 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Model-based learning for location-to-channel mapping
Aug 28, 2023
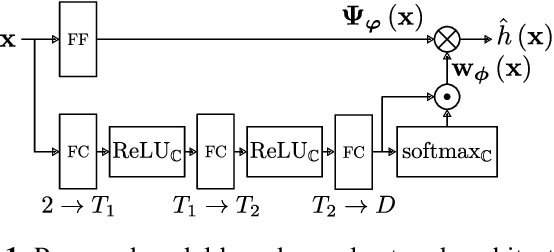

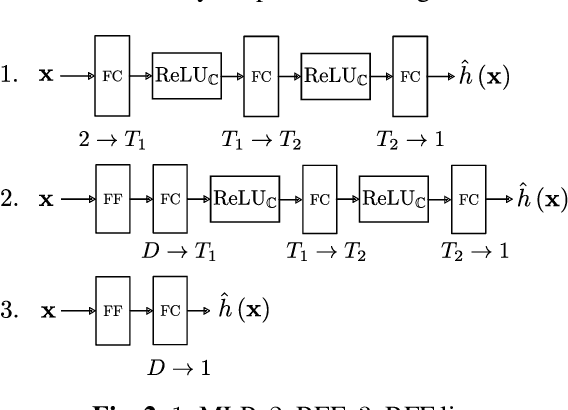
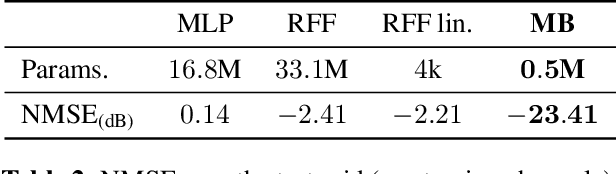
Modern communication systems rely on accurate channel estimation to achieve efficient and reliable transmission of information. As the communication channel response is highly related to the user's location, one can use a neural network to map the user's spatial coordinates to the channel coefficients. However, these latter are rapidly varying as a function of the location, on the order of the wavelength. Classical neural architectures being biased towards learning low frequency functions (spectral bias), such mapping is therefore notably difficult to learn. In order to overcome this limitation, this paper presents a frugal, model-based network that separates the low frequency from the high frequency components of the target mapping function. This yields an hypernetwork architecture where the neural network only learns low frequency sparse coefficients in a dictionary of high frequency components. Simulation results show that the proposed neural network outperforms standard approaches on realistic synthetic data.
A Topic-aware Summarization Framework with Different Modal Side Information
May 19, 2023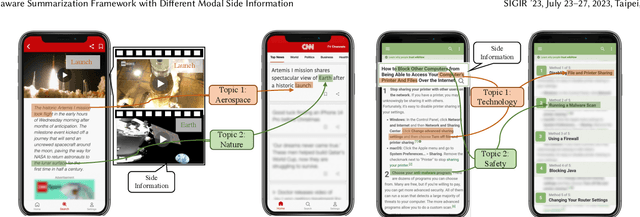
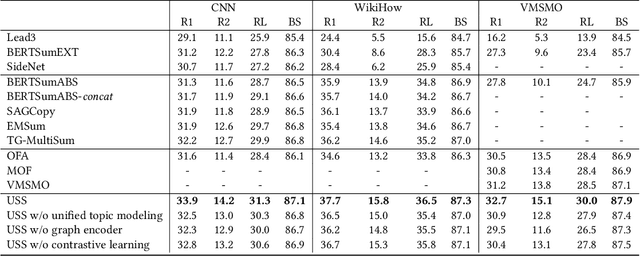
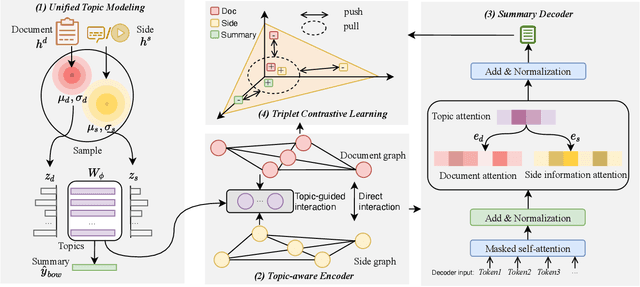
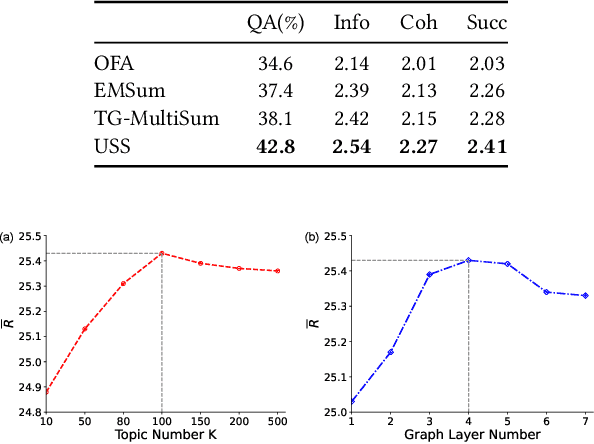
Automatic summarization plays an important role in the exponential document growth on the Web. On content websites such as CNN.com and WikiHow.com, there often exist various kinds of side information along with the main document for attention attraction and easier understanding, such as videos, images, and queries. Such information can be used for better summarization, as they often explicitly or implicitly mention the essence of the article. However, most of the existing side-aware summarization methods are designed to incorporate either single-modal or multi-modal side information, and cannot effectively adapt to each other. In this paper, we propose a general summarization framework, which can flexibly incorporate various modalities of side information. The main challenges in designing a flexible summarization model with side information include: (1) the side information can be in textual or visual format, and the model needs to align and unify it with the document into the same semantic space, (2) the side inputs can contain information from various aspects, and the model should recognize the aspects useful for summarization. To address these two challenges, we first propose a unified topic encoder, which jointly discovers latent topics from the document and various kinds of side information. The learned topics flexibly bridge and guide the information flow between multiple inputs in a graph encoder through a topic-aware interaction. We secondly propose a triplet contrastive learning mechanism to align the single-modal or multi-modal information into a unified semantic space, where the summary quality is enhanced by better understanding the document and side information. Results show that our model significantly surpasses strong baselines on three public single-modal or multi-modal benchmark summarization datasets.
Joint Semantic-Native Communication and Inference via Minimal Simplicial Structures
Aug 31, 2023In this work, we study the problem of semantic communication and inference, in which a student agent (i.e. mobile device) queries a teacher agent (i.e. cloud sever) to generate higher-order data semantics living in a simplicial complex. Specifically, the teacher first maps its data into a k-order simplicial complex and learns its high-order correlations. For effective communication and inference, the teacher seeks minimally sufficient and invariant semantic structures prior to conveying information. These minimal simplicial structures are found via judiciously removing simplices selected by the Hodge Laplacians without compromising the inference query accuracy. Subsequently, the student locally runs its own set of queries based on a masked simplicial convolutional autoencoder (SCAE) leveraging both local and remote teacher's knowledge. Numerical results corroborate the effectiveness of the proposed approach in terms of improving inference query accuracy under different channel conditions and simplicial structures. Experiments on a coauthorship dataset show that removing simplices by ranking the Laplacian values yields a 85% reduction in payload size without sacrificing accuracy. Joint semantic communication and inference by masked SCAE improves query accuracy by 25% compared to local student based query and 15% compared to remote teacher based query. Finally, incorporating channel semantics is shown to effectively improve inference accuracy, notably at low SNR values.
Post-Deployment Adaptation with Access to Source Data via Federated Learning and Source-Target Remote Gradient Alignment
Aug 31, 2023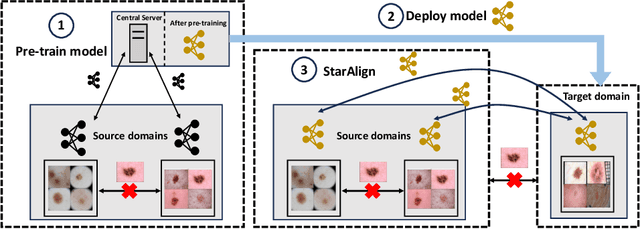
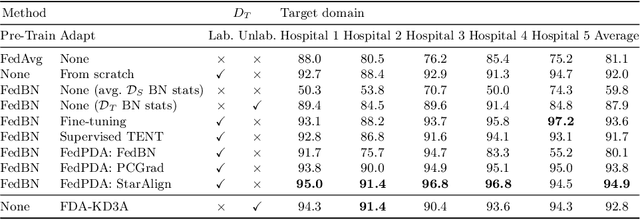
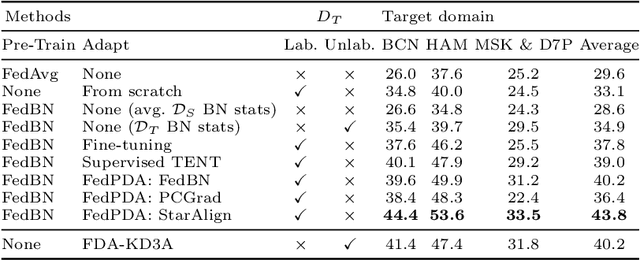
Deployment of Deep Neural Networks in medical imaging is hindered by distribution shift between training data and data processed after deployment, causing performance degradation. Post-Deployment Adaptation (PDA) addresses this by tailoring a pre-trained, deployed model to the target data distribution using limited labelled or entirely unlabelled target data, while assuming no access to source training data as they cannot be deployed with the model due to privacy concerns and their large size. This makes reliable adaptation challenging due to limited learning signal. This paper challenges this assumption and introduces FedPDA, a novel adaptation framework that brings the utility of learning from remote data from Federated Learning into PDA. FedPDA enables a deployed model to obtain information from source data via remote gradient exchange, while aiming to optimize the model specifically for the target domain. Tailored for FedPDA, we introduce a novel optimization method StarAlign (Source-Target Remote Gradient Alignment) that aligns gradients between source-target domain pairs by maximizing their inner product, to facilitate learning a target-specific model. We demonstrate the method's effectiveness using multi-center databases for the tasks of cancer metastases detection and skin lesion classification, where our method compares favourably to previous work. Code is available at: https://github.com/FelixWag/StarAlign
Efficacy of Neural Prediction-Based NAS for Zero-Shot NAS Paradigm
Aug 31, 2023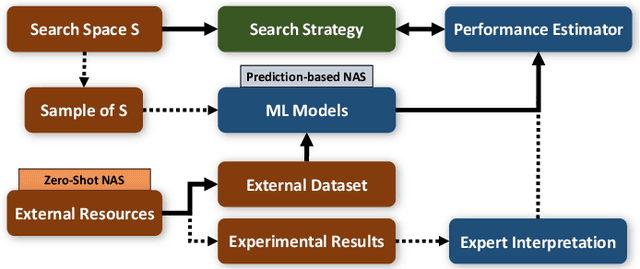
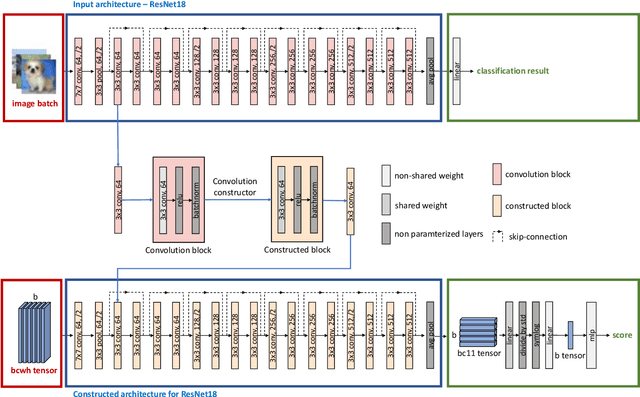
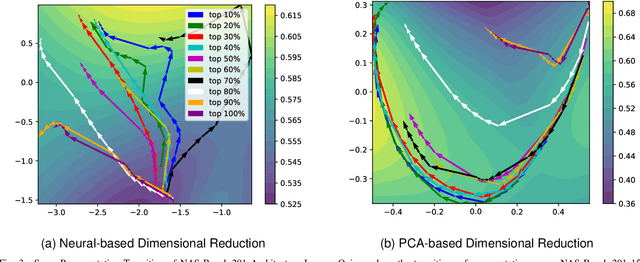
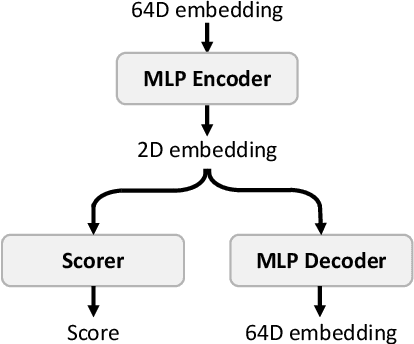
In prediction-based Neural Architecture Search (NAS), performance indicators derived from graph convolutional networks have shown significant success. These indicators, achieved by representing feed-forward structures as component graphs through one-hot encoding, face a limitation: their inability to evaluate architecture performance across varying search spaces. In contrast, handcrafted performance indicators (zero-shot NAS), which use the same architecture with random initialization, can generalize across multiple search spaces. Addressing this limitation, we propose a novel approach for zero-shot NAS using deep learning. Our method employs Fourier sum of sines encoding for convolutional kernels, enabling the construction of a computational feed-forward graph with a structure similar to the architecture under evaluation. These encodings are learnable and offer a comprehensive view of the architecture's topological information. An accompanying multi-layer perceptron (MLP) then ranks these architectures based on their encodings. Experimental results show that our approach surpasses previous methods using graph convolutional networks in terms of correlation on the NAS-Bench-201 dataset and exhibits a higher convergence rate. Moreover, our extracted feature representation trained on each NAS-Benchmark is transferable to other NAS-Benchmarks, showing promising generalizability across multiple search spaces. The code is available at: https://github.com/minh1409/DFT-NPZS-NAS
PointLLM: Empowering Large Language Models to Understand Point Clouds
Aug 31, 2023
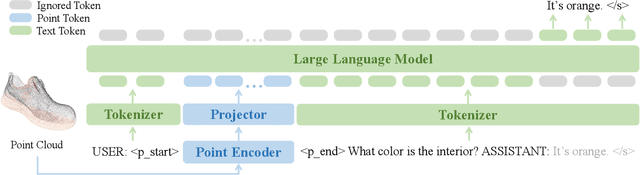


The unprecedented advancements in Large Language Models (LLMs) have created a profound impact on natural language processing but are yet to fully embrace the realm of 3D understanding. This paper introduces PointLLM, a preliminary effort to fill this gap, thereby enabling LLMs to understand point clouds and offering a new avenue beyond 2D visual data. PointLLM processes colored object point clouds with human instructions and generates contextually appropriate responses, illustrating its grasp of point clouds and common sense. Specifically, it leverages a point cloud encoder with a powerful LLM to effectively fuse geometric, appearance, and linguistic information. We collect a novel dataset comprising 660K simple and 70K complex point-text instruction pairs to enable a two-stage training strategy: initially aligning latent spaces and subsequently instruction-tuning the unified model. To rigorously evaluate our model's perceptual abilities and its generalization capabilities, we establish two benchmarks: Generative 3D Object Classification and 3D Object Captioning, assessed through three different methods, including human evaluation, GPT-4/ChatGPT evaluation, and traditional metrics. Experiment results show that PointLLM demonstrates superior performance over existing 2D baselines. Remarkably, in human-evaluated object captioning tasks, PointLLM outperforms human annotators in over 50% of the samples. Codes, datasets, and benchmarks are available at https://github.com/OpenRobotLab/PointLLM .
StratMed: Relevance Stratification for Low-resource Medication Recommendation
Aug 31, 2023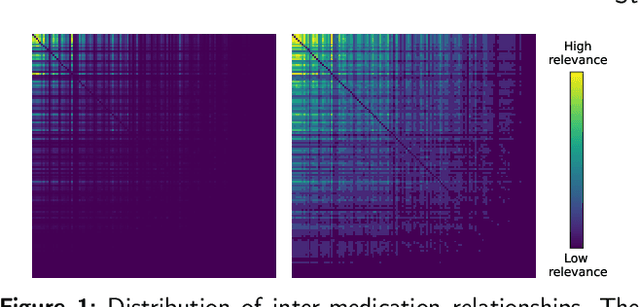
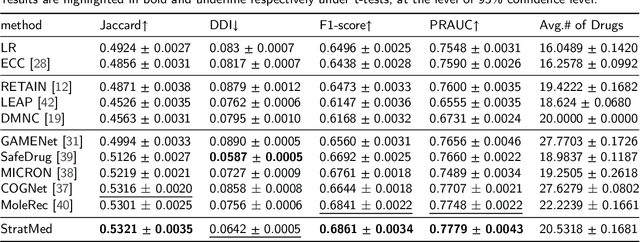
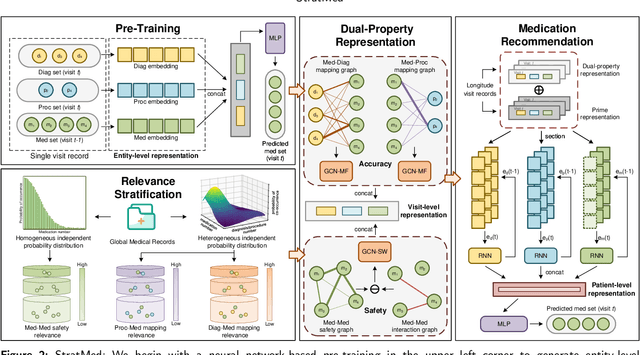

With the growing imbalance between limited medical resources and escalating demands, AI-based clinical tasks have become paramount. Medication recommendation, as a sub-domain, aims to amalgamate longitudinal patient history with medical knowledge, assisting physicians in prescribing safer and more accurate medication combinations. Existing methods overlook the inherent long-tail distribution in medical data, lacking balanced representation between head and tail data, which leads to sub-optimal model performance. To address this challenge, we introduce StratMed, a model that incorporates an innovative relevance stratification mechanism. It harmonizes discrepancies in data long-tail distribution and strikes a balance between the safety and accuracy of medication combinations. Specifically, we first construct a pre-training method using deep learning networks to obtain entity representation. After that, we design a pyramid-like data stratification method to obtain more generalized entity relationships by reinforcing the features of unpopular entities. Based on this relationship, we designed two graph structures to express medication precision and safety at the same level to obtain visit representations. Finally, the patient's historical clinical information is fitted to generate medication combinations for the current health condition. Experiments on the MIMIC-III dataset demonstrate that our method has outperformed current state-of-the-art methods in four evaluation metrics (including safety and accuracy).
TouchStone: Evaluating Vision-Language Models by Language Models
Aug 31, 2023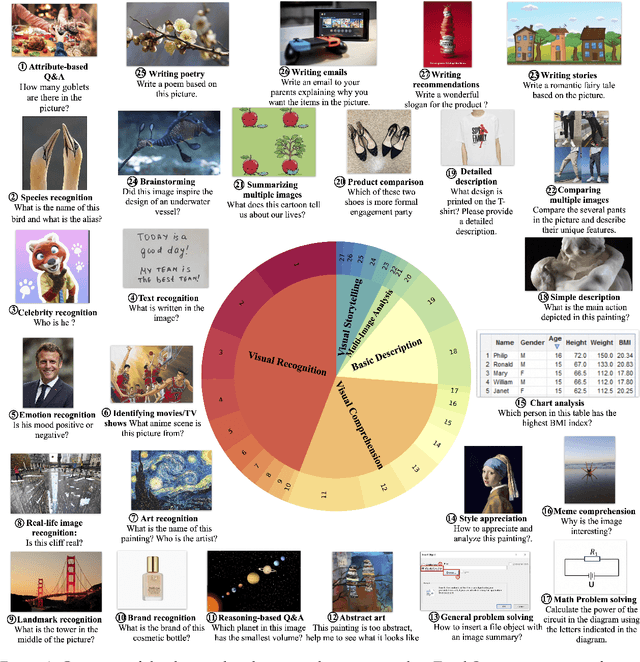
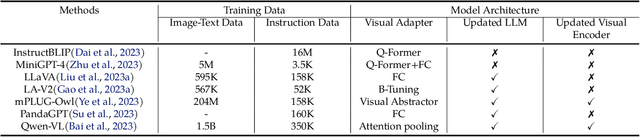


Large vision-language models (LVLMs) have recently witnessed rapid advancements, exhibiting a remarkable capacity for perceiving, understanding, and processing visual information by connecting visual receptor with large language models (LLMs). However, current assessments mainly focus on recognizing and reasoning abilities, lacking direct evaluation of conversational skills and neglecting visual storytelling abilities. In this paper, we propose an evaluation method that uses strong LLMs as judges to comprehensively evaluate the various abilities of LVLMs. Firstly, we construct a comprehensive visual dialogue dataset TouchStone, consisting of open-world images and questions, covering five major categories of abilities and 27 subtasks. This dataset not only covers fundamental recognition and comprehension but also extends to literary creation. Secondly, by integrating detailed image annotations we effectively transform the multimodal input content into a form understandable by LLMs. This enables us to employ advanced LLMs for directly evaluating the quality of the multimodal dialogue without requiring human intervention. Through validation, we demonstrate that powerful LVLMs, such as GPT-4, can effectively score dialogue quality by leveraging their textual capabilities alone, aligning with human preferences. We hope our work can serve as a touchstone for LVLMs' evaluation and pave the way for building stronger LVLMs. The evaluation code is available at https://github.com/OFA-Sys/TouchStone.
Federated Learning in UAV-Enhanced Networks: Joint Coverage and Convergence Time Optimization
Aug 31, 2023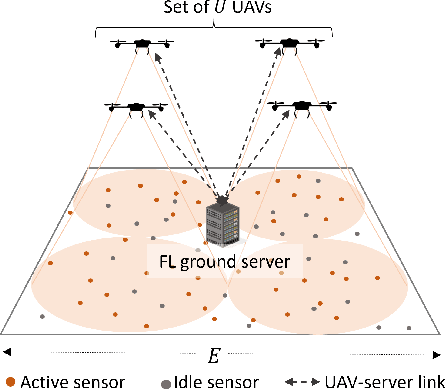
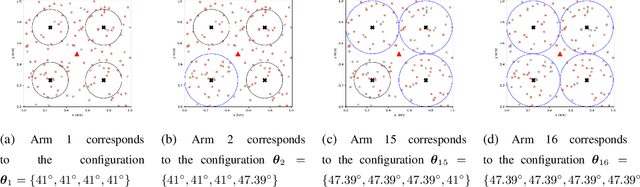
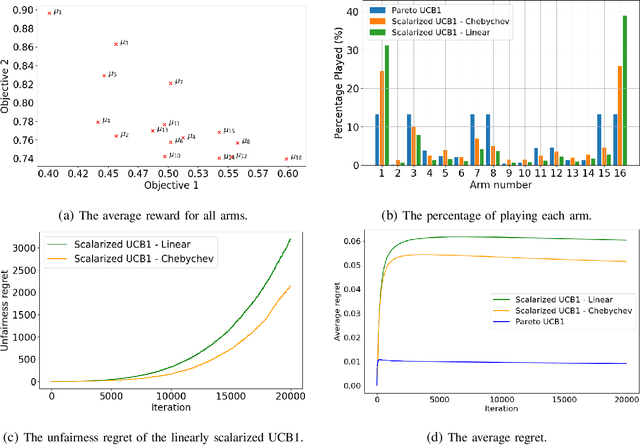
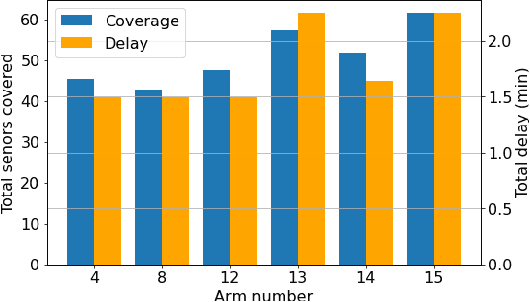
Federated learning (FL) involves several devices that collaboratively train a shared model without transferring their local data. FL reduces the communication overhead, making it a promising learning method in UAV-enhanced wireless networks with scarce energy resources. Despite the potential, implementing FL in UAV-enhanced networks is challenging, as conventional UAV placement methods that maximize coverage increase the FL delay significantly. Moreover, the uncertainty and lack of a priori information about crucial variables, such as channel quality, exacerbate the problem. In this paper, we first analyze the statistical characteristics of a UAV-enhanced wireless sensor network (WSN) with energy harvesting. We then develop a model and solution based on the multi-objective multi-armed bandit theory to maximize the network coverage while minimizing the FL delay. Besides, we propose another solution that is particularly useful with large action sets and strict energy constraints at the UAVs. Our proposal uses a scalarized best-arm identification algorithm to find the optimal arms that maximize the ratio of the expected reward to the expected energy cost by sequentially eliminating one or more arms in each round. Then, we derive the upper bound on the error probability of our multi-objective and cost-aware algorithm. Numerical results show the effectiveness of our approach.
Test-Time Adaptation for Point Cloud Upsampling Using Meta-Learning
Aug 31, 2023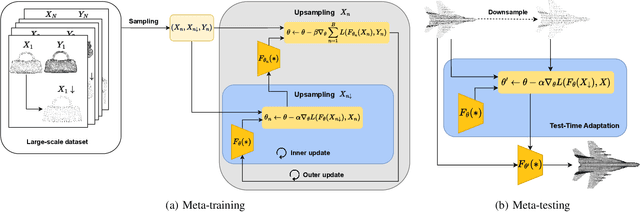
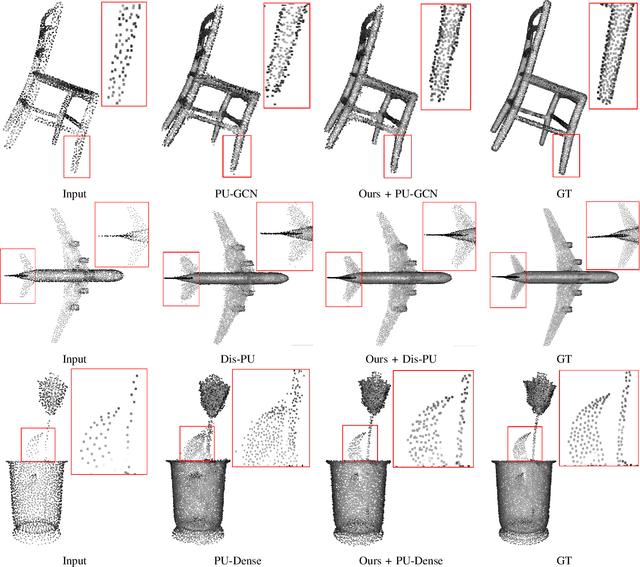
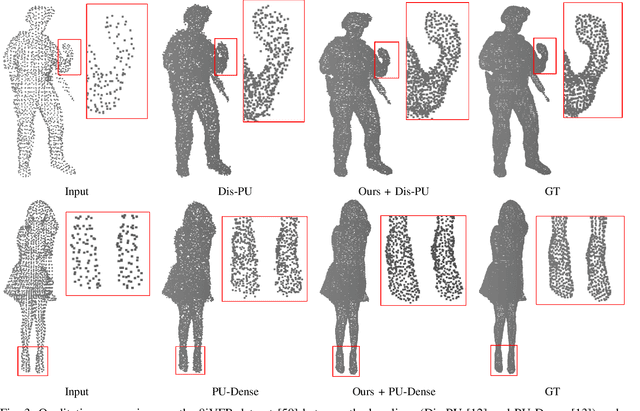
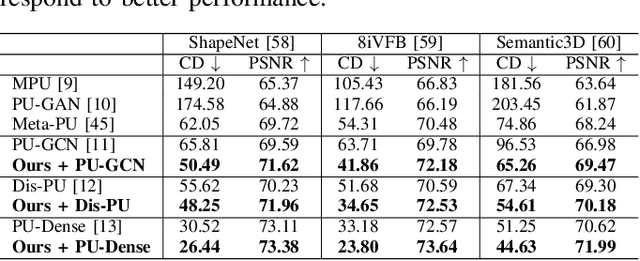
Affordable 3D scanners often produce sparse and non-uniform point clouds that negatively impact downstream applications in robotic systems. While existing point cloud upsampling architectures have demonstrated promising results on standard benchmarks, they tend to experience significant performance drops when the test data have different distributions from the training data. To address this issue, this paper proposes a test-time adaption approach to enhance model generality of point cloud upsampling. The proposed approach leverages meta-learning to explicitly learn network parameters for test-time adaption. Our method does not require any prior information about the test data. During meta-training, the model parameters are learned from a collection of instance-level tasks, each of which consists of a sparse-dense pair of point clouds from the training data. During meta-testing, the trained model is fine-tuned with a few gradient updates to produce a unique set of network parameters for each test instance. The updated model is then used for the final prediction. Our framework is generic and can be applied in a plug-and-play manner with existing backbone networks in point cloud upsampling. Extensive experiments demonstrate that our approach improves the performance of state-of-the-art models.