 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Drones4Good: Supporting Disaster Relief Through Remote Sensing and AI
Aug 09, 2023
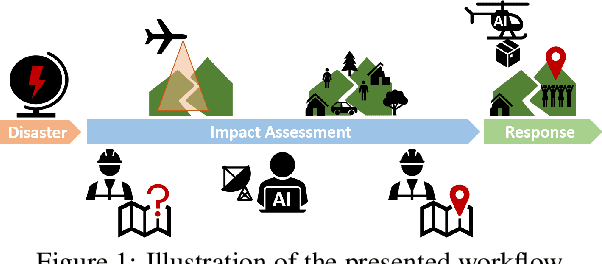



In order to respond effectively in the aftermath of a disaster, emergency services and relief organizations rely on timely and accurate information about the affected areas. Remote sensing has the potential to significantly reduce the time and effort required to collect such information by enabling a rapid survey of large areas. To achieve this, the main challenge is the automatic extraction of relevant information from remotely sensed data. In this work, we show how the combination of drone-based data with deep learning methods enables automated and large-scale situation assessment. In addition, we demonstrate the integration of onboard image processing techniques for the deployment of autonomous drone-based aid delivery. The results show the feasibility of a rapid and large-scale image analysis in the field, and that onboard image processing can increase the safety of drone-based aid deliveries.
TPDM: Selectively Removing Positional Information for Zero-shot Translation via Token-Level Position Disentangle Module
May 31, 2023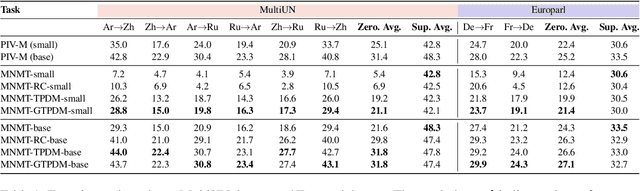
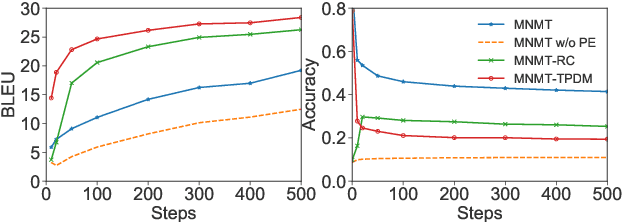
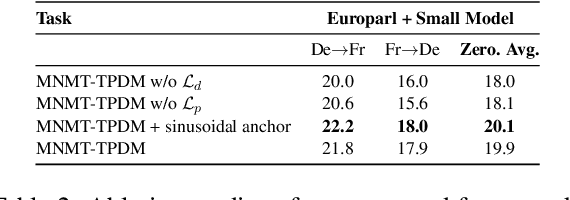
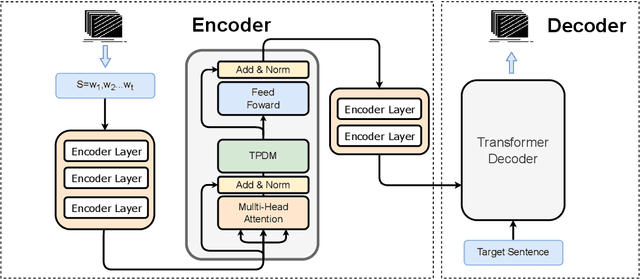
Due to Multilingual Neural Machine Translation's (MNMT) capability of zero-shot translation, many works have been carried out to fully exploit the potential of MNMT in zero-shot translation. It is often hypothesized that positional information may hinder the MNMT from outputting a robust encoded representation for decoding. However, previous approaches treat all the positional information equally and thus are unable to selectively remove certain positional information. In sharp contrast, this paper investigates how to learn to selectively preserve useful positional information. We describe the specific mechanism of positional information influencing MNMT from the perspective of linguistics at the token level. We design a token-level position disentangle module (TPDM) framework to disentangle positional information at the token level based on the explanation. Our experiments demonstrate that our framework improves zero-shot translation by a large margin while reducing the performance loss in the supervised direction compared to previous works.
Channel-Wise Contrastive Learning for Learning with Noisy Labels
Aug 14, 2023
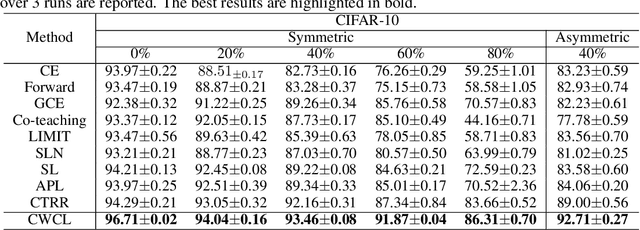
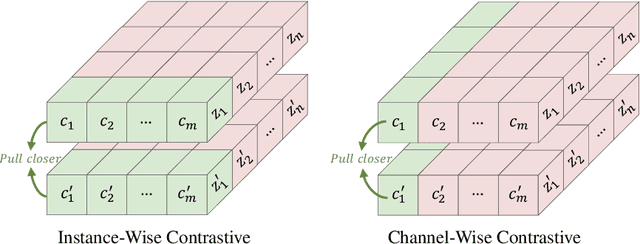
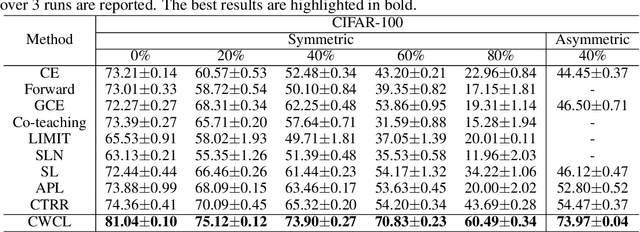
In real-world datasets, noisy labels are pervasive. The challenge of learning with noisy labels (LNL) is to train a classifier that discerns the actual classes from given instances. For this, the model must identify features indicative of the authentic labels. While research indicates that genuine label information is embedded in the learned features of even inaccurately labeled data, it's often intertwined with noise, complicating its direct application. Addressing this, we introduce channel-wise contrastive learning (CWCL). This method distinguishes authentic label information from noise by undertaking contrastive learning across diverse channels. Unlike conventional instance-wise contrastive learning (IWCL), CWCL tends to yield more nuanced and resilient features aligned with the authentic labels. Our strategy is twofold: firstly, using CWCL to extract pertinent features to identify cleanly labeled samples, and secondly, progressively fine-tuning using these samples. Evaluations on several benchmark datasets validate our method's superiority over existing approaches.
Space Object Identification and Classification from Hyperspectral Material Analysis
Aug 14, 2023

This paper presents a data processing pipeline designed to extract information from the hyperspectral signature of unknown space objects. The methodology proposed in this paper determines the material composition of space objects from single pixel images. Two techniques are used for material identification and classification: one based on machine learning and the other based on a least square match with a library of known spectra. From this information, a supervised machine learning algorithm is used to classify the object into one of several categories based on the detection of materials on the object. The behaviour of the material classification methods is investigated under non-ideal circumstances, to determine the effect of weathered materials, and the behaviour when the training library is missing a material that is present in the object being observed. Finally the paper will present some preliminary results on the identification and classification of space objects.
RMP-Loss: Regularizing Membrane Potential Distribution for Spiking Neural Networks
Aug 13, 2023
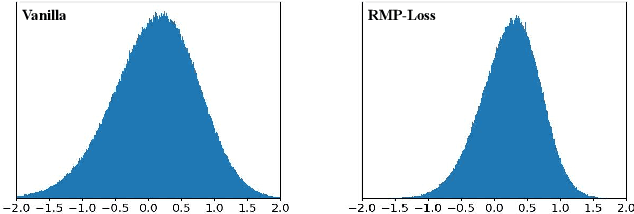
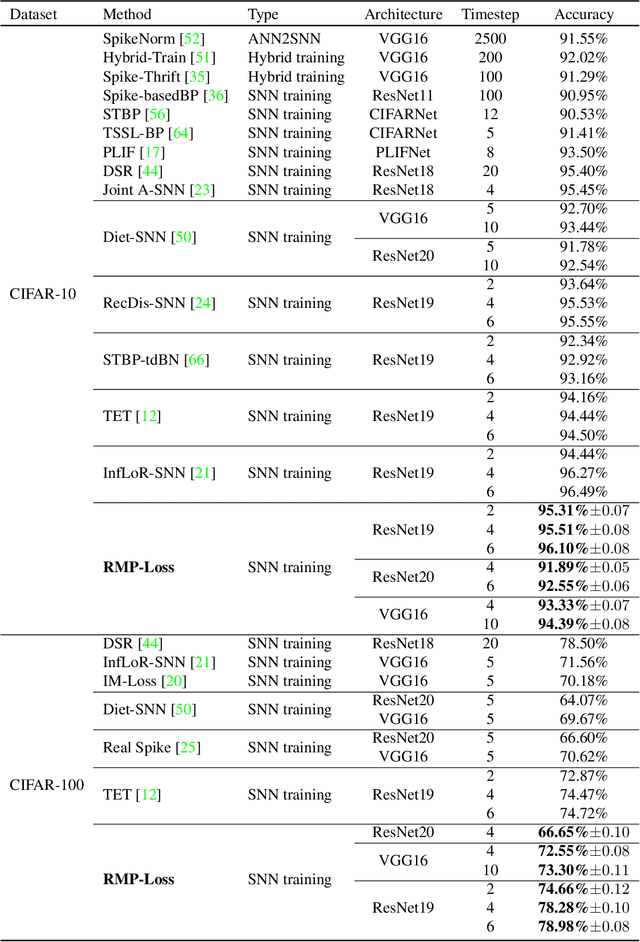
Spiking Neural Networks (SNNs) as one of the biology-inspired models have received much attention recently. It can significantly reduce energy consumption since they quantize the real-valued membrane potentials to 0/1 spikes to transmit information thus the multiplications of activations and weights can be replaced by additions when implemented on hardware. However, this quantization mechanism will inevitably introduce quantization error, thus causing catastrophic information loss. To address the quantization error problem, we propose a regularizing membrane potential loss (RMP-Loss) to adjust the distribution which is directly related to quantization error to a range close to the spikes. Our method is extremely simple to implement and straightforward to train an SNN. Furthermore, it is shown to consistently outperform previous state-of-the-art methods over different network architectures and datasets.
Multiscale Contextual Learning for Speech Emotion Recognition in Emergency Call Center Conversations
Aug 28, 2023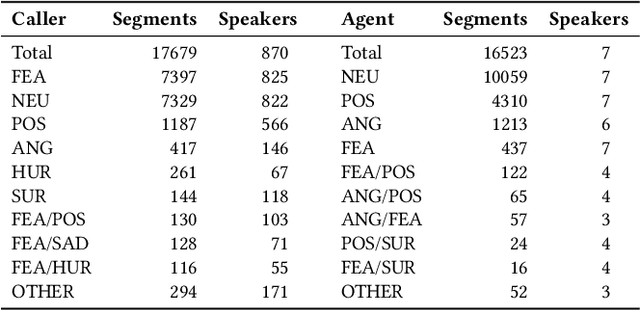
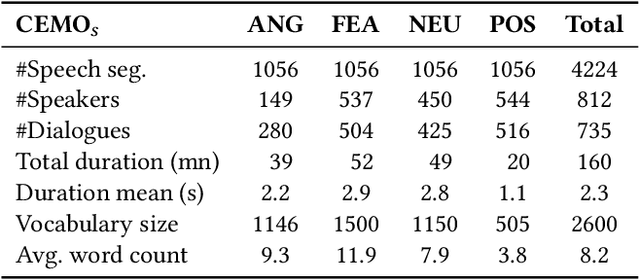
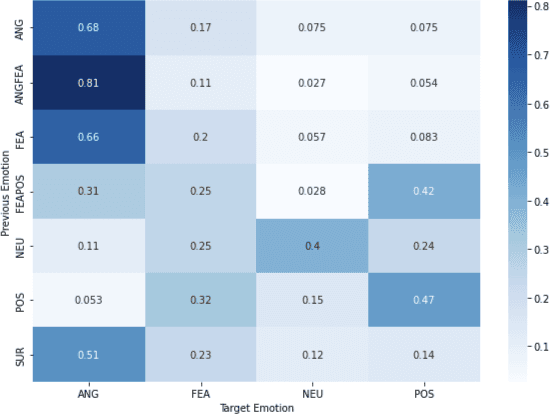
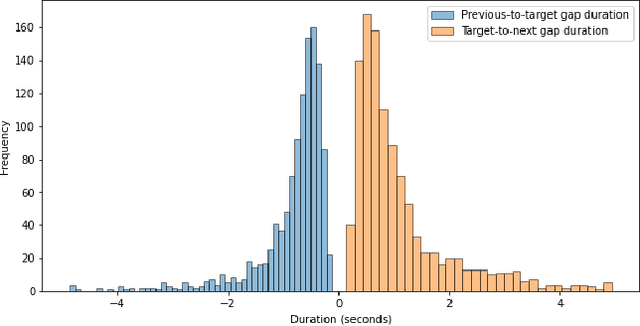
Emotion recognition in conversations is essential for ensuring advanced human-machine interactions. However, creating robust and accurate emotion recognition systems in real life is challenging, mainly due to the scarcity of emotion datasets collected in the wild and the inability to take into account the dialogue context. The CEMO dataset, composed of conversations between agents and patients during emergency calls to a French call center, fills this gap. The nature of these interactions highlights the role of the emotional flow of the conversation in predicting patient emotions, as context can often make a difference in understanding actual feelings. This paper presents a multi-scale conversational context learning approach for speech emotion recognition, which takes advantage of this hypothesis. We investigated this approach on both speech transcriptions and acoustic segments. Experimentally, our method uses the previous or next information of the targeted segment. In the text domain, we tested the context window using a wide range of tokens (from 10 to 100) and at the speech turns level, considering inputs from both the same and opposing speakers. According to our tests, the context derived from previous tokens has a more significant influence on accurate prediction than the following tokens. Furthermore, taking the last speech turn of the same speaker in the conversation seems useful. In the acoustic domain, we conducted an in-depth analysis of the impact of the surrounding emotions on the prediction. While multi-scale conversational context learning using Transformers can enhance performance in the textual modality for emergency call recordings, incorporating acoustic context is more challenging.
CommunityFish: A Poisson-based Document Scaling With Hierarchical Clustering
Aug 28, 2023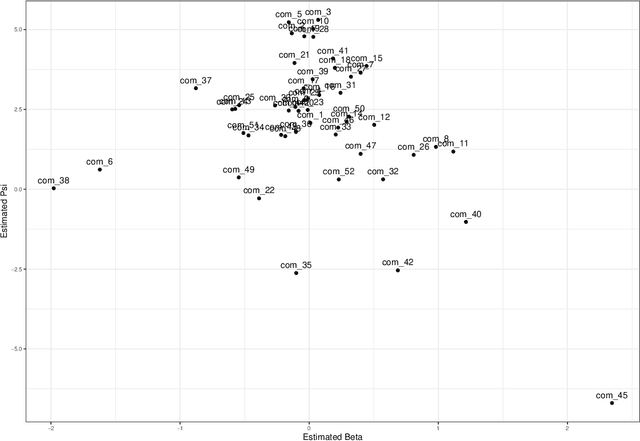
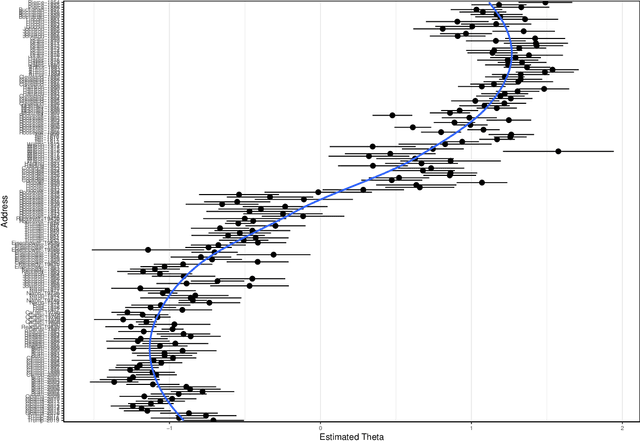
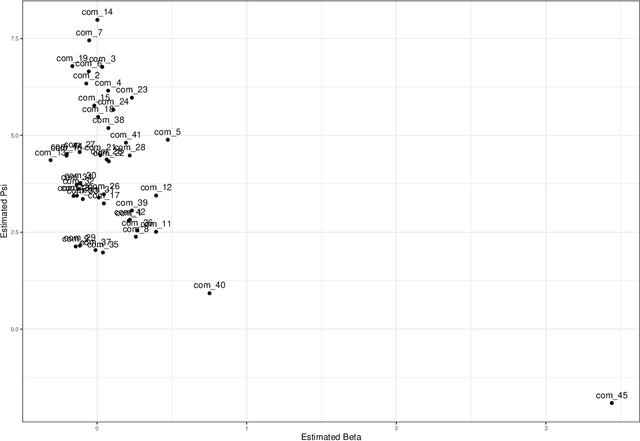
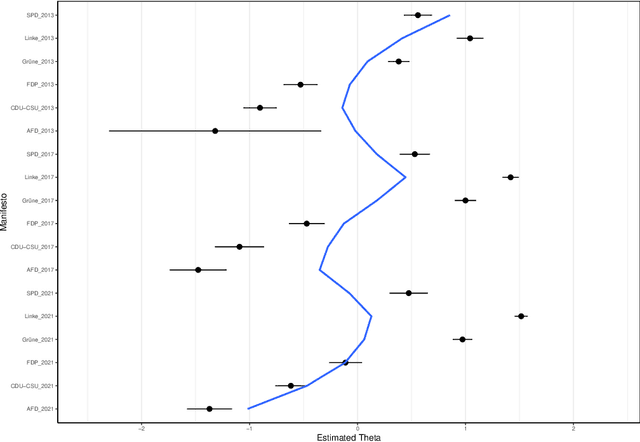
Document scaling has been a key component in text-as-data applications for social scientists and a major field of interest for political researchers, who aim at uncovering differences between speakers or parties with the help of different probabilistic and non-probabilistic approaches. Yet, most of these techniques are either built upon the agnostically bag-of-word hypothesis or use prior information borrowed from external sources that might embed the results with a significant bias. If the corpus has long been considered as a collection of documents, it can also be seen as a dense network of connected words whose structure could be clustered to differentiate independent groups of words, based on their co-occurrences in documents, known as communities. This paper introduces CommunityFish as an augmented version of Wordfish based on a hierarchical clustering, namely the Louvain algorithm, on the word space to yield communities as semantic and independent n-grams emerging from the corpus and use them as an input to Wordfish method, instead of considering the word space. This strategy emphasizes the interpretability of the results, since communities have a non-overlapping structure, hence a crucial informative power in discriminating parties or speakers, in addition to allowing a faster execution of the Poisson scaling model. Aside from yielding communities, assumed to be subtopic proxies, the application of this technique outperforms the classic Wordfish model by highlighting historical developments in the U.S. State of the Union addresses and was found to replicate the prevailing political stance in Germany when using the corpus of parties' legislative manifestos.
PointHPS: Cascaded 3D Human Pose and Shape Estimation from Point Clouds
Aug 28, 2023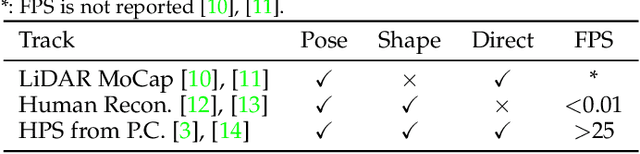
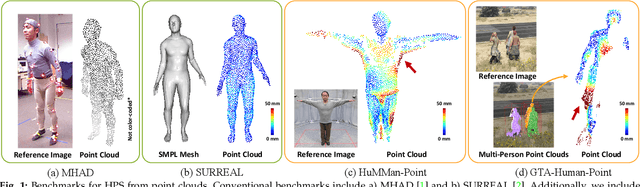
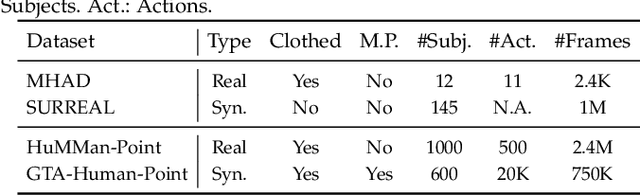
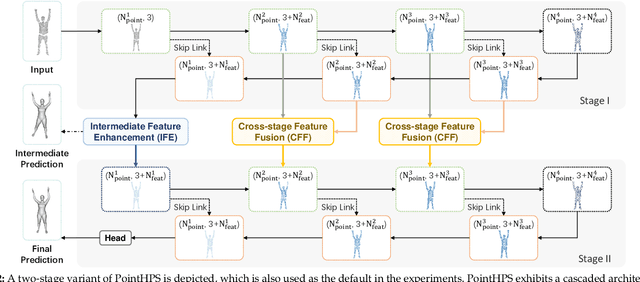
Human pose and shape estimation (HPS) has attracted increasing attention in recent years. While most existing studies focus on HPS from 2D images or videos with inherent depth ambiguity, there are surging need to investigate HPS from 3D point clouds as depth sensors have been frequently employed in commercial devices. However, real-world sensory 3D points are usually noisy and incomplete, and also human bodies could have different poses of high diversity. To tackle these challenges, we propose a principled framework, PointHPS, for accurate 3D HPS from point clouds captured in real-world settings, which iteratively refines point features through a cascaded architecture. Specifically, each stage of PointHPS performs a series of downsampling and upsampling operations to extract and collate both local and global cues, which are further enhanced by two novel modules: 1) Cross-stage Feature Fusion (CFF) for multi-scale feature propagation that allows information to flow effectively through the stages, and 2) Intermediate Feature Enhancement (IFE) for body-aware feature aggregation that improves feature quality after each stage. To facilitate a comprehensive study under various scenarios, we conduct our experiments on two large-scale benchmarks, comprising i) a dataset that features diverse subjects and actions captured by real commercial sensors in a laboratory environment, and ii) controlled synthetic data generated with realistic considerations such as clothed humans in crowded outdoor scenes. Extensive experiments demonstrate that PointHPS, with its powerful point feature extraction and processing scheme, outperforms State-of-the-Art methods by significant margins across the board. Homepage: https://caizhongang.github.io/projects/PointHPS/.
FaceChain: A Playground for Identity-Preserving Portrait Generation
Aug 28, 2023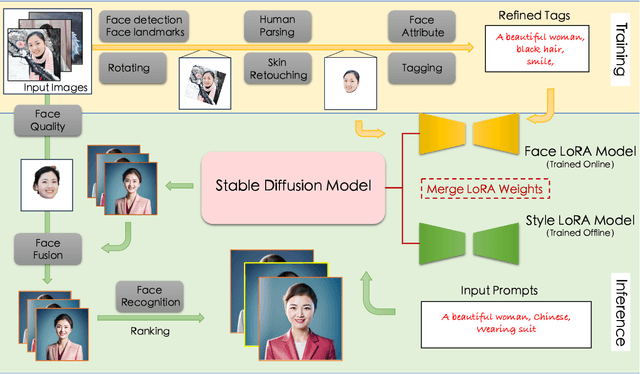

Recent advancement in personalized image generation have unveiled the intriguing capability of pre-trained text-to-image models on learning identity information from a collection of portrait images. However, existing solutions can be vulnerable in producing truthful details, and usually suffer from several defects such as (i) The generated face exhibit its own unique characteristics, \ie facial shape and facial feature positioning may not resemble key characteristics of the input, and (ii) The synthesized face may contain warped, blurred or corrupted regions. In this paper, we present FaceChain, a personalized portrait generation framework that combines a series of customized image-generation model and a rich set of face-related perceptual understanding models (\eg, face detection, deep face embedding extraction, and facial attribute recognition), to tackle aforementioned challenges and to generate truthful personalized portraits, with only a handful of portrait images as input. Concretely, we inject several SOTA face models into the generation procedure, achieving a more efficient label-tagging, data-processing, and model post-processing compared to previous solutions, such as DreamBooth ~\cite{ruiz2023dreambooth} , InstantBooth ~\cite{shi2023instantbooth} , or other LoRA-only approaches ~\cite{hu2021lora} . Through the development of FaceChain, we have identified several potential directions to accelerate development of Face/Human-Centric AIGC research and application. We have designed FaceChain as a framework comprised of pluggable components that can be easily adjusted to accommodate different styles and personalized needs. We hope it can grow to serve the burgeoning needs from the communities. FaceChain is open-sourced under Apache-2.0 license at \url{https://github.com/modelscope/facechain}.
Dynamic Kernel-Based Adaptive Spatial Aggregation for Learned Image Compression
Aug 17, 2023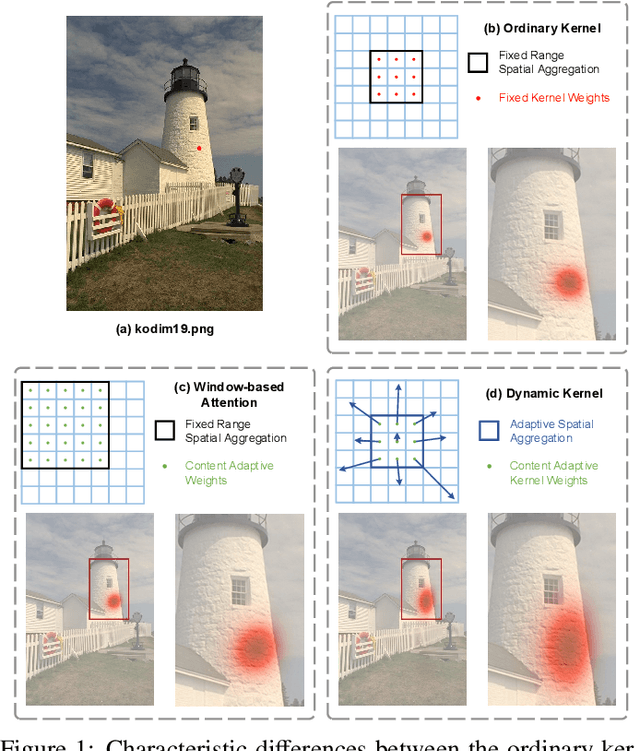
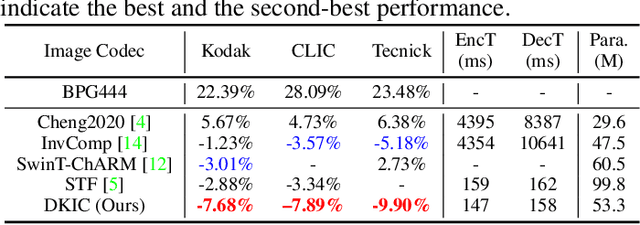
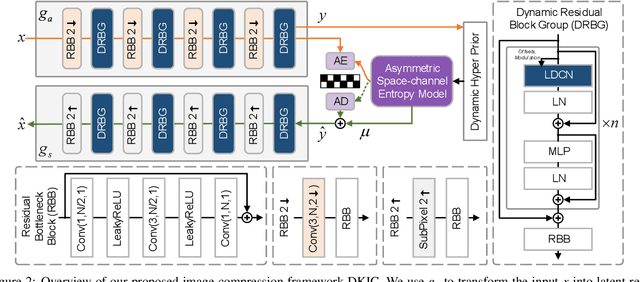
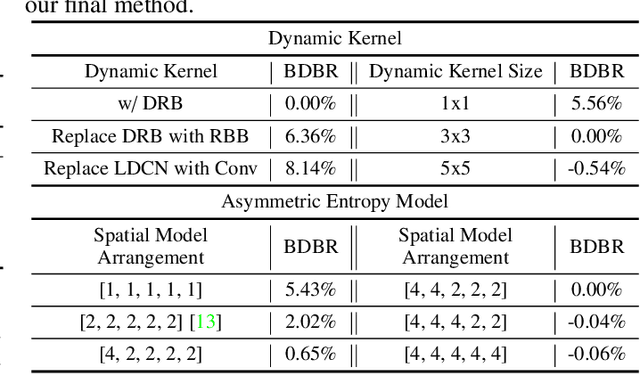
Learned image compression methods have shown superior rate-distortion performance and remarkable potential compared to traditional compression methods. Most existing learned approaches use stacked convolution or window-based self-attention for transform coding, which aggregate spatial information in a fixed range. In this paper, we focus on extending spatial aggregation capability and propose a dynamic kernel-based transform coding. The proposed adaptive aggregation generates kernel offsets to capture valid information in the content-conditioned range to help transform. With the adaptive aggregation strategy and the sharing weights mechanism, our method can achieve promising transform capability with acceptable model complexity. Besides, according to the recent progress of entropy model, we define a generalized coarse-to-fine entropy model, considering the coarse global context, the channel-wise, and the spatial context. Based on it, we introduce dynamic kernel in hyper-prior to generate more expressive global context. Furthermore, we propose an asymmetric spatial-channel entropy model according to the investigation of the spatial characteristics of the grouped latents. The asymmetric entropy model aims to reduce statistical redundancy while maintaining coding efficiency. Experimental results demonstrate that our method achieves superior rate-distortion performance on three benchmarks compared to the state-of-the-art learning-based methods.