 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Semantic Communications with Explicit Semantic Base for Image Transmission
Aug 12, 2023
Semantic communications, aiming at ensuring the successful delivery of the meaning of information, are expected to be one of the potential techniques for the next generation communications. However, the knowledge forming and synchronizing mechanism that enables semantic communication systems to extract and interpret the semantics of information according to the communication intents is still immature. In this paper, we propose a semantic image transmission framework with explicit semantic base (Seb), where Sebs are generated and employed as the knowledge shared between the transmitter and the receiver with flexible granularity. To represent images with Sebs, a novel Seb-based reference image generator is proposed to generate Sebs and then decompose the transmitted images. To further encode/decode the residual information for precise image reconstruction, a Seb-based image encoder/decoder is proposed. The key components of the proposed framework are optimized jointly by end-to-end (E2E) training, where the loss function is dedicated designed to tackle the problem of nondifferentiable operation in Seb-based reference image generator by introducing a gradient approximation mechanism. Extensive experiments show that the proposed framework outperforms state-of-art works by 0.5 - 1.5 dB in peak signal-to-noise ratio (PSNR) w.r.t. different signal-to-noise ratio (SNR).
LSTM-based QoE Evaluation for Web Microservices' Reputation Scoring
Aug 25, 2023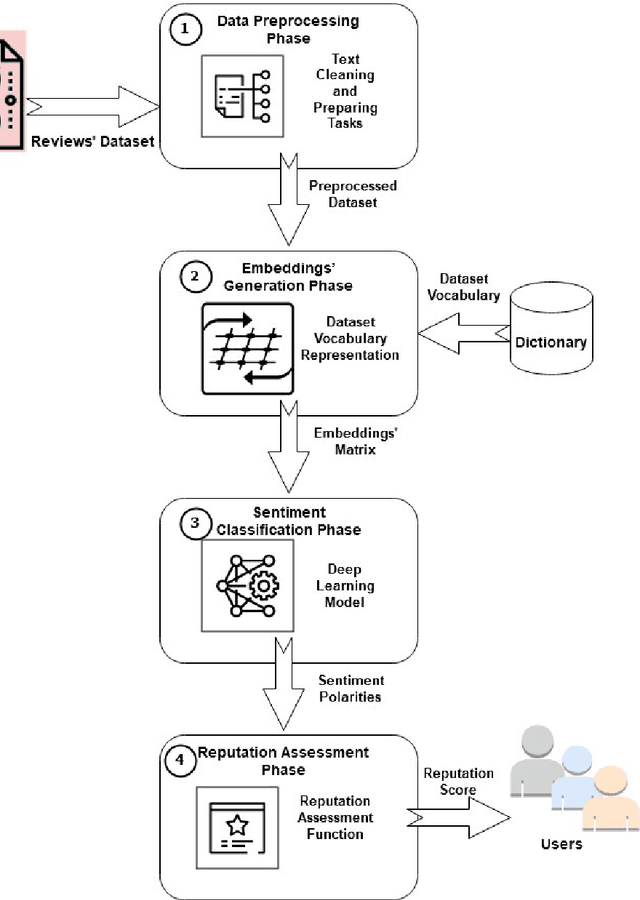

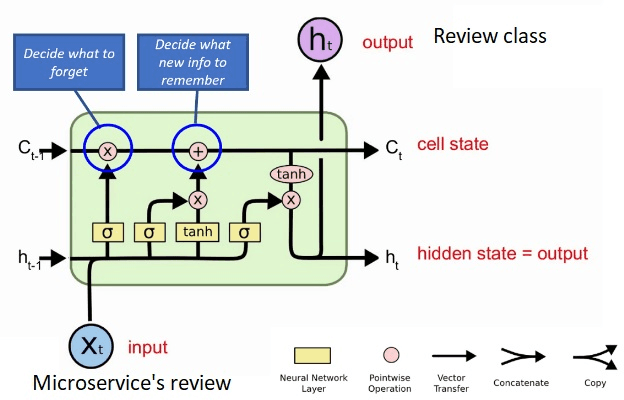
Sentiment analysis is the task of mining the authors' opinions about specific entities. It allows organizations to monitor different services in real time and act accordingly. Reputation is what is generally said or believed about people or things. Informally, reputation combines the measure of reliability derived from feedback, reviews, and ratings gathered from users, which reflect their quality of experience (QoE) and can either increase or harm the reputation of the provided services. In this study, we propose to perform sentiment analysis on web microservices reviews to exploit the provided information to assess and score the microservices' reputation. Our proposed approach uses the Long Short-Term Memory (LSTM) model to perform sentiment analysis and the Net Brand Reputation (NBR) algorithm to assess reputation scores for microservices. This approach is tested on a set of more than 10,000 reviews related to 15 Amazon Web microservices, and the experimental results have shown that our approach is more accurate than existing approaches, with an accuracy and precision of 93% obtained after applying an oversampling strategy and a resulting reputation score of the considered microservices community of 89%.
ARTIST: ARTificial Intelligence for Simplified Text
Aug 25, 2023

Complex text is a major barrier for many citizens when accessing public information and knowledge. While often done manually, Text Simplification is a key Natural Language Processing task that aims for reducing the linguistic complexity of a text while preserving the original meaning. Recent advances in Generative Artificial Intelligence (AI) have enabled automatic text simplification both on the lexical and syntactical levels. However, as applications often focus on English, little is understood about the effectiveness of Generative AI techniques on low-resource languages such as Dutch. For this reason, we carry out empirical studies to understand the benefits and limitations of applying generative technologies for text simplification and provide the following outcomes: 1) the design and implementation for a configurable text simplification pipeline that orchestrates state-of-the-art generative text simplification models, domain and reader adaptation, and visualisation modules; 2) insights and lessons learned, showing the strengths of automatic text simplification while exposing the challenges in handling cultural and commonsense knowledge. These outcomes represent a first step in the exploration of Dutch text simplification and shed light on future endeavours both for research and practice.
Diff-Retinex: Rethinking Low-light Image Enhancement with A Generative Diffusion Model
Aug 25, 2023
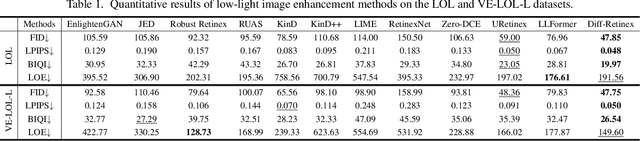
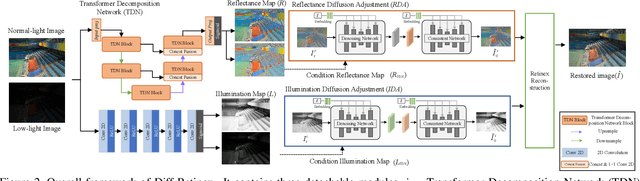
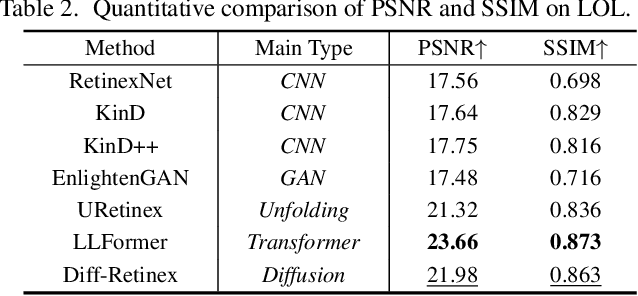
In this paper, we rethink the low-light image enhancement task and propose a physically explainable and generative diffusion model for low-light image enhancement, termed as Diff-Retinex. We aim to integrate the advantages of the physical model and the generative network. Furthermore, we hope to supplement and even deduce the information missing in the low-light image through the generative network. Therefore, Diff-Retinex formulates the low-light image enhancement problem into Retinex decomposition and conditional image generation. In the Retinex decomposition, we integrate the superiority of attention in Transformer and meticulously design a Retinex Transformer decomposition network (TDN) to decompose the image into illumination and reflectance maps. Then, we design multi-path generative diffusion networks to reconstruct the normal-light Retinex probability distribution and solve the various degradations in these components respectively, including dark illumination, noise, color deviation, loss of scene contents, etc. Owing to generative diffusion model, Diff-Retinex puts the restoration of low-light subtle detail into practice. Extensive experiments conducted on real-world low-light datasets qualitatively and quantitatively demonstrate the effectiveness, superiority, and generalization of the proposed method.
Viia-hand: a Reach-and-grasp Restoration System Integrating Voice interaction, Computer vision and Auditory feedback for Blind Amputees
Aug 14, 2023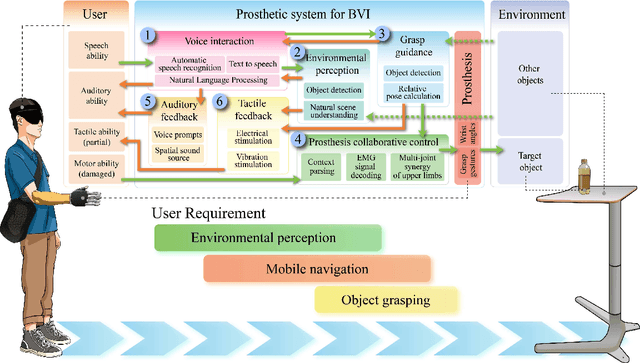
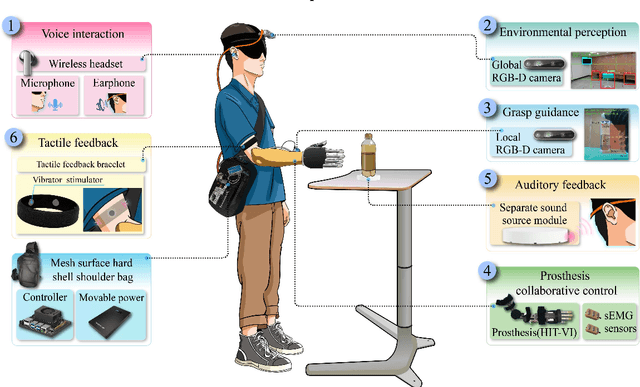

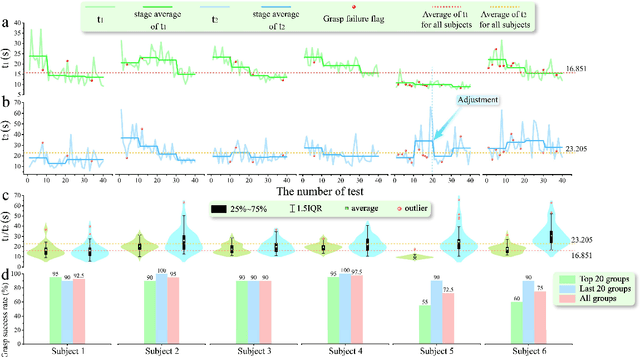
Visual feedback plays a crucial role in the process of amputation patients completing grasping in the field of prosthesis control. However, for blind and visually impaired (BVI) amputees, the loss of both visual and grasping abilities makes the "easy" reach-and-grasp task a feasible challenge. In this paper, we propose a novel multi-sensory prosthesis system helping BVI amputees with sensing, navigation and grasp operations. It combines modules of voice interaction, environmental perception, grasp guidance, collaborative control, and auditory/tactile feedback. In particular, the voice interaction module receives user instructions and invokes other functional modules according to the instructions. The environmental perception and grasp guidance module obtains environmental information through computer vision, and feedbacks the information to the user through auditory feedback modules (voice prompts and spatial sound sources) and tactile feedback modules (vibration stimulation). The prosthesis collaborative control module obtains the context information of the grasp guidance process and completes the collaborative control of grasp gestures and wrist angles of prosthesis in conjunction with the user's control intention in order to achieve stable grasp of various objects. This paper details a prototyping design (named viia-hand) and presents its preliminary experimental verification on healthy subjects completing specific reach-and-grasp tasks. Our results showed that, with the help of our new design, the subjects were able to achieve a precise reach and reliable grasp of the target objects in a relatively cluttered environment. Additionally, the system is extremely user-friendly, as users can quickly adapt to it with minimal training.
Information-Ordered Bottlenecks for Adaptive Semantic Compression
May 18, 2023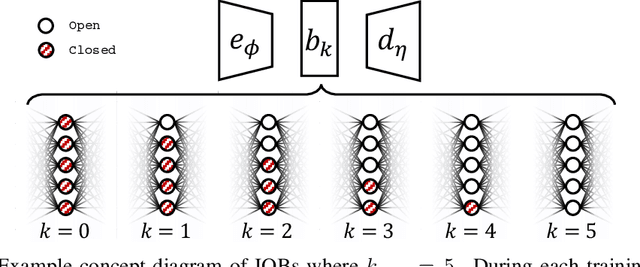
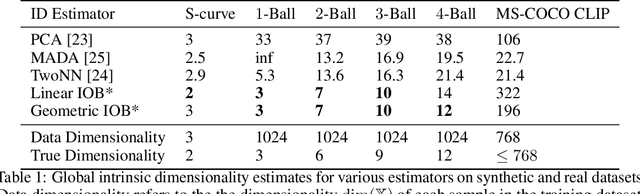

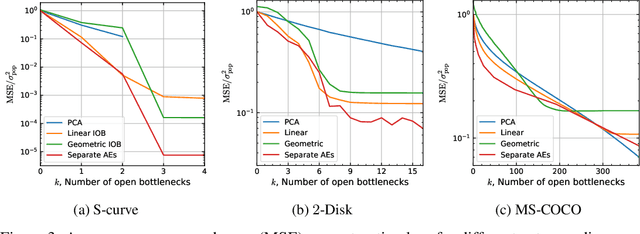
We present the information-ordered bottleneck (IOB), a neural layer designed to adaptively compress data into latent variables ordered by likelihood maximization. Without retraining, IOB nodes can be truncated at any bottleneck width, capturing the most crucial information in the first latent variables. Unifying several previous approaches, we show that IOBs achieve near-optimal compression for a given encoding architecture and can assign ordering to latent signals in a manner that is semantically meaningful. IOBs demonstrate a remarkable ability to compress embeddings of image and text data, leveraging the performance of SOTA architectures such as CNNs, transformers, and diffusion models. Moreover, we introduce a novel theory for estimating global intrinsic dimensionality with IOBs and show that they recover SOTA dimensionality estimates for complex synthetic data. Furthermore, we showcase the utility of these models for exploratory analysis through applications on heterogeneous datasets, enabling computer-aided discovery of dataset complexity.
On the Adversarial Robustness of Multi-Modal Foundation Models
Aug 21, 2023Multi-modal foundation models combining vision and language models such as Flamingo or GPT-4 have recently gained enormous interest. Alignment of foundation models is used to prevent models from providing toxic or harmful output. While malicious users have successfully tried to jailbreak foundation models, an equally important question is if honest users could be harmed by malicious third-party content. In this paper we show that imperceivable attacks on images in order to change the caption output of a multi-modal foundation model can be used by malicious content providers to harm honest users e.g. by guiding them to malicious websites or broadcast fake information. This indicates that countermeasures to adversarial attacks should be used by any deployed multi-modal foundation model.
On the Augmentation of Cognitive Accuracy and Cognitive Precision in Human/Cog Ensembles
Aug 16, 2023Whenever humans use tools human performance is enhanced. Cognitive systems are a new kind of tool continually increasing in cognitive capability and are now performing high level cognitive tasks previously thought to be explicitly human. Usage of such tools, known as cogs, are expected to result in ever increasing levels of human cognitive augmentation. In a human cog ensemble, a cooperative, peer to peer, and collaborative dialog between a human and a cognitive system, human cognitive capability is augmented as a result of the interaction. The human cog ensemble is therefore able to achieve more than just the human or the cog working alone. This article presents results from two studies designed to measure the effect information supplied by a cog has on cognitive accuracy, the ability to produce the correct result, and cognitive precision, the propensity to produce only the correct result. Both cognitive accuracy and cognitive precision are shown to be increased by information of different types (policies and rules, examples, and suggestions) and with different kinds of problems (inventive problem solving and puzzles). Similar effects shown in other studies are compared.
LibreFace: An Open-Source Toolkit for Deep Facial Expression Analysis
Aug 24, 2023
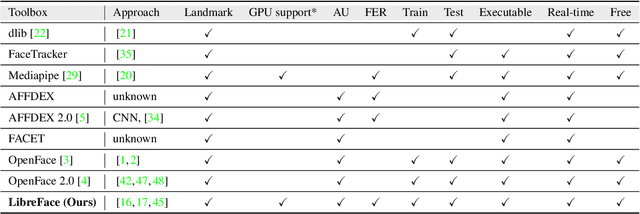
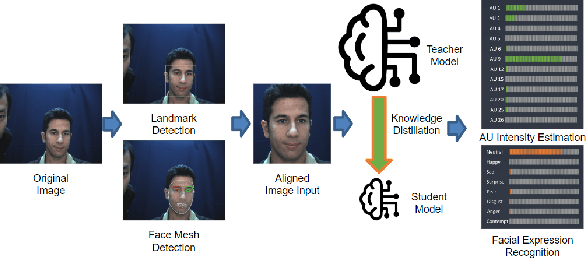

Facial expression analysis is an important tool for human-computer interaction. In this paper, we introduce LibreFace, an open-source toolkit for facial expression analysis. This open-source toolbox offers real-time and offline analysis of facial behavior through deep learning models, including facial action unit (AU) detection, AU intensity estimation, and facial expression recognition. To accomplish this, we employ several techniques, including the utilization of a large-scale pre-trained network, feature-wise knowledge distillation, and task-specific fine-tuning. These approaches are designed to effectively and accurately analyze facial expressions by leveraging visual information, thereby facilitating the implementation of real-time interactive applications. In terms of Action Unit (AU) intensity estimation, we achieve a Pearson Correlation Coefficient (PCC) of 0.63 on DISFA, which is 7% higher than the performance of OpenFace 2.0 while maintaining highly-efficient inference that runs two times faster than OpenFace 2.0. Despite being compact, our model also demonstrates competitive performance to state-of-the-art facial expression analysis methods on AffecNet, FFHQ, and RAF-DB. Our code will be released at https://github.com/ihp-lab/LibreFace
Heterogeneous Forgetting Compensation for Class-Incremental Learning
Aug 24, 2023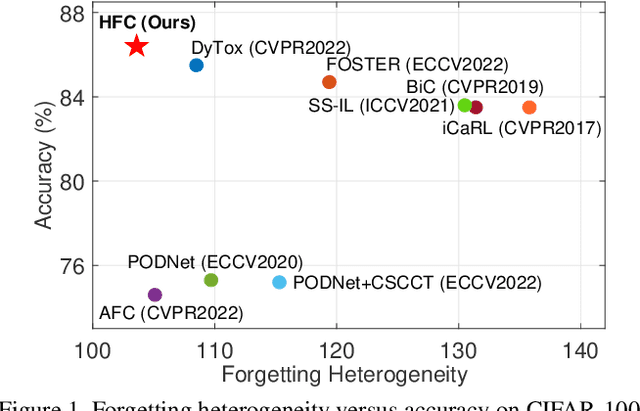
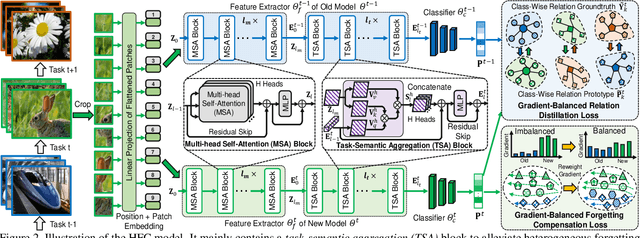
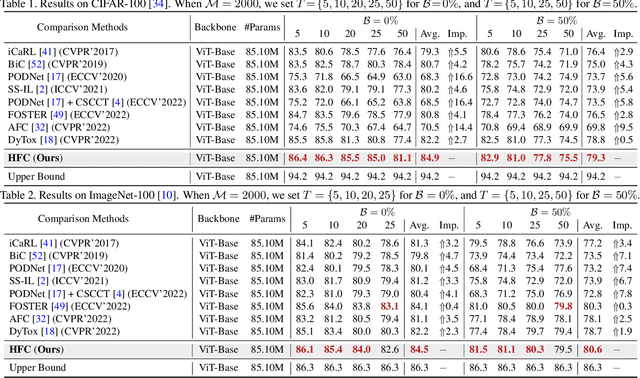
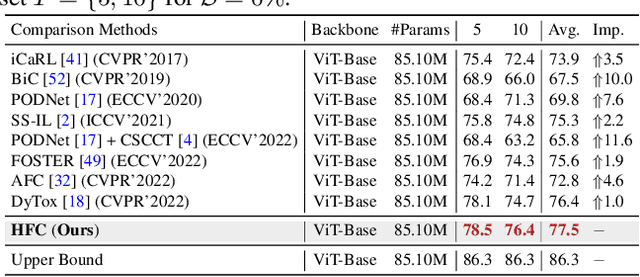
Class-incremental learning (CIL) has achieved remarkable successes in learning new classes consecutively while overcoming catastrophic forgetting on old categories. However, most existing CIL methods unreasonably assume that all old categories have the same forgetting pace, and neglect negative influence of forgetting heterogeneity among different old classes on forgetting compensation. To surmount the above challenges, we develop a novel Heterogeneous Forgetting Compensation (HFC) model, which can resolve heterogeneous forgetting of easy-to-forget and hard-to-forget old categories from both representation and gradient aspects. Specifically, we design a task-semantic aggregation block to alleviate heterogeneous forgetting from representation aspect. It aggregates local category information within each task to learn task-shared global representations. Moreover, we develop two novel plug-and-play losses: a gradient-balanced forgetting compensation loss and a gradient-balanced relation distillation loss to alleviate forgetting from gradient aspect. They consider gradient-balanced compensation to rectify forgetting heterogeneity of old categories and heterogeneous relation consistency. Experiments on several representative datasets illustrate effectiveness of our HFC model. The code is available at https://github.com/JiahuaDong/HFC.