 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Adaptive Face Recognition Using Adversarial Information Network
May 23, 2023
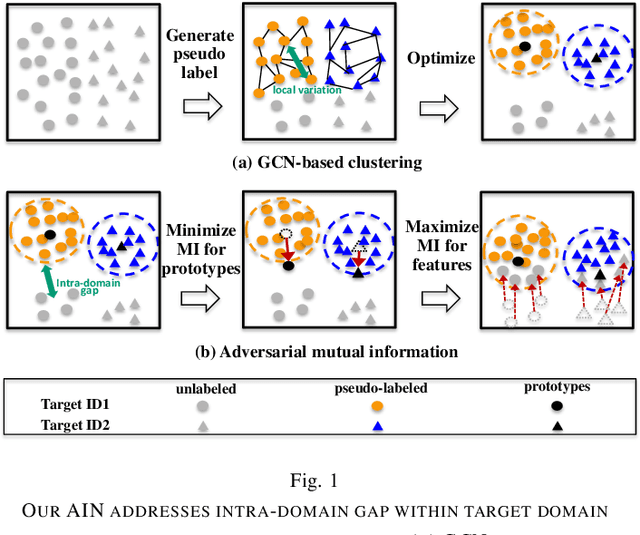

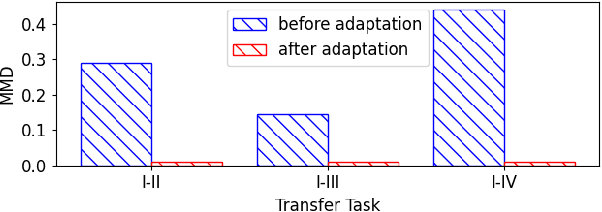
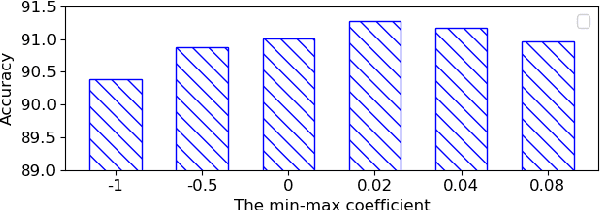
In many real-world applications, face recognition models often degenerate when training data (referred to as source domain) are different from testing data (referred to as target domain). To alleviate this mismatch caused by some factors like pose and skin tone, the utilization of pseudo-labels generated by clustering algorithms is an effective way in unsupervised domain adaptation. However, they always miss some hard positive samples. Supervision on pseudo-labeled samples attracts them towards their prototypes and would cause an intra-domain gap between pseudo-labeled samples and the remaining unlabeled samples within target domain, which results in the lack of discrimination in face recognition. In this paper, considering the particularity of face recognition, we propose a novel adversarial information network (AIN) to address it. First, a novel adversarial mutual information (MI) loss is proposed to alternately minimize MI with respect to the target classifier and maximize MI with respect to the feature extractor. By this min-max manner, the positions of target prototypes are adaptively modified which makes unlabeled images clustered more easily such that intra-domain gap can be mitigated. Second, to assist adversarial MI loss, we utilize a graph convolution network to predict linkage likelihoods between target data and generate pseudo-labels. It leverages valuable information in the context of nodes and can achieve more reliable results. The proposed method is evaluated under two scenarios, i.e., domain adaptation across poses and image conditions, and domain adaptation across faces with different skin tones. Extensive experiments show that AIN successfully improves cross-domain generalization and offers a new state-of-the-art on RFW dataset.
Calibrated Explanations for Regression
Sep 01, 2023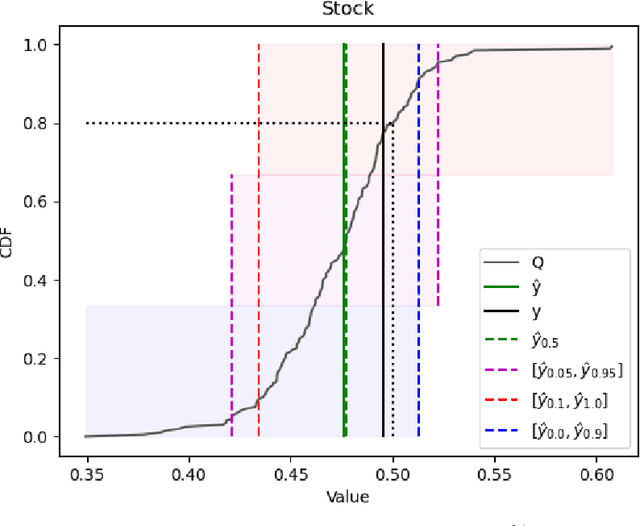

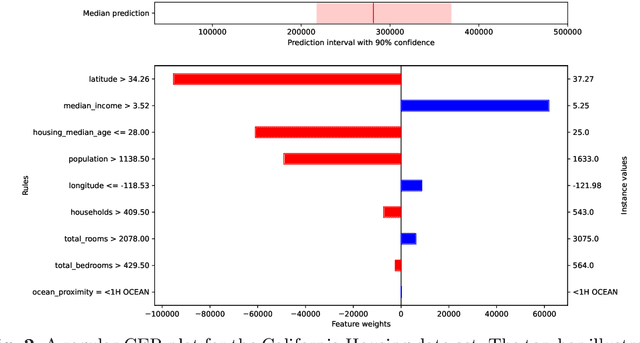

Artificial Intelligence (AI) is often an integral part of modern decision support systems (DSSs). The best-performing predictive models used in AI-based DSSs lack transparency. Explainable Artificial Intelligence (XAI) aims to create AI systems that can explain their rationale to human users. Local explanations in XAI can provide information about the causes of individual predictions in terms of feature importance. However, a critical drawback of existing local explanation methods is their inability to quantify the uncertainty associated with a feature's importance. This paper introduces an extension of a feature importance explanation method, Calibrated Explanations (CE), previously only supporting classification, with support for standard regression and probabilistic regression, i.e., the probability that the target is above an arbitrary threshold. The extension for regression keeps all the benefits of CE, such as calibration of the prediction from the underlying model with confidence intervals, uncertainty quantification of feature importance, and allows both factual and counterfactual explanations. CE for standard regression provides fast, reliable, stable, and robust explanations. CE for probabilistic regression provides an entirely new way of creating probabilistic explanations from any ordinary regression model and with a dynamic selection of thresholds. The performance of CE for probabilistic regression regarding stability and speed is comparable to LIME. The method is model agnostic with easily understood conditional rules. An implementation in Python is freely available on GitHub and for installation using pip making the results in this paper easily replicable.
FAM: fast adaptive federated meta-learning
Sep 01, 2023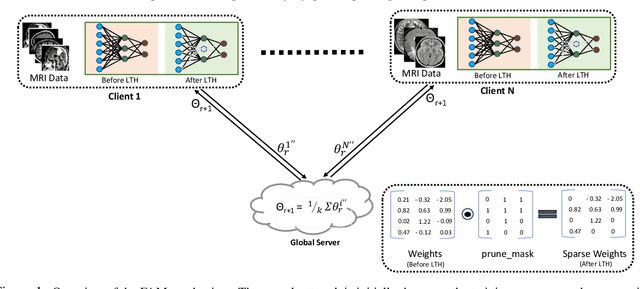

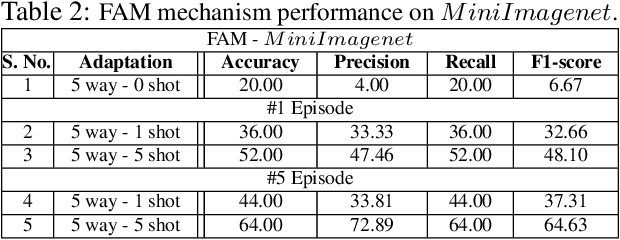
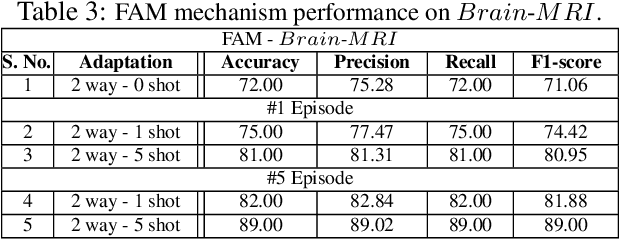
In this work, we propose a fast adaptive federated meta-learning (FAM) framework for collaboratively learning a single global model, which can then be personalized locally on individual clients. Federated learning enables multiple clients to collaborate to train a model without sharing data. Clients with insufficient data or data diversity participate in federated learning to learn a model with superior performance. Nonetheless, learning suffers when data distributions diverge. There is a need to learn a global model that can be adapted using client's specific information to create personalized models on clients is required. MRI data suffers from this problem, wherein, one, due to data acquisition challenges, local data at a site is sufficient for training an accurate model and two, there is a restriction of data sharing due to privacy concerns and three, there is a need for personalization of a learnt shared global model on account of domain shift across client sites. The global model is sparse and captures the common features in the MRI. This skeleton network is grown on each client to train a personalized model by learning additional client-specific parameters from local data. Experimental results show that the personalization process at each client quickly converges using a limited number of epochs. The personalized client models outperformed the locally trained models, demonstrating the efficacy of the FAM mechanism. Additionally, the sparse parameter set to be communicated during federated learning drastically reduced communication overhead, which makes the scheme viable for networks with limited resources.
Multitask Deep Learning for Accurate Risk Stratification and Prediction of Next Steps for Coronary CT Angiography Patients
Sep 01, 2023Diagnostic investigation has an important role in risk stratification and clinical decision making of patients with suspected and documented Coronary Artery Disease (CAD). However, the majority of existing tools are primarily focused on the selection of gatekeeper tests, whereas only a handful of systems contain information regarding the downstream testing or treatment. We propose a multi-task deep learning model to support risk stratification and down-stream test selection for patients undergoing Coronary Computed Tomography Angiography (CCTA). The analysis included 14,021 patients who underwent CCTA between 2006 and 2017. Our novel multitask deep learning framework extends the state-of-the art Perceiver model to deal with real-world CCTA report data. Our model achieved an Area Under the receiver operating characteristic Curve (AUC) of 0.76 in CAD risk stratification, and 0.72 AUC in predicting downstream tests. Our proposed deep learning model can accurately estimate the likelihood of CAD and provide recommended downstream tests based on prior CCTA data. In clinical practice, the utilization of such an approach could bring a paradigm shift in risk stratification and downstream management. Despite significant progress using deep learning models for tabular data, they do not outperform gradient boosting decision trees, and further research is required in this area. However, neural networks appear to benefit more readily from multi-task learning than tree-based models. This could offset the shortcomings of using single task learning approach when working with tabular data.
Projecting Robot Intentions Through Visual Cues: Static vs. Dynamic Signaling
Aug 19, 2023
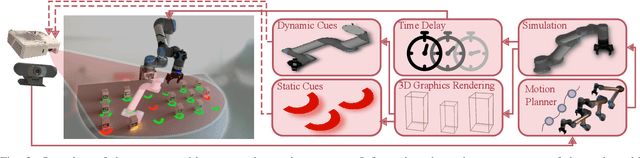

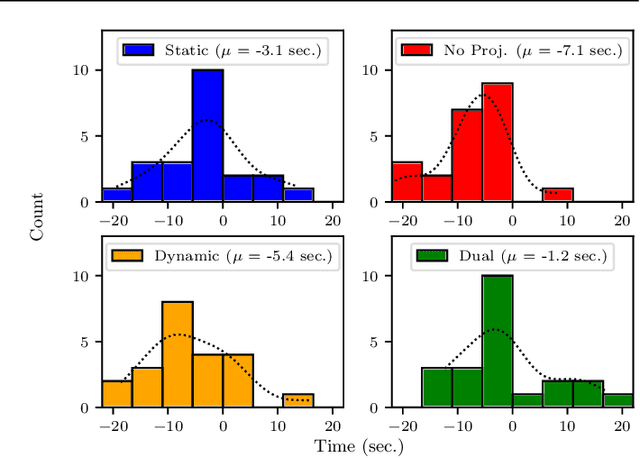
Augmented and mixed-reality techniques harbor a great potential for improving human-robot collaboration. Visual signals and cues may be projected to a human partner in order to explicitly communicate robot intentions and goals. However, it is unclear what type of signals support such a process and whether signals can be combined without adding additional cognitive stress to the partner. This paper focuses on identifying the effective types of visual signals and quantify their impact through empirical evaluations. In particular, the study compares static and dynamic visual signals within a collaborative object sorting task and assesses their ability to shape human behavior. Furthermore, an information-theoretic analysis is performed to numerically quantify the degree of information transfer between visual signals and human behavior. The results of a human subject experiment show that there are significant advantages to combining multiple visual signals within a single task, i.e., increased task efficiency and reduced cognitive load.
Contrastive Learning for Non-Local Graphs with Multi-Resolution Structural Views
Aug 19, 2023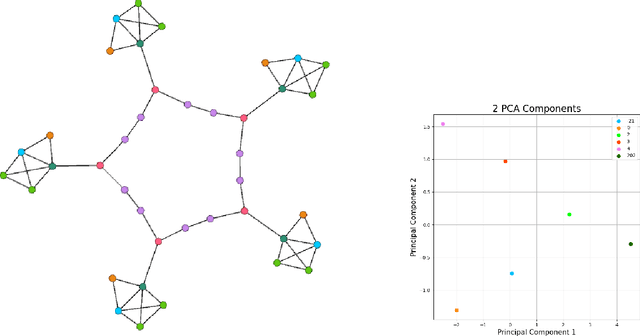
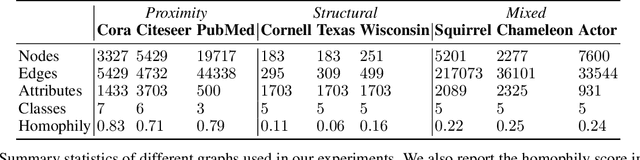
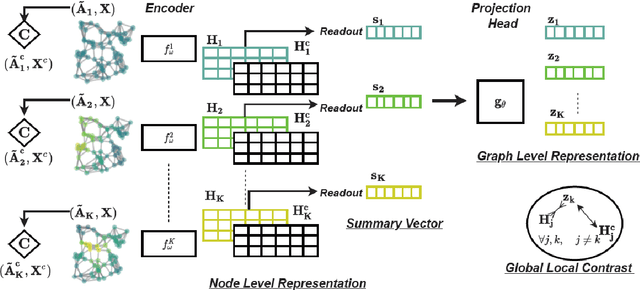
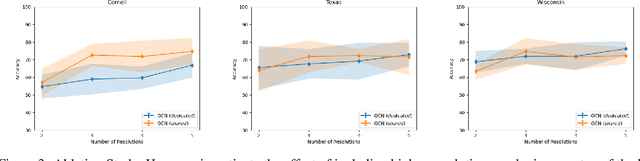
Learning node-level representations of heterophilic graphs is crucial for various applications, including fraudster detection and protein function prediction. In such graphs, nodes share structural similarity identified by the equivalence of their connectivity which is implicitly encoded in the form of higher-order hierarchical information in the graphs. The contrastive methods are popular choices for learning the representation of nodes in a graph. However, existing contrastive methods struggle to capture higher-order graph structures. To address this limitation, we propose a novel multiview contrastive learning approach that integrates diffusion filters on graphs. By incorporating multiple graph views as augmentations, our method captures the structural equivalence in heterophilic graphs, enabling the discovery of hidden relationships and similarities not apparent in traditional node representations. Our approach outperforms baselines on synthetic and real structural datasets, surpassing the best baseline by $16.06\%$ on Cornell, $3.27\%$ on Texas, and $8.04\%$ on Wisconsin. Additionally, it consistently achieves superior performance on proximal tasks, demonstrating its effectiveness in uncovering structural information and improving downstream applications.
A unified framework for information-theoretic generalization bounds
May 18, 2023This paper presents a general methodology for deriving information-theoretic generalization bounds for learning algorithms. The main technical tool is a probabilistic decorrelation lemma based on a change of measure and a relaxation of Young's inequality in $L_{\psi_p}$ Orlicz spaces. Using the decorrelation lemma in combination with other techniques, such as symmetrization, couplings, and chaining in the space of probability measures, we obtain new upper bounds on the generalization error, both in expectation and in high probability, and recover as special cases many of the existing generalization bounds, including the ones based on mutual information, conditional mutual information, stochastic chaining, and PAC-Bayes inequalities. In addition, the Fernique-Talagrand upper bound on the expected supremum of a subgaussian process emerges as a special case.
Information Design in Multi-Agent Reinforcement Learning
May 08, 2023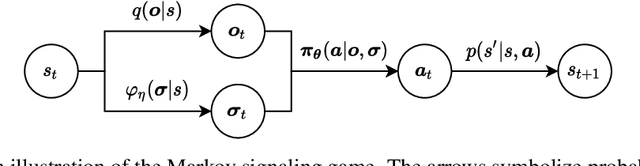
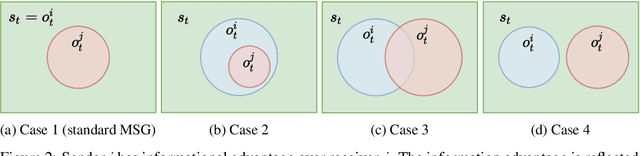
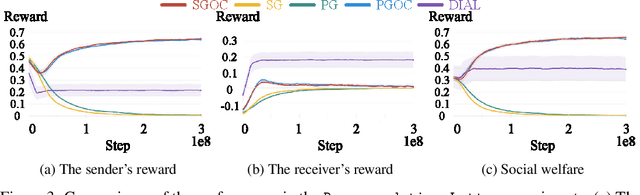

Reinforcement learning (RL) mimics how humans and animals interact with the environment. The setting is somewhat idealized because, in actual tasks, other agents in the environment have their own goals and behave adaptively to the ego agent. To thrive in those environments, the agent needs to influence other agents so their actions become more helpful and less harmful. Research in computational economics distills two ways to influence others directly: by providing tangible goods (mechanism design) and by providing information (information design). This work investigates information design problems for a group of RL agents. The main challenges are two-fold. One is the information provided will immediately affect the transition of the agent trajectories, which introduces additional non-stationarity. The other is the information can be ignored, so the sender must provide information that the receivers are willing to respect. We formulate the Markov signaling game, and develop the notions of signaling gradient and the extended obedience constraints that address these challenges. Our algorithm is efficient on various mixed-motive tasks and provides further insights into computational economics. Our code is available at https://github.com/YueLin301/InformationDesignMARL.
Learning Dynamic Graphs from All Contextual Information for Accurate Point-of-Interest Visit Forecasting
Jun 28, 2023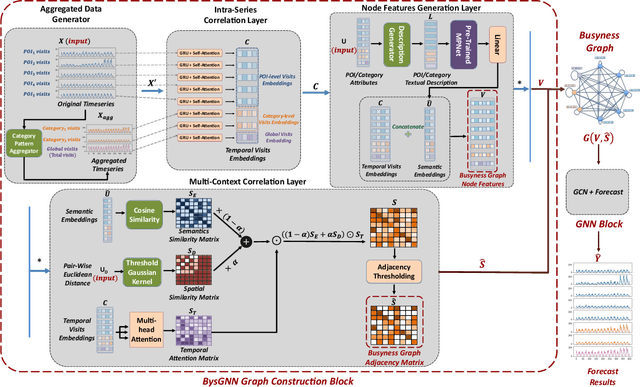

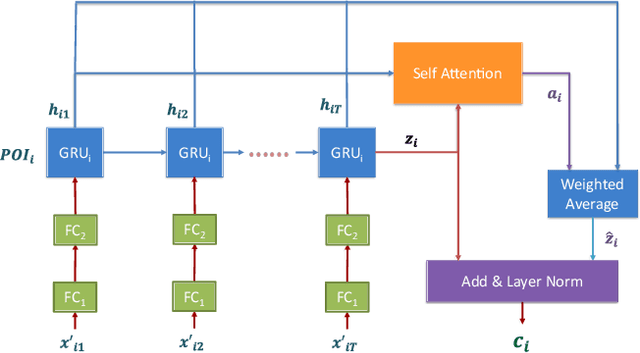

Forecasting the number of visits to Points-of-Interest (POI) in an urban area is critical for planning and decision-making for various application domains, from urban planning and transportation management to public health and social studies. Although this forecasting problem can be formulated as a multivariate time-series forecasting task, the current approaches cannot fully exploit the ever-changing multi-context correlations among POIs. Therefore, we propose Busyness Graph Neural Network (BysGNN), a temporal graph neural network designed to learn and uncover the underlying multi-context correlations between POIs for accurate visit forecasting. Unlike other approaches where only time-series data is used to learn a dynamic graph, BysGNN utilizes all contextual information and time-series data to learn an accurate dynamic graph representation. By incorporating all contextual, temporal, and spatial signals, we observe a significant improvement in our forecasting accuracy over state-of-the-art forecasting models in our experiments with real-world datasets across the United States.
CVNN-based Channel Estimation and Equalization in OFDM Systems Without Cyclic Prefix
Aug 25, 2023In modern communication systems operating with Orthogonal Frequency-Division Multiplexing (OFDM), channel estimation requires minimal complexity with one-tap equalizers. However, this depends on cyclic prefixes, which must be sufficiently large to cover the channel impulse response. Conversely, the use of cyclic prefix (CP) decreases the useful information that can be conveyed in an OFDM frame, thereby degrading the spectral efficiency of the system. In this context, we study the impact of CPs on channel estimation with complex-valued neural networks (CVNNs). We show that the phase-transmittance radial basis function neural network offers superior results, in terms of required energy per bit, compared to classical minimum mean-squared error and least squares algorithms in scenarios without CP.