 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Two-Stage Violence Detection Using ViTPose and Classification Models at Smart Airports
Aug 30, 2023
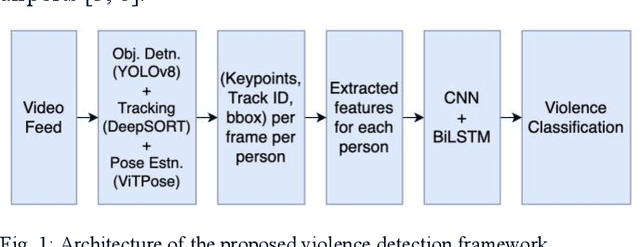

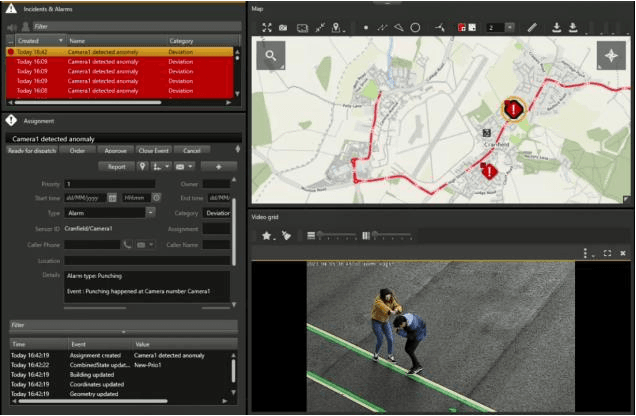
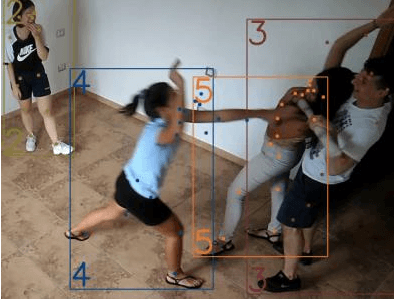
This study introduces an innovative violence detection framework tailored to the unique requirements of smart airports, where prompt responses to violent situations are crucial. The proposed framework harnesses the power of ViTPose for human pose estimation. It employs a CNN - BiLSTM network to analyse spatial and temporal information within keypoints sequences, enabling the accurate classification of violent behaviour in real time. Seamlessly integrated within the SAFE (Situational Awareness for Enhanced Security framework of SAAB, the solution underwent integrated testing to ensure robust performance in real world scenarios. The AIRTLab dataset, characterized by its high video quality and relevance to surveillance scenarios, is utilized in this study to enhance the model's accuracy and mitigate false positives. As airports face increased foot traffic in the post pandemic era, implementing AI driven violence detection systems, such as the one proposed, is paramount for improving security, expediting response times, and promoting data informed decision making. The implementation of this framework not only diminishes the probability of violent events but also assists surveillance teams in effectively addressing potential threats, ultimately fostering a more secure and protected aviation sector. Codes are available at: https://github.com/Asami-1/GDP.
MASA-TCN: Multi-anchor Space-aware Temporal Convolutional Neural Networks for Continuous and Discrete EEG Emotion Recognition
Aug 30, 2023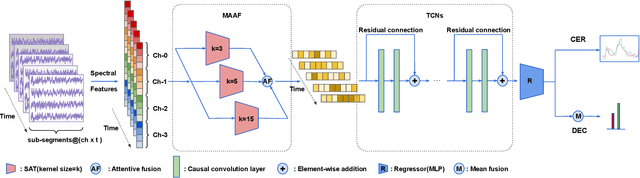
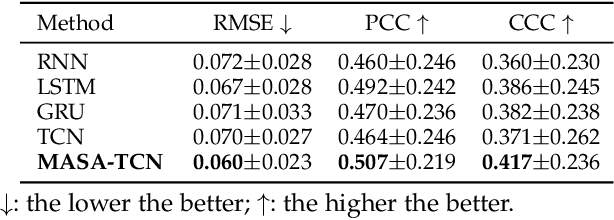
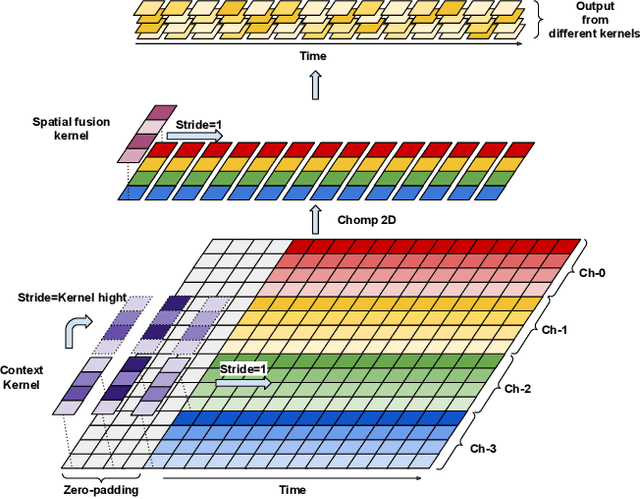
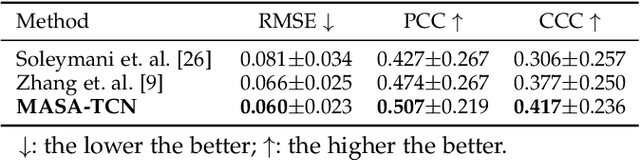
Emotion recognition using electroencephalogram (EEG) mainly has two scenarios: classification of the discrete labels and regression of the continuously tagged labels. Although many algorithms were proposed for classification tasks, there are only a few methods for regression tasks. For emotion regression, the label is continuous in time. A natural method is to learn the temporal dynamic patterns. In previous studies, long short-term memory (LSTM) and temporal convolutional neural networks (TCN) were utilized to learn the temporal contextual information from feature vectors of EEG. However, the spatial patterns of EEG were not effectively extracted. To enable the spatial learning ability of TCN towards better regression and classification performances, we propose a novel unified model, named MASA-TCN, for EEG emotion regression and classification tasks. The space-aware temporal layer enables TCN to additionally learn from spatial relations among EEG electrodes. Besides, a novel multi-anchor block with attentive fusion is proposed to learn dynamic temporal dependencies. Experiments on two publicly available datasets show MASA-TCN achieves higher results than the state-of-the-art methods for both EEG emotion regression and classification tasks. The code is available at https://github.com/yi-ding-cs/MASA-TCN.
Optimizing Factual Accuracy in Text Generation through Dynamic Knowledge Selection
Aug 30, 2023
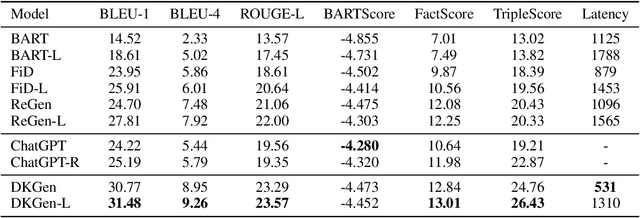
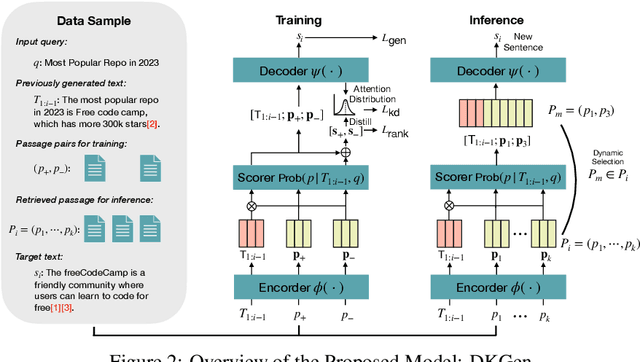
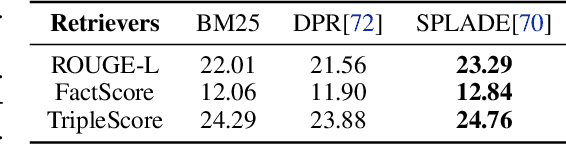
Language models (LMs) have revolutionized the way we interact with information, but they often generate nonfactual text, raising concerns about their reliability. Previous methods use external knowledge as references for text generation to enhance factuality but often struggle with the knowledge mix-up(e.g., entity mismatch) of irrelevant references. Besides,as the length of the output text grows, the randomness of sampling can escalate, detrimentally impacting the factual accuracy of the generated text. In this paper, we present DKGen, which divide the text generation process into an iterative process. In each iteration, DKGen takes the input query, the previously generated text and a subset of the reference passages as input to generate short text. During the process, the subset is dynamically selected from the full passage set based on their relevance to the previously generated text and the query, largely eliminating the irrelevant references from input. To further enhance DKGen's ability to correctly use these external knowledge, DKGen distills the relevance order of reference passages to the cross-attention distribution of decoder. We train and evaluate DKGen on a large-scale benchmark dataset. Experiment results show that DKGen outperforms all baseline models.
Self-Supervised Dynamic Hypergraph Recommendation based on Hyper-Relational Knowledge Graph
Aug 15, 2023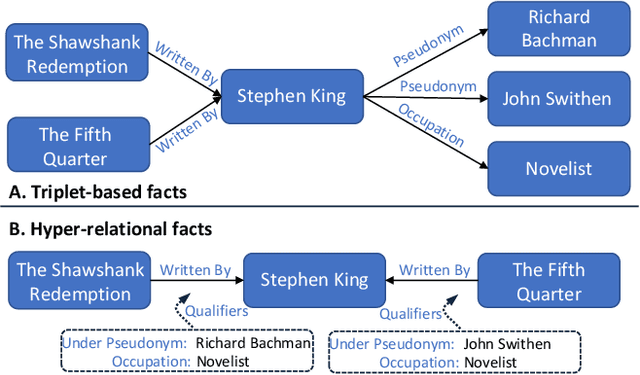
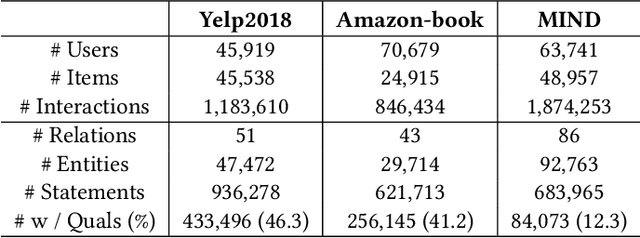
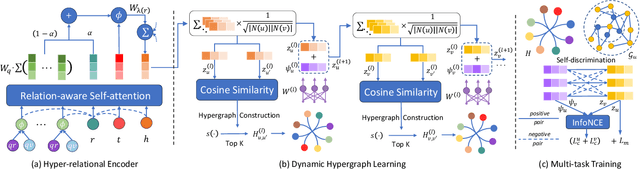
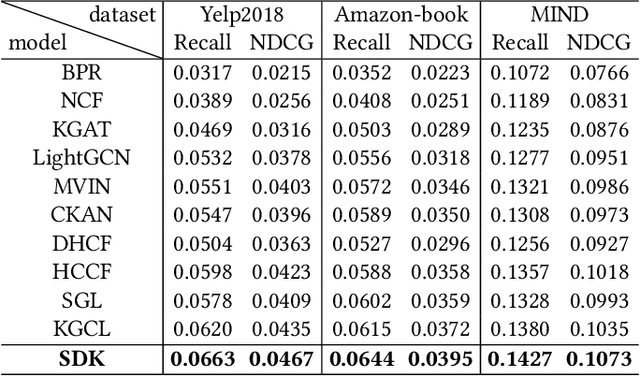
Knowledge graphs (KGs) are commonly used as side information to enhance collaborative signals and improve recommendation quality. In the context of knowledge-aware recommendation (KGR), graph neural networks (GNNs) have emerged as promising solutions for modeling factual and semantic information in KGs. However, the long-tail distribution of entities leads to sparsity in supervision signals, which weakens the quality of item representation when utilizing KG enhancement. Additionally, the binary relation representation of KGs simplifies hyper-relational facts, making it challenging to model complex real-world information. Furthermore, the over-smoothing phenomenon results in indistinguishable representations and information loss. To address these challenges, we propose the SDK (Self-Supervised Dynamic Hypergraph Recommendation based on Hyper-Relational Knowledge Graph) framework. This framework establishes a cross-view hypergraph self-supervised learning mechanism for KG enhancement. Specifically, we model hyper-relational facts in KGs to capture interdependencies between entities under complete semantic conditions. With the refined representation, a hypergraph is dynamically constructed to preserve features in the deep vector space, thereby alleviating the over-smoothing problem. Furthermore, we mine external supervision signals from both the global perspective of the hypergraph and the local perspective of collaborative filtering (CF) to guide the model prediction process. Extensive experiments conducted on different datasets demonstrate the superiority of the SDK framework over state-of-the-art models. The results showcase its ability to alleviate the effects of over-smoothing and supervision signal sparsity.
Teaching Smaller Language Models To Generalise To Unseen Compositional Questions
Aug 21, 2023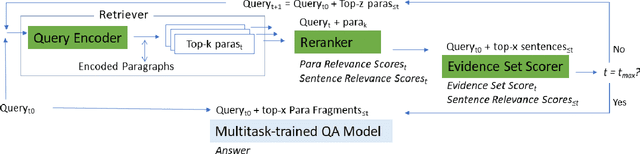

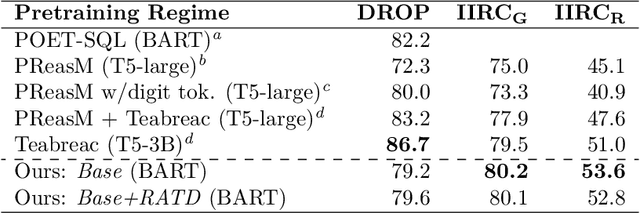
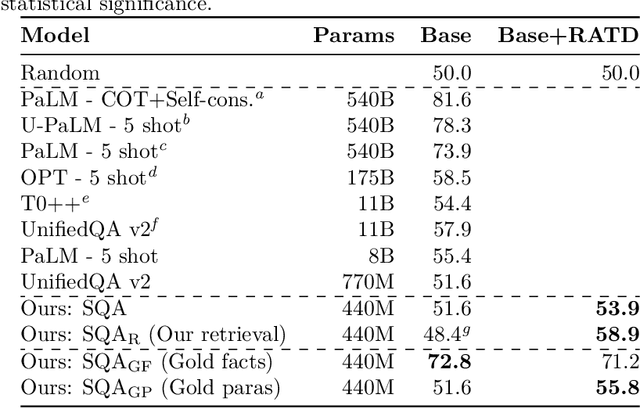
We equip a smaller Language Model to generalise to answering challenging compositional questions that have not been seen in training. To do so we propose a combination of multitask supervised pretraining on up to 93 tasks designed to instill diverse reasoning abilities, and a dense retrieval system that aims to retrieve a set of evidential paragraph fragments. Recent progress in question-answering has been achieved either through prompting methods against very large pretrained Language Models in zero or few-shot fashion, or by fine-tuning smaller models, sometimes in conjunction with information retrieval. We focus on the less explored question of the extent to which zero-shot generalisation can be enabled in smaller models with retrieval against a corpus within which sufficient information to answer a particular question may not exist. We establish strong baselines in this setting for diverse evaluation datasets (StrategyQA, CommonsenseQA, IIRC, DROP, Musique and ARC-DA), and show that performance can be significantly improved by adding retrieval-augmented training datasets which are designed to expose our models to a variety of heuristic reasoning strategies such as weighing partial evidence or ignoring an irrelevant context.
Generalized Sum Pooling for Metric Learning
Aug 21, 2023A common architectural choice for deep metric learning is a convolutional neural network followed by global average pooling (GAP). Albeit simple, GAP is a highly effective way to aggregate information. One possible explanation for the effectiveness of GAP is considering each feature vector as representing a different semantic entity and GAP as a convex combination of them. Following this perspective, we generalize GAP and propose a learnable generalized sum pooling method (GSP). GSP improves GAP with two distinct abilities: i) the ability to choose a subset of semantic entities, effectively learning to ignore nuisance information, and ii) learning the weights corresponding to the importance of each entity. Formally, we propose an entropy-smoothed optimal transport problem and show that it is a strict generalization of GAP, i.e., a specific realization of the problem gives back GAP. We show that this optimization problem enjoys analytical gradients enabling us to use it as a direct learnable replacement for GAP. We further propose a zero-shot loss to ease the learning of GSP. We show the effectiveness of our method with extensive evaluations on 4 popular metric learning benchmarks. Code is available at: GSP-DML Framework
Reconfigurable Intelligent Surface Enabled Joint Backscattering and Communication
Aug 21, 2023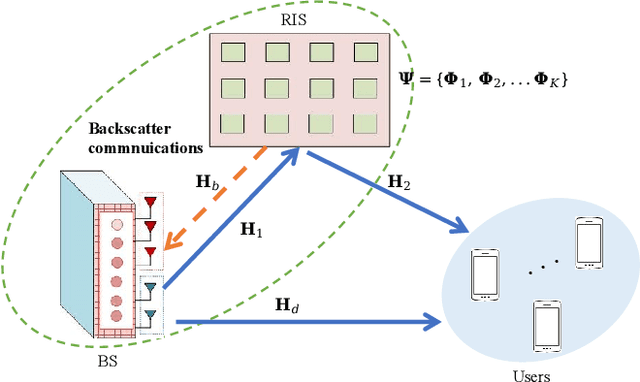
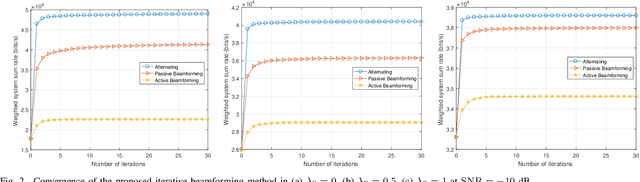
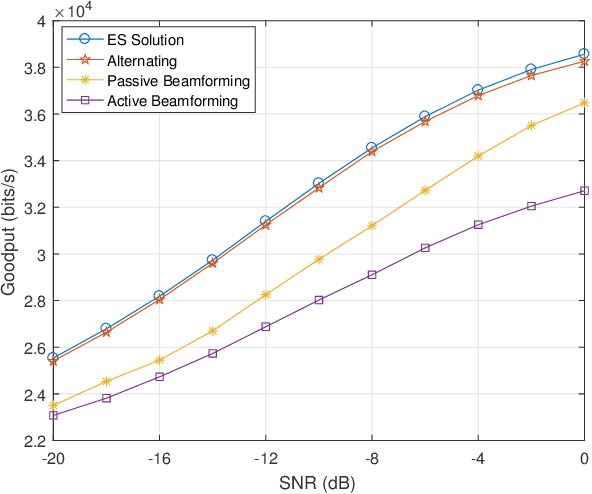
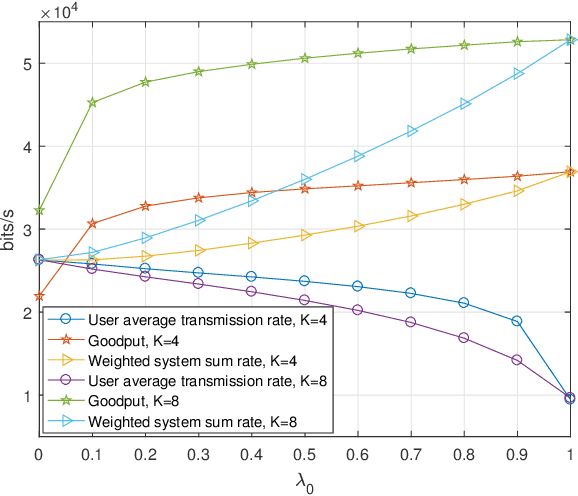
Reconfigurable intelligent surface (RIS) as an essential topic in the sixth-generation (6G) communications aims to enhance communication performance or mitigate undesired transmission. However, the controllability of each reflecting element on RIS also enables it to act as a passive backscatter device (BD) and transmit its information to reader devices. In this paper, we propose a RIS-enabled joint backscattering and communication (JBAC) system, where the backscatter communication coexists with the primary communication and occupies no extra spectrum. Specifically, the RIS modifies its reflecting pattern to act as a passive BD and reflect its own information back to the base station (BS) in the backscatter communication, while helping the primary communication from the BS to the users simultaneously. We further present an iterative active beamforming and reflecting pattern design to maximize the user average transmission rate of the primary communication and the goodput of the backscatter communication by solving the formulated multi-objective optimization problem (MOOP). Numerical results fully uncover the impacts of the number of reflecting elements and the reflecting patterns on the system performance, and demonstrate the effectiveness of the proposed scheme. Important practical implementation remarks have also been discussed.
* 11 pages, 8 figures, published to IEEE TVT
Schema-Driven Information Extraction from Heterogeneous Tables
May 23, 2023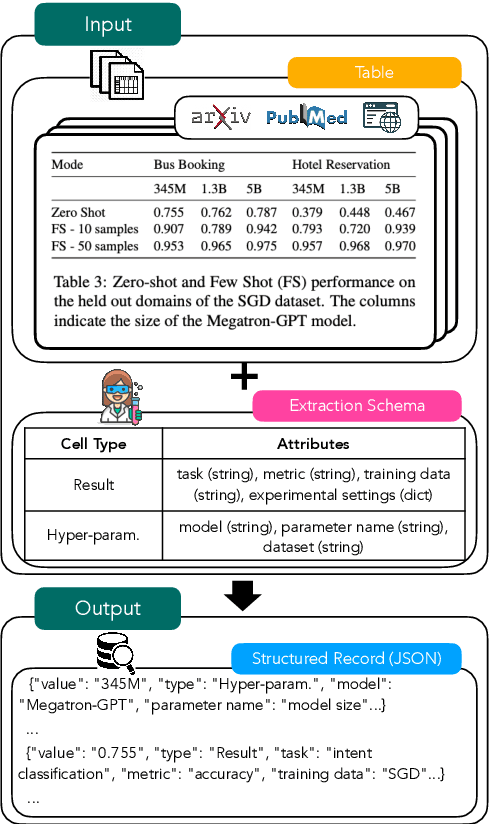
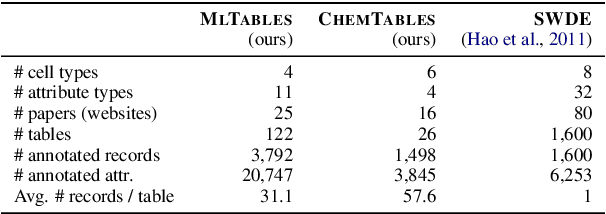
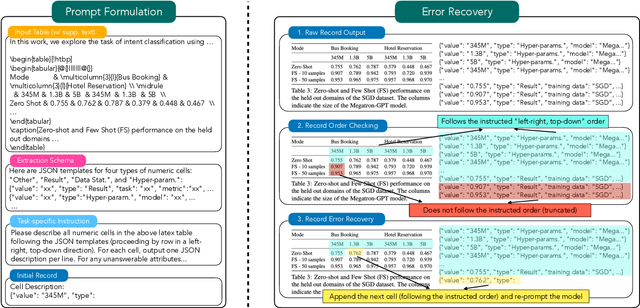
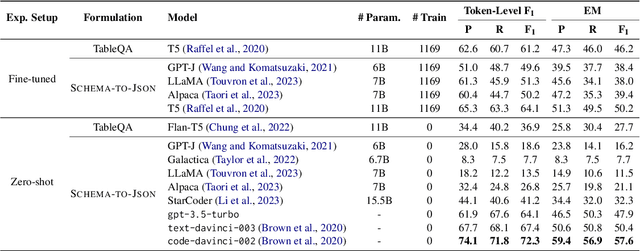
In this paper, we explore the question of whether language models (LLMs) can support cost-efficient information extraction from complex tables. We introduce schema-driven information extraction, a new task that uses LLMs to transform tabular data into structured records following a human-authored schema. To assess various LLM's capabilities on this task, we develop a benchmark composed of tables from three diverse domains: machine learning papers, chemistry tables, and webpages. Accompanying the benchmark, we present InstrucTE, a table extraction method based on instruction-tuned LLMs. This method necessitates only a human-constructed extraction schema, and incorporates an error-recovery strategy. Notably, InstrucTE demonstrates competitive performance without task-specific labels, achieving an F1 score ranging from 72.3 to 95.7. Moreover, we validate the feasibility of distilling more compact table extraction models to minimize extraction costs and reduce API reliance. This study paves the way for the future development of instruction-following models for cost-efficient table extraction.
Cross-Modal Retrieval Meets Inference:Improving Zero-Shot Classification with Cross-Modal Retrieval
Aug 29, 2023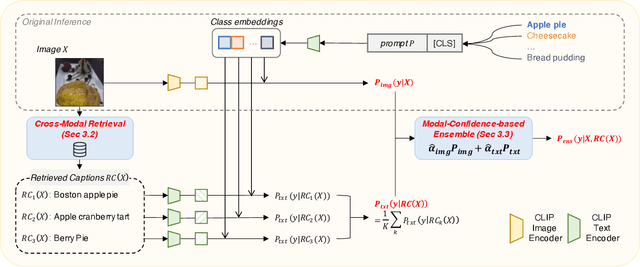
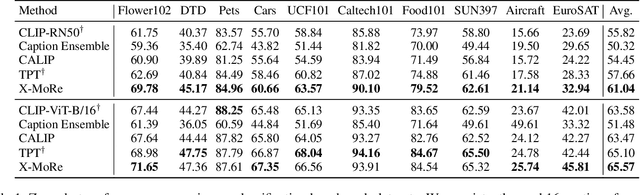
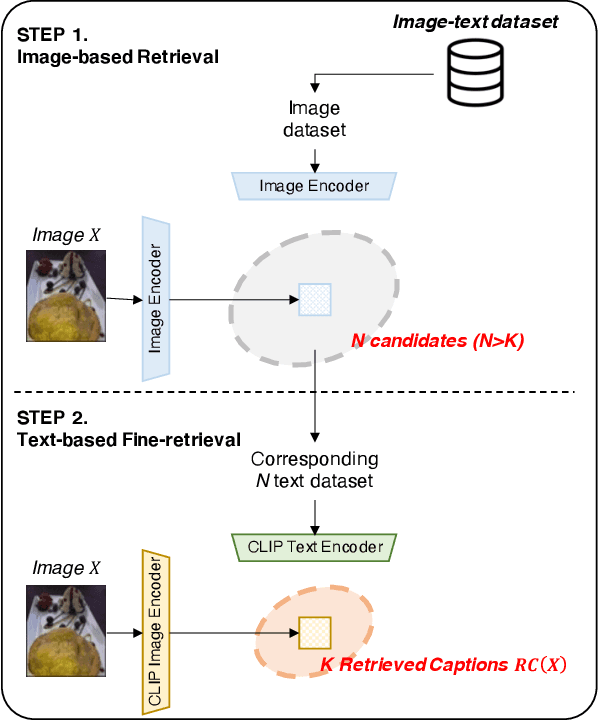
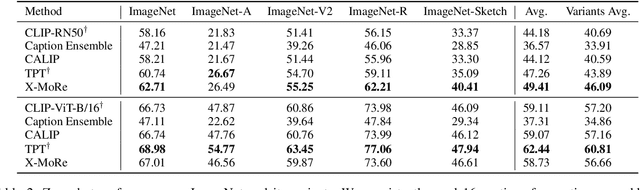
Contrastive language-image pre-training (CLIP) has demonstrated remarkable zero-shot classification ability, namely image classification using novel text labels. Existing works have attempted to enhance CLIP by fine-tuning on downstream tasks, but these have inadvertently led to performance degradation on unseen classes, thus harming zero-shot generalization. This paper aims to address this challenge by leveraging readily available image-text pairs from an external dataset for cross-modal guidance during inference. To this end, we propose X-MoRe, a novel inference method comprising two key steps: (1) cross-modal retrieval and (2) modal-confidence-based ensemble. Given a query image, we harness the power of CLIP's cross-modal representations to retrieve relevant textual information from an external image-text pair dataset. Then, we assign higher weights to the more reliable modality between the original query image and retrieved text, contributing to the final prediction. X-MoRe demonstrates robust performance across a diverse set of tasks without the need for additional training, showcasing the effectiveness of utilizing cross-modal features to maximize CLIP's zero-shot ability.
Let There Be Sound: Reconstructing High Quality Speech from Silent Videos
Aug 29, 2023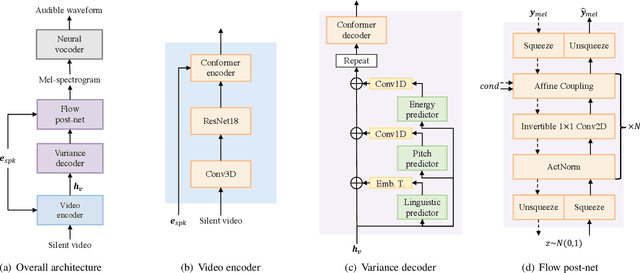
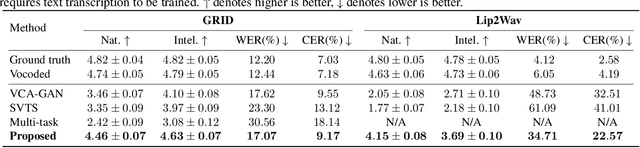
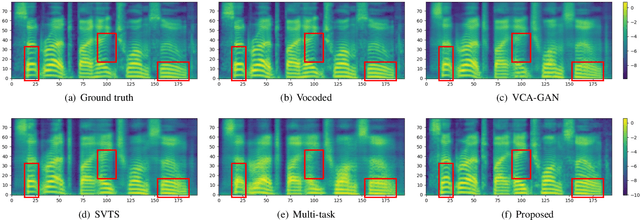
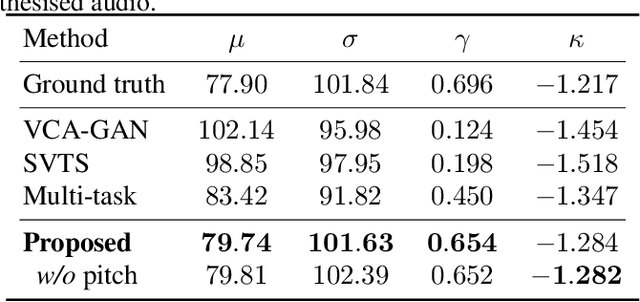
The goal of this work is to reconstruct high quality speech from lip motions alone, a task also known as lip-to-speech. A key challenge of lip-to-speech systems is the one-to-many mapping caused by (1) the existence of homophenes and (2) multiple speech variations, resulting in a mispronounced and over-smoothed speech. In this paper, we propose a novel lip-to-speech system that significantly improves the generation quality by alleviating the one-to-many mapping problem from multiple perspectives. Specifically, we incorporate (1) self-supervised speech representations to disambiguate homophenes, and (2) acoustic variance information to model diverse speech styles. Additionally, to better solve the aforementioned problem, we employ a flow based post-net which captures and refines the details of the generated speech. We perform extensive experiments and demonstrate that our method achieves the generation quality close to that of real human utterance, outperforming existing methods in terms of speech naturalness and intelligibility by a large margin. Synthesised samples are available at the anonymous demo page: https://mm.kaist.ac.kr/projects/LTBS.