 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Practical Edge Detection via Robust Collaborative Learning
Aug 27, 2023
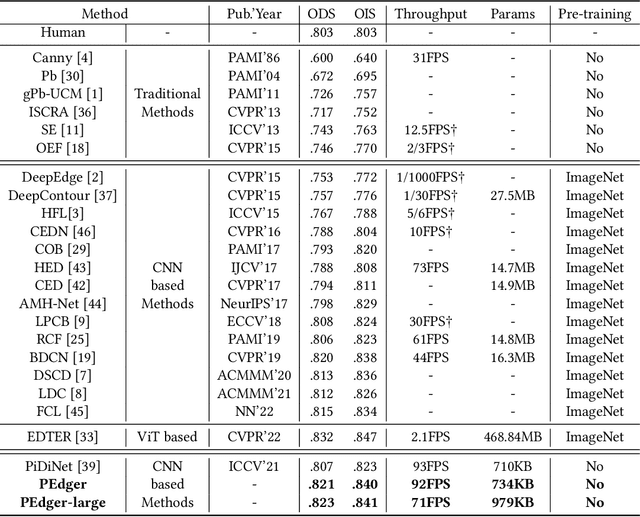

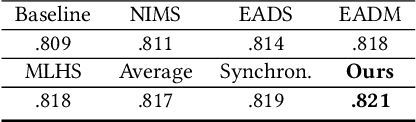
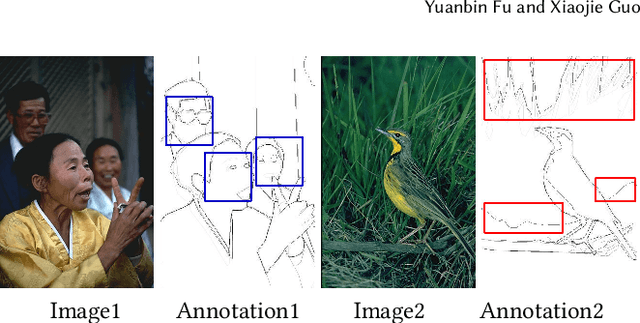
Edge detection, as a core component in a wide range of visionoriented tasks, is to identify object boundaries and prominent edges in natural images. An edge detector is desired to be both efficient and accurate for practical use. To achieve the goal, two key issues should be concerned: 1) How to liberate deep edge models from inefficient pre-trained backbones that are leveraged by most existing deep learning methods, for saving the computational cost and cutting the model size; and 2) How to mitigate the negative influence from noisy or even wrong labels in training data, which widely exist in edge detection due to the subjectivity and ambiguity of annotators, for the robustness and accuracy. In this paper, we attempt to simultaneously address the above problems via developing a collaborative learning based model, termed PEdger. The principle behind our PEdger is that, the information learned from different training moments and heterogeneous (recurrent and non recurrent in this work) architectures, can be assembled to explore robust knowledge against noisy annotations, even without the help of pre-training on extra data. Extensive ablation studies together with quantitative and qualitative experimental comparisons on the BSDS500 and NYUD datasets are conducted to verify the effectiveness of our design, and demonstrate its superiority over other competitors in terms of accuracy, speed, and model size. Codes can be found at https://github.co/ForawardStar/PEdger.
A Unified Transformer-based Network for multimodal Emotion Recognition
Aug 27, 2023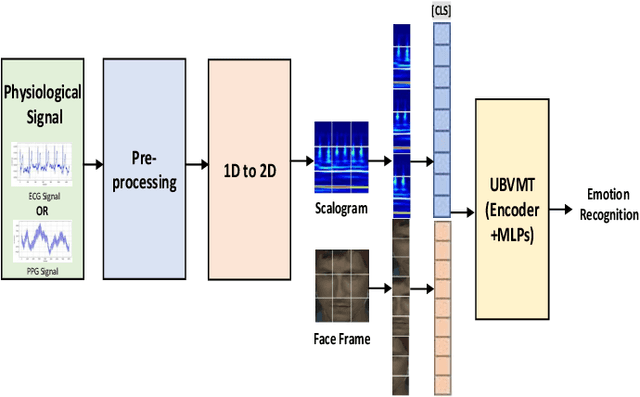
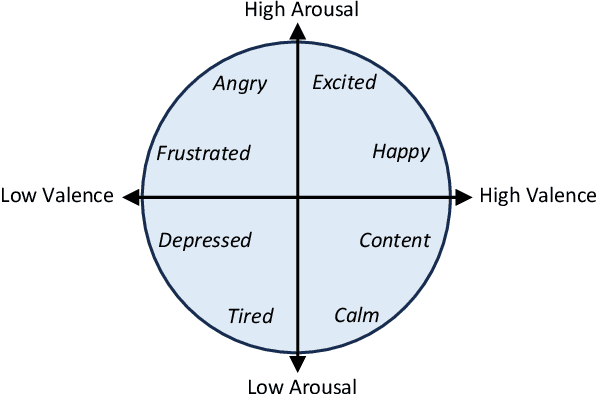

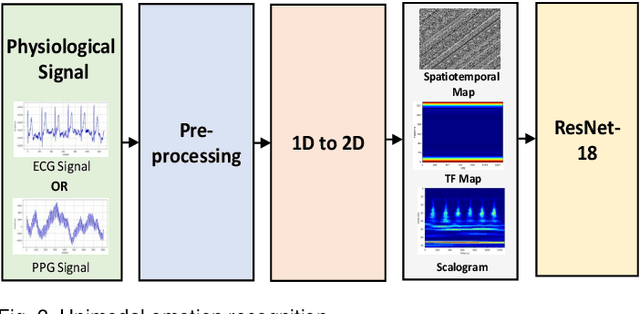
The development of transformer-based models has resulted in significant advances in addressing various vision and NLP-based research challenges. However, the progress made in transformer-based methods has not been effectively applied to biosensing research. This paper presents a novel Unified Biosensor-Vision Multi-modal Transformer-based (UBVMT) method to classify emotions in an arousal-valence space by combining a 2D representation of an ECG/PPG signal with the face information. To achieve this goal, we first investigate and compare the unimodal emotion recognition performance of three image-based representations of the ECG/PPG signal. We then present our UBVMT network which is trained to perform emotion recognition by combining the 2D image-based representation of the ECG/PPG signal and the facial expression features. Our unified transformer model consists of homogeneous transformer blocks that take as an input the 2D representation of the ECG/PPG signal and the corresponding face frame for emotion representation learning with minimal modality-specific design. Our UBVMT model is trained by reconstructing masked patches of video frames and 2D images of ECG/PPG signals, and contrastive modeling to align face and ECG/PPG data. Extensive experiments on the MAHNOB-HCI and DEAP datasets show that our Unified UBVMT-based model produces comparable results to the state-of-the-art techniques.
Balanced Representation Learning for Long-tailed Skeleton-based Action Recognition
Aug 27, 2023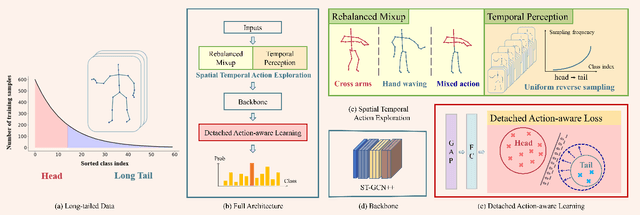
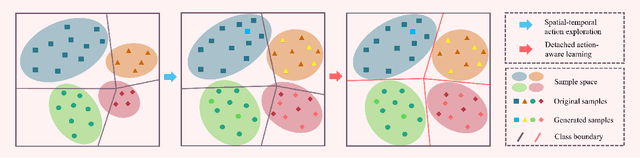
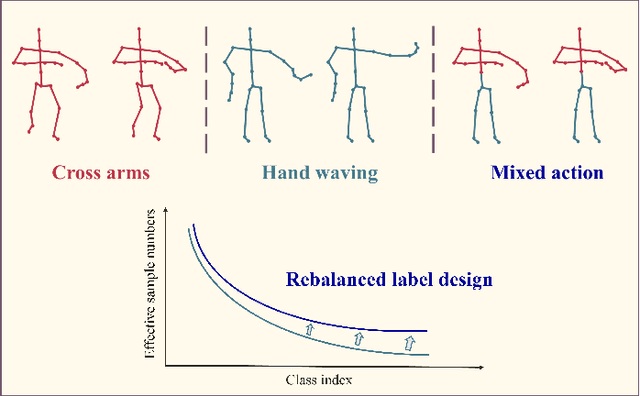
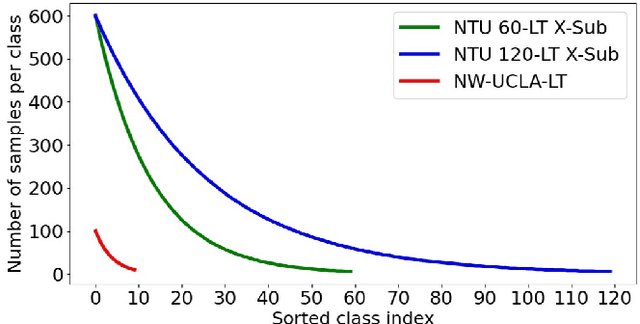
Skeleton-based action recognition has recently made significant progress. However, data imbalance is still a great challenge in real-world scenarios. The performance of current action recognition algorithms declines sharply when training data suffers from heavy class imbalance. The imbalanced data actually degrades the representations learned by these methods and becomes the bottleneck for action recognition. How to learn unbiased representations from imbalanced action data is the key to long-tailed action recognition. In this paper, we propose a novel balanced representation learning method to address the long-tailed problem in action recognition. Firstly, a spatial-temporal action exploration strategy is presented to expand the sample space effectively, generating more valuable samples in a rebalanced manner. Secondly, we design a detached action-aware learning schedule to further mitigate the bias in the representation space. The schedule detaches the representation learning of tail classes from training and proposes an action-aware loss to impose more effective constraints. Additionally, a skip-modal representation is proposed to provide complementary structural information. The proposed method is validated on four skeleton datasets, NTU RGB+D 60, NTU RGB+D 120, NW-UCLA, and Kinetics. It not only achieves consistently large improvement compared to the state-of-the-art (SOTA) methods, but also demonstrates a superior generalization capacity through extensive experiments. Our code is available at https://github.com/firework8/BRL.
FFEINR: Flow Feature-Enhanced Implicit Neural Representation for Spatio-temporal Super-Resolution
Aug 27, 2023Large-scale numerical simulations are capable of generating data up to terabytes or even petabytes. As a promising method of data reduction, super-resolution (SR) has been widely studied in the scientific visualization community. However, most of them are based on deep convolutional neural networks (CNNs) or generative adversarial networks (GANs) and the scale factor needs to be determined before constructing the network. As a result, a single training session only supports a fixed factor and has poor generalization ability. To address these problems, this paper proposes a Feature-Enhanced Implicit Neural Representation (FFEINR) for spatio-temporal super-resolution of flow field data. It can take full advantage of the implicit neural representation in terms of model structure and sampling resolution. The neural representation is based on a fully connected network with periodic activation functions, which enables us to obtain lightweight models. The learned continuous representation can decode the low-resolution flow field input data to arbitrary spatial and temporal resolutions, allowing for flexible upsampling. The training process of FFEINR is facilitated by introducing feature enhancements for the input layer, which complements the contextual information of the flow field. To demonstrate the effectiveness of the proposed method, a series of experiments are conducted on different datasets by setting different hyperparameters. The results show that FFEINR achieves significantly better results than the trilinear interpolation method.
Achievable Sum-rate of variants of QAM over Gaussian Multiple Access Channel with and without security
Aug 22, 2023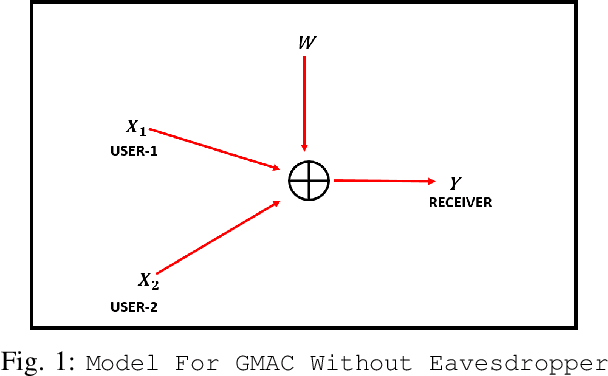
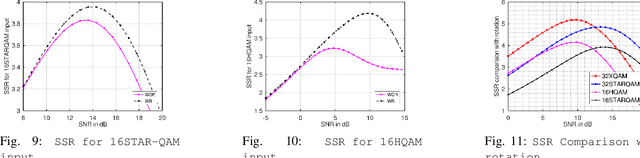
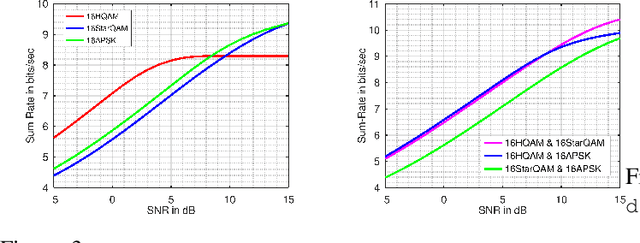
The performance of next generation wireless systems (5G/6G and beyond) at the physical layer is primarily driven by the choice of digital modulation techniques that are bandwidth and power efficient, while maintaining high data rates. Achievable rates for Gaussian input and some finite constellations (BPSK/QPSK/QAM) are well studied in the literature. However, new variants of Quadrature Amplitude Modulation (QAM) such as Cross-QAM (XQAM), Star-QAM (S-QAM), Amplitude and phase shift keying (APSK), and Hexagonal Quadrature Amplitude Modulation (H-QAM) are not studied in the context of achievable rates for meeting the demand of high data rates. In this paper, we study achievable rate region for different variants of M-QAM like Cross-QAM, H-QAM, Star-QAM and APSK. We also compute mutual information corresponding to the sum rate of Gaussian Multiple Access Channel (G-MAC), for hybrid constellation scheme, e.g., user 1 transmits using Star-QAM and user 2 by H-QAM. From the results, it is observed that S-QAM gives the maximum sum-rate when users transmit same constellations. Also, it has been found that when hybrid constellation is used, the combination of Star-QAM \& H-QAM gives the maximum rate. In the next part of the paper, we consider a scenario wherein an adversary is also present at the receiver side and is trying to decode the information. We model this scenario as Gaussian Multiple Access Wiretap Channel (G-MAW-WT). We then compute the achievable secrecy sum rate of two user G-MAC-WT with discrete inputs from different variants of QAM (viz, X-QAM, H-QAM and S-QAM).It has been found that at higher values of SNR, S-QAM gives better values of SSR than the other variants. For hybrid inputs of QAM, at lower values of SNR, combination of APSK and S-QAM gives better results and at higher values of SNR, combination of HQAM and APSK gives greater value of SSR.
Spatio-Temporal Adaptive Embedding Makes Vanilla Transformer SOTA for Traffic Forecasting
Aug 22, 2023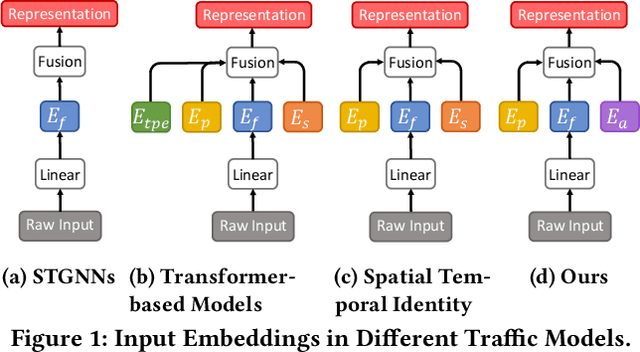
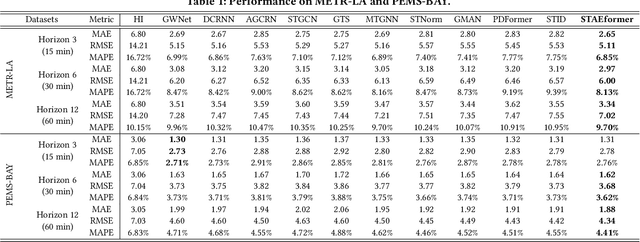
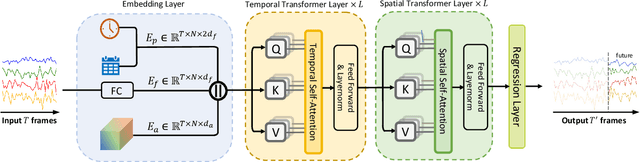
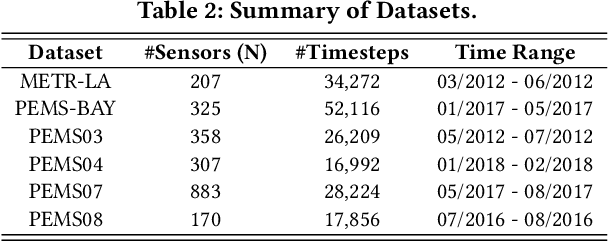
With the rapid development of the Intelligent Transportation System (ITS), accurate traffic forecasting has emerged as a critical challenge. The key bottleneck lies in capturing the intricate spatio-temporal traffic patterns. In recent years, numerous neural networks with complicated architectures have been proposed to address this issue. However, the advancements in network architectures have encountered diminishing performance gains. In this study, we present a novel component called spatio-temporal adaptive embedding that can yield outstanding results with vanilla transformers. Our proposed Spatio-Temporal Adaptive Embedding transformer (STAEformer) achieves state-of-the-art performance on five real-world traffic forecasting datasets. Further experiments demonstrate that spatio-temporal adaptive embedding plays a crucial role in traffic forecasting by effectively capturing intrinsic spatio-temporal relations and chronological information in traffic time series.
MatFuse: Controllable Material Generation with Diffusion Models
Aug 22, 2023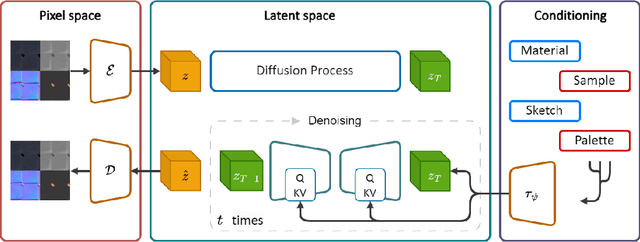
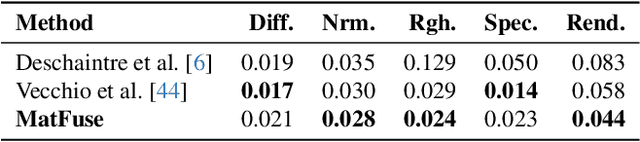
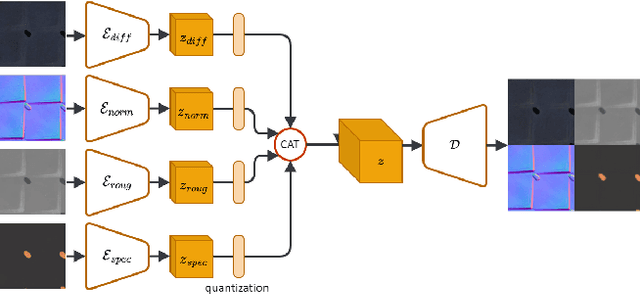
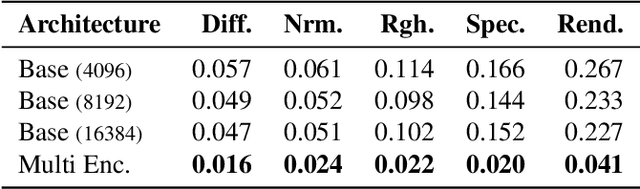
Creating high quality and realistic materials in computer graphics is a challenging and time-consuming task, which requires great expertise. In this paper, we present MatFuse, a novel unified approach that harnesses the generative power of diffusion models (DM) to simplify the creation of SVBRDF maps. Our DM-based pipeline integrates multiple sources of conditioning, such as color palettes, sketches, and pictures, enabling fine-grained control and flexibility in material synthesis. This design allows for the combination of diverse information sources (e.g., sketch + image embedding), enhancing creative possibilities in line with the principle of compositionality. We demonstrate the generative capabilities of the proposed method under various conditioning settings; on the SVBRDF estimation task, we show that our method yields performance comparable to state-of-the-art approaches, both qualitatively and quantitatively.
Invariant representation learning for sequential recommendation
Aug 22, 2023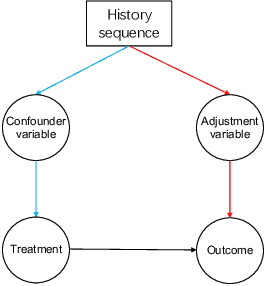

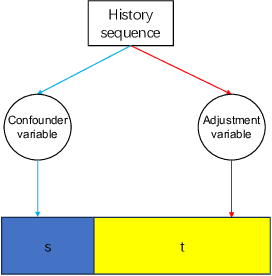
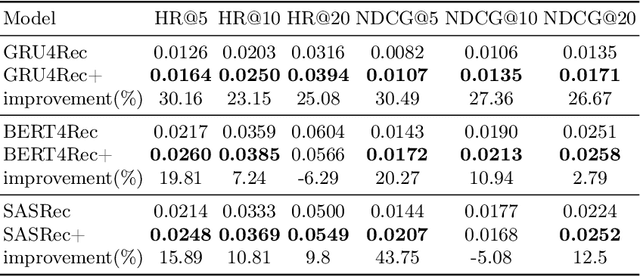
Sequential recommendation involves automatically recommending the next item to users based on their historical item sequence. While most prior research employs RNN or transformer methods to glean information from the item sequence-generating probabilities for each user-item pair and recommending the top items, these approaches often overlook the challenge posed by spurious relationships. This paper specifically addresses these spurious relations. We introduce a novel sequential recommendation framework named Irl4Rec. This framework harnesses invariant learning and employs a new objective that factors in the relationship between spurious variables and adjustment variables during model training. This approach aids in identifying spurious relations. Comparative analyses reveal that our framework outperforms three typical methods, underscoring the effectiveness of our model. Moreover, an ablation study further demonstrates the critical role our model plays in detecting spurious relations.
Source-free Domain Adaptive Human Pose Estimation
Aug 18, 2023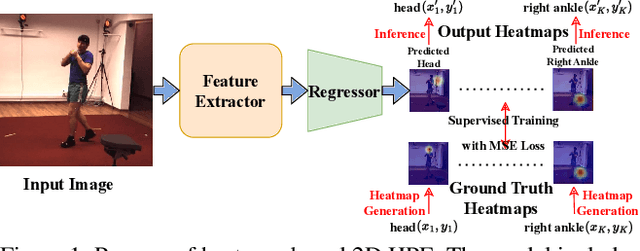
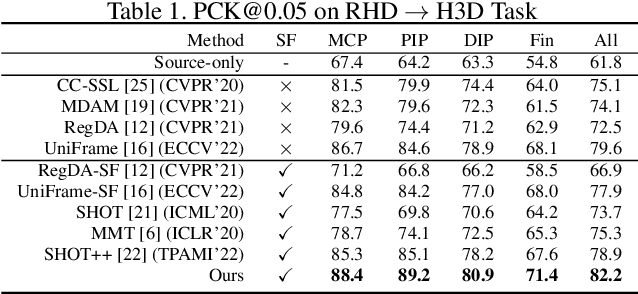
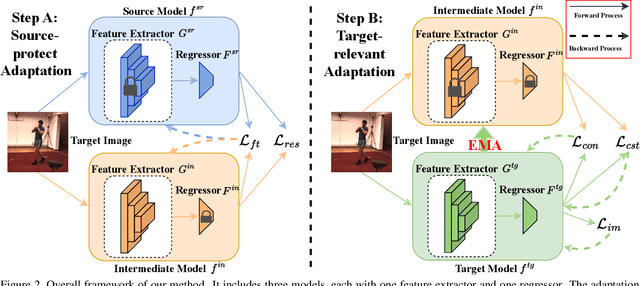
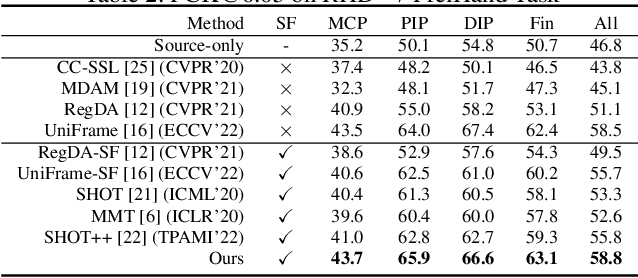
Human Pose Estimation (HPE) is widely used in various fields, including motion analysis, healthcare, and virtual reality. However, the great expenses of labeled real-world datasets present a significant challenge for HPE. To overcome this, one approach is to train HPE models on synthetic datasets and then perform domain adaptation (DA) on real-world data. Unfortunately, existing DA methods for HPE neglect data privacy and security by using both source and target data in the adaptation process. To this end, we propose a new task, named source-free domain adaptive HPE, which aims to address the challenges of cross-domain learning of HPE without access to source data during the adaptation process. We further propose a novel framework that consists of three models: source model, intermediate model, and target model, which explores the task from both source-protect and target-relevant perspectives. The source-protect module preserves source information more effectively while resisting noise, and the target-relevant module reduces the sparsity of spatial representations by building a novel spatial probability space, and pose-specific contrastive learning and information maximization are proposed on the basis of this space. Comprehensive experiments on several domain adaptive HPE benchmarks show that the proposed method outperforms existing approaches by a considerable margin. The codes are available at https://github.com/davidpengucf/SFDAHPE.
Local Structure-aware Graph Contrastive Representation Learning
Aug 07, 2023Traditional Graph Neural Network (GNN), as a graph representation learning method, is constrained by label information. However, Graph Contrastive Learning (GCL) methods, which tackle the label problem effectively, mainly focus on the feature information of the global graph or small subgraph structure (e.g., the first-order neighborhood). In the paper, we propose a Local Structure-aware Graph Contrastive representation Learning method (LS-GCL) to model the structural information of nodes from multiple views. Specifically, we construct the semantic subgraphs that are not limited to the first-order neighbors. For the local view, the semantic subgraph of each target node is input into a shared GNN encoder to obtain the target node embeddings at the subgraph-level. Then, we use a pooling function to generate the subgraph-level graph embeddings. For the global view, considering the original graph preserves indispensable semantic information of nodes, we leverage the shared GNN encoder to learn the target node embeddings at the global graph-level. The proposed LS-GCL model is optimized to maximize the common information among similar instances at three various perspectives through a multi-level contrastive loss function. Experimental results on five datasets illustrate that our method outperforms state-of-the-art graph representation learning approaches for both node classification and link prediction tasks.