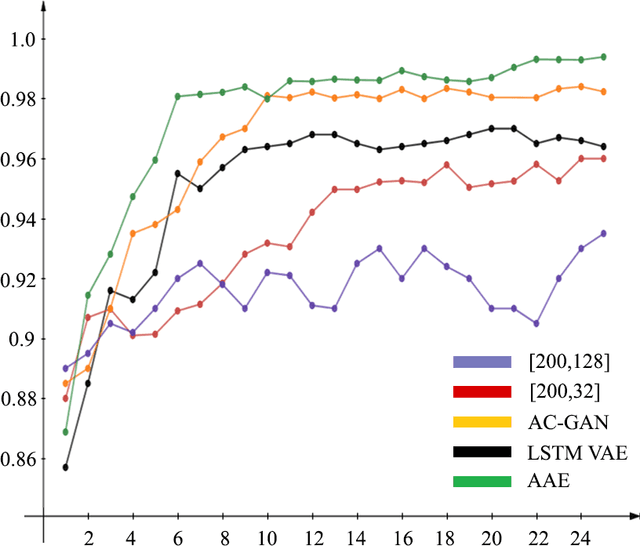
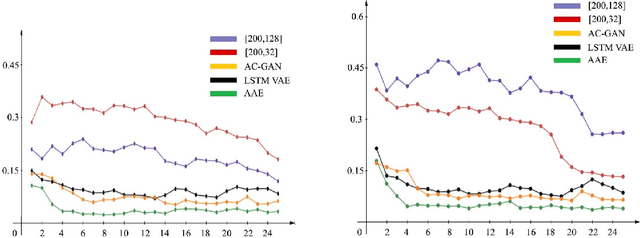
The selection of features for text classification is a fundamental task in text mining and information retrieval. Despite being the sixth most widely spoken language in the world, Bangla has received little attention due to the scarcity of text datasets. In this research, we collected, annotated, and prepared a comprehensive dataset of 212,184 Bangla documents in seven different categories and made it publicly accessible. We implemented three deep learning generative models: LSTM variational autoencoder (LSTM VAE), auxiliary classifier generative adversarial network (AC-GAN), and adversarial autoencoder (AAE) to extract text features, although their applications are initially found in the field of computer vision. We utilized our dataset to train these three models and used the feature space obtained in the document classification task. We evaluated the performance of the classifiers and found that the adversarial autoencoder model produced the best feature space.
Adaptive Preferential Attached kNN Graph with Distribution-Awareness
Aug 21, 2023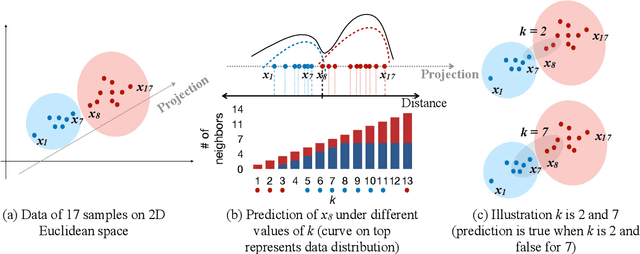
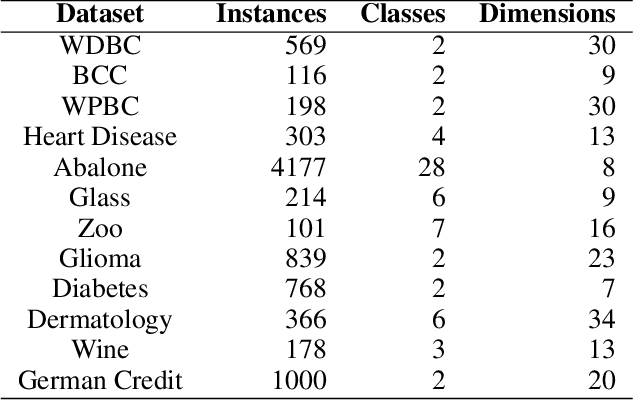
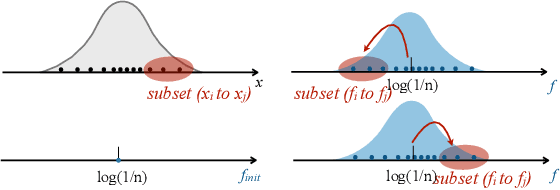
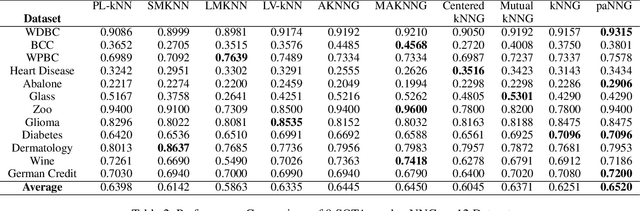
Graph-based kNN algorithms have garnered widespread popularity for machine learning tasks due to their simplicity and effectiveness. However, as factual data often inherit complex distributions, the conventional kNN graph's reliance on a unified k-value can hinder its performance. A crucial factor behind this challenge is the presence of ambiguous samples along decision boundaries that are inevitably more prone to incorrect classifications. To address the situation, we propose the Preferential Attached k-Nearest Neighbors Graph (paNNG), which adopts distribution-aware adaptive-k into graph construction. By incorporating distribution information as a cohesive entity, paNNG can significantly improve performance on ambiguous samples by "pulling" them towards their original classes and hence enhance overall generalization capability. Through rigorous evaluations on diverse datasets, paNNG outperforms state-of-the-art algorithms, showcasing its adaptability and efficacy across various real-world scenarios.
GAEI-UNet: Global Attention and Elastic Interaction U-Net for Vessel Image Segmentation
Aug 23, 2023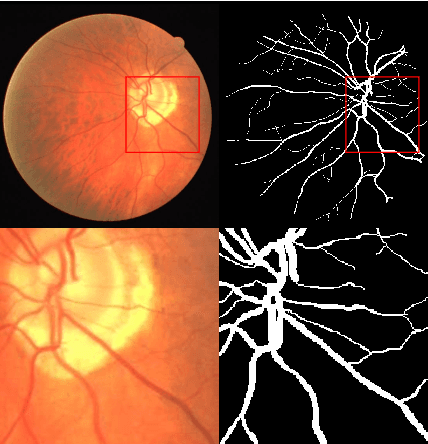
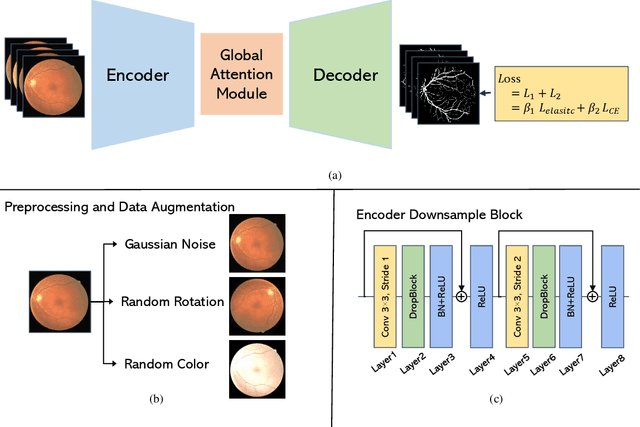
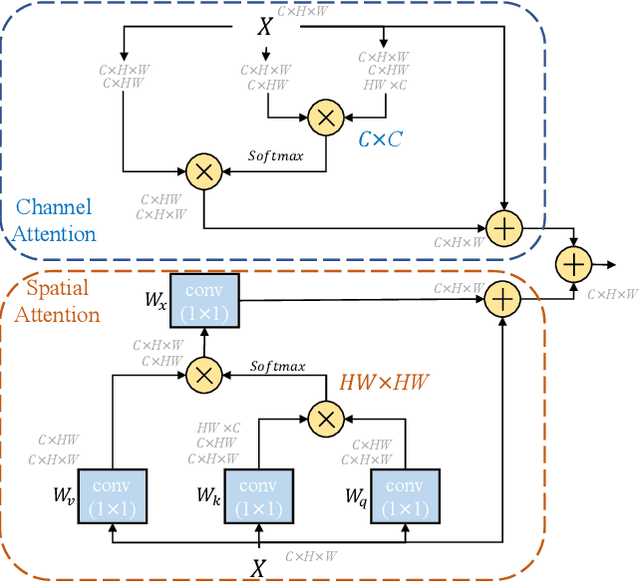
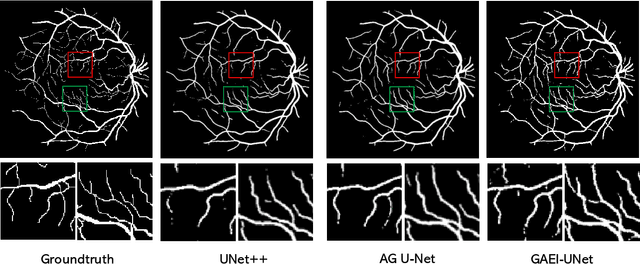
Vessel image segmentation plays a pivotal role in medical diagnostics, aiding in the early detection and treatment of vascular diseases. While segmentation based on deep learning has shown promising results, effectively segmenting small structures and maintaining connectivity between them remains challenging. To address these limitations, we propose GAEI-UNet, a novel model that combines global attention and elastic interaction-based techniques. GAEI-UNet leverages global spatial and channel context information to enhance high-level semantic understanding within the U-Net architecture, enabling precise segmentation of small vessels. Additionally, we adopt an elastic interaction-based loss function to improve connectivity among these fine structures. By capturing the forces generated by misalignment between target and predicted shapes, our model effectively learns to preserve the correct topology of vessel networks. Evaluation on retinal vessel dataset -- DRIVE demonstrates the superior performance of GAEI-UNet in terms of SE and connectivity of small structures, without significantly increasing computational complexity. This research aims to advance the field of vessel image segmentation, providing more accurate and reliable diagnostic tools for the medical community. The implementation code is available on Code.
Maintaining Plasticity via Regenerative Regularization
Aug 23, 2023In continual learning, plasticity refers to the ability of an agent to quickly adapt to new information. Neural networks are known to lose plasticity when processing non-stationary data streams. In this paper, we propose L2 Init, a very simple approach for maintaining plasticity by incorporating in the loss function L2 regularization toward initial parameters. This is very similar to standard L2 regularization (L2), the only difference being that L2 regularizes toward the origin. L2 Init is simple to implement and requires selecting only a single hyper-parameter. The motivation for this method is the same as that of methods that reset neurons or parameter values. Intuitively, when recent losses are insensitive to particular parameters, these parameters drift toward their initial values. This prepares parameters to adapt quickly to new tasks. On simple problems representative of different types of nonstationarity in continual learning, we demonstrate that L2 Init consistently mitigates plasticity loss. We additionally find that our regularization term reduces parameter magnitudes and maintains a high effective feature rank.
Fast Exact NPN Classification with Influence-aided Canonical Form
Aug 23, 2023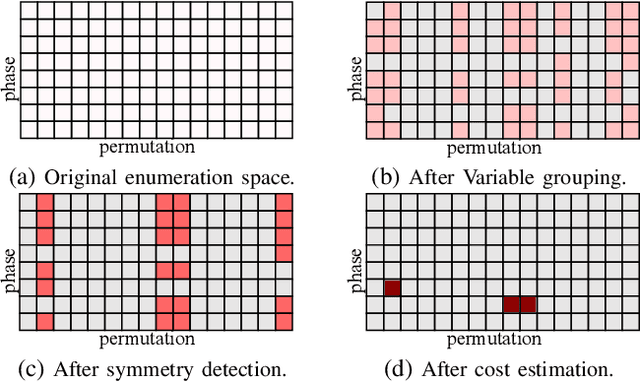
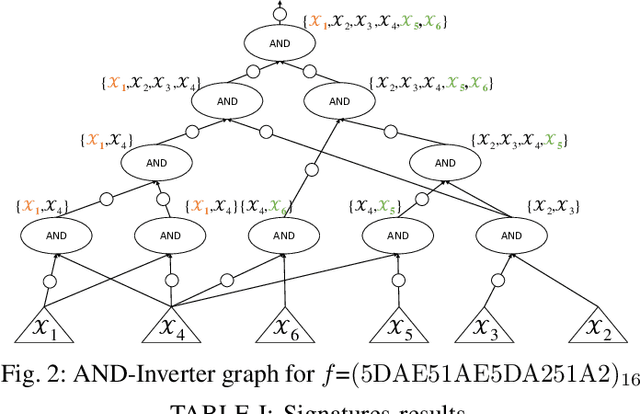
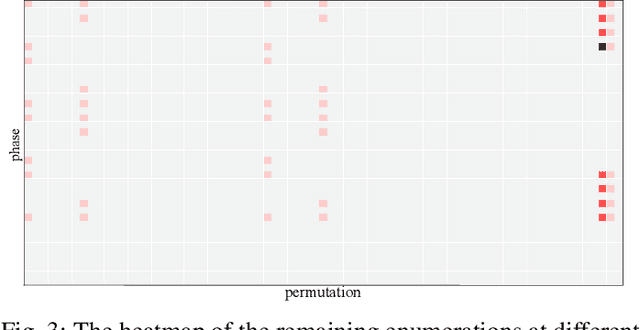
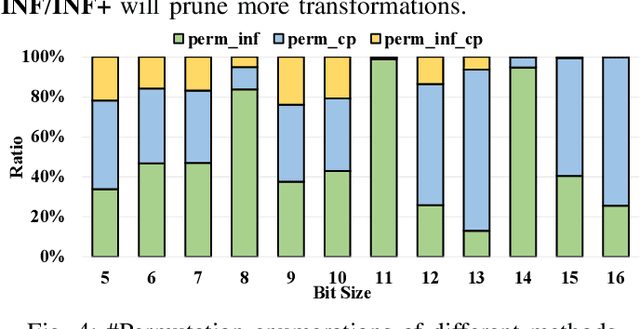
NPN classification has many applications in the synthesis and verification of digital circuits. The canonical-form-based method is the most common approach, designing a canonical form as representative for the NPN equivalence class first and then computing the transformation function according to the canonical form. Most works use variable symmetries and several signatures, mainly based on the cofactor, to simplify the canonical form construction and computation. This paper describes a novel canonical form and its computation algorithm by introducing Boolean influence to NPN classification, which is a basic concept in analysis of Boolean functions. We show that influence is input-negation-independent, input-permutation-dependent, and has other structural information than previous signatures for NPN classification. Therefore, it is a significant ingredient in speeding up NPN classification. Experimental results prove that influence plays an important role in reducing the transformation enumeration in computing the canonical form. Compared with the state-of-the-art algorithm implemented in ABC, our influence-aided canonical form for exact NPN classification gains up to 5.5x speedup.
Modeling Bends in Popular Music Guitar Tablatures
Aug 22, 2023Tablature notation is widely used in popular music to transcribe and share guitar musical content. As a complement to standard score notation, tablatures transcribe performance gesture information including finger positions and a variety of guitar-specific playing techniques such as slides, hammer-on/pull-off or bends.This paper focuses on bends, which enable to progressively shift the pitch of a note, therefore circumventing physical limitations of the discrete fretted fingerboard. In this paper, we propose a set of 25 high-level features, computed for each note of the tablature, to study how bend occurrences can be predicted from their past and future short-term context. Experiments are performed on a corpus of 932 lead guitar tablatures of popular music and show that a decision tree successfully predicts bend occurrences with an F1 score of 0.71 anda limited amount of false positive predictions, demonstrating promising applications to assist the arrangement of non-guitar music into guitar tablatures.
Uncertainty Estimation of Transformers' Predictions via Topological Analysis of the Attention Matrices
Aug 22, 2023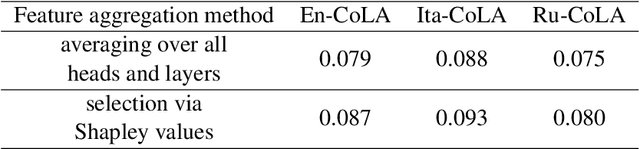
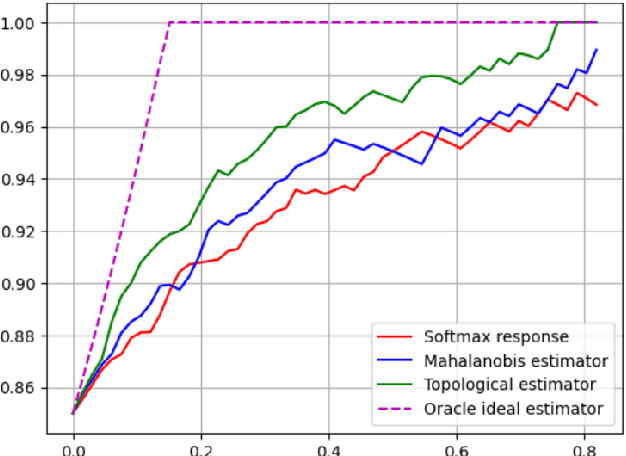
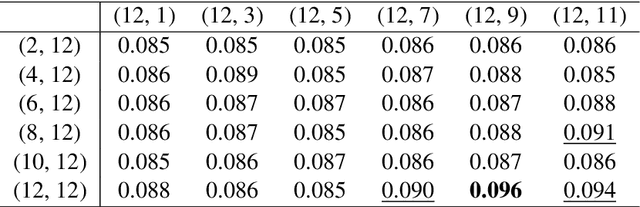
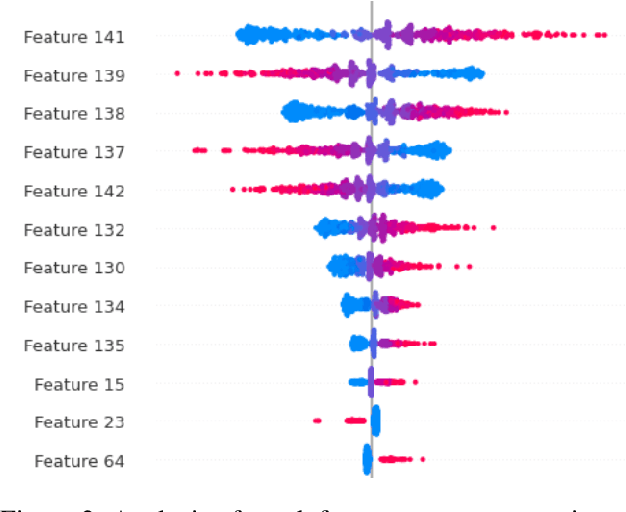
Determining the degree of confidence of deep learning model in its prediction is an open problem in the field of natural language processing. Most of the classical methods for uncertainty estimation are quite weak for text classification models. We set the task of obtaining an uncertainty estimate for neural networks based on the Transformer architecture. A key feature of such mo-dels is the attention mechanism, which supports the information flow between the hidden representations of tokens in the neural network. We explore the formed relationships between internal representations using Topological Data Analysis methods and utilize them to predict model's confidence. In this paper, we propose a method for uncertainty estimation based on the topological properties of the attention mechanism and compare it with classical methods. As a result, the proposed algorithm surpasses the existing methods in quality and opens up a new area of application of the attention mechanism, but requires the selection of topological features.
Masked Cross-image Encoding for Few-shot Segmentation
Aug 22, 2023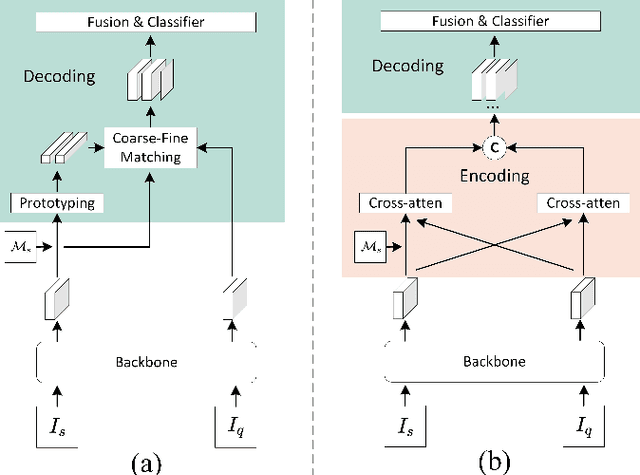
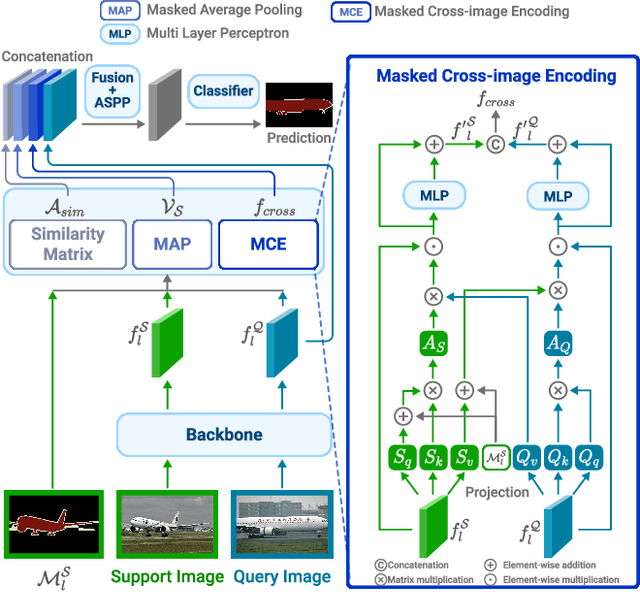

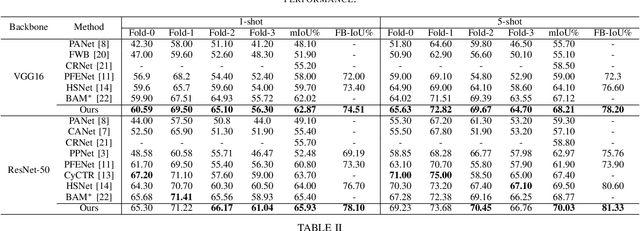
Few-shot segmentation (FSS) is a dense prediction task that aims to infer the pixel-wise labels of unseen classes using only a limited number of annotated images. The key challenge in FSS is to classify the labels of query pixels using class prototypes learned from the few labeled support exemplars. Prior approaches to FSS have typically focused on learning class-wise descriptors independently from support images, thereby ignoring the rich contextual information and mutual dependencies among support-query features. To address this limitation, we propose a joint learning method termed Masked Cross-Image Encoding (MCE), which is designed to capture common visual properties that describe object details and to learn bidirectional inter-image dependencies that enhance feature interaction. MCE is more than a visual representation enrichment module; it also considers cross-image mutual dependencies and implicit guidance. Experiments on FSS benchmarks PASCAL-$5^i$ and COCO-$20^i$ demonstrate the advanced meta-learning ability of the proposed method.