 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SieveNet: Selecting Point-Based Features for Mesh Networks
Aug 24, 2023
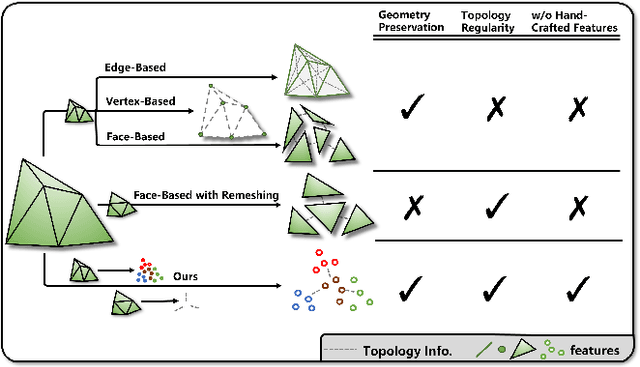
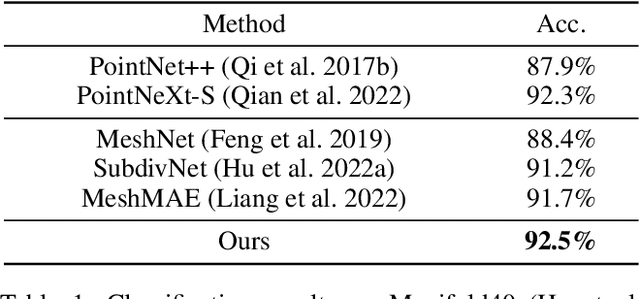
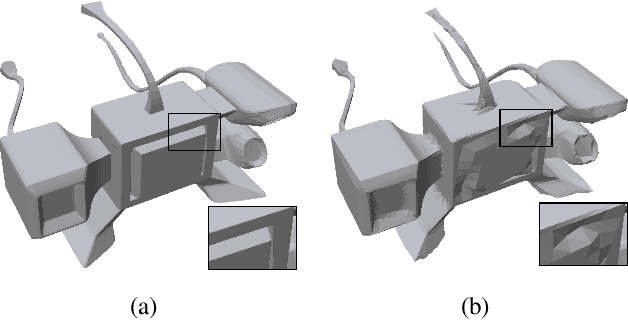
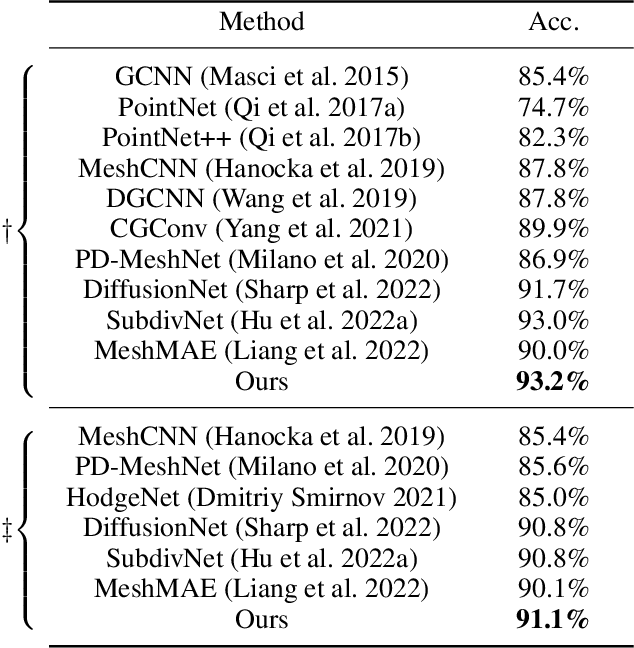
Meshes are widely used in 3D computer vision and graphics, but their irregular topology poses challenges in applying them to existing neural network architectures. Recent advances in mesh neural networks turn to remeshing and push the boundary of pioneer methods that solely take the raw meshes as input. Although the remeshing offers a regular topology that significantly facilitates the design of mesh network architectures, features extracted from such remeshed proxies may struggle to retain the underlying geometry faithfully, limiting the subsequent neural network's capacity. To address this issue, we propose SieveNet, a novel paradigm that takes into account both the regular topology and the exact geometry. Specifically, this method utilizes structured mesh topology from remeshing and accurate geometric information from distortion-aware point sampling on the surface of the original mesh. Furthermore, our method eliminates the need for hand-crafted feature engineering and can leverage off-the-shelf network architectures such as the vision transformer. Comprehensive experimental results on classification and segmentation tasks well demonstrate the effectiveness and superiority of our method.
Adversarial Training Using Feedback Loops
Aug 24, 2023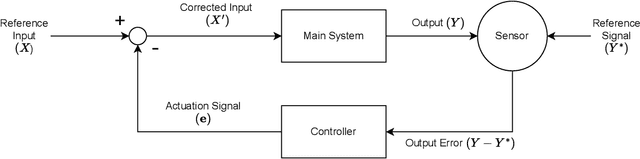
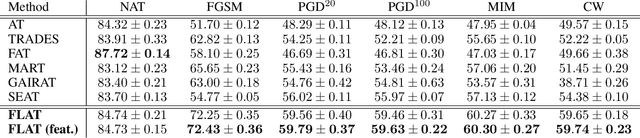
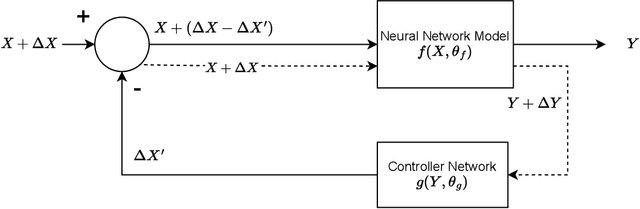
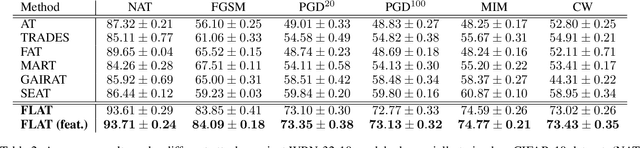
Deep neural networks (DNN) have found wide applicability in numerous fields due to their ability to accurately learn very complex input-output relations. Despite their accuracy and extensive use, DNNs are highly susceptible to adversarial attacks due to limited generalizability. For future progress in the field, it is essential to build DNNs that are robust to any kind of perturbations to the data points. In the past, many techniques have been proposed to robustify DNNs using first-order derivative information of the network. This paper proposes a new robustification approach based on control theory. A neural network architecture that incorporates feedback control, named Feedback Neural Networks, is proposed. The controller is itself a neural network, which is trained using regular and adversarial data such as to stabilize the system outputs. The novel adversarial training approach based on the feedback control architecture is called Feedback Looped Adversarial Training (FLAT). Numerical results on standard test problems empirically show that our FLAT method is more effective than the state-of-the-art to guard against adversarial attacks.
LibreFace: An Open-Source Toolkit for Deep Facial Expression Analysis
Aug 24, 2023
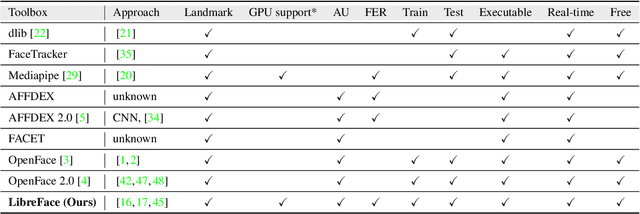
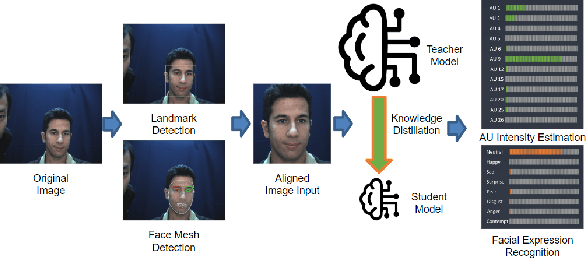

Facial expression analysis is an important tool for human-computer interaction. In this paper, we introduce LibreFace, an open-source toolkit for facial expression analysis. This open-source toolbox offers real-time and offline analysis of facial behavior through deep learning models, including facial action unit (AU) detection, AU intensity estimation, and facial expression recognition. To accomplish this, we employ several techniques, including the utilization of a large-scale pre-trained network, feature-wise knowledge distillation, and task-specific fine-tuning. These approaches are designed to effectively and accurately analyze facial expressions by leveraging visual information, thereby facilitating the implementation of real-time interactive applications. In terms of Action Unit (AU) intensity estimation, we achieve a Pearson Correlation Coefficient (PCC) of 0.63 on DISFA, which is 7% higher than the performance of OpenFace 2.0 while maintaining highly-efficient inference that runs two times faster than OpenFace 2.0. Despite being compact, our model also demonstrates competitive performance to state-of-the-art facial expression analysis methods on AffecNet, FFHQ, and RAF-DB. Our code will be released at https://github.com/ihp-lab/LibreFace
On the Augmentation of Cognitive Accuracy and Cognitive Precision in Human/Cog Ensembles
Aug 16, 2023Whenever humans use tools human performance is enhanced. Cognitive systems are a new kind of tool continually increasing in cognitive capability and are now performing high level cognitive tasks previously thought to be explicitly human. Usage of such tools, known as cogs, are expected to result in ever increasing levels of human cognitive augmentation. In a human cog ensemble, a cooperative, peer to peer, and collaborative dialog between a human and a cognitive system, human cognitive capability is augmented as a result of the interaction. The human cog ensemble is therefore able to achieve more than just the human or the cog working alone. This article presents results from two studies designed to measure the effect information supplied by a cog has on cognitive accuracy, the ability to produce the correct result, and cognitive precision, the propensity to produce only the correct result. Both cognitive accuracy and cognitive precision are shown to be increased by information of different types (policies and rules, examples, and suggestions) and with different kinds of problems (inventive problem solving and puzzles). Similar effects shown in other studies are compared.
Information-Ordered Bottlenecks for Adaptive Semantic Compression
May 18, 2023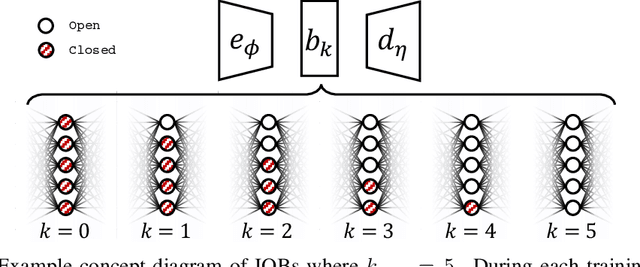
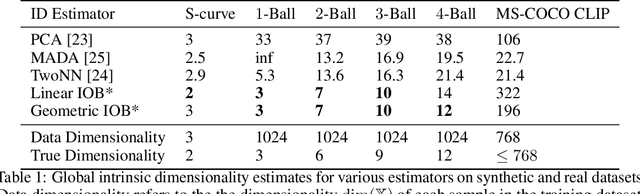

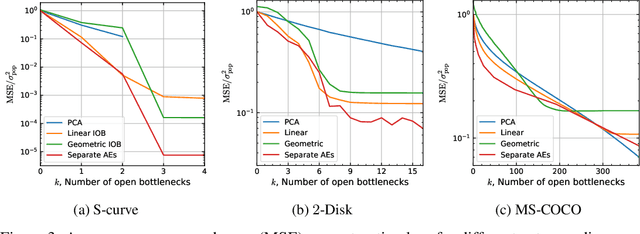
We present the information-ordered bottleneck (IOB), a neural layer designed to adaptively compress data into latent variables ordered by likelihood maximization. Without retraining, IOB nodes can be truncated at any bottleneck width, capturing the most crucial information in the first latent variables. Unifying several previous approaches, we show that IOBs achieve near-optimal compression for a given encoding architecture and can assign ordering to latent signals in a manner that is semantically meaningful. IOBs demonstrate a remarkable ability to compress embeddings of image and text data, leveraging the performance of SOTA architectures such as CNNs, transformers, and diffusion models. Moreover, we introduce a novel theory for estimating global intrinsic dimensionality with IOBs and show that they recover SOTA dimensionality estimates for complex synthetic data. Furthermore, we showcase the utility of these models for exploratory analysis through applications on heterogeneous datasets, enabling computer-aided discovery of dataset complexity.
Reframing the Brain Age Prediction Problem to a More Interpretable and Quantitative Approach
Aug 23, 2023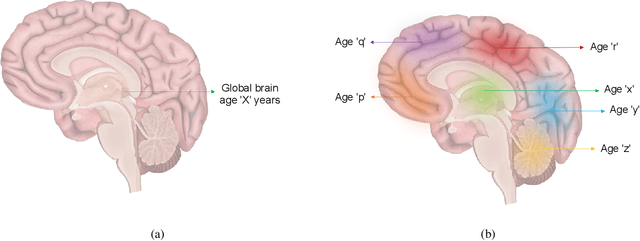

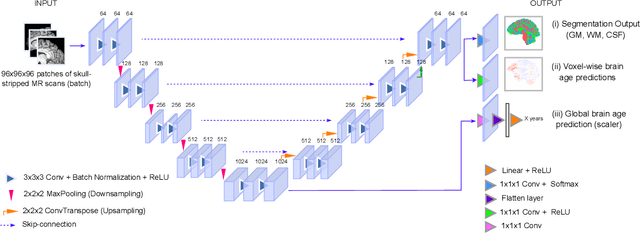
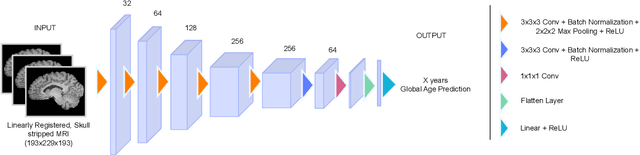
Deep learning models have achieved state-of-the-art results in estimating brain age, which is an important brain health biomarker, from magnetic resonance (MR) images. However, most of these models only provide a global age prediction, and rely on techniques, such as saliency maps to interpret their results. These saliency maps highlight regions in the input image that were significant for the model's predictions, but they are hard to be interpreted, and saliency map values are not directly comparable across different samples. In this work, we reframe the age prediction problem from MR images to an image-to-image regression problem where we estimate the brain age for each brain voxel in MR images. We compare voxel-wise age prediction models against global age prediction models and their corresponding saliency maps. The results indicate that voxel-wise age prediction models are more interpretable, since they provide spatial information about the brain aging process, and they benefit from being quantitative.
AutoPoster: A Highly Automatic and Content-aware Design System for Advertising Poster Generation
Aug 23, 2023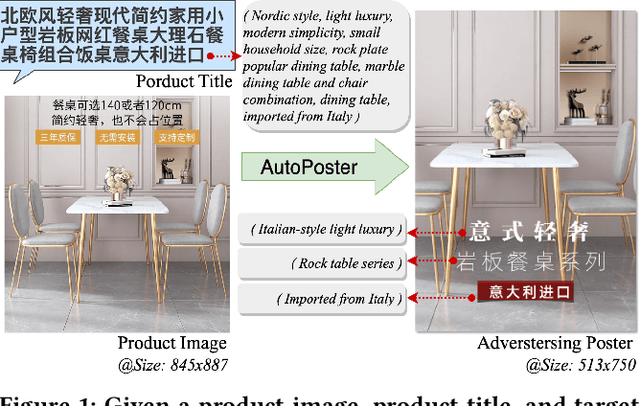

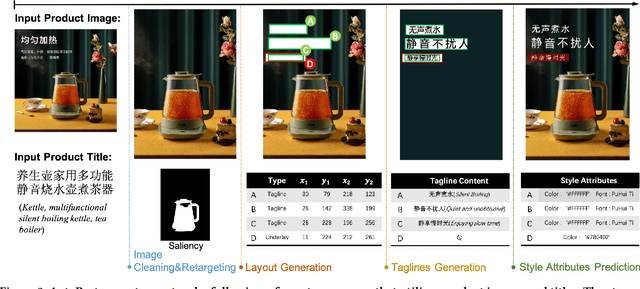

Advertising posters, a form of information presentation, combine visual and linguistic modalities. Creating a poster involves multiple steps and necessitates design experience and creativity. This paper introduces AutoPoster, a highly automatic and content-aware system for generating advertising posters. With only product images and titles as inputs, AutoPoster can automatically produce posters of varying sizes through four key stages: image cleaning and retargeting, layout generation, tagline generation, and style attribute prediction. To ensure visual harmony of posters, two content-aware models are incorporated for layout and tagline generation. Moreover, we propose a novel multi-task Style Attribute Predictor (SAP) to jointly predict visual style attributes. Meanwhile, to our knowledge, we propose the first poster generation dataset that includes visual attribute annotations for over 76k posters. Qualitative and quantitative outcomes from user studies and experiments substantiate the efficacy of our system and the aesthetic superiority of the generated posters compared to other poster generation methods.
Semantic-Aware Implicit Template Learning via Part Deformation Consistency
Aug 23, 2023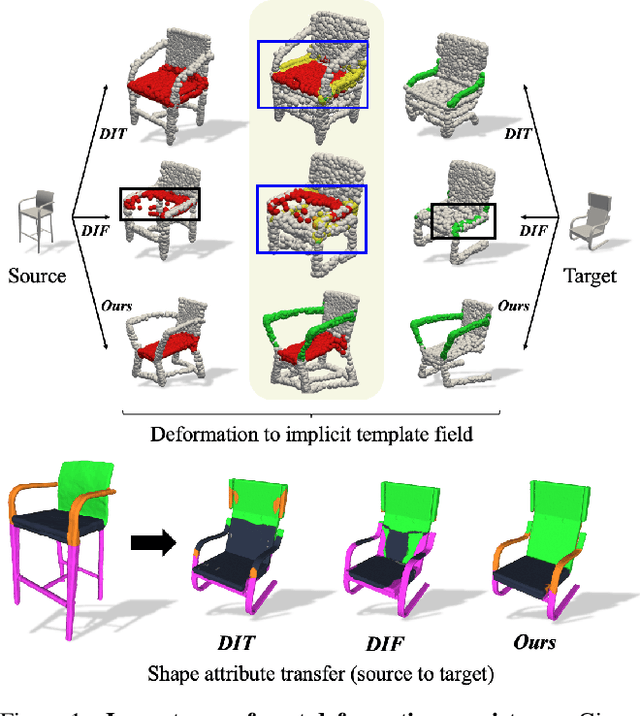

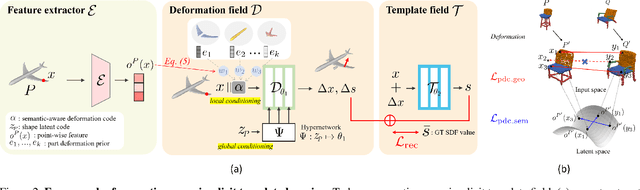
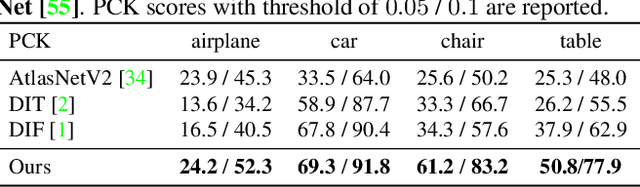
Learning implicit templates as neural fields has recently shown impressive performance in unsupervised shape correspondence. Despite the success, we observe current approaches, which solely rely on geometric information, often learn suboptimal deformation across generic object shapes, which have high structural variability. In this paper, we highlight the importance of part deformation consistency and propose a semantic-aware implicit template learning framework to enable semantically plausible deformation. By leveraging semantic prior from a self-supervised feature extractor, we suggest local conditioning with novel semantic-aware deformation code and deformation consistency regularizations regarding part deformation, global deformation, and global scaling. Our extensive experiments demonstrate the superiority of the proposed method over baselines in various tasks: keypoint transfer, part label transfer, and texture transfer. More interestingly, our framework shows a larger performance gain under more challenging settings. We also provide qualitative analyses to validate the effectiveness of semantic-aware deformation. The code is available at https://github.com/mlvlab/PDC.
DSFNet: Convolutional Encoder-Decoder Architecture Combined Dual-GCN and Stand-alone Self-attention by Fast Normalized Fusion for Polyps Segmentation
Aug 15, 2023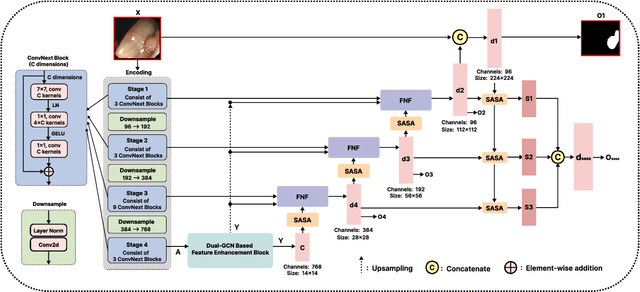
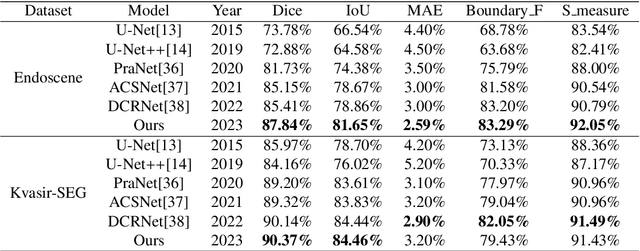
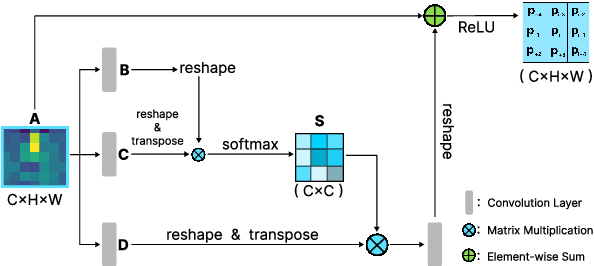
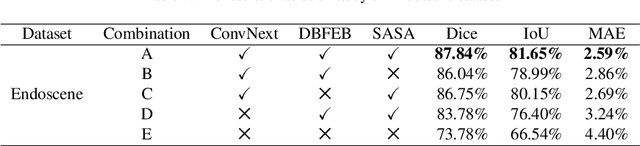
In the past few decades, deep learning technology has been widely used in medical image segmentation and has made significant breakthroughs in the fields of liver and liver tumor segmentation, brain and brain tumor segmentation, video disc segmentation, heart image segmentation, and so on. However, the segmentation of polyps is still a challenging task since the surface of the polyps is flat and the color is very similar to that of surrounding tissues. Thus, It leads to the problems of the unclear boundary between polyps and surrounding mucosa, local overexposure, and bright spot reflection. To counter this problem, this paper presents a novel U-shaped network, namely DSFNet, which effectively combines the advantages of Dual-GCN and self-attention mechanisms. First, we introduce a feature enhancement block module based on Dual-GCN module as an attention mechanism to enhance the feature extraction of local spatial and structural information with fine granularity. Second, the stand-alone self-attention module is designed to enhance the integration ability of the decoding stage model to global information. Finally, the Fast Normalized Fusion method with trainable weights is used to efficiently fuse the corresponding three feature graphs in encoding, bottleneck, and decoding blocks, thus promoting information transmission and reducing the semantic gap between encoder and decoder. Our model is tested on two public datasets including Endoscene and Kvasir-SEG and compared with other state-of-the-art models. Experimental results show that the proposed model surpasses other competitors in many indicators, such as Dice, MAE, and IoU. In the meantime, ablation studies are also conducted to verify the efficacy and effectiveness of each module. Qualitative and quantitative analysis indicates that the proposed model has great clinical significance.
StyleDiffusion: Controllable Disentangled Style Transfer via Diffusion Models
Aug 15, 2023
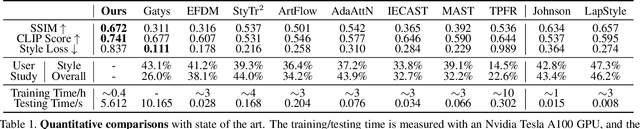
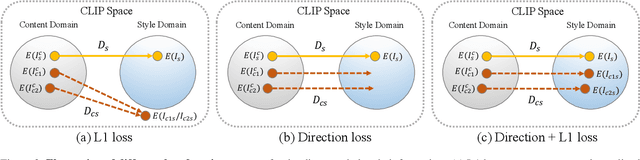

Content and style (C-S) disentanglement is a fundamental problem and critical challenge of style transfer. Existing approaches based on explicit definitions (e.g., Gram matrix) or implicit learning (e.g., GANs) are neither interpretable nor easy to control, resulting in entangled representations and less satisfying results. In this paper, we propose a new C-S disentangled framework for style transfer without using previous assumptions. The key insight is to explicitly extract the content information and implicitly learn the complementary style information, yielding interpretable and controllable C-S disentanglement and style transfer. A simple yet effective CLIP-based style disentanglement loss coordinated with a style reconstruction prior is introduced to disentangle C-S in the CLIP image space. By further leveraging the powerful style removal and generative ability of diffusion models, our framework achieves superior results than state of the art and flexible C-S disentanglement and trade-off control. Our work provides new insights into the C-S disentanglement in style transfer and demonstrates the potential of diffusion models for learning well-disentangled C-S characteristics.