 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Video Recommendation Using Social Network Analysis and User Viewing Patterns
Aug 24, 2023

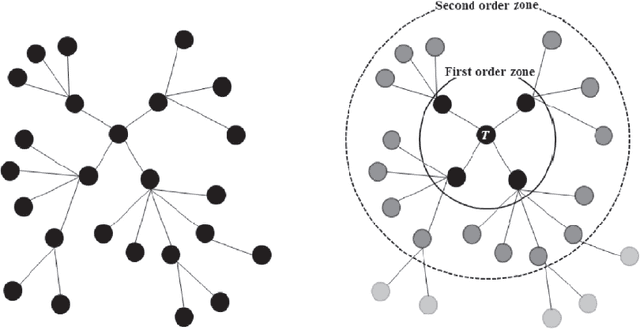
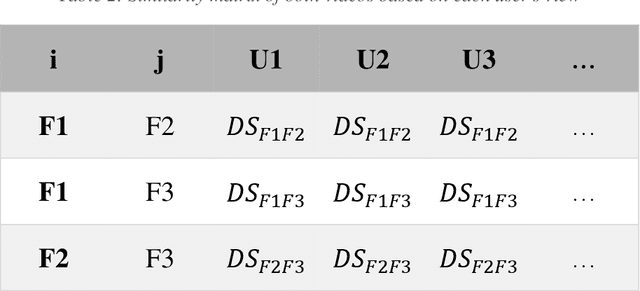
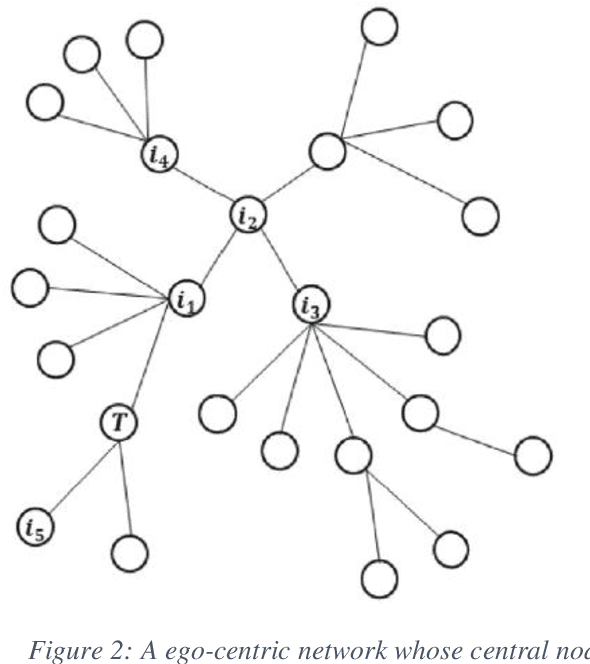
With the meteoric rise of video-on-demand (VOD) platforms, users face the challenge of sifting through an expansive sea of content to uncover shows that closely match their preferences. To address this information overload dilemma, VOD services have increasingly incorporated recommender systems powered by algorithms that analyze user behavior and suggest personalized content. However, a majority of existing recommender systems depend on explicit user feedback in the form of ratings and reviews, which can be difficult and time-consuming to collect at scale. This presents a key research gap, as leveraging users' implicit feedback patterns could provide an alternative avenue for building effective video recommendation models, circumventing the need for explicit ratings. However, prior literature lacks sufficient exploration into implicit feedback-based recommender systems, especially in the context of modeling video viewing behavior. Therefore, this paper aims to bridge this research gap by proposing a novel video recommendation technique that relies solely on users' implicit feedback in the form of their content viewing percentages.
An Efficient Distributed Multi-Agent Reinforcement Learning for EV Charging Network Control
Aug 24, 2023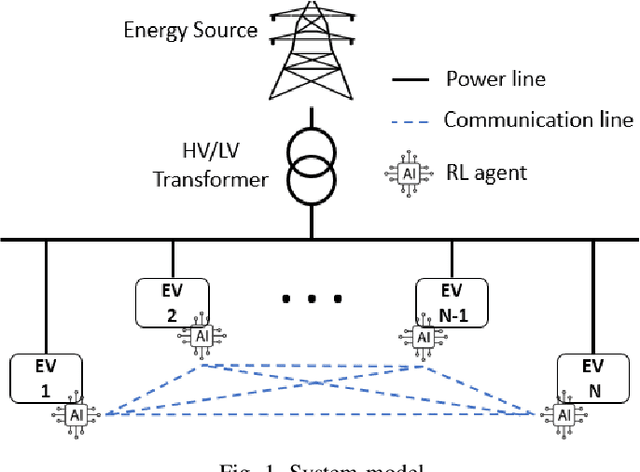
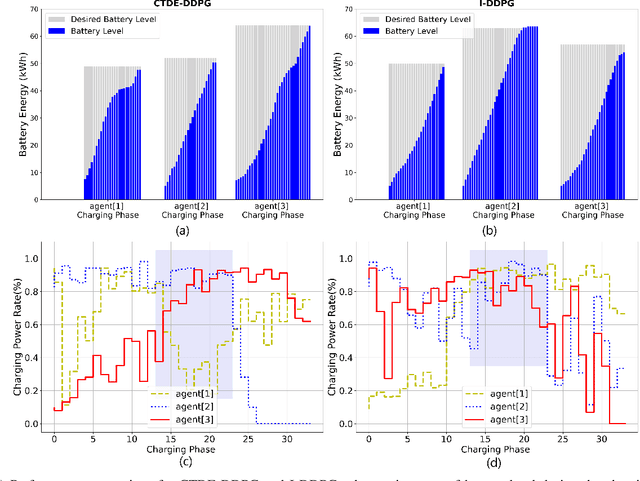
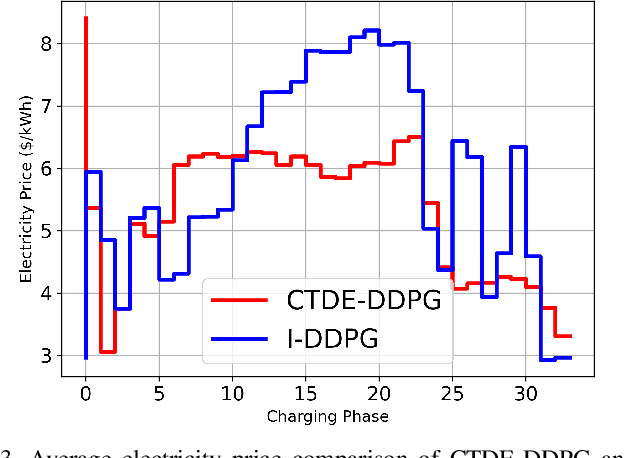
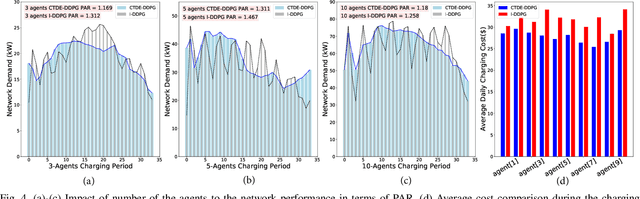
The increasing trend in adopting electric vehicles (EVs) will significantly impact the residential electricity demand, which results in an increased risk of transformer overload in the distribution grid. To mitigate such risks, there are urgent needs to develop effective EV charging controllers. Currently, the majority of the EV charge controllers are based on a centralized approach for managing individual EVs or a group of EVs. In this paper, we introduce a decentralized Multi-agent Reinforcement Learning (MARL) charging framework that prioritizes the preservation of privacy for EV owners. We employ the Centralized Training Decentralized Execution-Deep Deterministic Policy Gradient (CTDE-DDPG) scheme, which provides valuable information to users during training while maintaining privacy during execution. Our results demonstrate that the CTDE framework improves the performance of the charging network by reducing the network costs. Moreover, we show that the Peak-to-Average Ratio (PAR) of the total demand is reduced, which, in turn, reduces the risk of transformer overload during the peak hours.
Perspective-aware Convolution for Monocular 3D Object Detection
Aug 24, 2023
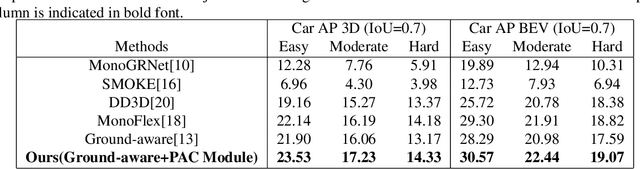

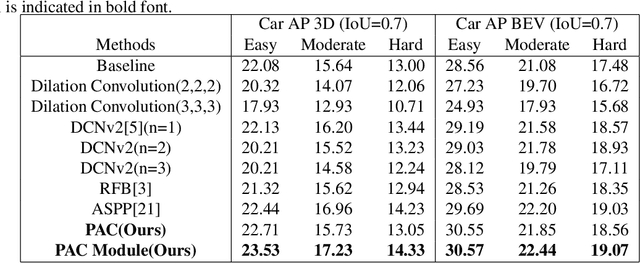
Monocular 3D object detection is a crucial and challenging task for autonomous driving vehicle, while it uses only a single camera image to infer 3D objects in the scene. To address the difficulty of predicting depth using only pictorial clue, we propose a novel perspective-aware convolutional layer that captures long-range dependencies in images. By enforcing convolutional kernels to extract features along the depth axis of every image pixel, we incorporates perspective information into network architecture. We integrate our perspective-aware convolutional layer into a 3D object detector and demonstrate improved performance on the KITTI3D dataset, achieving a 23.9\% average precision in the easy benchmark. These results underscore the importance of modeling scene clues for accurate depth inference and highlight the benefits of incorporating scene structure in network design. Our perspective-aware convolutional layer has the potential to enhance object detection accuracy by providing more precise and context-aware feature extraction.
Pixel-Aware Stable Diffusion for Realistic Image Super-resolution and Personalized Stylization
Aug 28, 2023
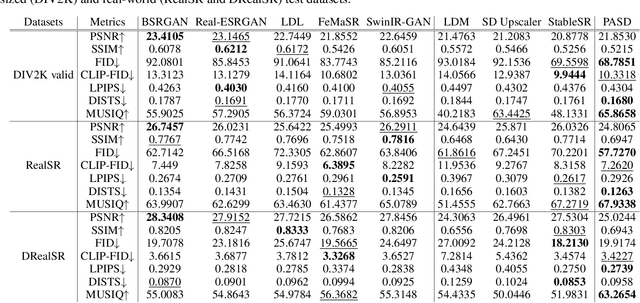
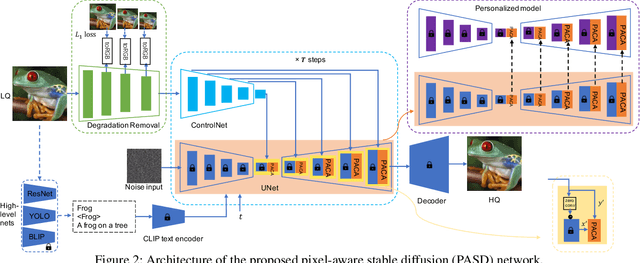
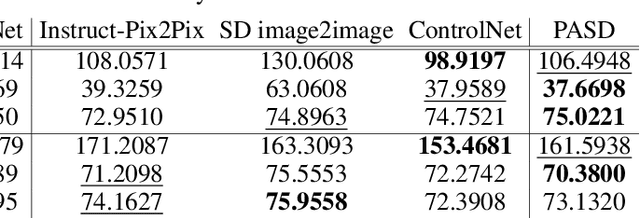
Realistic image super-resolution (Real-ISR) aims to reproduce perceptually realistic image details from a low-quality input. The commonly used adversarial training based Real-ISR methods often introduce unnatural visual artifacts and fail to generate realistic textures for natural scene images. The recently developed generative stable diffusion models provide a potential solution to Real-ISR with pre-learned strong image priors. However, the existing methods along this line either fail to keep faithful pixel-wise image structures or resort to extra skipped connections to reproduce details, which requires additional training in image space and limits their extension to other related tasks in latent space such as image stylization. In this work, we propose a pixel-aware stable diffusion (PASD) network to achieve robust Real-ISR as well as personalized stylization. In specific, a pixel-aware cross attention module is introduced to enable diffusion models perceiving image local structures in pixel-wise level, while a degradation removal module is used to extract degradation insensitive features to guide the diffusion process together with image high level information. By simply replacing the base diffusion model with a personalized one, our method can generate diverse stylized images without the need to collect pairwise training data. PASD can be easily integrated into existing diffusion models such as Stable Diffusion. Experiments on Real-ISR and personalized stylization demonstrate the effectiveness of our proposed approach. The source code and models can be found at \url{https://github.com/yangxy/PASD}.
A Transformer-Conditioned Neural Fields Pipeline with Polar Coordinate Representation for Astronomical Radio Interferometric Data Reconstruction
Aug 28, 2023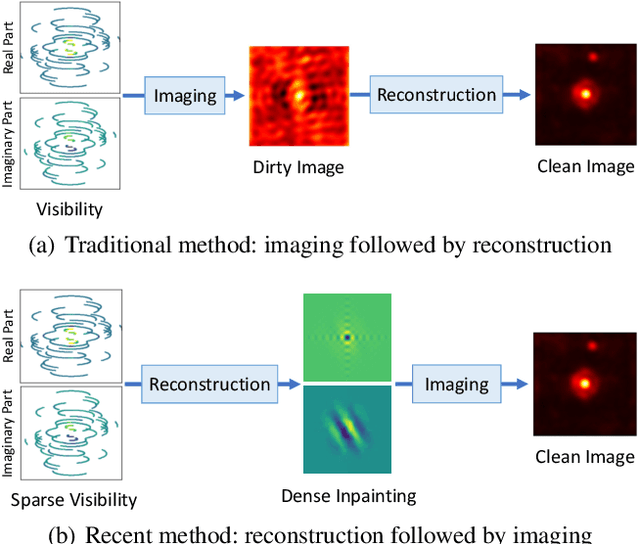
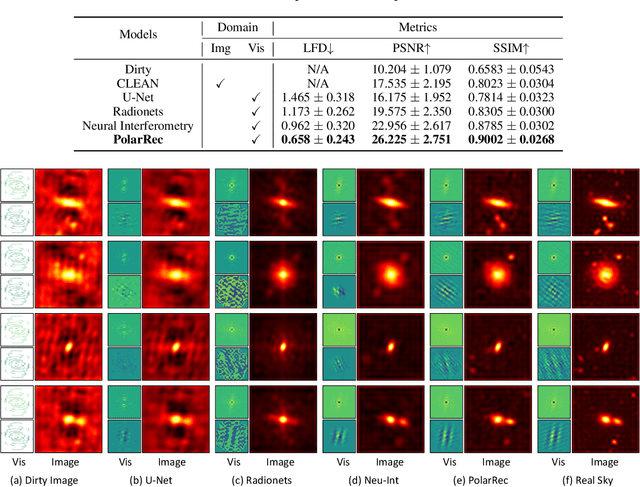
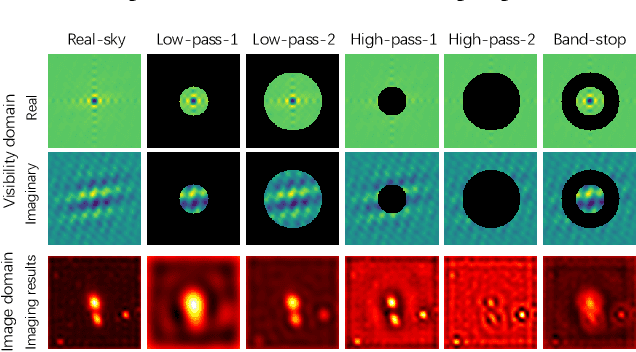
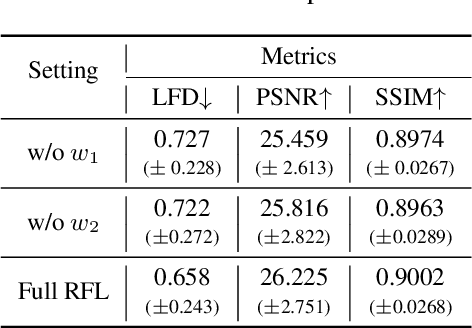
In radio astronomy, visibility data, which are measurements of wave signals from radio telescopes, are transformed into images for observation of distant celestial objects. However, these resultant images usually contain both real sources and artifacts, due to signal sparsity and other factors. One way to obtain cleaner images is to reconstruct samples into dense forms before imaging. Unfortunately, existing visibility reconstruction methods may miss some components of the frequency data, so blurred object edges and persistent artifacts remain in the images. Furthermore, the computation overhead is high on irregular visibility samples due to the data skew. To address these problems, we propose PolarRec, a reconstruction method for interferometric visibility data, which consists of a transformer-conditioned neural fields pipeline with a polar coordinate representation. This representation matches the way in which telescopes observe a celestial area as the Earth rotates. We further propose Radial Frequency Loss function, using radial coordinates in the polar coordinate system to correlate with the frequency information, to help reconstruct complete visibility. We also group visibility sample points by angular coordinates in the polar coordinate system, and use groups as the granularity for subsequent encoding with a Transformer encoder. Consequently, our method can capture the inherent characteristics of visibility data effectively and efficiently. Our experiments demonstrate that PolarRec markedly improves imaging results by faithfully reconstructing all frequency components in the visibility domain while significantly reducing the computation cost.
The Cultural Psychology of Large Language Models: Is ChatGPT a Holistic or Analytic Thinker?
Aug 28, 2023
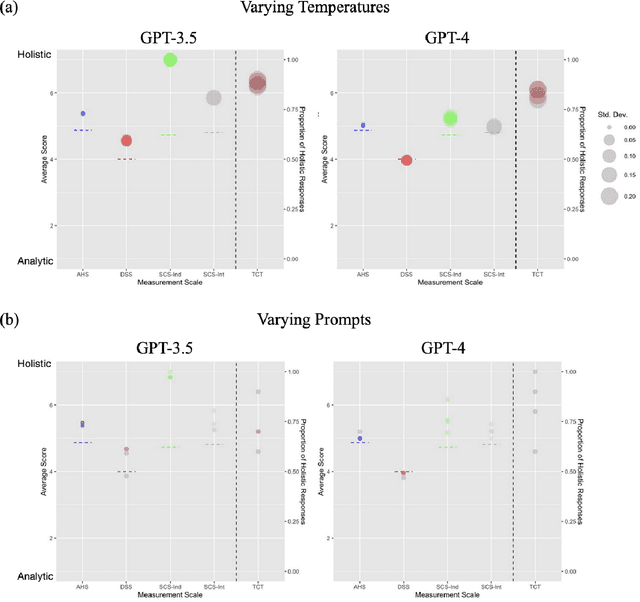
The prevalent use of Large Language Models (LLMs) has necessitated studying their mental models, yielding noteworthy theoretical and practical implications. Current research has demonstrated that state-of-the-art LLMs, such as ChatGPT, exhibit certain theory of mind capabilities and possess relatively stable Big Five and/or MBTI personality traits. In addition, cognitive process features form an essential component of these mental models. Research in cultural psychology indicated significant differences in the cognitive processes of Eastern and Western people when processing information and making judgments. While Westerners predominantly exhibit analytical thinking that isolates things from their environment to analyze their nature independently, Easterners often showcase holistic thinking, emphasizing relationships and adopting a global viewpoint. In our research, we probed the cultural cognitive traits of ChatGPT. We employed two scales that directly measure the cognitive process: the Analysis-Holism Scale (AHS) and the Triadic Categorization Task (TCT). Additionally, we used two scales that investigate the value differences shaped by cultural thinking: the Dialectical Self Scale (DSS) and the Self-construal Scale (SCS). In cognitive process tests (AHS/TCT), ChatGPT consistently tends towards Eastern holistic thinking, but regarding value judgments (DSS/SCS), ChatGPT does not significantly lean towards the East or the West. We suggest that the result could be attributed to both the training paradigm and the training data in LLM development. We discuss the potential value of this finding for AI research and directions for future research.
Spatio-Temporal Branching for Motion Prediction using Motion Increments
Aug 09, 2023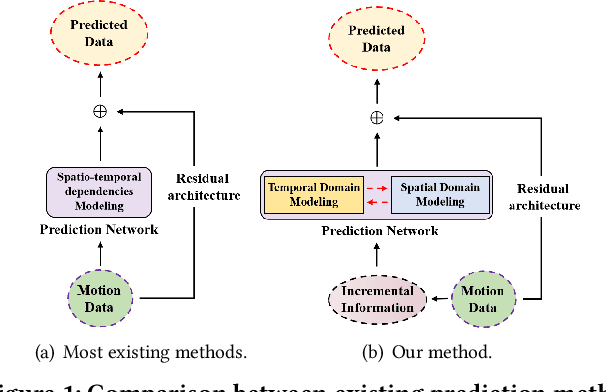
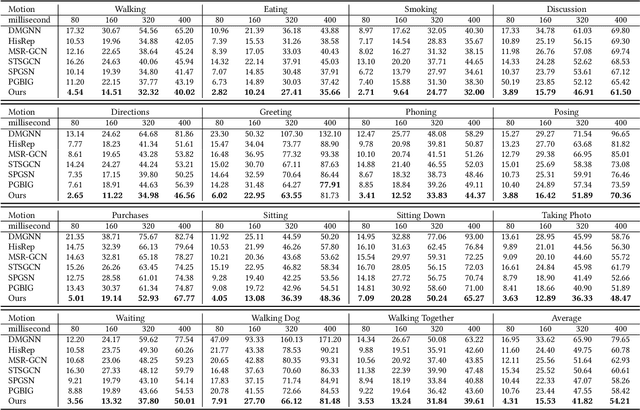
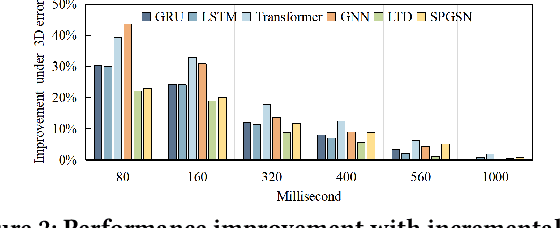
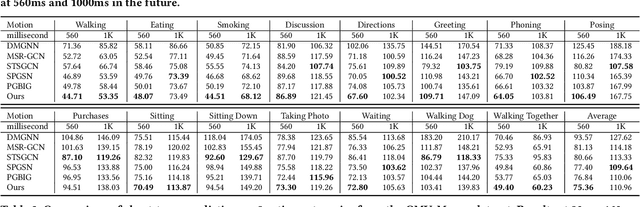
Human motion prediction (HMP) has emerged as a popular research topic due to its diverse applications, but it remains a challenging task due to the stochastic and aperiodic nature of future poses. Traditional methods rely on hand-crafted features and machine learning techniques, which often struggle to model the complex dynamics of human motion. Recent deep learning-based methods have achieved success by learning spatio-temporal representations of motion, but these models often overlook the reliability of motion data. Additionally, the temporal and spatial dependencies of skeleton nodes are distinct. The temporal relationship captures motion information over time, while the spatial relationship describes body structure and the relationships between different nodes. In this paper, we propose a novel spatio-temporal branching network using incremental information for HMP, which decouples the learning of temporal-domain and spatial-domain features, extracts more motion information, and achieves complementary cross-domain knowledge learning through knowledge distillation. Our approach effectively reduces noise interference and provides more expressive information for characterizing motion by separately extracting temporal and spatial features. We evaluate our approach on standard HMP benchmarks and outperform state-of-the-art methods in terms of prediction accuracy.
Feature Modulation Transformer: Cross-Refinement of Global Representation via High-Frequency Prior for Image Super-Resolution
Aug 09, 2023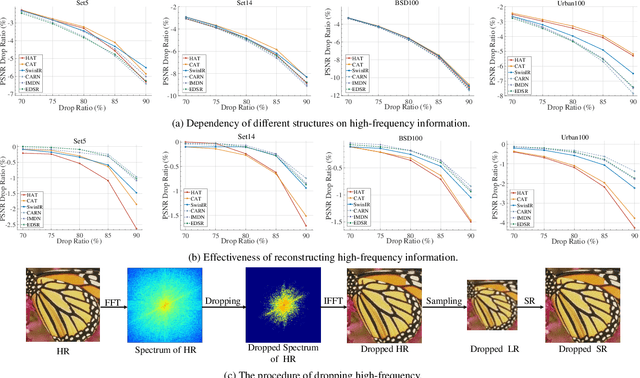
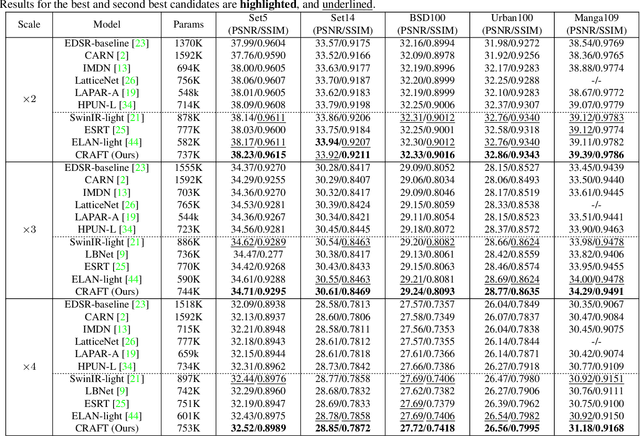
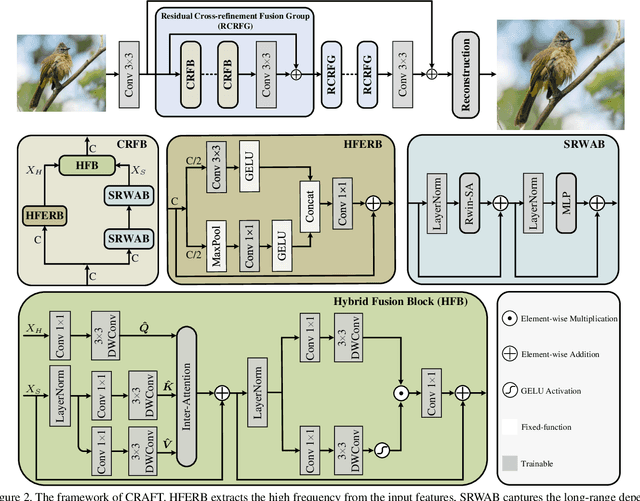
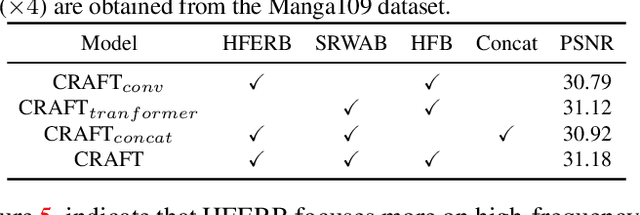
Transformer-based methods have exhibited remarkable potential in single image super-resolution (SISR) by effectively extracting long-range dependencies. However, most of the current research in this area has prioritized the design of transformer blocks to capture global information, while overlooking the importance of incorporating high-frequency priors, which we believe could be beneficial. In our study, we conducted a series of experiments and found that transformer structures are more adept at capturing low-frequency information, but have limited capacity in constructing high-frequency representations when compared to their convolutional counterparts. Our proposed solution, the cross-refinement adaptive feature modulation transformer (CRAFT), integrates the strengths of both convolutional and transformer structures. It comprises three key components: the high-frequency enhancement residual block (HFERB) for extracting high-frequency information, the shift rectangle window attention block (SRWAB) for capturing global information, and the hybrid fusion block (HFB) for refining the global representation. Our experiments on multiple datasets demonstrate that CRAFT outperforms state-of-the-art methods by up to 0.29dB while using fewer parameters. The source code will be made available at: https://github.com/AVC2-UESTC/CRAFT-SR.git.
Context-aware Event Forecasting via Graph Disentanglement
Aug 12, 2023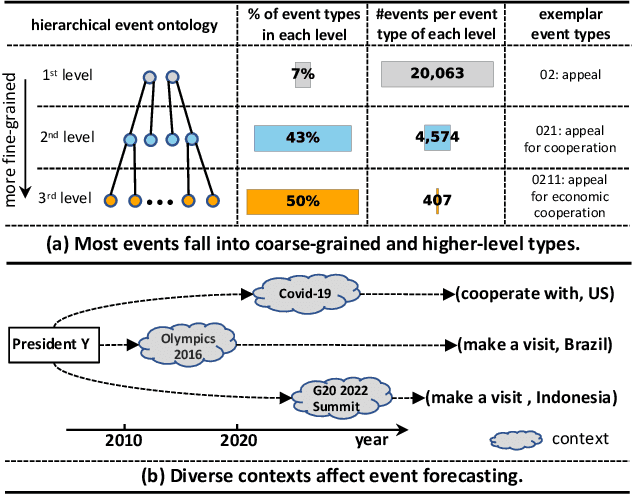
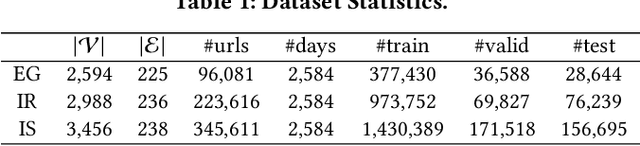
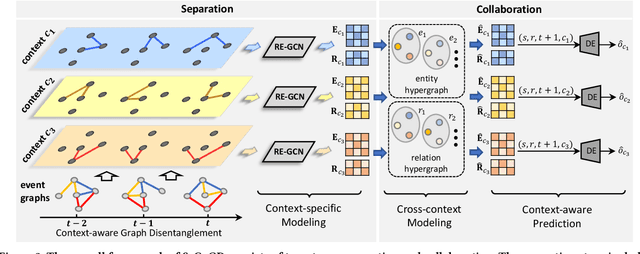
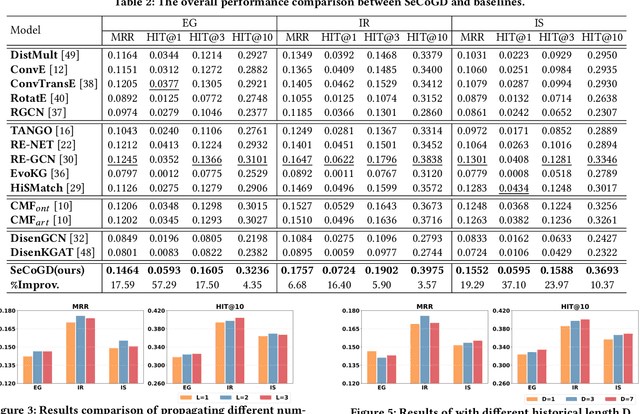
Event forecasting has been a demanding and challenging task throughout the entire human history. It plays a pivotal role in crisis alarming and disaster prevention in various aspects of the whole society. The task of event forecasting aims to model the relational and temporal patterns based on historical events and makes forecasting to what will happen in the future. Most existing studies on event forecasting formulate it as a problem of link prediction on temporal event graphs. However, such pure structured formulation suffers from two main limitations: 1) most events fall into general and high-level types in the event ontology, and therefore they tend to be coarse-grained and offers little utility which inevitably harms the forecasting accuracy; and 2) the events defined by a fixed ontology are unable to retain the out-of-ontology contextual information. To address these limitations, we propose a novel task of context-aware event forecasting which incorporates auxiliary contextual information. First, the categorical context provides supplementary fine-grained information to the coarse-grained events. Second and more importantly, the context provides additional information towards specific situation and condition, which is crucial or even determinant to what will happen next. However, it is challenging to properly integrate context into the event forecasting framework, considering the complex patterns in the multi-context scenario. Towards this end, we design a novel framework named Separation and Collaboration Graph Disentanglement (short as SeCoGD) for context-aware event forecasting. Since there is no available dataset for this novel task, we construct three large-scale datasets based on GDELT. Experimental results demonstrate that our model outperforms a list of SOTA methods.
BioCPT: Contrastive Pre-trained Transformers with Large-scale PubMed Search Logs for Zero-shot Biomedical Information Retrieval
Jul 02, 2023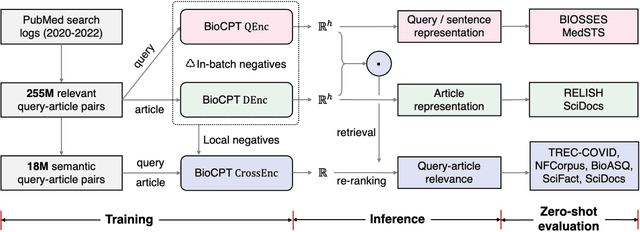
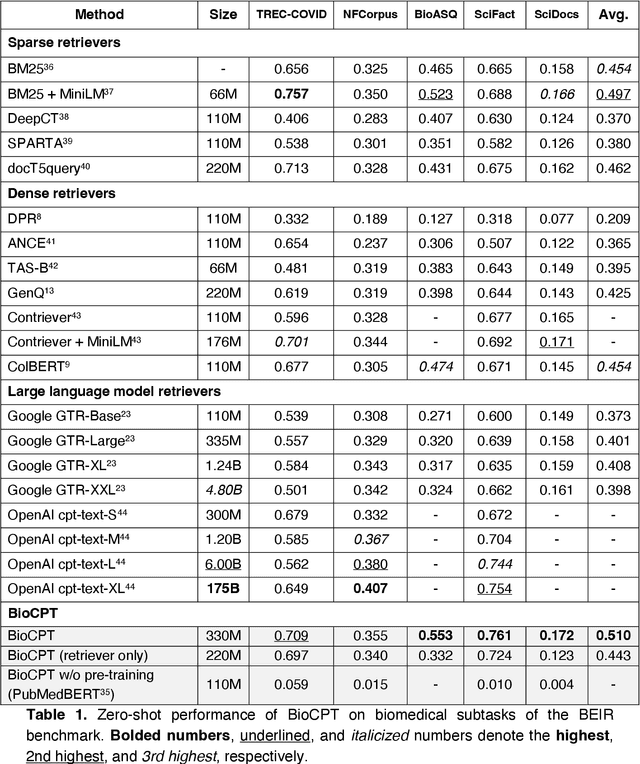
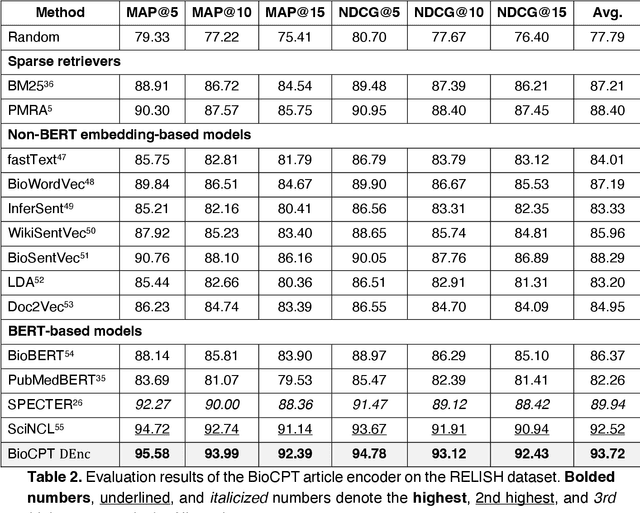
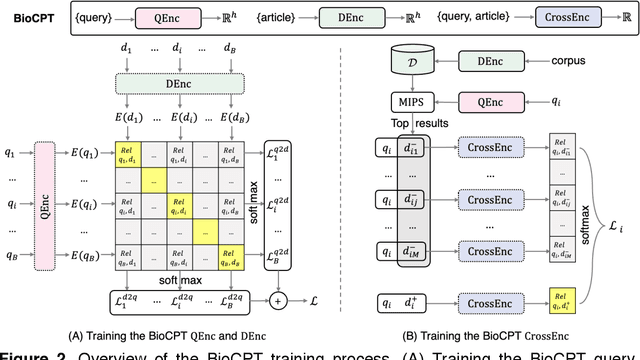
Information retrieval (IR) is essential in biomedical knowledge acquisition and clinical decision support. While recent progress has shown that language model encoders perform better semantic retrieval, training such models requires abundant query-article annotations that are difficult to obtain in biomedicine. As a result, most biomedical IR systems only conduct lexical matching. In response, we introduce BioCPT, a first-of-its-kind Contrastively Pre-trained Transformer model for zero-shot biomedical IR. To train BioCPT, we collected an unprecedented scale of 255 million user click logs from PubMed. With such data, we use contrastive learning to train a pair of closely-integrated retriever and re-ranker. Experimental results show that BioCPT sets new state-of-the-art performance on five biomedical IR tasks, outperforming various baselines including much larger models such as GPT-3-sized cpt-text-XL. In addition, BioCPT also generates better biomedical article and sentence representations for semantic evaluations. As such, BioCPT can be readily applied to various real-world biomedical IR tasks. BioCPT API and code are publicly available at https://github.com/ncbi/BioCPT.